

Märk. tõlge.: Artikli autor on Cindy Sridharan, imgix'i insener, kes tegeleb API arendamise ja eelkõige mikroteenuste testimisega. Selles artiklis jagab ta oma põhjalikku nägemust hetkeprobleemidest jaotatud jälgimise valdkonnas, kus tema arvates on puudus tõeliselt tõhusatest tööriistadest pakilisemate probleemide lahendamiseks.
[Illustratsioon on laenatud jaotatud jälgimise kohta.]
Arvatakse, et on keeruline juurutada ning selle kasu . Jälgimise „problemaatilisus“ seletatakse paljude põhjustega, sageli viidatakse süsteemi igas komponendis õigeid päiseid koos iga päringuga edastamise seadistamise keerukusele. Kuigi see probleem tõepoolest eksisteerib, ei saa seda üldse nimetada ületamatuks. See ei selgita, miks arendajad ei armasta jälgimist (isegi juba toimivat).
Peamine raskus jaotatud jälgimisega seondub mitte andmete kogumisse, mitte levitamis- ja esitamisvormide standardiseerimisse, ega ka mitte selle määramisse, millal, kus ja kuidas valim võtta. Ma ei püüa sugugi kujutada elementaarsetena neid "kasutamise probleemid" — tõepoolest on olemas märkimisväärsed tehnilised ja (kui vaatame tõeliselt avatud lähtekoodiga ) poliitilised väljakutsed, mis tuleb ületada, et neid probleeme saaks pidada lahendatud.
Kuid kui kujutada ette, et kõik need probleemid on lahendatud, on tõenäoline, et mitte midagi ei muutu oluliselt kasutajakogemuse. Jälgimine ei pruugi endiselt pakkuda praktilist kasu kõige sagedasemates tõrkeotsingustsenaariumides — isegi pärast selle rakendamist.
Selline erinev jälgimine
Jaotatud jälgimine hõlmab mitmeid eraldiseisvaid komponente:
- rakenduste ja vahepealsete juhtimisvahendite varustamine;
- jaotatud konteksti edastamine;
- jälgimise kogumine;
- jälgimise salvestamine;
- nende väljavõtmine ja visualiseerimine.
Rohkem arutelusid jaotatud jälgimise üle käsitletakse kui ühte unaarset operatsiooni, mille ainus eesmärk on aidata süsteemi täielikust diagnostikast. Selle põhjuseks on suuresti see, kuidas ajalooliselt on kujunenud arusaamad jaotatud jälgimise osas. , kui Zipkini lähtekoodide avamisel mainiti, et ta [Zipkin] teeb Twitteri kiiremaks. Esimesed kaubanduslikud pakkumised jälgimise jaoks reklaamiti samuti .
Märk. tõlge.: Juhuks, et edasine tekst oleks paremini arusaadav, defineerime kaks põhiteri vastavalt :
- Span — jaotatud jälgimise põhielement. See esindab mingi töövoo (näiteks andmebaasi päringu) kirjeldust koos nime, algus- ja lõpuaja, siltide, logide ja kontekstitasandiga.
- Span'id sisaldavad tavaliselt viiteid teistele span'idele, mis võimaldab siduda mitmeid span'e Trace — visuaalsus, mis näitab päringu eluiga selle liikumise käigus jaotatud süsteemis.
Trace'id sisaldavad uskumatult väärtuslikku teavet, mis suudab aidata sellistes ülesannetes nagu: tootmises testimine, katastroofi taastamise testide läbiviimine, vigade sisestamise testimine jne. Tegelikult on mõned ettevõtted juba hakanud jälgimist selliste eesmärkide saavutamiseks kasutama. Alustame sellest, et on ka teisi rakendusi peale kergesti span'ide edastamise salvestussüsteemi:
- Näiteks Uber kasutab jälgimise tulemusi testliikluse ja tootmisliikluse eristamiseks.
- Facebook jälgimise andmed kriitilise tee analüüsimiseks ja liikluse suunamiseks regulaarsete katastroofi taastamise testide ajal.
- Samuti sotsiaalmeedia Jupyter'i märkmike süsteemi, mis võimaldab arendajatel esitada vabatahtlikke päringuid jälgimistulemustest.
- Toetajad (Lineage Driven Failure Injection) kasutavad jaotatud jälgimisi vigade sisestamise testimiseks.
