


Hoolimata sellest, et andmeid on peaaegu igal pool palju, on analüütilised andmebaasid endiselt üsna eksootilised. Neid tuntakse halvasti ja kasutatakse veelgi halvemini. Paljud jätkavad "kaktuse söömist" MySQL või PostgreSQL abil, mis on projekteeritud erinevate stsenaariumide jaoks, kannatavad NoSQL-i all või maksavad üle kommertslahenduste eest. ClickHouse muudab mängureegleid ja vähendab oluliselt sisenemisbarjääri analüütiliste andmebaaside maailmas.
Ettekanne BackEnd Conf 2018 ja see on avaldatud esineja loal.


Kes ma olen ja miks ma räägin ClickHouse'ist? Olen LifeStreeti arenduse direkter, kes kasutab ClickHouse'i. Lisaks olen Altinity asutaja. See on Yandexi partner, mis edendab ClickHouse'i ja aitab Yandexil teha ClickHouse'ist edukamat. Olen samuti valmis jagama teadmisi ClickHouse'i kohta.

Ja ma ei ole Petja Zaitsevi vend. Paljud küsivad seda sageli. Ei, me ei ole vennad.

«Igaühele on teada», et ClickHouse on:
- Väga kiire,
- Väga mugav,
- Kasutatakse Yandexis.
Veidi vähem on teada, millistes ettevõtetes ja kuidas seda kasutatakse.

Kertan teile, miks, kus ja kuidas ClickHouse'i kasutatakse peale Yandexi.
Selgitan, kuidas konkreetseid ülesandeid lahendatakse ClickHouse'i abil erinevates ettevõtetes, milliseid tööriistu saate ClickHouse'ist oma vajaduste jaoks kasutada ja kuidas neid erinevates ettevõtetes on rakendatud.
Olen valinud kolm näidet, mis näitavad ClickHouse'i erinevaid külgi. Arvan, et see on huvitav.

Esimene küsimus: "Miks on ClickHouse vajalik?". Tundub, et küsimus on piisavalt ilmne, kuid vastuseid sellele on rohkem kui üks.

- Esimene vastus on seotud tootlikkusega. ClickHouse on väga kiire. Analüüs ClickHouse'is on samuti väga kiire. Seda saab sageli kasutada seal, kus midagi muud töötab väga aeglaselt või halvasti.
- Teine vastus on seotud kuludega. Esiteks, skaleerimise kulud. Näiteks Vertica on täiesti suurepärane andmebaas. See töötab väga hästi, kui teil on mitte liiga palju terabaiti andmeid. Kuid kui jutt on sadadest terabaitidest või petabaitidest, siis litsentsi ja toe hind tõuseb piisavalt kõrgeks. Ja see on kallis. ClickHouse on aga tasuta.
- Kolmas vastus on opereerimise kulu. See lähenemine on veidi teistsugune. RedShift on suurepärane analoog. RedShiftis saab lahenduse väga kiiresti valmis teha. See töötab hästi, kuid iga tund, iga päev ja iga kuu maksate te Amazonile üsna palju, sest see on üsna kallis teenus. Google BigQuery samuti. Kui keegi on seda kasutanud, siis teab ta, et seal saab käivitada mitu päringut ja üllatusena saada emakasu sadu dollareid.
ClickHouse'is neid probleeme ei esine.

Kus kasutatakse ClickHouse'i praegu? Peale Yandexi kasutatakse ClickHouse'i paljudes erinevates äriühingutes ja ettevõtetes.
- Esiteks on see veebirakenduste analüüs, st see on kasutusjuht, mis tuli Yandexist.
- Paljud AdTech ettevõtted kasutavad ClickHouse'i.
- Mitmed ettevõtted, kes peavad analüüsima operatiivlogisid erinevatest allikatest.
- Mõned ettevõtted kasutavad ClickHouse'i turvalogide jälgimiseks. Nad laadivad need ClickHouse'i, teevad aruandeid ja saavad vajalikud tulemid.
- Ettevõtted hakkavad seda kasutama finantsanalüüsis, st järk-järgult hakkab ka suuräri ClickHouse'i kasutusele võtma.
- CloudFlare. Kui keegi jälgib ClickHouse'i, siis on ta kindlasti kuulnud selle ettevõtte nime. See on üks olulisemaid panustajaid kogukonnas. Nendel on väga tõsine ClickHouse'i paigaldus. Näiteks nad lõid Kafka Engine'i ClickHouse'ile.
- Telekommunikatsiooniettevõtted on hakanud seda kasutama. Mitmed ettevõtted kasutavad ClickHouse'i kas tõestusena mõtte või juba tootmises.
- Üks ettevõte kasutab ClickHouse'i tootmisprotsesside jälgimiseks. Nad testivad mikroskeeme, koguvad hulga parameetreid, seal on umbes 2000 omadust. Ja seejärel analüüsivad – kas partii on hea või halb.
- Blockchain-analüüs. On selline Venemaa ettevõte nagu Bloxy.info. See analüüsib ethereum'i võrku. Ka selle nad tegid ClickHouse'il.

Ja suurus ei oma tähtsust. On palju ettevõtteid, kes kasutavad ühte väikest serverit. See aitab neil lahendada nende probleeme. Ja veel rohkem ettevõtteid kasutab suuri klastreid paljusid serverite või tosin serverit.
Ja kui vaadata rekordite järgi, siis:
- Yandex: 500+ serverit, 25 miljardit kirjet päevas nad seal salvestavad.
- LifeStreet: 60 serverit, umbes 75 miljardit kirjet päevas. Servereid on vähem, kirjeid rohkem kui Yandex'il.
- CloudFlare: 36 serverit, 200 miljardit kirjet päevas nad salvestavad. Neil on veel vähem servereid ja veel rohkem andmeid, mida nad salvestavad.
- Bloomberg: 102 serverile, umbes triljon kirjet päevas. Rekordite loobja.
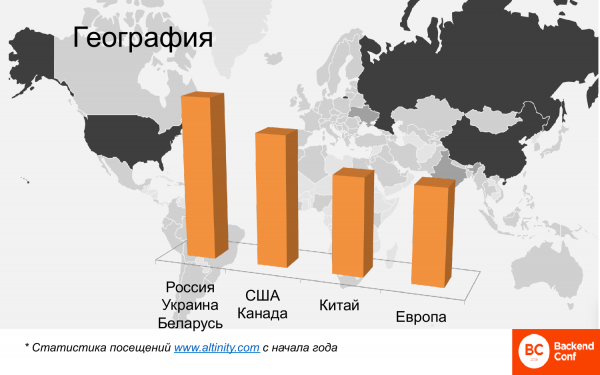
Geograafiliselt on see ka palju. See kaart näitab heatmap'i, kus ClickHouse'i maailmas kasutatakse. Siin paistab silma Venemaa, Hiina, Ameerika. Euroopa riike on vähe. Ja eristada saab 4 klastrit.
See on võrdlev analüüs, siin pole vaja otsida absoluutseid numbreid. See on analüüs külastajatest, kes loevad ingliskeelseid materjale Altinity saidil, kuna venekeelseid seal pole. Ja Venemaa, Ukraina, Valgevene, st venekeelne osa kogukonnast, on kõige arvukamad kasutajad. Järgnevad USA ja Kanada. Hiina jääb väga lähedale. Pool aastat tagasi ei olnud Hiinat peaaegu üldse, nüüd on Hiina juba Euroopat üle tükkis ja jätkab kasvu. Vanadaam Euroopa jääb samuti maha, ja ClickHouse'i kasutamise liider – nagu imelik see ei oleks, on Prantsusmaa.

