

Selles artiklis räägin sellest, kuidas projekt, mille kallal töötan, muutus suurest monoliidist mikroteenuste komplektiks.
Projekt sai oma ajalugu alguse üsna kaua aega tagasi, 2000. aasta alguses. Esimesed versioonid kirjutati Visual Basic 6-s. Aja jooksul sai selgeks, et selle keele arendust on tulevikus raske toetada, kuna IDE ja keel ise on halvasti arenenud. 2000. aastate lõpus otsustati üle minna paljulubavamale C#-le. Uus versioon kirjutati paralleelselt vana versiooniga, järk-järgult kirjutati aina rohkem koodi .NET-is. C# taustaprogramm keskendus algselt teenusearhitektuurile, kuid arenduse käigus kasutati tavalisi loogikaga teeke ja teenused käivitati ühe protsessina. Tulemuseks oli rakendus, mida nimetasime teenuse monoliidiks.
Selle kombinatsiooni üks väheseid eeliseid oli teenuste võimalus üksteisele välise API kaudu helistada. Korrektsemale teenusele ja tulevikus mikroteenuse arhitektuurile üleminekuks olid selged eeldused.
Alustasime lagunemisega tööd 2015. aasta paiku. Ideaalsesse seisu me veel jõudnud ei ole – suurest projektist on veel osi, mida vaevalt monoliitideks nimetada saab, aga needki ei näe välja nagu mikroteenused. Sellegipoolest on edasiminek märkimisväärne.
Ma räägin sellest artiklis.
Sisu
Olemasoleva lahenduse arhitektuur ja probleemid
Algselt nägi arhitektuur välja selline: kasutajaliides on eraldi rakendus, monoliitne osa on kirjutatud Visual Basic 6-s, .NET-rakendus on seotud teenuste komplekt, mis töötab üsna suure andmebaasiga.
Eelmise lahenduse miinused
Üks ebaõnnestumise punkt
Meil oli üksainus tõrkepunkt: .NET-i rakendus töötas ühes protsessis. Kui mõni moodul ebaõnnestus, ebaõnnestus kogu rakendus ja see tuli taaskäivitada. Kuna automatiseerime suure hulga erinevate kasutajate protsesse, ei saanud ühes neist ühe rikke tõttu kõik mõnda aega töötada. Ja tarkvara vea korral ei aidanud isegi varundamine.
Paranduste järjekord
See puudus on pigem korralduslik. Meie rakendusel on palju kliente ja nad kõik soovivad seda võimalikult kiiresti täiustada. Varem ei saanud seda paralleelselt teha ja kõik kliendid seisid järjekorras. See protsess oli ettevõtete jaoks negatiivne, sest nad pidid tõestama, et nende ülesanne on väärtuslik. Ja arendusmeeskond kulutas aega selle järjekorra korraldamiseks. See võttis palju aega ja vaeva ning lõppkokkuvõttes ei saanud toode nii kiiresti muutuda, kui nad oleks soovinud.
Mitteoptimaalne ressursside kasutamine
Teenuste ühe protsessi käigus hostimisel kopeerisime konfiguratsiooni alati täielikult serverist serverisse. Tahtsime paigutada kõige rohkem koormatud teenused eraldi, et mitte raisata ressursse ja saavutada paindlikum kontroll oma juurutusskeemi üle.
Kaasaegseid tehnoloogiaid on keeruline rakendada
Kõigile arendajatele tuttav probleem: projekti tahetakse juurutada kaasaegseid tehnoloogiaid, aga võimalust pole. Suure monoliitse lahenduse korral muutub iga praeguse raamatukogu uuendamine, rääkimata üleminekust uuele, üsna mittetriviaalseks ülesandeks. Läheb kaua aega, enne kui meeskonnajuhile tõestada, et see toob rohkem boonuseid kui raisatud närve.
Raskused muudatuste väljastamisel
See oli kõige tõsisem probleem – me andsime välja iga kahe kuu tagant.
Vaatamata arendajate testimisele ja pingutustele muutus iga väljalase panga jaoks tõeliseks katastroofiks. Ettevõte sai aru, et nädala alguses ei tööta mõni selle funktsionaalsus. Ja arendajad mõistsid, et neid ootab nädal tõsiseid vahejuhtumeid.
Kõigil oli soov olukorda muuta.
Ootused mikroteenustele
Komponentide probleem, kui see on valmis. Komponentide tarnimine valmisolekul lahuse lagundamise ja erinevate protsesside eraldamise teel.
Väikesed tootemeeskonnad. See on oluline, sest vana monoliidi kallal töötavat suurt meeskonda oli raske hallata. Selline meeskond oli sunnitud töötama range protsessi järgi, kuid sooviti rohkem loovust ja iseseisvust. Seda said endale lubada vaid väikesed meeskonnad.
Teenuste eraldamine eraldi protsessides. Ideaalis tahaksin selle konteineritesse isoleerida, aga suur hulk .NET Frameworkis kirjutatud teenuseid töötab ainult all Windows.NET Core'il põhinevad teenused ilmuvad nüüd, kuid neid on veel vähe.
Paindlikkus juurutamisel. Tahaksime teenuseid kombineerida nii, nagu me seda vajame, mitte nii, nagu kood seda sunnib.
Uute tehnoloogiate kasutamine. See on huvitav igale programmeerijale.
