

Приветствую, и сперва немного лирики. Я иногда завидую коллегам, работающим удалённо — ведь это прекрасно иметь возможность работать из любого конца подключённого к Internet мира, каникулы в любое время, ответственность за проекты и дедлайны, а не нахождение в офисе с 8 до 17. Моя позиция и рабочие обязанности практически исключают возможность долгого отсутствия в датацентре. Однако — периодически случаются интересные кейсы, подобные описанному ниже — и я понимаю, что существует мало позиций, где есть такой простор для творческого выражения внутреннего troubleshooter’а.
Небольшой дисклеймер — на момент написания статьи кейс полностью не решен, но учитывая скорость ответа вендоров, полное решение может занять еще месяцы, а поделиться своими находками хочется уже сейчас. Надеюсь, уважаемые читатели, вы простите мне эту поспешность. Но довольно воды — что там с кейсом?
Сначала вводная: есть фирма (где я работаю сетевым инженером), которая хостит клиентские решения в приватном облаке VMWare. Большинство новых решений подключаются к VXLAN-сегментам, которые управляются NSX-V — не буду оценивать сколько времени мне подарило это решение, кратко говоря — много. Удалось даже обучить коллег настройке NSX ESG и небольшие клиентские решения разворачиваются без моего участия. Важное замечание — control plane у нас с unicast-репликацией. Гипервизоры подключены избыточно двумя интерфейсами к разным физическим коммутаторам Juniper QFX5100 (собранным в Virtual Chassis) и политикой тиминга route based on originating virtual port — это для полноты картины.
Клиентские решения очень разнородные: от Windows IIS, где все компоненты web-сервера установлены на одной машине до вполне больших — например load-balanced Apache веб-фронты + LB MariaDB в Galera + сервера-шары, синхронизированные с помощью GlusterFS. Практически каждый сервер надо мониторить отдельно, а публичные адреса есть не у всех компонентов — если вы сталкивались с этой задачей и имеете более изящное решение, буду рад совету.
Моё решение мониторинга состоит в «подключении» фаервола (Fortigate) к каждой внутренней клиентской сети (+SNAT и, конечно, жёсткие ограничения по типу разрешённого трафика) и наблюдение за внутренними адресами — таким образом достигается некая унификация и упрощение мониторинга. Сам мониторинг происходит из кластера серверов PRTG. Схема мониторинга примерно такая:
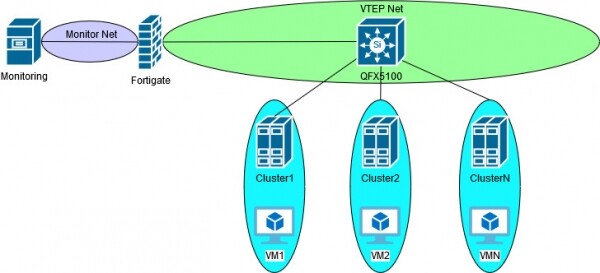
Пока мы оперировали только с VLAN всё было вполне обычно и предсказуемо работало, как часы. После внедрения NSX-V и VXLAN столкнулись с вопросом — а можно ли продолжать мониторинг по-старому? На момент этого вопроса самым «быстрым» решением было развернуть NSX ESG и подключить VXLAN trunk-интерфейс в VTEP сеть. Быстрым в кавычках — так как использовать GUI для настройки клиентских сетей, SNAT и правил фаервола может и унифицирует управление в едином интерфейсе vSphere, но по моему мнению довольно громоздкое и кроме всего прочего ограничивает набор инструментов для траблшутинга. Те, кто использовал NSX ESG как замену «настоящему» фаерволу, думаю, согласятся. Хотя, наверное, такое решение было бы более стабильным — ведь всё происходит в рамках одного вендора.
Еще одно решение — использовать NSX DLR в режиме бриджа между VLAN и VXLAN. Тут я думаю всё понятно — банально теряется выгода от применения VXLAN — ведь в этом случае всё-равно приходится тянуть VLAN к мониторинг-инсталляции. Кстати, в процессе отработки этого решения я столкнулся с проблемой, когда DLR-бридж не отсылал пакеты виртуалке с которой он находился на одном хосте. Знаю, знаю — в книгах и гайдах по NSX-V прямо сказано, что для NSX Edge должен быть выделен отдельный кластер, но это в книгах… Так или иначе, после пары месяцев с саппортом проблему мы не решили. В принципе логику действа я понял — модуль ядра гипервизора, ответственный за инкапсуляцию VXLAN не задействовался, если DLR и наблюдаемый сервер находились на одном хосте, так как трафик не покидает хост и по логике должен быть подключен к VXLAN сегменту — инкапсуляция не нужна. С саппортом мы остановились на виртуальном интерфейсе vdrPort, который логически объединяет аплинки и он же осуществляет бриджевание/инкапсуляцию — вот там было замечено несоответствие во входящем трафике, которое я взял на отработку в текущем кейсе. Но как было сказано, до конца я этот кейс не довёл, так как был переброшен на другой проект да и ветвь изначально тупиковая и желания её развивать особо не было. Если не ошибаюсь, проблема наблюдалась в версиях NSX и 6.1.4 и 6.2.
