


Patroni peamine eesmärk on tagada PostgreSQL-i kõrge kättesaadavus. Kuid Patroni on vaid mall, mitte valmis tööriist (nagu dokumentatsioonis ka öeldud). Esmapilgul, kui seadistada Patroni testlaboris, võib näha, kui suurepärane see tööriist on ja kui lihtsalt ta meie katseid klastrit lõhkuda talub. Kuid praktikas tootmisõhus ei toimu kõik alati nii sujuvalt ja elegantselt, nagu testlaboris.

Räägin natuke endast. Alustasin süsteemiadministraatorina. Tegin veebiarendust. Alates 2014. aastast töötan Data Egretis. Meie ettevõte tegeleb Postgresi nõustamisega. Me haldame just Postgresit ja töötame sellega iga päev, mistõttu on meil erinev eksperiment olemas, mis on seotud kasutamisega.
Ja 2018. aasta lõpus hakkasime vaikselt Patronit kasutama. Oleme omandanud teatud kogemused. Oleme seda kuidagi diagnostikaks kasutanud, häälestanud ja leidnud oma parimad praktikad. Sellest räägin ma oma ettekandes.
Lisaks Postgres’ile armastan Linuxi. Mulle meeldib sellega katsetada ja uurida, samuti ka kernelite koostamine. Mulle meeldib virtualiseerimine, konteinerid, Docker, Kubernetes. See kõik huvitab mind, sest see on seotud vanade administraatori harjumustega. Mulle meeldib tegeleda jälgimisega. Ja armastan Postgres'iga seotud asju, mis on seotud administreerimisega, st replikatsioon, varundamine. Vabal ajal kirjutan Go-s. Ma ei ole tarkvarainsener, kirjutan lihtsalt enda jaoks Go-s. Ja see toob mulle rõõmu.

- Ma arvan, et paljud teist teavad, et Postgres ei toeta HA (High Availability) otse välja pakutuna. HA saavutamiseks tuleb midagi paigaldada, seadistada, pingutada ja see saavutada.
- On mitmeid tööriistu, ja Patroni on üks neist, mis lahendab HA probleemid üsna osavalt ja tõhusalt. Kuid kui paigaldame selle kõik testlaborisse ja käivitame, saame näha, et see töötab, saame paljusid probleeme korduda ja jälgida, kuidas Patroni nendega tegeleb. Ja näeme, et kõik toimib suurepäraselt.
- Kuid praktikas oleme kokku puutunud erinevate probleemidega. Ja nende probleemide üle ma räägin.
- Räägin, kuidas me neid diagnoosisime, mida kohendasime – kas see aitas meid või mitte.

- Ma ei hakka rääkima, kuidas Patroni installida, sest selle kohta saab internetist palju teavet, samuti on võimalik vaadata konfigureerimisfaile, et mõista, kuidas see kõik töötab ja seadistatakse. Saab uurida skeeme, arhitektuure, leides selle kohta informatsiooni internetis.
- Ma ei hakka rääkima teiste kogemustest. Räägin ainult nendest probleemidest, millega meie olime silmitsi.
- Ja ma ei hakka rääkima probleemidest, mis ei puuduta Patronit ja PostgreSQL-i. Näiteks kui probleemid on seotud tasakaalustamisega, kui meie klaster lagunes, siis sellest ma ei räägi.

Ja väike disclaimer enne, kui meie ettekannet alustame.
Kõik need probleemid, millega me silmitsi seistes kokku puutusime, tulid esimestel 6-7-8 kuud. Aja jooksul jõudsime oma sisemiste parimate tavade juurde. Ja probleemid kadusid. Seetõttu oli ettekanne planeeritud kusagil pool aastat tagasi, kui see kõik oli värskelt meeles ja ma mäletasin seda hästi.
Ettevalmistuse käigus vaatasin läbi vanad postmorten, jälgisin logisid. Osad detailid võivad olla ununenud või teatud aspekte ei pruugitud täielikult uurida probleeme analüüsides, seega võib tunduda, et probleemide käsitlemine ei ole täielik või informatsiooni on puudulik. Palun vabandage selle hetke pärast.

Mis on Patroni?
- See on HA konstruktsiooni mall. Nii on dokumentatsioonis kirjas. Ja minu arvates on see väga õige täpsustus. Patroni ei ole hõbedane kuul, mis lahendab kõik teie probleemid, st peate pingutama, et see tööle hakkaks ja kasu tooks.
- See on agenditeenus, mis paigaldatakse igasse andmebaasi teenusesse ja mis toimib omamoodi init-süsteemina teie Postgres'i jaoks. See käivitab, peatab, taaskäivitab, muudab konfiguratsiooni ja muudab teie klastrite topoloogiat.
- Seega, et säilitada klastrite olekut ja selle hetkeesitust, on vajalik mingisugune salvestusruum. Selle vaatenurgast on Patroni valinud lahenduseks klastrite oleku säilitamise välistes süsteemides. Need võivad olla Etcd, Consul, ZooKeeper või Kubernetesi Etcd, ehk üks neist variantidest.
- Üks Patroni eripära on see, et automaatne failivahetus on juba süsteemis olemas, tuleb vaid see seadistada. Võrdluseks Repmgriga, kus failivahetus tuleb komplektiga. Repmgriga saame switchoveri, kuid kui soovime automaatset failivahetust, peame selle eraldi seadistama. Patronis on automaatne failivahetus juba süsteemis kaasas.
- Ja on veel palju muid funktsioone. Näiteks konfiguratsioonide haldamine, uute koopiate loomine, varundamine jne. Kuid need jäävad ettekande välisse, seega ma nendest ei räägi.

Ja väike kokkuvõte – Patroni peamine ülesanne on teha automaatne failivahetus tõhusalt ja usaldusväärselt, et klaster jääks töökorrale ja rakendus ei märkaks muudatusi klastrite topoloogias.

Kui hakkame kasutama Patronit, muutub meie süsteem veidi keerulisemaks. Kui meil oli varem Postgres, siis Patroni kasutamise korral saame me Patroni enda, saame DCS-i, kus hoitakse olekuteavet. Ja see kõik peab kuidagi töötama. Nii et mis võib katki minna?
Võib katki minna:
- Postgres võib katki minna. See võib olla master või replikatsioon, kumbki neist võib ebaõnnestuda.
- Ka Patroni võib katki minna.
- Ka DCS, kus hoitakse olekuteavet, võib ebaõnnestuda.
- Ja võrk võib katki minna.
Kasutame neid punkte oma ettekandes.