Üleminekuprobleemid
Muidugi, kui monoliiti oleks lihtne mikroteenusteks lõhkuda, poleks vaja sellest konverentsidel rääkida ja artikleid kirjutada. Selles protsessis on palju lõkse, ma kirjeldan peamisi, mis meid takistasid.
Esimene probleem tüüpiline enamikule monoliitidele: äriloogika sidusus. Kui kirjutame monoliiti, tahame oma klasse uuesti kasutada, et mitte kirjutada tarbetut koodi. Ja mikroteenustele üleminekul muutub see probleemiks: kogu kood on üsna tihedalt seotud ja teenuseid on keeruline eraldada.
Tööde alustamise ajal oli hoidlas üle 500 projekti ja üle 700 tuhande koodirea. See on üsna suur otsus ja teine probleem. Ei olnud võimalik seda lihtsalt võtta ja mikroteenusteks jagada.
Kolmas probleem — vajaliku infrastruktuuri puudumine. Tegelikult kopeerisime lähtekoodi serveritesse käsitsi.
Kuidas liikuda monoliidilt mikroteenustele
Mikroteenuste pakkumine
Esiteks tegime enda jaoks kohe kindlaks, et mikroteenuste eraldamine on iteratiivne protsess. Meilt nõuti alati paralleelselt äriprobleemide arendamist. See, kuidas me seda tehniliselt rakendame, on juba meie probleem. Seetõttu valmistusime korduvaks protsessiks. See ei tööta muul viisil, kui teil on suur rakendus ja see pole esialgu valmis ümberkirjutamiseks.
Milliseid meetodeid kasutame mikroteenuste isoleerimiseks?
Esimene tee — teisaldada olemasolevad moodulid teenustena. Sellega seoses meil vedas: juba oli registreeritud teenuseid, mis töötasid WCF-protokolli kasutades. Need jagati eraldi sõlmedeks. Portisime need eraldi, lisades igale konstruktsioonile väikese käivitusprogrammi. See on kirjutatud imelise Topshelfi teegi abil, mis võimaldab rakendust käivitada nii teenusena kui ka konsoolina. See on silumiseks mugav, kuna lahenduses pole vaja täiendavaid projekte.
Teenused ühendati vastavalt äriloogikale, kuna nad kasutasid ühiseid kooste ja töötasid ühise andmebaasiga. Vaevalt saaks neid puhtal kujul mikroteenusteks nimetada. Küll aga saaksime neid teenuseid osutada eraldi, erinevates protsessides. Ainuüksi see võimaldas vähendada nende mõju üksteisele, vähendades probleemi paralleelse arengu ja ühe tõrkepunktiga.
Hostiga kokkupanek on programmiklassis vaid üks koodirida. Varjasime Topshelfiga tööd abiklassis.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner<Accounts>.Run("RBA.Services.Accounts.Host");
}
}
}
Teine viis mikroteenuste eraldamiseks on: luua neid uute probleemide lahendamiseks. Kui monoliit samal ajal ei kasva, on see juba suurepärane, mis tähendab, et liigume õiges suunas. Uute probleemide lahendamiseks püüdsime luua eraldi teenuseid. Kui selline võimalus oli, siis lõime rohkem “kanoonilisi” teenuseid, mis haldavad täielikult oma andmemudelit, eraldi andmebaasi.
Meie, nagu paljud, alustasime autentimis- ja autoriseerimisteenustega. Nad sobivad selleks suurepäraselt. Need on sõltumatud, reeglina on neil eraldi andmemudel. Nad ise ei suhtle monoliidiga, vaid see pöördub mõne probleemi lahendamiseks nende poole. Neid teenuseid kasutades saate alustada üleminekut uuele arhitektuurile, siluda nende infrastruktuuri, proovida mõnda võrguteekidega seotud lähenemisviisi jne. Meie organisatsioonis ei ole ühtegi meeskonda, kes ei saaks autentimisteenust luua.
Kolmas viis mikroteenuste eraldamiseksSee, mida me kasutame, on meile pisut spetsiifiline. See on äriloogika eemaldamine kasutajaliidese kihist. Meie peamine kasutajaliidese rakendus on töölaud; see, nagu ka taustaprogramm, on kirjutatud C# keeles. Arendajad tegid aeg-ajalt vigu ja kandsid kasutajaliidesesse üle loogika osad, mis oleksid pidanud taustaprogrammis olemas olema ja mida oleks pidanud uuesti kasutama.
Kui vaatate kasutajaliidese osa koodist reaalset näidet, näete, et suurem osa sellest lahendusest sisaldab reaalset äriloogikat, mis on kasulik ka muudes protsessides, mitte ainult kasutajaliidese vormi koostamisel.
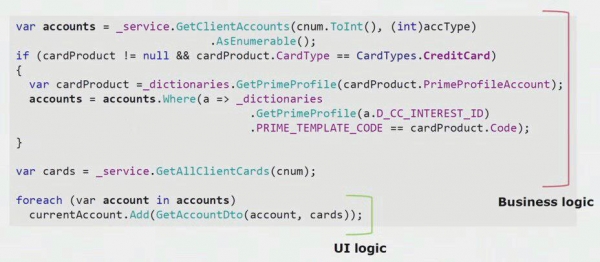
Tegelik kasutajaliidese loogika on alles paaril viimasel real. Viisime selle üle serverisse, et seda saaks uuesti kasutada, vähendades seeläbi kasutajaliidest ja saavutades õige arhitektuuri.
