

Kartke operatsioone, mis toovad kaasa buffers...
Vaatame väikese päringu näitel mõningaid universaalseid lähenemisviise, kuidas PostgreSQL päringute optimeerimiseks läheneda. Kas neid kasutada või mitte — otsustada on teil, kuid neist teadlik olemine on oluline.
Mõnes järgnevas PG versioonis võib olukord muutuda 'intelligentse' plaanijaga, kuid versioonides 9.4/9.6 näeb see välja enam-vähem sama, nagu siin näidatud.
VÕTAN täiesti reaalse päringu:
SELECT
TRUE
FROM
"Dokument" d
INNER JOIN
"DokumentРасширение" doc_ex
USING("@Dokument")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 OR d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1; tabelite ja väli nimedestK 'vene' tabeli ja väljade nimede suhtes võib suhtuda erinevalt, kuid see on maits küsimus. Kuna ei ole välismaalaste arendajaid, ja PostgreSQL võimaldab meil nime anda isegi hieroglüüfidega, kui need on jutumärkides, siis eelistame nimetada objekte üheselt mõistetavalt, et vältida tõlgenduste erinevusi.
Vaatame saadud plaani:
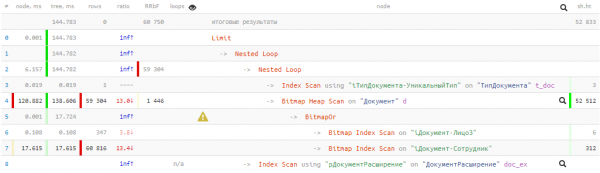
144ms ja pea 53K buffers — see, over 400MB of data! And we'll be lucky if all of them are in cache by the time our request comes, otherwise, it will take significantly longer while reading from disk.
The algorithm is the most important!
To optimize any request, we first need to understand what it is supposed to do.
For now, let's leave the development of the database structure out of this article, and agree that we can relatively 'cheaply' rewrite the request and/or apply some necessary indexes.
So, the request:
— checks for the existence of at least some document
— in the required state of ours and of a certain type
— where the author or executor is the employee we need
JOIN + LIMIT 1
Often, it’s easier for the developer to write a request that first joins a large number of tables, and then from all of this, only one record remains. But easier for the developer doesn't mean more efficient for the database.
In our case, there were only 3 tables — and what an effect…
Let's start by eliminating the join with the 'DocumentType' table, while also informing the database that our record type is unique. (me teame seda, aga planeerija ei kahtlegi):
WITH T AS (
SELECT
"@DokumendiTüüp"
FROM
"DokumendiTüüp"
WHERE
"DokumendiTüüp" = 'TöötlemisePlaan'
LIMIT 1
)
...
WHERE
d."DokumendiTüüp" = (TABLE T)
...Jah, kui tabel/CTE koosneb ainsast väljast ainsast kirjast, siis PG-s võib isegi nii kirjutada, selle asemel
d."DokumendiTüüp" = (SELECT "@DokumendiTüüp" FROM T LIMIT 1)„Laiskad” arvutused PostgreSQL päringutes
BitmapOr vs ÜHEND
Mõnedel juhtudel võib Bitmap Heap Scan meile väga kalliks minna — näiteks meie olukorras, kus piisavalt palju kirjeid vastab vajalikule tingimusele. Saime selle OR-tingimusest, mis muutus BitmapOr-operatsiooniks plaanis.
Naaseme algse ülesande juurde — peame leidma kirje, mis vastab igal tingimusest — see tähendab, et pole vaja otsida kõiki 59K kirjeid mõlema tingimuse järgi. On olemas viis, kuidas töötada välja üks tingimus ja teisele üle minna ainult siis, kui esimesest ei leitud midagi. Aitame end sellise konstruktsiooniga:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1«Väline» LIMIT 1 tagab, et otsing lõppeb esimese kirje leidmisel. Ja kui see leitakse juba esimeses plokis, siis teist ei täideta (ei täideta plaanis).
