

See artikkel on juba teine teema andmete kiirusest tihendamisest. Esimeses artiklis kirjeldati kompressorit, mis töötab kiirusel 10 Gbit/s ühe protsessorituuma kohta (minimaalne tihendamine, RTT-Min).
See kompressor on juba juurutatud kriminaalsete dubleerijate seadmetesse, et kiiresti tihendada andmehoidlate sisulisi andmeid ja suurendada krüptograafia vastupidavust. Samuti saab seda kasutada virtuaalmasinate piltide ja operatiivmälu swap-failide tihendamiseks, kui need salvestatakse kiiretoimelistesse SSD-kettadesse.
Esimeses artiklis kuulutati välja ka HDD ja SSD kõvakettade varukoopiate tihendamiseks mõeldud kompressioonialgoritmi arendamine (keskmine tihendamine, RTT-Mid), millel on oluliselt parendatud andmete tihendamise näitajad. Käesolevaks ajaks on see kompressor täielikult valmis ja see artikkel räägib just sellest.
Kompressor, mis rakendab RTT-Mid algoritmi, tagab tihendamisastme, mis on võrreldav standardsete arhiivide nagu WinRar ja 7-Zip kiirusrežiimis. Samal ajal on selle töökiirus vähemalt kümme korda kõrgem.
Andmete pakkimise/avamise kiirus on kriitiline parameeter, mis määrab kompressioonitehnoloogiate rakenduse ulatuse. Keegi ilmselt ei mõtle terabaidi andmete tihendamisele kiirusel 10-15 megabitti sekundis (just selline on arhiivide standardkompressiooni kiirus), sest sellele kulub peaaegu kakskümmend tundi, kui protsessor on täielikult koormatud…
Teisest küljest saab sama terabaidi kopeerida kiirusel umbes 2-3 gigabitti sekundis umbes kümne minutiga.
Seetõttu on suurte andmehulkade tihendamine asjakohane, kui see toimub kiirusel, mis ei ole madalam tegelikest sisend-/väljundkiirusest. Kaasaegsete süsteemide jaoks on see vähemalt 100 megabitti sekundis.
Selliseid kiirusenäitajaid saavad kaasaegsed kompressorid näidata ainult "kiire" režiimis. Just selles asjakohases režiimis teeme võrdluse algoritmi RTT-Mid ja traditsiooniliste kompressorite vahel.
Uue kompressioonialgoritmi võrdlev testimine
RTT-Mid kompressor töötas testprogrammis. Tõelises „töös“ rakenduses töötab see märgatavalt kiiremini, kus kasutatakse efektiivselt mitme lõime töötlemist ja rakendatakse „tavalist“ kompilaatorit, mitte C#.
Kuna võrdlustestis kasutatud kompressorid on ehitatud erinevatel alustel ja erinevad andmetüübid kompressivad erinevalt, kasutati testi objektiivsuse tagamiseks keskmise temperatuuri mõõtmise meetodit...
Loodi sektorite kaupa dumpfail loogilisest draivist operatsioonisüsteemiga Windows 10, mis esindab kõige loomulikumat erinevate andmestruktuuride segu, mis on iga arvuti peal olemas. Selle faili tihendamine võimaldab võrrelda uue algoritmi kiirus ja kompressioonimäär kaasaegsete arhiivide tõhusate kompressoritega.
Siin on see dumpfail:
Dumpfaili tihendamisel kasutasid RTT-Mid, 7-zip ja WinRar kompressoreid. WinRar ja 7-zip kompressorid olid seadistatud maksimaalse töökiirusena.
Töötav kompressor 7-zip:
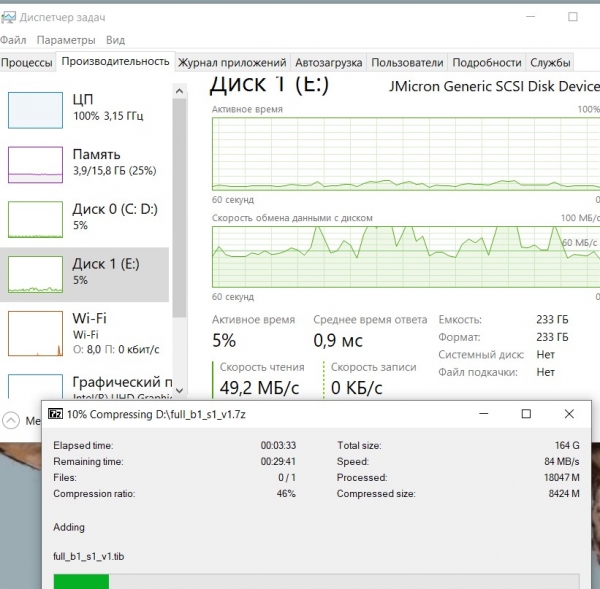
See koormab protsessorit 100%, samas kui keskmine lugemiskiirus lähtedumpi puhul on umbes 60 megabaiti/sek.
