

Tere, Habr!
Seoses praeguste sündmustega koroonaviiruse tõttu on mitmed internetiteenused hakanud saama suuremat koormust. Näiteks, , kuna ressursid said otsa. Ja kaugel sellest, et serverit saaks lihtsalt kiiremaks muuta, lisades võimsamat varustust, peab klientide päringud siiski töötlema (või nad lähevad konkurentide juurde).
Selles artiklis räägin lühidalt populaarsetest praktikatest, mis võimaldavad luua kiire ja tõrkeennetuse teenuse. Kuid valitud arendusmoodulite seas on ainult need, millega praegu on lihtne ära kasutada. Iga punkti jaoks on teil kas juba olemasolevad teegid või võimalus probleem lahendada pilveteenuse abil.
Horiontaalne skaleerimine
Kõige lihtsam ja kõigile tuntud punkt. Üldiselt on kõige sagedamini kaks koormuse jaotamise skeemi — horisontaalne ja vertikaalne skaleerimine. lubate teenustel töötada paralleelselt, jaotades seeläbi koormuse nende vahel. te tellite võimsamaid servereid või optimeerite koodi.
Näiteks võtan abstraktse pilveteenuse failide salvestamiseks, sarnase OwnCloudile, OneDrive'ile ja muudele.
Allpool on standardne diagramm sarnase süsteemi kohta, kuid see demonstreerib vaid süsteemi keerukust. Peame leidma viisi teenuste sünkroonimiseks. Mis juhtub, kui kasutaja salvestab faili tahvelarvutisse ja soovib seda hiljem vaadata telefonist?
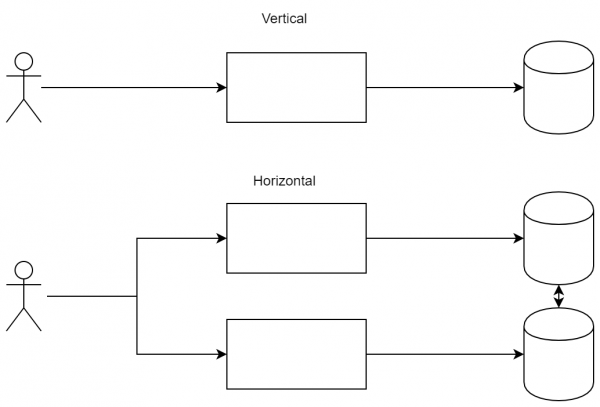
Erinevus lähenemistes: vertikaalsel skaleerimisel oleme valmis suurendama sõlmede võimsust, samas kui horisontaalsel lisame uusi sõlmi, et koormust jaotada.
CQRS
on üsna oluline muster, kuna see võimaldab erinevatel klientidel mitte ainult ühenduda erinevate teenustega, vaid ka saada samu sündmuste vooge. Selle eelised ei ole lihtsa rakenduse puhul nii ilmsed, kuid see on äärmiselt oluline (ja lihtne) koormatud teenuse jaoks. Selle tuum: sisenevad ja väljuvad andmevood ei tohiks üksteist ristuda. See tähendab, et te ei saa saata päringut ja oodata vastust, vaid saadate päringu teenusesse A, kuid saate vastuse teenuses B.
Selle lähenemise esimene eelis on võimalus katkestada ühendus (selle sõna laiemas tähenduses) pika küsimise protsessi käigus. Toome näiteks enam-vähem tavalise järjestuse:
- Klient saatis palveli serverile.
- Server alustas pika töötlemisega.
- Server vastas kliendile tulemusega.
Kujutage ette, et punktis 2 toimus ühenduse katkestamine (kas võrgu uuendamine või kasutaja liikus teisele lehele, katkestades ühenduse). Sel juhul on serveril keeruline saata vastust kasutajale, milline teave on käideldud. CQRS-i rakendades on järjestus pisut erinev:
- Klient tellis värskendusi.
- Klient saatis palveli serverile.
- Server vastas 'päring vastu võetud'.
- Server vastas tulemusega kanali kaudu punktist '1'.
