

Kolm aastat tagasi rääkis Viktor Tarnavski ja Aleksei Milovidov Yandexist laval HighLoad++ , kui hea ClickHouse on ja kuidas see ei aeglusta. Samuti oli naaber laval Aleksandr Zaitsev koos rääkimas üleminekust ClickHouse teise analüütilise DBMS-i ja järeldusega, et ClickHouse, muidugi, hea, kuid mitte väga mugav. Kui 2016. aastal ettevõte LifeStreet, kus Aleksandr toona töötas, tõi mitme petabaiti analüütilise süsteemi üle ClickHouse, oli see põnev "kollaste telliste teed" täis tundmatuid ohtusid — ClickHouse toona meenutas miinivälja.
Kolm aastat hiljem ClickHouse on palju parem — selle aja jooksul asutas Aleksandr ettevõtte Altinity, mis mitte ainult ei aita üleminekuid ClickHouse kümnetele projektidele, vaid täiustavad ka toodet koos Yandexi kolleegidega. Praegu ClickHouse ei ole see enam muretu jalutuskäik, kuid see pole ka enam miiniväli.
Aleksandr tegeleb jaotatud süsteemidega alates 2003. aastast, on arendanud suuri projekte MySQL, Oracle ja Vertica. Tšihtud HighLoad++ 2019 rääkis Aleksandr, üks pioneeridest, kes kasutas ClickHouse, milline on nüüd see DBMS. Saame teada peamistest omadustest ClickHouse: milline ta süsteemidest erineb ja millistel juhtudel on selle kasutamine tõhusam. Vaadates näiteid, käsitleme värskeid ja katsetatud praktikaid süsteemide loomisel ClickHouse.

Tagasivaade: mis toimus 3 aastat tagasi
Kolm aastat tagasi tõlkisime ettevõtte LifeStreet järgnevaga ClickHouse teise analüüsibaasi, ja reklaamivõrgu analüüsi migratsioon nägi välja järgmiselt:
- Juuni 2016. Aastal OpenSource ilmus ClickHouse ja meie projekt käivitati;
- August. Proof Of Concept: suur reklaamivõrk, infrastruktuur ja 200–300 terabaiti andmeid;
- Oktoober. Esimesed tootmisandmed;
- Detsember. Täielik tootekoormus — 10–50 miljardit sündmust päevas.
- Juuni 2017. Edukas kasutajate üleviimine ClickHouse, 2,5 petabaiti andmeid 60 serverist koosnevas klastris.
Migratsiooni käigus kasvas arusaamine, et ClickHouse — see on hea süsteem, millega on mugav töötada, kuid see on Yandexi sisemine projekt. Seetõttu on teatud nüansid: Yandex hakkab esmalt tegelema oma siseste tellijatega ja alles hiljem — kogukonna ja väliste kasutajate vajadustega, ning tol ajal ei olnud ClickHouse paljuski ettevõtte tasemel. Seetõttu asutasime märtsis 2017 Altinity ettevõtte, et teha ClickHouse veel kiiremini ja mugavamalt mitte ainult Yandexile, vaid ka teistele kasutajatele. Ja nüüd me:
- Koolitame ja aitame lahendusi üles ehitada ClickHouse nii, et kliendid ei teeks vigu ja et lahendus töötab lõpuks hästi;
- Tagame 24/7 toe ClickHouse-paigaldustele;
- Arendame oma ökosüsteemi projekte;
- Aktiivselt panustame ise ClickHouse, vastates kasutajate soovidele, kes tahavad näha teatud funktsioone.
Ja muidugi aitame üleminekuga ClickHouse koos MySQL, Vertica, Oracle, Greenplum, Redshift ja teistesse süsteemidesse. Oleme osalenud erinevates üleminekutes, ja need on kõik olnud edukaid.
Miks üldse üleminekut teha ClickHouse
Ei seisak! See on peamine põhjus. ClickHouse — väga kiire andmebaas erinevate stsenaariumide jaoks:

Juhuslikud tsitaadid inimestelt, kes on pikka aega töötanud ClickHouse.
Skaalautuvus. Mõnes teises andmebaasis võib ühel masinal saavutada korralikku sooritust, kuid ClickHouse saa skaleerida mitte ainult vertikaalselt, vaid ka horisontaalselt, lihtsalt lisades servereid. Kõik ei tööta nii sujuvalt, kui sooviks, kuid toimib siiski. Süsteemi saab kasvatada koos äri kasvuga. Oluline on see, et me ei ole piiratud praeguse lahendusega ja arengu potentsiaal on alati olemas.
Portatiivsus. Pole üksnes millelegi kinni seotud. Näiteks, koos Amazon Redshift on raske kuhugi üle minna. Aga ClickHouse saab selle paigaldada oma sülearvutisse, serverisse, juurutada pilve, minna Kubernetes — infrastruktuuri kasutamise osas pole piiranguid. See on mugav kõigile ja on suur eelis, mis ei ole paljudel teistel sarnastel andmebaasidel.
Paindlikkus. ClickHouse ei piira end ühe asjaga, näiteks Yandex.Metrica, vaid areneb ja seda kasutatakse üha suuremas ja suuremas arvus erinevates projektides ja valdkondades. Seda saab laiendada, lisades uusi funktsioone uute probleemide lahendamiseks. Näiteks peetakse logide hoidmist andmebaasis arusaamatuks, seetõttu mõeldi välja Elasticsearch. Aga tänu paindlikkusele ClickHouse, selles saate samuti logisid hoida, tihti isegi paremini kui Elasticsearch — in ClickHouse see nõuab 10 korda vähem riistvara.