Miks ma kõik seda räägin? Selleks, et näidata, et ClickHouse on muutumas standardseks lahenduseks suurte andmete analüüsiks ja seda kasutatakse juba väga paljudes kohtades. Kui te seda kasutate, siis olete õigel teel. Kui te seda veel ei kasuta, siis pole vaja karta, et jääte üksi ja keegi ei aita, sest paljud inimesed on juba sellega tegelenud.

Need on ClickHouse'i reaalsed kasutusnäited mitmetes ettevõtetes.
- Esimene näide on reklaamivõrgustik: üleminek Verticalt ClickHouse'ile. Ja ma tean mitmeid ettevõtteid, kes on Verticalt üle läinud või on ülemineku protsessis.
- Teine näide on tehinguhoidla ClickHouse'is. See näide põhineb anti-mustritel. Kõik, mida ei tohiks ClickHouse'is teha vastavalt arendajate soovitustele, on siin tehtud. Ja sellegipoolest on see nii tõhus, et see töötab. Ja töötab palju paremini kui tüüpiline tehingulahendus.
- Kolmas näide on jaotatud arvutused ClickHouse'is. Oli küsimus selle kohta, kuidas saab ClickHouse'i integreerida Hadoopi ökosüsteemi. Näitan näidet, kuidas ettevõte tegi ClickHouse'is midagi sarnast map reduce konteinerile, jälgides andmete lokaliseerimist jne, et lahendada väga keeruline ülesanne.

- LifeStreet – see on reklaamitehnoloogia ettevõte, millel on kõik tehnoloogiad, mis toetavad reklaamivõrku.
- Ta tegeleb reklaamide optimeerimise ja programmilise pakkumisega.
- Palju andmeid: umbes 10 miljardit sündmust päevas. Samas võivad sündmused jaguneda mitmeks alasündmuseks.
- Seda andmestikku kasutavad paljud kliendid, sealhulgas mitte ainult inimesed, vaid ka palju rohkem – erinevad algoritmid, mis tegelevad programmilise pakkumisega.

Ettevõte on läbinud pika ja keerulise tee. Ja ma rääkisin sellest HighLoadis. Alguses üleminek LifeStreet MySQL-lt (väikese peatumisega Oracle'il) Vertica-le. Ja selle kohta on võimalik leida lugu.
Ja kõik läks väga hästi, kuid üsna kiiresti sai selgeks, et andmed kasvavad ja Vertica on kallis. Seetõttu otsiti erinevaid alternatiive. Mõned neist on siin loetletud. Tegelikult tegime me tõestuskontseptsiooni või mõnikord jõudluskatsetusi peaaegu kõigi andmebaasidega, mis olid turul saadaval aastatel 2013 kuni 2016 ja sobisid oma funktsionaalsusega. Ja osa neist olin ma samuti HighLoadis rääkinud.

Olukord oli migreerida Verticast eelkõige, kuna andmed kasvasid. Ja need kasvasid eksponentsiaalselt mitu aastat. Kui nad lõpuks stabiliseerusid, oli siiski selge, et prognoosides seda kasvu, on äri nõudmised andmete mahu osas, mille põhjal tuleb teha mingeid analüüse, sellised, et varsti tuleb juttu petabaidist. Ja petabaidi eest maksmine on juba väga kallis, seetõttu otsiti alternatiivi, kuhu minna.
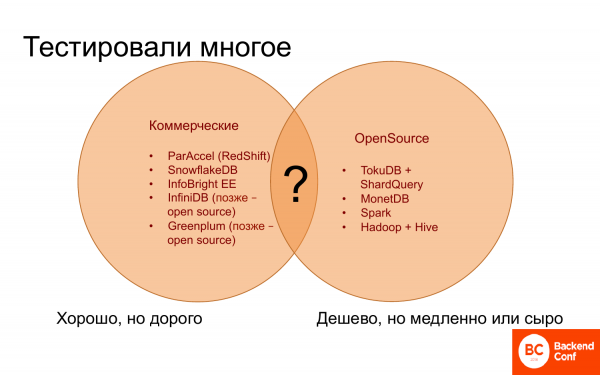
Kuhu minna? Pikka aega ei olnud selgelt aru saada, kuhu minna, kuna ühelt poolt on olemas kaubanduslikud andmebaasid, mis näivad töötavat hästi. Mõned töötavad peaaegu sama hästi kui Vertica, mõned aga halvemini. Kuid nad kõik on kallid, odavamat ja paremat leida ei õnnestunud.
Teiselt poolt on olemas avatud allika lahendused, mida on üsna vähe, st uurimiseks võib neid loendada sõrmedel. Need on tasuta või odavad, kuid töötavad aeglaselt. Tihti puudub neis vajalike ja kasulike funktsioonide hulk.
Seega, et koondada parim, mis kaubanduslikes andmebaasides on, ja kõik tasuta, mis avatud allikas leidub — midagi ei olnud.

