

Olen valmis tutvustama Nikolai Samohvalovi ettekande "Tööstuslik lähenemine PostgreSQL tuunimisele: katsetused andmebaasidega" kokkuvõtet.
Shared_buffers = 25% – kas see on palju või vähe? Või just paras? Kuidas mõista, kas see – pigem vananenud – soovitus sobib teie konkreetsesse olukorda?
Nüüd on aeg läheneda postgresql.conf parameetrite seadmiseks "täiskasvanulikult". Mitte pime "autotuunimine" või vanad soovitused artikkelidest ja blogidest, vaid põhinevalt:
- rangelt mõõdetud katsetele andmebaasidel, teostatud automatiseeritult, suuremahulistes kogustes ja tingimustes, mis on võimalikult lähedased "lahinguoludele",
- sügavale arusaamale andmebaasisüsteemi ja operatsioonisüsteemi töö eripäradest.
Kasutades Nancy CLI (), vaatleme konkreetset näidet – sõdavargad shared_buffers – erinevates olukordades, erinevates projektides ja püüame välja selgitada, kuidas leida meie infrastruktuuri, andmebaasi ja koormuse jaoks optimaalne seadistus.

Räägime katsetustest andmebaasidega. See on lugu, mis on kestnud üle kuue kuu.

Natuke minust. Kogemus postgresega on juba üle 14 aasta. Olen loonud mitmeid sotsiaalvõrgustikku kuuluvaid ettevõtteid. Igas neist on kasutatud ja kasutatakse postgressi.
Samuti on RuPostgres grupp Meetup'is, saavutades 2. koha maailmas. Jõuame aeglaselt 2000 inimeseni. RuPostgres.org.
Ja erinevate konverentside ПК, sealhulgas Highload, vastutan andmebaaside eest, eelkõige Postgresi eest alates selle loomisest.

Viimastel aastatel olen taas alustanud oma Postgresi konsultatsiooni praktikat 11 ajavööndis siit.

Ja kui ma seda paar aastat tagasi tegin, olin ma teinud natuke pausi aktiivsest käsitsi töö tegemisest Postgresiga, ilmselt alates 2010. aastast. Olin üllatunud, kui vähe on DBA tööde igapäevaselt muutunud, kui palju käsitsi ütlemist on endiselt vajalik. Ja ma mõtlesin kohe, et siit on midagi valesti, vajame rohkem automatiseerimist.
Kuna kõik toimus eemal, olid enamik kliente pilvemaailmas. Ja palju on juba silmaga nähtavalt automatiseeritud. Sellest räägin veidi hiljem. T. e. kõik see tõi mind ideeni, et peaks olema rida tööriistu, st mitte mingi platvorm, mis automatiseerib praktiliselt kõik DBA tegevused, et saaks hallata suurt hulka andmebaase.

Selles ettekandes ei tule olema:
- „Hõbedasi kuulikesi“ ja väiteid nagu – seadke 8 GB või 25 % shared_buffers, ja kõik on hästi. Shared_buffersist ei tule palju juttu.
- Hulku "sügavamaid kihte".

Mis juhtub?
- On olemas optimeerimisprintsiibid, mida me rakendame ja arendame. Olemas on ideed, mis meie teel tekkivad, ja erinevad tööriistad, mille me enamikul juhtudel loome avatud allika (Open Source) põhimõtetel. Lisaks sellele on meie pileti süsteem ja praktiliselt kogu suhtlus avatud allikas. Saate jälgida, mida me praegu teeme, milline on järgmine versioon jne.
- Samuti jagame kogemusi nende printsiipide ja tööriistade kasutamisest erinevates ettevõtetes: alates väikestest idufirmadest kuni suurte organisatsioonideni.

Kuidas see kõik areneb?

