

Komplekssetes ERP-süsteemides on paljusid entiteete, millel on hierarhiline loomus., kui homogeensed objektid järjestatakse suhete «eelkäija — järeltulija» puusse. See hõlmab nii ettevõtte organisatsioonilist struktuuri (kõik need filiaalid, osakonnad ja töögrupid), tootekatalooge, tööalasid kui ka müügikohtade geograafiat,...
Tegelikult ei ole ühtegi , kus mingit hierarhiat ei oleks. Aga isegi kui te ei tööta „äri“ jaoks, võite siiski kergesti kokku puutuda hierarhiliste suhetega. Näiteks teie genealoogiline puu või korruste skeem kaubanduskeskuses — sama struktuur.
On palju viise sellise puu salvestamiseks andmebaasis, kuid täna peatume ainult ühel variandil:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid); -- ärge unustage, et FK ei eelda automaatset indeksi loomist, erinevalt PK-st.
Ja samal ajal, kui te uurite hierarhia sügavust, ootab see kannatlikult, kui efektiivsed osutuvad teie "naiivsed" töömeetodid sellise struktuuriga.

Vaadakem levinud tekkivaid ülesandeid, nende rakendamist SQL-is ja proovime parandada nende jõudlust.
#1. Насколько глубока кроличья нора?
Kuna me soovime selgust, oletame, et see struktuur peegeldab osakondade alluvust organisatsiooni struktuuris: osakonnad, divisjonid, sektorid, filiaalid, töörühmad… kuidas iganes neid nimetada.
Alustame meie 'puu' genereerimisega 10K elemendist
INSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;Alustame kõige lihtsama ülesandega — leidke kõik töötajad, kes töötavad konkreetses sektoris, või hierarhia mõistes — leida kõik sõlme järeltulijad. Ja oleks hea saada ka järglase "sügavust"... Kõik see võib olla vajalik näiteks mingi .
Kõik oleks hästi, kui neid järeltulijaid oleks seal vaid paar taset ja koguselt kümne ringis, kuid kui tasemeid on rohkem kui 5 ja järeltulijaid juba tosin, võivad probleemid tekkida. Vaatame, kuidas kirjutatakse (ja töötavad) traditsioonilised variandid otsinguks „puu allapoole“. Aga kõigepealt määratleme, millised sõlmed on meie uuringute jaoks kõige huvitavamad.
Kõige „sügavamad“ alampuud:
WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC; id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...Kõige „laiemad“ alampuud:
...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Nende päringute jaoks kasutasime tüüpilist rekursiivset JOIN:
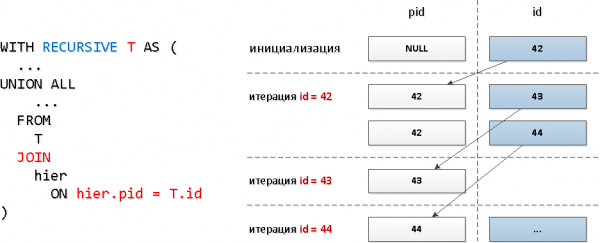
Ilmselt sellise päringumudeli korral iteratsioonide arv langeb kokku järeltulijate koguarvuga (nende leidub paar tosin), ja see võib nõuda märkimisväärseid ressursse ning seetõttu aega.
Kontrollime kõige „laiemas“ alampuus:
KUIDAS REKURSIOONILINE T NÄEB VÄLJA (
VALI
id
KUST
hier
KUS
id = 5300
UNION ALL
VALI
hier.id
KUST
T
LIITU
hier
ON hier.pid = T.id
)
TABLE T; 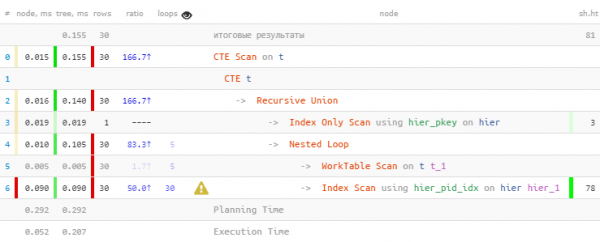
Nagu arvasime, leidsime kõik 30 kirjet. Kuid selleks kulus 60% kogu ajast — kuna tegime samal ajal ka 30 indeksi otsingut. Aga kas vähem on võimalik?
Massiline lugemine indeksi kaudu
Ja kas peame iga sõlme jaoks tegema eraldi päringu indeksi juurde? Selgub, et ei — me saame lugeda indekse samuti mitme võtme kaudu ühe päringu abil kasutades = ANY(array).
Ja igasse sellisesse identifikaatorite rühma saame panna kõik eelmisel sammul leitud ID-d "sõlmedes". See tähendab, et igal järgmisel sammul otsime kohe kõiki järglasi kindlast tasemest.