Vaatan juhtumeid läbi, kui need muutuvad keerulisemaks, mitte mitte selle järgi, et juhtum puudutab palju komponente, vaid subjektiivsete tunnete järgi, et see juhtum oli minu jaoks keeruline, seda oli raske analüüsida... ja vastupidi, mõni juhtum oli lihtne ja seda oli lihtne analüüsida.

Esimene juhtum on kõige lihtsam. See on juhtum, kus võtsime andmebaasi klastrite ja sellel samal klastril käivitasime meie DCS-i salvestusruumi. See on kõige levinum viga. See on arhitektuuriliste raskuste viga, st erinevate komponentide ühendamine ühte kohta.
Nii et juhtus faili rike, lähme vaatama, mis juhtus.

Ja siin on meil huvitav, millal failivahe juhtus. St. meid huvitab see ajahetk, mil klastris toimus oleku muutus.
Kuid failivahe ei toimu alati üheaegselt, st. see ei kesta mingit kindlat aega, see võib venida. See võib olla kestnud protsess.
Seega on tal algusaeg ja lõppaeg, s.t. tegu on kestva sündmusega. Jagame kõik sündmused kolme ajavahemikku: meil on aeg enne failivahet, failivahetuse ajal ja pärast failivahetust. St. vaatleme kõiki sündmusi selles ajaskaalas.

Ja kohe, kui failivahe juhtus, otsime põhjust, mis juhtus, mis viis failivahetuseni.
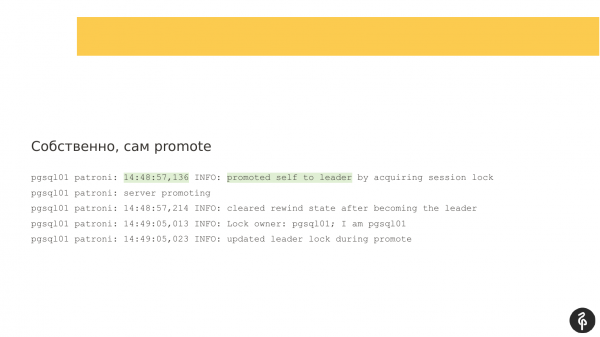
Kui vaatame logisid, näeme klassikalisi Patroni logisid. Need ütlevad meile, et serverist sai meister ja meistri roll läks sellele sõlmele. See on siin esile tõstetud.

Edasi peame aru saama, miks fail on toimunud, st millised sündmused on põhjustanud, et meistri roll on pidanud üle minema ühelt sõlmlt teisele. Sel juhul on kõik lihtne. Meil on probleem salvestussüsteemiga. Meister mõistis, et ta ei saa DCS-iga töötada, st tekkis mingi probleem suhtluses. Ta ütleb, et ei saa enam meistriks olla ja loobub oma volitustest. See rida "demoted self" räägib just sellest.

Kui vaatame sündmusi, mis eelnesid failimisele, siis näeme seal neid põhjuseid, mis põhjustasid probleemi meistri töö jätkamiseks.
Kui vaatame Patroni logisid, siis näeme, et meil on palju erinevaid vigu, ajastusi, st Patroni agent ei saa töötada DCS-iga. Sel juhul on see Consul agent, kellega suhtlemine toimub pordil 8500.
Ja probleem seisneb selles, et Patroni ja andmebaas on käivitunud ühel ja samal hostil. Ja sellel samal sõlmel olid käivitatud Consul serverid. Koormuse tekitamine serveris põhjustas probleeme ka serverite Consuliga. Nad ei suutnud normaalselt suhelda.

Mõne aja pärast, kui koormus oli vaibunud, suudeti meie Patroni jälle suhelda agentidega. Tavaline töö taastus. Ja sama Pgdb-2 server sai taas meistriks. See tähendab, et toimus väike vahetus, mille tõttu sõlm kaotas oma meistri volitused ja võttis need uuesti endale, st kõik naasis algsesse seisundisse.

Seda võib pidada vale häireks või samas võib öelda, et Patroni tegutses õigesti. See tähendab, et ta sai aru, et ei suuda säilitada klasti olekut ja võttis enda volitused tagasi.
Siin tekkis probleem, kuna Consul serverid olid sama riistvara peal, mis andmebaasid. Seega mõjutab iga koormus, olgu see siis koormus kettadelt või protsessoritelt, ka suhtlemist Consul klastri küljest.

Otsustasime, et need ei tohi koos eksisteerida, seega eraldasime Consulile eraldi klastrite. Patroni töötas nüüd eraldi Consuliga, st Postgresi klaster oli eraldi, Consul klaster oli eraldi. See on põhijuhend, kuidas kõiki neid asju eraldada ja hoida, et need ei eksisteeriks koos.
Ühe variandina on võimalik reguleerida ttl, loop_wait ja retry_timeout parameetreid, st proovida neid parameetreid suurendades lühiajalised koormuse tipud üle elada. Kuid see ei ole kõige sobivam lahendus, kuna koormus võib kesta kaua. Sel juhul ületame lihtsalt nende parameetrite limiidid, mis ei pruugi olla kasulik.
Esimene probleem, nagu te arvatavasti aimasite, on lihtne. Me panime DCS koos andmebaasiga kokku ja saime probleemi.

Teine probleem on sarnane esimesele. See sarnaneb sellega, et meil on jälle probleeme DCS süsteemiga suhtlemisel.

Kui vaatame logisid, näeme, et meil on jälle suhtlemise viga. Patroni ütleb, et ta ei saa DCS-iga suhelda, seetõttu läheb praegune master repliigi režiimi.
Vana master muutub repliigiks, siin toimib Patroni nagu peab. Ta käivitab pg_rewind, et tagasiviia tehingu ajalugu ja seejärel ühenduda uue masteriga, et jõuda uue masterini. Nii toimib Patroni, nagu tal ette nähtud on.

Siin peame leidma selle koha, mis eelnes failide muutmisele, st need vead, mis olid põhjuseks, miks meil failide muutmine aset leidis. Selles osas on logide jälgimine Patroni abil üsna mugav. Ta kirjutab kindla intervalliga samu sõnumeid. Kui me alustame logide kiiret kerimist, näeme, et logid on muutunud, mis tähendab, et mingeid probleeme on alanud. Me taastume kiiresti sellele kohale ja vaatame, mis toimub.
Normaalsetes olukordades näevad logid umbes sellised välja. Kontrollitakse lukustuse omanikku. Ja kui omanik on näiteks muutunud, võivad tekkida mingeid sündmusi, millele Patroni peab reageerima. Kuid antud juhul on meil kõik korras. Otsime seda kohta, kus vead algasid.