Neljas ja kõige olulisem viis mikroteenuste isoleerimiseks, mis võimaldab monoliiti vähendada, on olemasolevate teenuste eemaldamine koos töötlemisega. Kui võtame olemasolevad moodulid välja niisama, ei ole tulemus alati arendajatele meeldiv ning äriprotsess võib olla funktsionaalsuse loomisest alates aegunud. Refaktoreerimisega saame toetada uut äriprotsessi, sest ärinõuded muutuvad pidevalt. Saame täiustada lähtekoodi, eemaldada teadaolevad vead ja luua parema andmemudeli. Kasu on palju.
Teenuste eraldamine töötlemisest on lahutamatult seotud piiratud konteksti mõistega. See on domeenipõhise disaini kontseptsioon. See tähendab domeenimudeli osa, milles kõik ühe keele terminid on üheselt määratletud. Vaatame näitena kindlustuse ja arvete konteksti. Meil on monoliitne rakendus ja peame kontoga kindlustuses töötama. Eeldame, et arendaja leiab mõnest teisest komplektist olemasoleva kontoklassi, viitab sellele kindlustusklassist ja meil on töökood. Austatakse DRY põhimõtet, olemasolevat koodi kasutades saab ülesanne tehtud kiiremini.
Selle tulemusena selgub, et kontode ja kindlustuse kontekstid on omavahel seotud. Uute nõuete ilmnemisel segab see sidumine arengut, suurendades niigi keerulise äriloogika keerukust. Selle probleemi lahendamiseks peate koodis leidma piirid kontekstide vahel ja kõrvaldama nende rikkumised. Näiteks kindlustuse kontekstis on täiesti võimalik, et piisab 20-kohalisest Keskpanga kontonumbrist ja konto avamise kuupäevast.
Nende piiratud kontekstide üksteisest eraldamiseks ja mikroteenuste monoliitsest lahendusest eraldamise protsessi alustamiseks kasutasime sellist lähenemisviisi nagu rakenduses väliste API-de loomine. Kui teadsime, et mingist moodulist peaks saama mikroteenus, seda protsessi sees kuidagi muudetuna, siis tegime väliskõnede kaudu kohe väljakutsed teise piiratud konteksti kuuluvale loogikale. Näiteks RESTi või WCF-i kaudu.
Otsustasime kindlalt, et me ei väldi koodi, mis nõuab hajutatud tehinguid. Meie puhul osutus selle reegli järgimine üsna lihtsaks. Me ei ole veel kohanud olukordi, kus rangelt hajutatud tehinguid oleks tõesti vaja – lõplik moodulitevaheline kooskõla on täiesti piisav.
Vaatame konkreetset näidet. Meil on orkestri kontseptsioon – torujuhe, mis töötleb rakenduse olemit. Ta loob kordamööda kliendi, konto ja pangakaardi. Kui kliendi ja konto loomine õnnestub, kuid kaardi loomine nurjub, siis rakendus ei liigu olekusse “Ennestunud” ja jääb olekusse “Kaart pole loodud”. Tulevikus võtab taustategevus selle üles ja lõpetab. Süsteem on olnud mõnda aega ebaühtlases seisundis, kuid üldiselt oleme sellega rahul.
Kui tekib olukord, kus on vaja osa andmetest järjepidevalt salvestada, läheme suure tõenäosusega teenuse koondamisele, et seda ühes protsessis töödelda.
Vaatame näidet mikroteenuse eraldamisest. Kuidas saate selle suhteliselt ohutult tootmisse viia? Antud näites on meil süsteemist eraldi osa - palgateenuse moodul, mille ühe koodilõiku tahaksime teha mikroteenuse.
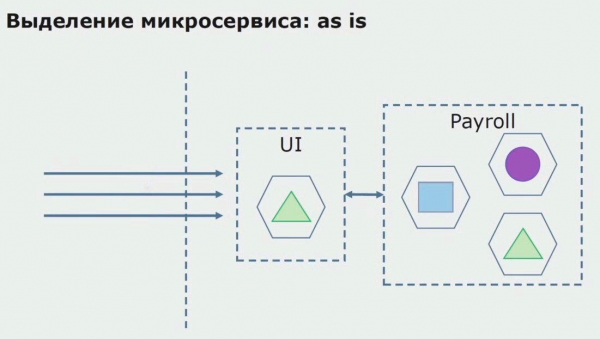
Kõigepealt loome koodi ümber kirjutades mikroteenuse. Täiustame mõningaid aspekte, millega me rahul ei olnud. Rakendame kliendilt uusi ärinõudeid. Lisame kasutajaliidese ja taustaprogrammi vahelisele ühendusele API lüüsi, mis pakub kõne suunamist.
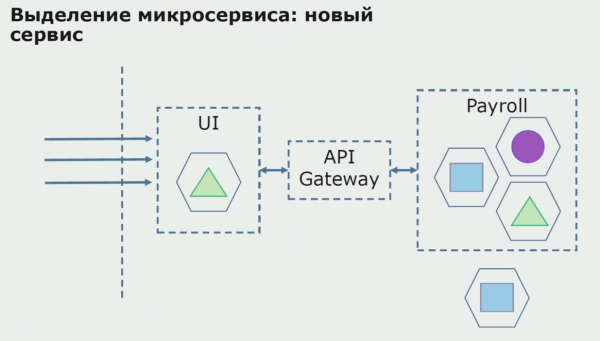
Järgmisena vabastame selle konfiguratsiooni tööle, kuid pilootolekus. Enamik meie kasutajaid töötab endiselt vanade äriprotsessidega. Uute kasutajate jaoks töötame välja monoliitrakenduse uue versiooni, mis seda protsessi enam ei sisalda. Põhimõtteliselt on meil piloodina töötav kombinatsioon monoliidist ja mikroteenusest.
