


Olen veebis GitHubis .
See on lihtne hash-tabel GPU jaoks, mis suudab töödelda sajandeid miljoneid sisendeid sekundis. Minu sülearvuti NVIDIA GTX 1060-ga sisestab kood umbes 64 miljonit juhuslikult genereeritud võtme-väärtuse paari umbes 210 ms jooksul ja eemaldab 32 miljonit paari umbes 64 ms jooksul.
Seega on sülearvuti kiirus umbes 300 miljonit sisestust/sek ja 500 miljonit eemaldamist/sek.
Tabel on kirjutatud CUDA-s, kuigi sama meetodit saab rakendada HLSL-i või GLSL-i. Teostusel on mitmeid piiranguid, mis tagavad kõrge jõudluse graafikakaardil:
- Töödeldakse ainult 32-bitiseid võtmeid ja sama suurusega väärtusi.
- Hash-tabelil on fikseeritud suurus.
- Ja see suurus peab olema võrdne kahe astmega.
Võtmete ja väärtuste jaoks peab olema reserveeritud lihtne eraldusmarker (antud koodis on see 0xffffffff).
Blokeerimata hash-tabel
Hash-tabelis kasutatakse avatud adresseerimist koos , st, see, this is just an array of key-value pairs that is stored in memory and has excellent cache performance. The same cannot be said for chaining, which implies searching for a pointer in a linked list. A hash table is a simple array that stores elements. KeyValue:
struct KeyValue
{
uint32_t key;
uint32_t value;
};
The size of the table is a power of two rather than a prime number because a single quick instruction is enough for the pow2/AND mask, while the modulus operator works much slower. This is important in the case of linear probing, as the index of the slot must be wrapped in every slot. As a result, the cost of the modulus operation is added in each slot.
The table stores only the key and value for each element, rather than the hash of the key. Since the table only stores 32-bit keys, the hash is computed very quickly. The provided code uses the Murmur3 hash, which performs just a few shifts, XORs, and multiplications.
Hash-tabelis kasutatakse blokeerimistest sõltumatut kaitsemeetodit, mis ei sõltu mälu paigutamise järjekorrast. Isegi kui mõned kirjutamisoperatsioonid häirivad teiste selliste operatsioonide järjekorda, säilitab hash-tabel ikkagi õige seisundi. Räägime sellest hiljem. Meetod töötab suurepäraselt graafikakaartides, kus tuhanded lõimed töötavad samaaegselt.
Hash-tabeli võtmed ja väärtused initsialiseeritakse tühjadeks.
Koodi saab muuta, et see suudaks töödelda ka 64-bitiseid võtmeid ja väärtusi. Võtmete jaoks on vajalikud aatomilised lugemise, kirjutamise ja vahetamise (compare-and-swap) operatsioonid. Väärtuste jaoks on vajalikud aatomilised lugemise ja kirjutamise operatsioonid. Õnneks on CUDA-s 32- ja 64-bitiste väärtuste lugemise kirjutamise operatsioonid aatomilised, kui need on õigesti joondatud (vt. ), ja kaasaegsed graafikakaardid toetavad 64-bitiseid aatomilisi vahetusoperatsioone. Loomulikult väheneb jõudlus mõnevõrra, kui liikuda 64 bitini.
Hash-tabeli seisund
Iga võtme-väärtuse paar hash-tabelis võib olla ühes neljast olekust:
- Kl Keys ja väärtus on tühjad. Sellises seisundis initsialiseeritakse hash-tabel.
- Key on salvestatud, kuid väärtus mitte veel. Kui teine täitmisprotsess loeb andmeid sel ajal, siis tagastab ta seejärel tühja väärtuse. See on normaalne, sama juhtuks, kui teine täitmisprotsess oleks lõpetanud veidi varem, ja räägime konkurentsivõimelisest andmestruktuurist.
- Nii võtme kui väärtuse kirjed on salvestatud.
- Väärtus on teiste täitmisprotsesside jaoks kättesaadav, kuid võti veel mitte. See võib juhtuda, kuna CUDA programmodel eeldab nõrgalt järjestatud mälumudelit. See on normaalne, mingil hetkel on võti endiselt tühi, isegi kui väärtus ei ole.
Oluline nüanss on see, et kui võti on salvestatud pesasse, ei liigu see enam — isegi kui võti eemaldatakse, räägime sellest hiljem.
