

Viimased umbes kuus kuud olen tegelenud pettuste vastase süsteemi loomisega (pettus, petturid jne) ilma algse infrastruktuurita. Tänaste ideede abil, mida oleme leidnud ja oma süsteemis ellu viinud, suudame avastada palju petturlikke tegevusi ja neid analüüsida. Selles artiklis soovin rääkida põhimõtetest, millele me tuginesime, ja sellest, mida me oleme teinud, et saavutada meie süsteemi praegune seisund, süvenemata tehnilistesse detailidesse.
Meie süsteemi põhimõtted
Kui kuulete selliseid termineid nagu "automaatne" ja "petuskeem", mõtleme tõenäoliselt masinõppele, Apache Sparkile, Hadoopile, Pythonile, Airflowle ja muudele tehnoloogiatele Apache Foundationi ökosüsteemis ning andeteaduse valdkonnas. Arvan, et on üks aspekt nende tööriistade kasutamisel, millest tavaliselt ei räägita: need eeldavad, et teie ettevõttes on teatud eeltingimused olemas enne nende kasutamist. Lühidalt öeldes vajate andmeplatvormi, mis hõlmab andmejärve ja ladustamist. Aga mis siis, kui teil ei ole sellist platvormi ja peate ikka veel praktikat arendama? Järgnevad põhimõtted, millest ma allpool räägin, on aidanud meil jõuda hetke, kus saame keskenduda oma ideede edendamisele, mitte lahenduse leidmisele. Sellegipoolest ei ole see projekti "platoo". Tehnoloogia ja toote aspektidest on veel palju tehtavat.
Põhimõte 1: äriarve esmajärjekorras
Kõik meie tegevused on koondatud „äriarvu” väärtuse ümber. Üldjoontes kuulub iga automatiseeritud analüüsi süsteem keeruliste süsteemide kategooriasse, millel on kõrge automatiseerituse ja tehnilise keerukuse tase. Tervikliku lahenduse loomine võtab tohutult aega, kui teete seda nullist. Otsustasime seada äriarvu väärtuse esikohale ja tehnilise täiuslikkuse teisele kohale. Reaalelus tähendab see, et me ei võta uuenduslikke tehnoloogiaid dogmin. Valime tehnoloogia, mis toimib praegu meie jaoks kõige paremini. Aja jooksul võime avastada, et tuleb mõned moodulid uuesti rakendada. See on kompromiss, mille oleme vastu võtnud.
Põhimõte 2: Täiendav inimintellekt (augmented intelligence)
Olen kindel, et enamik inimesi, kes ei tegele sügavalt masinõppe lahenduste arendamisega, võib arvata, et inimeste asendamine on eesmärk. Tegelikult on masinõppe lahendused kaugel täiuslikkusest ja asendamine on võimalik vaid teatud valdkondades. Oleme sellest ideest algusest peale loobunud mitmel põhjusel: andmete tasakaalustamatus petuskeemide kohta ja võimetus esitada kaasahaaravat funktsioonide loetelu masinõppe mudelite jaoks. Selle asemel valisime täiendatud intelligentsuse variandi. See on alternatiivne tehisintellekti kontseptsioon, mis keskendub AI abistavale rollile, rõhutades, et kognitiivsed tehnoloogiad on mõeldud inimintellekti parandamiseks, mitte selle asendamiseks. [1]
Arvestades seda, tähendaks täieliku masinõppe lahenduse väljatöötamine algusest peale tohutuid jõupingutusi, mis viivitaks väärtuse loomist meie äri jaoks. Otsustasime luua süsteemi, mille masinõppe aspekt kasvab iteratiivselt meie valdkonna ekspertide juhendamisel. Sellise süsteemi arendamise keeruline osa on see, et see peab andma meie analüütikutele juhtumeid mitte ainult sellest vaatepunktist, kas see on pettus või mitte. Üldiselt on iga klientide käitumise anomaalia kahtlane juhtum, mida spetsialistid peavad uurima ja kuidagi reageerima. Ainult väike osa nendest fikseeritud juhtumitest võib tõeliselt kuuluda pettuste kategooriasse.
