

Hiljuti rääkisin, kuidas kasutada tüüpretsepte PostgreSQL-andmebaasist. Täna räägime aga sellest, kuidas saab andmebaasi kirjutamist tõhusamaks muuta ilma igasuguste „nuppudeta” konfigureerimises — lihtsalt korraldades andmevooge õigesti.

#1. Секционирование
Artikkel sellest, kuidas ja miks tasub korraldada on juba olnud, nüüd räägime mõningate lähenemiste praktilisest rakendamisest meie .
„Asjad minevikust…”
Alguses, nagu iga MVP, alustas meie projekt suhteliselt vähese koormusega — jälgimine toimus ainult kõige kriitilisemate serverite osas, kõik tabelid olid võrreldes kompaktsetes… Kuid aeg möödus, jälgitavate hostide arv kasvas pidevalt ja püüdes taas midagi teha ühe 1.5TB suuruse tabeliga, mõistsime, et niimoodi elada on võimalik, kuid siiski äärmiselt ebamugav.
Ajalood olid peaaegu mütoloogilised, PostgreSQL 9.x erinevad variandid olid päevakajalised, seetõttu tuli kogu sektsioneerimine teha "käe järgi" — läbi tabelite pärimise ja triggereid dünaamilise roolimisega EXECUTE.
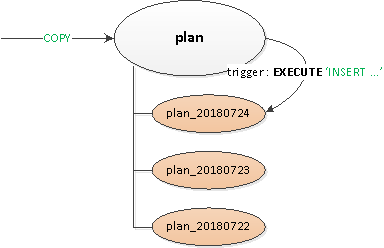
Saadud lahendus osutus piisavalt universaalseks, et seda saaks rakendada kõigile tabelitele:
- Deklariti tühine "pealkirja" vanemtabel, kus kirjeldati kõiki vajalikke indekseid ja triggereid.
- Kliendi vaates tehti kirje "juhtivas" tabelis ja selle sees läbi roolimise triggereid
BEFORE INSERTkirje "füüsiliselt" sisestati vajaliku sektsiooni. Kui sellist veel ei olnud — püüdsime erandi ja ... - ... abiga vanematabeli järgi loodi sektsioon, millel on piirang vajaliku kuupäeva järgi, et andmete väljavõtmisel toimuks lugemine ainult seal.
PG10: esimene katse
Kuid pärimise teel sektsioneerimine ei olnud ajalooliselt väga kohandatud aktiivse kirjutusvoo või suurt hulka lapssektsioone töötama. Näiteks võib meenutada, et vajaliku sektsiooni valimise algoritm oli ruutkompleksne, et kuna 100+ sektsiooniga töötab, te mõistate, kuidas ...
PG10 on seda olukorda märgatavalt parandanud, rakendades toe . Seetõttu proovisime seda kohe pärast salvestusruumi migratsiooni rakendada, kuid ...
Nagu selgus pärast juhendi põhjalikku uurimist, ei toeta natiivne sektsioneeritud tabel selle versiooni puhul:
- indeksite kirjeldamist
- triggereid
- ei saa olla kellegi 'pärijaks'
- tugi
INSERT ... ON CONFLICT - ei oska automaatselt sektsiooni luua
Pärast valusalt ninalöögiga saamist taipasime, et rakenduse modifitseerimiseta ei pääse, ja lükkasime edasised uuringud kuue kuu võrra edasi.
PG10: teine võimalus
Nii alustasime tekkinud probleemide järkjärgulist lahendamist:
- Kuna triggerid ja
ON CONFLICTleik nagu olid siiski vajalikud, tegime nende töötlemiseks vahepealse proksi-tabeli. - Vabastasime end 'redigeerimisest' triggereid — see tähendab
EXECUTE. - Tõime välja eraldi malltabeli kõigi indeksitega, et need ei oleks isegi proksi-tabelis.