Ükski ülaltoodud valikutest ei kuulu täielikult tõrke tõrkeotsingu, kus insener püüab probleemile vastust leida, vaadates jälgimist.
Aga kui asi kuid jõuab tõrkeotsingu stsenaariumi, jääb peamine liides diagrammiks traceview (kuigi mõned nimetavad seda ka „Gantt’i diagrammiks“ või „kaskaaddiagrammiks“). All traceview ma kõiki span’e ja seotud metaandmeid, mis koos moodustavad trace’i. Iga avatud lähtekoodiga jälgimissüsteem, samuti iga kommertslahendus jälgimiseks pakub traceview kasutajaliidest trace’ide visualiseerimiseks, detailimiseks ja filtreerimiseks.
Probleem kõigi jälgimissüsteemidega, millega olen siiani kokku puutunud, seisneb selles, et lõpp- visualiseerimine (traceview) peegeldab praktiliselt täielikult trace’i genereerimise protsessi omadusi. Isegi kui pakutakse alternatiivseid visualiseerimisi: intensiivsuse kaardid (heatmap), teenuse topoloogiad, viivituste histogrammid (latency), — lähevad need kõik lõpuks ikkagi kokku traceview.
Varem olen ma selle üle, et enamik „uuendusi“ jälgimise vallas, mis puudutab UI/UX, näib olevat piiratud metaandmete lisamisega trace’i, andmete kõrge kardinaalsusega (high-cardinality) või võimalusega detailida konkreetseid span’e või teha päringuid vahe- ja sisetrahvi. Sellega traceview jääb peamiseks visualiseerimise vahendiks. Nii kaua kui selline olukord püsib, jääb jaotatud jälgimine (parimal juhul) 4. kohale silumisvahendina, millele järgnevad mõõdikud, logid ja stack trace'id, ning halvemal juhul osutub see rahakulutamise ja ajakulu raiskamiseks.
Probleem traceview'ga
Eesmärk traceview — anda täieliku ülevaate konkreetse päringu läbimisest kõikide jaotatud süsteemi komponentide kaudu, millega see seotud on. Mõned edasijõudnumad jälgimissüsteemid võimaldavad üksikute span'ide detailset vaadet ja ajajaotuse analüüsi sisemine ühe protsessi kohta (kui span'id omavad funktsionaalseid piire).
Mikroteenuste arhitektuuri aluspõhimõte on idee, et organisatsiooniline struktuur areneb koos ettevõtte vajadustega. Mikroteenuste toetajad väidavad, et erinevate äriküsimuste jaotamine eraldi teenustele võimaldab väikestel, iseseisvatel arendustiimidel kontrollida nende teenuste kogu elutsüklit, võimaldades neil neid iseseisvalt luua, testida ja juurutada. Siiski on sellise jaotuse puuduseks info kaotamine selle kohta, kuidas iga teenus teistega suhtleb. Sellistes tingimustes pretendeerib jaotatud jälgimine väärtusliku tööriista rollile tõrkeotsingu teenuste vahelistes keerukates suhetes.
Kui teil on tõeliselt , ei ole ükski inimene suuteline hoidma selle täielikku pilti. Tegelikult on tööriista loomine eeldusel, et see on üldse võimalik, midagi sarnast antipattern’ile (efektiivne ja produktiivne lähenemine). Ideaalis on tõrkeotsinguks vajalik tööriist, mis aitab otsingut kitsendada., et insenerid saavad keskenduda probleemiga seotud mõõtmisele (teenused/kasutajad/majad jne), mis on seotud küsimuse stsenaariumiga. Vea põhjuse väljaselgitamisel ei pea insenerid lahendama seda, mis juhtus kõigis teenustes korraga, kuna selline nõudmine läheks vastupidiseks mikroteenuste arhitektuuri loomusele.
Kuid traceview on just see. Jah, mõned jälgimissüsteemid pakuvad kokkuv oldud traceview'd, kui spanide arv jälgis on nii suur, et need ei mahu ühte visualiseerimisse. Kuid isegi sellise kärbitud visualiseerimise kaudu sisalduva teabe mahukuse tõttu peavad insenerid ikkagi это. Да, некоторые системы трассировки предлагают сжатые traceview, когда число span’ов в trace настолько велико, что их невозможно отобразить в рамках одной визуализации. Однако из-за большого объема информации, содержащейся даже в такой урезанной визуализации, инженеры все равно sorteerima seda, kitsendades käsitsi probleemide allikate teenuste valikut. Kahjuks on sellisel alal masinad inimesest palju kiiremad, vähem alti vigadele ning nende tulemused on ühtlasemad.
