

Tere päevast Minu nimi on Danil Lipovoy, meie Sbertechi meeskond hakkas kasutama HBase'i operatiivandmete salvestusruumina. Selle õppimise käigus on kogunenud kogemusi, mida tahtsin süstematiseerida ja kirjeldada (loodame, et see on paljudele kasulik). Kõik allpool olevad katsed viidi läbi HBase'i versioonidega 1.2.0-cdh5.14.2 ja 2.0.0-cdh6.0.0-beta1.
- Üldarhitektuur
- Andmete kirjutamine HBASE-sse
- Andmete lugemine HBASE-st
- Andmete vahemällu salvestamine
- Pakettandmete töötlemine MultiGet/MultiPut
- Tabelite piirkondadeks jagamise strateegia (jagamine)
- Veataluvus, tihendamine ja andmete lokaliseerimine
- Seaded ja jõudlus
- Stressi testimine
- Järeldused
1. Üldarhitektuur
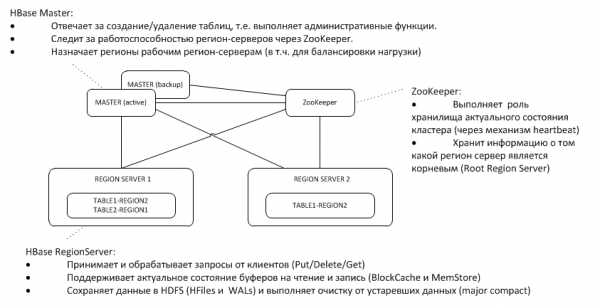
Varumeister kuulab ZooKeeperi sõlmel aktiivse südamelööke ja võtab kadumise korral üle masteri funktsioonid.
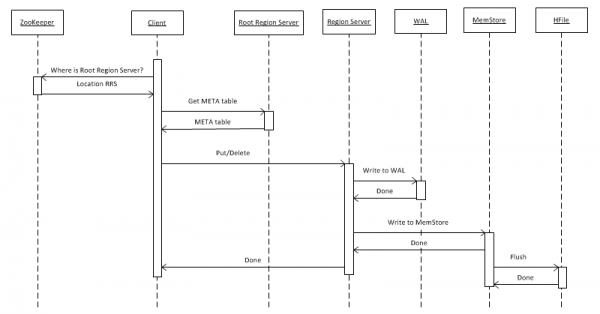
2. Kirjutage andmed HBASE-sse
Kõigepealt vaatame lihtsaimat juhtumit – võtmeväärtuse objekti kirjutamist tabelisse put(rowkey) abil. Klient peab esmalt välja selgitama, kus asub juurpiirkonna server (RRS), mis salvestab hbase:meta tabeli. Ta saab selle teabe ZooKeeperilt. Pärast seda pääseb see juurde RRS-ile ja loeb hbase:meta tabelit, millest eraldab teabe selle kohta, milline RegionServer (RS) vastutab huvipakkuvas tabelis antud reaklahvi andmete salvestamise eest. Edaspidiseks kasutamiseks salvestab metatabeli klient vahemällu ja seetõttu lähevad järgmised kõned kiiremini otse RS-i.
Järgmisena kirjutab RS pärast päringu saamist selle esmalt WriteAheadLog-i (WAL), mis on vajalik krahhi korral taastamiseks. Seejärel salvestab andmed MemStore'i. See on mälus olev puhver, mis sisaldab antud piirkonna jaoks sorteeritud võtmete komplekti. Tabeli saab jagada piirkondadeks (sektsioonideks), millest igaüks sisaldab lahutatud võtmete komplekti. See võimaldab suurema jõudluse saavutamiseks paigutada piirkondi erinevatesse serveritesse. Vaatamata selle väite ilmsusele näeme hiljem, et see ei tööta kõigil juhtudel.
Peale kande MemStore'i sisestamist tagastatakse kliendile vastus, et kirje salvestamine õnnestus. Kuid tegelikkuses salvestatakse see ainult puhvris ja jõuab kettale alles pärast teatud aja möödumist või kui see on täidetud uute andmetega.
Toimingu “Kustuta” sooritamisel andmeid füüsiliselt ei kustutata. Need märgitakse lihtsalt kustutatuks ja hävitamine ise toimub peamise kompaktfunktsiooni kutsumise hetkel, mida on üksikasjalikumalt kirjeldatud lõigus 7.