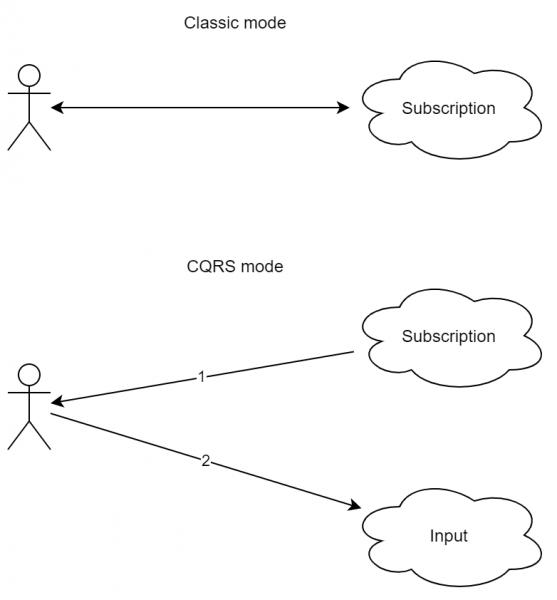
Nagu näha, on skeem pisut keerukam. Veelgi enam, intuitiivne request-response lähenemine ei ole siin kohal. Küll aga on selge, et ühenduse katkestamine päringu töötlemise käigus ei too kaasa viga. Veelgi enam, kui kasutaja on tegelikult ühendatud teenusega mitme seadme kaudu (näiteks mobiiltelefoni ja tahvelarvuti kaudu), saab korraldada nii, et vastus jõuaks mõlemasse seadmesse.
Huvitav on see, et sissetulevate sõnumite töötlemise kood on ühesugune (mitte 100%) nii klientide poolt mõjutatud sündmuste kui ka teiste sündmuste jaoks, sealhulgas teiste klientide sündmuste jaoks.
Kuid tegelikkuses saame me lisaboonuseid seetõttu, et ühesuunalist voogu saab töödelda funktsionaalses stiilis (kasutades RX ja analooge). Ja see on juba tõsine pluss, kuna põhimõtteliselt saab rakenduse teha täiesti reaktiivseks, rakendades samas funktsionaalset lähenemist. Suurtele programmidele võib see märkimisväärselt säästa ressursse arendamisel ja hooldamisel.
Kui kombineerida see lähenemine horisontaalse skaleerimisega, siis saadame me soovi korral päringud ühele serverile ja saame vastused teisest. Seega saab klient ise valida endale sobiva teenuse, samas kui süsteem suudab sisemiselt sündmusi õigesti töödelda.
Event Sourcing
Nagu teate, on jaotatud süsteemi üheks peamiseks omaduseks üldise aja ja ühise kriitilise sektsiooni puudumine. Ühe protsessi raames võite synchroniseerida (kõigi samade mutex'ite abil), mille jooksul olete kindel, et keegi teine ei täida seda koodi. Kuid jaotatud süsteemi puhul on see ohtlik, kuna see toob kaasa kulutusi ning tapab kogu skaleeritavuse võlu — kõik komponendid peavad ikkagi ootama üksteist.
Seetõttu saame olulise tõe — kiiret jaotatud süsteemi ei saa synchroniseerida, kuna muidu vähendame jõudlust. Teiselt poolt vajame sageli teatud komponentide järjepidevust. Selleks saab kasutada lähenemist , kus garanteeritakse, et andmete muutuste puudumisel teatud ajavahemiku jooksul pärast viimast uuendust („lõpuks”) tagastavad kõik päringud viimane uuendatud väärtus.
Oluline on mõista, et traditsiooniliste andmebaaside puhul rakendatakse sageli , kus iga sõlm omab samu andmeid (sarnast saavutatakse sageli siis, kui tehingut peetakse kehtivaks alles pärast teise serveri vastust). Siiski on siin mõned leevendused isoleerimise tasetest, kuid põhikirjeldus jääb samaks — te saate elada täiesti kooskõlastatud maailmas.
Kuid naaseme algse ülesande juurde. Kui osa süsteemist saab ehitada , siis saab luua järgmise skeemi.