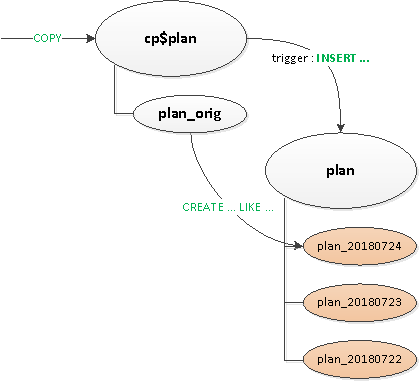
Lõpuks, pärast kõike seda, on peamine tabel juba loomulikult sektsioonideks jagatud. Uue sektsiooni loomine jääb siiski rakenduse hooleks.
„Teeme“ sõnaraamatuid
Nagu igas analüütilises süsteemis, olid ka meil „faktid“ ja „arvutused“ (sõnaraamatud). Meie puhul esindasid seda näiteks ühesuguseid aeglaseid päringuid või päringu teksti ennast.
„Faktid“ olid meil juba ammu päevade kaupa eraldatud, seega kustutasime vananenud sektsioone rahulikult ning need ei seganud meid (logid ju!). Kuid sõnaraamatute puhul tekkis probleem ...
Ei saa öelda, et neid oleks olnud väga palju, kuid umbes 100TB „faktide“ kohta sai 2.5TB sõnaraamat.Sellisest tabelist pole mugav midagi kustutada ega kokku suruda mõistliku ajaga, ja salvestamine muutus järjest aeglasemaks.
Nagu sõnaraamat ... igas kirjes peaks olema esindatud täpselt üks kord ... ja see on õige, aga ...! Keegi ei takista meid omamast igaühe kohta eraldi sõnaraamatutJah, see toob kaasa teatud ülemäärasuse, kuid samas võimaldab:
- kiiremini kirjutada/ lugeda väiksema sektsiooni suuruse tõttu
- kasutada vähem mälu kompaktsemate indeksite töötamise tõttu
- hoida vähem andmeid vana kergesti kustutamise võimaluse tõttu
Kogu tegevuste kompleksi tulemusena CPU koormus vähenes umbes 30% ja kettakoormus 50%:
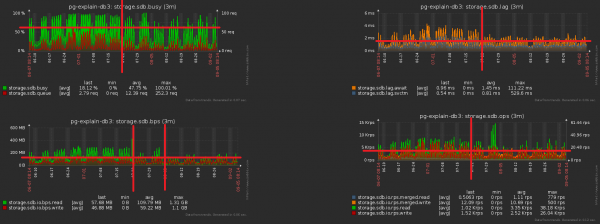
Ja samas jätkasime andmebaasi kirjutamist just sama palju, lihtsalt väiksema koormusega.
#2. Эволюция и рефакторинг БД
Nii et peatusime seal, et meil on iga päev oma sektsioon andmete jaoks. Nimelt, CHECK (dt = '2018-10-12'::date) — ja see on sektsioneerimise võti ja tingimus, mille alusel kantakse kirje konkreetsetesse sektsioonidesse.
Kuna kõik meie teenuse aruanded koostatakse konkreetse kuupäeva järgi, siis olid indeksid juba „no-sektsioneerimise aegadest“ kõik sellised, (Server, Astra Linux Special Editioni väljaanne, Plaani mall), (Server, Astra Linux Special Editioni väljaanne, Plaani sõlm), (Astra Linux Special Editioni väljaanne, Veaklass, Server),…
Aga nüüd elavad igas sektsioonis oma eksemplarid iga sellise indeksi… Ja igas sektsioonis kuupäev on konstant… Tuleb välja, et nüüd kirjutame sellesse indeksisse lihtsalt konstant ühe väli kui, mis suurendab nii selle mahtu kui ka otsingu aega, kuid ei anna mingit tulemust. Jätsime endale konksud, ups…

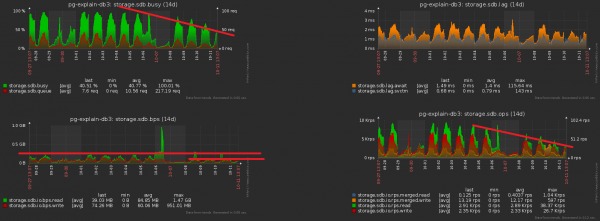
Optimeerimise suund on ilmselge — lihtsalt eemime kuupäeva välja kõikidest indeksitest jaotatud tabelites. Meie mahutavusega on sääst - umbes 1TB/nädal!