Hash-tabeli kood töötab isegi nõrgalt järjestatud mälumudelitega, kus ei ole teada lugemise ja kirjutamise järjekord mälu. Kui me uurime insertimist, otsimist ja kustutamist hash-tabelis, pidage meeles, et iga võtme-väärtuse paar on ühes neljast eespool kirjeldatud olekust.
Sisestamine hash-tabelisse
CUDA-funktsioon, mis sisestab hash-tabelisse võtme-väärtuse paare, näeb välja järgmine:
void gpu_hashtable_insert(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
uint32_t prev = atomicCAS(&hashtable[slot].key, kEmpty, key);
if (prev == kEmpty || prev == key)
{
hashtable[slot].value = value;
break;
}
slot = (slot + 1) & (kHashTableCapacity-1);
}
}
Võtme sisestamiseks iteratiivne kood läbib hash-tabeli massiivi, alustades sisestatava võtme hash'ist. Igas massiivi slotis teostatakse aatomiline võrreldes vahetus, kus selle sloti võti võrreldakse tühjaga. Kui leitakse vastuolu, uuendatakse slotis olev võti sisestatava võtmega ning seejärel tagastatakse sloti algne võti. Kui see algne võti oli tühi või vastas sisestatavale võtmele, siis tähendab see, et kood on leidnud sobiva sloti ja sisestab sloti sisestatud väärtuse.
Kui ühes tuumas gpu_hashtable_insert() on mitmeid elemente sama võtmega, seega võib ükskõik milline nende väärtustest olla salvestatud võtme sloti. Seda peetakse normiks: ühe võtme-väärtuse salvestamise operatsiooni jooksul tuleb olema edukas, kuid kuna see toimub paralleelselt mitmes täitmisvoos, ei saa me prognoosida, milline salvestamise operatsioon mälus viimane on.
Otsimine hajutustabelis
Kood võtmete otsimiseks:
uint32_t gpu_hashtable_lookup(KeyValue* hashtable, uint32_t key)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
return hashtable[slot].value;
}
if (hashtable[slot].key == kEmpty)
{
return kEmpty;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
Võtme väärtuse leidmiseks, mis on tabelis, itereerime massiivi alates otsitava võtme häsist. Igas slotis kontrollime, kas võtme on see, mida otsime, ja kui jah, siis tagastame selle väärtuse. Kontrollime ka, kas võtme on tühi, ja kui jah, siis katkestame otsimise.
Kui me ei suuda võtmeid leida, tagastab kood tühja väärtuse.
Kõiki neid otsinguoperatsioone saab teostada samaaegselt lisamise ja kustutamise käigus. Iga paari jaoks tabelis on üks neljast ülaltoodud olekust, mis kehtib voogude kohta.
Kustutamine hääletustabelis
Kood võtmete kustutamiseks:
void gpu_hashtable_delete(KeyValue* hashtable, uint32_t key, uint32_t value)
{
uint32_t slot = hash(key);
while (true)
{
if (hashtable[slot].key == key)
{
hashtable[slot].value = kEmpty;
return;
}
if (hashtable[slot].key == kEmpty)
{
return;
}
slot = (slot + 1) & (kHashTableCapacity - 1);
}
}
Võtme kustutamine toimub ebatavaliselt: me jätame võtme tabelisse ja märgime selle väärtuse (mitte võtme ennast) tühjaks. See kood sarnaneb väga lookup(), välja arvatud see, et võtme vaste leidmisel muudab see selle väärtuse tühjaks.
Kuidas eelnevalt mainitud, niipea kui võti on slotis, ei liigu see enam. Isegi kui element tabelist eemaldatakse, jääb võti oma kohale, lihtsalt selle väärtus muutub tühjaks. See tähendab, et me ei pea kasutama sloti väärtuse kirjutamise aatomset operatsiooni, kuna pole tähtis, kas praegune väärtus on tühi või mitte — see jääb ikkagi tühjaks.
Hääletustabeli suuruse muutmine
Häkkide suurust saab muuta, luues suurema tabeli ja sisestades sinna mitte-tühjad elemendid vanast tabelist. Ma ei rakendanud seda funktsionaalsust, kuna soovisisin koodi lihtsana hoida. Veelgi enam, CUDA-programmides toimub mälu eraldamine sageli host-koodis, mitte CUDA tuumas.
Artiklis kuidas muudab sellist lukustusvastast andmestruktuuri.
