

Tere kõigile! Olen tagapidi arendaja, kirjutan mikroteenuseid Java + Springis. Töölen ühes siseteenuste arendusmeeskonnas Tinkoffis.

Meie meeskonnas tekib sageli küsimus andmebaasi päringute optimeerimisest. Alati on tahtmine veelgi kiiremini töötada, kuid mõnikord ei piisa ainult mõistlikult üles ehitatud indeksitest — tuleb leida teisi lahendusi. Ühel neist rännakutest internetis, otsides mõistlikke optimeerimisi andmebaasidega töötamiseks, leidsin , kes on raamatu SQL Performance Explained autor. See on üks neist haruldastest blogidest, kus saab lugeda kõiki artikleid järjest.
Soovin tõlkida teile väikese artikli Markuselt. Seda võib mingil määral nimetada manifestiks, mis püüab juhtida tähelepanu vanale, kuid endiselt aktuaalsele probleemile SQLi standardi offset-operatsiooni jõudluses.
Mõnes kohas lisan autorile seletusi ja märkuseid. Kõiki selliseid kohti tähistan kui „prim.” selguse huvides.
Lühike sissejuhatus
Usun, et paljuski teavad, kui problemaatiliseks ja aeglaseks võib osutuda leheküljepõhiste valikute kasutamine offset'iga. Kuid kas teadsite, et seda on üsna lihtne asendada tootlikuma konstruktsiooniga?
Seega näitab tähtsaim sõna offset, et andmebaas peab vahele jätma esimesed n kirjet päringus. Siiski peab andmebaas ikkagi lugema need esimesed n kirjet kettalt, antud järjekorras (nt: rakendage sorteerimist, kui see on määratud), ja alles seejärel saab alustada kirjete tagastamist alates n+1 ja edasi. Kõige huvitavam on see, et probleem ei seisne mitte konkreetses rakenduses andmebaasis, vaid algses määratlemises vastavalt standardile:
…read sorteeritakse esmalt vastavalt <order by clause> ja seejärel piiratakse, kõrvaldamiseks määratud ridade arv <result offset clause> algusest…
-SQL:2016, Part 2, 4.15.3 Tuletatud tabelid (nt: praegu kõige rohkem kasutatav standard)
Siin on võtmepunkt see, et offset võtab ainult ühe parameetri — kirje arvu, mida tuleb vahele jätta, ja kõik. Järgides sellist määratlemist, võib andmebaas ainult välja tuua kõik kirjed ja seejärel kõrvaldada mittevajalikud. On ilmne, et selline määratlemine offset'ile sunnib tegema liigset tööd. Ja see, kas see on SQL või NoSQL, ei oma tähtsust.
Veel valu.
Offset probleemid ei lõpe siin ning siin on põhjus. Kui kahe lehe andmete lugemise vahel sisestab mõni teine toiming uue kirje, mis juhtub siis?
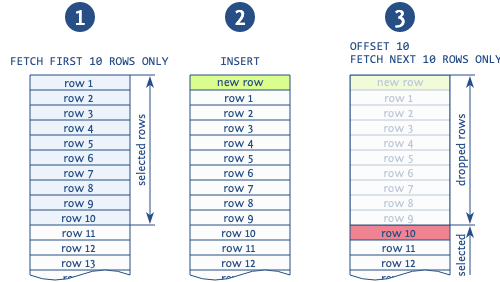
Kui offset'i kasutatakse varasemate lehtede kirjeid vahelejätmiseks, siis olukorras, kus uusi kirjeid lisatakse erinevate lehtede lugemise vahel, on tõenäoliselt tulemuseks duplikaadid (nt: see on võimalik, kui loeme lehti järjekorra järgi, siis võib meie tulemuste vahepeal ilmuda uus kirje).
Joonis illustreerib sellist olukorda. Andmebaas loeb esimesed 10 kirjet, seejärel sisestatakse uus kirje, mis nihutab kõik loetud kirjed ühe võrra. Seejärel võtab andmebaas järgmise lehe 10 kirjest ja alustab mitte 11. kirjast, nagu peaks, vaid 10. kirjast, dubleerides selle kirje. On ka teisi anomaaliaid, mis on seotud selle väljendi kasutamisega, kuid see on kõige levinum.
Nagu juba selgus, ei ole see probleem konkreetse andmebaasi või nende rakenduste jaoks. Probleem seisneb SQL-i standardi järgi leheküljenduse määratlemises. Me ütleme andmebaasile, millist lehte tuleb laadida või kui palju kirjeid tuleb vahele jätta. Andmebaas ei suuda sellist päringut optimeerida, kuna selleks on liiga vähe teavet.
Samuti tasub märkida, et see probleem ei ole konkreetse võtmesõna küsimus, vaid pigem päringu semantika. On veel mitmeid identselt probleemseid süntakse.