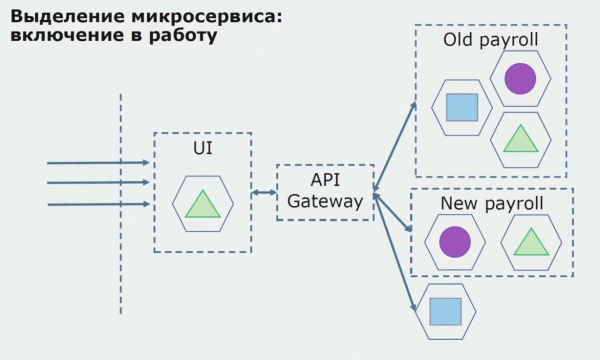
Eduka piloottöö korral saame aru, et uus konfiguratsioon on tõepoolest toimiv, saame vana monoliidi võrrandist eemaldada ja jätta uue konfiguratsiooni vana lahenduse asemele.
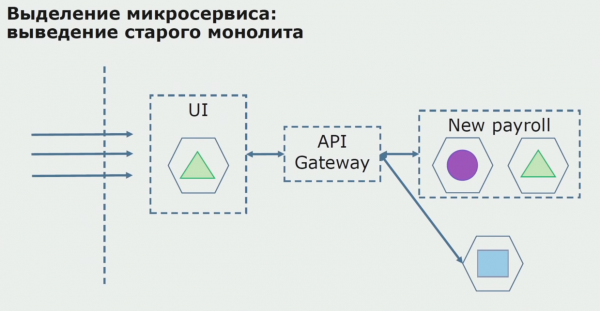
Kokkuvõttes kasutame monoliidi lähtekoodi tükeldamiseks peaaegu kõiki olemasolevaid meetodeid. Kõik need võimaldavad meil vähendada rakenduse osade suurust ja tõlkida need uutesse teekidesse, muutes parema lähtekoodi.
Töö andmebaasiga
Andmebaasi saab jagada halvemini kui lähtekoodi, kuna see ei sisalda mitte ainult praegust skeemi, vaid ka kogutud ajaloolisi andmeid.
Meie andmebaasil, nagu paljudel teistelgi, oli veel üks oluline puudus – selle tohutu suurus. See andmebaas loodi monoliidi keeruka äriloogika ja erinevate piiratud kontekstide tabelite vahel kogunenud suhete järgi.
Meie puhul kerkis kõigi hädade tipuks (suur andmebaas, palju ühendusi, kohati ebaselged piirid tabelite vahel) probleem, mis esineb paljudes suurtes projektides: jagatud andmebaasi malli kasutamine. Andmed võeti tabelitest läbi vaate, replikatsiooni ja saadeti teistesse süsteemidesse, kus seda replikatsiooni vaja oli. Seetõttu ei saanud me tabeleid eraldi skeemi liigutada, kuna neid kasutati aktiivselt.
Sama jaotus piiratud kontekstideks koodis aitab meil eraldada. Tavaliselt annab see meile üsna hea ülevaate sellest, kuidas andmeid andmebaasi tasemel jaotame. Saame aru, millised tabelid kuuluvad ühte piiratud konteksti ja millised teise.
Andmebaasi jaotamiseks kasutasime kahte globaalset meetodit: olemasolevate tabelite sektsioonideks jaotamiseks koos töötlemisega.
Olemasolevate tabelite eraldamine on hea meetod, mida kasutada, kui andmestruktuur on hea, vastab ärinõuetele ja kõik on sellega rahul. Sel juhul saame olemasolevad tabelid eraldada eraldi skeemiks.
Töötlemisega osakonda on vaja siis, kui ärimudel on kõvasti muutunud ja tabelid meid enam üldse ei rahulda.
Olemasolevate tabelite poolitamine. Peame otsustama, mida eraldame. Ilma nende teadmisteta ei tööta miski ja siin aitab meid piiritud kontekstide eraldamine koodis. Kui saate lähtekoodis kontekstide piiridest aru saada, saab reeglina selgeks, millised tabelid tuleks osakonna loendisse lisada.
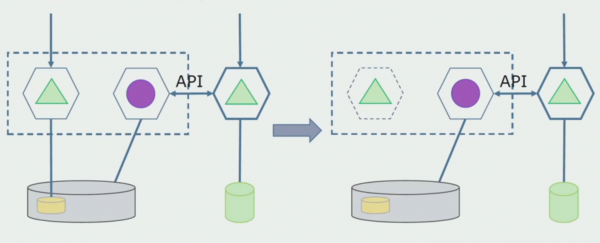
Kujutagem ette, et meil on lahendus, kus kaks monoliitmoodulit suhtlevad ühe andmebaasiga. Peame tagama, et ainult üks moodul suhtleb eraldatud tabelite jaotisega ja teine hakkab sellega API kaudu suhtlema. Alustuseks piisab, kui API kaudu toimub ainult salvestamine. See on vajalik tingimus, et saaksime rääkida mikroteenuste iseseisvusest. Lugemisühendused võivad püsida seni, kuni pole suurt probleemi.