HFile-vormingus failid kogutakse HDFS-i ja aeg-ajalt käivitatakse väike kompaktne protsess, mis lihtsalt liidab väikesed failid suuremateks ilma midagi kustutamata. Aja jooksul muutub see probleemiks, mis ilmneb ainult andmete lugemisel (selle juurde tuleme veidi hiljem tagasi).
Lisaks ülalkirjeldatud laadimisprotsessile on olemas palju tõhusam protseduur, mis on võib-olla selle andmebaasi tugevaim külg - BulkLoad. See seisneb selles, et moodustame iseseisvalt HFiles ja paneme need kettale, mis võimaldab meil suurepäraselt skaleerida ja saavutada väga korralikud kiirused. Tegelikult pole siin piirang mitte HBase, vaid riistvara võimalused. Allpool on alglaadimistulemused klastri kohta, mis koosneb 16 RegionServerist ja 16 NodeManager YARNist (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 lõime), HBase'i versioon 1.2.0-cdh5.14.2.
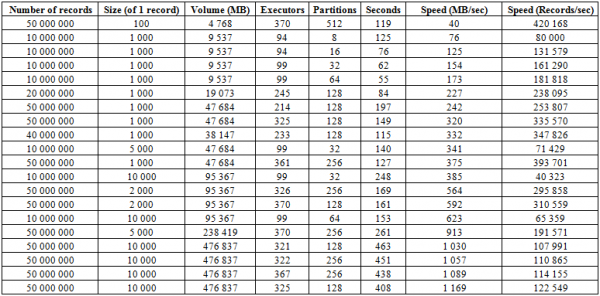
Siin näete, et suurendades tabelis olevate partitsioonide (regioonide) ja ka Sparki täitjate arvu, saame allalaadimiskiiruse tõusu. Samuti sõltub kiirus salvestuse helitugevusest. Suured plokid suurendavad MB/sek, väikesed plokid sisestatud kirjete arvu ajaühiku kohta, kusjuures kõik muud asjad on võrdsed.
Samuti saate alustada laadimist korraga kahte tabelisse ja saada topeltkiirust. Allpool on näha, et 10 KB plokkide kirjutamine kahte tabelisse korraga toimub kiirusega umbes 600 MB/sek igas (kokku 1275 MB/sek), mis ühtib ühte tabelisse kirjutamise kiirusega 623 MB/sek (vt. nr 11 ülal)

Kuid teine jooks 50 KB rekordiga näitab, et allalaadimiskiirus veidi kasvab, mis näitab, et see läheneb piirväärtustele. Samal ajal tuleb meeles pidada, et HBASE-le endale koormust praktiliselt ei teki, selleks on vaja vaid anda esmalt andmed hbase:meta-st ja pärast HFiles'i vooderdamist lähtestada BlockCache'i andmed ja salvestada MemStore'i puhver kettale, kui see pole tühi.
3. Andmete lugemine HBASE-st
Kui eeldame, et kliendil on kogu info hbase:meta-st juba olemas (vt punkt 2), siis läheb päring otse RS-i, kus on salvestatud vajalik võti. Esiteks tehakse otsing MemCache'is. Olenemata sellest, kas seal on andmeid või mitte, tehakse otsing ka BlockCache puhvris ja vajadusel HFilesis. Kui failist leiti andmeid, paigutatakse need BlockCache'i ja tagastatakse järgmisel päringul kiiremini. HFile'is on otsimine suhteliselt kiire tänu Bloom filtri kasutamisele, st. olles lugenud väikese hulga andmeid, teeb see kohe kindlaks, kas see fail sisaldab vajalikku võtit ja kui ei, siis liigub edasi järgmise juurde.
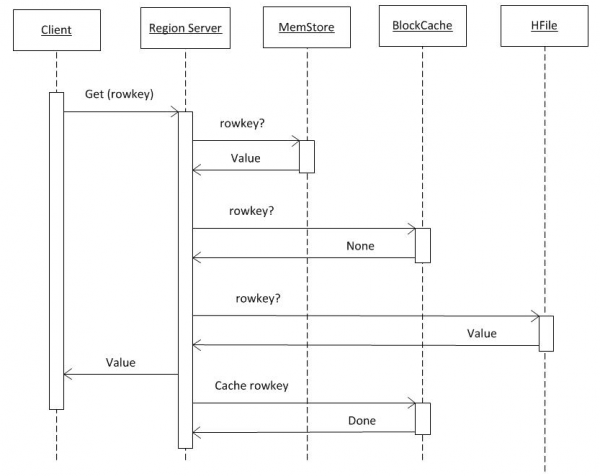
Pärast nendest kolmest allikast andmete saamist genereerib RS vastuse. Eelkõige saab see üle kanda mitu objekti leitud versiooni korraga, kui klient taotles versioonimist.