Esiteks, DBA peamine ülesanne, peale instantside loomise ja varukoopiate haldamise, on kitsaskohade otsimine ja jõudluse optimeerimine.
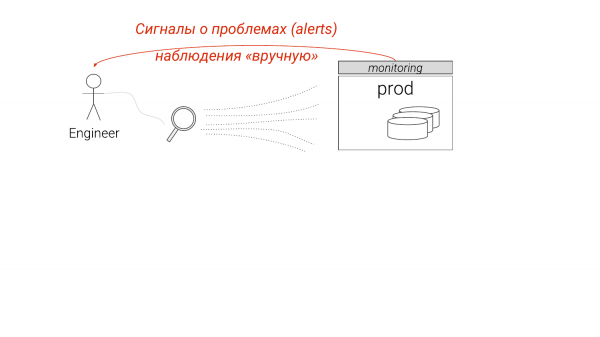
Praegu näeb see välja nii. Me jälgime statistikat, näeme teatud asju, kuid meil puuduvad mõned detailid. Alustame süvitsi uurimist, tavaliselt käsitsi, ja mõistame, mida sellega edasi teha.
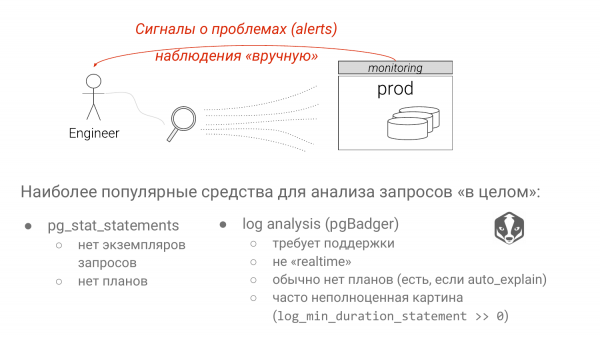
Ja on kaks lähenemist. Pg_stat_statements – standardlahendus aeglaste päringute tuvastamiseks. Ja Postgresse logide analüüs pgBadgeri abil.
Igal lähenemisel on tõsised puudused. Esimese lähenemisega viskame välja kõik parameetrid. Ja kui me näeme gruppe SELECT * FROM table where veerg on võrdne märgiga «?» või «$» alates Postgres 10 versioonist. Me ei tea, kas tegemist on index scan'i või seq scan'iga. See sõltub suuresti parameetrist. Kui sisestataks harva esinev väärtus, toimub index scan. Kui sisestataks väärtus, mis hõlmab 90% tabelist, toimub ilmselt seq scan, sest Postgres teab statistikat. See on suur puudus pg_stat_statements, kuigi mingid tööd on käimas.
Logianalüüsides on peamine puudus see, et te ei saa endale lubada «log_min_duration_statement = 0», nagu tavaliselt. Ja sellest räägime ka. Seega ei näe te kogu pilti. Ja mingi päring, mis on väga kiire, võib tarbida tohutult ressursse, kuid te ei näe seda, sest see jääb teie lävendist madalamale.
Kuidas DBA-d lahendavad leitud probleeme?
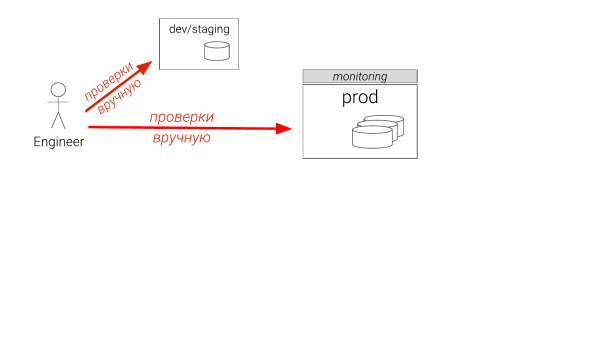
Näiteks leidsime mingi probleemi. Mida tavaliselt tehakse? Kui olete arendaja, siis teete midagi mõnes instance'is, mis ei ole sellise suurusega. Kui olete DBA, siis on teil staging. Ja see võib olla ainult üks. Ja see on olnud pool aastat maas. Ja te mõtleksite, et lähete productioni. Ja isegi kogenud DBA-d kontrollivad hiljem productionis, koopia peal. Ja juhtuvad juhtumid, kus luuakse ajutine indeks, veendutakse, et see aitab, kustutatakse see ja antakse arendajatele, et nad saaksid selle migreerimisfailidesse lisada. Nii et selline jama toimub praegu. Ja see on probleem.
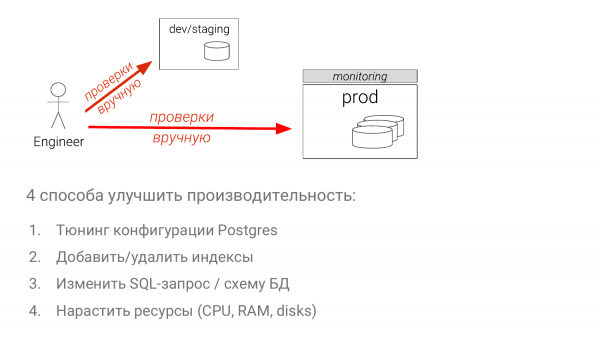
- Konfigureerimist timmida.
- Indeksite kogumit optimeerida.
- Muutke SQL-päringut (see on kõige keerulisem meetod).
- Lisage ressursse (keb kõige lihtsam meetod enamikul juhtudel).

Nende asjadega on palju. Postgresis on palju nuppe. Tuleb palju teada. Postgresis on palju indekseid, tänu ka sellele konverentsi korraldajatele. Ja kõike seda tuleb teada, ja just see tekitab mitte DBA-de seas tunde, et DBA-d tegelevad musta maagia ja asjadega. See tähendab, et tuleb umbes 10 aastat tegeleda, et hakata seda tõeliselt mõistma.
Ja olen selle musta maagia vastu. Soovin, et kõik oleks tehnoloogial, mitte intuitsioonil.
Elulised näited

Olen seda näinud vähemalt kahes projektis, sealhulgas oma omas. Järjekordne blogipostitus ütleb meile, et väärtus 1 000 default_statistict_target jaoks on hea. Hea, proovime seda tootmises.