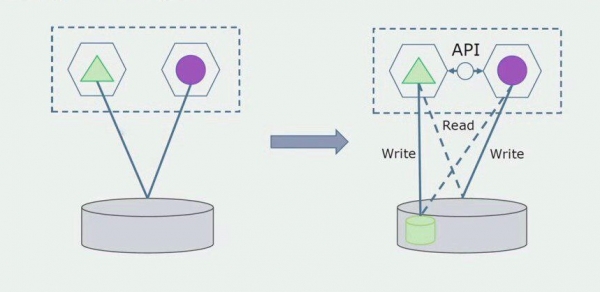
Järgmine samm on see, et saame eraldada eraldatud tabelitega töötava koodiosa, töötlemisega või ilma, eraldi mikroteenuseks ja käivitada selle eraldi protsessis, konteineris. See on eraldi teenus, millel on ühendus monoliidi andmebaasi ja nende tabelitega, mis sellega otseselt ei ole seotud. Monoliit suhtleb lugemiseks endiselt eemaldatava osaga.
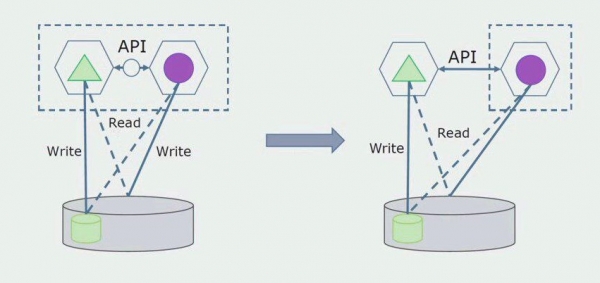
Hiljem eemaldame selle ühenduse ehk ka monoliitsest rakendusest eraldatud tabelitest andmete lugemine kantakse API-sse.
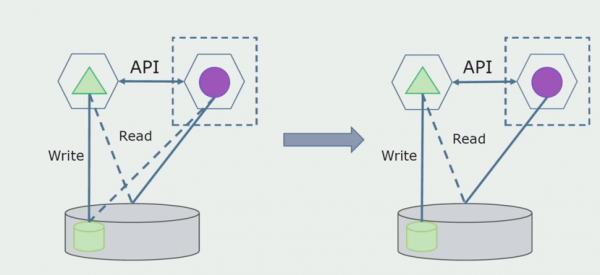
Järgmiseks valime üldandmebaasist välja tabelid, millega töötab ainult uus mikroteenus. Saame liigutada tabelid eraldi skeemi või isegi eraldi füüsilisse andmebaasi. Lugemisühendus mikroteenuse ja monoliitandmebaasi vahel on endiselt olemas, kuid muretsemiseks pole põhjust, sellises konfiguratsioonis võib see päris kaua elada.
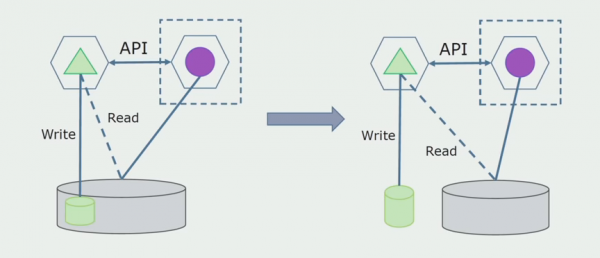
Viimane samm on kõigi ühenduste täielik eemaldamine. Sel juhul peame võib-olla migreerima andmed põhiandmebaasist. Mõnikord tahame mõnda välistest süsteemidest kopeeritud andmeid või katalooge mitmes andmebaasis uuesti kasutada. Seda juhtub meiega perioodiliselt.
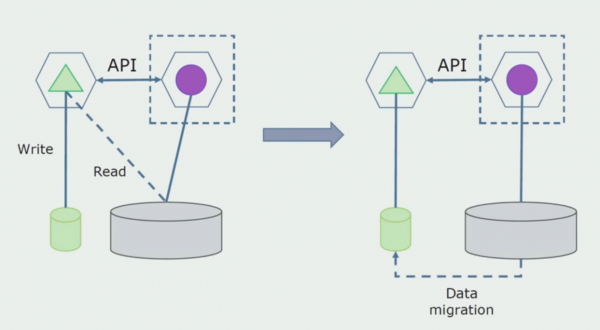
Töötlemise osakond. See meetod on väga sarnane esimesele, ainult vastupidises järjekorras. Eraldame kohe uue andmebaasi ja uue mikroteenuse, mis suhtleb monoliidiga API kaudu. Kuid samal ajal jääb alles hulk andmebaasitabeleid, mida tahame tulevikus kustutada. Meil pole seda enam vaja; asendasime selle uues mudelis.
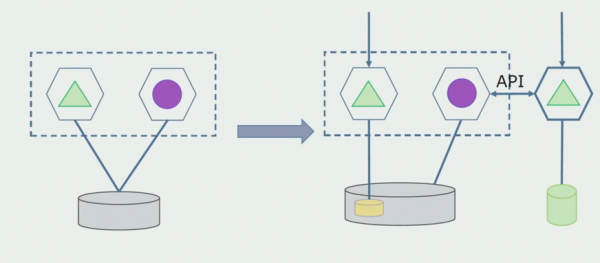
Selle skeemi toimimiseks vajame tõenäoliselt üleminekuperioodi.
