

Tere kõigile, jagame teiega väljaande „Virtuaalsed failisüsteemid” teist osa LinuxMiks neid vaja on ja kuidas need toimivad? Esimest osa saab lugeda . Tuletame meelde, et see väljaannete sari on ajastatud nii, et see langeb kokku kursusel uue voo käivitamisega , mis algab väga kiiresti.
Kuidas jälgida VFS-i eBPF-i ja bcc-tööriistade abil
Lihtsaim viis aru saada, kuidas kernel failidega töötab sysfs on seda praktikas näha ja lihtsaim viis ARM64 vaatamiseks on kasutada eBPF-i. eBPF (lühend sõnadest Berkeley Packet Filter) koosneb sisse töötavast virtuaalmasinast , mida privilegeeritud kasutajad saavad taotleda (query) käsurealt. Kerneli allikad ütlevad lugejale, mida tuum suudab; eBPF-i tööriistade käivitamine laaditud süsteemis näitab, mida kernel tegelikult teeb.

Õnneks on eBPF-i kasutamise alustamine tööriistade abil üsna lihtne , mis on saadaval pakettidena üldisest distributsioonist ja üksikasjalikult dokumenteeritud . Tööriistad bcc on Pythoni skriptid väikeste C-koodi sisestustega, mis tähendab, et igaüks, kes tunneb mõlemat keelt, saab neid hõlpsasti muuta. IN bcc/tools Pythoni skripte on 80, mis tähendab, et suure tõenäosusega suudab arendaja või süsteemiadministraator valida probleemi lahendamiseks midagi sobivat.
Proovige, et saada vähemalt pealiskaudne ettekujutus sellest, mida VFS-id töötavad süsteemis teevad vfscount või vfsstat. See näitab, oletame, et kümneid kõnesid vfs_open() ja "tema sõpru" juhtub sõna otseses mõttes iga sekund.
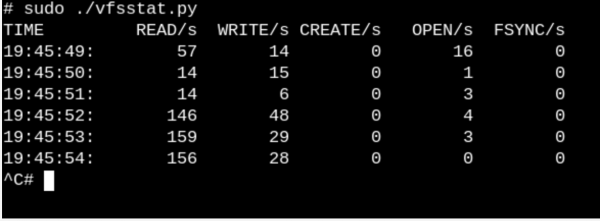
vfsstat.pyon Pythoni skript C-koodi lisadega, mis lihtsalt loeb VFS-i funktsioonikutsed.
Toome triviaalsema näite ja vaatame, mis juhtub, kui sisestame USB-mälupulga arvutisse ja süsteem selle tuvastab.
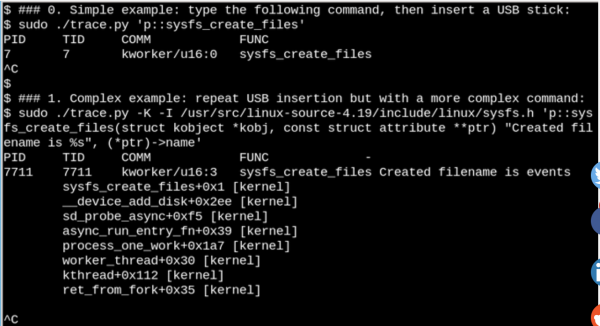
eBPF-i kasutades näete, mis toimub
/syskui USB-mälupulk on sisestatud. Siin on lihtne ja keeruline näide.
Ülaltoodud näites bcc tööriist prindib käsu käivitamisel teate sysfs_create_files(). Me näeme seda sysfs_create_files() käivitati kasutades kworker voog vastuseks tõsiasjale, et mälupulk sisestati, kuid milline fail loodi? Teine näide näitab eBPF-i võimsust. Siin trace.py Prindib kerneli tagasijälje (-K) ja loodud faili nime sysfs_create_files(). Ühe lause sisestamine on C-kood, mis sisaldab kergesti äratuntavat vormingustringi, mille pakub LLVM-i käivitav Pythoni skript just-in-time kompilaator. See kompileerib selle rea ja käivitab selle tuuma sees olevas virtuaalses masinas. Täisfunktsiooni allkiri sysfs_create_files () tuleb teises käsus reprodutseerida, et vormingustring saaks viidata ühele parameetritest. Vead selles C-kooditükis põhjustavad C-kompilaatoris äratuntavaid vigu. Näiteks kui parameeter -l on välja jäetud, näete teadet "BPF-teksti kompileerimine ebaõnnestus". Arendajad, kes tunnevad C ja Pythonit, leiavad tööriistad bcc lihtne laiendada ja muuta.