Ainult et, kahjuks, rekursiivse valiku korral ei saa viidata sellele ise enda sisse MGUTSIS päringus, kuid meil on vaja kuidagi eristada just need, mis leiti eelmisel tasemel... Selgub, et ei saa teha sisemist päringut kogu valiku kohta — aga konkreetse välja kohta saab küll. Ja see väli võib olla ka massiiv — just see ongi vajalik meie kasutamiseks. ANY.
Kostab veidi ulmeliselt, kuid diagrammil — kõik on lihtne.
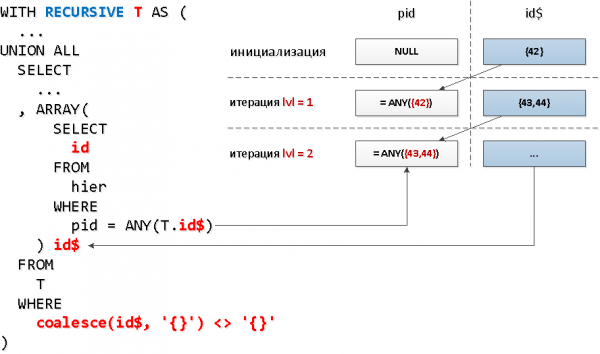
REKURSIOONIGA T KUI (
VALI
ARRAY[id] id$
KUST
id = 5300
ÜHENDUS KÕIK
VALI
ARRAY(
VALI
id
KUST
hier
KUS
pid = ANY(T.id$)
) id$
FROM
T
KUS
coalesce(id$, '{}') <> '{}' -- väljumise tingimus tsüklist - tühi massiiv
)
VALI
unnest(id$) id
FROM
T; 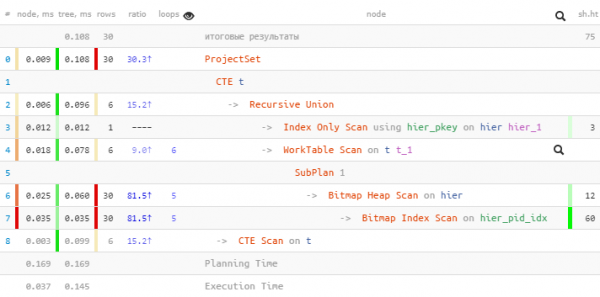
Ja siin on kõige olulisem mitte aegade 1.5-kordne võit, vaid see, et me lugesime vähem buffers, kuna indeksi kutsumisi on meil kokku 5, mitte 30!
Lisa boonuseks on see, et pärast lõplikku unnest jäävad identifikaatorid «taseme» järgi järjestatud.
Sõlme märgis
Järgmine aspekt, mis aitab parandada jõudlust — «lehtedel» ei saa olla lapsi, see tähendab, et nende jaoks ei ole vaja «alla» otsida üldse. Meie ülesande määratlemise kohaselt tähendab see, et kui oleme käinud osakondade ahelas ja jõudnud töötajani, siis ei pea me selle haru peale enam midagi otsima.
Viieme meie tabelisse täiendava boolean-välja, mis ütleb meile kohe, kas see konkreetne kirje meie puud on «sõlm» — see tähendab, kas tal võivad üldse olla järeltulijad.
ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
-- Päring on edukalt täidetud: 3033 rida muudeti 42 ms jooksul.Suurepärane! Selgub, et meil on vaid veidi üle 30% kõigist puu elementidest, millel on järglased.
Nüüd rakendame veidi teistsugust mehaanikat — ühendusi rekursiivse osa kaudu LATERAL, mis lubab meil otse pöörduda rekursiivse „tabeli“ väli poole, ning agregaatfunktsiooni filtritingimusega sõlme tunnuse alusel kasutame võtmete hulga vähendamiseks:
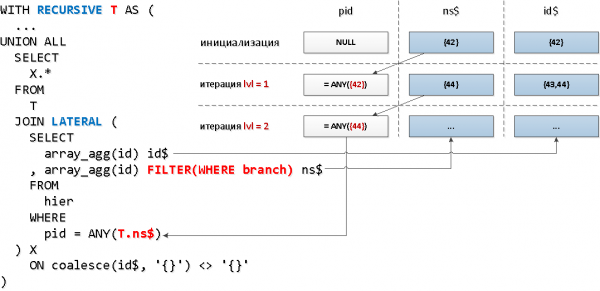
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T; 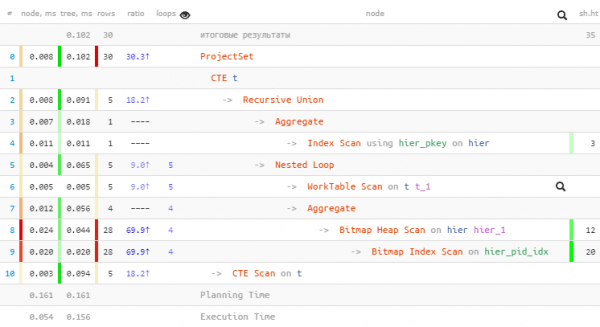
Suutsime vähendada veel üht pöördumist indeksi poole ja saime rohkem kui 2 korda mahus lugemiseks.
