


Tabelite ja indeksite paisumise (bloat) probleem on hästi tuntud ja see esineb mitte ainult Postgresis. On olemas võimalusi selle probleemiga tegelemiseks, näiteks VACUUM FULL või CLUSTER, kuid need blokeerivad tabelid töötamise ajal, seega ei pruugi neid alati kasutada.
Artiklis käsitletakse veidi teooriat selle kohta, kuidas paisumine tekib, kuidas sellega saab võidelda, deferred constraints ja probleeme, mida need põhjustavad pg_repack laienduse kasutamisel.
See artikkel on kirjutatud PgConf.Russia 2020.
Miks paisumine tekib
PostgreSQL põhineb mitme versiooniga mudelil (). Selle põhimõte on see, et igal tabeli real võib olla mitmeid versioone, samas kui tehingud näevad vaid üht neist versioonidest, kuid mitte tingimata sama. See võimaldab mitmel tehingul samal ajal töötada, mõjutamata üksteist oluliselt.
On ilmselge, et need versioonid tuleb salvestada. Postgres töötab mäluga lehe kaupa ja leht on minimaalne andmemaht, mida saab lugeda kettalt või kirjutada. Käsitletakse väikest näidet, et mõista, kuidas see toimub.
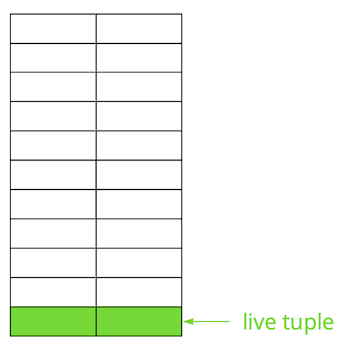
Oletame, et meil on tabel, kuhu oleme lisanud mitu salvestust. Faili esimesel lehel, kus tabelit hoitakse, on ilmunud uued andmed. Need on ridade elavad versioonid, mis on pärast commit'i teistele tehingutele kättesaadavad (lihtsuse huvides arvame, et Isolatsiooni tase on Read Committed).
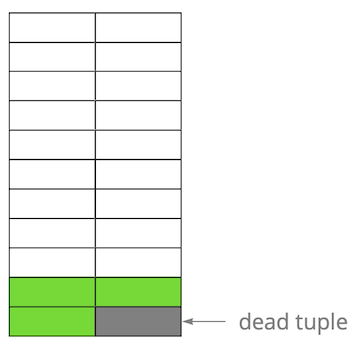
Seejärel uuendasime ühte salvestust ja märkisime seeläbi vana versiooni aegunuks.
Samm-sammult, uuendades ja eemaldades ridade versioone, saime lehe, kus umbes pooled andmed on „prügi“. Need andmed ei ole ühelegi tehingule nähtavad.
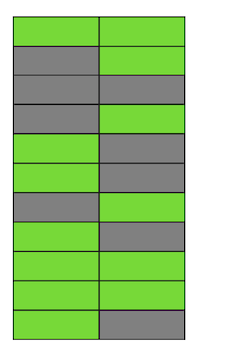
Postgres'is on olemas mehhanism , mis puhastab aegunud versioonid ja vabastab ruumi uutele andmetele. Kuid kui see ei ole piisavalt agressiivselt seadistatud või on hõivatud muude tabelitega, siis jäävad „prügiga andmed“ alles ja me peame kasutama lisalehti uutele andmetele.
Nii et meie näites koosneb tabel mingil hetkel neljast lehtedest, kuid elavaid andmeid on seal vaid pool. Seetõttu, kui me tabelisse pöördume, loeme palju rohkem andmeid, kui vajalik.
Isegi kui VACUUM eemaldab praegu kõik ebaolulised ridade versioonid, ei parane olukord dramaatiliselt. Meil on vaba ruumi lehtedes või isegi terveid lehti uute ridade jaoks, kuid me ikkagi loeme rohkem andmeid, kui vajalik.
Muide, kui täiesti tühi leht (teine meie näites) oleks faili lõpus, saaks VACUUM selle kärpida. Kuid praegu asub see keset faili, seega ei saa me sellega midagi teha.