- Võtmesõna offset, nagu eelnevalt mainitud.
- Kaks võtmesõna koosneva konstruktsioon [limit] offset (kuigi limit iseenesest ei ole nii halb).
- Filtreerimine madalamate piiride alusel, mis põhineb ridade numbreerimisel (nt row_number(), rownum jne).
Kõik need väljendid ütlevad lihtsalt, kui palju ridu tuleb vahele jätta, ei mingit lisainfot ega konteksti.
Edasi selles artiklis kasutatakse võtmesõna offset, et üldistada kõiki neid variante.
Elu ilma OFFSET
Ja nüüd kujutame ette, milline oleks meie maailm ilma kõigi nende probleemideta. Selgub, et elu ilma offsetita ei ole sugugi nii keeruline: selectiga saab valida ainult need read, mida me veel näinud ei ole (nt. need, mida eelmisel lehel ei olnud), kus on tingimus where.
Sel juhul lähtume tõsiasjast, et selectid täidetakse järjestatud kogudel (vana ja hea order by). Kuna meil on järjestatud kogum, saame kasutada üsna lihtsat filtrit, et tuua välja ainult need andmed, mis asuvad pärast eelmist lehtedetaili:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYJa see ongi kogu selle lähenemise põhimõte. Muidugi, kui sorteerida mitmete veergude järgi, saab kõik palju huvitavamaks, kuid idee jääb samaks. Oluline on märkida, et see konstruktsioon on rakendatav paljude -lahenduste.
See meetodit nimetatakse seek meetodiks või keyset lehtede pööramiseks. See lahendab ujuva tulemuse probleemi (nt: olukord, kus kirjeid vahepeal lugedes muutub) ja loomulikult töötab see kiiremini ja stabiilsemalt kui klassikaline offset. Stabiilsus seisneb selles, et päringu töötlemise aeg ei suurene proportsionaalselt küsitava lehe numbriga (nt: kui soovite rohkem teada erinevate lehtede pööramise lähenemiste toimimisest, saate . Seal võib leida ka erinevate meetodite võrdlusmõõdikud).
Üks slaididest , et võti- alusel lehtede pööramine ei ole muidugi kõikvõimas — sellel on oma piirangud. Kõige olulisem on see, et tal puudub võimalus lugeda juhuslikke lehti (nt: mittesekventiaalset). Kuid lõputute kerimiste ajastul (nt: front-endil) ei ole see sugugi probleem. Lehe numbri näitamine klikkimiseks on igal juhul halb lahendus UI arendamisel (nt: artikli autori arvamus).
Kuidas on tööriistadega?
Küljendamine võtmete alusel ei sobi sageli, kuna selle meetodi jaoks puudub tööriistade tugi. Enamik arendustööriistu, sealhulgas erinevad raamistikud, ei paku valikut, millisel moel küljendamine toimuda võib.
Olukorda halvendab asjaolu, et kirjeldatud meetod nõuab terviklikku tuge kasutatavate tehnoloogiate osas — alates andmebaasist kuni AJAX-päringu täitmiseni brauseris lõpmatu kerimise korral. Selle asemel, et määrata ainult lehe number, tuleb nüüd määrata võtmete kogum kõigi lehtede jaoks korraga.
Küll aga kasvab järk-järgult raamistike arv, mis toetavad küljendamist võtmete alusel. Siin on need, mis praegu olemas:
- Java jaoks;
- Ruby jaoks;
- ja Django jaoks;
- Python jaoks;
- — kriteeriumide API JPA rakenduste jaoks;
- Perl jaoks;
- , мапер для Node.js .
(Märkus: mõned lingid on eemaldatud, kuna tõlke hetkel ei olnud mõned teegid alates 2017–2018 aastast ajakohased. Kui on huvi, võib vaadata algallikasse.)
Just at this point, your help is needed. If you are developing or maintaining a framework that utilizes pagination in any way, I ask, I urge, I plead with you to implement native support for key-based pagination. If you have any questions or need assistance, I would be happy to help (, , ) (Note: from my experience with Markus, I can say that he is genuinely enthusiastic about promoting this topic).
If you are using ready-made solutions that you believe deserve to have support for key-based pagination, please create a request or even propose a ready-made solution, if possible. You can also refer to this article in the link.
Kokkuvõte
The reason why such a simple and useful approach as key-based pagination is rarely adopted is not because it is technically difficult to implement or requires significant effort. The main reason is that many are accustomed to seeing and working with offset — this approach is dictated by the standard itself.
Seetõttu mõtlevad vähesed inimestest lähenemisviisi muutmisele leheküljestamise osas, ja selle tõttu areneb raamistikute ja teekide tööriistade toetamine nõrgalt. Seega, kui idee ja eesmärk mitte-offset leheküljestamiseks on teile lähedane, — aidake seda levitada!
Allikas:
Autor: Markus Winand
Allikas: habr.com
