

CAP-teoreem on jaotatud süsteemide teooria nurgakivi. Loomulikult ei vaibunud vaidlused selle ümber: definitsioonid ei ole kanonilised ja ranget tõestust ei ole... Sellegipoolest, seistes kindlalt koduse mõistuse positsioonidel™, mõistame me intuitiivselt, et teoreem on õige.

Ainus, mis ei ole ilmselge, on tähendus täht «P». Kui klaster jaguneb, otsustab see – kas mitte vastata, kuni kvoorum on saavutatud, või anda andmed, mis on olemas. Sõltuvalt selle valiku tulemustest klassifitseeritakse süsteem kas CP- või AP-na. Näiteks võib Cassandra käituda nii või teisiti, sõltuvalt isegi mitte klastrite seadistustest, vaid iga konkreetse päringu parameetritest. Kuid kui süsteem ei ole «P» ja see on jagunenud, siis – mis siis?
Selle küsimuse vastus on üllatav: CA-klaster ei saa jaguneda.
Mis klaster see siis on, mis ei saa jaguneda?
Sellise klastriga on hädavajalik ühine andmesalvestussüsteem. Enamikul juhtudel tähendab see ühendust SAN-iga, mis piirab CA-lahenduste rakendamist suurte ettevõtetega, kes suudavad hallata SAN-infrastruktuuri. Selleks, et mitu serverite saaksid töötada sama andmetega, on vajalik klastrifailisüsteem. Sellised failisüsteemid on HPE (CFS), Veritas (VxCFS) ja IBM (GPFS) portfellides.
Oracle RAC
Real Application Clusteri valik ilmus esmakordselt 2001. aastal Oracle 9i väljaandes. Sellises klastris töötavad mitu instantsi serverile ühe ja sama andmebaasiga.
Oracle saab töötada nii klastrifailisüsteemiga kui ka oma lahendusega – ASM, Automatic Storage Management.
Iga instants peab oma ajalugu. Tehing toimub ja fikseeritakse ühe instantsi poolt. Kui instants ebaõnnestub, loeb klastris ellujäänud sõlm (instants) selle ajalugu ja taastab kadunud andmed – seeläbi tagatakse kättesaadavus.
Kõik eksemplarid toetavad oma vahemälu, ning samad leheküljed (plokid) võivad samaaegselt asuda mitu eksemplari vahemälus. Veelgi enam, kui mõni leht on vajalik ühele eksemplarile ja see on teise eksemplari vahemälus olemas, võib ta selle „naabrilt“ saada cache fusion mehhanismi kaudu, selle asemel et lugeda kettalt.
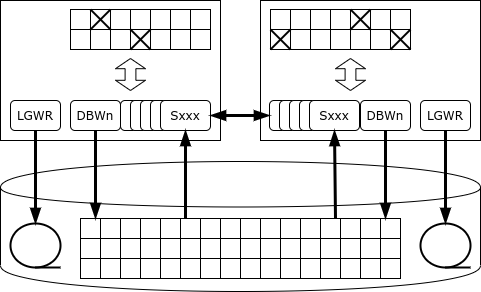
Aga mis juhtub, kui ühel eksemplaril on vaja andmeid muuta?
Oracle'i eripära on see, et tal ei ole eraldi lukustusteenust: kui server soovib rida lukustada, siis lukustuse registroitakse otse selle mälu leheküljel, kus lukustatav rida asub. Selle lähenemise tõttu on Oracle monoliitsete andmebaaside seas jõudlustaseme osas liider: lukustusteenus ei muutu kunagi kitsaskohaks. Kuid klastrikonfiguratsioonis võib selline arhitektuur viia intensiivse võrguvahetuse ja vastastikuste lukustusteni.
Kui kirje on lukustatud, teavitab instants kõik teised instantsid, et leht, millel see kirje asub, on hõivatud monopolerežiimis. Kui teisele instantsile peaks olema vajalik sama lehe kirje muutmine, peab see ootama, kuni lehe muudatused on fikseeritud, st teave muudatuste kohta on kirjutatud logisse kettale (sel ajal võib tehing jätkuda). Võib juhtuda ka, et lehte muudab järjestikku mitu instantsi, ning sel juhul tuleb lehe kettale kirjutamisel välja selgitada, kellel on selle lehe aktuaalne versioon.
Sama lehtede juhuslikud uuendused erinevate RAC sõlmede kaudu põhjustavad andmebaasi jõudluse järsu languse – kuni selleni, et klastrite jõudlus võib olla madalam kui ühe instantsi jõudlus.