Veel üks põhjus, miks ma pean traceview meetodit vale olevat, on see, et see ei sobi hästi hüpoteeside põhjalikuks tõrkeotsinguks. Oma olemuselt on tõrkeotsing — see iteraatiivne protsess, mis algab hüpoteesist, millele järgneb erinevate vaatlemiste ja süsteemist saadud faktide kontroll erinevates suundades, järeldused/üldistused ja edasine hüpoteesi tõe hindamine.
Võimalus kiire ja odav hüpoteese testida ja vastavalt vaimset mudelit parandada on aluseks tõrkeotsingule. Iga tõrkeotsingutööriist peab olema interaktiivne ja kitsendama otsinguruumi või, vale jälje korral, lubama kasutajal tagasi minna ja keskenduda süsteemi teisele valdkonnale. Ideaalne tööriist teeb seda ettevaatlikult, tõmmates kasutaja tähelepanu potentsiaalselt probleemsetele aladele kohe.
Kahjuks, traceview ei saa seda nimetada interaktiivse liidese tööriistaks. Parim, millele lootma jääda, on tuvastada mingi viivituste allikas ja vaadata läbi kõik seotud žetoonid ja logid. See ei aita inseneril tuvastada mustreid liikluses, näiteks viivituste jaotumise spetsiifikat, või tuvastada korrelatsioonide esinemist erinevate mõõtmiste vahel. võib aidata mõningaid nendest probleemidest üle saada. Tõepoolest, edukast analüüsist masinõppe abil, et tuvastada anomaalseid span'e ja määratleda alamkogum silte, mis võivad olla seotud anomaalse käitumisega. Siiski pole ma seni kohanud veenvaid visualiseerimisi, mis on tehtud masinõppe või andmeanalüüsi abil span'ide suhtes, mis märgatavalt eristuksid traceview'st või DAG'ist (suunatud ahela graaf).
Span'id on liiga madala taseme
Põhiline probleem traceview's on see, et span'id on liiga madala taseme primaarsed nii viivituste (latency) analüüsimiseks kui ka algpõhjuste määratlemiseks. See on nagu analüüsida üksikuid protsessorikäsklusi, püüdes likvideerida erandeid, teades, et on olemas palju kõrgema taseme tööriistu, nagu backtrace, mis on palju mugavam kasutada.
Pealegi julgen öelda järgmist: ideaalis ei vajaks me täielikku pilti nähtud päringutsükli jooksul, mille tänapäevased jälgimistööriistad esitavad. Selle asemel on vajalik kõrgema taseme abstraktsioon, mis sisaldab teavet selle kohta, mida valesti läks sarnasel printsiibil backtrace'iga, koos mõne kontekstiga. Selle asemel, et jälgida kogu jälgimist, eelistan ma näha selle osa, kus toimub midagi huvitavat või ebatavalist. Praegu toimub otsing käsitsi: insener saab jälgimise ja analüüsib ise span’eid, otsides midagi huvitavat. Lähteviis, kus inimesed tuijotavad span’eid eraldi jälgimistes, lootes avastada kahtlast tegevust, ei ole absoluutselt skaleeritav (eriti kui nad peavad mõtlema kõikidele metaandmetele, mis on kodeeritud erinevatesse span’idesse, nagu span ID, RPC meetodi nimi, span'i kestus, logid, sildid jne).
Alternatiivid traceview'le
Jälgimise tulemused on kõige kasulikud, kui neid saab visualiseerida viisil, mis annab ebatavalise arusaama süsteemi omavahel seotud osade toimimisest. Kuni seda ei ole, jääb tõrkeotsing suuresti inertiaks ja sõltub kasutaja võimest märkida õigeid seoseid, kontrollida süsteemi õigeid osi või koguda mosaiigikilde kokku — erinevalt tööriistast, mis aitab kasutajal neid hüpoteese sõnastada.
Ma ei ole visuaalne disainer ega UX-spetsialist, kuid järgmises osas tahan jagada mõned ideed, kuidas sellised visualiseerimised võiksid välja näha.