Tasuta Avatud lähtekood. Selle eest ei pea midagi maksma. Ei pea küsima luba, et installida süsteemi enda sülearvutisse või serverisse. Peidetud tasusid ei ole. Samuti ei saa ükski teine avatud lähtekoodiga andmebaasitehnoloogia kiiruselt konkureerida ClickHouse. MySQL, MariaDB, Greenplum — kõik nad on palju aeglasemad.
Kogukond, vaim ja lõbu.Siin on ClickHouse suurepärane kogukond: kohtumised, vestlusgrupid ja Aleksei Milovidov, kes laadib meid kõik oma energiaga ja optimistikusega.
Üleminek ClickHouse'ile
Üleminekuks ClickHouse millestki, on vaja vaid kolme asja:
- Mõista piiranguid ClickHouse ja milleks see ei sobi.
- Kasutada tehnoloogia eeliseid ja selle kõige tugevamaid külgi.
- Katsetada.Isegi mõistes, kuidas see töötab ClickHouse, ei ole alati võimalik ennustada, millal see on kiirem, millal aeglasem, millal parem ja millal halvem. Seetõttu proovige.
Ülemineku probleem
On ainult üks „aga”: kui üleminek toimub ClickHouse millegilt mujalt, siis tavaliselt läheb midagi valesti. Oleme harjunud teatud praktikate ja asjadega, mis toimivad meie lemmikandmebaasis. Näiteks iga inimene, kes on töötanud SQAndmebaaside puhul peetakse vajalikuks sellist funktsioonide kogumit:
- tehingud;
- piirangud;
- kooskõla;
- indeksid;
- UPDATE/DELETE;
- NULLid;
- millisekundid;
- automaatsete tüüpide konverteerimised;
- mitmikliitumised;
- meelevaldsed partitsioonid;
- klastrihalduse tööriistad.
Kogum on vajalik, aga kolm aastat tagasi ei olnud ühtegi neist funktsioonidest! ClickHouse Praegu on teostamata jäänud vähem kui pool: tehingud, piirangud, kooskõla, millisekundid ja tüüpide konverteerimised.
Ja mis kõige tähtsam — see, et ClickHouse mõned standardpraktikad ja lähenemisviisid ei tööta või ei toimi nii, nagu me harjunud oleme. Kõik, mis ilmub ClickHouse, vastab "ClickHouse'i viisile", st funktsioonid erinevad teistest andmebaasidest. Näiteks:
- Indekseid ei valita, vaid neid vahele jäetakse.
- UPDATE/DELETE need ei ole sünkroonsed, vaid asünkroonsed.
- Mitmikliitumised on olemas, kuid päringute planeerijat ei ole. Kuidas nad siis täidetakse, pole andmebaasi maailmast tulijatele üldse arusaadav.
ClickHouse'i stsenaariumid
1960. aastal kirjutas Ameerika matemaatik Ungari päritoluga Wigner E. P. artikli "Matemaatika ebaõiglane efektiivsus looduslikes teadustes» («Matemaatika hämmastav efektiivsus looduslikes teadustes») räägib sellest, et ümbritsev maailm kirjeldab kuidagi hästi matemaatilisi seadusi. Matemaatika on abstraktne teadus, kuid füüsikaseadused, mis on väljendatud matemaatilises vormis, ei ole triviaalset laadi, ja Wigner E. P. rõhutas, et see on väga kummaline.
Minu arvates, ClickHouse on see sama kummalisus. Ümber sõnastades Wignerit, võib öelda: hämmastav on matemaatika hämmastav efektiivsus ClickHouse nii erinevates analüütilistes rakendustes!
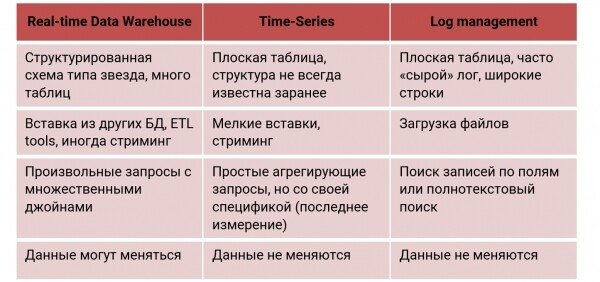
Näiteks, võtame Reaalajas Andmehoidla, kuhu andmeid laaditakse praktiliselt pidevalt. Soovime saada sellelt päringuid sekundilise viivitusega. Palun — kasutame ClickHouse, sest see ongi selle stsenaariumi jaoks välja töötatud. ClickHouse Nii kasutatakse seda mitte ainult veebis, vaid ka turunduse ja finantsanalüüsis, AdTech, samuti petuvastasestuge. Reaalajas Andmehoidlas kasutatakse keerulist struktureeritud skeemi tüüpi 'täht' või 'lumesahk', palju tabeleid используется сложная структурированная схема типа «звезда» или «снежинка», много таблиц с JOIN (mõnikord mitu), ja andmed on tavaliselt salvestatud ja muudetud mingites süsteemides.
Võtame teise stsenaariumi — Aja seeria: seadmete, võrkude jälgimine, kasutusstatistika, asjade internet. Siin kohtame ajaliselt järjestatud üsna lihtsaid sündmusi. ClickHouse selleks ei olnud algselt välja töötatud, kuid on end hästi tõestanud, seetõttu kasutavad suured ettevõtted ClickHouse monitooringu teabe ladustamiseks. Et uurida, kas see sobib ClickHouse ajaseeria jaoks, tegime meie lähenemise ja tulemuste põhjal benchmärgi InfluxDB ja TimescaleDB — spetsialiseeritud ajaseeria andmebaasid. , et ClickHouse, isegi ilma selliste ülesannete optimeerimiseta, võidab ja teistel väljakutel:
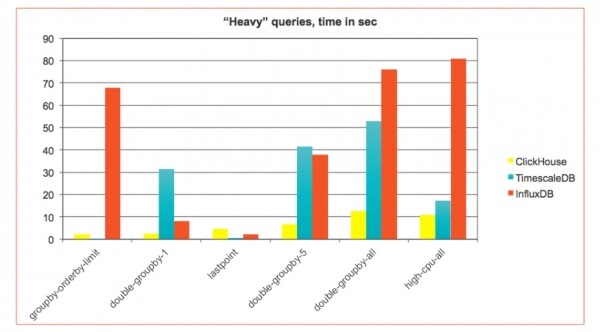
V ajaseeria kasutatakse tavaliselt kitsast tabelit — mitu väikest veergu. Monitooringu kaudu võib tulla väga palju andmeid — miljoneid kirjeid sekundis — ja tavaliselt saabuvad need väikeste lisandustega (reaalajas voogedastusega). Seetõttu on vajalik teine sisestusskenaar, samal ajal kui päringud on oma teatud spetsiifikaga.