Oracle RAC-i õige kasutamine tähendab andmete füüsilist jagamist (näiteks sektsioonitud tabelite mehhanismi abil) ning iga sektsiooni kogumi juurde pääsemist eraldi sõlme kaudu. RAC-i peamine eesmärk ei ole horisontaalne skaleerimine, vaid töökindluse tagamine.
Kui sõlm ei vasta heartbeat-signaalile, siis sõlm, mis seda esimesena avastab, käivitab diskihääletuse protseduuri. Kui ka siin ei ennusta kadunud sõlm oma kohalolekut, võtab üks sõlmedest endale vastutuse andmete taastamise eest:
- „külmutab” kõik lehed, mis olid kadunud sõlme vahemälus;
- loeb kadunud sõlme uuenduste logisid ja rakendab uuesti need muudatused, mis on nende logides kirjas, samas kontrollides, kas teistel sõlmedel on muutunud lehtede uuemad versioonid;
- tagastab lõpetamata tehingud.
Sõlmede vahel sujuva ülemineku lihtsustamiseks on Oracle'is mõisted, nagu teenus – virtuaalne eksemplar. Eksemplar võib teenindada mitut teenust ja teenus võib liikuda sõlmede vahel. Rakenduse eksemplar, mis teenindab kindlat osa andmebaasist (näiteks kliendirühma), töötab ühe teenuse olemasolu alusel, samas kui teenus, mis vastutab selle andmebaasi osa eest, liigub sõlme rikke korral teisele sõlmele.
IBM Pure Data Systems for Transactions
Klastrilahendus andmebaasisüsteemidele ilmus Suure Sinise portfelli 2009. aastal. Ideoloogiliselt on see pärand paralleelsüsteemide klastri Parallel Sysplex, mis on üles ehitatud "tavalisel" riistvaral. 2009. aastal ilmus toode DB2 pureScale, mis on tarkvarapakett, ja 2012. aastal pakkus IBM programmeeritud riistvara komplekti nimega Pure Data Systems for Transactions. Seda ei tohi segamini ajada Pure Data Systems for Analytics'iga, mis pole midagi muud kui ümbernimetatud Netezza.
PureScale'i arhitektuur näeb esmapilgul välja nagu Oracle RAC: mitmed sõlmed on ühendatud ühise andmesalvestussüsteemiga, kus igal sõlmel töötab oma andmebaasiserver koos oma mälualade ja tehingulogidega. Erinevalt Oracle'ist on DB2-s eraldatud lukustusservice, mida esindab db2LLM* protsesside kogum. Klassivälises konfiguratsioonis viiakse see teenus üle eraldi sõlmele, mida Parallel Sysplexis nimetatakse coupling facility (CF) ja Pure Data puhul – PowerHA.
PowerHA pakub järgmisi teenuseid:
- lukustuse haldur;
- globaalne puhvermälu;
- vaheprotsesside kommunikatsioonipiirkond.
Andmete edastamiseks PowerHA-st andmebaasisõlmedesse ja tagasi kasutatakse kaugjuurdepääsu mälule, mistõttu peab klastrisiseselt ühendus toetama RDMA protokolli. PureScale saab kasutada nii Infiniband'i kui ka RDMA üle Ethernet'i.
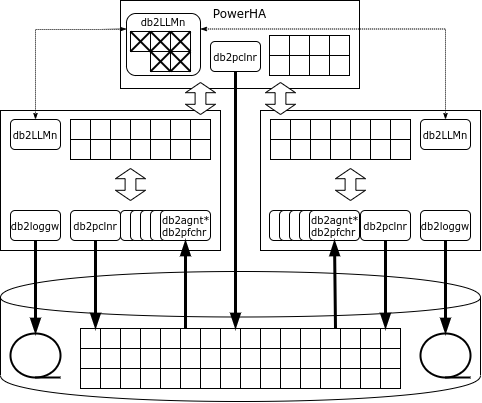
Kui sõlm vajab lehte ja see leht ei ole puhvris, siis sõlm küsib lehte globaalsest puhvrist, ja ainult juhul, kui seda seal samuti ei ole, loetakse see kettalt. Erinevalt Oracle'ist läheb päring ainult PowerHA-sse, mitte külgnevatesse sõlmedesse.