4. Andmete vahemällu salvestamine
MemStore'i ja BlockCache'i puhvrid hõivavad kuni 80% eraldatud kuhjasisesest RS-mälust (ülejäänud osa on reserveeritud RS-i teenindusülesannete jaoks). Kui tüüpiline kasutusrežiim on selline, et protsessid kirjutavad ja loevad kohe samu andmeid, siis on mõttekas vähendada BlockCache'i ja suurendada MemStore'i, sest Kui kirjutamisandmed ei satu lugemiseks vahemällu, kasutatakse BlockCache'i harvemini. BlockCache puhver koosneb kahest osast: LruBlockCache (alati hunnikus) ja BucketCache (tavaliselt hunnikuväline või SSD-l). BucketCache'i tuleks kasutada siis, kui lugemistaotlusi on palju ja need ei mahu LruBlockCache'i, mis viib prügikoguja aktiivsele tööle. Samal ajal ei tohiks lugemisvahemälu kasutamisest oodata radikaalset jõudluse kasvu, kuid pöördume selle juurde tagasi lõigus 8.
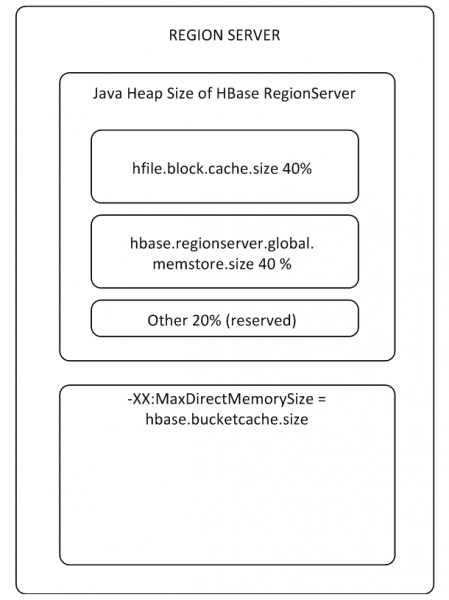
Kogu RS-i jaoks on üks BlockCache ja iga tabeli jaoks on üks MemStore (üks iga veeru perekonna jaoks).
Kui teoreetiliselt ei lähe kirjutamisel andmed vahemällu ja tõepoolest, sellised parameetrid CACHE_DATA_ON_WRITE tabeli jaoks ja “Cache DATA on Write” RS jaoks on seatud vääraks. Praktikas on aga nii, et kui me kirjutame andmed MemStore'i, siis loputame need kettale (seega tühjendame), seejärel kustutame saadud faili, siis hangimispäringu täites saame andmed edukalt kätte. Veelgi enam, isegi kui keelate BlockCache'i täielikult ja täidate tabeli uute andmetega, seejärel lähtestate MemStore'i kettale, kustutate need ja taotlete neid teisest seansist, hangitakse need ikkagi kuskilt alla. Nii et HBase ei salvesta mitte ainult andmeid, vaid ka salapäraseid saladusi.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Parameeter "Cache DATA on Read" on seatud väärtusele Väär. Kui teil on ideid, võite neid kommentaarides arutada.
5. Pakettandmete töötlemine MultiGet/MultiPut
Üksikute päringute töötlemine (Get/Put/Delete) on üsna kulukas toiming, nii et võimalusel tuleks need kombineerida Listiks või Loendiks, mis võimaldab jõudlust oluliselt suurendada. See kehtib eriti kirjutamisoperatsiooni kohta, kuid lugemisel on järgmine lõks. Allolev graafik näitab MemStore'ist 50 000 kirje lugemiseks kuluvat aega. Lugemine viidi läbi ühes lõimes ja horisontaaltelg näitab päringus olevate klahvide arvu. Siin on näha, et ühes päringus tuhande võtmeni suurendades langeb täitmise aeg, s.t. kiirus suureneb. Kui aga MSLAB-režiim on vaikimisi lubatud, algab pärast seda läve jõudluse radikaalne langus ja mida suurem on kirje andmemaht, seda pikem on tööaeg.