#2. Вернемся к корням
See algoritm on kasulik, kui peate koguma kirjeid kõigi „üles puu“ elementide jaoks, säilitades teavet selle kohta, millise algse lehe (ja milliste näitajatega) selle lisamine valikusse toimus — näiteks, töötlusaruande koostamiseks, mis sisaldab koondatud andmeid sõlmedel.
Edasi on mõistlik käsitleda ainult proof-of-concept'ina, kuna päring osutub liiga koormavaks. Kuid kui see domineerib teie andmebaasis — tasub kaaluda sarnaste meetodite rakendamist.
Alustame paarist lihtsast väitest:
- Ühte ja sama kirjet andmebaasist on parem lugeda ainult üks kord.
- Andmed andmebaasist on efektiivsem lugeda „pundina“, kui üksikult.
Nüüd proovime koostada meie vajadustele vastava päringu.
Samm 1
On ilmne, et rekursiooni algatamisel (kus see ikka ilma selleta!) tuleb meil lugeda lehtede enda kirjeid algsete identifikaatorite komplekti põhjal:
WITH RECURSIVE tree AS (
SELECT
rec -- see on terve tabeli kirje
, id::text chld -- see on "komplekt" algsetest lehtedest, mis siia tõid
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
... Kui kellelegi tundus kummaline, et 'kogum' on salvestatud stringina, mitte massiivina, siis sellel on lihtne selgitus. Stringide jaoks on olemas sisseehitatud agreggeeriv 'liitmis' funktsioon string_agg, aga massiivide jaoks ei ole. Kuigi selle .
Samm 2
Nüüd peame saama komplekti sektsioonide ID-dest, mida tuleb hiljem lugeda. Peaaegu alati dubleeruvad need erinevates algsete komplekti kirjetes — seetõttu peame need rühmitama, säilitades samas teabe allikate lehtede kohta.
Aga siin ootavad meid kolm ebameeldivust:
- 'Alurekursiivne' osa päringust ei tohi sisaldada agregaatfunktsioone koos
GROUP BY. - Juurdepääs rekursiivsele 'tabelile' ei saa olla sisemises alampäringus.
- Päring rekursiivses osas ei tohi sisaldada CTE-d.
Kuidas iganes, need probleemid on piisavalt kergesti ületatavad. Alustame lõpust.
CTE rekursiivses osas
Nii see ei töötleb:
WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)Ja nii — see töötab, sulud lahendavad!
WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)Sisemine päring rekursiivsele 'tabelile'
Hmm... Rekursiivne CTE ei saa olla sisemises päringus. Kuid see võib olla CTE sees! Ja sisemine päring võib sellele CTE-le viidata!
GROUP BY rekursiooni sees
Kahjuks... Meil on siiski lihtne viis, kuidas GROUP BY-d simuleerida kasutades DISTINCT ON ja aknafunktsioone!
SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1 -- ei tööta!Aga jällegi — see töötab!
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULLNäete nüüd, miks numbriline ID muutus tekstiks — et neid saaks kokku liita komaga!
Samm 3
Lõpuks jääb meil vähe teha:
- loeme «jaotiste» kirjed rühmitatud ID-de kogumi järgi
- seostame loetud jaotised «kogumitega» algsetest lehtedest
- «avatud» rida-kogum kasutades
unnest(string_to_array(chld, ',')::integer[])
REKURSIVE puu KUIDAS (
VALI
rec
, id::text chld
KUST
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
ÜHENDUS KÕIK
(
KUIDAS prnt KUIDAS (
Vali ERINEV ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
KUST
puu
KUST
(rec).pid EI OLE NULL
)
, sõlmed KUIDAS (
Vali
rec
KUST
hier rec
KUST
id = ANY(ARRAY(
Vali
id
KUST
prnt
))
)
Vali
sõlmed.rec
, prnt.chld
KUST
prnt
ÜHENDUS
sõlmed
ON (sõlmed.rec).id = prnt.id
)
)
Vali
unnest(string_to_array(chld, ',')::integer[]) leht
, (rec).*
KUST
puu; 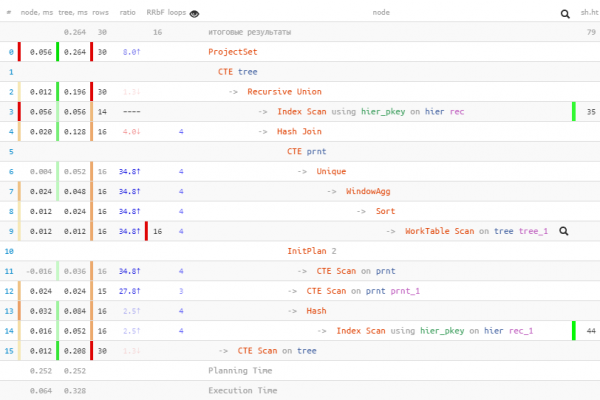
Allikas: habr.com