Kui eksemplar kavatseb rida muuta, lukustab ta selle eksklusiivses režiimis ja lehe, kus rida asub, jagatud režiimis. Kõik lukud registreeritakse globaalsete lukuhalduri tehingutes. Kui tehing on lõpetatud, saadab sõlme lukuhaldurile sõnumi, mis kopeerib muudetud lehe globaalde kihti, vabastab lukud ja invalideerib muudetud lehe teiste sõlmede vahemälu.
Kui leht, kus asub muudetav rida, on juba lukustatud, loeb lukuhaldur muudetud lehe sõlme mälust, mis muudatused tegi, vabastab lukud, invalideerib muudetud lehe teiste sõlmede vahemälus ja annab lehe lukustamise üle sõlmele, kes seda soovis.
«Mustad», st muudetud, lehed võivad olla salvestatud kettale nii tavalise sõlme kui ka PowerHA (castout) kaudu.
Kui üks pureScale sõlmedest tõrge, on taastamine piiratud ainult nende tehingutega, mis hetkel, mil tõrge toimus, polnud veel lõpetatud: tehingutes muudetud lehed on globaalses vahemälus PowerHA-s. Sõlm taaskäivitub piiratud konfiguratsiooniga ühe klastriserveri peal, rullides tagasi lõpetamata tehingud ja vabastades lukud.
PowerHA töötab kahel serveril, ja peamine sõlm replikeerib oma oleku sünkroonselt. Kui peamine PowerHA sõlm tõrgeb, jätkab klaster tööd reservsõlmega.
Muidugi, kui andmestikku puudutatakse läbi ühe sõlme, on klastrite kogutootlikkus kõrgem. PureScale võib isegi märkida, et teatud andmeala töödeldakse ühe sõlmega, ning siis töödeldakse kõik sellele alale, mis kuulub sellele, kohalikult ilma suhtluse PowerHA-ga. Kuid niipea, kui rakendus proovib neile andmetele juurde pääseda teise sõlme kaudu, jätkub tsentraliseeritud lukustamisprotsess.
IBM-i sise testid, kus 90% on lugemine ja 10% kirjutamine, mis on väga sarnane reaalsele tööstuslikele koormustele, näitavad peaaegu lineaarselt laienemist kuni 128 sõlmeni. Kahjuks ei avalikustata testimise tingimusi.
HPE NonStop SQL
Hewlett-Packard Enterprise'i portfellis on ka oma kõrgeAvailabilitas platvorm. See on NonStop platvorm, mis toodi turule 1976. aastal ettevõtte Tandem Computers poolt. 1997. aastal omandas ettevõtte Compaq, mis omakorda liitus 2002. aastal Hewlett-Packardiga.
NonStop'i kasutatakse kriitiliste rakenduste, näiteks HLR-i või pankakaartide töötlemise, ehitamiseks. Platvorm on pakitud programmid-hardware kompleksi (appliance), mis sisaldab arvutusnode, andmesalvestussüsteemi ja kommunikatsiooniseadmeid. ServerNeti võrk (kaasaegsetes süsteemides Infiniband) teenib nii sõlmede vahelise suhtluse kui ka andmesalvestussüsteemi juurdepääsu.
Varasemates süsteemi versioonides kasutati patenteeritud protsessoreid, mis olid omavahel sünkroniseeritud: kõik toimingud teostasid mitmed protsessorid sünkroonselt, ja kui üks protsessor eksis, katkestati see, samal ajal kui teine jätkas tööd. Aja jooksul läks süsteem üle tavalistele protsessoritele (alguses MIPS, seejärel Itanium ja lõpuks x86), ning sünkroniseerimiseks hakati kasutama teisi mehhanisme:
- teated: igal süsteemi protsessil on kaksik-"vari", kellele aktiivne protsess perioodiliselt saadab sõnumeid oma olekust; kui peamine protsess ebaõnnestub, hakkab variprotsess tööle viimasest sõnumist määratud hetkel;
- hääletus: andmesalvestussüsteemil on spetsiaalne riistvarakomponent, mis võtab vastu mitu sama sisendit ja teostab need ainult siis, kui sisendid kattuvad; füüsilise sünkroniseerimise asemel töötavad protsessorid asünkroonselt, ning nende töö tulemusi võrreldakse ainult sisendi/väljundi hetkedel.
Alates 1987. aastast töötab NonStop platvormil relatsiooniline andmebaasisüsteem – alguses SQL/MP ja hiljem – SQL/MX.