Ja nüüd, kasutades oma tööriista kaks aastat hiljem ning tehes katseid andmebaasidega, millest täna räägime, saame võrrelda, mis oli ja mis on muutunud.
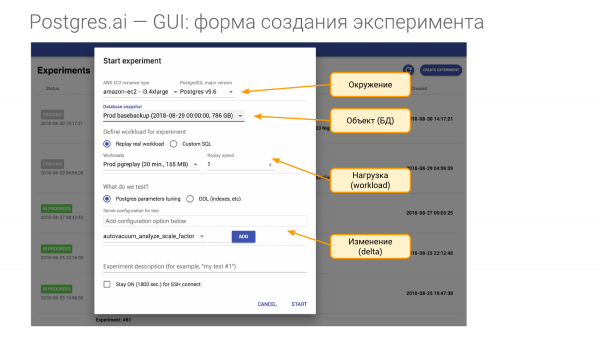
Ja selleks peame looma eksperimendi. See koosneb neljast osast.
- Esimene on keskkond. Meil on vaja riistvara. Ja kui ma tulen mõnda ettevõttesse ja sõlmime lepingu, siis ütlen, et nad annaksid mulle sama riistvara nagu tootmises. Iga teie Meister jaoks vajame vähemalt ühte sellist riistvara. Olgu see virtuaalne masin Amazonis või Google’is, või mul on just selline riistvara vajalik. Tõepoolest, soovin keskkonda taastada. Keskkonna mõistesse kuulub ka Postgressi põhiversioon.
- Teine osa on meie teadusuuringute objekt. See on andmebaas. Selle saab luua mitmel viisil. Näitan, kuidas.
- Kolmas osa on koormus. See on kõige keerulisem hetk.
- Ja neljas osa on see, mida me kontrollime, st millega me võrreldes töötame. Oletame, et saame konfiguratsioonis muuta ühte või mitut parameetrit, või saame luua indeksi jne.
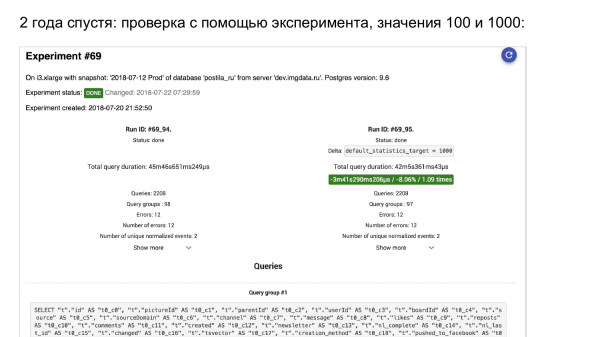
Me alustame eksperimenti. Siin on pg_stat_statements. Vasakul on see, mis oli. Paremal on see, mis on nüüd.
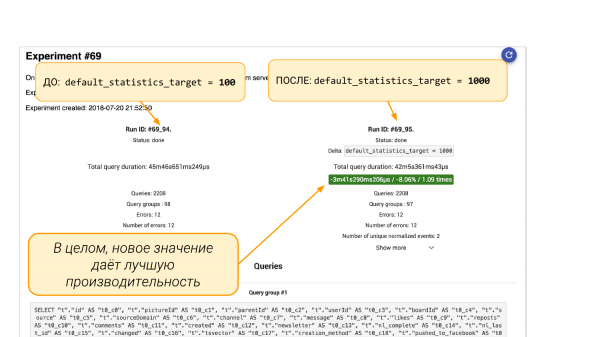
Vasakul default_statistics_target = 100, paremal = 1 000. Me näeme, et see aitas meid. Üldiselt on kõik 8 % paremaks muutunud.
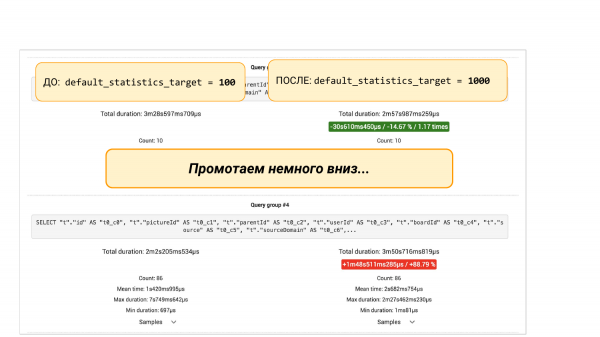
Kuid kui me scrollime allapoole, siis seal on pgBadger või pg_stat_statements-i päringugrupid. Siin on kaks varianti. Me näeme, et mõni päring on langenud 88 %. Ja siin tuleb inseneri lähenemine. Saame sügavamale kaevuda, sest on huvitav, miks see langes. Tuleb mõista, mis statistika oli. Miks suuremad buketid statistikas toovad halvemad tulemused.
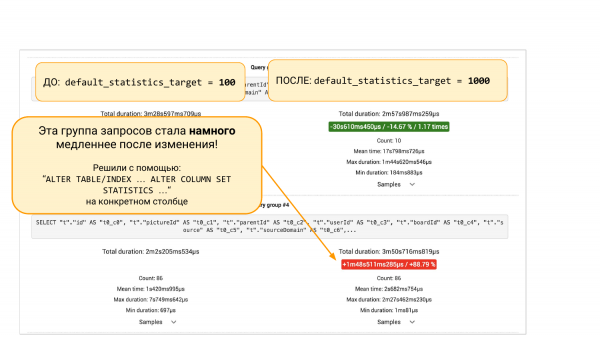
Või me ei kaevu, vaid teeme 'ALTER TABLE … ALTER COLUMN' ja toome tagasi 100 buketti selle veeru statistikas. Ja edasi saame veel eksperimendi käigus veenduda, et see lahendus aitas. Kõik. See on inseneri lähenemine, mis aitab meil näha pilti ja teha otsuseid andmete, mitte intuitsiooni põhjal.


Mõned näited teistest valdkondadest. Testides on CI-testid olnud juba aastaid. Ükski projekt ei suuda enam mõistlikult eksisteerida ilma automaatsete testideta.
Teistes tööstusharudes: lennunduses, autotööstuses, kui testime aerodünaamikat, on meil ka võimalus eksperimente teha. Me ei hakka kohe jooniste järgi midagi kosmosesse saatma ega tooma autot kohe teele. Näiteks on olemas aerodünaamiline tunnel.
Teiste valdkondade vaatluste põhjal saame teha järeldusi.

Esiteks, meil on spetsiaalne keskkond. See on tootmisprotsessile lähedane, kuid mitte täiesti sama. Selle peamine omadus on, et see peaks olema odav, korduv ja võimalikult automatiseeritud. Lisaks peavad olema erivahendid detailseks analüüsiks.
Tõenäoliselt, kui me lennuki käivitame ja lendame, on meil vähem võimalusi uurida iga millimeetrit tiiva pinnast kui aerodünaamilises tunnelis. Meil on rohkem vahendeid diagnostikaks. Saame endale lubada rohkem kõike rasket, mida me ei saa lennuki õhus olles kaasas kanda. Sama kehtib ka Postgresi puhul. Me saame mõnes olukorras katsetuse käigus aktiveerida otsese päringute logimise. Ja me ei soovi seda tootmises teha. Võib-olla aktiveerime selle plaanide puhul auto_explaini kaudu.
Ja nagu ma juba ütlesin, kõrge automatiseerituse tase tähendab, et me vajutasime nuppu ja kordasime. Nii peab see olema, et katsetusi oleks palju ja et see oleks pidev protsess.
Nancy CLI – andmebaasikatsetuste alussamm.

Ja nii me sellise asja tegime. T. e. ma rääkisin nendest ideedest juunis, peaaegu aasta tagasi. Ja meil on juba Open Source'is nii nimetatud Nancy CLI. See on alus andmebaasalaste laborite ehitamiseks.
- See on Open Source'is, Gitlabis. Võite vaadata, võite proovida. Olen slaidides lingi jätnud. Saate sellele klikkida ja seal ongi. kõigi parameetrite kohta.
Muidugi, seal on veel palju arendustööd. Ideid on palju. Kuid see, mida me juba praktiliselt igapäevaselt kasutame, on juba olemas. Ja kui meil tekib mõte – mis juhtub, kui kustutame 40 000 000 rida, kui kõik takerdub IO-sse, siis saame katsetada ja vaadata lähemalt, et mõista, mis toimub, ning seejärel proovida seda jooksvalt parandada. Ehk teeme katse. Näiteks kohandame midagi ja vaatame, mis lõpptulemus on. Ja seda me teeme mitte produktsioonis. See on idee sisu.
Kus see võiks töötada? See võib töötada kohalikult, st seda saab teha kuskil, isegi MacBookil. Vajalik on Docker, lähme. Ja kõik. Saame käivitada mingisuguses instance'is riistvara peal või virtuaalkeskkonnas, kus iganes.
Ja on ka võimalus kaugjuhtida Amazonis EC2 instantsul, spottides. See on väga hea võimalus. Näiteks tegime eile rohkem kui 500 katset i3 instantsil, alustades kõige väiksemast ja lõpetades i3-16-xlarge'iga. Ja need 500 katset maksid meile 64 dollarit. Igaühe kestus oli 15 minutit. Seega, tänu sellele, et kasutatakse spotte, on see väga odav – 70% allahindlus, Amazon peab tasu sekundite kaupa. Saate teha palju. Saate teha tõelist uurimistööd.
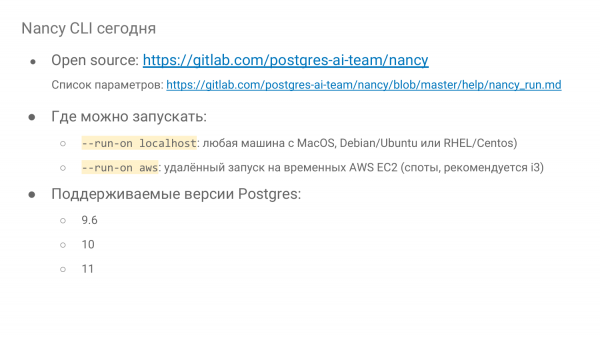
Ja kolm peamist Postgresi versiooni on toetatud. Pole nii keeruline viia ellu mõnda vana ja ka uut 12. versiooni.