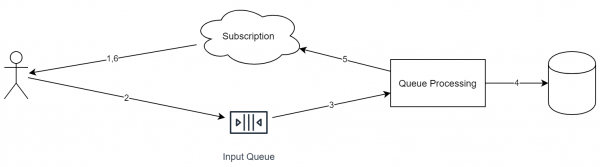
Selle lähenemise olulised omadused:
- Iga tulev asi paneb ühte järjekorda.
- Küsimuse töötlemise käigus võib teenus samuti paigutada ülesandeid teistesse järjekordadesse.
- Igal siseneval sündmusel on identifikaator (mis on vajalik dedupikatsiooniks).
- Järjekord töötab ideoloogiliselt skeemi "append only" alusel. Sealt ei saa elemente kustutada ega ümber paigutada.
- Järjekord töötab FIFO skeemi alusel (vabandust tautoloogia pärast). Kui on vajalik paralleelne täitmine, siis tuleks ühel etappidel objektid erinevatesse järjekordadesse ümber paigutada.
Kordan, et vaatleme olukorda veebipõhise failihoiustamise süsteemi. Sel juhul näeb süsteem umbes selline välja:
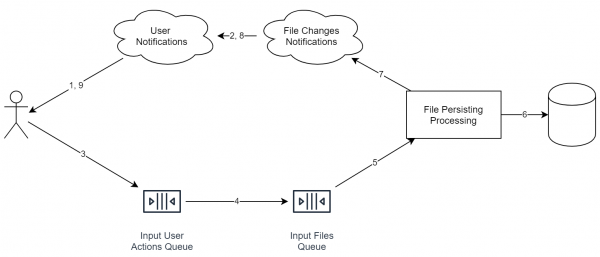
Oluline on, et diagrammil olevad teenused ei tähenda tingimata eraldi serverit. Isegi protsess võib olla sama. Oluline on midagi muud: ideoloogiliselt on need asjad jagatud nii, et horisontaalne skaleerimine oleks hõlpsasti rakendatav.
Kahte kasutajat teenuseseade näeb välja selline (teenused, mis on mõeldud erinevatele kasutajatele, on eristatud erinevate värvidega):
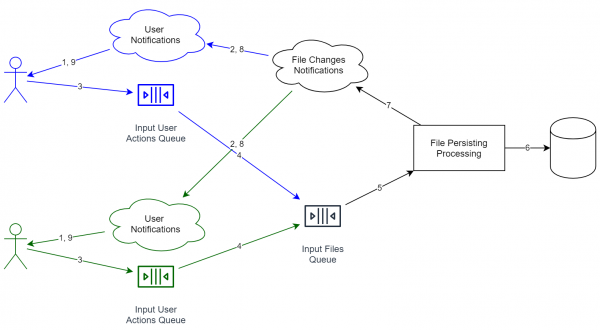
Sellise kombinatsiooni eelised:
- Teabe töötlemise teenused on jagatud. Ootejärjekorrad on samuti eraldi. Kui peame suurendama süsteemi läbilaskevõimet, piisab, kui käivitame rohkem teenuseid suuremal arvul serverites.
- Kui saame teavet kasutajalt, ei pea me tingimata ootama, kuni andmed täielikult salvestatakse. Vastupidi, piisab, kui vastame "ok", ja alustada tööd järk-järgult. Ootejärjekord tasandab ka tippe, kuna uue objekti lisamine toimub kiiresti ja kasutaja ei pea ootama, kuni kogu tsükkel on läbitud.
- Näiteks olen lisanud deduplication teenuse, mis proovib kokku liita sarnased failid. Kui see töötab pikka aega 1% juhtudel, siis klient ei märka seda peaaegu üldse (vt ülal), mis on suur pluss, kuna meilt ei nõuta enam sada protsenti kiirus ja usaldusväärsus.
Kuid kohe on näha ka miinuseid:
- Meie süsteemil on kadunud range järjepidevus. See tähendab, et kui näiteks tellida erinevaid teenuseid, siis teoreetiliselt võib saada erineva oleku (kuna üks teenustest ei pruugi saada teate varasest järjekorrast). Veel ühe tagajärjena pole süsteemil nüüd ühist aega. See tähendab, et ei saa, näiteks, kõiki sündmusi lihtsalt saabumise aja järgi sorteerida, kuna kellad serverite vahel ei pruugi olla sünkroonitud (veelgi enam, kahe serveri samaaegne aeg on utoopia).
