

Tere, Habra elanikud. Nagu juba eelnevalt mainisime, käivitab OTUS sel kuul kaks masinõppe kursust, nimelt ja . Seetõttu jagame jätkuvalt kasulikku materjali.
Selle artikli eesmärk on rääkida meie esimesest kogemusest kasutades .
. Alustame ülevaatetest selle jälgimisserverist ning logime kõik uurimisiteratsioonid. Seejärel jagame kogemust Spark'i ühendamisest MLflow'ga UDF kaudu. с его tracking-сервера и прологируем все итерации исследования. Затем поделимся опытом соединения Spark с MLflow с помощью UDF.
Kontekst
Meie ITGLOBAL.COM kasutab masinõpet ja tehisintellekti, et anda inimestele võimalus hoolitseda oma tervise ja heaolu eest. Seetõttu on masinõppe mudelid meie andmete töötlemise toote aluseks, ja just seetõttu köitis meid MLflow — avatud lähtekoodiga platvorm, mis katab masinõppe eluiga.
MLflow
MLflow'i peamine eesmärk on pakkuda masinõppe kohal täiendavat kihti, mis võimaldaks andmete teadlastel töötada praktiliselt iga masinõppe raamatukoguga (, , , , ja ), tõstes selle töö uuele tasemele.
MLflow pakub kolme komponenti:
- Jälgimine – eksperimentide salvestamine ja päringud: kood, andmed, konfiguratsioon ja tulemused. Mudeli loomise protsessi jälgimine on väga oluline.
- Projektid – pakendamisformat, et käivitada igasugustel platvormidel (näiteks, )
- Mudeli – üldine formaat mudelite saatmiseks erinevatesse juurutustööriistadesse.
MLflow (artikli kirjutamise hetkel alpha-versioon) on avatud lähtekoodiga platvorm, mis võimaldab hallata masinõppe elutsüklit, sealhulgas eksperimente, taaskasutust ja juurutamist.
MLflow seadistamine
MLflow kasutamiseks tuleb esmalt seadistada kogu Python keskkond, selleks kasutame (kui soovite Pythonit Macile installida, vaadake ). Nii suudame luua virtuaalse keskkonna, kuhu installime kõik vajalikud teegid.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Kasutage Python 3.7
mkvirtualenv mlflow # Looge virtuaalne keskkond Python 3.7-ga
workon mlflow
```Installime vajalikud teegid.
```
pip install mlflow==0.7.0
Cython==0.29
numpy==1.14.5
pandas==0.23.4
pyarrow==0.11.0
```Märkus: kasutame PyArrow mudeleid, nagu UDF. PyArrow ja Numpy versioone tuli korrigeerida, kuna viimased versioonid olid omavahel vastuolus.
Käivitame jälgimise kasutajaliidese.
MLflow Tracking võimaldab meil logida ja pärida eksperimente Pythonis ja API kaudu. Lisaks on võimalik määrata, kus hoida mudeli artefakte (localhost, , , või ). Kuna Alpha Health kasutab AWS-i, on artefaktide ladustamiseks S3.
# Running a Tracking Server
mlflow server
--file-store /tmp/mlflow/fileStore
--default-artifact-root s3://<bucket>/mlflow/artifacts/
--host localhost
--port 5000 MLflow soovitab kasutada püsivat failide ladustamist. Failide ladustamine on koht, kus server hoiab käivituste ja eksperimentide metainfot. Serverit käivitades veenduge, et see viitaks püsivale failide ladustamisele. Siin eksperimendi jaoks kasutame lihtsalt /tmp.
Pidage meeles, et kui soovime kasutada mlflow serverit vanade eksperimentide käivitamiseks, peavad need olema failide ladustamises olemas. Kuid ka ilma selleta saaksime neid kasutada UDF-is, kuna meil on vaja lihtsalt mudeli teed.
Märkus: Pidage meeles, et Tracking UI ja mudeli klient peavad olema ligipääsetavad artefakti asukohale. See tähendab, et olenemata sellest, et Tracking UI asub EC2 instantsis, peab MLflow käitamise ajal masinal olema otsene ligipääs S3-le artefaktide mudelite kirjutamiseks.
Tracking UI hoiab artefakte S3-s
Mudelite käivitamine
Niipea kui Tracking-server töötab, saab alustada mudelite koolitamist.
Käesoleva näitena kasutame MLflow näite modifikatsiooni veinist .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py
--alpha 0.9
--l1_ratio 0.5
--wine_file ./data/winequality-red.csvKuna me juba ütlesime, MLflow võimaldab logida parameetreid, mõõdikuid ja mudelite artefakte, et saaksime jälgida, kuidas need iteratsioonide käigus arenevad. See funktsioon on äärmiselt kasulik, kuna nii saame taastada parima mudeli, pöördudes Tracking-serveri poole või mõistes, millist koodi vajaliku iteratsiooni täitmiseks kasutati, tuginedes git hash commit'ide logidele.
with mlflow.start_run():
... mudel ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model") 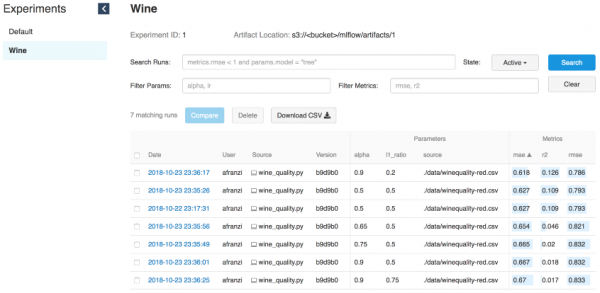
Veini iteratsioonid
Mudelile mõeldud serveripoolne osa
MLflow jälgimisserver, mis on käivitatud käsklusega "mlflow server", omab REST API-d, mis võimaldab jälgida käivitusi ja salvestada andmeid kohalikku failisüsteemi. Saate määrata jälgimisserveri aadressi keskkonnamuutuja "MLFLOW_TRACKING_URI" abil ning MLflow jälgimise API ühendab automaatselt selle aadressiga, et luua/saada teavet käivituste, logi mõõtmete jne kohta.