Objekti saame määrata kolme viisi. Need on:
- Dump/sql-fail.
- Peamine viis on PGDATA katalooge kloonida. Üldjuhul võetakse see varundusserverist. Kui teil on normaalsed binaarsed varukoopiad, saate sealt kloone teha. Kui teil on pilveteenused, siis hoolitseb selle eest teie eest pilveteenus nagu Amazon ja Google. See on kõige olulisem viis tõelise tootmisprotsessi kloonide jaoks. Me just selle meetodi kaudu käivitame.
- Ja viimane meetod sobib teaduslikeks uuringuteks, kui on soov aru saada, kuidas Postgres mingit funktsiooni töötab. See on pgbench. Sa saad genereerida pgbenchiga. See on lihtsalt üks valik «db-pgbench». Sa ütled, milline on skaala. Ja kõik genereeritakse pilves, nagu on öeldud.

Ja koormus:
- Koormust saame täita ühes SQL voos. See on kõige primitiivsem meetod.
- Või võime koormust emuleerida. Ja me saame emuleerida seda eelkõige järgmiselt. Me peame koguma kõik logid. Ja see on valus. Ma näitan, miks. Ja pgreplay abil, mis on integreeritud Nancy'sse, esitame need.
- Või teine variant. Nii öeldud käsitöökoormus, mida me teeme teatud pingutusega. Analüüsides meie praegust koormust tootmissüsteemis, tõmbame välja kõige olulisemad päringugrupid. Ja pgbench abil saame emuleerida seda koormust laboris.

- Või peame täitma mõne SQL päringu, st kontrollime mingit migratsiooni, loome indeksi, teeme ANALYZE. Ja vaatame, mis oli enne ja pärast vaakumit. Ühesõnaga, ükskõik milline SQL.
- Või muudame konfiguratsioonis ühte või mitut parameetrit. Saame paluda, et kontrollitaks näiteks 100 väärtust Amazonis meie terabaidi andmebaasi jaoks. Ja mõne tunni pärast on teil tulemus. Tüüpiliselt kulub terabaidi andmebaasi käivitamiseks mitmeid tunde. Kuid arenduses on meil patch, mille kaudu on võimalik seeria, st saate järjestikuselt samal serveril sama pgdata kasutada ja testida. Postgres restardib, vahemälu tühjendatakse. Ja saate koormust testida.

- Saabub kataloog, kus on palju erinevaid faile, alustades pg snapshottidest.stat***. Ja seal on kõige huvitavam – pg_stat_statements ja pg_stat_kcacke. Need on kaks laiendust, mis analüüsivad päringute tegemist. Ja pg_stat_bgwriter sisaldab mitte ainult pgwriteri statistikat, vaid ka checkpoint'i statistikat ja teavet selle kohta, kuidas taustprotsessid puhtaid puhvrisid nimetavad. Seda kõike on huvitav uurida. Näiteks, kui seadistame shared_buffers, siis on väga huvitav vaadata, kui palju seal kedagi välja tõrjutakse.
- Saabuvad ka Postgresi logid. Kaks logi – ettevalmistuslogi ja koormuse mängimise logi.
- Suhteliselt uus funktsioon – FlameGraphs.
- Kui olete kasutanud pgreplay või pgbench koormuse simuleerimise valikuid, siis on see nende loomulik väljund. Näete latency ja TPS-i. Saate aru, kuidas nad seda nägid.
- Süsteemi teave.
- Põhijõudluse ja IO kontrollid. See on rohkem mõeldud EC2 instantside jaoks Amazoni teenuses, kui soovite voolus käivitada 100 identset instantsi ja seal läbi viia 100 erinevat testimist, siis on teil 10 000 eksperimenti. Peate veenduma, et te ei saa vigast instantsi, keda keegi teine juba piirab. Sellel riistvaral tegutsevad teised kasutajad ning teile jääb vähe ressursse. Sellised tulemused oleks parem kõrvaldada. Ja just Alexey Kopytovi sysbenchi abil teeme mõned lühikesed kontrollid, mida saab hiljem võrrelda teistega, st saate aru, kuidas CPU ja IO end käitavad.

Millised on tehnilised raskused erinevate ettevõtete näitel?

Oletame, et soovime reaalset koormust logide abil korrata. Suurepärane idee, kui see on kirjutatud Open Source pgreplay'i abil. Kasutame seda. Kuid et see korralikult töötaks, peate lubama täieliku päringute logimise koos parameetrite ja ajastusega.
Seal on mõned raskused seoses duration ja timestampiga. Me jätame selle teema kõrvale. Peamine küsimus on – kas te saate endale seda lubada või mitte?

