

Aeg-ajalt tekib vajadus leida seotud andmeid võtmete komplekti põhjal, kuni jõuame vajaliku kokkuvõtete arvu juurde.
Kõige rohkem "elulise" näitena — väljendada 20 vanimat ülesannet, mis on nimekirjas töötajate seas (näiteks ühes osakonnas). Erinevate juhtimis- "armatuurlaudade" jaoks, mis sisaldavad lühikesi ülevaateid töövaldkondade kohta, on sarnane teema piisavalt sage.

Artiklis vaatleme PostgreSQL-i "naivset" varianti sellise ülesande lahendamiseks, "nutikamat" ja täielikult keerulisemat algoritmi "tsükkel" SQL-is, millel on lahkumistingimus leitud andmetest,millel võib olla kasulik roll nii üldiseks arenguks kui ka rakendamiseks sarnastes olukordades.
Võtame testkomplekti andmed Et saadetavad kirjed ei "hüppaks" kordade kaupa sarnaste sorteerimisväärtuste korral, laiendame objekti indeksit esmase võtme lisamisega.See annab sellele kohe unikaalsuse ja garanteerib meile sorteerimise järjekorra üheselt mõistetavuse:
LOOBA INDEX TASK(owner_id, task_date, id);
-- ja vana eemaldame
KUSTUTA INDEX task_owner_id_task_date_idx;Nii nagu kuulda, nii ka kirjutatakse
Alustame kõige lihtsama päringu koostamisest, edastades täitjate ID-d :
VALI
*
KUSTUTAGE
task
KUS
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
JÄRJESTATUD
task_date, id
PIIRANG 20; 
Veidi kurb — tellisime vaid 20 kirjet, kuid Index Skaneerimine tagastas meile 960 rida, mille me pidime veel sorteerima… Aga proovime lugeda vähem.
unnest + ARRAY
Esimene mõte, mis aitab — kui me vajame kõigest 20 sorteeritud kirjet, siis piisab, kui lugeda mitte rohkem kui 20 sorteeritud samas järjekorras iga võtme. Hea küll, sobiv indeks (owner_id, task_date, id) on meil olemas.
Kasutame sama mehhanismi väljavõtte ja „veerudeks pööramise” täieliku tabeli kirje, nagu ka . Samuti rakendame kokkuvõtmist massiivi kasutades funktsiooni ARRAY():
WITH T AS (
VALI
unnest(ARRAY(
VALI
t
KUSTUTAGE
task t
KUS
owner_id = unnest
JÄRJESTATUD
task_date, id
PIIRANG 20 -- piirame siia...
)) r
KUSTUTAGE
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
VALI
(r).*
KUSTUTAGE
T
JÄRJESTATUD
(r).task_date, (r).id
PIIRANG 20; -- ... ja siin - samuti 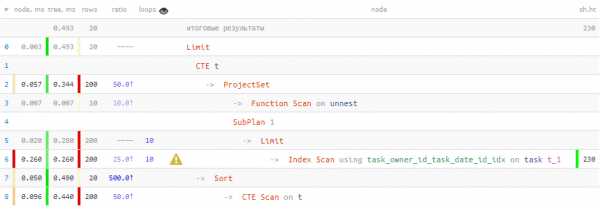
Oh, see, much better now! 40% faster and using 4.5 times less data to read.