Kuna selliste tühi või tugevalt hajutatud lehtede arv muutub suureks, mida nimetatakse bloatiks, hakkab see mõjutama jõudlust.
Kõik ülaltoodud on bloati tekke mehhanism tabelites. Indeksites toimub see umbes samamoodi.
Kas mul on bloat?
On mitmeid viise, kuidas määrata, kas teil on bloat. Esimese idee kohaselt kasutatakse Postgresi sisemist statistikat, kus on ligikaudne teave tabelites olevate ridade arvu, “elus” ridade arvu jne kohta. Internetist leiab palju variatsioone juba valmis skriptidest. Me võtsime aluseks PostgreSQL eksperdid, kes saavad hinnata tabelite ja toast ja bloat btree-indeksite bloat’i. Meie kogemuse järgi on selle täpsus 10-20%.
Teine võimalus on kasutada laiendust , mis võimaldab vaadata lehtede sisu ning saada nii hinnangulist kui ka täpset bloat'i väärtust. Kuid teisel juhul tuleb skaneerida kogu tabel.
Väike bloat, kuni 20%, on meie arvates vastuvõetav. Seda võib pidada analoogseks fillfactor’iga ja . 50% ja rohkem võib ilmuda jõudlusega probleeme.
Bloat’i vastu võitlemise viisid
Postgresis on mitu sisseehitatud meetodit bloat’i tõkestamiseks, kuid need ei pruugi alati ja kõigile sobida.
Seadistada AUTOVACUUM, et bloat ei tekiks. Ja kui täpsemalt, et see oleks teie jaoks vastuvõetaval tasemel. See võib tunduda nagu „kapteni” nõuanne, kuid reaalsus ei ole alati midagi, mida on kerge saavutada. Näiteks, kui teete aktiivset arendust koos pideva andmebaasi struktuuri muutmisega või toimub mingisugune andmete migratsioon. Tulemusena võib teie koormusprofiil sageli muutuda ja tavaliselt on see erinev erinevate tabelite jaoks. See tähendab, et peate pidevalt natuke ette töötama ja kohandama AUTOVACUUMi, et vastata iga tabeli muutuvatele vajadustele. Kuid on selge, et seda ei ole kerge teha.
Teine levinud põhjus, miks AUTOVACUUM ei suuda tabeleid töödelda, on pikaajalised tehingud, mis ei luba tal andmeid kustutada, kuna need on nende tehingute jaoks saadaval. Soovitus on selge: vabaneda „riputatavast“ tehingust ja minimeerida aktiivsete tehingute aega. Kuid kui teie rakenduse koormus on OLAP ja OLTP hübriid, võib teil sama ajal olla nii palju sagedaid uuendusi ja lühikesi päringuid kui ka pikaajalisi operatsioone, näiteks aruande koostamine. Sellises olukorras tasub kaaluda koormuse jagamist erinevatele andmebaasidele, mis võimaldab igaühe täpsemat seadistamist.
Veel üks näide: isegi kui profiil on homogeenne, kuid andmebaas on väga kõrge koormuse all, siis isegi kõige agressiivsem AUTOVACUUM ei pruugi toime tulla ning bloat hakkab tekkima. Skaleerimine (vertikaalne või horisontaalne) on ainus lahendus.
Kuidas käituda olukorras, kus olete AUTOVACUUMi seadistanud, kuid bloat jätkab kasvu.
Meeskond VACUUM FULL restruktureerib tabelite ja indeksite sisu, jättes neisse vaid aktuaalsed andmed. Bloat'i kõrvaldamiseks töötab see ideaalselt, kuid selle täitmise ajal haaratakse tabelile eksklusiivne lukustus (AccessExclusiveLock), mis ei võimalda selle tabeliga päringute täitmist, isegi select'ide puhul. Kui saate endale lubada teenuse või selle osa peatamist mõneks timeks (alates kümnetest minutidest kuni mitme tunni jooksul sõltuvalt andmebaasi suurusest ja teie riistvarast), on see variant parim. Kahjuks ei suuda me VACUUM FULL'i planeeritud hoolduse ajal teostada, seega see meetod meile ei sobi.