Logihaldus. Logide kogumine andmebaasi — see on tavaliselt halb, kuid ClickHouse seda on võimalik teha teatud kommentaaridega, nagu eespool kirjeldatud. Paljud ettevõtted kasutavad ClickHouse täpselt selleks. Sellisel juhul kasutatakse tasast laia tabelit, kus hoiame logisid tervikuna (näiteks kujul JSON), või lõigatakse tükkideks. Andmed laaditakse tavaliselt suurte partiidena (failidena) ja otsitakse mingi välja järgi.
Iga nende funktsioonide jaoks kasutatakse tavaliselt spetsialiseeritud andmebaase. ClickHouse üks võib seda kõike teha nii hästi, et ületab neid võimekuses. Vaatame nüüd lähemalt ajaseeria stsenaariumi ja seda, kuidas õigesti "valmistada" ClickHouse seda stsenaariumi.
Aja-järgne
Praegu on see peamine stsenaarium, mille jaoks ClickHouse peetakse standardlahenduseks. Aja-järgne on ajas järjestatud sündmuste kogum, mis esindab mingi protsessi muutusi ajas. Näiteks see võib olla südame löögisagedus päeva jooksul või süsteemis toimuvate protsesside arv. Kõik, mis annab ajateike koos mõõtmistega – see on ajaseeria:

Seda tüüpi sündmusi tuleb kõige rohkem jälgimisest. See võib olla mitte ainult veebijälgimine, vaid ka reaalsete seadmete jälgimine: autod, tööstussüsteemid, IoT, tootmine või isesõitvad taksod, mille pagasiruumi Yandex juba praegu paneb ClickHouse-server.
Näiteks on ettevõtteid, mis koguvad andmeid laevadelt. Iga paari sekundi tagant saadavad konteineritelt sensorid sadu erinevaid mõõtmisi. Ingeniirid analüüsivad neid, loovad mudeleid ja püüavad mõista, kui efektiivselt laeva kasutatakse, kuna konteinerilaev ei tohi seista hetkekski. Iga seismine tähendab rahakaotust, seega on oluline prognoosida marsruuti nii, et peatused oleksid minimaalsed.
Praegu on tõusuteel spetsialiseeritud andmebaasid, mis mõõdavad ajaseeria. Veebisaidil DB-Engines kuidas erinevad andmebaasid kuidagi järjestatakse ning neid saab vaadata tüüpide järgi:
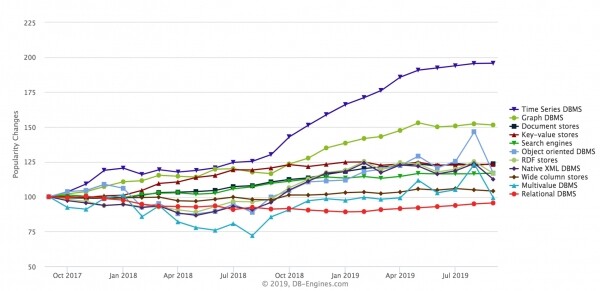
Kiireimalt kasvav tüüp on aja-seeriad. Samuti kasvavad graafiku andmebaasid, kuid aja-seeriad kasvavad kiiremini viimasel paaril aastal. Tüüpilised selle perekonna andmebaasid on InfluxDB, Prometheus, KDB, TimescaleDB (valmistatud PostgreSQL), lahendused Amazonilt. ClickHouse võib siin samuti olla kasutusel, ja see on kasutusel. Toon mõned avalikud näited.
Üks pioneere on ettevõte CloudFlare (CDN-teenusepakkuja). Nad jälgivad oma CDN kaudu ClickHouse (DNS-päringute, HTTP-päringud) tohutu koormusega — 6 miljonit sündmust sekundis. Kõik läheb läbi Kafka, saadetakse ClickHouse, mis võimaldab reaalajas jälgida süsteemi sündmuste armatuurlauas.
Comcast — üks juhtivaid telekommunikatsiooni ettevõtteid USA-s: internet, digitaaltelevisioon, telefoniteenus. Nad on loonud sarnase juhtimissüsteemi CDN raames Avatud lähtekood projekt Apache Traffic Control oma tohutute andmete haldamiseks. ClickHouse kasutatakse analüütika tagaküljena.
Percona sisemiselt integreeritud ClickHouse oma PMM, et hoida silm peal erinevatel MySQL.
Spetsiifilised nõuded
Aja-seeria andmebaasidel on omad spetsiifilised nõuded.
- Kiire sisestamine paljusid agente. Me peame väga kiiresti andmeid paljust voogudest sisestama. ClickHouse teeb seda hästi, kuna kõik sisestamised pole blokeerivad. Iga insert on uus fail kettal, ning väikseid sisestusi saab vahemällu salvestada erinevatel viisidel. ClickHouse On parem sisestada andmeid suurtes partiiades, mitte ühe rea haaval.