Kui USB-draiv on sisestatud, näitab kerneli tagasijälg, et PID 7711 on lõime kworkermis faili lõi «events» в sysfs. Vastavalt sellele helistati sysfs_remove_files() näitab, et draivi eemaldamine tõi kaasa faili kustutamise events, mis vastab viiteloenduse üldkontseptsioonile. Samal ajal vaatamine sysfs_create_link () eBPF-iga USB-draivi sisestamise ajal näitab, et on loodud vähemalt 48 sümboolset linki.
Mis on sündmuste faili mõte? Kasutamine Otsimiseks , näitab, mida see põhjustab disk_add_events ()ja kas "media_change"Või "eject_request" saab salvestada sündmuse faili. Siin teavitab kerneli ploki kiht kasutajaruumi, et "ketas" on ilmunud ja väljutatud. Pange tähele, kui informatiivne on see uurimismeetod USB-draivi sisestamine, võrreldes sellega, kui proovite aru saada, kuidas asjad toimivad puhtalt allikast.
Kirjutuskaitstud juurfailisüsteemid võimaldavad manustatud seadmeid
Loomulikult ei lülita keegi serverit ega oma arvutit pistikupesast tõmmates välja. Aga miks? Selle põhjuseks on asjaolu, et füüsilistele salvestusseadmetele ühendatud failisüsteemidel võib kirjutus olla mahajäänud ja nende olekut salvestavad andmestruktuurid ei pruugi olla salvestusruumi kirjutamisega sünkroonitud. Kui see juhtub, peavad süsteemi omanikud utiliidi käivitamiseks ootama järgmise alglaadimiseni. fsck filesystem-recovery ja halvimal juhul andmete kadu.
Siiski teame me kõik, et paljud asjade interneti seadmed, aga ka ruuterid, termostaadid ja autod töötavad nüüd... LinuxPaljudel neist seadmetest puudub praktiliselt igasugune kasutajaliides ja neid pole võimalik puhtalt välja lülitada. Kujutage ette auto käivitamist tühja akuga, kui juhtseadme toide katkeb. pidevalt üles-alla hüppamine. Kuidas on nii, et süsteem käivitub ilma pika ajata fsckmillal mootor lõpuks tööle hakkab? Ja vastus on lihtne. Manustatud seadmed tuginevad juurfailisüsteemile (lühendatud ro-rootfs (kirjutuskaitstud juurfailisüsteem)).
ro-rootfs pakuvad palju eeliseid, mis on vähem ilmsed kui autentsus. Üks eelis on see, et pahavara ei saa sinna kirjutada /usr või /lib, kui protsessi pole Linux ei saa sinna kirjutada. Teine on see, et suures osas muutmatu failisüsteem on kaugseadmete välitoe jaoks ülioluline, kuna tugipersonal kasutab kohalikke süsteeme, mis on nominaalselt identsed kohapealsete süsteemidega. Võib-olla kõige olulisem (kuid ka kõige salakavalam) eelis on see, et ro-rootfs sunnib arendajaid juba süsteemi kujundamise alguses otsustama, millised süsteemiobjektid on muutmatud. Ro-rootfsiga töötamine võib olla ebamugav ja vaevaline, nagu see on programmeerimiskeeltes sageli konstantsete muutujate puhul, kuid selle eelised kaaluvad kergesti üles lisakulud.
loomine rootfs Kirjutuskaitstud funktsionaalsus nõuab manussüsteemide arendajatelt lisapingutusi ja siin tulebki mängu VFS. Linux nõuab, et failid oleksid /var olid kirjutatavad ja lisaks proovivad paljud manustatud süsteeme käitavad populaarsed rakendused luua konfiguratsiooni dot-files в $HOME. Kodukataloogi konfiguratsioonifailide üks lahendus on tavaliselt nende eelgenereerimine ja sisseehitamine rootfs. Jaoks /var Üks võimalik viis on paigaldada see eraldi kirjutatavale partitsioonile, samas / monteeritud kirjutuskaitstud. Teine populaarne alternatiiv on sidumis- või ülekattekinnituste kasutamine.
