

Tegevuse iseloomust tulenevalt tuleb ette olukordi, kus arendaja kirjutab päringu ja mõtleb: "tabel on nutikas, ise lahendab kõik!"«
Mõnel juhul (osaliselt teadmatusest andmebaasi võimaluste suhtes, osaliselt enneaegsetest optimeerimistest) viib selline lähenemine "frankensteini" loomisele.
Alustuseks toon näite sellisest päringust:
-- iga võtme paari jaoks leidke seotud väärtused
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- leiame iga esimese võti jaoks min/max väärtused
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- seome esimese võtme põhjal võtme paarid ja min/max-väärtused
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Kvaliteedi objektiivseks hindamiseks loome mingisuguse meelevaldse andmestiku komplekti:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
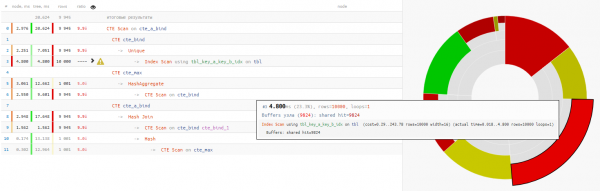
Selgub, et andmete lugemine võttis vähem kui veerand kogu päringu täitmise ajast: выполнения запроса:
Läbime põhjalikult
Vaata tähelepanelikult päringut ja mõtleme:
- Miks on siin WITH RECURSIVE, kui mingeid rekursiivseid CTE-sid pole?
- Miks gruppeerida min/max väärtused eraldi CTE-s, kui need hiljem ikkagi seotakse originaalvalikuga?
+25% aega - Miks kasutada lõpus korduvat lugemist eelmisest CTE-st tingimusteta ‘SELECT * FROM’ kaudu?
+14% aega
Selles olukorras vedas meid, et ühendamiseks valiti Hash Join, mitte Nested Loop, sest muidu oleksime saanud mitte ühe ainsa CTE skaneerimise, vaid 10K!
veidi CTE skaneerimisestSiin on oluline meeles pidada, et CTE skaneerimine on sama mis Seq Scan — see tähendab, et ei mingit indekseerimist, vaid ainult täielik otsimine, mis nõuaks 10K x 0.3ms = 3000ms cte_max tsüklite puhul või 1K x 1.5ms = 1500ms cte_bind tsüklite puhul!
Kuidas, aga mida soovisime lõpuks saada? Ah, tavaliselt tekib selline küsimus kuskil viienda minuti jooksul «kolmeastmeliste» päringute analüüsi käigus.
Soovisime iga unikaalse võtme paari jaoks välja tuua min/max rühmas key_a järgi.
Kasutame selleks :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 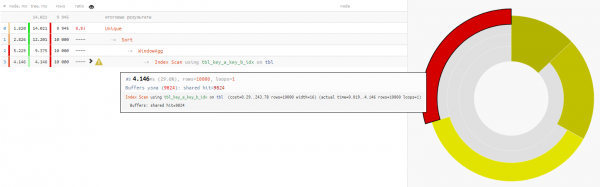
Kuna andmete lugemine mõlemas variandis kestab umbes 4-5 ms, on kogu meie ajavõit -32% — puhas koormus, mis on eemaldatud CPU põhilt, kui selline päring toimub piisavalt tihti.
Üldiselt ei tohiks anda andmebaasi ülesanne "ümmargune — kanda, nurgeline — veeretada".
Allikas: habr.com