- Paindlik skeem. Dokumendihalduses ajaseeria me ei tea tavaliselt andmete struktuuri täielikult. Saame luua jälgimissüsteemi konkreetse rakenduse jaoks, kuid siis on seda teise rakenduse jaoks keeruline kasutada. Selleks on vajalik paindlikum skeem. ClickHouse, võimaldab seda teha, isegi kui tegemist on rangelt tüübitud andmebaasiga.
- Tõhus andmete säilitamine ja unustamine. Tavaliselt on tegemist ajaseeria hiiglaslike andmemägede, seetõttu tuleks need hoida võimalikult efektiivselt. Näiteks, InfluxDB hea kompressioon — see on selle peamine omadus. Kuid peale salvestamise tuleb osata ka vanu andmeid "unustada" ja teha mingit downsampling — automaatne kogumite arvutamine.
- Kiired taotlused kogutud andmetele. Mõnikord on huvitav vaadata viimaseid 5 minutit täpsusega millisekundite kaupa, kuid kuumõõdud andmete puhul ei pruugi minutine või sekundiline granulaarsus olla vajalik — piisab üldstatistikast. Taolise toe puudumine on vajalik, vastasel juhul võtab 3 kuu andmete päring aega liiga kaua, isegi ClickHouse.
- Päringud tüüpi "viimane punkt, seisuga». Need on tüüpilised ajaseeria päringud: vaatame viimast mõõtmist või süsteemi olekut antud ajahetkel t. Andmebaasides ei ole need päringud kuigi meeldivad, kuid ka neid tuleb osata teostada.
- "Aja järjendite" kokkuvõtmine. Aja-järgne — see on ajaseeria. Kui on kaks ajaseeriat, tuleb neid tihti ühendada ja korreleerida. Kõik andmebaasid ei võimalda seda mugavalt teha, eriti kui ajaseeriad ei ole ühtlustatud: siin on ühed ajakohased ja seal teised. Keskmised väärtused on võimalikud, kuid äkki jääb ikkagi auk, mistõttu jääb segaseks.
Vaatame, kuidas neid nõudeid täidetakse ClickHouse.
Skeem
V ClickHouse skeem ajaseeria võib teha mitmeti, sõltuvalt andmete regulaarsetest omadustest. Näiteks võib koostada süsteemi regulaarsete andmete põhjal, kui me teame kõiki metrikate eelnevalt. Nii on teinud CloudFlare monitooringuga CDN — see on hästi optimiseeritud süsteem. Võib luua üldisema süsteemi, mis jälgib kogu infrastruktuuri ja erinevaid teenuseid. Ebaühtlaste andmete korral ei tea me, mida jälgime — see on tõenäoliselt kõige üldisem juhtum.
Regulaarsed andmed. Veerud. Skeem on lihtne – veerud vajalike tüüpidega:
LOODA TABEL cpu (
created_date Kuupäev KOHUSTUSLIK tänasest,
created_at KuupäevaAeg KOHUSTUSLIK nüüd,
time String,
tags_id UInt32, /* liitmine dim_tagiga */
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) MOOTOR = MergeTree(created_date, (tags_id, created_at), 8192);See on tavaline tabel, mis jälgib mingit süsteemi koormuse tegevust (kasutaja, süsteem, idle, nice). Lihtne ja mugav, kuid mitte paindlik. Kui soovime paindlikumat skeemi, võime kasutada massiive.
Ebaühtlased andmed. Massiivid:
LOODA TABEL cpu_alc (
created_date Kuupäev,
created_at KuupäevaAeg,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
)
) MOOTOR = MergeTree(created_date, (tags_id, created_at), 8192);
VALI max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
Struktuur Sissetoomine — need on kaks massiivi: metrics.name ja metrics.value. Siin saab salvestada selliseid juhuslikke jälgimisandmeid nagu nimede massiiv ja mõõtmete massiiv iga sündmuse juures. Edasiarendamiseks, efektiivsuse hoidmiseks, võib selle struktuuri asemel luua mitu. Näiteks ühe — float-väärtuse, teise — int-väärtuse, sest int soovime säilitada tõhusamalt.
Aga sellise struktuuri kasutamine on keerulisem. Peate kasutama spetsiaalset konstruktsiooni, et esmalt indeksi väärtused ja seejärel massiivi väärtused välja tuua:
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...Kuid see töötab siiski piisavalt kiiresti. Teine viis ebaühtlaste andmete hoidmiseks on ridades.
Ebaühtlased andmed. Read. Selles traditsioonilises meetodis hoitakse kohe nii nimesid kui ka väärtusi ilma massiivideta. Kui ühest seadmest tuleb korraga 5 000 mõõtmist — genereeritakse andmebaasis 5 000 rida:
CREATE TABLE cpu_rlc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metric_name LowCardinality(String),
metric_value Float64
) ENGINE = MergeTree(created_date, (metric_name, tags_id, created_at), 8192);
SELECT
maxIf(metric_value, metric_name = 'usage_user'),
...
FROM cpu_r
WHERE metric_name IN ('usage_user', ...)
ClickHouse sellega toimib — sellel on erilised laiendid ClickHouse SQL. Näiteks, maxIf — spetsiaalne funktsioon, mis arvutab maksimumi metrika põhjal teatud tingimuste täitmisel. Ühes päringus saab kirjutada mitu sellist väljendit ja kohe arvutada väärtuse mitme metrika jaoks.