Materializing table records through CTEI would like to point out that in some cases trying to work with record fields immediately after searching for them in a subquery, without 'wrapping' them in CTE, can lead to 'multiplying' InitPlan in proportion to the number of these fields:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Tulemus (kulu=4.77..4.78 rida=1 laius=16) (reaalne aeg=0.063..0.063 rida=1 tsüklid=1)
Puudutab: jagatud tabas=16
Algplaan 1 (tagastab $0)
-> Piirama (kulu=0.42..1.19 rida=1 laius=48) (reaalne aeg=0.031..0.032 rida=1 tsüklid=1)
Puudutab: jagatud tabas=4
-> Indeksi skaneerimine, kasutades task_owner_id_task_date_id_idx ülesandes t (kulu=0.42..387.57 rida=500 laius=48) (reaalne aeg=0.030..0.030 rida=1 tsüklid=1)
Indeksi tingimus: (omanik_id = 1)
Puudutab: jagatud tabas=4
Algplaan 2 (tagastab $1)
-> Piirama (kulu=0.42..1.19 rida=1 laius=48) (reaalne aeg=0.008..0.009 rida=1 tsüklid=1)
Puudutab: jagatud tabas=4
-> Indeksi skaneerimine, kasutades task_owner_id_task_date_id_idx ülesandes t_1 (kulu=0.42..387.57 rida=500 laius=48) (reaalne aeg=0.008..0.008 rida=1 tsüklid=1)
Indeksi tingimus: (omanik_id = 1)
Puudutab: jagatud tabas=4
Algplaan 3 (tagastab $2)
-> Piirama (kulu=0.42..1.19 rida=1 laius=48) (reaalne aeg=0.008..0.008 rida=1 tsüklid=1)
Puudutab: jagatud tabas=4
-> Indeksi skaneerimine, kasutades task_owner_id_task_date_id_idx ülesandes t_2 (kulu=0.42..387.57 rida=500 laius=48) (reaalne aeg=0.008..0.008 rida=1 tsüklid=1)
Indeksi tingimus: (omanik_id = 1)
Puudutab: jagatud tabas=4
Algplaan 4 (tagastab $3)
-> Piirama (kulu=0.42..1.19 rida=1 laius=48) (reaalne aeg=0.009..0.009 rida=1 tsüklid=1)
Puudutab: jagatud tabas=4
-> Indeksi skaneerimine, kasutades task_owner_id_task_date_id_idx ülesandes t_3 (kulu=0.42..387.57 rida=500 laius=48) (reaalne aeg=0.009..0.009 rida=1 tsüklid=1)
Indeksi tingimus: (omanik_id = 1)
Puudutab: jagatud tabas=4
Sama kirje on leitud 4 korda... Kuni PostgreSQL 11-ni esines seda käitumist regulaarselt, ja lahenduseks on selle „ümberpakkimine“ CTE-s, mis on nende versioonide puhul optimeerijale tingimatu piir.
Rekursiivne akumulator
Eelmises versioonis lugesime kokku 200 rida kuni vajalike 20-ni. Mitte enam 960, aga veel vähem — kas saab?
Proovime kasutada teadmist, et meil on vaja kokku 20 kirjet. St alustame andmete lugemist ainult siis, kui oleme jõudnud soovitud arvuni.
Samm 1: algne loend
On ilmne, et meie „sihtloend“ 20 kirjet peaks alustama „esimestest“ kirjetest ühes meie owner_id võti. Seetõttu leiame esmalt sellised „kõige esimesed“ igal võtmel ja paneme need loendisse, sorteerides selle soovitud järjekorras — (task_date, id).
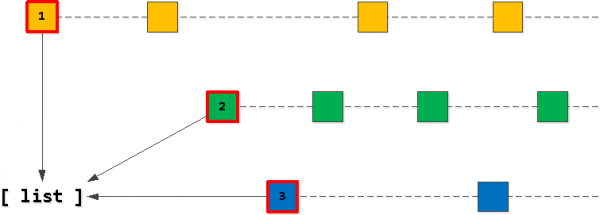
Samm 2: leiame „järgmised“ kirjed
Nüüd, kui võtame oma loendist esimese kirje ja hakkame „sammuma“ indeksil edasi säilitades owner_id võti, siis kõik leitud kirjed on järgmised tulemuses. Loomulikult ainult kuni me ei ületa rakendusliku võtme teise kirje loendis.
Kui juhtub, et me „ristusime“ teise salvestusega, siis viimane loetud salvestus tuleb lisada loendisse esimesena (sama owner_id-ga), pärast mida sorteerime loendi uuesti.