Kerides tagasi sinna, kus vead hakkasid ilmuma, näeme, et meil toimus automaatne failide muutmine. Ja kuna meie vead olid seotud suhtlemisega DCS-iga ning meie puhul kasutasime Consulit, vaatame üle ka Consuli logid, et näha, mis seal toimus.
Umbes ajakohastades failiserveri aega ja Consul'i logides olevat aega, näeme, et meie Consul'i klastrikaaslased hakkavad kahtlema teiste Consul'i klastriliikmete olemasolus.

Ja kui vaadata ka teiste Consul'i agentide logisid, siis on seal samuti näha, et toimub mingi võrgu kokkuvarisemine. Kõik Consul'i klastriliikmed kahtlevad üksteise olemasolus. See on andnud tõuke failiserverile.
Kui vaadata, mis juhtus enne neid vigu, siis võib näha erinevaid vigu, näiteks deadline, RPC ebaõnnestumine, st on ilmselgelt mingi probleem Consul'i klastriliikmete omavahelises suhtluses.

Lihtsaim vastus on - parandada võrku. Kuid mul, seistes tribüünil, on lihtne sellest rääkida. Kuid asjaolud on sellised, et tellija ei saa alati endale lubada võrgu parandamist. Ta võib elada andmekeskuses ja tal ei pruugi olla võimalusi võrku parandada või seadmetele mõju avaldada. Seetõttu vajame mingeid teisi variante.

Variantideks on:
- Lihtsaim variant, millest räägitakse minu arvates isegi dokumentatsioonis, on Consul-i kontrollide keelamine, st lihtsalt tühja massiivi edastamine. Niiviisi ütlebime Consul-agendile, et ta ei kasuta mingeid kontrolle. Nende kontrollide tõttu suudame me ignoreerida neid võrgu torme ja mitte algatada failide edastamist.
- Teine variant on raft_multiplieri kontrollimine. See on Consul-serveri parameeter. Vaikeväärtus on 5. See väärtus on dokumentatsioonis soovitatud staging keskkondade jaoks. Tegelikult mõjutab see sõnumite vahetamise sagedust Consul võrgu osaliste vahel. See parameeter mõjutab ametlike teatiste vahetamise kiirus, mis toimub Consul-klastris. Tootmisprotsessis soovitatakse seda väärtust vähendada, et sõlmed saaksid teateid sagedamini vahetada.
- Teine võimalus, mida me hakkasime kasutama, on Consul-protsesside prioriteedi suurendamine teiste protsesside seas operatsioonisüsteemi protsessoriplaneerijas. On olemas selline parameeter nagu "nice", mis määrab protsesside prioriteedi, mida operatsioonisüsteemi planeerija arvestab. Me vähendasime Consul-agentide nice väärtust, st tõstsime prioriteeti, et operatsioonisüsteem annaks Consul-protsessidele rohkem aega tööks ja oma koodi täitmiseks. Meie puhul lahendas see meie probleemi.
- Teine võimalus on mitte kasutada Consulit. Mul on sõber, kes on suur Etcd'i toetaja. Me vaidleme regulaarselt, kumb on parem: Etcd või Consul. Kuid mis puutub paremustesse, siis jõuame tavaliselt arusaamisele, et Consul'il on agent, mida tuleb igas andmebaasi sõlmes käivitada. See tähendab, et Patroni suhtleb Consul'i klastriga läbi selle agendi. Ja just see agent muutub kitsaskohaks. Kui agendiga midagi juhtub, siis ei saa Patroni enam Consul'i klastri tööga tegeleda. See on probleem. Etcd puhul ei ole agenti. Patroni saab otse suhelda Etcd'i serverite nimekirjaga ja nendega. Seega, kui teie ettevõttes on kasutusel Etcd, siis võib see ilmselt olla parem valik kui Consul. Kuid meie klientide puhul oleme alati piiratud sellega, mida klient on valinud ja kasutab. Enamikul juhtudel on kõigil klientidel Consul.
- Viimase punktina vaatame parameetrite väärtusi üle. Saame neid väärtusi tõsta, lootes, et meie lühiajalised võrguprobleemid on lühikesed ega ületa nende parameetrite vahemikku. Nii saame vähendada Patroni agressiivsust automaatse failivahetuse osas, kui tekivad mingid võrguprobleemid.
Usun, et paljud, kes kasutavad Patronit, tunnevad selle käsu ära.
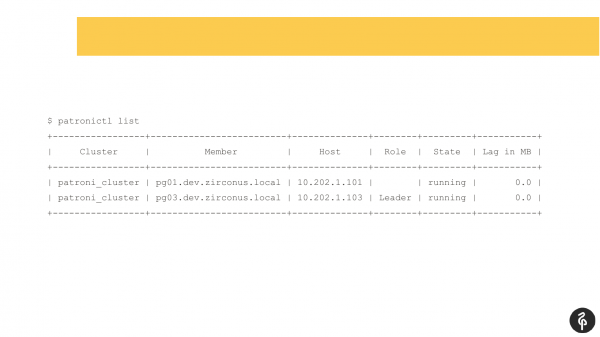
See käsk näitab klastrite praegust seisundit. Esmapilgul võib see pilt tunduda normaalne. Meil on meister, meil on koopiahäire, replikatsioonilagi ei ole. Kuid see pilt on normaalne seni, kuni me ei tea, et selles klastris peaks olema kolm sõlme, mitte kaks.

Seega toimus automaatne failivahetus. Pärast seda failivahetust kadus meil koopiahäire. Peame välja selgitama, miks see kadus ja tagasi tooma, taastama. Ja me läheme jälle logidesse, et vaadata, miks automaatne failivahetus toimus.

Antud juhul sai teine koopiahäire meistriks. Siin on kõik korras.

Ja peame vaatama replikat, mis on väljaspool klastrit. Avame Patroni logid ja vaatame, et klastriga ühendamisel tekkis probleem pg_rewind'i etapis. Klastrisse ühendamiseks on vajalik tagasiviimine tehingulogisse, et küsida vajalik tehingulogi meistrilt ja sellega meistrile järele jõuda.
Antud juhul meil ei ole tehinguloge ja replikatsioon ei saa käivituda. Seetõttu peatame Postgresi vea tõttu. Seega ei ole see klastris.

Peame mõistma, miks seda klastris ei ole ja miks logisid ei olnud. Liigume uue meistri juurde ja vaatame, mis tal logides on. Tundub, et pg_rewind'i teostamisel toimus checkpoint. Ja osa vanadest tehingulugudest nimetati lihtsalt ümber. Kui vana meister proovida uue meistriga ühenduda ja neid logisid küsida, olid need juba ümber nimetatud, neid lihtsalt ei olnud.