Võtame kolm lähenemist:
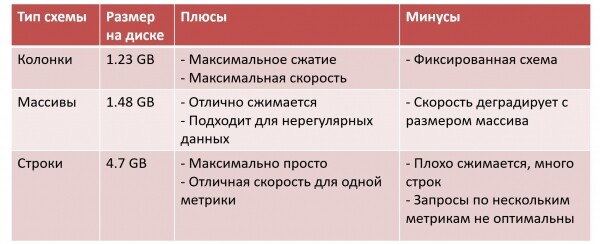
Siin olen lisanud „Andmete suurus kettal“ mõne testandmekogumi jaoks. Veergude puhul on meil kõige väiksem andmete suurus: maksimaalne tihendamine, maksimaalne päringute kiirus, kuid me maksame selle eest, et peame kõik koheselt fikseerima.
Massiivide puhul on kõik veidi halvem. Andmed siiski tihenduvad hästi ja ebaühtlast skeemi on võimalik hoida. Aga ClickHouse — veergude andmebaas, ja kui hakkame kõike massiivis hoidma, siis see muutub reavahetuseks ning me maksame paindlikkuse eest tõhususe arvelt. Iga operatsiooni jaoks tuleb kogu massiiv mällu lugeda, seejärel leida seest vajalik element — ja kui massiiv suureneb, siis kiirus halveneb.
Ühes ettevõttes, mis kasutab sellist lähenemist (näiteks, massive kas või 128 elemendist. Mitme tuhande mõõtme andmed koguses 200 TB andmeid/päevas ei hoita mitte ühes massiivis, vaid 10 või 30 massiivis koos spetsiaalse loogikaga salvestamiseks.
Maksimaalselt lihtne lähenemine — stringidega. Kuid andmed tihenduvad halvasti, tabeli suurus on suur, ja kui päringud käivad läbi mitme mõõtme, siis ClickHouse ei tööta optimaalselt.
Hübriidskeem
Oletame, et oleme valinud skeemi massiiviga. Kui meil on teadlikkus, et enamus meie juhtpaneelidest näitab ainult user ja system mõõdikuid, saame täiendavalt massiivist tabeli tasandil need mõõdikud veergudesse materialiseerida järgmiselt:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
),
usage_user Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_user')],
usage_system Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_system')]
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
Sisestamisel ClickHouse loendab need automaatselt. Nii saab meeldivad ja kasulikud ühendatud: skeem on paindlik ja üldine, kuid kõige sagedamini kasutatavad veerud on ära tõstetud. Tõden, et see ei nõudnud muudatusi sisestamisel ja ETL, mis jätkab massiivide sisestamist tabelisse. Me lihtsalt tegime ALTER TABLE, lisasime mõned veerud ja saime hübriidse ning kiiremast skeemi, millega saab kohe alustada.
Koodekid ja kokkusurumine
Kuna ajaseeria on oluline, kui hästi te andmeid pakite, sest teave võib olla väga suur. ClickHouse on kompressioonivahendeid, mis saavutavad efekti 1:10, 1:20 ja mõnikord isegi rohkem. See tähendab, et 1 TB kompressimata andmed kettal võtavad 50-100 GB. Väiksem suurus on hea, andmete lugemine ja töötlemine on kiirem.
Korke kompressioonitaseme saavutamiseks, ClickHouse tugi järgmisi koodekeid:
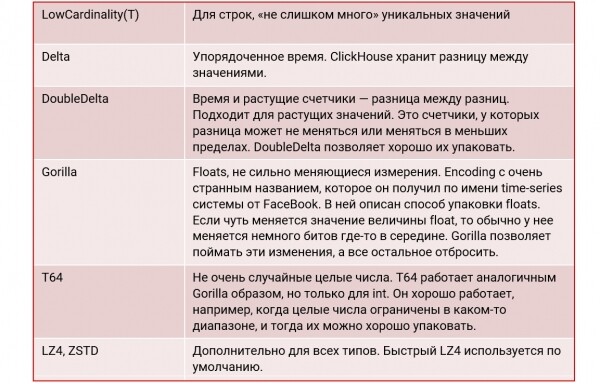
Näidis tabel:
CREATE TABLE benchmark.cpu_codecs_lz4 (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now() Codec(DoubleDelta, LZ4),
tags_id UInt32,
usage_user Float64 Codec(Gorilla, LZ4),
usage_system Float64 Codec(Gorilla, LZ4),
usage_idle Float64 Codec(Gorilla, LZ4),
usage_nice Float64 Codec(Gorilla, LZ4),
usage_iowait Float64 Codec(Gorilla, LZ4),
usage_irq Float64 Codec(Gorilla, LZ4),
usage_softirq Float64 Codec(Gorilla, LZ4),
usage_steal Float64 Codec(Gorilla, LZ4),
usage_guest Float64 Codec(Gorilla, LZ4),
usage_guest_nice Float64 Codec(Gorilla, LZ4),
additional_tags String DEFAULT ''
)
ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Siin määratleme koodeki DoubleDelta ühes juhus, teises — Gorilla, ja kindlasti lisame veel LZ4 kompressiooni. Tulemuseks on andmete suuruse märkimisväärne vähenemine kettal:
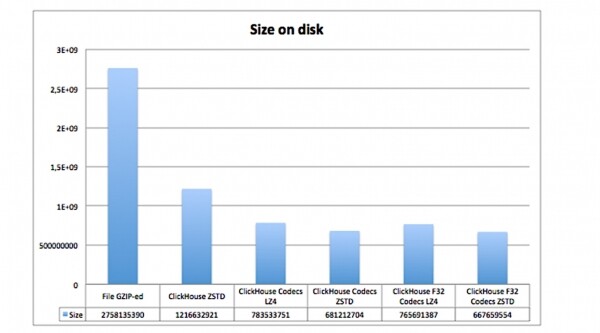
Siin on näidatud, kui palju ruumi võtavad samad andmed, kuid erinevate koodekite ja kompressioonide kasutamisel:
- GZIP-itud fail kettal;
- ClickHouse'is ilma koodekideta, aga ZSTD-kompressiooniga;
- ClickHouse'is koode ja LZ4 ning ZSTD kokkusurutud.