Probleem on selles, et see võib olla kergesti kättesaamatu. Te peate enne kõike mõistma, milline voog logisse kirjutatakse. Kui teil on pg_stat_statements, saate sellise päringuga (link on slaididel olemas) aru saada, kui palju baite kirjutatakse sekundis.
Me vaatame päringu pikkust. Me ignoreerime, et seal ei ole parameetreid, kuid me teame päringu pikkust ja teame, mitu korda sekundis see täidetakse. Nii saame hinnata, kui palju baite sekundis kirjutatakse. Me võime eksida kahes kahekordse võrra, kuid määrame täpselt selle järjekorra.
Me näeme, et 802 korda sekundis seda päringut täidetakse. Ja me näeme, et bytes_per sec – 300 kB/s kirjutatakse pluss miinus. Ja tavaliselt suudame sellist voogu endale lubada.

Aga! Asi on selles, et on erinevaid logimissüsteeme. Ja vaikimisi on inimestel tavaliselt "syslog".
Ja kui teil on syslog, siis võib teil olla selline pilt. Me võtame pgbench'i, lülitame sisse päringute logimise ja vaatame, mis juhtub.
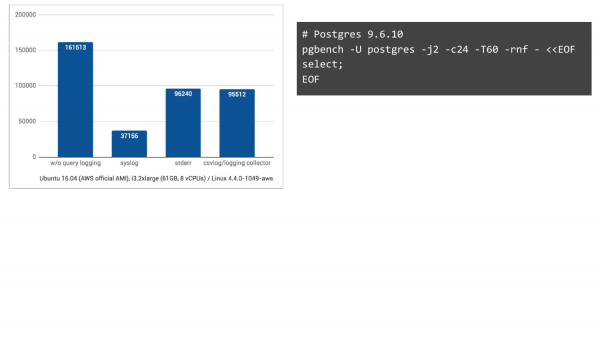
Ilma logimiseta on see vasakul külg. Me saavutasime 161 000 TPS. Syslogiga – Ubuntu 16.04 Amazonis saavutasime 37 000 TPS. Ja kui me muudame kahel muul moel logimist, on olukord oluliselt parem. Ehkki me ootasime, et see väheneb, ei olnuks see siiski nii drastiline.
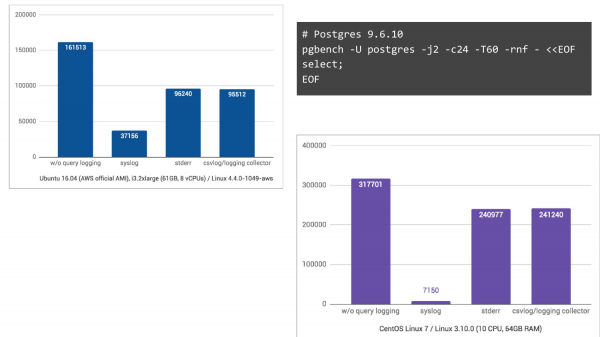
Ja CentOS 7 puhul, kus osaleb ka journald, muutes logid binaarsesse formaati mugavaks otsimiseks jne, on olukord isegi hullem, TPS kukub 44 korda.
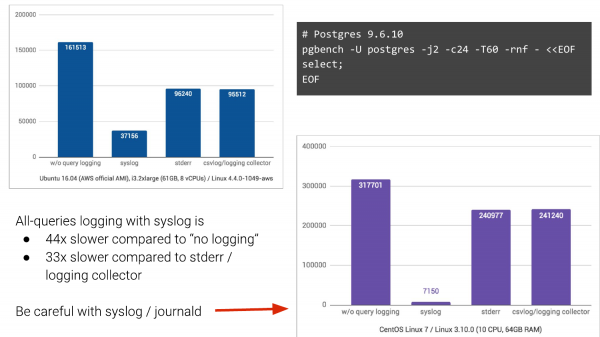
Ja see on see, millega inimesed elavad. Ja sageli on ettevõtetes, eriti suurtes, seda väga raske muuta. Kui saate syslogist lahkuda, siis lahkuge sellest kindlasti.

- Hinnake IOPS-i ja kirjutusvoogu.
- Kontrollige oma süsteemi logimist.
- Kui prognoositav koormus on liiga suur, kaaluge proovide võtmise võimalust.

Meil on pg_stat_statements. Nagu ma ütlesin, peab see kindlasti olemas olema. Ja me saame iga päringugrupi spetsiaalselt failis kirjeldada. Seejärel saame kasutada pgbenchis väga mugavat funktsiooni – võimalust sisestada mitu faili valiku „-f” kaudu.
Ta mõistab palju «-f». Ja saab öelda «@» lõpus, milline osa igast failist peaks olema. St me saame öelda, et nüüd teosta seda 10% juhtudest, ja seda 20%. Ja see tuletab meid lähemale sellele, mida me näeme tootmises.

Kuidas me saame aru, mis meil tootmises on? Milline osa ja mis? Siin on natuke kõrvalekaldumine. Meil on veel üks toode. . Samuti on see põhineb Open Source'il. Ja me arendame seda aktiivselt praegu.
See sündis veidi muudel põhjustel. Põhjustel, et jälgimine on ebapiisav. St sa tuled, vaatad baasi, vaatad probleeme, mis on. Ja tavaliselt teed health_check’i. Kui oled kogenud DBA, siis teed health_check’i. Vaatasid indeksite kasutust jne. Kui sul on OKmeter, siis on kõik suurepärane. See on suurepärane jälgimine Postgres’i jaoks. OKmeter.io – palun installige see, seal on kõik väga hästi tehtud. See on tasuline.
Kui sul seda ei ole, siis tavaliselt sul pole palju, mida on. Jälgimises on tavaliselt olemas CPU, IO ja seda ka tingimustega, ja kõik. Aga meil on vaja rohkem. Me peame nägema, kuidas töötab automaatne vakuum, kuidas töötab kontrollpunkt, IO-s peame eraldama kontrollpunkti bgwriter’ist ja taustprotsessidest jne.
Probleem on see, et kui sa aitad mõnda suurt ettevõtet, ei saa nad midagi kiiresti rakendada. Nad ei saa kiiresti osta OKmeteri. Võib-olla ostavad nad selle kuue kuu pärast. Nad ei saa kiiresti installida mingisuguseid pakette.
Ja meil tekkis mõte, et vajame sellist spetsiaalset tööriista, mis ei nõua mingit installimist, st te ei pea tootmisse midagi paigaldama. Installige see oma sülearvutisse või jälgimisserverisse, kust selle käivitada. Ja see analüüsib palju asju: operatsioonisüsteemi, failisüsteemi ja ise Postgres'i, tehes kergeid päringuid, mida saab otse tootmises kasutada ja mis ei too kaasa purunemist.
Me nimetame seda Postgres-checkup'iks. Kui meditsiiniliselt, siis see on regulaarne heaolu kontroll. Kui autotemaatika kontekstis, siis – see on nagu hooldus. Sa teed autole hooldust iga kuue kuu või aasta tagant, sõltuvalt markist. Kas sa teed oma andmebaasile hooldust? St kas sa teed regulaarselt süvitsi minevat uurimist? Seda on vaja teha. Kui sa teed varukoopiaid, siis tee ka checkup, see on sama oluline.
Ja meil on selline tööriist. See hakkas aktiivselt arenema alles kolm kuud tagasi. See on veel noor, kuid seal on palju kasulikku.