Ma võrdlesin sündmuste toimumise aegu. Seal on vahe vaid 150 millisekundit, st checkpoint lõpetati 369 millisekundiga, WAL-segmendid nimetati ümber. Ja 517 millisekundi möödudes käivitus vana koopia rewind. St me saime vaid 150 millisekundiga hakkama, et koopia ei saaks ühendust luua ja töötada.

Millised on valikud?
Alguses kasutasime replikatsiooni slote. Me arvasime, et see on hea. Kuigi käituse algfaasis lülitasime slote välja. Me arvasime, et kui slote koguneb palju WAL-segmente, võib meistriseade kokku kukkuda. Ta kukub kokku. Me piinasime ennast mõnda aega ilma slotideta. Ja saime aru, et me vajame slote, me taastastasime need.
Aga siin on probleem, et kui meistriseade muutub koopiaks, kustutab ta slote ja koos slottidega ka WAL-segmendid. Selle probleemi vältimiseks otsustasime tõsta wal_keep_segments parameetrit. See on vaikimisi 8 segmenti. Tõstsime selle 1000-ni ja vaatasime, kui palju vaba ruumi meil on. Ja me andsime 16 gigabaiti wal_keep_segments jaoks. St üleminekul on meil alati kõigil sõlmedel 16 gigabaiti tehingute ajakirju reservi.
Ja pluss – see on endiselt asjakohane pikaajaliste hooldustööde jaoks. Oletame, et peame värskendama ühte replit. Ja me tahame selle välja lülitada. Me peame uuendama tarkvara, võib-olla operatsioonisüsteemi, midagi veel. Ja kui me repliika välja lülitame, kustutatakse sellele replikale ka pesa. Ja kui me kasutame väikest wal_keep_segments, siis pikka aega repliika puudumise korral, mängitakse tehingu logid uuesti. Me käivitame repliika, see küsib neid tehingu logisid, kus ta peatus, kuid meistris ei pruugi neid olla. Ja repliika ei saa ka ühendust saada. Seetõttu hoiame suurt logide varu.

Meil on tootmisbaas. Seal töötavad juba projektid.
Toimus faili tõrge. Me sisenesime ja vaatasime – kõik on korras, replikad on kohal, replikatsiooni viivitus puudub. Ka logide osas pole vigu, kõik on hästi.
Toote meeskond ütleb, et tundub, et peaks olema mingit tüüpi andmeid, kuid me näeme neid ühes allikas, ent andmebaasis neid ei ole. On vaja mõista, mis nendega juhtus.

On selge, et pg_rewind on need üle kirjutatud. Me mõistsime seda kohe, kuid läksime vaatama, mis juhtus.

Logides saame alati leida, millal toimus failide haldamine, kes sai meistriks ja saame määrata, kes oli vana meister ja millal ta soovis saada koopiaks. Seega, need logid on vajalikud, et selgitada välja kadunud tehinguajakirjade maht.
Meie vana meister taaskäivitati. Ja autostardi seadetes oli kirjas Patroni. Patroni käivitus ja seejärel käivitas Postgres’i. Täpsemalt enne Postgres’i käivitamist ja enne kui ta tegi sellest koopiat, käivitas Patroni pg_rewind protsessi. Seega kustutas ta osa tehinguajakirjadest, laadis uued alla ja ühendas need. Siin toimis Patroni suurepäraselt, nagu peab. Meie klaster taastus. Meil oli 3 sõlme, pärast failide haldamist oli 3 sõlme – kõik on suurepärane.

Me kaotasime osa andmeid. Ja meil on vaja aru saada, kui palju me kaotasime. Otsime just seda hetke, mil toimus rewindi protsess. Saame seda leida selliste logikirjete põhjal. Rewind käivitus, tegi midagi ja lõpetas.

Peame leidma selle positsiooni tehinguajakirjades, kus vana meister peatunud on. Antud juhul on see see mark. Ja me vajame teist märki, st seda vahet, mille võrra vana meister erineb uuest.
Võrdleme tavalist pg_wal_lsn_diff kahe ajamärgiga. Antud juhul saame 17 megabaiti. Kas see on palju või vähe, otsustab igaüks ise. Sest kellelegi on 17 megabaiti vähe, kellelegi palju ja vastuvõetamatu. Siin peab igaüks individuaalselt hindama vastavalt oma äri vajadustele.

Aga mida me enda jaoks selgitanud oleme?
Esiteks peame otsustama – kas me vajame süsteemi taaskäivitamise järel alati Patroni automaatkäivitust? Tihti on nii, et peame minema vana peameistri juurde, vaatama, kui kaugele ta on läinud. Võib-olla kontrollima tehingute ajakirjade segmente, vaatama, mis seal toimub. Ja mõistma – kas me saame need andmed kaotada või peame käivitama vanema peameistri standalone-režiimis, et need andmed välja tuua.
Ja alles pärast seda peame langetama otsuseid, kas saame need andmed kõrvale jätta või saame neid taastada, ühendades selle sõlme meie klastrisse replikana.
Lisaks on olemas parameeter «maximum_lag_on_failover». Kui ma õigesti mäletan, on selle parameetri vaikimisi väärtus 1 megabaid.
Kuidas see töötab? Kui meie replikatsioon on andmete edastamisel 1 megabaidiga maas, ei osale see replikatsioon valimistel. Ja kui peaks juhtuma fail, vaatab Patroni, millised replikatsioonid on maas. Kui nad on suure hulga tehingute logidega maas, ei saa nad olla peamine. See on väga hea kaitsefunktsioon, mis aitab vältida suurte andmekadude tekkimist.
Aga probleem seisneb selles, et Patroni ja DCS replikatsioonilagu uuendatakse teatud ajavahemike järel. Minu arust on vaikimisi ttl väärtus 30 sekundit.
Seega võib olla olukord, kus DCS-is oleva replikatsiooni lag on üks, aga tegelikult võib see olla hoopis teine lag või isegi mitte olla, st see ei ole reaalajas. Ja see ei kajasta alati tõelist olukorda. Seega ei tasuks sellele tuginedes keerukat loogikat ehitada.
Ja alati jääb risk andmete kadumise osas. Halvimal juhul kehtib üks valem, parimal juhul aga teine. St kui planeerime Patroni rakendamist ja hindame, kui palju andmeid me võime kaotada, peame arvestama nende valemitega ja saama enam-vähem aru, kui palju andmeid me võime kaotada.
Ja teil on häid uudiseid. Kui vana meister lahkus, võib ta lahkuda mõne taustaprotsessi arvelt. Ehkki mingil hetkel toimus autovakuum ja ta kirjutas andmed, salvestades need tehingute registrisse. Need andmed saame hõlpsasti tähelepanuta jätta ja kaotada. Sellest ei ole mingit probleemi.