Ühendatavad ja virnastatavad alused, nende kasutamine konteinerites
Käsu täitmine man mount on parim viis siduvate ja ülekattetavate kinnituste tundmaõppimiseks, mis annavad arendajatele ja süsteemiadministraatoritele võimaluse luua failisüsteem ühel teel ja seejärel avaldada see teise rakendustele. Manussüsteemide puhul tähendab see võimalust faile salvestada /var kirjutuskaitstud välkmälupulgal, kuid ülekatte või linkitava paigaldustee kaudu tmpfs в /var laadimisel võimaldab see rakendustel sinna märkmeid kirjutada (scrawl). Järgmine kord, kui lülitate muudatused sisse /var läheb kaduma. Ülekattekinnitus loob liidu tmpfs ja selle aluseks olev failisüsteem ning võimaldab teil olemasolevates failides näiliselt muudatusi teha ro-tootf samas kui sidutav kinnitus võib uued tühjaks teha tmpfs kaustad, mis on nähtavad sissekirjutatavatena ro-rootfs viise. Kuigi overlayfs see on õige (proper) failisüsteemi tüüp, millesse on rakendatud siduv ühendamine .
Ülekatte ja ühendatava kinnituse kirjelduse põhjal ei imesta see keegi neid kasutatakse aktiivselt. Vaatame, mis juhtub, kui me seda kasutame konteineri käivitamiseks tööriista abil mountsnoop pärit bcc.
Väljakutse system-nspawn käivitab konteineri töötamise ajal mountsnoop.py.
Vaatame, mis juhtus:
Käivita mountsnoop konteineri käivitamise ajal näitab, et konteineri käitusaeg sõltub suuresti lingitavast ühendusest (kuvatakse ainult pika väljundi algust).
see on systemd-nspawn pakub valitud faile procfs и sysfs hostist konteinerisse kui teed selle juurde rootfs. Välja arvatud MS_BIND lipp, mis seadistab sidumisühenduse, määratlevad mõned muud ühendusmärgid hosti ja konteineri nimeruumide muudatuste vahel. Näiteks võib lingitud kinnitus muudatused vahele jätta /proc и /sys mahutisse või peita need olenevalt kõnest.
Järeldus
Sisemise struktuuri mõistmine Linux võib tunduda võimatu ülesandena, kuna kernel ise sisaldab tohutul hulgal koodi, jättes kõrvale kasutajaruumi rakendused Linux ja süsteemikõnede liidesed C-teekides, näiteks glibc. Üks viis edusammude saavutamiseks on lugeda ühe tuuma alamsüsteemi lähtekoodi, pannes rõhku süsteemikutsete ja kasutajaruumi päiste, aga ka peamiste sisemiste kerneli liideste (nt tabel) mõistmisele. file_operations. Failitoimingud pakuvad "kõik on fail" põhimõtet, muutes nende haldamise eriti nauditavaks. C-kerneli lähtefailid tipptaseme kataloogis fs/ esindavad virtuaalsete failisüsteemide rakendamist, mis on ümbriskiht, mis pakub laiaulatuslikku ja suhteliselt lihtsat ühilduvust populaarsete failisüsteemide ja salvestusseadmete vahel. Ühendatakse linkimise ja kattumisega nimeruumide kaudu. Linux — on VFS-i võlujõud, mis võimaldab luua konteinereid ja kirjutuskaitstud juurfailisüsteeme. Koos lähtekoodi, eBPF-i kerneli tööriista ja selle liidese uurimisega bcc
muutes põhiuuringute lihtsamaks kui kunagi varem.
Sõbrad, andke teada, kas see artikkel oli teile abiks. Võib-olla on teil kommentaare või ettepanekuid? Ja neile, kes on huvitatud "Administraatori" kursusest, Linux", kutsume teid üles , mis toimub 18. aprillil.
Allikas: www.habr.com