- Ükski sündmus ei saa nüüd lihtsalt tagasi võtta (nagu võiks andmebaasi puhul teha). Selle asemel tuleb lisada uus sündmus — , mis muudab viimase oleku soovitud seisundiks. Näiteks sarnases valdkonnas: ilma ajaloos muutmist (mis on mõnes mõttes halb) ei saa gitis commit'i tagasi pöörata, kuid saab teha erilise , mis põhimõtteliselt lihtsalt taastab vana oleku. Kuid ajaloos jäävad nii vale commit kui ka rollback alles.
- Andmeskeem võib muutuda versioonist versiooni, kuid vanu sündmusi ei saa nüüd uutele standarditele uuendada (sest sündmusi ei saa põhimõtteliselt muuta).
Nagu näha, sobib Event Sourcing suurepäraselt kokku CQRS-iga. Veelgi enam, süsteemi rakendamine tõhusate ja mugavate järjekordadega, kuid ilma andmevoogude jagamiseta, on juba iseenesest keeruline, sest tuleb lisada sünkroniseerimispunkte, mis neutraliseerivad kõik järjekordade positiivsed eelised. Mõlema lähenemise samaaegsel rakendamisel tuleb programmi töö koodi kergelt kohandada. Meie puhul, kui fail serverisse saadetakse, tuleb vastuseks vaid „okei”, mis tähendab ainult seda, et „faili lisamise operatsioon on salvestatud”. Formaalset öeldes ei tähenda see, et andmed on juba teistele seadmetele kergesti kättesaadavad (näiteks ei pruugi deduplitseerimisteenus indeksit koheselt uuendada). Kuid mõne aja pärast saab klient teate stiilis „fail X on salvestatud”.
Tulemuseks:
- Failide saatmise staatuste arv suureneb: klassikalise „fail saadetud” asemel saame kaks: „fail lisatud serveri järjekorda” ja „fail salvestatud salvestusse”. Viimane tähendab, et teised seadmed saavad faili juba hakata vastu võtma (arvestades, et järjekorrad töötavad erineva kiirusel).
- Kuna saadetiste teave tuleb nüüd erinevate kanalite kaudu, peame leiutama lahendusi, et saada faili töötlemise staatust. Selle tulemusena: erinevalt klassikalisest request-response mudelist võib klient failide töötlemise protsessis taaskäivituda, kuid selle töötlemise staatuse täpsus jääb säilima. Ja see punkt töötab, põhimõtteliselt, kohe välja pakutud lahendusena. Seetõttu oleme nüüd tõrketele tolerantsemad.
Sharding
Nagu eelnevalt kirjeldatud, puudub event sourcing süsteemides range kooskõla. See tähendab, et võime kasutada mitmeid andmehoidlaid ilma nende vahelise sünkroniseerimiseta. Lähenedes meie ülesandele, saame:
- Jagada faile tüüpide järgi. Näiteks saab pilte/videot dekodeerida ja valida efektiivseima formaadi.
- Jagada kontosid riikide lõikes. Paljude seaduste tõttu võib see osutuda vajalikuks, kuid see arhitektuuri skeem annab sellise võimaluse automaatselt.
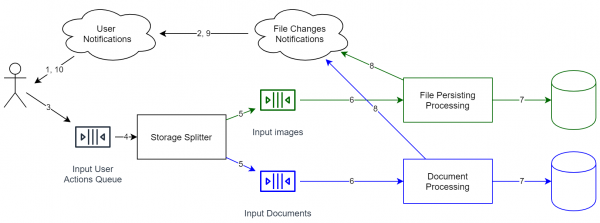
Kui soovite andmeid ühest salvestuspunktist teise viia, siis on standardsete vahenditega seda raske teha. Kahjuks tuleb sellisel juhul järjekord peatada, migratsioon teostada ja seejärel uuesti käivitada. Üldiselt pole andmete edastamine „reaalajas” võimalik, kuid kui sündmuste järjekord on täielikult säilitatud ja teil on varasemate salvestuspunktide kopeerimised, saame sündmusi järgmiselt uuesti mängida:
- Event Source'is on igal sündmusel oma identifikaator (ideaalis mitte vähenemas). Seega saame salvestusse lisada välja — viimane töödeldud elemendi id.