«Peidame CASE'i alla» keerulised tingimused
Algse päringu juures on äärmiselt ebamugav hetk — seisundi kontroll seondunud tabelis „DokumentLisa“. Ükskõik kui õiged on muud tingimused väljendis (näiteks, d.«Kustutatud» EI OLE TÕENE), toimub see ühendamine alati ja „kulutab ressursse“. Rohkem või vähem neid kulutatakse — sõltub selle tabeli mahust.
Kuid päringut saab muuta nii, et seotud kirje otsing toimub ainult siis, kui see on tõeliselt vajalik:
SELECT
...
FROM
"Dokument" d
WHERE
... /*indeksi tingimus*/ AND
CASE
WHEN "$Kavand" IS NULL AND "Kustutatud" IS NOT TRUE THEN (
SELECT
"Seisund"[1] IS TRUE
FROM
"DokumentLisa"
WHERE
"@Dokument" = d."@Dokument"
)
END Kuna seondumises tabelis meile ei ole tulemusteks vaja ühtegi väljad, siis on meil võimalus muuta JOIN tingimuseks alampäring.
Jätame indekseeritavad väljad CASE'i „välja”, lihtsad tingimused toome WHEN-plokki — ja nüüd käivitatakse „raske” päring vaid THEN-i üleminekul.
Minu perekonnanimi on „Kokku”
Kogume tulemuse päringu kõik eespool kirjeldatud mehhanismidega:
WITH T AS (
SELECT
"@DokumendiTüüp"
FROM
"DokumendiTüüp"
WHERE
"DokumendiTüüp" = 'Tööplaan'
)
(
SELECT
TRUE
FROM
"Dokument" d
WHERE
("Isik3", "DokumendiTüüp") = (19091, (TABLE T)) AND
CASE
WHEN "$Mustand" IS NULL AND "Kustutatud" IS NOT TRUE THEN (
SELECT
"Olek"[1] IS TRUE
FROM
"DokumendiLisa"
WHERE
"@Dokument" = d."@Dokument"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Dokument" d
WHERE
("DokumendiTüüp", "Töötaja") = ((TABLE T), 19091) AND
CASE
WHEN "$Mustand" IS NULL AND "Kustutatud" IS NOT TRUE THEN (
SELECT
"Olek"[1] IS TRUE
FROM
"DokumendiLisa"
WHERE
"@Dokument" = d."@Dokument"
)
END
LIMIT 1
)
LIMIT 1;Kohandame [alla] indekseid
Kogenud silm märkas, et indekseeritavad tingimused UNION alablokkides veidi erinevad — see on seepärast, et meil on tabelis juba sobivad indekseid. Ja kui neid ei oleks, siis oleks olnud mõistlik luua: Dokument(Moodus3, DokumendiTüüp) ja Dokument(DokumendiTüüp, Töötaja).
väljade järjekorrast ROW-tingimustesPlaneerija vaatenurgast on võimalik ka kirjutada (A, B) = (constA, constB), ja (B, A) = (constB, constA). Kuid kirjutamisel väljade järjekorras indeksis, selline päring on pärast lihtsam debikeerida.
Mis plaanis on?
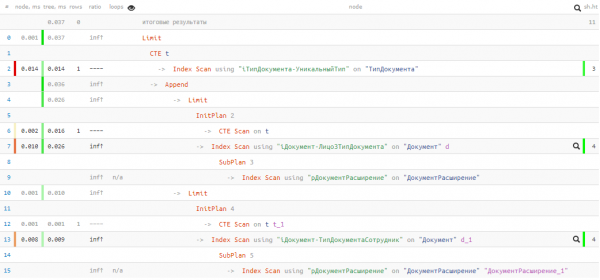
Kahjuks ei tulnud esimeses UNION-plokis midagi välja, seega teine siiski läks täitmisele. Kuid isegi sel juhul — kokku 0.037ms ja 11 pufferit!
Oleme kiirendanud päringut ja vähendanud andmete „tõukamist” mälus mõne tuhande korra, kasutades piisavalt lihtsaid meetodeid — päris hea tulemus väikese kopeerimise puhul. 🙂
Allikas: habr.com
