

Teade
Kollegid, suve keskpaiku plaanin avaldada veel ühe artiklite seeria massiteenuse süsteemide projekteerimise kohta: "Eksperiment VTrade" — katse kirjutada raamistiku kauplemissüsteemide jaoks. Seerias käsitletakse börsi, oksjoni ja poe loomise teooriat ja praktikat. Artikli lõpus kutsub autor üles hääletama kõige huvitavamate teemade üle.

See on viimane artikkel jaotise kohta jaotatud reaktiivsetest rakendustest Erlangu/Elixiriga. S võib leida reaktiivse arhitektuuri teoreetilised alused. illustreerib peamisi mustreid ja mehhanisme selliste süsteemide loomisel.
Täna käsitleme koodibaasi ja projektide arengut üldiselt.
Teenuste korraldamine
Reaalses elus teenuse arendamisel tuleb sageli ühendada mitu suhtlemismustrit ühes kontrolleris. Näiteks teenus users, mis lahendab projekti kasutajaprofiilide haldamise ülesandeid, peab vastama päringutele req-resp ja teatama profiilide uuendustest pub-sub kaudu. See juhtum on üsna lihtne: jagamise taga on üks kontroller, mis rakendab teenuse loogikat ja avaldab uuendusi.
Situatsioon muutub keerulisemaks, kui peame rakendama tõrkevaru jaotatud teenust. Oletame, et kasutajate nõudmised on muutunud:
- nüüd peab teenus töötlema päringuid 5 klastrisõlmes,
- olema võimeline täitma taustatöötlusülesandeid,
- ja suutma dünaamiliselt hallata tellimuste loode profiili värskendustele.
Märkus: Andmete järjepideva salvestamise ja kopeerimise küsimust me ei aruta. Eeldame, et need küsimused on varem lahendatud ja süsteemis on juba olemas usaldusväärne ning skaleeritav salvestuskiht, millel on töötlejatel suhtlemismehhanismid.
Kasutajate teenuse formaalne kirjeldus on muutunud keerulisemaks. Programmi seisukohalt on tänu sõnumside kasutamisele muudatused minimaalsed. Esimese nõude täitmiseks peame seadistama tasakaalustamise req-resp vahetuspunktis.
Taustatööde töötlemise nõudmine tekib sageli. Users'is võivad need olla kasutajate dokumentide kontrollimine, üles laaditud multimeedia töötlemine või andmete sünkroonimine sotsiaalsete võrgustikega. Need ülesanded tuleb mingil viisil jaotada klastris ja nende täitmise kulgu jälgida. Seetõttu on meil kaks lahenduse varianti: kas kasutada eelmise artikli ülesannete jaotamise шаблони või, kui see ei sobi, kirjutada kohandatud ülesannete planeerija, mis hallataks meie vajaduste järgi.
3. punkt nõuab pub-sub шаблони laiendamist. Ja selle teostamiseks, pärast pub-sub vahetuspunkti loomist, peame käivitama ka selle punkti kontrolleri meie teenuse raames. Seega, nagu me viiksime tellimise ja loobumise töötlemise loogika messaging kihist välja users'i rakendusse.
Kokkuvõttes näitas ülesande dekompositsioon, et nõuete rahuldamiseks peame käivitama 5 teenuse eksemplari erinevates sõlmedes ja looma täiendava üksuse – pub-sub kontrolleri, mis vastutab tellimise eest.
5 töötleja käivitamiseks ei ole teenuse koodi vaja muuta. Ainus lisategevus on tasakaalustamisreeglite seadistamine vahetuspunktis, millest räägime hiljem.
Lisaks on tekkinud täiendav keerukus: pub-sub juht ja kohandatud ülesannete ajastaja peavad töötama ainsas eksemplaris. Jällegi, messaging teenus, olles alus, peab pakkuma juhtimismehhanismi.
Juhi valik
Jaotatud süsteemides on juhi valik – menetlus, mille käigus määratakse ainus protsess, mis vastutab jaotatud koormuse töötlemise planeerimise eest.