Ei olnud suurt midagi, kuni Yandex ühel päeval ei tõmmanud ClickHouse'i nagu kunstnik kübara seest välja. See oli ootamatu otsus, mille üle endiselt küsitakse: „Miks?“, kuid siiski.
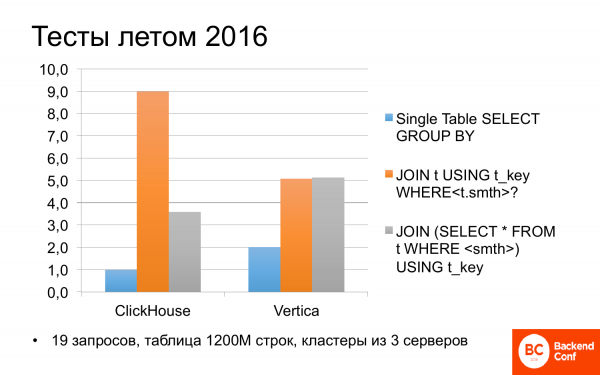
Ja kohe suvel 2016. aastal hakkasime vaatama, mis ClickHouse'i enda sees toimub. Selgus, et see võib kohati olla kiirem kui Vertica. Testisime erinevaid stsenaariume erinevate päringutega. Ja kui päring kasutas ainult üht tabelit, st ilma igasuguste liitumisteta (join), siis oli ClickHouse kaks korda kiirem kui Vertica.
Ma ei viitsinud ja vaatasin hiljuti ka Yandexi teste. Seal on sama: ClickHouse on kaks korda kiirem kui Vertica, seega räägivad nad sellest sageli.
Aga kui päringutes on liitumised (join), siis ei ole kõik nii üheselt arusaadav. Ja ClickHouse võib olla Vertica'ist kaks korda aeglasem. Kui päringut veidi kohendada ja ümber kirjutada, siis on tulemused enam-vähem võrdsed. Üsna hea. Ja tasuta.

Saades testide tulemused ja vaadates sellele eri nurkade alt, suunas LifeStreet ennast ClickHouse'i poole.

See on 2016. aasta, tuletan meelde. See oli nagu naljas, kus hiired nuttisid ja piinasid end, aga jätkasid kaktuse söömist. Sellest on põhjalikult räägitud, olemas on videod jne.

Seetõttu ei hakka ma sellest põhjalikult rääkima, vaid räägin vaid tulemustest ja mitmest huvitavast asjast, millest ma siis ei rääkinud.
Tulemused on järgmised:
- Edasi minek ja süsteem on töötanud tootmises üle aasta.
- Tõhusus ja paindlikkus on kasvanud. 10 miljardi kirje asemel, mida me suutsime päevas hoida ja seejuures lühikest aega, salvestab LifeStreet nüüd 75 miljardit kirjet päevas ja suudab seda teha 3 kuud või kauem. Kui arvestada tipptasemel, siis salvestatakse kuni miljon sündmust sekundis. Üle miljoni SQL-päringu päevas jõuab sellesse süsteemi, peamiselt erinevatelt robotitelt.
- Kuigi ClickHouse'i jaoks kasutatakse rohkem servereid kui Vertica jaoks, on ka riistvara kokkuhoid, kuna Verticas kasutati üsna kalliseid SAS-kettasid. ClickHouse'is kasutati SATA-kettasid. Miks? Sest Verticas on insert sünkroonne. Sünkroniseerimine nõuab, et kettad ei oleks liiga aeglased ja et võrk ei oleks liiga aeglane, st see on piisavalt kallis operatsioon. ClickHouse'is on insert asünkroonne. Veelgi enam, andmeid saab alati kohapeal kirjutada, lisakulusid ei ole, mistõttu saab ClickHouse'i andmeid sisestada palju kiiremini kui Verticas isegi mitte kõige kiirematel kettadel. Lugemine on aga enam-vähem sama. SATA lugemine, kui need on RAID-is, on piisavalt kiire.
- Ei ole litsentsiga piiratud, st 3 petabaiti andmeid 60 serveris (20 serverit – üks koopia) ja 6 triljonit kirjet faktides ja agregaatides. Me ei saanud Verticas midagi sellist endale lubada.

Nüüd liigun ma selle näite praktilistele asjadele.
- Esimene on tõhus skeem. Skeemi sõltub väga palju.
- Teine on tõhusate SQL-ide genereerimine.
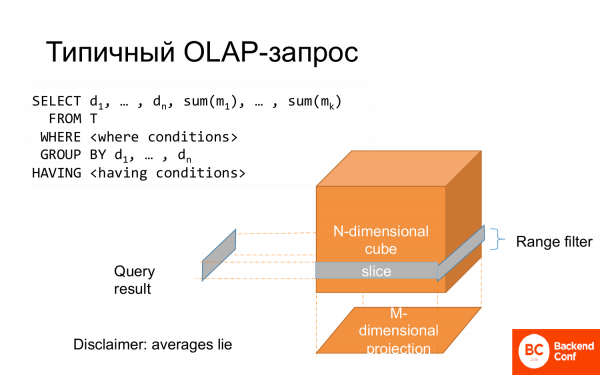
Tüüpiline OLAP-päring on select. Osa veerge on group by, osa veerge läheb aggregaatfunktsioonidesse. On olemas where, mida võib mõelda kui kuubi lõiku. Kogu group by võib mõelda kui projektsioon. Ja seetõttu nimetatakse seda mitmemõõtmeliseks andmeanalüüsiks.

Seda modelleeritakse sageli star-skeemina, kus keskne fakt ja selle omadused asuvad ümbritsevatel külgedel.

Ja füüsilise disaini seisukohalt, kuidas see andmebaasi tabelisse paigutatakse, luuakse tavaliselt normaliseeritud esitus. Võite seda denormaliseerida, kuid see on andmekasutuses kulukas ning vähem efektiivne päringute osas. Seetõttu luuakse tavaliselt normaliseeritud esitus, st faktitabel ja palju mõõtetabeleid.
Kuid ClickHouse'is ei toimi see hästi. On kaks põhjust:
- Esiteks, ClickHouse'il ei ole väga häid liitumisi (join), st liitumised (join) on olemas, kuid need on halvad. Siiani on nad halvad.
- Teiseks, tabelid ei uuene. Tavaliselt on star-skeemi ümber olevates tabelites midagi muuta. Näiteks kliendi nimi, firma nimi jne. Ja see ei toimi.
ClickHouse'il on sellest väljapääs. Tegelikult kaks:
- Esimene on sõnastike kasutamine. External Dictionaries aitavad 99% ulatuses lahendada star-skeemi probleemi, uuendusi ja muud.
- Teine on massiivide kasutamine. Massiivid aitavad samuti vabaneda join-idest ja normaliseerimise probleemidest.

- Join-e pole vaja.
- uuendatavad. Alates märtsist 2018 on ilmnenud dokumenteerimata võimalus (dokumentatsioonist te ei leia) uuendada sõnastikke osaliselt, st neid kirjeid, mis on muutunud. Praktikas on see nagu tabel.
- Alati mälus, seega join-id sõnastikuga töötavad kiiremini kui juhul, kui see oleks tabel, mis asub kettal, ja ei ole sugugi kindel, et see on vahemikus, tõenäoliselt mitte.