Koondame kõige "mõjukamad" päringugrupid – raport K003 Postgres-checkup-is
Ja seal on raportite grupp K. Praegu on kolm raportit. Ja seal on ka raport K003. Seal on pg_stat_statements-i tipp, sorteeritud total_time järgi.
Kui sorteerime päringugruppe total_time järgi, näeme tipus gruppi, mis koormab meie süsteemi kõige rohkem, st tarbib rohkem ressursse. Miks ma räägin päringugruppidest? Kuna me eemaldame parameetrid. Need ei ole enam päringud, vaid päringugrupid, st need on abstraktsed.
Ja kui optimeerime ülevalt alla, kergendame oma ressursse ja lükkame edasi aega, millal peame uuendama. See on väga hea viis raha säästa.
Võib-olla ei ole see väga hea viis kasutajakogemuse osas, kuna me ei pruugi näha haruldasi, kuid väga ebameeldivaid juhtumeid, kus inimene ootas 15 sekundit. Kokkuvõttes on need nii haruldased, et me ei näe neid, kuid samas tegeleme ressurssidega.

Mis toimus selles tabelis? Me tegime kaks lõikesalvestust. Postgres_checkup arvutab iga mõõtme, nagu total-time, calls, rows, shared_blks_read jne, erinevuse. Kõik on arvutatud. Pg_stat_statementsil on suur probleem, et ta ei mäleta, millal seda lähtestati. Kui pg_stat_database mäletab, siis pg_stat_statements ei mäleta. Te näete seal 1 000 000 numbrit, aga kust me selle saime, pole teada.
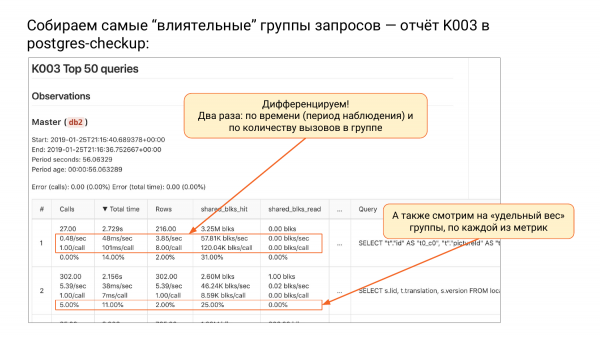
Siin me teame, et meil on kaks lõikesalvestust. Me teame, et selles olukorras oli erinevus 56 sekundit. Väga väike aeg. Total_time’i järgi sorteeritud. Edasi saame me diferentseerida, st jagame kõik mõõtmed durationiga. Kui me iga mõõtme jagame durationiga, saame kutsungite arvu sekundis.
Edasi on total_time per second – see on minu lemmik mõõde. See mõõdetakse sekundites, st kui palju sekundeid kulus meie süsteemil selle päringugrupi täitmiseks sekundis. Kui te näete seal rohkem kui üks sekund sekundis, tähendab see, et vajadusi on rohkem kui üks tuum. See on väga hea mõõde. Te saate aru, et sellele isikule on näiteks vajalik vähemalt kolm tuuma.
See, this is our know-how; I haven't seen anything like it before. Notice – it's very simple – second by second. Sometimes, when your CPU is at 100%, it's half an hour per second, meaning you've spent half an hour on just this request.
Next, we see rows per second. We know how many rows were returned per second.
And another interesting aspect. How many shared_buffers we read per second from the shared_buffers itself. The hits were already there, while the rows we took from the operating system's cache or from the disk. The first option is fast, while the second might be fast or might not, depending on the situation.
The second method of differentiation – we divide the number of requests in this group. In the second column, you will always have one request divided by the request. And then it gets interesting – how many milliseconds it took for this request. We know the average behavior of this request. It required 101 milliseconds for each request. This is a traditional metric we need for understanding.
Kui palju ridu iga päring keskmiselt tagastas. Näeme, et see grupp tagastab 8. Kui palju keskmiselt vahemälust tuli ja loeti. Näeme, et kõik on suurepäraselt vahemälus. Ainult hitid esimese grupi jaoks.
Ja iga rea neljas alamrida – see on protsent kogu koguarvust. Meil on calls. Ütleme, et 1 000 000. Ja me saame aru, kui suur on selle grupi panus. Näeme, et antud juhul on esimese grupi panus väiksem kui 0,01%. See tähendab, et see on nii aeglane, et me ei näe seda üldpildis. Teine grupp aga – 5% kõigist kutsumistest. See tähendab, et 5% kõigist kutsumistest on teine grupp.
Ka total_time on huvitav. Esimese grupi päringutele kulutasime 14% kogu tööajast. Teisele grupile – 11% jne.
Ma ei hakka detailidesse süvenema, kuid seal on nüansse. Me näitame ülal viga, sest kui me võrdleme, võivad snapshotid muutuda, st mõned päringud võivad kaduda ja teises ei pruugi neid enam olla, aga mõned võivad uued ilmuda. Ja me seal arvutame vea. Kui näete 0, siis on see hea. Vigu ei ole. Kui veaprotsent on kuni 20%, on see OK.