Süsteemides, mis ei kaldu keskendumisele, kasutatakse universaalseid algoritme ja konsensusel põhinevaid algoritme, näiteks paxos või raft.
Kuna messaging on vahendaja ja keskne element, siis teab ta kõigist teenuse kontrollijatest - juhtide kandidaatidest. Messaging võib määrata juhi ilma hääletamiseta.
Kõik teenused saavad pärast käivitamist ja ühendamist vahetuspunktiga süsteemiteate #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. Kui LeaderPid on sama kui pid praeguse protsessi puhul, määratakse ta juhiks ja nimekiri Servers kätkeb endas kõiki sõlme ja nende parameetreid.
Kui klastris tekib uus sõlm ja varasem sõlm lülitatakse välja, saavad kõik teenuse kontrollerid #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} ja #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} vastavalt.
Seega teavad kõik komponendid kõigist muudatustest ning klastris on igal hetkel tagatud üks juht.
Vahekohtunikud
Kompaktsede hajutatud töötlemisprotsesside rakendamiseks ning juba olemasoleva arhitektuuri optimeerimise probleemide lahendamiseks on mugav kasutada vahekohtunikke.
Kuna teenuste koodi ei soovi muuta ja lahendada näiteks täiendava töötlemise, marsruutimise või sõnumite logimise ülesandeid, võib teenuse ette lisada proxy töötlija, mis täidab kogu täiendava töö.
Klassikaline näide pub-sub optimeerimise kohta on hajutatud rakendus, millel on äri- süda, mis genereerib uuenduste sündmusi, näiteks hinnamuutuse turul, ja juurdepääsu kiht — N serverit, mis pakuvad websocket API-d veebiklientidele.
Kui läheneda probleemile otse, näeb kliendi teenindamine välja järgmiselt:
- kliendil on ühendus platvormiga. Serveripoolel, mis lõpetab liikluse, algab protsessi käivitamine, mis teenindab seda ühendust.
- teenuse protsessis toimub autentimine ja tellimine uuenduste jaoks. Protsess kutsub esile subscribe meetodi teemadele.
- pärast sündmuse genereerimist südamikus toimetatakse see protsessidele, mis haldavad ühendusi.
Kujutame ette, et meil on 50000 tellijat teemale "uudised". Tellijad on jaotatud 5 serveri vahel ühtlaselt. Seega iga uuendus, jõudnud vahetuspunkti, replitseeritakse 50000 korda: 10000 korda igas serveris, vastavalt tellijate arvule seal. Mitte kõige efektiivsem skeem, kas pole?
Et olukorda parandada, tutvustame proxy't, millel on sama nimi nagu vahetuspunktil. Globaalse nimede registrator peab olema võimeline nime alusel tagastama lähima protsessi, see on oluline.
Käivitame selle proxy serverites juurdepääsu kihis, ja kõik meie protsessid, mis haldavad websocket api, tellivad selle, mitte algse pub-sub vahetuspunkti südamikus. Proxy tellib südamikust ainult unikaalse tellimise korral ja replitseerib saabunud sõnumi kõikidele oma tellijatele.
Seega edastatakse südamiku ja juurdepääsu serverite vahel 5 sõnumit, mitte 50000.
Marsruutimine ja tasakaalustamine
Req-Resp
Praeguses messaging'i rakenduses on 7 päringute jaotamise strateegiat:
default. Päring edastatakse kõikidele kontrolleritele.ring-levi. Teostatakse iteratsioon ja tsükliline päringute jaotamine kontrollerite vahel.konsensus. Teenust pakkuvad kontrollerid jagunevad liidriks ja järgnejateks. Päringud edastatakse ainult liidrile.konsensus & ring-levi. Grupis on liider, kuid päringud jaotatakse kõigi liikmete vahel.kleepuv. Arvutatakse hash-funktsioon ja seotakse teatud töötlejaga. Järgnevad päringud selle signatuuriga jõuavad samale töötlejale.kleepuv-funktsioon. Vahetuspunkti algatamisel edastatakse lisaks hash-funktsiooni arvutamise funktsioon.kleepuvjaotamiseks.lõbu.. Sarnane kleepuva funktsiooniga, ainult et lisaks on võimalik suunata, tagasi lükata või eeltöötleda seda.
