

Lühike sissejuhatus
Usun, et me võiksime teha rohkem, kui meil oleks samm-sammult juhiseid, mis ütleks, mida ja kuidas teha. Mäletan oma elust hetki, kui ei saanud alustada mingit asja, kuna oli lihtsalt raske aru saada, kust alustada. Võib-olla varasemad sõnad "Data Science" tõid sind mõtlema, et see on midagi, mis on sinust kaugel, ja inimesed, kes sellega tegelevad, on kusagil mujal maailmas. Kuid nad on just siin. Ja võib-olla just tänu nendele inimestele jõudis sinu uudistevoogu artikkel. On palju kursuseid, mis aitavad sul seda ametit omandada, ja siin aitan sul teha oma esimese sammu.
Kas oled valmis? Ütlen kohe, et sul tuleb teada Python 3, kuna seda kasutan siin. Soovitan samuti eelnevalt installida Jupyter Notebooki või vaadata, kuidas kasutada Google Colabit.
Esimene samm

Kaggle — sinu oluline abiline selles vallas. Teoreetiliselt saab ka ilma hakkama, kuid sellest räägin ma teises artiklis. See on platvorm, kus toimuvad Data Science'i konkurssid. Igas sellises võistluses saad varakult tohutult kogemusi erinevate ülesannete lahendamisel, arendamisel ja meeskonnatöös, mis on tänapäeval väga oluline.
Meie ülesanne pärineb sealt. Selle nimi on: "Titanic". Ülesanne seisneb selles, et prognoosida, kas iga eraldi inimene jääb ellu. Üldjoontes seisneb andmeteadlase ülesanne andmete kogumises, töötlemises, mudeli õpetamises, prognoosimises jne. Kaggle'is saame aga andmete kogumise etapi vahele jätta — need on platvormil juba olemas. Me peame need lihtsalt alla laadima ja saame tööga alustada!
Seda saab teha järgmise viisi kaudu:
Data vahekaardil on failid, milles on andmed.


Andmed on alla laaditud, meie Jupyter'i spikerdokumentide ette valmistanud ja…
Teine samm
Kuidas me nüüd need andmed alla laadime?
Esiteks impordime vajalikud teegid:
import pandas as pd
import numpy as np
Pandas võimaldab meil laadida .csv faile edasiseks töötlemiseks.
Numpy on vajalik, et esitada meie andmetabel maatriksina numbritega.
Liigume edasi. Vaatame faili train.csv ja laadime selle üles:
dataset = pd.read_csv('train.csv')
Viitame meie andmekogumile train.csv muutujaga dataset. Vaadakem, mis seal on:
dataset.head()

