

— väga võimas ja mugav mehhanism, kui seotud andmete kohta tehakse samu toiminguid "sügavale". Kuid kontrollimatu rekurssioon on paha, mis võib viia kas lõputu täitmiseni protsessi, või (mis juhtub sagedamini) kuni kogu saadaval mäluruumi "näljatamiseni"..

Andmebaasid töötavad selles osas samade põhimõtete kohaselt — "käsid kaevata, mina ka kaevan". Teie päring ei pruugi mitte ainult aeglustada naaberprotsesse, pidevalt kasutades protsessori ressursse, vaid võib ka "maha kukkuda" kogu andmebaas, "söödud" kogu saadaval mälu. Seetõttu kaitse lõputu rekursiooni eest on arendaja kohustus.
PostgreSQL-is tekkis võimalus kasutada rekursiivseid päringuid läbi juba ammuses versioonis 8.4, kuid siiani võib regulaarselt kohata potentsiaalselt haavatavaid "kaitsetuid" päringuid. Kuidas end sellistest probleemidest vabaks saada?
Ärge kirjutage rekursiivseid päringuid
Küll aga kirjutage rekursiivseid. Lugupidamisega, Teie K.O.
Tegelikult pakub PostgreSQL piisavalt palju funktsioone, millega saab ei rakendada rekursiooni.
Kasutage põhimõtteliselt teistsugust lähenemist ülesandele
Mõnikord saab ülesandele lihtsalt vaadata 'teise nurga alt'. Sellise olukorra näidet tõin ma artiklis — rea numbrite korrutamine ilma kasutaja määratud aggregeerimisfunktsioonide rakendamiseta:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY -- lõpp-tulemuse valik
i DESC
LIMIT 1;Sellist päringut saab asendada matemaatikagurude variandiga:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Kasutage generate_series asemel silmusid
Oletame, et meie ees on ülesanne genereerida kõik võimalikud prefiksid stringile 'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T; Kas siinkohal on tõepoolest vajalik rekursioon?.. Kui kasutada LATERAL ja generate_series, siis ei ole isegi CTE-d vajalikud:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Muuda andmebaasi struktuuri
Näiteks, teil on foorumi sõnumite tabel, kus on seosed, kes kellele vastas, või teema :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to); 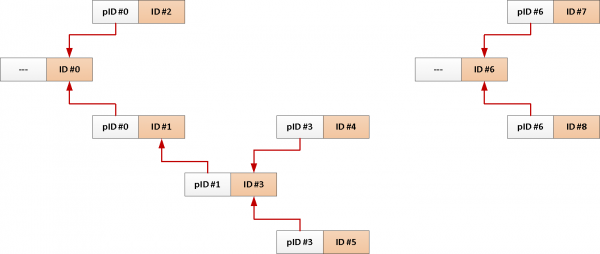
Ja tüüpiline päring, mis laadib kõiki sõnumeid ühe teema kaupa, näeb välja umbes selline:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Kuna meil on alati vaja kogu teemat juure sõnumist, miks siis mitte lisada selle identifikaator igasse kirjesse automaatsete vahenditega?
-- lisame välja ühise teema identifikaatoriga ja indeksi sellele
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
-- initialize teema identifikaatori triggeris sisestamisel
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id -- võtame algsest sündmusest
ELSE ( -- või sõnumist, millele vastame
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins(); 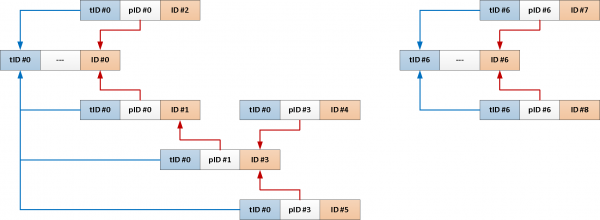
Nüüd saab kogu meie rekursiivne päring kokku tõmmata vaid selliseks:
SELECT
*
FROM
message
WHERE
theme_id = $1;Kasutada rakenduslikke "piire"
Kui me mingil põhjusel ei saa andmebaasi struktuuri muuta, vaatame, millele toetuda, et isegi andmetes oleva vea korral ei tekiks lõpmatu rekurss.
Rekursiooni 'sügavuse' loendur
Lihtsalt suurendame loendurit ühe võrra igal rekurssioni sammul kuni hetkeni, mil saavutame piiri, mida peame täiesti ebapiisavaks:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 -- piir
) Pro: Tsüklilisuse katsetamisel teeme me ikkagi mitte rohkem kui määratud iteratsioonide 'sügavuse' piiri.
Contra: Ei ole garantiid, et me ei töötle uuesti sama kirjet — näiteks sügavusel 15 ja 25, ning edasi iga +10 sügavuse kohta. Ja 'laiuse' kohta ei ole keegi midagi lubanud.
Formaalsetel alustel ei saa see rekurss olema lõpmatu, kuid kui igal sammul rekordite arv suurendab eksponentsiaalselt, teame kõik, kuidas see lõpeb...
Teekonna hoidja
Kirjutame järjestikku kõik kohtunud rekursiooni käigus objektide identifikaatorid massti, mis on ainulaadne 'tee' kuni sinna:
REKURSIOON T NAGU (
VALIGE
ARRAY[id] tee
...
ÜHENDAGE KÕIK
VALIGE
tee || id
...
KUS
id ALL(T.tee) -- ei ühti ühegi
) Pro: Kui andmetes on tsükkel, ei töötle me kindlasti sama kirjet ühe ja sama tee raames uuesti.
Contra: Kuid samas saame käia läbi, tõeliselt, kõik kirjed, nii et me ei korduks.
Teepikkuse piirang
Kuna vältida olukorda, kus rekursioon rändab arusaamatusse sügavusse, võime kahe eelneva meetodi kombineerida. Või, kui me ei soovi liialdavaid välju toetada, täiendada rekursiooni jätkamise tingimist teepikkuse hindamisega:
REKURSIOON T NAGU (
VALIGE
ARRAY[id] tee
...
ÜHENDAGE KÕIK
VALIGE
tee || id
...
KUS
id ALL(T.tee) JA
array_length(T.tee, 1) < 10
) Valige endale sobiv meetod!
Allikas: habr.com