On selge, et koode sisaldavad tabelid võtavad palju vähem ruumi.
Suurus on oluline
Samuti on oluline õige andmetüüp:
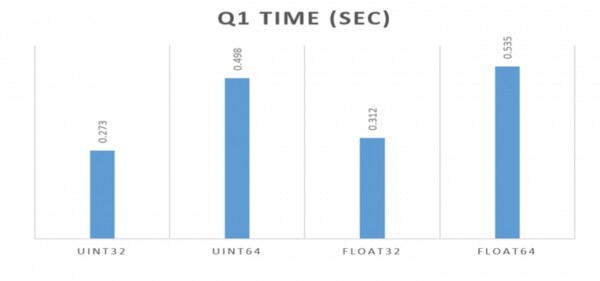
Käitusin kõigis ülaltoodud näidetes Float64. Aga kui me oleksime valinud Float32, siis oleks see isegi parem olnud. Seda on hästi demonstreeritud Percona meeskonna poolt ülaltoodud lingil. Oluline on kasutada võimalikult kompaktselt sobivat tüüpi: isegi vähem olulisel määral kettaruumi jaoks kui päringute kiirus. ClickHouse on sellele väga tundlik.
Kui saate kasutada int32 asetatakse int64, oodake peaaegu kahekordset jõudluse suurenemist. Andmed võtavad vähem mälu ja kogu "aritmeetika" töötab palju kiiremini. ClickHouse ise — väga rangelt tüübitud süsteem, mis kasutab maksimaalselt ära kõiki võimalusi, mida pakuvad kaasaegsed süsteemid.
Agregatsioon ja Materialized Views
Agregatsioon ja materialiseeritud vaated võimaldavad luua agregaatide erinevate olukordade jaoks:
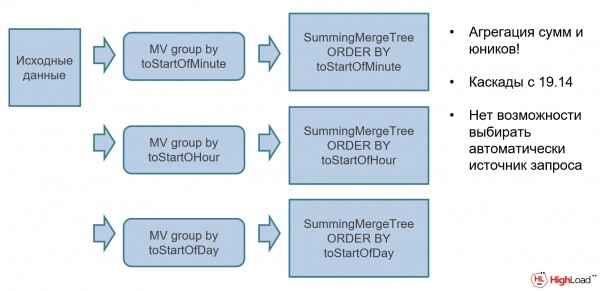
Näiteks võivad teil olla mitteaggregeeritud allikandmed, millele saab rakendada erinevaid materialiseeritud vaateid automaatse kogumisega spetsiaalse mootori kaudu. SummingMergeTree (SMT). SMT on spetsiaalne aggregeeriv andmestruktuur, mis arvutab automaatset kogumist. Andmebaasi sisestatakse toored andmed, need aggregeeritakse automaatselt ja neid saab kohe kasutada juhtpaneelidel.
TTL unustame vanad andmed
Kuidas unustada andmeid, mis enam ei ole vajalikud? ClickHouse seda oskab teha. Tabeleid luues saab määrata TTL avaldisi: näiteks, et minutilised andmed hoiame ühe päeva, päevased — 30 päeva ja nädalased või kuu andmeid ei puuduta kunagi:
CREATE TABLE aggr_by_minute
…
TTL time + interval 1 day
CREATE TABLE aggr_by_day
…
TTL time + interval 30 day
CREATE TABLE aggr_by_week
…
/* no TTL */
Multi-tier jagame andmed kettale
Arendades edasi seda ideed, saab andmeid hoida ClickHouse erinevates kohtades. Oletame, et tahame hoida kuumaid andmeid viimase nädala kohta väga kiirel kohalikke SSD, samas kui ajaloolised andmed paigutame mujale. Täna on see võimalik: ClickHouse Saame konfigureerida säilitamise poliitikat (

storage policy) nii, et) так, что ClickHouse andmed suunatakse automaatselt teise salvestusse pärast teatud tingimuste täitmist.
Kuid see ei ole veel kõik. Konkreetses tabelis saab määrata reeglid, millal andmed aja jooksul külmale salvestusele ülevi kasutatakse. Näiteks 7 päeva jooksul on andmed väga kiirel kettal, ja kõik üle selle perioodi kantakse aeglasele kettale. See on hea, kuna see võimaldab süsteemil hoida maksimaalset jõudlust, samal ajal jälgides kulutusi ja mitte raisates vahendeid külmadele andmetele:
CREATE TABLE
...
TTL date + INTERVAL 7 DAY TO VOLUME 'cold_volume',
date + INTERVAL 180 DAY DELETE
Ainulaadsed võimalused ClickHouse
Peaaegu kõiges on ClickHouse need 'šedörid', kuid need kaovad eksklusiivsuse tõttu — asjad, mida teistes andmebaasides ei ole. Näiteks mõned ainulaadsed funktsioonid ClickHouse:
- Massiivid. Dokumendihalduses ClickHouse väga hea tugi massiividele, samuti võimalus neil keerulisi arvutusi teostada.
- Agrrgateeritud andmestruktuurid. See on üks 'tapja omadustest' ClickHouse. Kuigi Yandexi mehed väidavad, et me ei soovi andmeid agregreerida, teeb seda kõik ClickHouse, sest see on kiire ja mugav.
- Materjaliseeritud vaated. Koos koos andmete kogumise struktuuridega võimaldavad materialiseeritud vaated mugavat reaalajas kogumist.
- ClickHouse SQL. See on keele laiendus SQL mõningate lisafunktsioonidega, mis on saadaval ainult ClickHouse. Varem oli see ühtpidi laiendus ja teistpidi puudus. Nüüd oleme peaaegu kõik puudused võrreldes SQL 92 ära kaotanud, nüüd on see vaid laiendus.