Siis on kaks võimalikku lähenemist.
Esimene: dubleerime kõik andmed uues ja vanas andmebaasis. Sel juhul on meil andmete liiasus ja võivad tekkida sünkroonimisprobleemid. Kuid me saame võtta kaks erinevat klienti. Üks töötab uue versiooniga, teine vana versiooniga.
Teine: jagame andmed mõne ärikriteeriumi järgi. Näiteks oli meil süsteemis 5 toodet, mis olid salvestatud vanas andmebaasis. Kuuenda paigutame uue äriülesande raames uude andmebaasi. Kuid meil on vaja API-lüüsi, mis sünkroonib need andmed ja näitab kliendile, kust ja mida saada.
Mõlemad lähenemisviisid töötavad, vali sõltuvalt olukorrast.
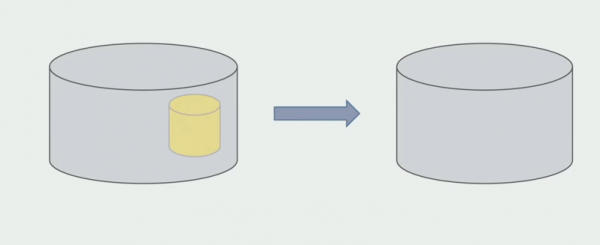
Kui oleme veendunud, et kõik töötab, saab vanade andmebaasistruktuuridega töötava monoliidi osa keelata.
Viimane samm on vanade andmestruktuuride eemaldamine.
Kokkuvõtteks võib öelda, et meil on andmebaasiga probleeme: sellega on võrreldes lähtekoodiga raske töötada, raskem jagada, aga saab ja peaks hakkama. Oleme leidnud mõned viisid, mis võimaldavad seda üsna turvaliselt teha, kuid andmetega on siiski lihtsam vigu teha kui lähtekoodiga.
Lähtekoodiga töötamine
Selline nägi lähtekoodi diagramm välja, kui hakkasime monoliitset projekti analüüsima.
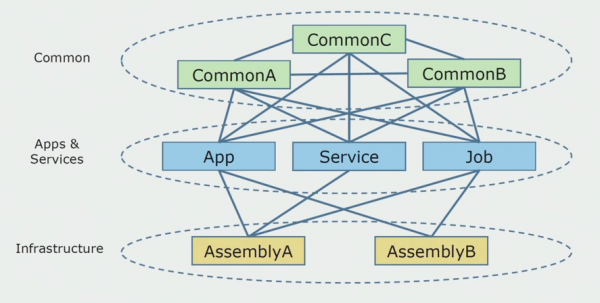
Selle saab laias laastus jagada kolmeks kihiks. See on käivitatud moodulite, pistikprogrammide, teenuste ja individuaalsete tegevuste kiht. Tegelikult olid need monoliitse lahenduse sisenemispunktid. Kõik need suleti tihedalt ühise kihiga. Sellel oli äriloogika, mida teenused jagasid, ja palju ühendusi. Iga teenus ja pistikprogramm kasutas olenevalt nende suurusest ja arendajate südametunnistusest kuni kümmet või enamat tavalist komplekti.
Meil vedas, et meil olid infrastruktuuri raamatukogud, mida sai eraldi kasutada.
Mõnikord tekkis olukord, kus mõned levinud objektid ei kuulunud tegelikult sellesse kihti, vaid olid infrastruktuuri raamatukogud. See lahendati ümbernimetamisega.
Suurimaks murekohaks olid piiratud kontekstid. Juhtus, et 3-4 konteksti segati ühes ühises koosluses ja kasutati üksteist samade ärifunktsioonide raames. Tuli aru saada, kuhu ja milliste piiride järgi seda jagada saab ning mida edasi teha selle jaotuse kaardistamisega lähtekoodikoostudeks.
Oleme koodi jagamise protsessi jaoks sõnastanud mitu reeglit.
Esimene: me ei tahtnud enam äriloogikat teenuste, tegevuste ja pistikprogrammide vahel jagada. Tahtsime muuta äriloogika mikroteenuste sees sõltumatuks. Mikroteenuseid seevastu peetakse ideaalis teenusteks, mis eksisteerivad täiesti iseseisvalt. Usun, et selline lähenemine on mõnevõrra raiskav ja seda on raske saavutada, sest näiteks C#-s olevad teenused ühendatakse igal juhul tavalise raamatukoguga. Meie süsteem on kirjutatud C# keeles, muid tehnoloogiaid me veel kasutanud ei ole. Seetõttu otsustasime, et saame endale lubada tavaliste tehniliste sõlmede kasutamist. Peaasi, et need ei sisalda äriloogika fragmente. Kui teil on kasutatava ORM-i kohal mugav ümbris, on selle kopeerimine teenusest teenusesse väga kulukas.
Meie meeskond on domeenipõhise disaini fänn, nii et sibularhitektuur sobis meile suurepäraselt. Meie teenuste aluseks ei ole andmete juurdepääsukiht, vaid domeeniloogikaga koost, mis sisaldab ainult äriloogikat ja millel puudub seos infrastruktuuriga. Samal ajal saame domeenikomplekti iseseisvalt muuta, et lahendada raamistikega seotud probleeme.