- Ega join-e pole vaja.
- See on kompaktne esitus 1 paljudele.
- Ja minu arvates on massiivid tehtud nördimiseks. Need on lambda-funktsioonid ja muu.
See ei ole iluelemendi jaoks. See on väga võimas funktsionaalsus, mis võimaldab teha paljusid asju väga lihtsalt ja elegantselt.

Tüüpilised näited, mis aitavad lahendada massiive. Need näited on lihtsad ja piisavalt visuaalsed:
- Otsimine siltide järgi. Kui teil on seal hashtags ja soovite leida mingit teavet hashtag'i järgi.
- Otsing key-value paaride kaudu. Samuti on mõned atribuudid väärtusega.
- Salvestage võtmete loendid, mille peate tõlkima millegi muuks.
Kõiki neid ülesandeid saab lahendada ilma massiivideta. Sildid saab panna ühte ritta ja valida regulaaravaldusega või panna eraldi tabelisse, kuid siis tuleb teha liitumised (join).

Ja ClickHouse'is ei pea midagi tegema, piisab string massiivi kirjeldamisest hashtagi jaoks või võib luua sisemise struktuuri key-value tüüpide süsteemide jaoks.
Sisemine struktuur – see võib-olla ei ole kõige õnnestunum nimetus. Need on kaks massiivi, millel on ühine osa nimes ja mõned omavahel seotud omadused.
Ja sildi järgi otsimine on väga lihtne. On funktsioon has, mis kontrollib, kas massiivis on element. Kõik, leidsime kõik kirjed, mis kuuluvad meie konverentsile.
Subidi järgi otsimine on veidi keerulisem. Peame esmalt leidma võtme indeksi ja siis võtma selle indeksi element ja kontrollima, kas see väärtus on see, mida vajame. Kuid see on ikkagi väga lihtne ja kompaktne.
Regulaarav väljend, mille sooviksite kirjutada, kui hoiaksite kõik ühes reas, oleks see esiteks kohmakas. Ja teiseks töötaks see palju kauem kui kaks massiivi.

Teine näide. Teil on massiiv, kus hoidsite ID-sid. Ja saate need nimedeks tõlkida. Funktsioon arrayMap. See on tüüpiline lambda-funktsioon. Te edastate sinna lambda-väljendeid. Ja see toob igale ID-le sõnastikust välja nime väärtuse.
Sama moodi saab teha ka otsingut. Edastatakse predikaatfunktsioon, mis kontrollib, millistele elementidele vastavad.

Need asjad lihtsustavad skeemi ja lahendavad hulga probleeme.
Aga järgmine probleem, millega me silmitsi seisame ja mille osas soovin mainida, on efektiivsed päringud.
- ClickHouse'is ei ole päringute planeerijat. Üldse mitte.
- Kuid keerulisi päringuid tuleb ikka planeerida. Millal?
- Kui päringus on mitu liitumist (join), mille te keerate alam-päringuteks. Ja järjekord, milles need täidetakse, on oluline.
- Ja teine – kui päring on jagatud. Sest jagatud päringus täidetakse ainult kõige sisemine alamvalik jagatuna, samas kui kõik muu saadetakse ühele serverile, millega olete ühendatud ja kus see täidetakse. Seega, kui teil on paljude liitumistega (join) jagatud päringud, tuleb valida järjekord.
Ja isegi lihtsamatel juhtudel on mõnikord otstarbekas planeerija tööd teha ja päringuid veidi ümber kirjutada.

Siin on näide. Vasakul on päring, mis näitab 5 parimat riiki. See täidetakse umbes 2,5 sekundi jooksul. Paremal on sama päring, kuid veidi ümber kirjutatud. Me ei gruppeerinud enam rea kaupa, vaid gruppeerisime võtme (int) kaupa. See on kiiremini. Ja siis liitsime tulemusele sõnaraamatu. Kui esimene päring võttis 2,5 sekundit, siis see uus päring täidetakse 1,5 sekundiga. See on hea.

Sarnane näide filtrite ümber kirjutamisest. Siin on päring Venemaa kohta. See täidetakse 5 sekundi jooksul. Kui me kirjutame selle ümber nii, et ei võrreldaks enam rida, vaid numbreid mõne võtme kogumiga, mis kuulub Venemaale, siis see on palju kiirem.

Selliseid trikke on palju. Need võimaldavad oluliselt kiirendada päringute tööd, mis teie arvates juba töötavad kiiresti või, vastupidi, töötavad aeglaselt. Neid saab veel kiiremini teha.

- Maksimaalne töö jaotatud režiimis.
- Sorteerimine minimaalsete tüüpide alusel, nagu ma seda intansid tehes tegin.
- Kui on mingid liitumised (join), sõnastikud, siis on parem need teha viimasel korral, kui teil on juba andmed vähemalt osaliselt grupeeritud, sest siis toimub liitumise (join) või sõnastiku väljakutsumine vähem ja see on kiirem.
- Filtrite asendamine.
On veel teisi tehnikaid, mitte ainult neid, mida ma demonstreerisin. Ja kõik need võimaldavad mõnikord oluliselt kiirendada päringute täitmist.

Läheme järgmise näite juurde. Firma X USA-st. Mida ta teeb?
Ülesanne oli:
- Offline-reklaami tehingute seondamine.
- Erinevate seondumise mudelite modelleerimine.

Mis on stsenaarium?
Tavaline külastaja külastab saiti umbes 20 korda kuus erinevatelt reklaamidel või lihtsalt nii, et ta meeles peab seda saiti. Ta vaatab tooteid, paneb need ostukorvi, võtab need ostukorvist välja. Ja lõpuks ostab ta midagi.
Mõistlikud küsimused: „Kellele tuleks reklaamihinna eest maksta, kui seda on vaja?” ja „Milline reklaam mõjutas teda, kui mõjutas?” See tähendab, miks ta ostis ja kuidas teha nii, et sarnased inimesed ostaksid samuti?
Selle ülesande lahendamiseks on vaja siduda sündmusi, mis veebisaidil juhtuvad, õigesti, st luua nende vahel seosed. Seejärel edastada need analüüsimiseks DWH-sse. Ja selle analüüsi põhjal luua mudel, kellele ja millist reklaami näidata.

Reklaamitehing on komplekt seotud kasutaja sündmustest, mis algavad reklaami kuvamisest, seejärel toimub midagi, mille järel võib järgneda ost ja potentsiaalselt ka edasised ostud. Näiteks, kui see on mobiilirakendus või mobiilmäng, siis installimine toimub tavaliselt tasuta, aga kui seal toimub midagi muud, võivad selleks kulud tekkida. Mida rohkem inimene rakenduses kulutab, seda väärtuslikumaks ta muutub. Kuid selleks tuleb kõik siduda.