Nii näevad logid välja juhul, kui on määratud maximum_lag_on_failover ja toimus failover, ning tuleb valida uus meister. Replikatsioon hindab ennast osalemiseks sobimatuks ja loobub liidri valimisest. Ta ootab, kuni uus meister on valitud, et siis temaga ühendust võtta. See on täiendav meede andmete kadumise vältimiseks.

Siin on meie tootmismeeskond märkinud, et nende toode kogeb probleeme Postgresi kasutamisel. Samas ei saa me kogu meistrisse sisse logida, kuna see ei ole SSH kaudu saadaval. Samuti ei toimu automaatset failoverit.
See host saadeti sunniviisiliselt taaskäivitama. Taaskäivitamise tõttu toimus automaatne failover, kuigi oleks olnud võimalik teha ka käsitsi failoverit, nagu ma nüüd mõistan. Pärast taaskäivitamist vaatame juba, mis meil praeguse meistriga oli.
Samas teadsime meeldud, et meil on ketastega probleeme, st olime juba jälginud, kus kaevata ja mida otsida.

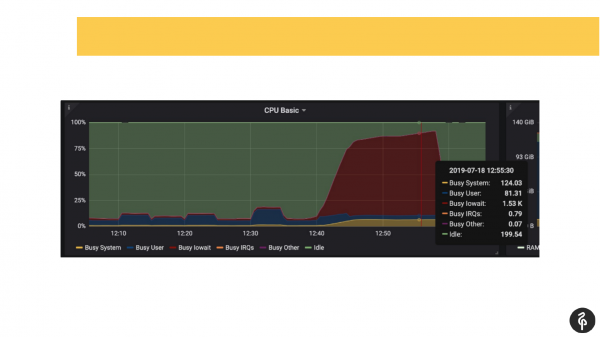
Uurime PostgreSQL logi, et vaadata, mis seal toimub. Nägime seal komiteerimisi, mis kestavad üks-kaks-kolm sekundit, mis ei ole normaalne. Nägime, et meie automaatne puhastus käivitub väga kaua ja kummaliselt. Ja nägime ajutisi faile kettal. St need on kõik ketaste probleemide näitajad.

Vaatasime süsteemi dmesg’i (tuumaküsimuste logi). Ja nägime, et meil on ühe kettaga probleeme. Kettasüsteem oli tarkvaraline RAID. Vaatasime /proc/mdstat ja nägime, et meil puudub üks ketas. St siin on 8 ketta RAID, meil puudub üks. Kui slaidi hoolikalt vaadata, saab väljundis näha, et meil puudub sde. Üldiselt öeldes, on ketas välja langenud. See käivitas ketta probleemid ja rakendused kogesid ka probleeme PostgreSQL klastriga töötamisel.

Ja ei aita meile antud juhul Patroni, kuna Patronil pole ülesannet jälgida serveri, ketta seisundit. Selliseid olukordi peame jälgima välise monitooringu kaudu. Me lisasime välisse monitooringusse kiiresti ketaste monitooringu.
Ja tuli mõte – kas võiks meid aidata fencing või software watchdog? Arvasime, et neist ei oleks olnud kasu, kuna probleemide ajal jätkas Patroni suhtlemist DCS-klastriga ega näinud ühtegi probleemi. See tähendab, et DCS-i ja Patroni jaoks oli klaster korras, kuigi tegelikult oli probleeme ketastega, oli probleeme andmebaasi saadavusega.
Minu arvates on see üks kõige kummalisemaid probleeme, mida olen väga kaua uurinud, lugenud läbi väga palju logisid, kaevanud ja nimetanud seda klastrisimulatsiooniks.

Probleem seisnes selles, et vana master ei saanud normaalseks replikaks, st Patroni käivitas selle, Patroni näitas, et see sõlm on replikana kohal, kuid samas ei olnud ta normaalne replika. Nüüd näete, miks. See jäi mulle meelde selle probleemi käsitlemisest.

Kuidas kõik algas? Nagu eelmine probleem, algas see kettajamidest. Meil olid sekundis üks või kaks tehtud muudatust.

Oli ühenduse katkestamisi, st kliendid viskasid välja.

Oli erineva raskusastmega blokeeringuid.

Ja seetõttu ei olnud kettaalajuhatus kuigi vastutulelik.

Ja kõige müstilisem minu jaoks – see saabunud immediate shutdown request. Postgres'il on kolm väljalülitamise režiimi:
- On graceful, kui me ootame, et kõik kliendid ise välja lülituvad.
- On fast, kui me sunnime kliente välja lülituma, sest me valmistume väljalülitamiseks.
- Ja immediate. Antud juhul immediate ei teata isegi klientidele, et nad peaks välja lülituma, vaid see lihtsalt sulgub ilma hoiatamata. Kõigile klientidele saadab operatsioonisüsteem juba RST sõnumi (TCP-sõnum, et ühendus katkestati ja kliendil pole enam midagi teha).
Kes saatis selle signaali? Postgres'i taustaprotsessid ei saada üksteisele selliseid signaale, st see on kill-9. Nad ei saata selliseid üksteisele, vaid reageerivad vaid sellega, st see on Postgres'i hädasekundiline taaskäivitamine. Kes selle saatis, ma ei tea.
Vaadates käsku „last”, märkasin, et üks inimene, kes oli samuti sellele serverile sisse logitud, oli koos meiega, kuid ma kartsin küsimust esitada. Võib-olla oli see kill -9. Logidest oleksin näinud kill -9, kuna Postgres teatab, et sai kill -9, kuid ma ei leidnud seda logidest.

Edasi uurides märkasin, et Patroni ei olnud pikka aega loginud – 54 sekundit. Ja kui võrrelda kahte ajatemplit, siis siin oli umbes 54 sekundit sõnumeid.
Selle aja jooksul toimus automaatne failivõit. Patroni töötas siinkohal taas suurepäraselt. Meie vana meister ei olnud jõudnud, midagi temaga juhtus. Ja algasid uue meistri valimised. Kõik toimis hästi. Meie pgsql01 sai uueks juhiks.

Meil on replikatsioon, mis sai meistriks. Ja on teine replikatsioon. Teise replikatsiooniga olidki probleemid. See üritas ümber konfigureerida. Nagu ma aru saan, üritas ta muuta recovery.conf, taaskäivitada Postgresi ja ühenduda uue meistriga. iga 10 sekundi tagant saadab ta sõnumeid, et ta proovib, kuid tal ei õnnestu.