Funktsioon head() võimaldab meil vaadata andmeraami esimesi ridu.
Veerg Survived sisaldab meie tulemusi, mis on selles andmeraamis teada. Antud ülesande puhul peame ennustama veeru Survived väärtused andmetele test.csv. Nendes andmetes on teave teiste Titanic'i reisijate kohta, kelle puhul me ei tea tulemusi.
Nii jagame meie tabeli sõltuvateks ja sõltumatuteks andmeteks. Siin on kõik lihtne. Sõltuvad andmed on need, mis sõltuvad sõltumatutest, see, mis on tulemustes. Sõltumatud andmed on need, mis mõjutavad tulemust.
Näiteks, meil on selline andmekogum:
„Vova õppis informaatikat — ei.
Vova sai informaatikast 2.”
Hinne informaatikast sõltub vastusest küsimusele: õppis Vova informaatikat? Selge? Liigume edasi, oleme juba lähemal eesmärgile!
Tavapärane muutujate seade sõltumatute andmete jaoks on X. Sõltuvate jaoks - y.
Teeme järgmist:
X = dataset.iloc[ : , 2 : ]
y = dataset.iloc[ : , 1 : 2 ]
Mis see on? Funktsioon iloc[:, 2: ] ütleb Pythoni: tahan näha muutuja X sees andmeid, mis algavad teisest veerust (kaasa arvatud, eeldusel, et arvemine algab nullist). Teises reas ütleb, et soovime näha y-s esimese veeru andmeid.
[ a:b, c:d ] on konstruktsioon, mida me kasutame sulgudes. Kui mõnda muutujat ei näidata, jäävad need vaikimisi. See tähendab, et saame näidata [:,: d] ja siis saame andmeraamisse kõik veerud, välja arvatud need, mis algavad numbrist d ja edasi. Muutujad a ja b määravad read, kuid meil on neid kõiki vaja, seega jätame selle vaikimisi.
Vaadakem, mis meil on:
X.head() 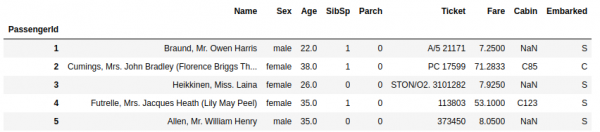
y.head() 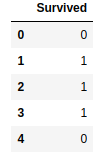
Selle väikese juhendi lihtsustamiseks eemaldame veerud, mis vajavad erilist 'hoolt', või ei mõjuta üldse ellujäämist. Neis sisaldub andmeid tüüpi str.
count = ['Name', 'Ticket', 'Cabin', 'Embarked']
X.drop(count, inplace=True, axis=1)
Super! Liigume järgmise sammu juurde.
Kolmas samm
Siin peame kodeerima meie andmed, et masin saaks paremini aru, kuidas need andmed tulemust mõjutavad. Kuid kodeerime ainult str tüüpi andmeid, mida me jätsime. Veerg "Sex". Kuidas me soovime kodeerida? Kujutame inimese soo andmed vektorina: 10 — mees, 01 — naine.
Alustuseks teisendame meie tabelid NumPy maatriksiks:
X = np.array(X)
y = np.array(y)
Ja nüüd vaatame:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X = np.array(ct.fit_transform(X))
Biblioteek sklearn on tõeliselt äge raamatukogu, mis võimaldab meil teostada täielikku tööd andmete teaduses. See sisaldab hulgaliselt huvitavaid masinõppe mudeleid ning võimaldab meil andmete ettevalmistamisega tegeleda.
OneHotEncoder võimaldab meil kodeerida inimese sugu just nii, nagu me seda kirjeldasime. Loodud saab kaks klassi: mees ja naine. Kui isik on mees, kirjutatakse veergu "mees" 1 ja "naine" veergu vastavalt 0.
OneHotEncoder() järel on [1] — see tähendab, et soovime kodeerida veergu number 1 (arvestamine algab nullist).
Super. Liigume veel edasi!
Tavaliselt juhtub, et mõned andmed jäävad täitmata (st NaN — number ei ole). Näiteks on meil informatsioon inimese kohta: tema nimi, sugu. Kuid andmeid tema vanuse kohta ei ole. Sellisel juhul rakendame meetodit: leiame keskmise aritmeetika kõigis veergudes ja kui mõned andmed on veerus puudu, täidame tühimikud keskmise aritmeetika abil.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X)
X = imputer.transform(X)
Ja nüüd arvestame olukordadega, kus andmed on väga tugevalt hajutatud. Mõned andmed asuvad vahemikus [0:1], mõned võivad ulatuda sadu ja isegi tuhandeid. Et välistada selline hajusus ja arvutid oleksid täpsemad arvutustes, skaleerime andmed, mõõdame skaalat. Olgu kõik numbrid mitte suuremad kui kolm. Selleks kasutame funktsiooni StandardScaler.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X[:, 2:] = sc.fit_transform(X[:, 2:])
Nüüd näevad meie andmed välja sellised:

Suurepärane. Oleme juba lähedal oma eesmärgile!
Neljas samm
Koolitame oma esimest mudelit! Sklearni raamatukogust leiame tohutult huvitavaid võimalusi. Kasutasin antud ülesande jaoks Gradient Boosting Classifier mudelit. Klassifikaatorit kasutatakse, kuna meie ülesanne on klassifitseerimise ülesanne. Peame prognoosi määrama 1 (ellujäänud) või 0 (ei ellu jäänud).
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier(learning_rate=0.5, max_depth=5, n_estimators=150)
gbc.fit(X, y)
Funktsioon fit ütleb Pythoni: las mudel otsib seoseid X ja y vahel.
Mõne sekundiga on mudel valmis.

Kuidas seda rakendada? Näeme varsti!
Viies etapp. Kokkuvõte
Nüüd peame laadima tabeli meie testandmetega, mille jaoks tuleb koostada prognoos. Selle tabeliga teeme täpselt samu toiminguid, mida tegime X-ga.
X_test = pd.read_csv('test.csv', index_col=0)
loend = ['Name', 'Ticket', 'Cabin', 'Embarked']
X_test.drop(loend, inplace=True, axis=1)
X_test = np.array(X_test)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1])],
remainder='passthrough')
X_test = np.array(ct.fit_transform(X_test))
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X_test)
X_test = imputer.transform(X_test)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_test[:, 2:] = sc.fit_transform(X_test[:, 2:])
Rakendame juba meie mudelit!
gbc_predict = gbc.predict(X_test)
Kõik. Oleme koostanud prognoosi. Nüüd tuleb see salvestada csv formaati ja saata veebilehele.
np.savetxt('my_gbc_predict.csv', gbc_predict, delimiter=",", header = 'Ellujäänud')
Valmis. Saime faili, mis sisaldab iga reisija prognoose. Nüüd on jäänud need lahendused veebilehele üles laadida ja saada prognoosi hindamine. See primitiivne lahendus annab mitte ainult 74% õigeid vastuseid avalikus, vaid ka teatud edasiviivate tõuke Data Science'is. Kõige uudishimulikumad võivad igal ajal mulle kirjutada otse ja esitada küsimusi. Aitäh kõigile!
Allikas: habr.com