Fookus konkreetsetel teenustel
Olukordades, kus tööstus koondub ideede ümber , tundub mõistlik, et eraldiseisvad meeskonnad peaksid kõigepealt jälgima, kas nende teenused vastavad nendele eesmärkidele. Seeläbi teenusele orienteeritud visualiseerimine sobib kõige paremini sellistele meeskondadele.
Trace'id, eriti ilma valikuta, on iga jaotatud süsteemi komponendi kohta teabe kullakaevandused. Seda teavet saab toitma nutikas töötleja, kes tarnib seda kasutajatele. teenustele orienteeritud leidmisi. Neid saab tuvastada ette juba enne, kui kasutaja trace'e vaatab:
- Viivituste jaotuse diagrammid ainult tugevalt eristuvate päringute jaoks (oudlier päringud);
- Viivituste jaotuse diagrammid juhtudel, kui teenuse SLO eesmärke ei saavutata;
- Kõige „üldisemad”, „huvitavamad” ja „imidud” sildid päringutes, mis kõige rohkem korduvad;
- Viivituste jaotus juhtudel, kui sõltuvused teenus ei saavuta seatud SLO eesmärke;
- Viivituste jaotus erinevate alamteenuste vahel.
Mõnele neist küsimustest ei saa sisseehitatud mõõdikud lihtsalt vastata, sundides kasutajaid hoolikalt uurima span'e. Tulemusena on meil äärmiselt kasutajasõbralik mehhanism.
Seetõttu tekib küsimus: kuidas on lood keerukate interaktsioonidega erinevate teenuste vahel, mida hallatakse erinevate meeskondade poolt? Kas tõesti ei? traceview kas see ei peeta kõige sobivamaks tööriistaks sellise olukorra käsitlemiseks?
Mobiiliarendajad, stateless teenuste omanikud, stateful teenuste (nt andmebaaside) omanikud ja platvormide omanikud võivad olla huvitatud muust esitusest jaotatud süsteemist; traceview — see on liiga universaalne lahendus nende põhjalikult erinevate vajaduste jaoks. Isegi väga keerulises mikroteenuste arhitektuuris ei vaja teenuseomanikud sügavaid teadmisi rohkem kui kahe-kolme upstream- ja downstream-teenuse kohta. Sisuliselt on enamikul stsenaariumidest kasutajatele piisav vastata küsimustele, mis puudutavad piiratumat teenuste kogumit..
See on nagu vaadata väikest alamkogumit teenustest suurendusklaasi kaudu põhjalikuks uurimiseks. See võimaldab kasutajal esitada rohkem olulisi küsimusi, mis puudutavad nende teenuste keerulist vastastikust mõju ja nende vahetuid sõltuvusi. See on sarnane tagasijälgimisele teenuste maailmas, kus insener teab, mida kuidas, ja omab ka teatud ülevaadet ümbritsevatest teenustest, et paremini mõista, miks.
Minu lähenemine on täielik vastand ülemise-kuni-alguse lähenemisele, mis põhineb traceview'l, kus analüüs algab kogu trace'ist ja seejärel liigutakse järk-järgult üksikute span'ide poole. Vastupidi, alumise-kuni-ülemise lähenemine algab väikese ala analüüsist, mis on lähedane potentsiaalsele sündmuse põhjusele, ja seejärel laiendatakse otsinguruumi vastavalt vajadusele (võimaliku teiste meeskondade kaasamisega laiemate teenuste analüüsimiseks). Teine lähenemine on paremini kohandatud algsete hüpoteeside kiireks kontrollimiseks. Pärast konkreetsete tulemuste saamist saab liikuda suunatumale ja põhjalikumale analüüsile.
Topoloogia loomine
Konkreetse teenusega seotud vaated võivad olla uskumatult kasulikud, kui kasutaja teab, milline teenus või teenuste rühm põhjustab viivituste suurenemist või on vigade allikaks. Kuid keeruka süsteemi puhul võib teenuse rikkumiste tuvastamine osutuda kriitiliseks ülesandeks rikke ajal, eriti kui teenustelt ei ole saanud tõrketeateid.
