

Aeg-ajalt tekib arendajal vajadus edastada päringusse hulk parameetreid või isegi kogu valik «sisse». Mõnikord kohtab väga kummalisi lahendusi selle probleemi jaoks.
Siit alustame «vastupidiselt» ja vaatame, kuidas ei peaks tegema, miks ja kuidas võiks paremini teha.
Otsene «sisestamine» väärtustest päringusse
Näeb tavaliselt välja umbes nii:
query = "SELECT * FROM tbl WHERE id = " + value… või nii:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Selle meetodi kohta on öeldud, kirjutatud ja küllalt:

Peaaegu alati on see — otsene tee SQL-i süstimistesse ja liigsele koormusele äriloogikas, mis peab „liimima“ teie päringu stringi.
Osaliselt võib selline lähenemine olla õigustatud ainult juhul, kui on vajalik partitsioneerimine PostgreSQL 10 ja varasemates versioonides efektiivsema plaani saamiseks. Nendes versioonides määratakse skaneeritavate partitsioonide nimekiri veel enne edastatavate parameetrite arvestamist, vaid ainult päringu keha põhjal.
$n-argumendid
Kasutamine parameetrid — see on hea, see võimaldab kasutada , vähendades koormust nii äriloogikale (päringu rida vormitakse ja edastatakse vaid kord) kui ka andmebaasi serverile (ei ole vajalik iga päringu esinemise jaoks uuesti analüüsida ja planeerida).
Muutuv argumentide arv
Probleemid ootavad meid, kui soovime edastada ettenägematult suurt hulka argumente:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Kui jätta päring selliseks, siis see kuigi kaitseb meid võimalike süstide eest, viib see siiski vajaduseni liita/analüüsida päringut iga variandi jaoks argumentide arvust. Juba parem kui iga kord nii teha, kuid saaksime ka ilma selleta hakkama.
Piisab, kui edastada vaid üks parameeter, mis sisaldab serialiseeritud massiivi esitust:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Ainus erinevus on vajadus selgelt muuta argument soovitud massiivi tüübiks. Kuid see ei tekita probleeme, kuna me teame eelnevalt, kuhu me suundume.
Valimise edastamine (maatriks)
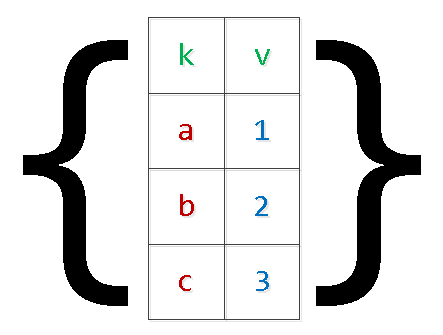
Tavaliselt on see erinevad variandid andmekogumite edastamiseks, et sisestada neid andmebaasi „ühe päringuga“:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Lisaks eespool kirjeldatud päringu "ümberkleebimise" probleemidele võib see meid viia ka mälupuudus ja serveri kukkumiseni. Põhjus on lihtne — PG reservib argumentide jaoks täiendavat mälu, samas kui kirjeid komplektis piirab ainult äritegevuse loogika nõudmised. Eriti äärmuslikes juhtumites on tulnud näha "numbrilisi" argumente, mis ületavad $9000 — nii ei tohi teha.
Kirjutame päringu uuesti, rakendades juba "kaheastmelist" serialiseerimist:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Jah, juhtudel, kus massi sees on "keerulisi" väärtusi, tuleb neid sulgudesse panna.
On selge, et sellisel viisil saab "laiendada" valikut suvalise arvu väljadega.
unnest, unnest, …
Aeg-ajalt on erandeid, kus "masside massi" asemel edastatakse mitu "veergude massi", millest ma rääkisin :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Sellise meetodi puhul, vale väärtuste loendite genereerimise korral erinevatele veergudele, on väga lihtne saada täiesti ootamatud tulemused, mis sõltuvad ka serveri versioonist:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
Alates versioonist 9.3 lisandus PostgreSQL-is täielikud funktsioonid JSON-tüübi töötlemiseks. Seega, kui sisendparameetrite määramine toimub brauseris, saate seal ka otse kujundada JSON-objekt SQL-päringuks:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Eelmiste versioonide puhul saab kasutada sama meetodit each(hstore), kuid keerukate objektide hstore'iga tõlgendamisel võivad tekkida probleemid.
json_populate_recordset
Kui te juba teadsite, et „sisend“ JSON-massiivist andmed lähevad mõne tabeli täitmiseks, siis saate vältida „dereferenseerimise“ ja vajalike tüüpide muutmisega palju säästa, kasutades funktsiooni json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
Ja see funktsioon lihtsalt "avab" edastatud objektide massiivi valikusse, toetumata tabeli formaadile:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2TEMPORARY TABLE
Kuid kui edastatavas andmevalimis andmete maht on väga suur, siis on keeruline või mõnikord võimatu panna seda ühte serialiseeritud parameetrisse, kuna see nõuab suurt mälu erakordset mälu. Näiteks peate pika aja jooksul koguma suurt andmepaketti välisest süsteemist ning siis soovite selle korraga andmebaasis töödelda.
Sel juhul on parim lahendus :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- korrata palju-muid kordi
...
-- siin teeme midagi kasulikku kogu selle tabeliga
See meetod sobib hästi harvade suurte andmeedastuste jaoks. andmete.
Andmestruktuuri kirjeldamise osas erineb ajutine tabel "tavalisest" ainult ühe tunnuse poolest süsteemitabelis pg_class, ja seejärel määratleme selle, takistades seeläbi kasutajal selgelt selle väljaid muuta. See on üks andmete peitmise mustritest pg_type, pg_depend, pg_attribute, pg_attrdef, … — ning ei erine muust.
Seetõttu tekitab veebisüsteemides, kus on palju lühiajalisi ühendusi, igaühe jaoks selline tabel uusi süsteemikirjeid iga kord, mis kustutatakse andmebaasiühenduse sulgemisel. Lõppkokkuvõttes, kontrollimatute TEMP TABLE'i kasutamine toob kaasa tabelite "paisumise" pg_catalogis ja aeglustab mitmeid operatsioone, mis neid kasutavad.
Muidugi, selle vastu saab võidelda süsteemikatalooge tüübid VACUUM FULLi perioodilise läbimisega üle.
Seansi muutujad
Oletame, et eelneva juhtumi andmetöötlus on piisavalt keeruline, et seda ühe SQL päringuga teha, kuid soovime seda piisavalt tihti kasutada. Seega soovime kasutada protseduurilist töötlemist , kuid andmete edastamine ajutiste tabelite kaudu oleks liiga kallis.
$n-parameetrite kasutamine andmete edastamiseks anonüümsesse plokki ei õnnestu samuti. Seansi muutujad ja funktsioon current_setting.
Pe Before version 9.2, it was necessary to configure in advance a special namespace oma seansimuutujate jaoks. Käesolevatel versioonidel saab kirjutada enam-vähem nii: SET my.val = '{1,2,3}'; DO $$ DECLARE id integer; BEGIN FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP RAISE NOTICE 'id : %', id; END LOOP; END; $$ LANGUAGE plpgsql; -- NOTICE: id : 1 -- NOTICE: id : 2 -- NOTICE: id : 3
Teistes toetatud protseduurilistes keeltes võib leida ka muid lahendusi.Teistel toetatud protseduuriliselt keeltes võib leida ka muid lahendusi.
Kas tead veel viise? Jagage kommentaarides!
Allikas: habr.com