Konkurentsus
Ülaltoodud koodilõikudes funktsioonid gpu_hashtable_insert(), _lookup() ja _delete() töötlevad ühte võtme-väärtuse paari korraga. Allpool gpu_hashtable_insert(), _lookup() ja _delete() töötlevad massiivi paare paralleelselt, iga paari jaoks eraldi GPU täitmisvoos:
// CPU code to invoke the CUDA kernel on the GPU
uint32_t threadblocksize = 1024;
uint32_t gridsize = (numkvs + threadblocksize - 1) / threadblocksize;
gpu_hashtable_insert_kernel<<<gridsize, threadblocksize>>>(hashtable, kvs, numkvs);
// GPU code to process numkvs key/values in parallel
void gpu_hashtable_insert_kernel(KeyValue* hashtable, const KeyValue* kvs, unsigned int numkvs)
{
unsigned int threadid = blockIdx.x*blockDim.x + threadIdx.x;
if (threadid < numkvs)
{
gpu_hashtable_insert(hashtable, kvs[threadid].key, kvs[threadid].value);
}
}
Lukustusvastane häkk tabel toetab konkurentsiat, otsingut ja kustutamist. Kuna võtme-väärtuse paarid on alati ühes neljast olekust ja võtmed ei liigu, tagab tabel õigsuse isegi erinevat tüüpi operatsioonide samaaegse kasutamise korral.
Kuid kui me töötleme samal ajal massiivi sisendeid ja eemaldamisi ning kui sisendmassiivis on korduvad võtmed, siis ei saa me ennustada, millised paarid "võidavad" — need, mis kirjutatakse viimati häshtabellisse. Oletame, et kutsume esile sisestuskoodi paaride massiiviga. A/0 B/1 A/2 C/3 A/4. Kui kood lõpetatakse, siis paarid B/1 ja C/3 on garanteeritult tabelis, kuid seal võib olla ükskõik milline paar A/0, A/2 või A/4. See võib olla probleem või mitte — kõik sõltub kasutamisest. Te võite eelnevalt teada, et sisendmassiivis ei ole korduvaid võtmeid, või te võite mitte hoolida, milline väärtus viimati salvestati.
Kui see on teie jaoks probleem, tuleb korduvad paarid jagada erinevatesse süsteemsetesse CUDA-kutsetesse. CUDA-s lõppeb iga tuuma kutse operatsioon alati enne järgmist tuuma kutset (vähemalt ühe voolu sees. Erinevates voogudes tuumad täidetakse paralleelselt). Kui ülaltoodud näites kutsuda üks tuum välja A/0 B/1 A/2 C/3, ja teine A/4, siis saab võtme A väärtuse 4.
Nüüd räägime sellest, kas funktsioonid lookup() ja delete() kasutada lihtsat (plain) või muutuva (volatile) punkti massiivi paaride hulgast räsitabelis. kinni pidama, et:
Kompilaator võib oma äranägemise järgi optimeerida lugemis- ja kirjutamisoperatsioone globaalsetes või ühistes mäludes ... Need optimeerimised saab välja lülitada võtmesõna
volatile: ... iga viide sellele muutuvale kompileeritakse tegelikuks mälu lugemise või kirjutamise käsuks.
Korrektsuse kaalutlused ei nõua rakendamist volatile. Kui täitmisvoog kasutab varasemat lugemistehingust vahemällu salvestatud väärtust, tähendab see, et ta kasutab natuke aegunud teavet. Kuid see on siiski teave räsitabeli õigest olekust teatud hetkel kernekutses. Kui vajate kõige värskemat teavet, saate kasutada punkti volatile, kuid see vähendab pisut jõudlust: minu testide järgi vähenes 32 miljoni elemendi kustutamisel kiirus 500 miljonilt kustutamiselt/säkki 450 miljonini kustutamiselt/säkki.
Tootlikkus
64 miljoni elemendi lisamise ja 32 miljoni kustutamise testis oli konkurents std::unordered_map ja räsitabeli vahel GPU jaoks praktiliselt puuduv.
