


Tere kõigile!
Mina olen Nikita, Ciani inseneride meeskonna juht. Üks minu kohustustest ettevõttes on vähendada tootmises esinevate infrastruktuuriga seotud intsidentide arvu nullini.
Olukord, millest edaspidi juttu tuleb, on meile palju valu põhjustanud, ning selle artikli eesmärk on takistada teisi inimesi meie vigu kordamast või vähemalt nende mõju minimeerimist.
Eelõigus
Kaugel minevikus, kui Cian koosnes monoliitidest ja mikroteenuste märke ei olnud veel, mõõtsime ressursi kättesaadavust 3–5 lehe kontrollimisega.
Kui need vastasid — kõik oli hästi, kui nad pikka aega ei vastanud — tuli alert. Kui kaua nad peavad olema mittetoimivad, et seda peeti intsidendiks, määrasid inimesed koosolekutel. Inseneride meeskond osales alati intsidendi uurimisel. Uurimise lõpetamisel kirjutati postmortem — omamoodi aruanne e-posti teel, vormingus: mis juhtus, kui kaua see kesti, mida me toona tegime, mida me tulevikus teeme.
Olulised veebilehe lehed või kuidas me mõistame, et oleme põhja jõudnud
Ette mõista vea prioriteeti, oleme välja toonud kõige kriitilisemad teie äritegevusele olulised veebilehe lehed. Nende põhjal arvutame edukaid/ebaedu päringute ja katkestuste arvu. Sel moel mõõdame uptime'i.
Oletame, et oleme tuvastanud mitmeid üliolulisi osa saidist, mis vastutavad peamise teenuse — kuulutuste otsimise ja esitamise — eest. Kui vigadega lõppevate päringute arv ületab 1%, on see kriitiline juhtum. Kui tippajad 15 minuti jooksul on vea protsent üle 0,1%, loetakse see samuti kriitiliseks juhtumiks. Need kriteeriumid katab enamik juhtumeid, teised jäävad artikli raamesse.
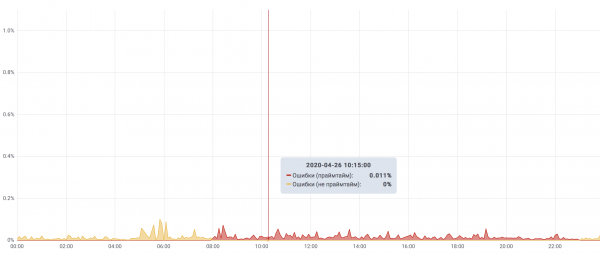
Cian parimate juhtumite tipplist
Nii et me oleme kindlasti õppinud määrama, et juhtum on aset leidnud.
Nüüd on iga juhtum meil üksikasjalikult välja toodud ning peegeldatud Jira epikus. Märkusena: selle jaoks oleme loonud eraldi projekti, nimetasime selle FAIL-iks — seal saab luua ainult epikuid.
Kui koguda kõik ebaõnnestumised viimase paariaasta jooksul, siis juhivad:
- juhtumid, mis on seotud mssql-iga;
- juhtumid, mis on põhjustatud välistest teguritest;
- administraatori vead.
Vaatame lähemalt administraatorite vigu ning mõned teised huvitavad ebaõnnestumised.
Viiendat kohta hõivame „DNS-i korrastamisega“
See oli sombune teisipäev. Otsustasime korrastada DNS-kliendiga.
Soovisime migreerida sisemised DNS-serverid bindilt powerdns-ile, eraldades selleks täiesti eraldi serverid, kus muud teenused puudusid.
Paigaldasime igasse meie andmekeskuse asukohta ühe DNS-serveri ning järgnes domeenide üleviimise hetk bindilt powerdns-ile ja infrastruktuuri suunamine uutele serveritele.
Üleviimise kõige aktiivsemal hetkel serverite, mis oli märgitud kohalike vahemällu salvestavate bind-ide seas kõigil serveritel, jäi alles ainult üks, mis asus andmekeskuses Peterburis. See andmekeskus oli algselt deklareeritud meile mitte-kriitilisena, kuid muutus äkitselt kriitiliseks punktiks.
Just üleviimise ajal kukkus ühendus Moskva ja Peterburi vahel. Oleme praktiliselt DNS-ist ilma jäänud viis minutit ja taastunud siis, kui hoster vead olid kõrvaldatud.