Teenuste topoloogia loomine võib olla äärmiselt kasulik, et välja selgitada, milline teenus näitab tõusnud veakordade sagedust või suurenenud viivitust, mis põhjustab märgatavat teenuse kvaliteedi halvenemist. Rääkides topoloogia loomisest, ei pea ma silmas teenuste kaarti, mis kuvab kõiki süsteemis olemasolevaid teenuseid ja on tuntud oma . Selline kujutamine ei ole paremate tulemuste saavutamine kui suunatud acyclic graaf lähtuv traceview. Selle asemel sooviksin näha dünaamiliselt genereeritud teenuste topoloogiat, mis põhineb kindlatel atribuudi, nagu veakordade sagedus, vastuse aeg või mõni kasutaja määratud parameeter, mis aitab selgitada olukorda teatud kahtlaste teenustega.
Vaatame näiteks. Kujutame ette mõnda hüpoteetilist uudiste saiti. Pealehe teenus (front page) vahetab andmeid Redisiga, soovitusteenusega, reklaamiteenusega ja videoserveriga. Videoserver võtab videod S3-st ja metaandmed DynamoDB-st. Soovitusteenus saab metaandmed DynamoDB-st, laadib andmed Redisest ja MySQL-ist, kirjutab sõnumeid Kafka-sse. Reklaamiteenus saab andmed MySQL-ist ja kirjutab sõnumeid Kafka-sse.
Allpool on skeem selle topoloogia kohta (paljud kommertsprogrammid koostavad topoloogiat jälgimiseks). See võib olla kasulik, kui on vaja aru saada teenuste sõltuvustest. Kuid ajal, tõrkeotsingu, kui mingi teenus (ütleme, videoserver) näitab pikendatud reageerimisaega, ei ole selline topoloogia eriti kasulik.
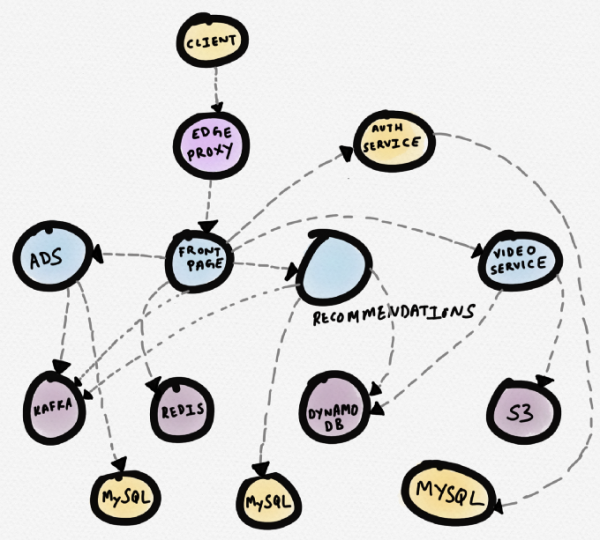
Hüpoteetilise uudiste veebisaidi teenuste skeem
Paremini sobiks diagramm, mis on allpool kujutatud. Sellel on probleemne teenus (video) kujutatud otse keskel. Kasutaja märgib selle kohe. Antud visualiseerimisest on selge, et videoserver töötab anomaalselt, kuna S3 reageerimisaeg on pikenemas, mis mõjutab osa avalehe laadimiskiirusest.
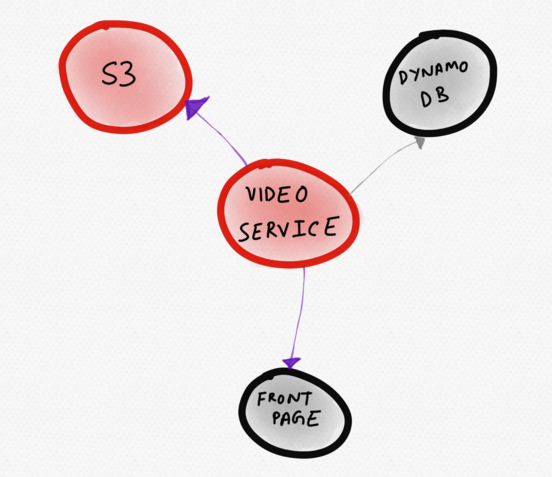
Dünaamiline topoloogia, mis kuvab ainult "huvitavad" teenused
Dünaamiliselt genereeritud topoloogilised skeemid võivad olla tõhusamad kui staatilised teenuste kaardid, eriti paindlikes ja automaatselt skaleeritavates infrastruktuurides. Teenuste topoloogiate võrdlemise ja vastandamise võimalus võimaldab kasutajal esitada asjakohasemaid küsimusi. Täpsemad küsimused süsteemi kohta toovad suurema tõenäosusega kaasa parema arusaama selle toimimisest.