- Lambdaavaldised. Kas need on olemas ka teistes andmebaasides?
- ML-tugi. See on erinevates andmebaasides, mõnes paremini, mõnes halvemini.
- Avaallikakood. Me võime koos laiendada ClickHouse praegu on ClickHouse umbes 500 kaastöötajat ja see arv kasvab pidevalt.
Ning küsimustes
V ClickHouse on palju erinevaid viise sama asja tegemiseks. Näiteks saab viimast väärtust tabelist kolme erineva meetodiga tagastada CPU (on olemas ka neljas, kuid see on veel eksootilisem).
Esimene näitab, kui mugav on teha ClickHouse päringud, kui soovite kontrollida, et tuple on alampäringis. Just seda ma isiklikult teistes andmebaasides väga tundsin. Kui ma tahan midagi alampäringuga võrrelda, siis teistes andmebaasides saab seda võrrelda ainult skalaari, ja mitme veeru jaoks peab kirjutama JOIN. Dokumendihalduses ClickHouse saab kasutada tupleid:
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)Teine meetod teeb sama, kuid kasutab agregaatfunktsiooni argMax:
SELECT
argMax(usage_user, created_at),
argMax(usage_system, created_at),
...
FROM cpu V ClickHouse on mitukümmend agregaatfunktsiooni, ja kui kasutada kombinatoore, siis kommutatsiooni seaduste järgi tuleb neid umbes tuhat. ArgMax — üks funktsioone, mis arvutab maksimaalse väärtuse: päring tagastab väärtuse usage_user, millel saavutatakse maksimaalne väärtus created_at:
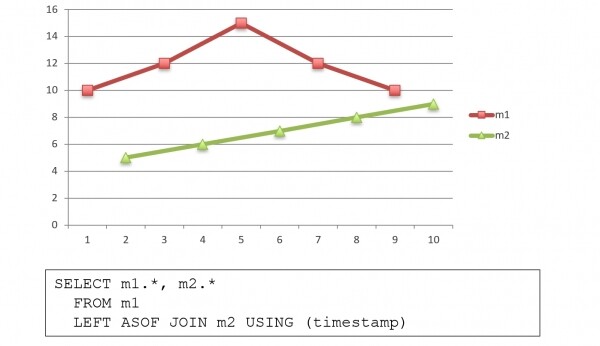
SELECT now() as created_at,
cpu.*
FROM (SELECT DISTINCT tags_id from cpu) base
ASOF LEFT JOIN cpu USING (tags_id, created_at)
ASOF JOIN — „ridade” „liimimine” erineva ajaga. See on ainulaadne funktsioon andmebaasides, mis on ainult kdb+. Kui on kaks ajasarja erineva ajaga, ASOF JOIN võimaldab neid ühe päringuga nihutada ja kokku liita. Iga väärtuse jaoks ühes ajareas on lähim väärtus teises, ja need tagastatakse ühel real:
Analüütilised funktsioonid
Standardi järgi SQL-2003 võib kirjutada nii:
SELECT origin,
timestamp,
timestamp -LAG(timestamp, 1) OVER (PARTITION BY origin ORDER BY timestamp) AS duration,
timestamp -MIN(timestamp) OVER (PARTITION BY origin ORDER BY timestamp) AS startseq_duration,
ROW_NUMBER() OVER (PARTITION BY origin ORDER BY timestamp) AS sequence,
COUNT() OVER (PARTITION BY origin ORDER BY timestamp) AS nb
FROM mytable
ORDER BY origin, timestamp;
V ClickHouse niimoodi ei saa — see ei toeta standardit SQL-2003 ja tõenäoliselt ei hakka kunagi seda tegema. Selle asemel on ClickHouse tavaline kirjutada nii:

Lubasin lambdasid – siin nad on!
See on analoog analüütilisest päringust, mis on standardis SQL-2003: see arvutab kahe vahelise erinevuse timestamp, duration, järjestusnumber — kõik, mida me tavaliselt loeme analüütilisteks funktsioonideks. Me ClickHouse loeme neid massiivide kaudu: esmalt kokku surume andmed massiiviks, seejärel teeme massiivil kõik, mida soovime, ja seejärel avame tagasi. See ei ole väga mugav, nõuab armastust funktsionaalse programmeerimise vastu, vähemalt, kuid see on väga paindlik.
Eri funktsioonid
Lisaks sellele on ClickHouse palju spetsialiseeritud funktsioone. Näiteks, kuidas määrata, kui palju sessioone toimub korraga? Tüüpiline jälgimise ülesanne on määrata maksimaalne koormus ühe päringu kaudu. Selleks ClickHouse on spetsiaalne funktsioon:

Üldiselt on ClickHouse'is palju spetsiaalseid funktsioone erinevate eesmärkide jaoks:
- runningDifference, runningAccumulate, neighbor;
- sumMap(key, value);
- timeSeriesGroupSum(uid, timestamp, value);
- timeSeriesGroupRateSum(uid, timestamp, value);
- skewPop, skewSamp, kurtPop, kurtSamp;
- WITH FILL / WITH TIES;
- simpleLinearRegression, stochasticLinearRegression.
See ei ole täielik funktsioonide nimekiri, neid on kokku umbes 500-600. Näpunäide: kõik funktsioonid ClickHouse leidub süsteemitabelis (kõiki funktsioone ei ole dokumenteeritud, kuid kõik on huvitavad):
select * from system.functions order by nameClickHouse hoiab endas palju teavet enda kohta, sealhulgas log tabelid, query_log, jälgimislogi, blokkmooduli operatsioonide logi (part_log), mõõdikute logi ja süsteemilog, mida ta tavaliselt kirjutab kettale. Mõõdikute logi on ajaseeria ühes ClickHouse üldiselt ClickHouse: andmebaas ise võib mängida ajaseeria andmebaase, „imedes“ seega iseennast.