Ja isegi nendel katsetel, kui vana master saab immediate-shutdown signaali. Master taaskäivitub. Ja taastumine lõppeb, kuna vana master läheb taaskäivitamise režiimi. St replikatsioon ei saa temaga ühendust võtta, kuna ta on välja lülitatud.

Mingi hetk ta toimis, kuid replikatsioon ei käivitatud.
Mul on ainult üks hüpotees, et recovery.conf-is oli vana masteri aadress. Ja kui uus master ilmus, siis teine replik püüdis endiselt ühendust võtta vana masteriga.
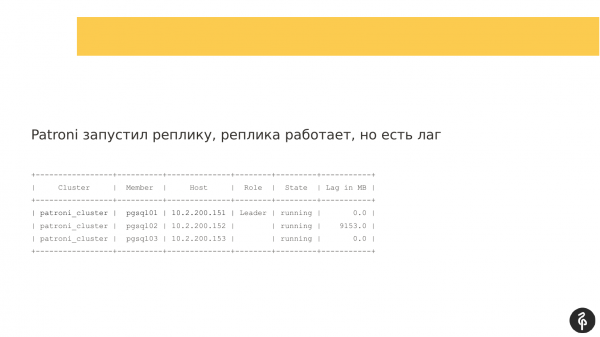
Kui Patroni käivitati teisel replikal, node käivitati, kuid ei saanud replikatsiooni kaudu ühendust võtta. Ja replikatsiooni viivitus tekkis, mis nägi välja umbes niimoodi. St kõik kolm sõlme olid kohal, kuid teine sõlm jäi maha.
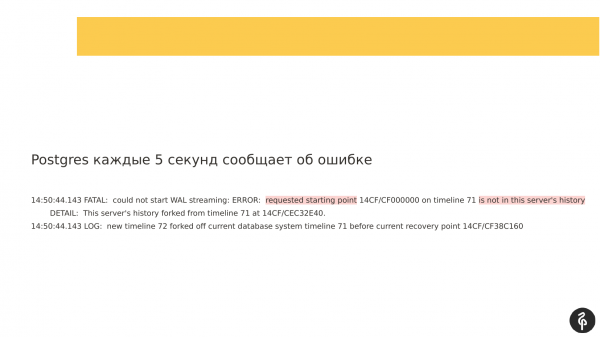
Samas, kui vaadata logisid, mis kirjutati, oli näha, et replikatsioon ei saa käivituda, kuna tehingu logid erinevad. Ja need tehingu logid, mida master pakub ja mis on märgitud recovery.conf-is, ei sobi lihtsalt meie praeguse sõlmega.

Ja tegin siin vea. Ma oleksin pidanud tulema ja vaatama, mis recovery.confis toimub, et kontrollida oma oletust, et me ei seo end vale meesteriga. Aga toona ma alles õppisin ja see ei tulnud mulle pähe, või ma märkasin, et replikatsioon jääb maha ja seda tuleb ümber laadida, nii et ma töötasin kuidagi hooletult. See oli minu eksimus.

30 minuti pärast tuli administraator, st ma taaskäivitasin Patroni replikatsioonil. Ma olin juba temast loobunud, mõtlesin, et seda tuleb ümber laadida. Ja mõtlesin – taaskäivitaks Patroni, äkki õnnestub midagi head. Recovery käivitus. Ja andmebaas avanes isegi, ta oli valmis ühendusi vastu võtma.
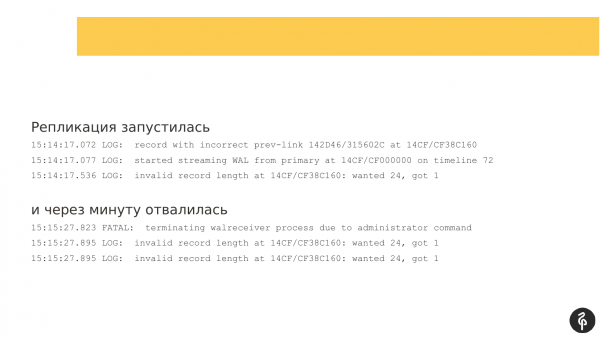
Replikatsioon käivitus. Aga minuti pärast kukkus see välja veaga, et tal ei sobi tehingute logid.

Mõtlesin, et taaskäivitaks veel kord. Taaskäivitasin Patroni veel kord, ja ma ei käivitanud Postgresi, vaid just Patroni, lootes, et ta maagiliselt käivitab andmebaasi.

Replikatsioon käivitus uuesti, kuid tehingute ajalugu erines, need ei olnud need, mis olid eelmisel käivitamisel. Replikatsioon peatus uuesti. Ja sõnum oli juba veidi erinev. See ei andnud mulle eriti teavet.

Ja siis tuli mul mõte – mis siis, kui ma taaskäivitaksin Postgressi, samal ajal teeksin praeguses masteris checkpoint'i, et edendada tehingute ajaloos punkti veidi edasi, et taastumine algaks teisest hetkest? Lisaks oli meil seal ka WAL'i varu.

Taaskäivitasin Patroni, tegin paar checkpoint'i masteris, paar taaskäivitamise punkti replikas, kui see avati. Ja see aitas. Mõtlesin kaua, miks see aitas ja kuidas see toimis. Ja replikatsioon käivitus. Ja replikatsioon enam purunenud ei olnud.

See probleem on minu jaoks üks müsteeriume, mille üle ma ikka veel pead vaevan, et mis seal tegelikult toimus.
Milliseid järeldusi siit teha? Patroni töötab nagu kavandatud ja ilma vigu tegemata. Kuid see ei tähenda 100% garantii, et kõik on korras. Replika võib tööle hakata, kuid samas võib see olla pooliku olekuga, ning rakendus ei saa sellise replikaga töötada, kuna seal on vanad andmed.
Ja pärast failivahetust tuleb alati kontrollida, et meie klaster on korras, st et replikaid on piisavalt ja replikatsioonis pole viivitusi.
Ja nende probleemide käsitlemise käigus formuleerin soovitusi. Olen püüdnud need koondada kahte slaidi. Tõenäoliselt võiks kõik lood kokku panna kahe slaidi peale ja neid vaid rääkida.