On palju sidumise mudeleid.
Kõige populaarsemad on:
- Viimane interaktsioon, kus interaktsioon on kas klikk või kuvamine.
- Esimene interaktsioon, s.t. esimene asi, mis inimese veebilehele tõi.
- Lineaarne kombinatsioon – kõik võrdselt.
- Hävimine.
- Ja muud.
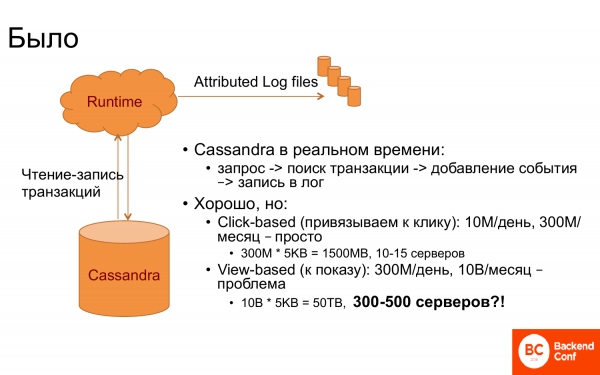
Kuidas see kõik algselt töötas? Oli Runtime ja Cassandra. Cassandra'd kasutati tehingute salvestamiseks, see tähendab, et seal salvestati kõik seotud tehingud. Ja kui mõni sündmus jõuab Runtime'i, näiteks kindla lehe kuvamine või midagi muud, siis tehti päring Cassandra'sse – kas selline inimene eksisteerib või mitte. Siis toodi välja temaga seotud tehingud ja tehti sidumine.
Ja kui õnnestub leida tehingu ID, siis on see lihtne. Kuid tavaliselt ei ole õnne. Seetõttu oli vaja leida viimane tehing või tehing viimase klõpsuga jne.
See töötas väga hästi, kuni sidumine toimis viimase klõpsuga. Kuna klikke on näiteks 10 miljonit päevas, 300 miljonit kuus, kui seada kuu vahemik. Ja kuna Cassandras peab see kõik olema mälus, et see kiiresti töötaks, kuna nõutakse, et Runtime vastaks kiiresti, siis oli vaja umbes 10-15 serverit.
Kuid kui sooviti siduda tehingu näitamisega, ei olnud see enam nii lõbus. Miks? Näha on, et 30 korda rohkem sündmusi tuleb salvestada. Ja seetõttu on vaja 30 korda rohkem servereid. Ja see tundub olevat mingisugune astronoomiline number. Hoidmine kuni 500 serverit, et saavutada sidumine, samas kui Runtime serverite arv on oluliselt väiksem, on vale number. Ja hakati mõtlema, mida teha.

Ja jõuti ClickHouse'i. Kuidas seda ClickHouse'is teha? Esmapilgul tundub, et see on antipatternide kogum.
- Tehing suureneb, me liidame sellele üha uusi sündmusi, st see on muudetav, samas kui ClickHouse ei toimi eriti hästi muudetavate objektidega.
- Kui külastaja meie juurde jõuab, peame välja tõmbama tema tehingud võtme, st tema külastuse ID järgi. See on samuti punktipäring, mida ClickHouse ei kasuta. Tüüpiliselt ClickHouse'is kasutatakse suuri... skaneerimisi, kuid siin peame saama mõned kirjed. Samuti on see vastupidine muster.
- Lisaks oli tehing JSON-is, kuid ümber kirjutada ei soovitud, seetõttu soovisime hoiustada JSON-i struktureerimata kujul, ja kui vaja, siis midagi sealt välja võtta. See on samuti vastupidine muster.
St. ühte kogumit vastupidiseid mustreid.
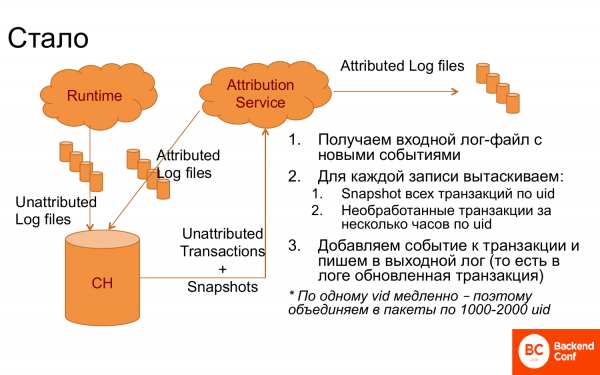
Kuid sellegipoolest õnnestus luua süsteem, mis töötas väga hästi.
Mis on tehtud? Tekkis ClickHouse, kuhu koguti logid, jagatuna sissekanneteks. Ilmus attributed teenus, mis sai ClickHouse'ilt logid. Pärast seda saadi iga sissekande jaoks visit id kaudu tehingud, mis võisid olla veel töötlemata, ja lisaks snapshot'id, st juba seotud tehingud, nimelt eelneva töö tulemus. Nendest loodi juba loogika, valiti õige tehing ja ühendati uued sündmused. Seejärel salvestati logi uuesti. Logi saadeti tagasi ClickHouse'i, st tegu oli pidevalt tsüklilise süsteemiga. Ning lisaks saadeti see DWH-sse, et seal analüüsida.
Just sellisel kujul see ei töötanud väga hästi. Ja et ClickHouse'i päring oleks lihtsam, gruppeerisime need päringud visit id kaupade kaupa 1 000-2 000 ja tõmbasime 1 000-2 000 inimese jaoks kõik tehingud. Ja siis see kõik hakkas tööle.
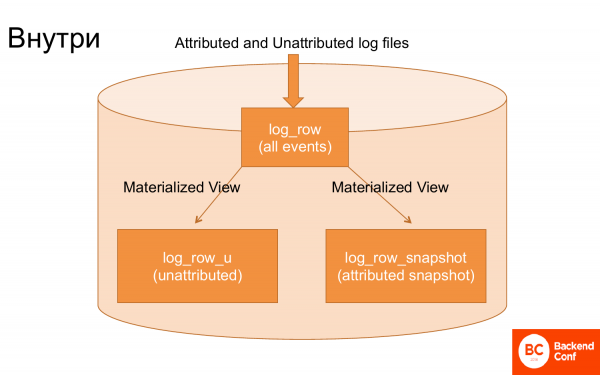
Kui vaadata ClickHouse'i sisse, siis seal on kokku 3 põhitaanet, mis seda kõike teenindavad.
Esimene tabel, kuhu logid laetakse, ja logid laetakse praktiliselt ilma töötlemiseta.
Teine tabel. Neid logisid käidi materialiseeritud vaate kaudu läbi, mis ei oleks veel omistatud sündmused, st seostumata. Ja nende logide materialiseeritud vaate kaudu toodi välja tehingud, et luua seisak. Ehk spetsiifiline materialiseeritud vaade koosnes seisakust, milleks oli viimase kogunenud tehingu seisund.
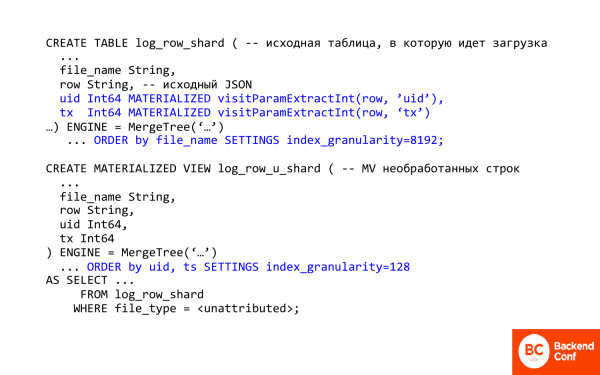
Siin on kirjutatud tekst SQLis. Tahaksin sellele märkida mitu olulist asja.
Esimene oluline asi on võimalus ClickHouse'is JSONist väljavõtteid teha veergudest ja väljadest. Ehk ClickHouse'is on mõned meetodid JSONiga töötamiseks. Need on väga-väga primitiivsed.
visitParamExtractInt võimaldab JSONist atribuutide väljavõtteid teha, st esimene sobitamine aktiveerub. Niimoodi saab välja võtta tehingu ID või külastuse ID. See on üks.
Teiseks – siin on kasutatud nutikat materialiseeritud väljad. Mida see tähendab? See tähendab, et te ei saa seda tabelisse sisestada, st see ei ole sisestatav, see arvutatakse ja salvestatakse sisestamisel. Sisestamisel teeb ClickHouse teie eest töö ära. Ja juba toodud JSONist see, mis teil hiljem vajalik on.
Antud juhul on materialiseeritud vaade mõeldud töötlemata ridade jaoks. Just seda kasutatakse esimese tabeli puhul, kus on praktiliselt toored logid. Ja mida ta teeb? Esiteks muudab ta sortimist, st sortimine toimub nüüd külastuse ID põhjal, sest meil on oluline kiiresti leida konkreetse isiku tehing.
Teine oluline asi on index_granularity. Kui olete näinud MergeTree'd, siis tavaliselt on index_granularity vaikimisi 8192. Mis see on? See on indeksi harvuse parameeter. ClickHouse'is on indeks harv, ta ei indekseeri kunagi iga kirje. Ta teeb seda iga 8192. tagant. See on hea, kui on vaja palju andmeid arvutada, aga halb, kui on vähe, sest on suur overhead. Ja kui vähendame index granularity't, siis vähendame overhead'i. Ühte vähendada ei saa, sest kui mälu ei jätku. Indeks on alati mälus.

