

Продолжаем серию статей, посвященных исследованию малоизвестных способов улучшения производительности «вроде бы простых» запросов на PostgreSQL:
Не подумайте, что я так сильно не люблю JOIN… 🙂
Но зачастую без него запрос получается ощутимо производительнее, чем с ним. Поэтому сегодня попробуем вообще избавиться от ресурсоемкого JOIN — с помощью словаря.

Начиная с PostgreSQL 12 часть описанных ниже ситуаций может воспроизводиться чуть иначе из-за . Это поведение может быть возвращено к прежнему с помощью указания ключа
MATERIALIZED.
Много «фактов» по ограниченному словарю
Давайте возьмем вполне реальную прикладную задачу — надо вывести список или активных задач с отправителями:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
В абстрактном мире авторы задач должны были бы равномерно распределяться среди всех сотрудников нашей организации, но в реальности задачи приходят, как правило, от достаточно ограниченного количества людей — «от начальства» вверх по иерархии или «от смежников» из соседних отделов (аналитики, дизайнеры, маркетинг, …).
Давайте примем, что в нашей организации из 1000 человек только 20 авторов (обычно даже меньше) ставят задачи в адрес каждого конкретного исполнителя и , чтобы ускорить «традиционный» запрос.
Скрипт-генератор
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
Покажем последние 100 задач для конкретного исполнителя:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 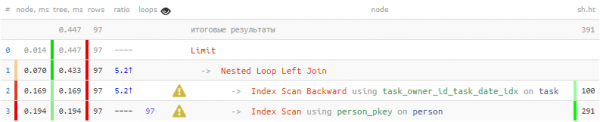
Selgub, et 1/3 всего времени и 3/4 чтений страниц данных были сделаны только для того, чтобы 100 раз поискать автора — для каждой выводимой задачи. Но мы же знаем, что среди этой сотни всего 20 разных — нельзя ли использовать это знание?
hstore-словарь
Kasutame seda для генерации «словаря» ключ-значение:
CREATE EXTENSION hstoreВ словарь нам достаточно поместить ID автора и его имя, чтобы потом иметь возможность извлечь по этому ключу:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 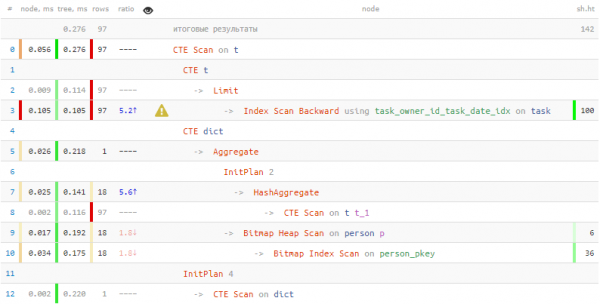
На получение информации о персонах затрачено в 2 раза меньше времени и в 7 раз меньше прочитано данных! Помимо «ословаривания», этих результатов нам помогло достичь еще и массовое извлечение записей из таблицы за единственный проход с помощью = ANY(ARRAY(...)).
Записи таблицы: сериализация и десериализация
Но что делать, если нам нужно сохранить в словаре не одно текстовое поле, а целую запись? В этом случае нам поможет способность PostgreSQL работать с записью таблицы как с единым значением:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;Давайте разберем, что тут вообще происходило:
- Мы взяли p как алиас к полной записи таблицы person и собрали из них массив.
- Этот массив записей перекастовали в массив текстовых строк (person[]::text[]), чтобы поместить его в hstore-словарь в качестве массива значений.
- При получении связанной записи мы ее вытащили из словаря по ключу как текстовую строку.
- Текст нам нужно превратить в значение типа таблицы person (для каждой таблицы автоматически создается одноименный ей тип).
- «Развернули» типизованную запись в столбцы с помощью
(...).*.
json-словарь
Но такой фокус, как мы применили выше, не пройдет, если нет соответствующего табличного типа, чтобы сделать «раскастовку». Ровно такая же ситуация возникнет, и если в качестве источника данных для сериализации мы попробуем использовать строку CTE, а не «реальной» таблицы.
В этом случае нам помогут :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; Надо отметить, что при описании целевой структуры мы можем перечислять не все поля исходной строки, а только те, которые нам действительно нужны. Если же у нас есть «родная» таблица, то лучше воспользоваться функцией json_populate_record.
Доступ к словарю у нас происходит по-прежнему однократно, но издержки на json-[де]сериализацию достаточно велики, поэтому таким способом разумно пользоваться только в некоторых случаях, когда «честный» CTE Scan показывает себя хуже.
Тестируем производительность
Итак, мы получили два способа сериализации данных в словарь — hstore / json_object. Помимо этого, сами массивы ключей и значений можно породить тоже двумя способами, с внутренним или внешним преобразованием к тексту: array_agg(i::text) / array_agg(i)::text[].
Проверим эффективность разных видов сериализации на сугубо синтетическом примере — сериализуем разное количество ключей:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;Оценочный скрипт : сериализация
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 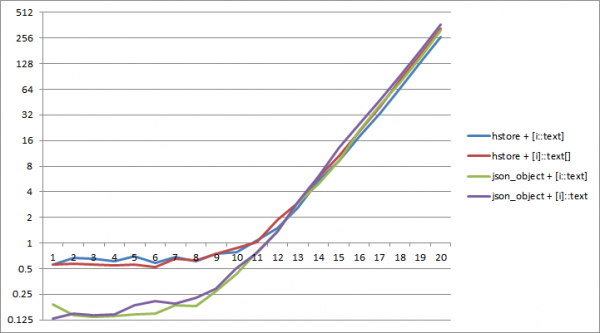
На PostgreSQL 11 примерно до размера словаря в 2^12 ключей сериализация в json требует меньше времени. При этом наиболее эффективной является комбинация json_object и «внутреннего» преобразования типов array_agg(i::text).
Теперь давайте попробуем прочитать значение каждого ключа по 8 раз — ведь если к словарю не обращаться, то зачем он нужен?
Оценочный скрипт : чтение из словаря
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 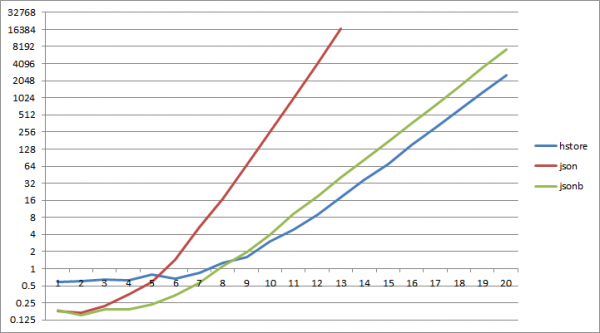
И… уже примерно при 2^6 ключей чтение из json-словаря начинает кратно проигрывать чтению из hstore, для jsonb то же самое происходит при 2^9.
Итоговые выводы:
- если надо сделать JOIN с многократно повторяющимися записями — лучше использовать «ословаривание» таблицы
- если ваш словарь ожидаемо маленький и читать вы из него будете немного — можно использовать json[b]
- во всех остальных случаях hstore + array_agg(i::text) будет эффективнее
Allikas: habr.com
