

Если ваша IT инфраструктура растёт слишком быстро, вы рано или поздно столкнётесь с выбором – линейно увеличивать людские ресурсы на её поддержку или начинать автоматизацию. До какого-то момента мы жили в первой парадигме, а потом начался долгий путь к Infrastructure-as-Code.

Разумеется, НСПК – не стартап, но такая атмосфера царила в компании в первые годы существования, и это были очень интересные годы. Меня зовут , более 10 лет я поддерживаю инфраструктуру Linux с высокими требованиями доступности. К команде НСПК присоединился в январе 2016 года и, к сожалению, не застал самого начала существования компании, но пришел на этапе больших изменений.
В целом, можно сказать, что наша команда поставляет для компании 2 продукта. Первый – это инфраструктура. Почта должна ходить, DNS работать, а контроллеры домена – пускать вас на сервера, которые не должны падать. IT ландшафт компании огромен! Это business&mission critical системы, требования по доступности некоторых – 99,999. Второй продукт – сами сервера, физические и виртуальные. За существующими нужно следить, а новые регулярно поставлять заказчикам из множества подразделений. В этой статье я хочу сделать акцент на том, как мы развивали инфраструктуру, которая отвечает за жизненный цикл serverite.
Teekonna algus
В начале пути наш стек технологий выглядел так:
ОС CentOS 7
Контроллеры домена FreeIPA
Автоматизация — Ansible(+Tower), Cobbler
Всё это располагалось в 3х доменах, размазанных на нескольких ЦОДах. В одном ЦОД –офисные системы и тестовые полигоны, в остальных ПРОД.
Создание серверов в какой-то момент выглядело так:
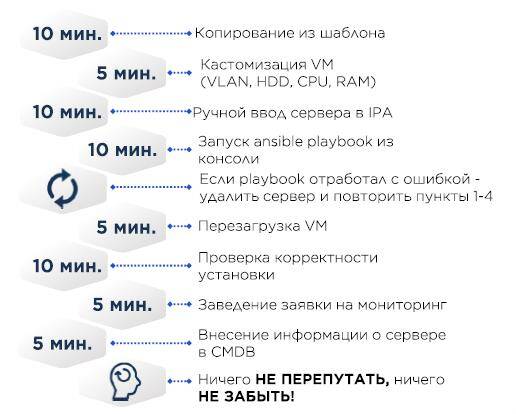
В шаблоне VM CentOS minimal и необходимый минимум вроде корректного /etc/resolv.conf, остальное приезжает через Ansible.
CMDB – Excel.
Если сервер физический, то вместо копирования виртуальной машины на него устанавливалась ОС с помощью Cobbler – в конфиг Cobbler добавляются MAC адреса целевого сервера, сервер по DHCP получает IP адрес, а дальше наливается ОС.
Поначалу мы даже пытались делать какой-то configuration management в Cobbler. Но со временем это стало приносить проблемы с переносимостью конфигураций как в другие ЦОД, так и в Ansible код для подготовки VM.
Ansible в то время многие из нас воспринимали как удобное расширение Bash и не скупились на конструкции с использованием shell, sed. В общем Bashsible. Это в итоге приводило к тому, что, если плейбук по какой-либо причине не отрабатывал на сервере, проще было удалить сервер, поправить плейбук и прокатить заново. Никакого версионирования скриптов по сути не было, переносимости конфигураций тоже.
Например, мы захотели изменить какой-то конфиг на всех серверах:
- Изменяем конфигурацию на существующих серверах в логическом сегменте/ЦОД. Иногда не за один день – требования к доступности и закон больших чисел не позволяет применять все изменения разом. А некоторые изменения потенциально деструктивны и требуют перезапуск чего-либо – от служб до самой ОС.
- Исправляем в Ansible
- Исправляем в Cobbler
- Повторяем N раз для каждого логического сегмента/ЦОД
Для того, чтобы все изменения проходили гладко, необходимо было учитывать множество факторов, а изменения происходят постоянно.
- Рефакторинг ansible кода, конфигурационных файлов
- Изменение внутренних best practice
- Изменения по итогам разбора инцидентов/аварий
- Изменение стандартов безопасности, как внутренних, так и внешних. Например, PCI DSS каждый год дополняется новыми требованиями
Рост инфраструктуры и начало пути
Количество серверов/логических доменов/ЦОД росло, а с ними количество ошибок в конфигурациях. В какой-то момент мы пришли к трём направлениям, в сторону которых нужно развивать configuration management:
- Автоматизация. Насколько возможно, нужно избегать человеческого фактора в повторяющихся операциях.
- Повторяемость. Управлять инфраструктурой намного проще, когда она предсказуема. Конфигурация серверов и инструментов для их подготовки должна быть везде одинаковой. Это так же важно для продуктовых команд – приложение должно гарантированно после тестирования попадать в продуктивную среду, настроенную аналогично тестовой.
- Простота и прозрачность внесения изменений в configuration management.
Осталось добавить пару инструментов.
В качестве хранилища кода мы выбрали GitLab CE, не в последнюю очередь за наличие встроенных модулей CI/CD.
Хранилище секретов — Hashicorp Vault, в т.ч. за прекрасное API.
Тестирование конфигураций и ansible ролей – Molecule+Testinfra. Тесты идут намного быстрее, если подключаете к ansible mitogen. Параллельно мы начали писать собственную CMDB и оркестратор для автоматического деплоя (на картинке над Cobbler), но это уже совсем другая история, о которой в будущем расскажет мой коллега и главный разработчик этих систем.
Наш выбор:
Molecule + Testinfra
Ansible + Tower + AWX
Мир Серверов + DITNET(Собственная разработка)
Cobbler
Gitlab + GitLab runner
Hashicorp Vault