- Kopeerime järjekorra, et kõik sündmused saaksid töötlemiseks minna mitmesse sõltumatusse salvestusse (esimene on see, kus andmed juba on, ja teine on uus, kuid hetkel tühi). Loomulikult ei töötle me teist järjekorda veel.
- Käivitame teise järjekorra (ehk alustame sündmuste uuesti mängimist).
- Kui uus järjekord on suhteliselt tühi (st elementide lisamise ja nende äravõtmise vaheline keskmine ajavahemik on vastuvõetav), on võimalik hakata lugemisprotsesse suunama uuele salvestusele.
Kuidas näha, ei ole meie süsteemis kunagi olnud ja ei ole ka ranget ühtsust. On ainult eventual consistency, mis tähendab, et sündmusi töödeldakse samas järjekorras (kuid võimaliku erineva viivitusega). Kasutades seda, saame suhteliselt lihtsalt andmeid üle kanda ilma süsteemi seiskamiseta teise maailma otsa.
Seega, jätkates meie näidet veebifailide salvestamisest, annab selline arhitektuur meile juba mitu eelist:
- Saame liigutada objekte lähemale kasutajatele, ja seda dünaamiliselt. Seeläbi on võimalik teenuse kvaliteeti parandada.
- Saame hoida osa andmeid ettevõtete sees. Näiteks nõuavad ettevõtte kasutajad sageli, et nende andmed salvestataks kontrollitavates andmekeskustes (andmete lekete vältimiseks). Sharding abil saame seda hõlpsasti toetada. Ja ülesanne muutub veelgi lihtsamaks, kui kliendil on ühilduv pilv (näiteks, ).
- Oluline on märkida, et me ei pea seda kindlasti tegema. Alguses piisab meile ühest salvest, et alustada kõigi kontode haldamist (et saaksime võimalikult kiiresti tööle hakata). Selle süsteemi peamine omadus on lihtsus, kuigi see on laiendatav. Ei ole vaja kohe kirjutada koodi, mis töötab miljoni eraldi iseseisva järjekorraga jne. Kui tulevikus on vajadus, saab seda alati teha.
Statiline sisu hostimine
See punkt võib tunduda iseenesestmõistetav, kuid see on vajalik enam-vähem standardse koormatud rakenduse jaoks. Idee on lihtne: kogu statiline sisu edastatakse mitte samalt serverilt, kus rakendus asub, vaid spetsiaalsetelt serveritelt, mis on selleks otstarbeks ette nähtud. Seega toimuvad need operatsioonid kiiremini (näiteks nginx edastab faile kiiremini ja odavamalt kui Java-server). Lisaks võimaldab CDN-arkitektuur () paigutada meie failid lähemale lõppkasutajatele, mis paraneb teenuse kasutusmugavus.
Lihtsam ja standardne näide staatilisest sisust on komplekt skripte ja pilte veebisaidi jaoks. Nendega on kõik lihtne — need on ette teada, seejärel arhiiv laaditakse CDN-serveritesse, kust see edastatakse lõpptarbijatele.
Kuid tegelikkuses saab staatilise sisu puhul kasutada lähenemist, mis sarnaneb lambdanike arhitektuurile. Tagasi meie ülesande juurde (failide veebihoiustamine), kus peame failid kasutajatele jagama. Lihtsaim lahendus on luua teenus, mis igas kasutaja päringus teeb kõik vajalikud kontrollid (autentimine jne), ja seejärel laadib faili otse meie hoidlast. Sellise lähenemise peamine miinus on see, et staatiline sisu (ja fail teatud revisjoniga on sisuliselt staatiline sisu) jagatakse samalt serverilt, mis sisaldab äriloogikat. Selle asemel võiks kasutada järgmist skeemi:
- Server väljastab allalaadimise URL-i. See võib olla kujul file_id + key, kus key on mini-digitaalallkiri, mis annab õiguse ressursile ligipääsuks järgmise päeva jooksul.