Jaotamisstrateegia määratakse vahetuspunkti algatamisel.
Lisaks jaotamisele võimaldab messaging tähistada üksusi. Vaatleme süsteemi erinevaid tähiseid:
- Ühenduse silt. See aitab mõista, millise ühenduse kaudu sündmused pärit on. Seda kasutatakse siis, kui kontrolleri protsess on ühendatud ühe vahetuspunktiga, kuid erinevate marsruutimisvõtmetega.
- Teenuse silt. See võimaldab ühel teenusel grupeerida töötlejad ja laiendada marsruutimise ning koormuse jaotamise võimalusi. Req-resp mustri korral on marsruutimine lineaarne. Saadame päringu vahetuspunkti, mis edasi edastab selle teenusele. Kuid kui peame töötlejad loogilisteks gruppideks jagama, siis toimub jagamine siltide abil. Sildi määramisel suunatakse päring konkreetse kontrollerite gruppi.
- Päringu silt. See võimaldab eristada vastuseid. Kuna meie süsteem on asünkroonne, peab teenuse vastuste töötlemiseks olema võimalik määrata RequestTag päringu saatmisel. Selle põhjal saame mõista, millise päringu vastus meile saabus.
Pub-sub
Pub-sub puhul on kõik natuke lihtsam. Meil on vahetuspunkt, kuhu avaldatakse sõnumeid. Vahetuspunkt jagab sõnumeid tellijate vahel, kes on tellinud vajalikud marsruutimisvõtmed (võib öelda, et see on analoog teemale).
Skaalautuvus ja töökindlus
Süsteemi üldine skaala sõltub süsteemi kihtide ja komponentide skaalaastmest:
- Teenused skaleeritakse lisades klastrisse täiendavaid sõlmi, millel on selle teenuse töötlejad. Protsessi käigus saab optimaalset koormuse tasakaalustamise poliitikat valida katse ajal.
- Kuna teenus messaging ühes klastris skaleerub, siis tavaliselt kas koormatud vahetuspunktid viiakse eraldi sõlmedesse või lisatakse proxy protsesse kõrgelt koormatud klastritsoonidesse.
- Kogu süsteemi skaleeritavus sõltub arhitektuuri paindlikkusest ja eraldi klastrite ühendamise võimest üldiseks loogiliseks üksuseks.
Projektide edu sõltub sageli skaala lihtsusest ja kiirusest. Messaging praeguses vormis kasvab koos rakendusega. Isegi kui meil puudub 50-60 masinat sisaldav klaster, saame kasutada föderatsiooni. Kahjuks ületab föderatsiooni teema selle artikli raamid.
Varu
Laadija koormuse jaotuse käigus arutasime juba teenusekontrollerite varundamist. Kuid ka sõnumiteed tuleb varundada. Kui sõlm või masin läbi kukkub, peab sõnumiteede taastamine toimuma automaatselt ja võimalikult kiiresti.
Oma projektides kasutan täiendavaid sõlmi, mis võtavad koormuse üle, kui midagi kukub. Erlangis on olemas standardne rakendus jaotatud režiimis OTP rakenduste jaoks. Jaotatud režiim teostab just selle rikkumise taastamise, käivitades kukkunud rakenduse teisel eelnevalt käivitatud sõlmel. Protsess on läbipaistev, pärast rikkumist liigub rakendus automaatselt varukoopiale. Täpsemalt selle funktsionaalsuse kohta lugemiseks võite vaadata .
Tootlikkus
Proovime vähemalt ligikaudselt võrrelda rabbitmq ja meie kohandatud sõnumiteed.