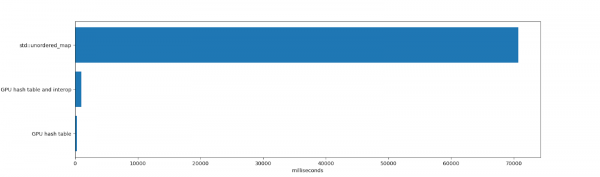
std::unordered_map kasutas 70 691 ms elementide sisestamiseks ja kustutamiseks ning seejärel vabastamiseks unordered_map (miljonite elementide vabastamine võtab aega, kuna sees toimub unordered_map palju mälu eraldamist). Ausalt öeldes, std:unordered_map on hoopis teised piirangud. See on ühe CPU-täitevoo täitmine, mis toetab mis tahes suurusega võtme-väärtuse paare, töötab hästi kõrgete kasutuskohtadega ja näitab stabiilset jõudlust pärast arvukaid kustutusi.
Hash-tabeli tööaeg GPU ja programmid vahel oli 984 ms. Siia kuulub aeg, mis kulus tabeli mälu paigutamiseks ja selle eemaldamiseks (ühekordne 1 GB mälu eraldamine, mis CUDA-s võtab aega), elementide sisestamine ja kustutamine ning nende üle iteratsioon. Samuti on arvesse võetud kõiki kopeerimisi videokaardi mälu ja sealt.
Häkkedabeli töö kestis 271 ms. See hõlmab aega, mis kulus graafikakaardile elementide sisestamiseks ja kustutamiseks, kuid ei arvestata mälestusse kopeerimise ja saadud tabeli itereerimise aega. Kui GPU-tabel elab kaua või kui hälbedabel on täielikult graafikakaardi mälus (näiteks hälbedabeli loomiseks, mida kasutab muu GPU-kood, mitte keskprotsessor), on testimise tulemus asjakohane.
Graafikakaardi hälbedabel demonstreerib kõrget jõudlust tänu suurele läbilaskevõimele ja aktiivsele paralleelsele töötlemisele.
Puudused
Häkkedabeli arhitektuuril on mitmeid probleeme, millega tuleb arvestada:
- Klastri vormimise tõttu takistab lineaarne uurimine, mistõttu on tabelis klahvid kaugeltki mitte ideaalsed.
- Klahve ei kustutata funktsiooni
kustutaja need ummistavad aja jooksul tabelit.
Aja tõttu võib hash-tabeli jõudlus järk-järgult kahaneda, eriti kui see on pikka aega olemas ning selles tehakse arvukaid sisestusi ja kustutusi. Üks viis nende puuduste leevendamiseks on ümberhashimine uude tabelisse, millel on piisavalt madal kasutuskordaja ja kustutatud võtmete filtreerimine ümberhashimise ajal.
Probleemide illustreerimiseks kasutan ülaltoodud koodi, et luua 128 miljoni elemendi tabel, sisestan tsükliliselt 4 miljonit elementi, kuni täidan 124 miljonit pesa (kasutuskordaja umbes 0,96). Siin on tulemuste tabel, iga rida on CUDA tuuma kõne, mille ajal sisestatakse 4 miljonit uut elementi ühte hash-tabelisse:
Kasutuskordaja
4 194 304 elemendi sisestamise kestus
0,00
11,608448 ms (361,314798 miljonit võtit/sekundis)
0,03
11,751424 ms (356,918799 miljonit võtit/sekundis)
0,06
11,942592 ms (351,205515 miljonit võtit/sekundis)
0,09
12,081120 ms (347,178429 miljonit võtit/sekundis)
0,12
12,242560 ms (342,600233 miljonit võtit/sekundis)
0,16
12,396448 ms (338,347235 miljonit võtit/sekundis)
0,19
12,533024 ms (334,660176 miljonit võtit/sekundis)
0,22
12,703328 ms (330,173626 miljonit võtit/sekundis)
0,25
12,884512 ms (325,530693 miljonit võtit/sekundis)
0,28
13,033472 ms (321,810182 miljonit võtit/sekundis)
0,31
13,239296 ms (316,807174 miljonit võtit/s)
0,34
13,392448 ms (313,184256 miljonit võtit/s)
0,37
13,624000 ms (307,861434 miljonit võtit/s)
0,41
13,875520 ms (302,280855 miljonit võtit/s)
0,44
14,126528 ms (296,909756 miljonit võtit/s)
0,47
14,399328 ms (291,284699 miljonit võtit/s)
0,50
14,690304 ms (285,515123 miljonit võtit/s)
0,53
15,039136 ms (278,892623 miljonit võtit/s)
0,56
15,478656 ms (270,973402 miljonit võtit/s)
0,59
15,985664 ms (262,379092 miljonit võtit/s)
0,62
16,668673 ms (251,627968 miljonit võtit/s)
0,66
17,587200 ms (238,486174 miljonit võtit/s)
0,69
18,690048 ms (224,413765 miljonit võtit/s)
0,72
20,278816 ms (206,831789 miljonit võtit/s)
0,75
22,545408 ms (186,038058 miljonit võtit/s)
0,78
26,053312 ms (160,989275 miljonit võtit/s)
0,81
31,895008 ms (131,503463 miljonit võtit/s)
0,84
42,103294 ms (99,619378 miljonit võtit/s)
0,87
61,849056 ms (67,815164 miljonit võtit/s)
0,90
105,695999 ms (39,682713 miljonit võtit/s)
0,94
240,204636 ms (17,461378 miljonit võtit/s)
Kasutusse määramise kasvu korral väheneb jõudlus. See on enamasti soovimatu. Kui rakendus lisab tabelisse elemente ja viskab need seejärel ära (nt raamatu sõnade arvestamisel), pole see probleem. Kuid kui rakendus kasutab pikaajalist hash-tabelit (nt graafikuredaktor, et salvestada mittetühje osa piltidest, kui kasutaja sisestab ja eemaldab teavet sageli), võib selline käitumine tekitada probleeme.