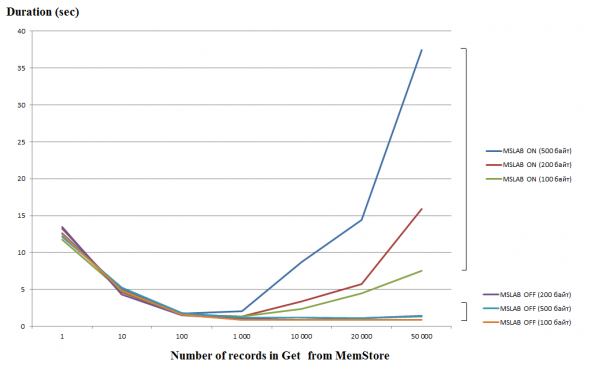
Testid viidi läbi virtuaalmasinas, 8 tuumaga, versioon HBase 2.0.0-cdh6.0.0-beta1.
MSLAB-režiim on loodud hunniku killustatuse vähendamiseks, mis tekib uue ja vana põlvkonna andmete segunemise tõttu. Kui MSLAB on lubatud, paigutatakse andmed lahendusena suhteliselt väikestesse lahtritesse (tükkidena) ja töödeldakse tükkidena. Selle tulemusena, kui nõutud andmepaketi maht ületab eraldatud suuruse, langeb jõudlus järsult. Teisest küljest ei ole selle režiimi väljalülitamine samuti soovitatav, kuna see põhjustab intensiivse andmetöötluse hetkedel GC tõttu seisakuid. Hea lahendus on lahtri mahu suurendamine aktiivse kirjutamise kaudu put-i kaudu lugemisega samal ajal. Väärib märkimist, et probleem ei ilmne, kui käivitate pärast salvestamist loputuskäsu, mis lähtestab MemStore'i kettale, või kui laadite BulkLoadi abil. Allolev tabel näitab, et MemStore'i päringud suuremate (ja sama hulga) andmete kohta põhjustavad aeglustumist. Suurendades tükkide suurust, taastame töötlemisaja normaalseks.
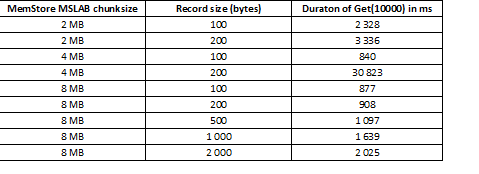
Lisaks tükkide suuruse suurendamisele aitab andmete jagamine piirkondade kaupa, s.t. laua poolitamine. Selle tulemusel tuleb igasse piirkonda vähem päringuid ja kui need lahtrisse mahuvad, jääb vastus heaks.
6. Tabelite piirkondadeks jagamise strateegia (jagamine)
Kuna HBase on võtmeväärtuste salvestusruum ja jaotamine toimub võtme alusel, on äärmiselt oluline jagada andmed ühtlaselt kõigi piirkondade vahel. Näiteks sellise tabeli kolmeks osaks jagamisel jagatakse andmed kolme piirkonda:
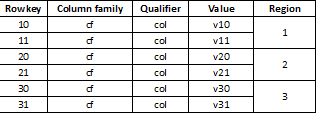
Juhtub, et see viib järsu aeglustumiseni, kui hiljem laaditud andmed näevad välja näiteks pikad väärtused, millest enamik algab sama numbriga, näiteks:
1000001
1000002
...
1100003
Kuna võtmed on salvestatud baidimassiivina, algavad need kõik samamoodi ja kuuluvad samasse piirkonda nr 1, kus see võtmevahemik on salvestatud. Jaotusstrateegiaid on mitu:
HexStringSplit – muudab võtme kuueteistkümnendsüsteemis kodeeritud stringiks vahemikus "00000000" => "FFFFFFFF" ja lisab vasakule nullid.
UniformSplit – muudab võtme baitimassiiviks kuueteistkümnendkoodiga vahemikus "00" => "FF" ja täidis paremal nullidega.
Lisaks saate jagamiseks määrata mis tahes vahemiku või võtmete komplekti ja konfigureerida automaatset poolitamist. Üks lihtsamaid ja tõhusamaid lähenemisviise on aga UniformSplit ja räsikonkatenatsiooni kasutamine, näiteks kõige olulisem baitide paar võtme käivitamisel funktsiooni CRC32 (rowkey) kaudu ja reaklahv ise:
räsi + reaklahv
Seejärel jaotatakse kõik andmed piirkondade vahel ühtlaselt. Lugemisel visatakse esimesed kaks baiti lihtsalt ära ja alles jääb algne võti. RS kontrollib ka andmemahtu ja võtmeid piirkonnas ning limiitide ületamise korral jagab selle automaatselt osadeks.