Meeskond CLUSTER ka restruktureerib tabelite sisu nagu VACUUM FULL, samas lubades määrata indeksi, mille alusel andmed füüsiliselt kettal järjestatakse (kuid tulevikus uute ridade jaoks ei saa järjestust garanteerida). Teatud olukordades on see üsna hea optimeerimine mitmete päringute jaoks – indeksiga mitme kirje lugemiseks. Puuduseks on selle käsu sama omadus nagu VACUUM FULL'il – see blokeerib tabeli töötamise ajal.
Meeskond REINDEX on sarnane kahe eelneva versiooniga, kuid see teostab konkreetse indeksi või kõigi tabeli indeksite ümberkujundamise. Lukustused on veidi nõrgemad: ShareLock tabeli jaoks (takistab muudatusi, kuid lubab selecti teostada) ja AccessExclusiveLock ümberkujundatavale indeksile (blokib päringud, mis kasutavad seda indeksit). Siiski, Postgresi 12. versioonis ilmus parameeter , mis lubab indeksit ümber kujundada, blokeerimata samal ajal rikkaid lisamisi, muudatusi või eemaldamisi.
Varem, Postgresi varasemates versioonides, on võimalik saavutada sama tulemus, mis on sarnane REINDEX CONCURRENTLY-ile, kasutades . See lubab luua indeksi ilma range lukustamiseta (ShareUpdateExclusiveLock, mis ei takista samaaegseid päringuid), seejärel asendada vana indeks uuega ja eemaldada vana indeks. See lubab eemaldada indeksi ülekasvu, takistamata teie rakenduse tööd. Oluline on arvestada, et indeksite ümberkujundamise korral on diskipõhises süsteemis täiendav koormus.
Seega, kuigi indeksite jaoks on olemas viise ülekasvu eemaldamiseks „kuumalt“, ei ole tabelite jaoks selliseid meetodeid. Siia tulevad erinevad välised laiendused: (varasemalt pg_reorg), , ja teised. Selle artikli raames ma ei hakka neid võrdlema ja räägin ainult pg_repack'ist, mida pärast teatavat kohandamist kasutame.
Kuidas pg_repack töötab

Oletame, et meil on täiesti tavaline tabel – koos indeksitega, piirangutega ja, kahjuks, bloat'iga. Esimese sammuna loob pg_repack logitabeli, et salvestada kõiki muudatusi töötamise ajal. Trikkri kaudu replitseeritakse need muudatused iga sisestuse, värskenduse ja kustutamise korral. Seejärel luuakse tabel, mis on struktuuri poolest sarnane algsele, kuid ilma indeksite ja piiranguteta, et mitte andmete sisestamise protsessi aeglustada.
Seejärel kannab pg_repack uude tabelisse andmed vanast, filtreerides automaatselt kõik ebaolulised read ja siis loob uue tabeli jaoks indeksid. Kõigi nende toimingute sooritamise ajal kogunevad logitabelisse muudatused.
Järgmine samm on muudatuste viimine uude tabelisse. Ülekandeprotsess toimub mitmes etapis, ja kui logitabelis jääb vähem kui 20 kirjet, seab pg_repack sisse tiheda lukustuse, viib viimased andmed üle ja asendab vana tabeli uuega Postgresi süsteemitabelites. See on ainus ja väga lühike hetk, mil te ei saa tabeliga töötada. Pärast seda eemaldatakse vana tabel ja logitabel, vabastades ruumi failisüsteemis. Protsess on lõpule viidud.
Teoreetiliselt tundub kõik suurepärane, aga kuidas see praktikas välja näeb? Testisime pg_repack'i ilma koormuseta ja koormuse all, kontrollisime selle toimimist juhusliku peatamise korral (teisisõnu, kui vajutada Ctrl+C). Kõik testid olid positiivsed.
Siis suundusime tootmisse — ja siin läks kõik nii, nagu me ootame.
Esimene kord tootmises
Esimeses klastris saime vea, mis seondus unikaalse piirangu rikkumisega:
$ ./pg_repack -t tablename -o id
INFO: tabeli "tablename" ümberpaigutamine
ERROR: päring ebaõnnestus:
ERROR: duplikaadi võtme väärtus rikub unikaalset piirangut "index_16508"
DETAIL: Võti (id, indeks)=(100500, 42) on juba olemas.