Töötav kompressor WinRar:
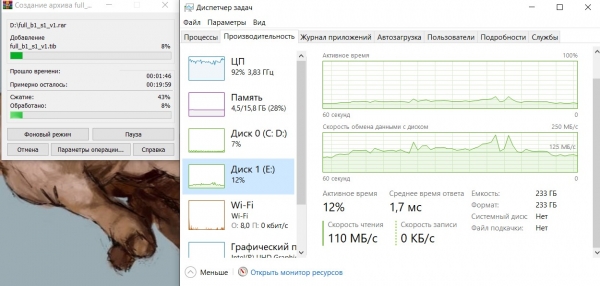
Seisund on sarnane, protsessori koormus on praktiliselt 100%, keskmine dump-lugemise kiirus on umbes 125 megabaiti/s.
Nagu eelmisel juhul, on arhiivimise kiirus piiratud protsessori võimalustega.
Nüüd töötab testprogramm kompressorile. RTT-Mid:
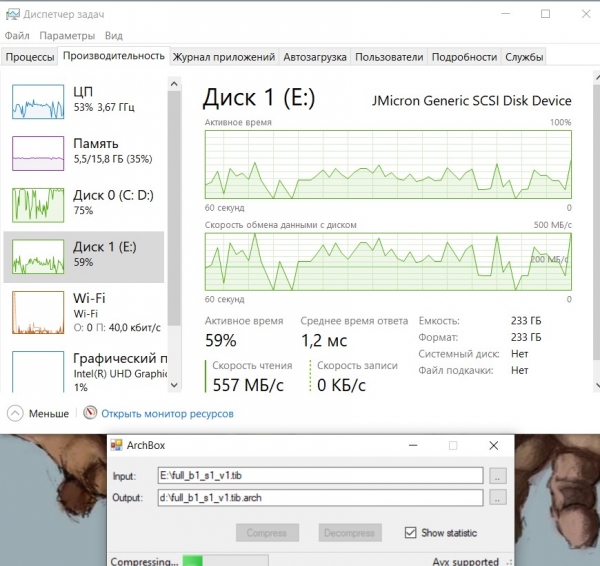
Kuvatud ekraanipilt näitab, et protsessor on koormatud 50% ja ülejäänud aja ootab, kuna kompressitud andmeid ei ole kuhugi laadida. Andmete laadimisdisk (Disk 0) on praktiliselt täielikult täidetud. Andmete lugemiskiirus (Disk 1) kõigub tugevasti, kuid keskmiselt on see üle 200 megabaiti/s.
Kompressori töökiirus on antud juhul piiratud kompressitud andmete kirjutamise võimalusega Disk 0-le.
Nüüd on saadud arhiivide tihendustase:



On näha, et RTT-Mid kompressor on saavutanud parima kompressioonitulemuse, tema loodud arhiiv on 1,3 gigabaiti väiksem kui WinRari arhiiv ja 2,1 gigabaiti väiksem kui 7z arhiiv.
Aeg, mis kulus arhiivi loomisele:
- 7-zip – 26 minutit 10 sekundit;
- WinRar – 17 minutit 40 sekundit;
- RTT-Mid – 7 minutit 30 sekundit.
Sellest tulenevalt suutis isegi testimisversioon, mis ei olnud optimeeritud ja kasutas RTT-Mid algoritmi, luua arhiivi enam kui kaks ja pool korda kiiremini, samas kui arhiiv osutus oluliselt väiksemaks kui konkurentidel...
Need, kes ei usu ekraanipilte, saavad nende usaldusväärsust ise kontrollida. Testimisprogramm on saadaval , laadige alla ja kontrollige.
Aga ainult AVX-2 toetavate protsessorite korral, ilma nende käskude toetamiseta kompressorpump ei tööta, ja ärge katsetage algoritmi vanadel AMD protsessoritel, need on AVX käskude täitmisel aeglased...
Kasutatud kompressioonimeetod
Algselt kasutatakse algoritmis korduvate tekstifragmente indeksimise meetodit baitide granulaarsuses. Selline kokkusurumise meetod on olnud tuntud juba pikka aega, kuid seda ei ole kasutatud, kuna sobivuste otsimise operatsioon nõudis väga palju ressursse ja kulutas oluliselt rohkem aega kui sõnastiku koostamine. Seega on RTT-Mid algoritm klassikaline näide liikumisest „minevikku tulevikku“...