7. Vea taluvus ja andmete lokaalsus
Kuna iga võtmekomplekti eest vastutab ainult üks piirkond, on RS-i krahhi või dekomisjoneerimisega seotud probleemide lahenduseks kõigi vajalike andmete salvestamine HDFS-i. Kui RS langeb, tuvastab kapten selle ZooKeeperi sõlme südamelöökide puudumise tõttu. Seejärel määrab see teenindatava piirkonna teisele RS-ile ja kuna HFiles on salvestatud hajutatud failisüsteemi, loeb uus omanik neid ja jätkab andmete teenindamist. Kuna aga osa andmetest võib olla MemStore'is ja neil ei olnud aega HFilesi siseneda, kasutatakse toimingute ajaloo taastamiseks WAL-i, mis on samuti salvestatud HDFS-i. Pärast muudatuste rakendamist on RS võimeline päringutele vastama, kuid kolimine viib selleni, et osa andmeid ja neid teenindavaid protsesse satuvad erinevatesse sõlmedesse, s.t. paikkond väheneb.
Probleemi lahendus on suur tihendamine - see protseduur liigutab failid nende eest vastutavatesse sõlmedesse (kus asuvad nende piirkonnad), mille tulemusena suureneb selle protseduuri käigus võrgu ja ketaste koormus järsult. Tulevikus aga kiireneb ligipääs andmetele märgatavalt. Lisaks ühendab major_compaction kõik HF-failid ühes piirkonnas ja puhastab ka andmed olenevalt tabeli sätetest. Näiteks saate määrata objekti versioonide arvu, mida tuleb säilitada, või eluea, mille järel objekt füüsiliselt kustutatakse.
Sellel protseduuril võib olla väga positiivne mõju HBase'i tööle. Alloleval pildil on näha, kuidas aktiivse andmesalvestuse tulemusel jõudlus halvenes. Siin näete, kuidas 40 lõime kirjutasid ühte tabelisse ja 40 lõime lugesid samaaegselt andmeid. Lõimede kirjutamine genereerib üha rohkem H-faile, mida loevad teised lõimed. Selle tulemusena tuleb üha rohkem andmeid mälust eemaldada ja lõpuks hakkab tööle GC, mis praktiliselt halvab kogu töö. Suure tihendamise käivitamine tõi kaasa tekkinud prahi koristamise ja tootlikkuse taastamise.
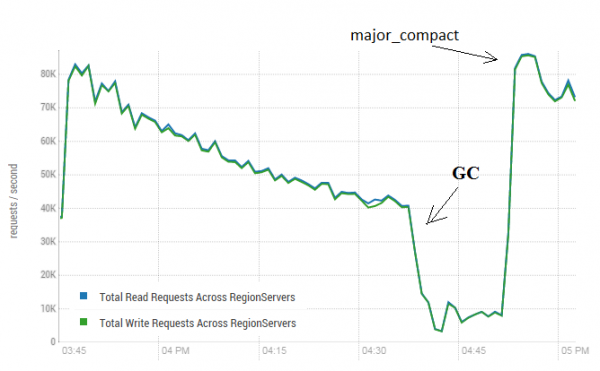
Test viidi läbi 3 DataNode ja 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 keermega). HBase'i versioon 1.2.0-cdh5.14.2
Väärib märkimist, et suurem tihendamine käivitati "reaalajas" tabelis, kuhu andmeid aktiivselt kirjutati ja loeti. Internetis oli väide, et see võib andmete lugemisel põhjustada vale vastuse. Kontrollimiseks käivitati protsess, mis genereeris uued andmed ja kirjutas need tabelisse. Pärast mida lugesin ja kontrollisin kohe, kas saadud väärtus kattub kirjapanduga. Selle protsessi käigus viidi suuremat tihendamist läbi umbes 200 korda ja ühtegi riket ei registreeritud. Võib-olla ilmneb probleem harva ja ainult suure koormuse korral, mistõttu on kindlam peatada kirjutamis- ja lugemisprotsessid plaanipäraselt ning teostada puhastus, et vältida GC-i tühjenemist.