Järeldused:
Varem eemaldasime välistest teguritest tööde ettevalmistamisel, kuid nüüd on need ka valmistumise loendis. Nüüd püüdleme selle poole, et kõik komponendid oleksid reserveeritud n-2, ning tööde ajaks saame seda taset langetada n-1-ni.
- Tegevusplaani koostamise ajal märkige üles punktid, kus teenus võib kokku kukkuda, ja mõelge läbi stsenaarium, kus kõik läheb "halvemast hullemaks".
- Jaotage sisemised DNS-serverid erinevatesse geolokatsioonidesse / andmekeskustesse / riiulitesse / lülititesse / sisenditesse.
- Igal serveril olge kohalik vahemällu salvestav DNS-server, mis suunab päringud peamistele DNS-serveritele ning juhul, kui see pole saadaval, vastab vahemälust.
Neljas koht — "Korrastame Nginxi"
Ühel päeval otsustas meie meeskond, et "on piisavalt talutud" ja käivitus nginx konfiguratsioonide refaktoreerimise protsess. Peamine eesmärk on tuua konfiguratsioonid intuitiivsesse struktuuri. Varem oli kõik "ajalooliselt kujunenud" ja ei kandnud endas mingit loogikat. Nüüd on iga server_name välja toodud oma nime saanud faili ning kõik konfiguratsioonid jaotatud kaustadesse. Ütlematagi selge, et konfiguratsioon sisaldab 253949 rida või 7836520 tähte ja hõivab peaaegu 7 megabaiti. Ülemine struktuur:
Nginx struktuur
├── access
│ ├── allow.list
...
│ └── whitelist.conf
├── geobase
│ ├── exclude.conf
...
│ └── geo_ip_to_region_id.conf
├── geodb
│ ├── GeoIP.dat
│ ├── GeoIP2-Country.mmdb
│ └── GeoLiteCity.dat
├── inc
│ ├── error.inc
...
│ └── proxy.inc
├── lists.d
│ ├── bot.conf
...
│ ├── dynamic
│ └── geo.conf
├── lua
│ ├── cookie.lua
│ ├── log
│ │ └── log.lua
│ ├── logics
│ │ ├── include.lua
│ │ ├── ...
│ │ └── utils.lua
│ └── prom
│ ├── stats.lua
│ └── stats_prometheus.lua
├── map.d
│ ├── access.conf
│ ├── ..
│ └── zones.conf
├── nginx.conf
├── robots.txt
├── server.d
│ ├── cian.ru
│ │ ├── cian.ru.conf
│ │ ├── ...
│ │ └── my.cian.ru.conf
├── service.d
│ ├── ...
│ └── status.conf
└── upstream.d
├── cian-mcs.conf
├── ...
└── wafserver.confAs a result of renaming and redistributing the configs, some of them had incorrect extensions and were not included in the include *.conf directive. Consequently, some hosts became unavailable and returned a 301 redirect to the main page. Because the response code was neither 5xx nor 4xx, this issue was not noticed immediately and was caught only by morning. After this, we started writing tests to verify infrastructure components.
Järeldused:
- Struktureeri konfiguratsioonid õigesti (mitte ainult nginx) ja mõtle struktuuri juba projekti varases etapis. Nii muudate need meeskonnale arusaadavamaks, mis omakorda vähendab TTM-i.
- Mõnede infrastruktuuri komponentide jaoks kirjutage teste. Näiteks: kontrollige, et kõik võtme server_name’id annavad õiged staatuse ja vastuse sisu. Piisab, kui teil on mõned skriptid, mis kontrollivad põhifunktsioone, et mitte keset ööd paanikas mõelda, mida veel kontrollida.
Kolmas koht – „Cassandra's lõppes ühtäkki ruum“
Andmed kasvasid järk-järgult ja kõik oli hästi, kuni hetkeni, mil Cassandra klastris hakkasid suured kayspace'de repair'id kukkuma, kuna compaction ei suutnud nendega töötada.
Ühel tormisel päeval muutus klaster peaaegu kõrvitsaks, nimelt:
- klastri kokku jääb umbes 20% ruumi;
- node’e ei saa korralikult lisada, kuna pärast node’i lisamist ei toimu cleanup’i ruumipuuduse tõttu jaotustes;
- tõhusus langeb järk-järgult, kuna kompaktimine ei toimi;
- klaster töötab hädaolukorras.