RTT kompressor kasutab ainulaadset kiiruskaevanduse vastete otsimise skannerit, mis on võimaldanud kiirendada kompressiooniprotsessi. Oma valmistatud skanner, see on "minu ilu...", "hind on suur, kuna tegemist on täielikult käsitööga" (kirjutatud assembleri keeles).
Vastete otsimise skanner kasutab kaheastmelist tõenäosusplaani, esmalt kontrollitakse 'märke', ja ainult pärast 'märke' tuvastamist käivitatakse tegeliku vastete avastamise protseduur.
Vastete otsimise aken on ettearvamatu suurusega, sõltuvalt entropia astmest töödeldavas andmeplokis. Täiesti juhuslike (kompressitavate) andmete puhul on selle suurus megabait, korduvate andmete puhul on see alati suurem kui megabait.
Kuid paljud kaasaegsed andmeformaatide ei ole tihendatavad ja ressursside tarbiv skanner nende peal töötlemiseks on täiesti kasutu ja raiskav, seega skanner kasutab kahte töörežiimi. Esiteks otsitakse algteksti osasid, kus võivad esineda kordused, ning see protseduur viiakse läbi tõenäosuslikul meetodil ja kestab väga kiiresti (kiirusel 4-6 gigabaidi sekundis). Seejärel töödeldakse osa, kus võivad olla kokkulangevused, põhiskanneriga.
Indeksitihendamine ei ole väga efektiivne, korduvad fragmentid tuleb asendada indeksitega ning indeksimassiiv vähendab oluliselt tihendamise koefitsienti.
Tihedamat tihendamist saavutatakse mitte ainult täielikult kattuvate baitide ridade indekseerimisega, vaid ka osaliste kattuvustega, kus real on nii kattuvad kui ka mittesobivad baitid. Selleks, et registreerida kattuvusi kahe ploki vahel, on indeksvormingus lisatud kattumise maskimisväli. Veelgi suuremaks tihendamiseks kasutatakse indekseerimist, kus mitu osaliselt kattuvat plokki kattuvad jooksva plokiga.
See võimaldas saavutada kompressoriga RTT-Mid kokkusurumise määr, mis on võrreldav sõnaraamatumeetodil valmistatud kompressoritega, kuid töötades palju kiiremini.
Uue kompressioonialgoritmi töökiirus
Kui kompressor töötab mälukahekasutuse korral (ühe lõime kohta on vajalik 4 MegaByte), siis töökiirus kõigub vahemikus 700-2000 MegaByte/s ühe protsessorituuma kohta, sõltudes kompressitava teabe tüübist ning sõltumatult protsessori töö sagedusest.
Mitme lõimega kompressori rakenduse puhul määrab efektiivne skaleeritavus kolmanda taseme mäluhake maht. Näiteks, kui „pardal” on 9 MegaByte mäluhake, pole mõtet käivitada rohkem kui kahte kompressioonivoogu, kuna kiirus ei suurene. Kuid 20 MegaByte mälu korral saab juba käivitada viis kompressioonivoogu.
Oluline näitaja, mis mõjutab kompressori töökiirus, on mälu latentsus. Algsed algoritmid kasutavad juhuslikke päringuid, millest osa (umbes 10%) ei jõua vahemällu, sundides seega ootele jääma, kuni andmed mälust kätte saadakse, mis vähendab töökiirus.
Kompressori kiirusel on oluline mõju ka andmesisestus- ja -väljastussüsteemide töö. Päringud mälu osas sisend-/väljundoperatsioonidest blokeerivad protsessorilt andmete päringud, mis samuti vähendavad kompressiooni kiirus. See probleem on oluline sülearvutitele ja lauaarvutitele, serverite kuna seal on see vähem oluline tänu paremale süsteembeebi juurdepääsu juhtimisse ja mitmekanalilisele mälule.
Artiklis räägitakse kõikjal kompressioonist, dekompressioon jääb selle artikli väliselt, kuna seal «kõik on hästi». Dekompresseerimine toimub oluliselt kiiremini ja on piiratud sisendi/väljastuse kiirusest. Üks füüsiline tuum ühes voos tagab rahulikult dekompressiooni kiirusel 3-4 gigabaiti/sekundis.
See on seotud sellega, et lahti pakkimise protsessis puudub vasteotsingu operatsioon, mis "neelab" erinevate ressurside, nagu protsessor ja vahemälu, põhifunktsioone kompressiooni ajal.
Kompresseeritud andmete salvestuse usaldusväärsus
Nagu kogu andmete kompressiooni tarkvara klassi (arhivaatorid) nime viitab, on need mõeldud teabe pikaajaliseks säilitamiseks, mitte aastateks, vaid sajanditeks ja tuhandeteks aastateks...