Ja ma mõõtsin hash-tabeli sondimise sügavust pärast 64 miljoni sisestuse (kasutuse määr 0,5). Keskmine sügavus oli 0,4774, nii et enamik võtmeid asus kas parimates võimalikes slotides või ühe slotiga parimast positsioonist. Maksimaalne sondimise sügavus oli 60.
Siis mõõtsin sondimise sügavust tabelis, kus oli 124 miljonit sisestust (kasutuse määr 0,97). Keskmine sügavus oli juba 10,1757, maksimaalne sügavus — 6474 (!!). Lineaarse sondimise jõudlus langeb tugevalt suurte kasutuse määrade korral.
Selle häshtabeli kasutusefektiivsuse hoidmine madalal tasemel on parim praktika. Kuid see suurendab jõudlust mälutarbimise arvelt. Õnneks on see 32-bitiste võtmete ja väärtuste puhul mõistetav. Kui ülaltoodud näites hoiame 128 miljoni elemendiga tabelis kasutusefektiivsuse tasemeks 0,25, saame neis hoidmiseks mahutada maksimaalselt 32 miljonit elementi, samas kui ülejäänud 96 miljonit pesa jääb kasutamata — iga paari kohta 8 baiti, 768 MB kadunud mälu.
Pange tähele, et see käsitleb graafikakaardi mälu kaotust, mis on väärtuslikum ressurss kui süsteemimälu. Kuigi enamik tänapäevaseid lauagraafikakaarte, mis toetavad CUDA-d, omavad vähemalt 4 GB mälu (artikli kirjutamise ajal oli NVIDIA 2080 Ti-l 11 GB), ei ole selliste suuruste kaotamine siiski kõige mõistlikum lahendus.
Hiljem kirjutan täpsemalt graafikakaartide jaoks mõeldud häshtabelite loomise kohta, mis ei puutu kokku uurimisaste probleemidega, samuti meetoditest, kuidas kasutamata pesa uuesti kasutada.
Uurimisaste
Klahvi süvendi määramiseks saame välja tõmmata klahvi räsikoodi (selle ideaalne indeks tabelis) selle tegelikust tabeli indeksist:
// get_key_index() -> index of key in hash table
uint32_t probelength = (get_key_index(key) - hash(key)) & (hashtablecapacity-1);
Kuna kahte binaarnumbrit täiendavates koodides ja asjaolu, et räsitabeli maht on kahe astmes, töötab see lähenemine isegi siis, kui klahvi indeks liigutatakse tabeli algusesse. Oletame, et klahvi räsitakse 1, kuid see on sisestatud 3. sloti. Siis saame tabeli jaoks, mille maht on 4, (3 — 1) & 3, mis on võrreldav 2-ga.
Kokkuvõte
Kui teil on küsimusi või märkusi, kirjutage mulle või avage uus teema.
See kood on kirjutatud inspiratsiooni saades kaunilt artiklitest:
Tulevikus jätkan ma räsitabelite rakendustega videokaartide jaoks kirjutamist ja analüüsin nende jõudlust. Mul on plaanis ahelalastamine, Robin Hoode räsimine ja kukeseene räsimine, kasutades aatomoperatsioone, millel on videokaartidele sobivad andmestruktuurid.
Allikas: habr.com