Edasi liikudes, naaseme meie teema juurde. Peame koostama töökoormuse. Alustame ülevalt alla, kuni jõuame 80% või 90% -ni. Tüüpiliselt on see 10-20 gruppi. Ja teeme failid pgbench'i jaoks. Seal kasutame juhuslikku (random) lähenemist. Kahjuks ei toimi see alati. Postgres 12-s on selle lähenemise rakendamiseks rohkem võimalusi.
Nii kogume 80-90% kokku total_time-st. Mis järgmiseks panna «@»-le? Vaatame kõnesid, jälgime protsente ja saame aru, et siin peaks olema teatud protsent. Nendest protsentidest saame aru, kuidas igat faili tasakaalustada. Pärast seda kasutame pgbench'i ja alustame tööd.
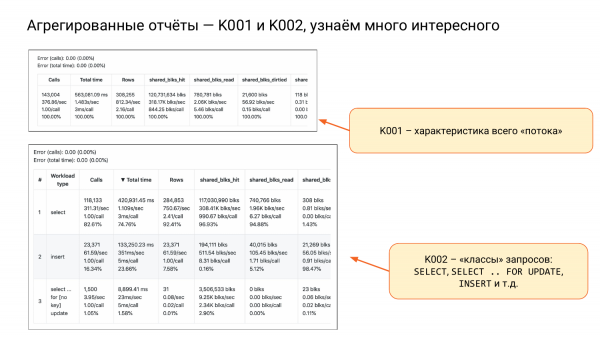
Meil on veel K001 ja K002.
K001 – see on üks suur rida koos nelja alarühmaga. See iseloomustab kogu meie koormust. Vaadake teist veergu ja teist alarühma. Näeme, et see on umbes 1,5 sekundit sekundis, st kui on kaks tuuma, siis on see hea. Koormus on umbes 75%. Ja see töötab nii. Kui meil on 10 tuuma, siis oleme täiesti rahulikud. Nii saame ressursse hinnata.
K002 – seda nimetame päringute klassideks, st SELECT, INSERT, UPDATE, DELETE. Ja eraldi SELECT FOR UPDATE, kuna see lukustab.
Siit võime järeldada, et SELECT'i tavalised lugemised moodustavad 82% kõigist kutsumistest, kuid tarbivad ainult 74% total_time'ist. See tähendab, et neid kutsutakse palju, kuid nad tarbivad vähem ressursse.
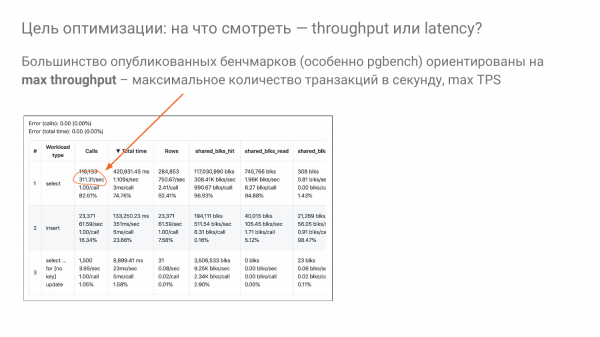
Ja naaseme küsimuse juurde: «Kuidas valida õigesti shared_buffers?». Olen märganud, et enamikki benchmark'e ehitatakse idee põhjal – vaatame, milline on läbilaskevõime. Seda mõõdetakse tavaliselt TPS või QPS'iga.
Ja me püüame, kasutades seadistusi, autolt pigistada võimalikult palju tehinguid sekundis. Siin on just 311 sekundis SELECT'i jaoks.

Kuid keegi ei sõida tööle ja tagasi koju autoga täis speeds. See on rumal. Nii on ka andmebaasidega. Me ei tohiks sõita maksimaalsel kiirusel, keegi ei tee seda. Keegi ei ela tootmises, kus CPU on 100%. Kuigi võib-olla on keegi, kes elab, kuid see ei ole hea.
Idee on selline, et tavaliselt kasutame me umbes 20% oma võimalustest, soovitatavalt mitte üle 50%. Püüame optimeerida reageerimisaega meie kasutajate jaoks eelkõige. St. me peame oma käsi keerama nii, et 20% kiirusel oleks minimaalne latentsus, tinglikult. See on idee, mida püüame ka oma katsetes rakendada.
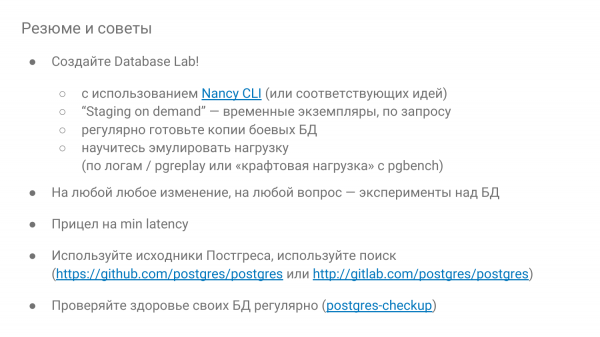
Ja lõpetuseks soovitused:
- Kohustuslikult tehke Database Lab.
- Võimaluse korral tehke see nõudmise alusel, et see tööle vajutada teatud ajaks - proovige ja siis visake minema. Kui teil on pilved, siis see on iseenesest mõistetav, s.t. omage palju seismist.
- Olge uudishimulikud. Ja kui midagi ei klapi, kontrollige katsetega, kuidas see käitub. Nancy't saab kasutada, et end harida ja kontrollida, kuidas andmebaas töötab.
- Ja sihtige minimaalset reageerimisaega.
- Ärge kartke Postgresi lähtekoodide ees. Kui töötate lähtekoodidega, peate oskama inglise keelt. Seal on palju kommentaare, kõik on selgitatud.
- Ja kontrollige andmebaasi tervist regulaarselt, vähemalt kord kolme kuu jooksul käsitsi või Postgres-checkupiga.