Võrdlev kuvamine
Veel üks kasulik visualiseerimine on võrdlev kuvamine. Praegu ei sobi jälgimised eriti hästi kõrvuti võrdlemiseks, seega tavaliselt võrreldakse span'id. Peamine idee selle artikli juures ongi see, et span'id on liiga madala taseme detailid, et välja tuua kõige väärtuslikumat teavet jälgimistulemuste põhjal.
Kahte trace’i võrdlemine ei nõua radikaalselt uusi visualiseerimisi. Tegelikult piisab mingist sarnast nagu histogramm, mis esindab samu andmeid, mis traceview. Üllatav, kuid isegi see lihtne meetod võib anda palju rohkem tulemusi kui kahe trace’i eraldi uurimine. Veelgi võimsam oleks võimalus visualiseerida trace’ide võrdlemist koos juba mainitud direktiiviga. Olekse äärmiselt kasulik näha, kuidas hiljuti juurutatud andmebaasi konfiguratsiooni muutmine koos GC (jäätmete kogumise) sisselülitamisega mõjutab downstream-teenuse reageerimisaega mitme tunni jooksul. Kui see, mida ma siin kirjeldan, tundub olevat sarnane A/B analüüsile infrastruktuuri muutuste mõjude kohta paljudes teenustes kasutades jälgimistulemusi, siis sa ei ole tõest liiga kaugel.
Kokkuvõte
Ma ei sea kahtluse alla jälgimise kasulikkust. Olen kindel, et puudub muu meetod, millega koguda sama rikkalikku, kontekstitundlikku ning turvalist teavet nagu jälgimised. Siiski usun, et kõik jälgimislahendused kasutavad neid andmeid äärmiselt ebaefektiivselt. Niikaua, kuni jälgimistööriistad on kinni traceview-esituses, on neil piiratud võimalused maksimaalselt ära kasutada väärtuslikku teavet, mida võib extraktida jälgimiste andmetest. Lisaks on olemas oht luua täiesti ebamugav ja mitteintuitiivne visuaalne liides, mis piirab tõsiselt kasutaja võimalusi rakenduse tõrgete leidmiseks.
Ahnade süsteemide tõrkeotsing, isegi uusimate tööriistade kasutamisel, on äärmiselt keeruline. Tööriistad peaksid aitama arendajal formuleerida ja kontrollida hüpoteesi, aktiivselt pakkudes asjakohast teavet, tuvastades kõrvalekaldeid ja märkides viivituste jaotuse eripärasid. Et jälgimine muutuks arendajate jaoks eelistatud tööriistaks tootmissüsteemide rikete lahendamisel või erinevaid teenuseid hõlmavate probleemide lahendamisel, on vajalikud originaalsed kasutajaliidesed ja visualiseerimised, mis vastavad rohkem arendajate vaimsele mudelile, kes loovad ja haldavad neid teenuseid.
On vajalik tõsine vaimne pingutus, et kavandada süsteem, mis esindab erinevaid signaale, mis on kättesaadavad jälgimise tulemustes, viisil, mis on optimeeritud analüüsi ja järelduste tegemise hõlbustamiseks. Tuleb hoolikalt mõelda, kuidas süsteemi topoloogiat siluda tõrkeotsingu ajal, et aidata kasutajal ületada pimedad kohad, ilma et peaks vaatama üksikuid jälgimisi või ulatusi.
Me vajgivad head abstraktsiooni ja kihistamise võimalused (eriti kasutajaliideses). Sellised, mis sobivad hästi hüpoteeside põhjalikku silumise protsessi, kus saab iteratiivselt küsimusi esitada ja hüpoteese kontrollida. Need ei lahenda automaatselt kõiki jälgitavuse probleeme, kuid aitavad kasutajatel oma intuitsiooni teravdada ja kaalu leidma paremaid küsimusi. Kutsun üles arvestama süvitsi minevate ja innovaatiliste lähenemistega visualiseerimise valdkonnas. Siin on tõeline perspektiiv silmaringi laiendamiseks.
P.S. tõlkija märkused
Lugege ka meie blogist:
- «»;
- «»;
- «».
Allikas: habr.com