See on samuti ainulaadne asi – kuna me teeme head tööd ajaseeria, miks mitte hoida endas kõike, mida vajame? Me ei vaja Prometheus, me hoiame kogu oma teabe endas. Me oleme ühendatud Grafana ja jälgime iseennast. Siiski, kui ClickHouse kui see kukub, siis me ei näe, — miks, — seega tavaliselt nii ei tehta.
Suur klaster või palju väikeseid ClickHouse
Mis on parem — üks suur klaster või palju väikeseid ClickHouse? Traditsiooniline lähenemine DWH — see on suur klaster, kus iga rakenduse jaoks määratakse skeem. Me läksime andmebaasi administraatori juurde — andke meile skeem, ja me saime selle:
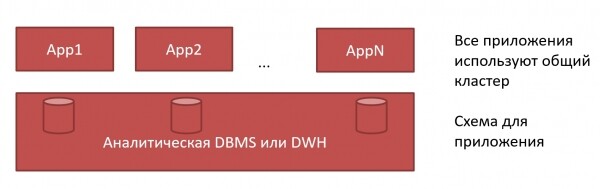
V ClickHouse seda saab teha teisiti. Igal rakendusel võib olla oma ClickHouse:
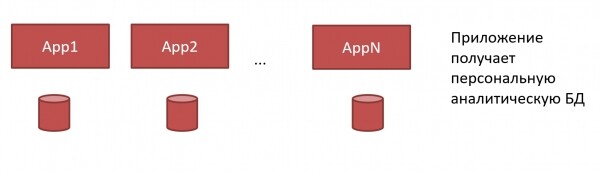
Me ei vaja enam suurt monstrosust DWH ja kangekaelseid administraatoreid. Igal rakendusel võib olla oma ClickHouse, ja arendaja võib seda ise teha, kuna ClickHouse see paigaldub väga lihtsalt ja ei nõua keerulist haldamist:
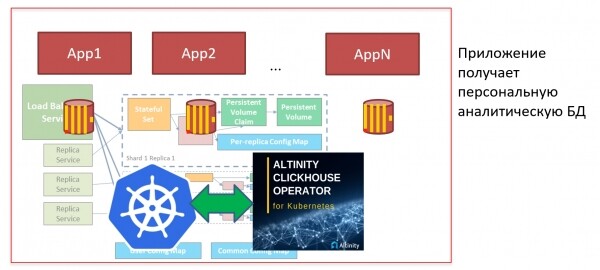
Aga kui meil on palju ClickHouse, ja seda tuleb tihti paigaldada, siis tahaks selle protsessi automatiseerida. Selleks saab näiteks kasutada Kubernetes ja clickhouse-operaatorit. Kuberneteses ClickHouse saab paigaldada «ühe klikiga»: ma võin vajutada nuppu, käivitada manifeste ja baasi ongi valmis. Saame kohe luua skeemi, alustada seal andmete laadimist, ja viie minutiga on mul juba valmid dashboard . Nii lihtne see on! Grafana. Настолько все просто!
Mis on lõpptulemus?
Nii et, ClickHouse — see on:
- Kiire. See on kõigile teada.
- Lihtne. Veidi vaieldav, aga ma arvan, et rasked õpingud toovad kerguse lahingus. Kui saada aru, kuidas ClickHouse see töötab, siis edasi on kõik väga lihtne.
- Universaalne. See sobib erinevate stsenaariumite jaoks: DWH, Aja seeria, Logi salvestus. Kuid see ei ole OLTP andmebaas, seega ärge proovige seal lühikesi sisendeid ja lugemisi teha.
- Huvitav. Ilmselt on see, kes töötab ClickHouse, veetnud palju huvitavaid hetki nii heas kui halvas mõttes. Näiteks, kui ilmus uus versioon, kõik lakkas töötamast. Või kui te töötasite ülesande kallal kaks päeva, kuid pärast küsimust Telegrami grupis lahendati see kahe minutiga. Või kuidas konverentsil Aleksei Milovidovi ettekandes purunes ClickHouse ülekanne HighLoad++. Taolised asjad juhtuvad pidevalt ning muudavad meie elu ClickHouse värvikaks ja huvitavaks!
Esitluse saab vaadata .

Oodatud kohtumine kõrge koormusega süsteemide arendajatega toimub 9. ja 10. novembril Skolkovo's. Lõfinally toimub see offline-konverents (kuigi kõik ettevaatusabinõud on olemas), kuna HighLoad++ energiat ei saa veebis pakendada.
Konverentsil leiame ja näitame teile juhtumeid tehnoloogiate maksimaalsetest võimalustest: HighLoad++ on olnud, on ja jääb ainukeseks kohaks, kus kahe päeva jooksul teada saada, kuidas toimivad Facebook, Yandex, VKontakte, Google ja Amazon.
Pidades meie kohtumisi katkematult alates 2007. aastast, kohtume sel aastal 14. korda. Selle aja jooksul on konverents kasvanud 10 korda, eelmisel aastal tõi valdkonna oluline sündmus kokku 3339 osalejat, 165 esinejat ettekannete ja kohtumiste jaoks ning samal ajal toimus 16 rada.
Eelmisel aastal oli teie jaoks 20 bussi, 5280 liitrit teed ja kohvi, 1650 liitrit mahla ning 10200 pudelit vett. Samuti 2640 kilogrammi toitu, 16000 taldrikut ja 25000 klaasi. Muuseas, müüdud ümbertöödeldud paberi raha eest istutasime 100 tamme seemikut 🙂Piletid on ostmiseks saadaval , et saada uudiseid konverentsi kohta — , ja vestelda — kõigis sotsiaalmeedias: , , ja .
Allikas: habr.com