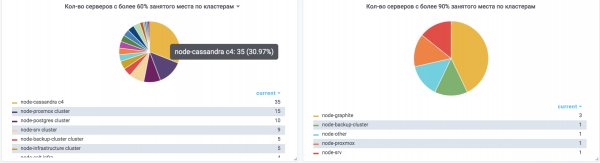
Välja minek — lisasime veel 5 sõlme ilma puhastuseta, pärast mida hakkasime järk-järgult klastrist välja viima ja uuesti sisestama nagu tühjad sõlmed, millel polnud enam ruumi. Aega on kulunud palju rohkem, kui oleks soovinud. Olius osaline või täielik juurdepääsu katkemise oht.
Järeldused:
- Kõigil cassandra serveritel peaks olema iga jaotuse peal maksimaalselt 60% ruumist kasutusel.
- Need peaksid olema koormatud mitte rohkem kui 50% CPU-st.
- Ärge jätke tähelepanuta kapatsiteedi planeerimist ja peate seda arvestama iga komponendiga, lähtudes selle spetsifikast.
- Mida rohkem sõlmi klastris on, seda parem. Serverid, millel on väike andmete hulk, saavad kiiremini uuesti käivitada, ja sellist klastrit on lihtsam elustada.
Teine koht — „Andmed kadusid consul key-value salvestusest“
Teenuse avastamiseks kasutame nagu paljud teisedki konsulti. Kuid meil kasutatakse seda key-value süsteemi ka monoliidi sinine-roheline juurutamiseks. Seal salvestatakse teave aktiivsete ja mitteaktiivsete upstreamide kohta, mis vahetavad kohti juurutamise ajal. Selle jaoks kirjutati juurutamisteenus, mis suhtles KV-ga. Mingil hetkel andmed KV-st kadusid. Taastasime need mälu abil, kuid mõne vea tõttu. Tagajärjeks oli see, et juurutamisel jaotus koormus upstreamide vahel ebaühtlaselt ja saime palju 502 vigu, kuna backendide CPU oli üle koormatud. Lõpuks kolisime consul KV-st postgres'i, kust andmete kustutamine pole enam nii lihtne.
Järeldused:
- Teenused, millel pole mingit autentimist, ei tohiks sisaldada veebisaidi töö jaoks kriitilisi andmeid. Näiteks, kui teil pole autentimist ES-is, oleks parem piirata pääsu võrgu tasandil kõikjalt, kus see pole vajalik, jätta alles ainult vajalikud ning seadistada action.destructive_requires_name: true.
- Töötage varundamise ja taastamise mehhanism eelnevalt välja. Näiteks looge eelnevalt skript (näiteks pythonis), mis suudab varundada ja taastada.
Esimene koht — „Kapten mitte-ilmsus“
Teatud hetkel märkisime, et koormuse jaotumine nginx'i ülemistele serveritele on ebaühtlane, kui taustal oli 10+ serverit. Kuna round-robin suunas päringud alates esimesest kuni viimase ülemise serverini järjestikku ja iga nginx'i taaskäivitamine algas otsast, jõudis esimestesse ülemistesse serveritesse alati rohkem päringuid kui teistesse. Tulemuseks töötasid need aeglasemalt ja kogu sait kannatas. See muutus järjest märgatavamaks liikluse suurenemisega. Lihtsalt nginx'i uuendamine random'i aktiveerimiseks ei aidanud — pidime ümber kirjutama hulga lua koodi, mis ei töötanud versioonis 1.15 (sel ajal). Lõpuks pidime meie nginx 1.14.2 patšeerima, lisades toe random'ile. See lahendas probleemi. See bugi võidab auhinna „kapten ebaüheduse eest“.
Järeldused:
See oli väga huvitav ja põnev uurida seda bussi).
- Seadke jälgimine üles nii, et see aitaks kiiresti leida sarnaseid fluktuatsioone. Näiteks võite kasutada ELK-d, et jälgida rps-i iga taustal oleva ülemise serveri jaoks, jälgides nende vastamisaja muutusi nginx'i vaatenurgast. Sel juhul aitas see meil probleemi tuvastada.
Paljude vigade vältimine nõuab hoolikamat lähenemist oma tööle. Alati tuleb meeles pidada Murphy seadust: Mis iganes võib valesti minna, lähebki valesti, ning komponendid tuleb üles ehitada selle seaduse kohaselt.
Allikas: habr.com