Patronit kasutades peab alati olema monitooring. Peate alati teadma, millal on toimunud automaatne failivahetus, sest kui te ei tea, et teil on olnud automaatne failivahetus, siis ei kontrolli te klastrit. Ja see on halb.
Pärast igat failivahetust peame alati käsitsi kontrollima klastrit. Peame veenduma, et meil on alati piisav arv replikasid, et replikatsioonis pole viivitusi, logides ei esine voogedastusega, Patroni ega DCS süsteemiga seotud vigu.
Automaatika suudab toimida tõhusalt, Patroni on väga hea tööriist. See suudab todistada, kuid see ei vii klastrit soovitud olekusse. Ja kui me sellest teada ei saa, siis tekivad meil probleemid.
Patroni ei ole hõbedane kuul. Me peame ikkagi mõistma, kuidas Postgres töötab, kuidas replikeerimine toimub ja kuidas Patroni Postgresega suhtleb ning kuidas sõlmede vahel kooskõlastamine toimub. See on vajalik, et osata käsitsi lahendada tekkivaid probleeme.

Kuidas ma lähenen diagnostika küsimusele? Kuidas on kujunenud, et töötame erinevate klientidega ja ELK virnat keegi ei kasuta, mistõttu tuleb logisid uurida, avades 6 konsooli ja 2 vahelehte. Ühel vahelehel on Patroni logid iga sõlme jaoks, teisel vahelehel on Consuli või vajadusel Postgrese logid. Diagnoosimine on väga keeruline.
Milliseid lähenemisi ma olen välja töötanud? Esiteks, ma alati vaatan, millal failisüsteem muutus. See on minu jaoks tee ääres. Vaatan, mis juhtus enne failivahetust, selle ajal ja pärast failivahetust. Failivahetusel on kaks märgist: alguse ja lõpu aeg.
Jätkan logide vaatamist kuni failivahetuseni, mis toimus enne failivahetust, st otsin põhjuseid, miks failivahetus juhtus.
See annab ülevaate sellest, mis toimus ja mida tulevikus teha, et selliseid olukordi ei tekiks (ja seega ei toimuks failivahetust).
Kuhu me tavaliselt vaatame? Mina vaatan:
- Esiteks Patroni logisid.
- Seejärel vaatan Postgrese logisid või DCS logisid, sõltuvalt sellest, mida olen Patroni logides leidnud.
- Ka süsteemi logid annavad vahel arusaama, mis oli failivahetuse põhjus.

Kuidas ma suhtub Patronisse? Patronisse suhtub väga hästi. Minu arvates on see parim, mis praegu olemas on. Tunnen palju teisi tooteid. Need on Stolon, Repmgr, Pg_auto_failover, PAF. 4 tööriista. Olen neid kõiki proovinud. Patroni meeldis mulle kõige rohkem.
Kui keegi küsib: „Kas ma soovitaksin Patronit?“, siis ütlen, et jah, sest Patron meeldib mulle. Ja tundub, et olen õppinud seda hästi seadistama.
Kui teid huvitab, millised probleemid võivad veel esineda Patroniga, peale nende, mida olen maininud, saate alati minna lehele GitHubis on palju erinevaid lugusid ja seal arutatakse palju huvitavaid probleeme. Lõpuks on seal välja toodud ja lahendatud ka mõned vead, nii et see on huvitav lugemine.
Seal on huvitavaid lugusid sellest, kuidas inimesed endale jalga lasevad tulistada. Väga õpetlik. Loed ja mõistad, et seda ei peaks tegema. Panin endale märkme.
Soovin jagada suurt tänu ettevõttele Zalando, et nad toetavad seda projekti, eriti Alexander Kukushkinile ja Alexei Kliukinile. Alexei Kliukin on üks kaasautor, kes ei tööta enam Zalando juures, kuid need on kaks inimest, kes alustasid selle tootega.
Ja ma arvan, et Patroni on tõeliselt äge tööriist. Olen rahul, et see olemas on, see on huvitav. Suur aitäh kõigile kaasautoritele, kes kirjutavad Patroni jaoks plaane. Loodan, et Patroni muutub vananedes üha küpsemaks, ägedamaks ja töökindlamaks. See on juba töökindel, kuid loodan, et see muutub veel paremaks. Niisiis, kui plaanite Patronit kasutada, siis ärge kartke. See on hea lahendus, mida saate rakendada ja kasutada.
Sellega on kõik. Kui teil on küsimusi, küsige.