- Failide jagamist teostab lihtne nginx järgmiste valikute abil:
- Sisu vahemälu. Kuna see teenus võib asuda eraldi serveris, oleme ette valmistanud võimaluse salvestada kõik hiljuti allalaaditud failid kettale.
- Võtit kontrollitakse ühenduse loomise hetkel.
- Valikuline: sisu voogesitus. Näiteks, kui me tihendame kõik failid teenuses, on võimalik dekompressioon otse selles moodulis. Seetõttu tehakse IO operatsioonid seal, kus need kõige paremini sobivad. Java arhiivija võib hõlpsasti eraldada palju liigset mälu, kuid teenuse ümberkirjutamine äriloogika jaoks tingimuslike Rust/C++ abil võib samuti osutuda ebaefektiivseks. Meie puhul kasutame erinevaid protsesse (või isegi teenuseid), seega on äärmiselt efektiivne eraldada äriloogika ja IO operatsioonid.
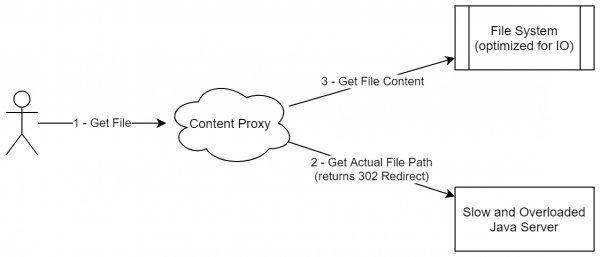
Sarnane skeem ei ole väga sarnane staatilise sisu jagamisele (kuna me ei laadita kogu staatilist paketti kuskile), kuid tõepoolest tegeleb selline lähenemine muutumatute andmete jagamisega. Veelgi enam, seda skeemi saab üldistada ka teiste juhtumite peale, kus sisu ei ole lihtsalt staatiline, vaid võib olla esitatud muutumatute ja kustutamata plokkide komplektina (kuigi neid võib lisada).
Veel aitab paar sõna (näiteks): kui olete töötanud Jenkins'i või TeamCity'ga, siis teate, et mõlemad lahendused on kirjutatud Java's. Need on Java-protsessid, mis tegelevad nii ehituste orkestreerimise kui ka sisu haldusega. Eriti on neil mõlemal ülesanded, nagu "edastada fail / kaust serverist". Näiteks artefaktide väljastamine, lähtekoodi edastamine (kui agent ei laadi koodi otse allikast, vaid teeb seda server), juurdepääs logidele. Kõik need ülesanded erinevad IO-koormusest. Seega peab server, mis vastutab keerulise äri logika eest, suutma tõhusalt läbi lasta suuri andmepuhanguid. Ja mis kõige huvitavam, sellist operatsiooni saab delegeerida ka nginx’ile täpselt sama skeemi järgi (ainus erinevus on see, et päringusse tuleb lisada andmekiip).
Kuid kui pöörata tagasi meie süsteemi, siis näeme järgmist skeemi:
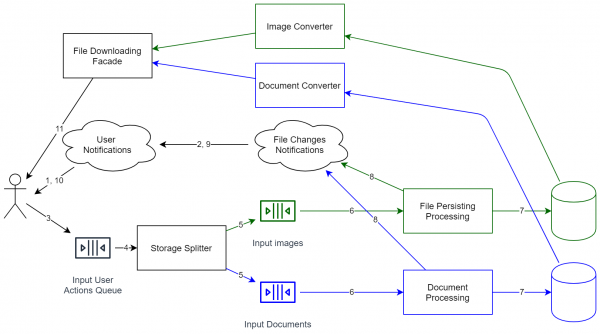
Nagu näha, on süsteem radikaalselt keerukamaks muutunud. See on nüüd mitte lihtsalt miniprotsess, mis salvestab faile kohapeal. Nüüd on vajalikud mitte kõige lihtsamad toetused, API versiooni kontrollimine jne. Seetõttu, kui kõik diagrammid on valmis, on kõige parem üksikasjalikult hinnata, kas selliste kulude suurenemine on õigustatud. Kui aga soovite, et süsteemi oleks võimalik laiendada (sealhulgas veelgi suurema arvu kasutajate toetamiseks), tuleks selliste lahendustega arvestada. Selle tulemusena on süsteem arhitektuuriliselt valmis täiendava koormuse jaoks (peaaegu iga komponent on kopeeritav horisontaalseks skaleerimiseks). Süsteemi saab uuendada ilma selle peatamiseta (lihtsalt mõned operatsioonid võivad väheke aeglustuda).