Кстати про ansible роли. Сначала она была одна, после нескольких рефакторингов их стало 17. Категорически рекомендую разбивать монолит на идемпотентные роли, которые можно потом запускать отдельно, дополнительно можно добавить теги. Мы роли разбили по функционалу – network, logging, packages, hardware, molecule etc. А вообще, придерживались стратегии ниже. Не настаиваю на том, что это истина в единственной инстанции, но у нас сработало.
- Копирование серверов из “золотого образа” – зло!Из основных недостатков – вы точно не знаете, в каком состоянии образы сейчас, и что все изменения придут во все образы во все фермы виртуализации.
- Используйте дефолтные файлы конфигурации по минимуму и договоритесь с другими подразделениями, что за основные системные файлы отвечаете вы, näiteks:
- Оставьте /etc/sysctl.conf пустым, настройки должны лежать только в /etc/sysctl.d/. Ваш дефолт в один файл, кастом для приложения в другой.
- Используйте override файлы для редактирования systemd юнитов.
- Шаблонизируйте все конфиги и подкладывайте целиком, по возможности никаких sed и его аналогов в плейбуках
- Рефакторя код системы управления конфигурациями:
- Разбейте задачи на логические сущности и перепишите монолит на роли
- Используйте линтеры! Ansible-lint, yaml-lint, etc
- Меняйте подход! Никакого bashsible. Нужно описывать состояние системы
- Под все Ansible роли нужно написать тесты в molecule и раз в день генерировать отчёты.
- В нашем случае, после подготовки тестов (которых больше 100) нашлось около 70000 ошибок. Исправляли несколько месяцев.

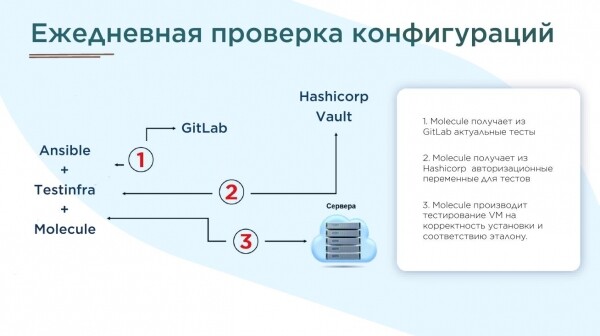
Наша реализация
Итак, ansible роли были готовы, шаблонизированы и проверены линтерами. И даже гиты везде подняты. Но вопрос надежной доставки кода в разные сегменты остался открытым. Решили синхронизировать скриптами. Выглядит так:
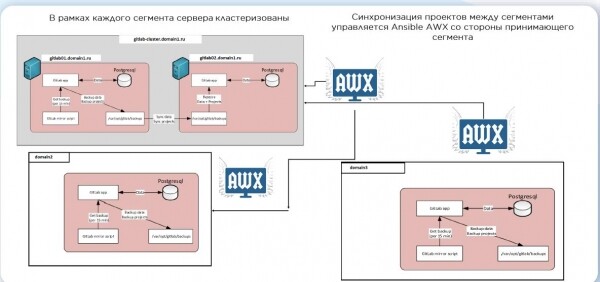
После того, как приехало изменение, запускается CI, создаётся тестовый сервер, прокатываются роли, тестируются молекулой. Если всё ок, код уходит в прод ветку. Но мы не применяем новый код на существующие сервера в автомате. Это своеобразный стопор, который необходим для высокой доступности наших систем. А когда инфраструктура становится огромной, в дело идёт ещё закон больших чисел – даже если вы уверены, что изменение безобидное, оно может привести к печальным последствиям.
Вариантов создания серверов тоже много. Мы в итоге выбрали кастомные скрипты на питоне. А для CI ansible:
- name: create1.yml - Create a VM from a template
vmware_guest:
hostname: "{{datacenter}}".domain.ru
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.ru
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Вот к чему мы пришли, система продолжает жить и развиваться.
- 17 ansible-ролей для настройки сервера. Каждая из ролей предназначена для решения отдельной логической задачи (логирование, аудит, авторизация пользователей, мониторинг и т.д.).
- Тестирование ролей. Molecule + TestInfra.
- Собственная разработка: CMDB + Оркестратор.
- Время создания сервера ~30 минут, автоматизировано и практически не зависит от очереди задач.
- Одинаковое состояние/именование инфраструктуры во всех сегментах – плейбуки, репозитории, элементы виртуализации.
- Ежедневная проверка состояния серверов с генерацией отчётов о расхождениях с эталоном.
Надеюсь мой рассказ будет полезен тем, кто в начале пути. А какой стек автоматизации используете вы?
Allikas: habr.com