Selles etapis puutusime kokku oma esimese tõsise probleemiga. Teenus pidi viitama ühele domeenikoostule, tahtsime muuta loogika sõltumatuks ja DRY põhimõte takistas meid siin kõvasti. Arendajad soovisid dubleerimise vältimiseks naaberkoosluste klasse uuesti kasutada ja selle tulemusena hakati domeene uuesti omavahel siduma. Analüüsisime tulemusi ja otsustasime, et võib-olla peitub probleem ka lähtekoodi salvestusseadme piirkonnas. Meil oli suur hoidla, mis sisaldas kogu lähtekoodi. Kogu projekti lahendust oli kohalikul masinal väga keeruline kokku panna. Seetõttu loodi projekti osade jaoks eraldi väikelahendused ning keegi ei keelanud neile mingit ühist või domeenikoosseisu lisada ja taaskasutada. Ainus tööriist, mis meil seda teha ei võimaldanud, oli koodi ülevaatus. Kuid mõnikord see ka ebaõnnestus.
Seejärel hakkasime liikuma eraldi hoidlate mudelile. Äriloogika ei liigu enam teenusest teenusesse, domeenid on muutunud tõeliselt iseseisvaks. Piiratud kontekste toetatakse selgemalt. Kuidas me infrastruktuuri raamatukogusid taaskasutame? Eraldasime need eraldi hoidlasse, seejärel panime need Nugeti pakettidesse, mille panime Artifactorysse. Iga muudatuse korral toimub kokkupanek ja avaldamine automaatselt.
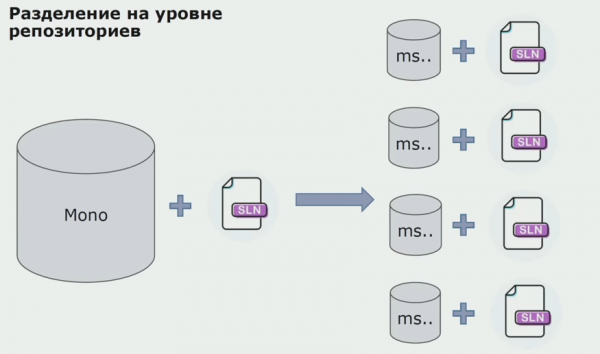
Meie teenused hakkasid viitama sisemistele taristupakettidele samamoodi kui välistele. Laadime Nugetist alla väliseid teeke. Artifactoryga töötamiseks, kuhu need paketid paigutasime, kasutasime kahte paketihaldurit. Väikestes hoidlates kasutasime ka Nugetit. Mitme teenusega hoidlates kasutasime paketti, mis tagab moodulite vahel suurema versioonijärjepidevuse.
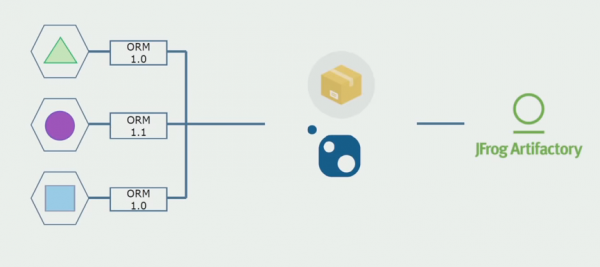
Seega, töötades lähtekoodi kallal, muutes veidi arhitektuuri ja eraldades hoidlaid, muudame oma teenused sõltumatumaks.
Infrastruktuuri probleemid
Enamik mikroteenustele ülemineku negatiivseid külgi on seotud infrastruktuuriga. Teil on vaja automatiseeritud juurutamist, vajate infrastruktuuri käitamiseks uusi teeke.
Käsitsi paigaldamine keskkondadesse
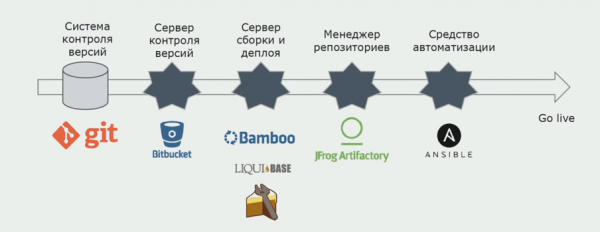
Algselt paigaldasime keskkondadele mõeldud lahenduse käsitsi. Selle protsessi automatiseerimiseks lõime CI/CD konveieri. Valisime pideva tarneprotsessi, kuna pidev juurutamine ei ole meie jaoks äriprotsesside seisukohast veel vastuvõetav. Seetõttu toimub tööks saatmine nupu abil ja testimiseks - automaatselt.
Lähtekoodi salvestamiseks kasutame Atlassiani, Bitbucket ja ehitamiseks Bamboot. Meile meeldib Cake'is koostamisskripte kirjutada, kuna see on sama, mis C#. Artifactorysse tulevad valmis paketid ning Ansible jõuab automaatselt testserveritesse, misjärel saab neid kohe testida.
Eraldi metsaraie
Omal ajal oli üks monoliidi ideedest pakkuda ühisraiet. Samuti pidime mõistma, mida teha plaatidel olevate üksikute logidega. Meie logid kirjutatakse tekstifailidesse. Otsustasime kasutada tavalist ELK virna. Otse pakkujate kaudu me ELK-le ei kirjutanud, vaid otsustasime, et muudame tekstiloge ja kirjutame neisse identifikaatorina jälje ID, lisades teenuse nime, et neid logisid saaks hiljem sõeluda.