See piirangul oli automaatselt genereeritud nimetus index_16508 – selle lõi pg_repack. Selle koosseisu kuuluvaid atribuute analüüsides määrasime me “meie” piirangu, mis talle vastab. Probleem seisnes aga selles, et see pole tavaline piirang, vaid edasilükatud (), s.t. selle kontrollimine toimub hiljem kui sql-käsk, mis toob kaasa ootamatud tagajärjed.
Edasilükatud piirangud: miks need on vajalikud ja kuidas need töötavad
Veidi teooriat edasilükatud piirangute kohta.
Vaatame lihtsat näidet: meil on autotüüpide loendustabel, millel on kaks atribuuti – nimetus ja auto järjestus loendis.
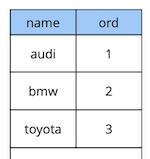
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Oletame, et meil on vaja vahetada esimese ja teise auto kohti. Lahendus “otseselt” – uuendada esimene väärtus teiseks ja teine esimeseks:
begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Kuid selle koodi täitmisel saame me oodatult piirangu rikkumise, sest tabeli väärtuste järjekord on ainulaadne:
[23305] VIGA: duubeldatud võtme väärtus rikub ainulaadse piirangu “uk_cars”
Detail: Key (ord)=(2) juba eksisteerib.
Kuidas teisiti teha? Esimene variant: lisada täiendav väärtuse asendamine järjestusse, mida tabelis kindlasti ei eksisteeri, näiteks "-1". Programmeerimises nimetatakse seda "kahe muutuja väärtuste vahetuseks kolmanda kaudu". Selle meetodi ainus puudus on täiendav uuendus.
Teine variant: projekteerida tabel ümber, et kasutada järjestuse väärtusena ujuva komaga andmetüüpi, selle asemel et täisarve. Siis, kui uuendate väärtust näiteks 1-lt 2.5-le, asetub esimene kirje automaatselt teise ja kolmanda vahele. See lahendus töötab, kuid sellel on kaks piirangut. Esiteks, see ei sobi, kui väärtust kasutatakse kuskil kasutajaliideses. Teiseks, sõltuvalt andmetüübi täpsusest on teil piiratud arv võimalikke sisestusi enne, kui tuleb kõikide kirje väärtuste ümberarvutamine.
Kolmas variant: teha piirang viivitamata, et seda kontrollitakse ainult kommiteerimise hetkel:
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);Kuna meie algse päringu loogika tagab, et enne kinnitamist on kõik väärtused unikaalsed, täidetakse see edukalt.
Ülaltoodud näide on muidugi väga sünteetiline, kuid ideed see avab. Meie rakenduses kasutame viivitustega piiranguid, et rakendada loogikat, mis lahendab konflikte, kui kasutajad töötavad samaaegselt jagatud objektide vidinatega tahvlil. Selliste piirangute kasutamine võimaldab meil rakenduskoodi natuke lihtsamaks muuta.
Üldiselt, sõltuvalt piirangu tüübist Postgresis, on nende kontrollimisel kolm granulaarsuse taset: rea, tehingu ja väljendi tase.
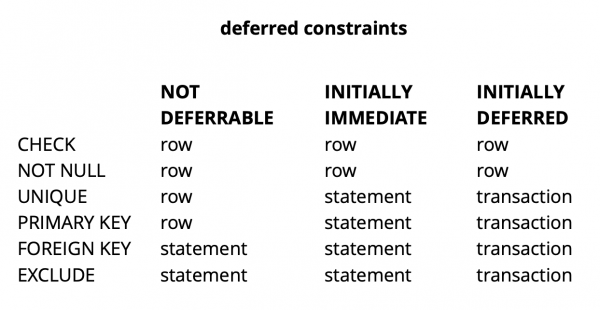
Allikas:
CHECK ja NOT NULL kontrollitakse alati rea tasandil, teiste piirangute puhul, nagu näha tabelist, on erinevaid variante. Rohkem teavet saab lugeda. .