Kogu andmebaas jaguneb osadeks, mille eest vastutab igaühe oma andmejuhtimise protsess (Data Access Manager - DAM). See tagab andmete salvestamise, vahemälestuse ja lukustamismehhanismi. Andmete töötlemisega tegelevad täitmisprotsessid (Executor Server Process), mis töötavad samadel sõlmedel kui vastavad andmejuhid. SQL/MX ajakava jagab ülesanded täitjatele ja ühendab tulemused. Kooskõlastatud muudatuste tegemiseks kasutatakse kahefaasilist kinnitamise protokolli, mida tagab TMF (Transaction Management Facility) teeki.
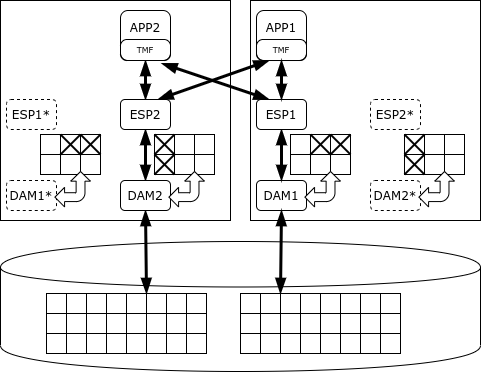
NonStop SQL oskab prioriseerida protsesse nii, et pikad analüütilised päringud ei takista tehingute täitmist. Kuid selle peamine eesmärk on just lühikeste tehingute töötlemine, mitte analüüs. Arendaja garanteerib NonStop klastrite saadavuse viie „üheksanda“ tasemel, mis tähendab, et katkestus ei ületa 5 minutit aastas.
SAP HANA
Esimene stabiilne HANA andmebaasi versioon (1.0) ilmus novembris 2010 ning SAP ERP pakett ülemineku HANA-le toimus maist 2013. Platvorm põhineb ostetud tehnoloogiatel: TREX otsingumootor (veergude salvestuses), P*TIME andmebaasi ja MAX DB-l.
Sõna «HANA» on akronüüm, mis tähistab High performance ANalytical Appliance. See andmebaasisüsteem tarnitakse koodina, mis suudab töötada igasugustes x86 serverites, kuid tööstuslikud installatsioonid on lubatud ainult sertifitseeritud seadmetel. Saadaval on lahendused HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi ja NEC. Mõned Lenovo konfiguratsioonid võimaldavad isegi töötamist ilma SAN-ita – ühise salvestuslahenduse rolli täidab GPFS-klaster kohalike kõvaketaste peal.
Erinevalt eespool loetletud platvormidest on HANA mäluandmebaas, st algne andmete koopia salvestatakse mällu, samas kui kettale salvestatakse ainult ajakirjad ja perioodilisedSnapshots – taaste jaoks avarii korral.
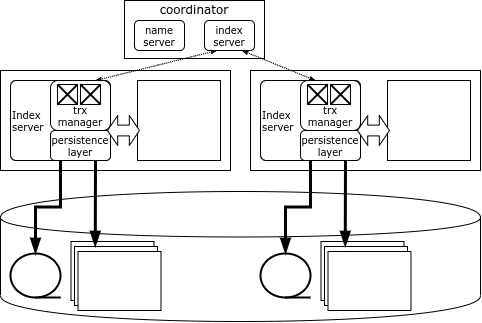
Iga HANA klastrisõlm vastutab oma andmete osa eest, samas kui andmekartograafia salvestatakse spetsiaalses komponendis – Nime Server, mis asub koordinaatorisõlmes. Andmed ei dubleeru sõlmede vahel. Teave lukustuste kohta salvestatakse samuti igas sõlmes, kuid süsteemis on olemas globaalne üksteise lukustamise detektor.
HANA klient ühenduse loomisel klastri anatoomilised andmed ja seejärel saavad nad otse pöörduda ükskõik millise sõlme poole vastavalt vajalikele andmetele. Kui tehing hõlmab ainult ühe sõlme andmeid, saab selle teostada kohapeal, kuid kui muudetakse mitme sõlme andmeid, pöördub algatanud sõlm koordinaatori poole, kes avab ja koordineerib jaotatud tehingu, salvestades selle optimeeritud kahefaasilise kinnituse protokolli abil.
Koordinaatorisõlm on dubleeritud, seega, kui koordinaator läheb välja, astub koheselt mängu varusõlm. Kui aga sõlm, kus andmed asuvad, rikki läheb, on ainus viis nende andmeteni pääsemiseks sõlme taaskäivitamine. Üldiselt hoitakse HANA klastrites varuserverit (spare), et kadunud sõlm võimalikult kiiresti taaskäivitada.
Allikas: habr.com