Põhimõte 3: ulatuslike analüüsid läviv platvorm
Meie süsteemi kõige keerulisem osa on tööprotsessi läbiv kontroll. Analüütikud ja arendajad peavad saama hõlpsasti juurdepääsu ajaloolistele andmestikele koos kõikide analüüsiks kasutatud mõõdikute ülevaatega. Lisaks peab andmeplatvorm pakkuma lihtsat viisi olemasoleva mõõdikute komplekti täiendamiseks uute lisamisega. Loomulikult soovime, et loodud protsessid, mis hõlmavad mitte ainult tarkvaraprotsesse, võimaldaksid hõlpsasti arvutada varasemaid perioode, lisada uusi mõõdikuid ning kohandada andmete prognoose. Sellise eesmärgi saavutamiseks võiksime koguda kõik andmed, mida meie tootmissüsteem genereerib. Kuid sel juhul muutuksid andmed järk-järgult koormavaks. Me peaksime salvestama kasvava hulga andmeid, mida me ei kasuta, ja neid kaitsma. Sellises stsenaariumis muutuksid andmed aja jooksul järjest vähem oluliseks, kuid nende haldamine nõuaks ikkagi meie pingutusi. Andmete kogumine (data hoarding) ei olnud meie jaoks mõistlik, seetõttu otsustasime kasutada teistsugust lähenemist. Otsustasime korraldada reaalajas andmehoidlaid sihtsüsteemide ümber, mida soovime klassifitseerida, ja säilitada vaid need andmed, mis võimaldavad kontrollida kõige uuemaid ja asjakohasemaid perioode. Nende jõupingutuste keerukus seisneb selles, et meie süsteem on heterogeenne, koos mitmete andmehoidlate ja tarkvaramoodulitega, mis nõuavad tõhusat planeerimist, et tagada nende ühtlane toimimine.
Meie süsteemi konstruktiivsed kontseptsioonid
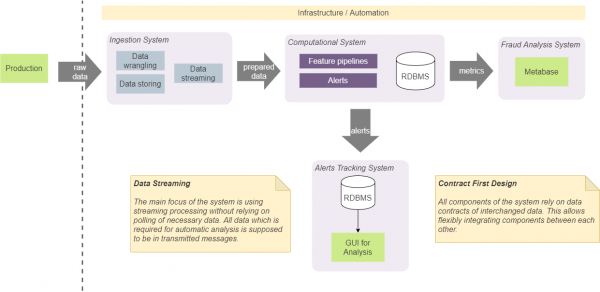
Meie süsteemis on neli peamist komponenti: andmete vastuvõtusüsteem, arvutuslik süsteem, BI analüüs ja jälgimissüsteem. Need teenivad konkreetseid isoleeritud eesmärke ning me hoiab neid isoleerituna, järgides kindlaid arenduse lähenemisviise.
Lepingu alusel projekteerimine
Esiteks leppisime kokku, et komponendid peavad toetuma ainult teatud andmestruktuuridele (lepingutele), mida nende vahel edastatakse. See võimaldab hõlpsalt integreerida nende vahel ja ei kehtesta konkreetset koostisosade koosseisu (ja järjestust). Näiteks mõnel juhul võimaldab see meil otse integreerida vastuvõtusüsteemi hoiatuste jälgimise süsteemiga. Sellisel juhul tehakse see kooskõlas kokku lepitud teavituste lepinguga. See tähendab, et mõlemad komponendid on integreeritud lepinguga, mida võib kasutada ükskõik milline teine komponent. Me ei lisa täiendavat lepingut hoiatuste lisamiseks jälgimisse süsteemist sisendisse. Selline lähenemine eeldab eelnevalt määratud minimaalsete lepingute arvu kasutamist ja lihtsustab süsteemi ja kommunikatsiooni. Sisuliselt kasutame lähenemist, mida nimetatakse „Contract First Design“, ja rakendame seda andmevoogude lepingutele. [2]
Voogedastus igal pool
Süsteemis oleku salvestamine ja haldamine toob paratamatult kaasa selle rakendamise keerukuse. Üldiselt peaks olek olema kergesti kättesaadav mistahes komponendist, see peaks olema järjepidev ja pakkuma kõigi komponentide jaoks kõige aktuaalsemat väärtust ning olema usaldusväärne õige väärtustega. Lisaks suurendavad pidevad kutsed püsivasse salvestusse viimase oleku saamiseks sisend-väljastuse operatsioonide arvu ja keerukust algoritmides, mida meie reaalaja kanalites kasutatakse. Seetõttu otsustasime võimalusel oleku haldamine meie süsteemist täielikult eemaldada. See lähenemine nõuab, et kõik vajalikud andmed oleksid edastatavas andmeplokis (teates) kaasas. Näiteks kui peame arvutama teatud vaatluste (operatsioonide või teatud omadustega juhtumite arvu) koguhulga, arvutame selle mälus ja genereerime selliste väärtuste voogu. Sõltuvad moodulid kasutavad voogude jagamiseks (partition) ja pakkimiseks (batch) jagamist, et toime tulla viimaste väärtustega. See lähenemine eemaldas vajaduse püsiva plaadisalvestuse järele selliste andmete jaoks. Meie süsteem kasutab sõnumite maaklerina Kafka’t ja seda saab kasutada andmebaasina KSQL-ga. [3] Kuid selle kasutamine siduks meie lahenduse tugevalt Kafka’ga, seetõttu otsustasime seda mitte kasutada. Meie valitud lähenemine võimaldab asendada Kafka teise sõnumite maakleriga ilma tõsiste sisemiste muudatusteta süsteemis.