Küsimused
Aitäh väga palju! Väga huvitav asi.
Kaks asja.
Jah, kaks tükki. Ainult et ma ei saanud täielikult aru. Kui me Nancy'ga töötame, saame me reguleerida ainult ühte parameetrit või terve grupi korraga?
Meil on delta-konfiguratsiooniparameeter. Sinna saad keerata nii palju kui soovid. Kuid tuleb mõista, et kui muudatusi on palju, võid teha valeid järeldusi.
Jah. Miks ma küsisin? Sest eksperimente on keeruline teha, kui sul on ainult üks parameeter. Sa reguleerid seda, vaatad, kuidas see töötab. Häälestad selle. Siis hakkad järgmist muutma.
Samas saab korraga reguleerida, kuid see sõltub olukorrast, muidugi. Siiski on parem testida ühte idee. Meil tekkis eile idee. Olime väga sarnases olukorras. Kaks konfiguratsiooni. Ja me ei saanud aru, miks oli suur erinevus. Ja tekkis idee, et peaksime kasutama dikotoomiat, et järjestikku mõista ja leida, mis vahe on. Saame kohe poole parameetritest muuta sama sarnaseks, siis veerandi jne. Kõik on paindlik.
Ja on veel küsimus. Projekt on noor, areneb. Dokumentatsioon on juba valmis, kas on olemas detailne kirjeldus?
Ma tegin sinna spetsiaalselt lingi parameetrite kirjeldusele. See on olemas. Kuid palju on veel puudu. Otsin kaasamõtlejaid. Ja ma leian neid, kui esindan. See on väga äge. Keegi töötab juba minuga, keegi aitas ja tegi midagi. Ja kui see teema teid huvitab, andke mulle kindlasti tagasisidet – mida on puudu.
Kui labori ära teeme, võib-olla tuleb tagasiside. Näeme. Aitäh!
Tere! Aitäh ettekande eest! Märkasin, et Amazoni tugi on olemas. Kas plaanitakse ka GSP tuge?
Hea küsimus. Oleme alustanud. Ja oleme hetkeks peatunud, sest soovime raha säästa. Toetust pakutakse localhost'is töötamise kaudu. Saate ise luua instantsi ja töötada kohalikult. Muide, just nii me teeme. Getlabs jagan, seal GSP peal. Kuid me ei näe praegu mõtet sellise orkestreerimise tegemiseks, kuna Google'il ei ole odavaid spot'ide pakkumisi. Seal on ??? instantsid, kuid nendele kehtivad piirangud. Esiteks on alati ainult 70% allahindlus ja seal ei saa hinna osas mängida. Spot'ide puhul tõstame hinda 5-10% võrra, et vähendada tõenäosust, et teid ümber lükatakse. See tähendab, et spot'ide puhul säästate raha, kuid need võivad igal ajal ära võtta. Kui teie hind on veidi kõrgem kui teistel, surete hiljem. Google'il on täielikult erinev spetsiifika. Ja veel on üks väga halb piirang – nad elavad ainult 24 tundi. Ja mõnikord tahame katset teha 5 päeva. Kuid spot'ide puhul on see võimalik, mõnikord elavad need kuude kaupa.
Tere! Aitäh ettekande eest! Te mainisite checkup'i. Kuidas te arvutate vigu stat_statements?
Väga hea küsimus. Ma võin väga detailselt näidata ja rääkida. Lühidalt – me vaatame, kuidas on muutunud rühmade päringute kogum: kui palju on kadunud ja kui palju on uusi tekkinud. Ja seejärel vaatame kahte mõõdikut: total_time ja calls, seega on seal kaks viga. Ja vaatame, milline on kadunud rühmade panus. Seal on kaks alammoodi: lahkunud ja saabunud. Vaatame, kui suur on nende panus kogu pilti.
Kas te ei karda, et see seal pöörleb kaks-kolm korda ajavahemikus snapšottide vahel?
St. nad registreerusid uuesti või kuidas?
Näiteks, see päring on juba üks kord välja tõrjuda, siis tuli tagasi ja tõrjuti taas välja, siis tuli veel kord tagasi ja tõrjuti jälle välja. Ja te siin midagi arvutasite, kus see kõik on?
Hea küsimus, tuleb vaadata.
Ma tegin sarnast asja. Muidugi lihtsamat, ma tegin seda üksi. Aga mul tuli nullida, teha reset stat_statements ja orienteeruda snapšoti hetkel, et seal oleks vähem teatud osa, et see ei oleks ikkagi jõudnud lakke, kui palju stat_statements-ite võib koguneda. Ja ma lähtun, et tõenäoliselt ei ole midagi välja tõrjutud.
Jah-jah.
Aga ma ei mõista, kuidas võiks midagi muud usaldusväärselt teha.
Kahjuks ei mäleta ma täpselt - kas me seal kasutame päringu teksti või queryid pg_stat_statements ja selle järgi juhindume. Kui me juhindume queryid'ist, siis peaksime võrreldes sarnaseid asju.
Ei, see võib mitme võrgu vahel välja juhtida ja uuesti tagasi tulla.
Kas selle sama id-ga?
Jah.
Me uurime seda. Hea küsimus. Peame uurima. Kuid seni, mida me näeme, on meil kas kirjutatud 0...
See on muidugi haruldane juhtum, aga olin jahmunud, kui kuulsin, et stat_statements seal võib välja juhtida.
Pg_stat_statements'is võib palju olla. Oleme kohtunud sellega, et kui teil track_utility = on, siis jälgitakse ka teie setteid.
Jah, muidugi.
Ja kui teil on random java hibernate, siis hakkab seal lukuklahvi tabel lukustuma. Ja niipea, kui te keelate väga koormatud rakenduse, on teil 50-100 gruppi. Ja seal on enam-vähem kõik stabiilne. Üks viis selle vastu võitlemiseks on pg_stat_statements.max suurendada.
Jah, aga tuleb teada, kui palju. Ja kuidagi peab selle üle jälgima. Mina teen nii. T. e. mul on pg_stat_statements.max. Ja vaatan, et ma snapshot'i ajal ei ole jõudnud 70% juurde. Hästi, see tähendab, et me ei ole midagi kaotanud. Teeme reseti. Ja kogume uuesti. Kui järgmises snapshot'is on vähem kui 70, siis tähendab, et tõenäoliselt ei ole me jälle midagi kaotanud.
Jah. Vaikimisi on praegu 5000. Ja paljudele sellest piisab.
Tavaliselt – jah.
Video:

P.S. Isiklikult lisan, et kui Postgresis on konfidentsiaalsed andmed ja neid ei tohi testkeskkonda viia, siis võib kasutada . Skeem on umbkaudu järgmine:
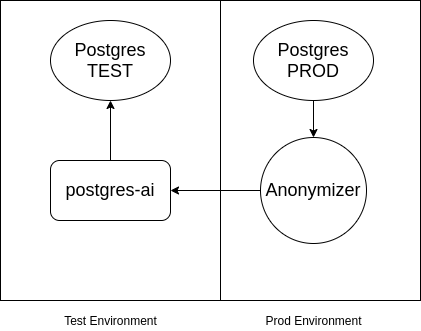
Allikas: habr.com