Ja snapshot kasutab veel mõningaid huvitavaid ClickHouse'i funktsioone.
Esiteks on see AggregatingMergeTree. Ja AggregatingMergeTree's hoitakse argMax, st see on tehingu olek, mis vastab viimasele timestamp'ile. Tehingud genereeritakse pidevalt uute külastajate jaoks. Ja viimasest tehingu olekust lisasime sündmuse ja meil tekkis uus olek. See jõudis tagasi ClickHouse'i. Ja argMax kaudu selles materialiseeritud esituses saame alati kätte ajakohase oleku.

- Sidumine on «lahutatud» Runtime'ist.
- Kuni 3 miljardit tehingut kuus salvestatakse ja töödeldakse. See on kordades rohkem kui oli Cassandra's, s.t. tüüpilises tehingusüsteemis.
- 2x5 ClickHouse'i serverikluster. 5 serverit, kus iga serveril on koopia. See on isegi vähem, kui oli Cassandra's click based atribuutimise tegemiseks, ja siin on meil impression based. S.t. selle asemel, et suurendada serverite arvu 30 korda, õnnestus neid vähendada.

Ja viimane näide on finantsfirma Y, mis analüüsis aktsiate hindade muutuste korrelatsioone.
Ja ülesanne oli järgmine:
- On umbes 5000 aktsiat.
- Hinnad on teada iga 100 millisekundi järel.
- Andmed on kogunenud 10 aasta jooksul. Ilmselt on mõne ettevõtte jaoks rohkem, mõne jaoks vähem.
- Kokku umbes 100 miljardit rida.
Ja tuli arvutada muudatuste korrelatsioon.
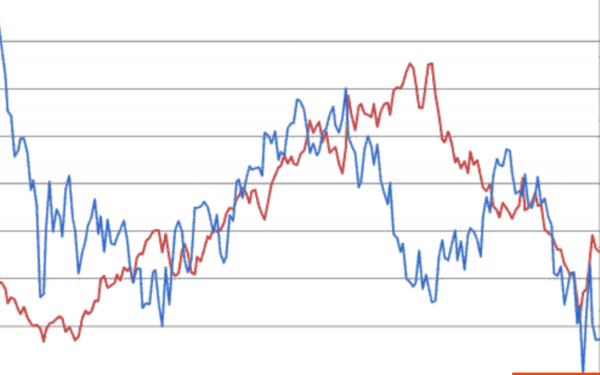
Siin on kaks aktsiat ja nende kursid. Kui üks tõuseb ja teine tõuseb, siis on see positiivne korrelatsioon, st kui üks kasvab, siis kasvab ka teine. Kui üks tõuseb, nagu graafiku lõpus, ja teine langeb, siis on see negatiivne korrelatsioon, st kui üks kasvab, siis teine langeb.
Analüüsides neid vastastikuseid muudatusi, saab teha prognoose finantsturul.

Kuid ülesanne on keeruline. Mida selleks tehakse? Meil on 100 miljardit kirjet, milles on: aeg, aktsia ja hind. Peame esmalt arvutama 100 miljardit korda runningDifference hindade algoritmist. RunningDifference on ClickHouse'is funktsioon, mis arvutab järjestikku kahe rea vahe.
Ja pärast seda tuleb arvutada korrelatsioon, lisaks tuleb korrelatsioon arvutada iga paari jaoks. 5000 aktsia jaoks on paare 12,5 miljonit. Ja see on palju, st 12,5 korda tuleb arvutada sellist korrelatsiooni funktsiooni.
Ja kui keegi unustas, siis ͞x ja ͞y on statistiline ootus. See tähendab, et tuleb arvutada mitte ainult juured ja summad, vaid ka nende summade sees veel teised summad. Koguda tuleb tohutult arvutusi 12,5 miljonit korda ja samas on vaja ka tunni kaupa grupeerida. Ja tunde on meil ka päris palju. Ja kõik see tuleb teha 60 sekundi jooksul. See on nali.