Samuti ei mõjuta suur tihendamine MemStore'i olekut; selle kettale loputamiseks ja tihendamiseks peate kasutama flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Seaded ja jõudlus
Nagu juba mainitud, näitab HBase oma suurimat edu BulkLoadi käivitamisel seal, kus tal pole vaja midagi teha. See kehtib aga enamiku süsteemide ja inimeste kohta. See tööriist sobib aga pigem andmete hulgi salvestamiseks suurtes plokkides, samas kui protsess nõuab mitut konkureerivat lugemis- ja kirjutamistaotlust, kasutatakse ülalkirjeldatud käske Get ja Put. Optimaalsete parameetrite määramiseks käivitati tabeli parameetrite ja sätete erinevate kombinatsioonidega:
- 10 lõime käivitati korraga 3 korda järjest (nimetagem seda lõimede plokiks).
- Ploki kõigi lõimede tööaeg keskmistati ja see oli ploki töö lõpptulemus.
- Kõik lõimed töötasid sama tabeliga.
- Enne iga keermeploki käivitamist tehti suurem tihendus.
- Iga plokk sooritas ainult ühe järgmistest toimingutest:
— Pane
— Hangi
— Hangi+Pane
- Iga plokk sooritas oma operatsiooni 50 000 iteratsiooni.
- Kirje ploki suurus on 100 baiti, 1000 baiti või 10000 XNUMX baiti (juhuslik).
- Plokid käivitati erineva arvu nõutud võtmetega (kas üks võti või 10).
- Plokid jooksid erinevate tabeliseadete all. Muudetud parameetrid:
— BlockCache = sisse või välja lülitatud
— BlockSize = 65 KB või 16 KB
— vaheseinad = 1, 5 või 30
— MSLAB = lubatud või keelatud
Nii et plokk näeb välja selline:
a. MSLAB-režiim lülitati sisse/välja.
b. Loodi tabel, mille jaoks määrati järgmised parameetrid: BlockCache = true/none, BlockSize = 65/16 Kb, Partition = 1/5/30.
c. Kompressioon määrati GZ-le.
d. 10 lõime käivitati samaaegselt, tehes sellesse tabelisse 1/10/100 baiti kirjetega 1000/10000 put/get/get+put toiminguid, sooritades järjest 50 000 päringut (juhuslikud võtmed).
e. Punkti d korrati kolm korda.
f. Kõikide keermete tööaeg keskmistati.
Testiti kõiki võimalikke kombinatsioone. On ennustatav, et rekordi suuruse kasvades kiirus väheneb või vahemällu salvestamise keelamine põhjustab aeglustumist. Eesmärk oli aga mõista iga parameetri mõju määra ja olulisust, mistõttu kogutud andmed sisestati lineaarse regressioonifunktsiooni sisendisse, mis võimaldab hinnata olulisust t-statistika abil. Allpool on Put-operatsioone sooritavate plokkide tulemused. Täielik kombinatsioonide komplekt 2*2*3*2*3 = 144 valikut + 72 tk. mõnda tehti kaks korda. Seega on kokku 216 jooksu:
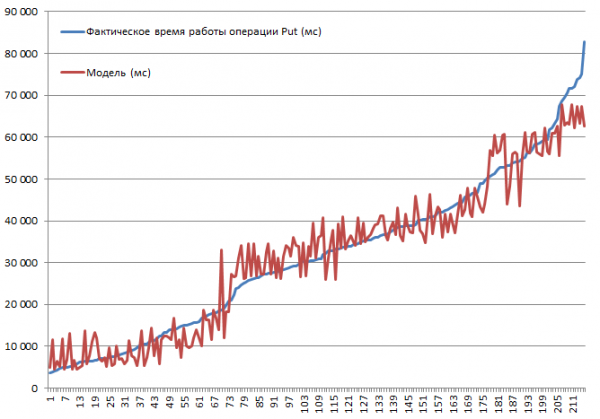
Testimine viidi läbi miniklastris, mis koosnes 3 DataNode'ist ja 4 RS-st (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 lõime). HBase'i versioon 1.2.0-cdh5.14.2.
Suurim sisestamise kiirus, 3.7 sekundit, saavutati väljalülitatud MSLAB-režiimiga, ühe partitsiooniga tabelis, kui BlockCache oli lubatud, BlockSize = 16, kirjed 100 baiti, 10 tükki paki kohta.