Leidsin rabbitmq testimisest openstacki meeskonna poolt.
Algse dokumendi punktis 6.14.1.2.1.2.2 on esitatud RPC CAST: tulemused.
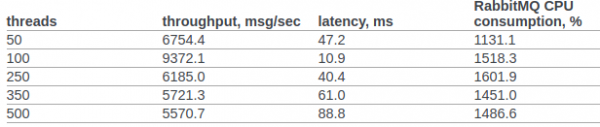
Eeltingimusi, et operatiiv süsteemi või erlangi VM-i ei muuda. Testimise tingimused:
- erl opts: +A1 +sbtu.
- Erlang'i test käivitub vanal i7 mobiilse seadmena sülearvutis.
- Klastri testid toimuvad 10G võrgu serverites.
- Kood töötab Docker konteinerites. Võrk on NAT-režiimis.
Testikood:
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Skenaario 1: Test käivitub sülearvutis vanal i7 mobiilse seadmena. Test, messaging ja teenus toimuvad ühel sõlmel ühes Docker konteineris:
Järjestikused 10000 tsüklit ~0 sekundiga (26987 tsüklit/s)
Järjestikused 20000 tsüklit ~1 sekundiga (26915 tsüklit/s)
Järjestikused 100000 tsüklit ~4 sekundiga (26957 tsüklit/s)
Parallel 2 100000 tsüklit ~2 sekundiga (44240 tsüklit/s)
Parallel 4 100000 tsüklit ~2 sekundiga (53459 tsüklit/s)
Parallel 10 100000 tsüklit ~2 sekundiga (52283 tsüklit/s)
Parallel 100 100000 tsüklit ~3 sekundiga (49317 tsüklit/s)Skeem 2: 3 sõlme, mis on käivitunud erinevates masinates Docker'i all (NAT).
Järjestikused 10000 tsüklit ~1 sekundiga (8684 tsüklit/s)
Järjestikused 20000 tsüklit ~2 sekundiga (8424 tsüklit/s)
Järjestikused 100000 tsüklit ~12 sekundiga (8655 tsüklit/s)
Parallel 2 100000 tsüklit ~7 sekundiga (15160 tsüklit/s)
Parallel 4 100000 tsüklit ~5 sekundiga (19133 tsüklit/s)
Parallel 10 100000 tsüklit ~4 sekundiga (24399 tsüklit/s)
Parallel 100 100000 tsüklit ~3 sekundiga (34517 tsüklit/s)Kõigil juhtudel ei ületanud CPU kasutamine 250%
Kokkuvõte
Loodan, et see tsükkel ei näe välja nagu teadusartikli kogumik ning minu kogemus toob tõelist kasu nii jaotatud süsteemide teadlastele kui ka praktikutele, kes on alles teel oma ärisüsteemide jaotatud arhitektuuride loomisele ning vaatavad huviga Erlangit/Elixirit, kuid kahtlevad, kas see on seda väärt...
Foto
Ainult registreeritud kasutajad saavad küsitluses osaleda. , palun.
Milliseid teemasid peaksin põhjalikumalt käsitlema tsükli "Eksperiment VTrade" raames?
Teooria: Turud, orderid ja nende kehtivus: DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Orderite raamat. Teooria ja praktika raamatute rakendamisest grupiga
Kaubanduse visualiseerimine: tiketid, baarid, resolutsioonid. Kuidas salvestada ja kleebendada
Tagakorter. Planeerimine ja arendus. Töötajate kontroll ja intsidentide uurimine
API. Selgitame välja, millised liidesed on vajalikud ja kuidas neid rakendada
Teabe salvestamine: PostgreSQL, Timescale, Tarantool kaubandussüsteemides
Reaktiivsus kaubandussüsteemides
Muu. Kirjutan kommentaaridesse
Hääletas 6 kasutajat. 4 kasutajat hoidusid.
Allikas: habr.com