Kuid mingil viisil pidin ma ära suutma, sest kõik see töötas enne ClickHouse'i saabumist väga, väga aeglaselt.

Nad üritasid seda arvutada Hadoopi, Spark'i ja Greenplum'i peal. Ja kõik juhtus väga aeglaselt või oli kallis. See tähendab, et teatud määral sai arvutada, kuid see oli hiljem kallis.
Ja siis tuli ClickHouse ning kõik läks palju paremaks.
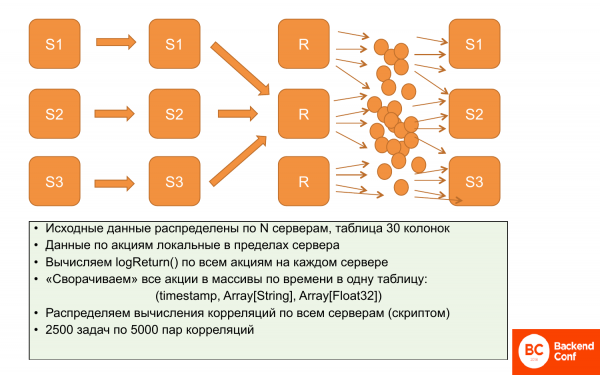
Tuletan meelde, et meil on andmete lokaalsusega probleem, seetõttu ei saa korrelatsioone lokaliseerida. Me ei saa andmeid ühele serverile ja teisele teise serverisse koondada ja arvutada, me peame kõik andmed olema kõikides kohtades.
Mida nad tegid? Alguses olid andmed lokaliseeritud. Iga serveri peal hoitakse andmeid teatud aktsiate hindade osas. Ja need ei üksteisega ristuva. Seega saab logReturni paralleelselt ja sõltumatult arvutada, kõik see toimub samal ajal ja on jaotatud.
Edasi otsustasime neid andmeid vähendada, kaotamata seejuures väljendusrikkust. Vähendada massiivide abil, st iga ajavahemiku jaoks luua aktsiate ja hindade massiivid. Nii võtab andmete salvestamine palju vähem ruumi. Ja nendega on ka veidi mugavam töötada. Need on peaaegu paralleelsed opereerimised, st arvutame paralleelselt osaliselt ja salvestame seejärel serverisse.
Pärast seda saab seda replikeerida. Täht "r" tähendab, et need andmed oleme replikeerinud. St kõikidel kolmel serveril on samu andmeid – need massiivid.
Seejärel saab spetsiaalse skripti abil sellest komplektist 12,5 miljonist korrelatsioonist, mida tuleb arvutada, teha pakette. St 2 500 ülesannet 5 000 korrelatsiooni paari kohta. Ja seda ülesannet saab arvutada konkreetse ClickHouse serveris. Tal on kõik andmed, kuna andmed on samad ja ta saab neid järjestikult arvutada.
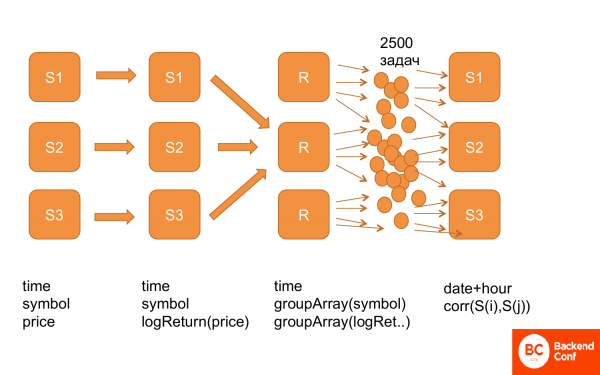
Veel veel, kuidas see välja näeb. Esiteks on meil kõik andmed sellises struktuuris: aeg, aktsiad, hind. Siis arvutasime logReturn'i, st sama struktuuri andmed, ainult et hinna asemel on meil juba logReturn. Pärast seda muutsime need ümber, st saime aja ja groupArray aktsiate ja hindade kaupa. Me ühendame need. Ja pärast seda genereerisime hunniku ülesandeid ja toitsime need ClickHouse'ile, et ta saaks need arvutada. Ja see töötab.

Proof of concept ülesande puhul oli see alamine ülesanne, st võtsime vähem andmeid. Ja vaid kolme serveri peal.
Need kaks esimest etappi: log_return'i arvutamine ja massiividesse mähkimine võttis kumbki umbes tunni.
Aga korrelatsiooni arvutamine kestis kuskil 50 tundi. Kuid 50 tundi on vähe, sest varem töötas see nädalate kaupa. See oli suur edu. Ja kui arvestada, siis 70 korda sekundis arvutati kõike sellel klastril.
Aga kõige olulisem on see, et see süsteem on praktiliselt ilma kitsaskohtadeta, st see skaleerub praktiliselt lineaarselt. Ja nad kontrollisid seda. Nad skaleerisid selle edukalt.

- Õige skeem on pool edu. Ja õige skeem on kasutada kõiki vajalikke tehnoloogiaid ClickHouse'is.
- Summing/AggregatingMergeTrees on tehnoloogiad, mis võimaldavad agregreerida või lugeda snapshots olekuna kui erandit. See lihtsustab paljusid asju.
- Materialiseeritud vaated võimaldavad ületada ühte indeksi piirangut. Võib-olla ei väljendanud ma seda väga selgelt, kuid kui me laadisime logisid, siis toored logid olid tabelis ühe indeksiga, samas kui atribuutide logid olid tabelis, st sama teave, lihtsalt filtreeritud, kuid indeks oli täiesti erinev. Tunduvad nagu samad andmed, kuid erinev sorteerimine. Ja Materialiseeritud vaated võimaldavad, kui see on vajalik, selliseid piiranguid ClickHouse'is ümber käia.
- Vähendage indeksi granulaarsust täpppäraste päringute jaoks.
- Ja jagage andmeid nutikalt, püüdke maksimaalselt lokaliseerida andmeid serveri sees. Ja püüe, et päringud kasutaks samuti lokaliseerimist seal, kus see on võimalikult maksimaalne.
Kokkuvõtteks võib öelda, et ClickHouse on nüüd kindlalt valitsenud nii kommertsbasseinide kui ka avatud lähtekoodiga andmebaaside alal, st just analüütika jaoks. See on suurepäraselt sobitunud sellesse maastikku. Ja veel enam, see hakkab vaikselt teisi välja tõrjuma, sest kui on olemas ClickHouse, siis ei ole vajadust InfiniDB järele. Veritka võib peagi olla mittevajalik, kui nad teevad normaalse SQL toe. Kasutage seda!