Lühidalt kokku võttes pakuvad viivitatud piirangud teatud olukordades paremini loetavat koodi ja vähem käske. Kuid selle eest tuleb maksta debugeerimisprotsessi keerukuse eest, kuna vea tekkimise hetk ja hetk, mil te sellest teada saate, on ajaliselt lahus. Veel üks võimalik probleem on see, et ajakava ei suuda alati koostada optimaalselt plaani, kui päringus on viivitatud piirang.
Töötame edasi pg_repackiga
Oleme saanud aru, mis on viivitatud piirangud, kuid kuidas need on seotud meie probleemiga? Tuletagem meelde viga, mille saime varem:
$ ./pg_repack -t tablename -o id
INFO: tabeli "tablename" ümberpaigutamine
ERROR: päring ebaõnnestus:
ERROR: duplikaadi võtme väärtus rikub unikaalset piirangut "index_16508"
DETAIL: Võti (id, indeks)=(100500, 42) on juba olemas.See ilmneb siis, kui kopeeritakse andmeid logitabelist uude tabelisse. See tundub kummaline, sest logitabeli andmed kinnitatakse koos algtabeli andmetega. Kui need vastavad algtabeli piirangutele, siis kuidas nad saavad uues tabelis neid samme rikkuda?
Kuidas selgus, peitub probleemi juur pg_repack'i eelnevas etapis, kus luuakse ainult indeksid, kuid mitte piirangud: vanas tabelis oli unikaalne piirang, kuid uues loodi selle asemel unikaalne indeks.
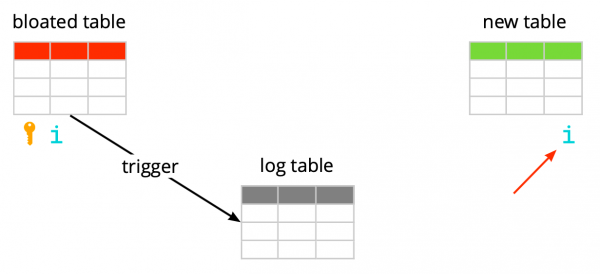
Siin on oluline märkida, et kui piirang on tavaline, mitte edasilükatud, siis loodud ainulaadne indeks on sellele piirangule samaväärne, kuna Postgresis rakendatakse ainulaadseid piiranguid ainulaadsete indeksite loomise abil. Kuid edasilükatud piirangu korral ei ole käitumine sama, kuna indeks ei saa olla edasilükatud ning kontrollitakse alati SQL-käsu täitmise hetkel.
Seega seisneb probleemi sisu kontrollimise „edasilükatuses”: algses tabelis toimub see kinnitamise hetkel, uues aga SQL-käsu täitmise hetkel. See tähendab, et meil on vaja tagada, et kontrollid toimuksid mõlemal juhul sama moodi: kas alati edasilükatult või alati kohe.
Nii et, millised ideed meil olid.
Luua indeks, mis on analoogne edasilükatule.
Esimene idee on teostada mõlemad kontrollid viivitamatult. See võib põhjustada mõningaid valepositiivseid piiranguid, kuid kui neid on vähe, ei tohiks see kasutajate tööd mõjutada, kuna sellised konfliktid on nende jaoks normaalne olukord. Need juhtuvad näiteks siis, kui kaks kasutajat alustavad samal ajal ühe ja sama vidina redigeerimist, ja teise kasutaja klient ei jõua saada teavet selle kohta, et vidin on juba esimese kasutaja poolt redigeerimiseks blokeeritud. Sel juhul vastab server teisele kasutajale keeldumisega ja tema klient tagastab muudatused ning blokeerib vidina. Veidi hiljem, kui esimene kasutaja on redigeerimise lõpetanud, saab teine teate, et vidin ei ole enam blokeeritud, ja saab oma tegevust korrata.

Kuna kontrollid peavad alati olema kiired, lõime uue indeksi, mis on analoogne originaalsele viivitamatule piirangule:
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
-- run pg_repack
DROP INDEX CONCURRENTLY uk_tablename__immediate;Testkeskkonnas leidsime vaid mõned oodatud vead. Edu! Käivitasime uuesti pg_repack tootmises ja saime esimeses klastris tunni töö jooksul 5 viga. See on vastuvõetav tulemus. Kuid teises klastris suurenes veade arv mitmekordselt ja pidime pg_repacki peatama.