Küsimused
Aitäh ettekande eest! Kui pärast failisüsteemi siiski on vaja väga hoolikalt vaatama minna, siis miks me vajame automaatset failisüsteemi?
Kuna see on uus asi. Me oleme sellega tegelenud vaid aasta. Parim on kindel olla. Soovime sisse minna ja vaadata, et kõik on tõepoolest õigesti toimunud. See on täiskasvanu taseme usaldamatuse tase – parem on üle kontrollida ja vaadata.
Näiteks, me käisime hommikul vaatamas, eks ole?
Ei hommikul, me tavaliselt saame automaatse failisüsteemi kohta teada peaaegu kohe. Me saame teateid, näeme, et automaatne failisüsteem on toimunud. Me läheme praktiliselt kohe sisse ja vaatame. Kuid kõik need kontrollid peaksid olema viidud jälgimise tasemele. Kui pöörduda Patroni poole REST API kaudu, on olemas ajalugu. Ajaloo põhjal saab vaadata ajamärke, millal failisüsteem toimus. Selle põhjal saab teha jälgimist. Saame vaadata ajalugu, kui palju seal sündmusi on olnud. Kui meie sündmuste arv on suurenenud, tähendab, et automaatne failisüsteem on toimunud. Saame minna ja vaadata. Või meie automatiseerimine jälgimisel kontrollis, et kõik meie koopiad on kohal, viivitust ei ole ja kõik on hästi.
Aitäh!
Suur tänu suurepärase jutu eest! Kui me viime DCS klastrit kaugele Postgres klastrist, kas siis tuleb ka seda klastrit perioodiliselt hooldada? Millised on parimad tavad selle osas, et osad DCS klastrist tuleb välja lülitada, midagi nendega teha jne? Kuidas kogu see konstruktsioon sel ajal töötab? Ja kuidas need asjad teostada?
Ühele ettevõttele tuli koostada probleemide matriits, et mõista, mis juhtub, kui üks või mitu komponenti ebaõnnestub. Selle matriitsi põhjal vaatame järjestikku läbi kõik komponendid ja koostame stsenaariume, mis juhtub nende komponentide rike korral. Vastavalt sellele on iga rikke stsenaariumi jaoks võimalik koostada taastamisplaan. DCS puhul on see osa standardsetest infrastruktuuridest. Administraator tegeleb selle haldamisega, ja me toetume juba halduritele, kes seda haldavad, ning nende võimele seda olukordades parandada. Kui DCS-d üldse ei ole, siis korraldame selle juurutamise meie, kuid ei jälgi selle eest väga hoolikalt, kuna me ei vasta infrastruktuuri eest, vaid anname soovitusi selle kohta, kuidas ja mida jälgida.
Nii et, kas ma sain õigesti aru, et tuleb välja lülitada Patroni, välja lülitada failivaatleja ja lõpetada kõik tegevused enne, kui teeme midagi hostidega?
See sõltub sellest, kui palju sõlmi on DCS-klusteris. Kui sõlmi on palju ja me katkestame vaid ühe sõlme (replika), siis kluster säilitab kvoorumi. Patroni jääb töövõimeliseks ja mitte midagi ei aktiveeru. Kui teeme keerulisi toiminguid, mis mõjutavad rohkem sõlmi ja mille puudumine võib kvoorumi rikkuda, siis – jah, võib-olla tasub Patroni pausile panna. Selleks on vastav käsk – patronictl pause, patronictl resume. Me lihtsalt paneme pausile ja autofailivaatleja ei aktiveeru sel ajal. Teeme DCS-klusteris hooldustöid, siis eemaldame pausi ja jätkame elu.
Aitäh palju!
Suur tänu ettekande eest! Kuidas toote meeskond suhtub andmete kaotsiminekusse?
Toote meeskond on ükskõikne, aga meeskonnajuhid on mures.
Millised garantiiid seal on?
Garantiide tagamine on väga keeruline. Aleksandr Kukushkinilt on olemas ettekande "Kuidas arvutada RPO ja RTO", st taastamisaeg ja kui palju andmeid võime kaotada. Ma arvan, et peaksime need slaidid leidma ja uurima. Mäletan, et seal on spetsiifilised sammud, kuidas neid asju arvutada. Kui palju tehinguid me võime kaotada, kui palju andmeid me võime kaotada. Ühe võimalusena saame kasutada sünkroonset replikatsiooni Patroni tasemel, kuid see on ka kahe teraga mõõk: kas meil on andmete usaldusväärsus või kaotame kiirusest. On olemas sünkroonne replikatsioon, kuid see ei taga ka 100% -list kaitset andmete kaotamise eest.
Aleksei, aitäh suurepärase ettekande eest! Kas teil on kogemusi Patroni kasutamisel nulltaseme kaitse jaoks? St koos sünkroonse standby-ga? See on esimene küsimus. Ja teine küsimus. Te olete kasutanud erinevaid lahendusi. Me kasutasime Repmgr, kuid ilma automaatfailoverita ja nüüd plaanime autot ühendamist failoveriga. Me kaalume Patronit kui alternatiivset lahendust. Mida te saate öelda Patroni plusside kohta võrreldes Repmgr-iga?
Esimene küsimus puudutas sünkroonilisi replikaate. Meil ei kasuta keegi sünkroonilist replikatsiooni, kuna see tekitab kõigis hirmu (Mõned kliendid juba kasutavad, ega ole saanud tootlikkuse osas mingeid probleeme - Ettekanne märkmed). Kuid oleme endale välja töötanud reegli, et sünkroonilise replikatsiooniga klastris peavad olema vähemalt kolm sõlme, sest kui meil on kaks sõlme ja kui peamine või replikatsioon murdub, siis Patroni viib selle sõlme Standalone-režiimi, et rakendus saaks edasi töötada. Sel juhul on andmete kadumise riskid.
Teise küsimuse osas oleme kasutanud Repmgr'i ja kasutame seda endiselt osades klientides ajaloolistel põhjustel. Mis on öelda? Patronis on automaatne failikuulamine olemas juba vaikimisi, Repmgris tuleb automaatne failikuulamine aga sisse lülitada eraldi funktsioonina. Peame käivitama Repmgr daemon'i igas sõlmes ja siis saame automaatse failikuulamise seadistada.
Repmgr kontrollib – kas Postgres sõlmed on elus. Repmgr protsessid kontrollivad teineteise olemasolu, mis ei ole väga efektiivne lähenemine, kuna võivad esineda keerulised olukorrad võrgu isolatsioonis, kus suur Repmgr klaster võib laguneda mitmeks väiksemaks ja jätkata toimimist. Olen ammu Repmgr'i jälginud, võib-olla on nad selle probleemi lahendanud... aga võib-olla ka mitte. Info edastamine kihi seisundist DCS-i, nagu teeb Stolon või Patroni, on kõige elujõulisem variant.
Aleksei, mul on küsimus, mis võibolla on algaja oma. Te tõite ühes esimeses DCS-i näites kohalikult masinalt kaugsõlme. Me mõistame, et võrk on asi, millel on oma eripärad, see eksisteerib iseseisvalt. Ja mis juhtub, kui mingil põhjusel DCS-klaster muutub kättesaamatuks? Põhjuseid ei hakka ma nimetama, neid võib olla palju: alates vigasest võrguhäälestusest kuni reaalse probleemini.
Ma ei launud seda valjult, kuid DCS-kloon peab olema ka talitlushäirete vastu vastupidav, st see peab koosnema paarist arvutist, et kvoorum saaks kokku tulla. Mis juhtub, kui DCS-kloon muutub kättesaamatuks või ei suuda kvoorumit kokku kutsuda, st mingisugune võrgu jagunemine või node'id ebaõnnestuvad? Sel juhul läheb Patroni klaster read only režiimi. Patroni klaster ei suuda määrata klastrite seisundit ega seda, mida teha. Ta ei suuda DCS-iga ühendust võtta ja salvestada klastris uut olekut, seetõttu läheb kogu klaster read only režiimi. Ta ootab kas operaatori käsitsi sekkumist või kuni DCS taastub.
Ükskõik kuidas öelda, DCS muutub meie jaoks teenuseks, mis on sama oluline kui ise andmebaas?
Jah, jah. Paljudes kaasaegsetes ettevõtetes on teenuste avastamine (Service Discovery) lahutamatu osa infrastruktuurist. See rakendatakse isegi enne, kui andmebaasid infrastruktuuris olemas on. Ütleme nii, et infrastruktuur käivitati, andmekeskuses oli kõik seadistatud, ja meil oli kohe teenuste avastamine. Kui see on Consul, siis saab selle pealt üles ehitada ka DNS. Kui see on Etcd, siis võib see olla osa Kubernetes'i klastrist, kus kõik muu juba seadistatakse. Minu arvates on teenuste avastamine juba lahutamatu osa kaasaegsetest infrastruktuuridest. Ja sellest mõeldakse palju varem, kui andmebaasidest.
Aitäh!
Allikas: habr.com