Allikas:
Mudeli teenindamiseks vajame käivitatud jälgimisserverit (vt käivitamise liidest) ja mudeli Run ID-d.

Run ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve
--port 5005
--run_id 0f8691808e914d1087cf097a08730f17
--model-path model Mudelite teenindamiseks MLflow serve funktsiooni abil vajame juurdepääsu jälgimise kasutajaliidesele, et saada mudeli teavet lihtsalt märkimisega --run_id.
Kui mudel on ühendatud jälgimisserveriga, saame uue mudeli lõpp-punkti.
# Query Tracking Server Endpoint
curl -X POST
http://127.0.0.1:5005/invocations
-H 'Content-Type: application/json'
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Mudelite käitamine Sparkis
Kuigi jälgimisserver on piisavalt võimas, et teenindada reaalajas mudeleid, nende koolitust ja kasutada serve funktsiooni (allikas: ), on Spark (batoon või voog) veelgi võimsam lahendus tänu jaotusele.
Kujutage ette, et olete just läbi viinud koolituse offline-režiimis ja seejärel rakendanud väljundi mudeli kõikidele oma andmetele. Just siin näitavad Spark ja MLflow oma parimat külge.
Paigaldame PySpark + Jupyter + Spark
Allikas:
Kuna soovime näidata, kuidas rakendame MLflow mudeleid Spark'i andmepakettidesse, peame seadma Jupyter notebookide koostöö PySparkiga.
Alustage viimase stabiilse versiooni paigaldamisest :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/sparkPaigaldage PySpark ja Jupyter virtuaalsesse keskkonda:
pip install pyspark jupyterSeadistage keskkonnamuutujad:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks" Määrates notebook-dir, saame hoida meie notebookid soovitud kaustas.
Käivita Jupyter PySparkist
Kuna suudame seadistada Jupyter PySpark'i draiveriks, saame nüüd käivitada Jupyter notebooki PySpark'i kontekstis.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic laiendamine on lubatud!
[I 19:05:01.573 NotebookApp] Teen notebooks kohaliku katalooge: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] Jupyter Notebook töötab:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Kasutage Control-C, et peatada see server ja sulgeda kõik kernlid (kaks korda, et skip kinnitamine).
[C 19:05:01.574 NotebookApp]
Kopeerige/tehke kleepige see URL oma brauserisse, kui te esmakordselt ühendate,
et sisse logida tokeniga:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745 
Nagu eelnevalt mainitud, pakub MLflow mudeli artefaktide logimise funktsiooni S3-s. Kui meil on valida mudel, saame selle importida UDF-na mooduli kaudu mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3:///mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False) 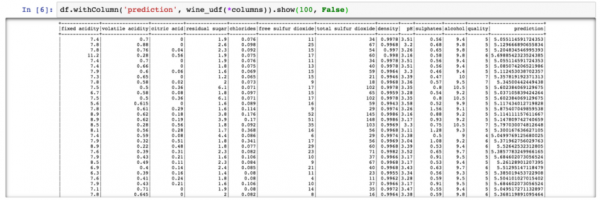
PySpark – Veini kvaliteedi prognoosi väljund
Seni oleme rääkinud, kuidas kasutada PySpark'i koos MLflow'ga, käivitades veini kvaliteedi prognoosi kogu veiniandmete kogumi peal. Aga mida teha, kui soovite kasutada Python MLflow mooduleid Scala Spark'ist?
Me testisime ka seda, jagades Spark'i konteksti Scala ja Python'i vahel. Ehkki registreerisime MLflow UDF'i Python'is ja kasutasime seda Scala's (jah, see ei pruugi olla parim lahendus, aga mis meil on).
Scala Spark + MLflow
Selle näite jaoks lisame olemasolevasse Jupiterisse.
Installeerime Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Saadaval olevad kernelid:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Kuidas näha lisatud märkmekotis, kasutatakse UDF'i koos Spark'i ja PySpark'iga. Loodame, et see osa on kasulik neile, kes armastavad Scala't ja soovivad rakendada masinõppe mudeleid tootmises.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf..predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Järgmised sammud
Kuigi MLflow on artikli kirjutamise ajal veel Alpha-versioonis, näeb see välja üsna lubav. Üksnes võimalus kasutada mitut masinõppe raamistikku ja pääseda neile ligi ühest lõpp-punktist viib soovitus süsteemid uuele tasemele.
Lisaks toob MLflow andmeinsenerid ja andmete teadlased kokku, luues nende vahel ühise kihi.
Pärast seda MLflow uurimist usume, et liigume edasi ja hakkame seda kasutama oma Spark-i torustikes ja soovitus süsteemides.
Olaks tore sünkroniseerida failide salvestusruum andmebaasiga, mitte failisüsteemiga. Nii peaksime saama mitu lõpp-punkti, mis saavad kasutada samu faile. Näiteks kasutada mitut instantsi ja ühe ja sama Glue metastore'iga.
Kokkuvõtteks tahaksime tänada MLFlow kogukonda, et muudate meie andmetöötluse huvitavamaks.
Kui mängite MLflow'ga, ärge kartke meile kirjutada ja rääkida, kuidas te seda kasutate, eriti kui kasutate seda tootmises.
Lisainfot kursuste kohta:
Loe edasi:
Allikas: habr.com