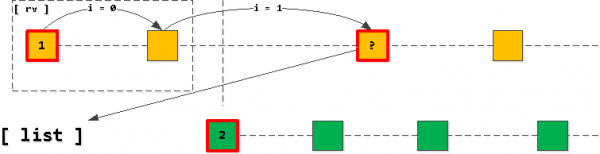
See tähendab, et loendis peab olema kogu aeg mitte rohkem kui üks salvestus iga võtme kohta (kui salvestused on läbi, ja me ei ole „ristunud“, kaob loendist lihtsalt esimesena salvestus ja midagi ei lisandu), ning need on alati järjestatud kasvava rakendatavuse võti (task_date, id) alusel.
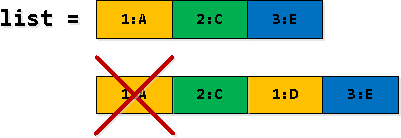
Samm 3: filtreerime ja „vahetame“ salvestusi
Mõnes meie rekursiivse valiku real rv korduvad — kõigepealt leiame sellised, nagu on „ristumise piir 2. salvestuses loendis“, ja siis asendame selle loendi 1. salvestusena. Esimene ilmumine tuleb filtreerida.
Hirmuäratav lõpp-päring
WITH RECURSIVE T AS (
-- #1 : lisame "esimese" salvestused igale komplekti võtmele
WITH wrap AS ( -- "materialiseerime" salvestused, et välja võtmiseks ei nõuaks InitPlan/SubPlan kordamist
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- sorteerime nimekirja soovitud järjekorras
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : loeme 1. järjekorra võtme salvestused, kuni ületame 2. salvestuse
SELECT
CASE
-- kui 1. salvestuse võtme jaoks ei leitud midagi
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- eemaldame selle nimekirjast
-- kui me ei ole ületanud 2. salvestuse rakendusvõtit
WHEN X.not_cross THEN
T.list -- jätkame sama nimekirja muudatusteta
-- kui 2. salvestust nimekirjas enam ei ole
WHEN T.list[2] IS NULL THEN
-- lihtsalt tagastame tühja nimekirja
'{}'
-- sorteerime sõnastiku uuesti, eemaldades 1. salvestuse ja lisades viimase leitud
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "materialiseerime" salvestuse
SELECT
CASE
-- kui me aga "ületame" 2. salvestuse
WHEN NOT T.not_cross
-- siis vajalik salvestus on nimekirja esimene
THEN T.list[1]
ELSE ( -- kui ei ületanud, siis võti jäi samaks nagu eelmisel salvestusel - lähtume sellest
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- kui 2. salvestust nimekirjas enam ei ole, aga me leidsime midagi
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ei leidnud midagi või "ületatud"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- piirame siin arvu
T.list IS DISTINCT FROM '{}' -- või seni, kuni nimekiri ei ole läbi
)
-- #3 : "laiendame" salvestused - järjekord on garanteeritud struktuuri järgi
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- võtame ainult "mitteületavad" salvestused 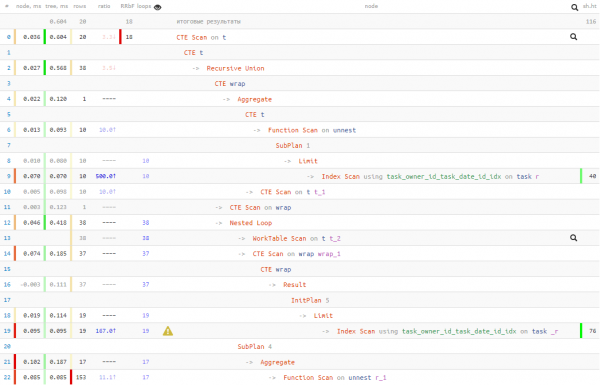
Seega vahetasime 50% andmete lugemist 20% täitmise ajaga . See tähendab, et kui teil on põhjust kahtlustada, et lugemine võib kaua aega võtta (näiteks andmed ei ole sageli vahemälus ja tuleb neid diskilt hankida), siis on võimalik lugemise koormust vähendada.Igal juhul on täitmise aeg parem kui „naivne” esimene versioon. Kuid millist neist 3 variantidest kasutada — see on teie valik.
Rakenduste arenduskeskkonna KDevelop 5.5 väljaanne
Allikas: habr.com