Miks see juhtus? Veatekke tõenäosus sõltub sellest, kui palju kasutajaid töötab samal ajal samade vidinatega. Näib, et sel hetkel oli esimeses klastris andmeid, kus konkurentsi muudatusi tehti, oluliselt vähem kui teistes, st meie lihtsalt „vedas“.
Idee ei toiminud. Sel hetkel nägime kahte muud lahendust: kirjutada oma rakenduskood ümber, et loobuda edasi lükatud piirangutest, või „õpetada“ pg_repack neid rakendama. Me valisime teise.
Asendada uue tabeli indeksid algse tabeli edasi lükatud piirangutega.
Paranduse eesmärk oli ilmselge – kui algsel tabelil on edasi lükatud piirang, siis tuleb uue jaoks luua selline piirang, mitte indeks.
Meie muudatuste kontrollimiseks kirjutasime lihtsa testi:
- edastuspiiranguga tabel ja üks rida;
- sisestame tsüklis andmed, mis on olemasoleva kirje konfliktis;
- teeme uuenduse – andmed ei ole enam konfliktis;
- salvestame muudatused.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;Originaalne versioon pg_repack kukkus alati esimesel sisestamisel, muudetud versioon töötas vigadeta. Suurepärane.
Läheme tootmisse ja saame jälle vea samas faasis, kui andmed logitabelist uude kopeeritakse:
$ ./pg_repack -t tablename -o id
INFO: tabeli "tablename" ümberpaigutamine
ERROR: päring ebaõnnestus:
ERROR: duplikaadi võtme väärtus rikub unikaalset piirangut "index_16508"
DETAIL: Võti (id, indeks)=(100500, 42) on juba olemas.Klassikaline olukord: testkeskkondades töötab kõik, aga tootmises – ei?!
APPLY_COUNT ja kahe partii ühendus
Alustasime koodi analüüsimist sõna-sõnalt ja avastasime olulise hetke: andmete ülekandmine logitabelist uude toimub partii kaupa, konstant APPLY_COUNT näitas partii suurust:
for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue; /* there might be still some tuples, repeat. */
...
}Probleem on selles, et algse tehingu andmed, mille raames mitu operatsiooni võivad potentsiaalselt piirangut rikkuda, võivad siirdumise käigus sattuda kahe partii piirile – pool käske kinnitatakse esimeses partis ja teine pool teises. Ja siin on see lapse mäng: kui esimeses partis käsud midagi ei riku, siis on kõik hästi, aga kui rikuvad – toimub viga.
APPLY_COUNT on 1000 kirjet, mis selgitab, miks meie testid läksid edukalt – nad ei katnud 'partide piiri' juhtumit. Kasutasime kahte käsku – insert ja update, seega täpselt 500 tehingut kahe käsuga mahtusid alati partiisse ja me ei kohanud probleeme. Pärast teise update'i lisamist lõpetas meie muudatus töötamise:
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id; -- veel üks update
COMMIT;
END;
END LOOP;Seega, järgmine ülesanne on muuta nii, et algse tabeli andmed, mis muudetakse ühes tehingus, jõuaksid uude tabelisse samuti ühes tehingus.
Partii loobumisest
Ja meil oli jälle kaks lahenduse varianti. Esimene: loobume täiesti partii jagamisest ja teeme andmete ülekande ühe tehinguga. Selle lahenduse kasuks rääkis selle lihtsus — vajalikud koodimuudatused on minimaalsed (tuletan meelde, et vanemates versioonides töötas pg_reorg just niimoodi). Kuid probleem on see — me loome pika tehingu, mis, nagu varasemalt mainitud, on uus bloati tekkimise oht.