Madalaim sisestamiskiirus 82.8 sekundit saadi MSLAB-režiimi lubamisel, ühe partitsiooniga tabelis, kus BlockCache oli lubatud, BlockSize = 16, kirjed 10000 1 baiti, igaüks XNUMX.
Vaatame nüüd mudelit. Näeme R2-l põhineva mudeli head kvaliteeti, kuid on täiesti selge, et ekstrapoleerimine on siin vastunäidustatud. Süsteemi tegelik käitumine parameetrite muutumisel ei ole lineaarne, seda mudelit pole vaja ennustamiseks, vaid selleks, et mõista, mis antud parameetrite piires juhtus. Näiteks näeme siin Studenti kriteeriumist, et parameetrid BlockSize ja BlockCache ei oma Put-operatsiooni puhul tähtsust (mis on üldiselt üsna etteaimatav):

Kuid tõsiasi, et partitsioonide arvu suurendamine toob kaasa jõudluse vähenemise, on mõnevõrra ootamatu (oleme juba näinud BulkLoadiga partitsioonide arvu suurendamise positiivset mõju), kuigi arusaadav. Esiteks tuleb töötlemiseks genereerida päringud ühe piirkonna asemel 30 piirkonnale ja andmemaht ei ole nii suur, et sellest kasu oleks. Teiseks määrab kogu tööaja kõige aeglasem RS ja kuna DataNode'ide arv on väiksem kui RS-ide arv, on mõnel piirkonnal null asukoht. Noh, vaatame viit parimat:

Nüüd hindame Get blocki käivitamise tulemusi:

Sektsioonide arv on kaotanud tähtsuse, mis on ilmselt seletatav asjaoluga, et andmed on hästi vahemällu salvestatud ja lugemisvahemälu on (statistiliselt) kõige olulisem parameeter. Loomulikult on päringu sõnumite arvu suurendamine ka jõudluse jaoks väga kasulik. Parimad hinded:

Noh, lõpuks vaatame ploki mudelit, mis esmakordselt sooritas hankimise ja seejärel pani:

Kõik parameetrid on siin olulised. Ja juhtide tulemused:

9. Koormustestimine
Noh, lõpuks käivitame enam-vähem korraliku koormuse, kuid alati on huvitavam, kui teil on, millega võrrelda. Cassandra võtmearendaja DataStaxi veebisaidil on olemas NT mitmest NoSQL-i salvestusruumist, sealhulgas HBase'i versioon 0.98.6-1. Laadimine toimus 40 lõime, andmemahuga 100 baiti, SSD-ketaste abil. Loe-Muuda-Kirjuta operatsioonide testimise tulemus näitas järgmisi tulemusi.
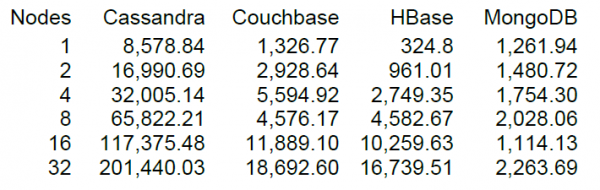
Minu arusaamist mööda viidi lugemine läbi 100 kirje plokkides ja 16 HBase sõlme puhul näitas DataStaxi test jõudlust 10 tuhat toimingut sekundis.
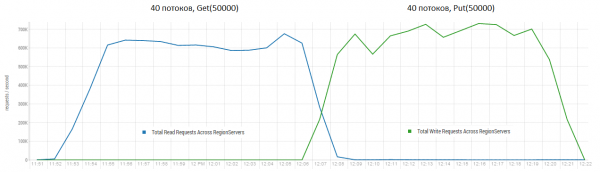
Õnneks on ka meie klastris 16 sõlme, kuid pole kuigi "õnnelik", et igaühel on 64 südamikku (lõime), samas kui DataStaxi testis on neid ainult 4. Teisalt on neil SSD-draivid, meil aga HDD-d. või rohkem HBase'i uus versioon ja protsessori kasutamine koormuse ajal praktiliselt ei suurenenud (visuaalselt 5-10 protsenti). Proovime siiski seda konfiguratsiooni kasutama hakata. Tabeli vaikeseaded, lugemine toimub võtmevahemikus 0 kuni 50 miljonit juhuslikult (st sisuliselt iga kord uus). Tabel sisaldab 50 miljonit kirjet, mis on jagatud 64 sektsiooniks. Võtmed räsitakse kasutades crc32. Tabeli sätted on vaikimisi, MSLAB on lubatud. Käivitades 40 lõime, loeb iga lõime 100 juhusliku võtme komplekti ja kirjutab loodud 100 baiti kohe nendesse võtmetesse tagasi.