See kontseptsioon ei tähenda, et me ei kasutaks ketashoiust ja andmebaase. Süsteemi jõudluse kontrollimiseks ja analüüsimiseks peame salvestama kettale olulise osa andmeid, mis esindavad erinevaid näitajaid ja olekuid. Oluline on märkida, et reaalajas algoritmid ei sõltu sellistest andmetest. Enamikul juhtudel kasutame salvestatud andmeid iseseisvaks analüüsiks, tõrkeotsimiseks ja konkreetsete juhtumite ning süsteemi väljastatud tulemuste jälgimiseks.
Meie süsteemi probleemid
On teatud probleemid, mille oleme lahendanud teatud tasemel, kuid nad vajavad läbimõeldumaid lahendusi. Soovin neid lihtsalt siinkohal mainida, kuna iga punkt väärib eraldi artiklit.
- Me peame endiselt määratlema protsessid ja poliitikad, mis aitavad kaasa oluliste ja asjakohaste andmete kogumisele meie automaatseks analüüsiks, avastamiseks ja andmete uurimiseks.
- Inimeste analüüsi tulemuste integreerimine süsteemi automaatse seadistamise protsessi, et seda uuendada kõige värskemate andmetega. See hõlmab mitte ainult meie mudeli uuendamist, vaid ka protsesside uuendamist ja meie andmete mõistmise täiustamist.
- Tasakaalu leidmine määratletud IF-ELSE lähenemise ja masinõppe vahel. Keegi ütles: „Masinõpe on meeleheites olevate jaoks” - see tähendab, et soovite kasutada masinõpet, kui enam ei mõista, kuidas oma algoritme optimeerida ja parandada. Teisest küljest, määratletud lähenemine ei luba avastada ettenägematuid anomaaliaid.
- Vajame lihtsat viisi, et kontrollida meie hüpoteese või korrelatsioone andmete mõõdikute vahel.
- Süsteem peab omama mitut taset tõeliselt positiivsete (true positive) tulemuste saamiseks. Pettuste juhtumid on vaid osa kõigist juhtumitest, mida saab süsteemi jaoks positiivseteks pidada. Näiteks soovivad analüütikud saada kõik kahtlased juhtumid kontrollimiseks, ja vaid väike osa neist on pettused. Süsteem peab tõhusalt esitama analüütikutele kõik juhtumid, sõltumata sellest, kas tegemist on tõelise pettuse või lihtsalt kahtlase käitumisega.
- Andmepank peab võimaldama varasema perioodi andmekogumite saamist koos reaalajas genereeritud ja arvutatud tulemustega.
- Süsteemi üksikute komponentide lihtne ja automaatne juurutamine vähemalt kolmes erinevas keskkonnas: tootmis-, katse (beta) ja arendaja keskkondades.
- Ja viimane, kuid mitte vähem oluline. Me peame looma ulatusliku jõudluse kontrollimise platvormi, kus saame oma mudelite analüüsimiseks tootmisesse viia. [4]
Lingid
Allikas: habr.com