Nagu ma juba alguses ütlesin, on mitmed internetiteenused praegu suurenenud koormuse all. Ja mõned neist on lõpetanud korraliku töö. Sisuliselt on süsteemid ebaõnnestunud just siis, kui äri peaks raha teenima. See tähendab, et selle asemel, et edasi lükata tarnimist või pakkuda klientidele «planeerige tarne järgnevate kuude jooksul», ütles süsteem lihtsalt «mine konkurentide juurde». Just see on madala jõudluse hind: kaotused toimuvad siis, kui kasum oleks kõrgeim.
Kokkuvõte
Need lähenemised on olnud tuntud ka varem. Näiteks kasutab VK juba ammu Static Content Hosting ideed piltide edastamiseks. Paljud online-mängud kasutavad mängijate jagamiseks piirkondade vahel Sharding-skeemi või mängulokatsioonide eraldamiseks (kui maailm on ühtne). Event Sourcing lähenemist kasutatakse aktiivselt e-posti puhul. Enamik kaubandusrakendusi, kuhu voolavad pidevalt andmed, on tegelikult üles ehitatud CQRS lähenemisele, et filtreerida saadud andmeid. Ja horisontaalset skaleerimist on juba pikka aega rakendatud mitmes teenuses.
Kuid mis kõige tähtsam, on need mustrid nüüdseks väga kergesti rakendatavad kaasaegsetes rakendustes (kui need on kohased, muidugi). Pilved pakuvad sharding'u ja horisontaalset skaleerimist kohe, mis on palju lihtsam kui tellida erinevaid pühendatud servereid erinevates andmekeskustes iseseisvalt. CQRS on samuti muutunud palju lihtsamaks tänu raamatukogude arengule, nagu RX. Kümme aastat tagasi suutis harva ükski veebisait sellist toetada. Ürituste allikas on samuti uskumatult lihtsalt seadistatav juba valmis konteinerite tõttu Apache Kafka'ga. Kümme aastat tagasi oleks see olnud innovatsioon, nüüd on see argipäev. Samuti on staatilise sisu majutamine muutunud: tänu mugavamatest tehnoloogiatest (sealhulgas põhjaliku dokumentatsiooni ja suure vastuste andmebaasi olemasolu tõttu) on selline lähenemine muutunud veelgi lihtsamaks.
Kokkuvõtteks, rida keeruliste arhitektuurimustrite rakendamine on nüüd palju lihtsam, seega tasub sellele eelnevalt tähelepanu pöörata. Kui kümneaastasest rakendusest loobuti mõnest eelnevalt nimetatud lahendusest kõrgete rakendamise ja töökindluse kulude tõttu, siis nüüd, uues rakenduses või pärast refaktooringut, on võimalik luua teenus, mis on arhitektuuri poolest nii laiendatav (tõhususe mõttes) kui ka uutele klientide nõudmistele valmis (näiteks isikuandmete lokaliseerimiseks).
Ja kõige tähtsam: palun ärge kasutage neid lähenemisi, kui teil on lihtne rakendus. Jah, need on ilusad ja huvitavad, kuid saidi jaoks, mille tippaegne külastatavus on 100 inimest, võib sageli piirduda klassikalise monoliitse lahendusega (vähemalt väliselt, seestpoolt saab kõik jagada mooduliteks jne).
Allikas: habr.com