Alus: 16 DataNode ja 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 keerme). HBase'i versioon 1.2.0-cdh5.14.2.
Keskmine tulemus on lähemal 40 tuhandele toimingule sekundis, mis on oluliselt parem kui DataStaxi testis. Kuid katselistel eesmärkidel saate tingimusi veidi muuta. On üsna ebatõenäoline, et kogu töö tehakse ainult ühel laual ja ka ainult unikaalsete võtmetega. Oletame, et on olemas teatud "kuum" võtmete komplekt, mis genereerib põhikoormuse. Seetõttu proovime luua koormus suuremate kirjetega (10 KB), ka 100 partiidena, 4 erinevas tabelis ja piirates taotletavate võtmete vahemikku 50 tuhandeni.. Allolev graafik näitab 40 lõime käivitamist, iga lõime loeb 100 klahvi komplekti ja kirjutab neile klahvidele kohe juhuslikult 10 KB tagasi.
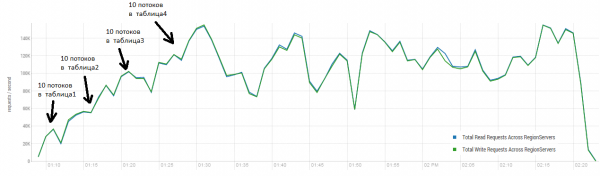
Alus: 16 DataNode ja 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 keerme). HBase'i versioon 1.2.0-cdh5.14.2.
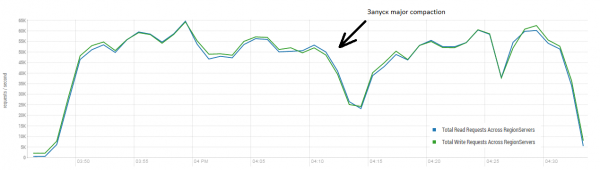
Koormamise ajal käivitati mitu korda suurem tihendus, nagu ülal näidatud, ilma selle protseduurita halveneb jõudlus järk-järgult, kuid täitmise ajal tekib ka lisakoormus. Maksehäireid põhjustavad erinevad põhjused. Mõnikord lõpetasid lõimed töötamise ja nende taaskäivitamisel tekkis paus, mõnikord tekitasid kolmanda osapoole rakendused klastri koormuse.
Lugemine ja kohe kirjutamine on HBase'i jaoks üks raskemaid tööstsenaariume. Kui teete ainult väikseid, näiteks 100 baidiseid, 10-baidiseid müügipäringuid, kombineerides need 50-50 tuhande tükkideks, võite saada sadu tuhandeid toiminguid sekundis ja kirjutuskaitstud päringutega on olukord sarnane. Väärib märkimist, et tulemused on radikaalselt paremad kui DataStaxi tulemused, eelkõige tänu taotlustele XNUMX tuhande suurustes plokkides.
Alus: 16 DataNode ja 16 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 keerme). HBase'i versioon 1.2.0-cdh5.14.2.
10. Järeldused
See süsteem on üsna paindlikult konfigureeritud, kuid paljude parameetrite mõju on endiselt teadmata. Mõnda neist testiti, kuid neid ei lisatud saadud testikomplekti. Näiteks näitasid esialgsed katsed ebaolulist tähtsust sellisel parameetril nagu DATA_BLOCK_ENCODING, mis kodeerib teavet naaberrakkude väärtuste abil, mis on arusaadav juhuslikult genereeritud andmete puhul. Kui kasutate palju dubleerivaid objekte, võib kasu olla märkimisväärne. Üldiselt võib öelda, et HBase jätab mulje üsna tõsisest ja läbimõeldud andmebaasist, mis võib suurte andmeplokkidega toimingute tegemisel olla üsna produktiivne. Eriti kui lugemis- ja kirjutamisprotsesse on võimalik ajas eraldada.
Kui teie arvates on midagi, mida pole piisavalt avalikustatud, olen valmis teile üksikasjalikumalt rääkima. Kutsume teid jagama oma kogemusi või arutama, kui te millegagi ei nõustu.
Allikas: www.habr.com