Aja jooksul kaotavad andmekandjad osa andmeid; siin on näide:

Sellel "analoogsel" andmekandjal on tuhat aastat, mõned fragmendid on kadunud, kuid üldiselt on teave "loetav"...
Ükski vastutav tänapäevaste digitaalsüsteemide andmesalvestusseadmete ja nende digiandmekandjate tootjatest ei anna garantiid, et andmed oleksid täielikult kaitstud rohkem kui 75 aasta jooksul.
Ja see on probleem, kuid probleem, mis on edasi lükatud; selle lahendavad meie järeltulijad...
Digitaalsete andmete salvestussüsteemid võivad andmeid kaotada mitte ainult 75 aasta pärast, vaid andmevead võivad tekkida igal ajal, isegi nende salvestamise ajal. Nende moonutuste vähendamiseks püütakse kasutada üleliigsust ja veaparandussüsteeme. Üleliigsus ja veaparandussüsteemid ei suuda kadunud teavet alati taastada ning kui nad seda teevad, pole mingit garantiid, et taasteprotsess on toimunud õigesti.
Ja see on samuti suur probleem, kuid mitte edasilükatud, vaid praegune.
Kaasaegsed kompressorid, mida kasutatakse digitaalsete andmete arhiveerimiseks, põhinevad erinevatel sõnastikmeetodi modifikatsioonidel ning selliste arhivide puhul võib teabe fragmentide kadumine olla fataalne sündmus. Sellise olukorra jaoks on isegi väljakujunenud termin — 'katkine' arhiv…
Sõnumite hoidmise madal usaldusväärsus sõnaraamatupõhise tihendamise arhiivides on seotud tihendatud andmete struktuuriga. Sellises arhiivis ei hoita algset teksti, vaid seal on salvestatud sõnastiku kirje numbrid, samas kui sõnastik muudetakse dünaamiliselt vastavalt hetkel tihendatavale tekstile. Kui arhiivi fragment on kaotsi läinud või moonutatud, ei ole võimalik kõiki järgnevaid arhiivi kirjeid tuvastada ei sisu, ega kirje pikkuse alusel, kuna pole selge, millele sõnastiku kirje number vastab.
Sellest 'katkist' arhiivist teabe taastamine on võimatu.
RTT algoritm põhineb usaldusväärsemas tihendatud andmete salvestamise meetodis. Sellega rakendatakse indekseerimise meetodit korduvate fragmentide jälgimiseks. See lähenemine tihendamisele võimaldab minimeerida teabe suunamisel tekkinud moonutuste tagajärgi ja paljudel juhtudel automaatselt parandada infot salvestamisel tekkinud moonutusi.
See on seotud sellega, et arhiveeritud fail indekseeritud tihendamise korral sisaldab kahte välja:
- algset teksti välja, millest on eemaldatud korduvaid osi;
- indeksite välja.
Andmete taastamiseks kriitiliselt tähtis indeksite väli ei ole suur ja seda saab andmete salvestamise usaldusväärsuse tagamiseks dubleerida. Seetõttu, isegi kui algse teksti või indeksimassiivi fragment kaob, taastatakse kogu ülejäänud teave probleemideta, nagu pildil „analoogses” andmekandjas.
Algoritmi puudused
Puudusteta ei ole väärtusi. Indeksipõhine tihendamine ei vähenda lühikeste korduvate järjestuste mahtu. See on seotud indeksimeetodi piirangutega. Indeksid on vähemalt 3 baiti suurused ja võivad ulatuda kuni 12 baitini. Kui kordumine on väiksem kui seda iseloomustav indeks, siis seda ei arvestata, olenemata sellest, kui sageli sellised kordused komprimeeritavas failis esinevad.
Traditsiooniline, sõnastikupõhine kokkusurumismeetod tõhusalt tihendab lühikeste korduste mitmekesisust ning seetõttu saavutab suurema kokkusurumise määra võrreldes indeksikokkusurumisega. Tõsi, see saavutatakse kõrge protsessori koormuse arvelt, et sõnastikupõhine meetod saaks andmeid efektiivsemalt tihendada, peab see vähendama andmete töötlemise kiirust kuni 10-20 megabaiti sekundis reaalsetes arvutusmasinates täiskoormuse korral.
Nii madalad kiirusnäitajad on tänapäevastele andmesalvestussüsteemidele vastuvõetamatud ja esindavad pigem «akadeemilist» huvi kui praktilist.
Informatsiooni kokkusurumise määra tõstmine toimub järgmise RTT algoritmi modifikatsiooni (RTT-Max) abil, mis on juba arendamisel.
Nii et nagu alati, järgneb jätk...
Allikas: habr.com