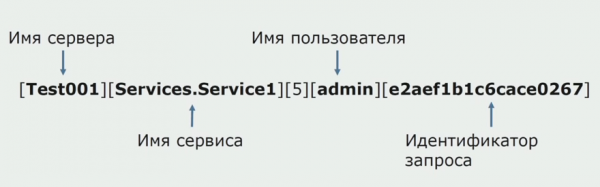
Filebeati abil saame oma logisid koguda järgmistelt allikatelt: serverid, seejärel teisendage need, kasutage Kibanat kasutajaliideses päringute loomiseks ja vaadake, kuidas kõne teenuste vahel suunati. Jälgimis-ID-d on selleks väga kasulikud.
Testimise ja silumisega seotud teenused
Algselt ei saanud me täielikult aru, kuidas arendatavaid teenuseid siluda. Monoliidiga oli kõik lihtne; käitasime seda kohalikul masinal. Alguses prooviti sama teha mikroteenustega, kuid mõnikord on ühe mikroteenuse täielikuks käivitamiseks vaja käivitada mitu teist ja see on ebamugav. Mõistsime, et peame üle minema mudelile, kus jätame kohalikku masinasse ainult need teenuse või teenused, mida tahame siluda. Ülejäänud teenuseid kasutatakse serveritest, mis vastavad konfiguratsioonile prod. Pärast silumist väljastatakse testimise ajal iga ülesande jaoks testserverile ainult muudetud teenused. Seega testitakse lahendust sellisel kujul, nagu see tulevikus tootmisse ilmub.
On servereid, mis käitavad ainult teenuste tootmisversioone. Neid servereid on vaja vahejuhtumite korral, tarnimise kontrollimiseks enne juurutamist ja sisekoolituseks.
Oleme lisanud automaatse testimisprotsessi, kasutades populaarset Specflow teeki. Testid käivituvad automaatselt NUniti abil kohe pärast Ansible'ist juurutamist. Kui ülesande katvus on täisautomaatne, pole käsitsi testimist vaja. Kuigi mõnikord on siiski vaja täiendavat käsitsi testimist. Kasutame Jiras märgendeid, et määrata, milliseid teste konkreetse probleemi korral käivitada.
Lisaks on suurenenud vajadus koormustestide järele, varem tehti seda vaid harvadel juhtudel. Testide käitamiseks kasutame JMeterit, nende salvestamiseks InfluxDB-d ja protsessigraafikute koostamiseks Grafanat.
Mida me saavutanud oleme?
Esiteks vabanesime mõistest "vabastamine". Möödas on kaks kuud kestnud koletu väljalasked, mil see koloss tootmiskeskkonnas kasutusele võeti, häirides ajutiselt äriprotsesse. Nüüd juurutame teenuseid keskmiselt iga 1,5 päeva järel, rühmitades need, kuna need käivituvad pärast kinnitamist.
Meie süsteemis pole surmavaid tõrkeid. Kui anname välja veaga mikroteenuse, läheb sellega seotud funktsionaalsus katki ja kõik muud funktsionaalsust ei mõjuta. See parandab oluliselt kasutajakogemust.
Saame juurutusmustrit juhtida. Vajadusel saate valida teenuste rühmad ülejäänud lahendusest eraldi.
Lisaks oleme probleemi oluliselt vähendanud suure täiustuste järjekorraga. Nüüd on meil eraldi tootemeeskonnad, kes töötavad mõne teenusega iseseisvalt. Scrumi protsess sobib siia juba hästi. Konkreetsel meeskonnal võib olla eraldi tooteomanik, kes määrab talle ülesandeid.
Kokkuvõte
- Mikroteenused sobivad hästi keerukate süsteemide lagundamiseks. Selle käigus hakkame mõistma, mis on meie süsteemis, millised on piiratud kontekstid, kus on nende piirid. See võimaldab teil täiustusi moodulite vahel õigesti jaotada ja vältida koodi segadust.
- Mikroteenused pakuvad organisatsioonilisi eeliseid. Tihti räägitakse neist vaid kui arhitektuurist, kuid igasugust arhitektuuri on vaja ärivajaduste lahendamiseks, mitte omaette. Seega võime öelda, et mikroteenused sobivad hästi väikestes meeskondades probleemide lahendamiseks, arvestades, et Scrum on praegu väga populaarne.
- Eraldamine on iteratiivne protsess. Te ei saa võtta rakendust ja jagada seda lihtsalt mikroteenusteks. Saadud toode ei ole tõenäoliselt funktsionaalne. Mikroteenuste pühendamisel on kasulik olemasolev pärand ümber kirjutada ehk muuta see meile meeldivaks ning funktsionaalsuse ja kiiruse poolest paremini ärivajadustele vastavaks koodiks.
Väike hoiatus: Mikroteenustele ülemineku kulud on üsna märkimisväärsed. Üksinda taristuprobleemi lahendamine võttis kaua aega. Nii et kui teil on väike rakendus, mis ei vaja spetsiifilist skaleerimist, välja arvatud juhul, kui teie meeskonna tähelepanu ja aja pärast võistleb suur hulk kliente, siis ei pruugi mikroteenused olla need, mida te täna vajate. See on üsna kallis. Kui alustada protsessi mikroteenustega, siis on kulud esialgu suuremad kui sama projektiga alustamisel monoliidi arendamisega.
PS Emotsionaalsem lugu (ja nagu sulle isiklikult) - vastavalt .
Siin on aruande täisversioon.
Allikas: www.habr.com