Ja nüüd märkame, et selline terabaid tuleb ka kuidagi salvestada. See tähendab, et me peame kettale nüüd vähem koormust panema! Sellel pildil on hästi näha saavutatud efekt meie nädalase koristustöö tulemusena:
#3. «Размазываем» пиковую нагрузку
Üks suuremaid muresid koormatud süsteemides on ülemäärane sünkroniseerimine mõnedele tegevustele, mis ei nõua seda. Mõnikord «sest ei märganud», mõnikord «oli lihtsam», kuid varem või hiljem tuleb sellest lahti saada.
Suureme oma eelmist pilti lähemale - ja näeme, et meie ketas «tõmbab» koormust kahekordse amplituudiga naabrite vahepealsete mõõtmiste vahel, mis selgelt ei peaks olema «statistiliselt» sellise tegevuste hulga juures:
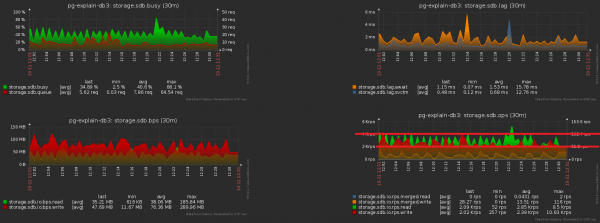
Seda on piisavalt lihtne saavutada. Meie järelevalvesse on juba peaaegu 1000 serverit, igaüks töötlemisel eraldi loogilise voona, ning iga voog eemaldab kogutud teabe saatmiseks andmebaasi kindla perioodsusega, enam-vähem nii:
setInterval(sendToDB, interval)Probleem peitub just selles, kõik voolud algavad umbes samal ajal, seega on saatmishetked peaaegu alati ühteaegu "kuni punktini". Ups nr 2…
Õnneks on seda lihtne parandada, lisades "juhusliku" hajutuse aja jooksul:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Кэшируем, что нужно можно
Kolmas traditsiooniline probleem kõrge koormuse puhul — vahemälu puudumine seal, kus see võiks olla.
Näiteks oleme teinud analüüsi võimaliku plaani sõlmede lõikes (kõik need Seq Scan on users), kuid kohe mõtlema, et need on massiliselt sarnased — unustatud.
Ei, loomulikult, andmeid ei kirjutata andmebaasi uuesti, see katkestab trigeri INSERT ... ON CONFLICT DO NOTHING. Kuid andmed jõuavad andmebaasi ikkagi, ja peame tegema üleliigset lugemist konfliktide kontrollimiseks. Ups nr 3…
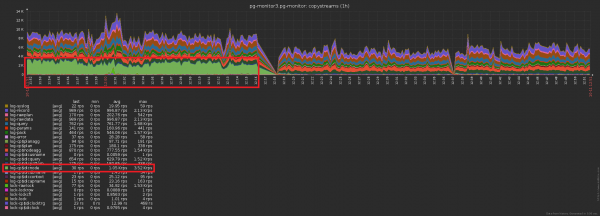
Erinevus andmebaasi saadetavate rekordite arvus enne/pärast vahemälu sisselülitamist — on ilmne:
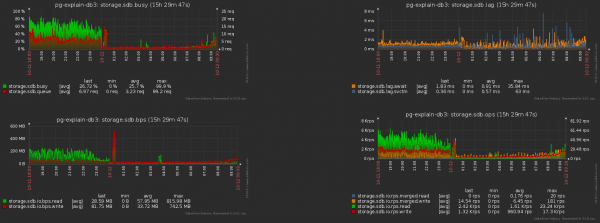
Ja see — kaasneva koormuse langus salvestusruumis:
Kokku
"Terabait-päevas" kõlab lihtsalt hirmuäratavalt. Kui teete kõike õigesti, siis on see ainult 2^40 baiti / 86400 sekundit = ~12.5MB/s, mida suudavad isegi lauaarvutite IDE-kettad. 🙂
Ja kui tõsiselt rääkida, siis isegi kümnekordse koormuse ebaühtluse korral päeva jooksul saate rahulikult osaleda tänapäevaste SSD-de võimalustes.

Allikas: habr.com