—Aitäh ettekande eest! Väga huvitav! Kas oli mingeid võrdlusi Apache Phoenixiga?
- Ei, ma ei ole kuulnud, et keegi oleks võrdlejat. Me ja Yandex püüame jälgida kõiki ClickHouse'i võrdlusi erinevate andmebaasidega. Sest kui äkki osutub midagi kiiremini ClickHouse'ist, siis Aleksei Milovidov ei suuda öösel magada ja hakkab seda kiiresti kiirendama. Ma ei ole sellest võrdlusest kuulnud.
(Aleksandr Milovidov) Apache Phoenix on SQL-mootor Hbase'il. Hbase on peamiselt mõeldud key-value tüüpi töödeks. Igas reas võib olla suvaline arv veerge suvaliste nimedega. Sama kehtib ka selliste süsteemide kohta nagu Hbase, Cassandra. Neis ei toimita rasked analüütilised päringud korralikult. Võite arvata, et need töötavad hästi, kui teil pole ClickHouse'iga töötamisest mingit kogemust.
Aitäh
Tere päevast! Olen juba päris palju selle teema vastu huvi tundnud, sest mul on analüüsisüsteem. Kuid kui vaatan ClickHouse'i, tekib mul tunne, et ClickHouse sobib väga hästi sündmuste analüüsimiseks, mutable. Ja kui mul on vaja analüüsida palju ärilisi andmeid koos suure hulga tabelitega, siis ClickHouse, nii palju kui ma aru saan, ei sobi mulle eriti? Eriti kui need muudavad. Kas see on õige või on olemas näiteid, mis võiksid selle ümber lükata?
See on õige. Ja see kehtib enamikule spetsialiseeritud analüütikabaasidest. Need on kohandatud ühe või mitme suure, muudetava tabeli ja paljude väikeste, aeglaselt muutuvate tabelite jaoks. Ehk siis ClickHouse ei ole nagu Oracle, kuhu saab panna kõike ja luua väga keerulisi päringuid. Et ClickHouse'i tõhusalt kasutada, tuleb skeem üles ehitada viisil, mis ClickHouse'is hästi toimib. Ehk tuleks vältida liialdatud normaliseerimist, kasutada sõnastikke ja üritada luua vähem pikki seoseid. Ja kui skeem selliselt üles ehitada, siis saavad sarnased äriülesanded ClickHouse'is olema lahendatud palju efektiivsemalt kui traditsioonilistes relaatiivsetes andmebaasides.
Aitäh ettekande eest! Mul on küsimus viimase finantsjuhtumi kohta. Neil oli analüüs. Pidi olema võrdlus, kuidas asjad üles ja alla käivad. Ja ma saan aru, et te ehitasite süsteemi just seda analüüsi silmas pidades? Kui neil homsest on näiteks vaja mingit muud aruannet nende andmete põhjal, peab skeemi uuesti üles ehitama ja andmed uuesti laadima? Ehk siis tuleb teha mingit eeltöötlust, et päring saada?
Muidugi, see on ClickHouse'i kasutamine konkreetse ülesande jaoks. Traditsiooniliselt oleks see võib-olla lahendatud Hadoopi raames. Hadoopile on see ideaalne ülesanne. Kuid Hadoopis on see väga aeglane. Minu eesmärk on demonstreerida, et ClickHouse'is saab lahendada ülesandeid, mida tavaliselt lahendatakse täiesti erinevate vahenditega, kuid samas palju efektiivsemalt. See on suunatud konkreetsele ülesandele. Selge on, et kui on sarnane ülesanne, siis saab seda sarnasel viisil lahendada.
Selge. Te ütlesite, et 50 tundi töötati. Kas see hõlmas algust, kui andmed üles laaditi või saadi tulemused?
Jah-jah.
Hea, aitäh väga.
See on 3-serveri klastris.
Tere! Aitäh ettekande eest! Kõik on väga huvitav. Küsin veidi mitte funktsionaalsuse kohta, vaid ClickHouse'i kasutamisest stabiilsuse seisukohalt. Kas teil on olnud mingeid probleeme, kas on olnud vaja taastada? Kuidas ClickHouse selle ajal käitub? Ja kas juhtus nii, et teil langes välja ka replikatsioon? Meie, näiteks, oleme ClickHouse'is kokku puutunud probleemiga, kus see ületab siiski oma limiidi ja kukub.
Muidugi, ideaalseid süsteeme pole. Ka ClickHouse'il on oma probleemid. Kuid kas olete kuulnud, et Yandex.Metrica ei töötanud pikka aega? Ilmselt mitte. See on usaldusväärselt töötanud ClickHouse'is umbes 2012-2013. aastast. Ma võin rääkida ka oma kogemusest. Meil pole kunagi olnud täielikke katkestusi. Mõned osalised probleemid võisid esineda, kuid need ei ole kunagi olnud piisavalt kriitilised, et tõsiselt äri mõjutada. Sellist olukorda pole kunagi olnud. ClickHouse on piisavalt usaldusväärne ega kuku juhuslikult. Selle pärast ei pea muretsema. See ei ole tooraine. Seda on tõestanud paljud ettevõtted.
Tere! Te ütlesite, et andmemudelit tuleb kohe hästi läbi mõelda. Aga kui see juba juhtus? Andmed voolavad ja voolavad. Aasta möödub ja ma saan aru, et nii ei saa elada, mul on vaja andmeid uuesti üles laadida ja nendega midagi ette võtta.
See sõltub loomulikult teie süsteemist. On mitu võimalust seda praktiliselt katkematult teha. Näiteks võite luua materialiseeritud vaate, millesse luua teine andmestruktuur, kui seda saab ühemõtteliselt kaardistada. St. kui see võimaldab kaardistamist ClickHouse'i abil, st. teatud asjade väljavõtmist, primaarvõtme muutmist, partitsioneerimist muutmist, siis saab luua materialiseeritud vaate. Sinna kirjutatakse teie vanad andmed, uued kirjutatakse automaatselt. Ja siis saab lihtsalt üle minna materialiseeritud vaate kasutamisele, seejärel suunata kirjutamine ja hävitada vana tabel. See on täiesti katkematu meetod.
Aitäh.
Allikas: habr.com