Teine lahendus on keerulisem, kuid võib-olla ka õigem: luua logitabelis veerg, mis sisaldab tehingu identifikaatorit, mis andmed tabelisse lisas. Sel juhul saame andmete kopeerimise ajal rühmitada need selle atribuudi järgi ja tagada, et seotud muudatused kantakse üle koos. Partii koosneb mitmest tehingust (või ühest suurest) ja selle suurus varieerub sõltuvalt sellest, kui palju andmeid on nendes tehingutes muudetud. Oluline on märkida, et kuna erinevate tehingute andmed satuvad logitabelisse juhuslikus järjekorras, ei saa seda enam järjestikku lugeda nagu varem. seqscan igas päringus, kus filterdame tx_id järgi, on liiga kulukas, vajalik indeks, kuid see aeglustaks meetodi tööd ka oma uuendamise kulude tõttu. Kokkuvõttes tuleb nagu tavaliselt millegi nimel ohverdada.
Nii, otsustasime alustada esimesest variantist, kuna see oli lihtsam. Esiteks pidi selguma, kas pikaajaline tehing on tõeliseks probleemiks. Kuna peamine andmete ülekandmine vanast tabelist uude toimub samuti ühe pikaajalise tehingu raames, muutus küsimus selleks, "kui palju me seda tehingut suurendame?" Esimese tehingu kestus sõltub peamiselt tabeli suurusest. Uue kestus sõltub aga sellest, kui palju muudatusi tabelis on kogunenud andmete ülekandmise aja jooksul, st koormuse intensiivsusest. pg_repack'i käitamine toimus teenuste minimaalsete koormuste ajal, ja muudatuste maht oli võrreldes algse tabeli mahuga järsult väike. Otsustasime, et võime uue tehingu kestuse tähelepanuta jätta (keskmiselt on see 1 tund ja 2-3 minutit).
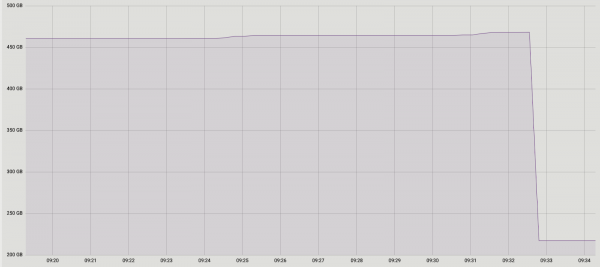
Eksperimentide tulemused olid positiivsed. Ülesanne seadistuses töötas samuti. Selguse huvides – pilt ühe andmebaasi suurusest pärast käitust:
Kuna see lahendus meie vajadustele täielikult vastas, siis ei hakanud me teist tõeks rakendama, kuid kaalume võimalust selle arendajatega arutada. Meie praegune täiendus, kahjuks, ei ole veel avaldamiseks valmis, kuna oleme lahendanud probleemi ainult unikaalsete edasilükatud piirangute osas, samas kui täiendava plaani jaoks on vajalik ka teiste tüüpide toe loomine. Loodame, et õnnestub see tulevikus saavutada.
Võib-olla tekkis teil küsimus, miks me üldse sellesse pg_repacki täiustamise loosse laskusime, mitte ei kasutanud selle analooge? Mõnes mõttes mõtlesime ka sellele, kuid meie varasem positiivne kogemus selle kasutamisel edasilükatud piiranguteta tabelites motiveeris meid proovima probleemi sisu mõista ja seda parandada. Lisaks võtab teiste lahenduste kasutusele võtmine samuti aega testimiseks, seetõttu otsustasime, et kõigepealt proovime probleemi selles lahenduses lahendada, ja kui mõistame, et ei suuda seda mõistliku ajaga teha, siis hakkame analooge kaaluma.
Järeldused
Mida me saame oma kogemuse põhjal soovitada:
- Jälgige oma bloat'i. Jälgimisandmete põhjal saate aru, kui hästi on autovacuum seadistatud.
- Seadistage AUTOVACUUM, et hoida bloat aktsepteeritaval tasemel.
- Kui bloat ikkagi kasvab ja te ei suuda sellega “väljakutsuvat” lahendustena toime tulla, ärge kartke kasutada väliseid laiendusi. Peamine on kõik korralikult testida.
- Ärge kartke kohandada väliseid lahendusi vastavalt oma vajadustele – mõnikord võib see olla efektiivsem ja isegi lihtsam kui oma koodi muutmine.
Allikas: habr.com