И тут — бинго! Fortinet аннонсирует нативную . И не просто point-to-point или VXLAN-over-IPSec, не софтварный бриджинг VLAN-VXLAN — всё это начали внедрять еще с версии 5.4 (и представлено у других ), а настоящую поддержку unicast control plane. При внедрении решения я столкнулся с еще одной проблемой — проверяемые сервера периодически то «пропадали» то появлялись в мониторинге, хотя сама виртуалка была жива. Причиной как оказалось было то, что я забыл разрешить Ping на VXLAN-интерфейсе. В процессе ребалансировки кластеров, виртуалки перемещались, а Ping’ом завершался vMotion, чтобы обозначить новый ESXI хост, на который переместилась машина. Глупость моя, но эта проблема еще раз подорвала доверие к саппорту производителся — в этом случае Fortinet. Я уж не говорю, что каждый кейс, связанный с VXLAN начинается с вопроса «а где у вас в настройках софтсвич VLAN-VXLAN?» В этот раз мне посоветовали изменить MTU — это для Ping’а, который 32 байта. Потом «поиграйся» с tcp-send-mss и tcp-receive-mss в полиси — для VXLAN, который инкапсулируется в UDP. Фуф, простите — накипело. В общем эту проблему решил своими силами.
Успешно откатав тестовый трафик, решено было внедрять это решение. И в продакшене выяснилось, что после дня-двух постепенно отваливаются вообще всё, что мониторится через VXLAN. Деактивация/активация интерфейса помогала, но только на время. Памятуя о неторопливости саппорта производителся, я занялся траблшутингом со своей стороны — в конце концов моя компания, моя сеть — моя ответственность.
Под спойлером ход траблшутинга. Кто устал от букв и бахвальства — пропускайте и переходите к постанализу.
Ход траблшутингаСпасибо, что продолжили чтение — продолжим!
Итак, мониторинг работает некоторое время, потом отваливается сам собой. Значит в политиках фаервола скорее всего проблем нет. Однако, так как я сталкивался с проблемой зависающих системных процессов в Fortigate версий 5.6+, поэтому сначала смотрим «diagnose debug flow» — ожидаемо трафик разрешается и улетает с интерфейса и ожидаемо ничего не приходит в ответ. Значит копаем далее по стеку. Придётся, к сожалению, скрывать адреса пусть даже и RFC1918, но надеюсь снабдить процесс достаточным описанием для понимания. Сервер внутри VXLAN имеет адрес х.х.х.15, интерфейс фортигейта х.х.х.254, все остальные адреса относятся к сети VTEP.
Для успешной передачи VXLAN-инкапсулированых пакетов необходимо наличие корректной информации в нескольких таблицах. Для overlay это ARP и OVSDB, для underlay это ARP и CAM. В случае Fortigate VXLAN FDB и есть OVSDB. Там и начнём:
fortigate (root) #diag sys vxlan fdb list vxlan-LS
mac=00:50:56:8f:3f:5a state=0x0002 flags=0x00 remote_ip=у.у.у.47 port=4789 vni=5008 ifindex=7
Тут всё достаточно просто — MAC адрес виртуалки должен находиться на VTEP с адресом у.у.у.47. Посмотрев содержимое и настройки ESXI кластера, я нахожу, что MAC виртуалки верный, адрес VTEP тоже. Проверяю CAM/ARP таблицу на фортике — опять все совпадает с настройками ESXI хоста:
fortigate (root) #get sys arp | grep у.у.у.47
у.у.у.47 0 00:50:56:65:f6:2c dmz
Таблицы верны и трафик уходит — может проблема не на фортигейте? Я намеренно пропустил анализ коммутации трафика на Juniper’е — по логике это на нём надо осуществлять следующий шаг траблшутинга, но сеть у меня простая — всего один VLAN для VTEP и все компоненты подключены напрямую. Плюс вспоминаю кейс с DLR-бриджем, VDR и пропадающем трафике — иду снифить на ESXI хост, попутно создаю кейс уже к VMWare. Ниже MAC «97:6e» принадлежит фортику, vmnic1 — это интерфейс, который имеет VTEP с адресом у.у.у.47 снифим в обоих направлениях "—dir 2":
pktcap-uw --uplink vmnic1 --vni 5008 --mac 90:6c:ac:a9:97:6e --dir 2 -o /tmp/monitor.pcap
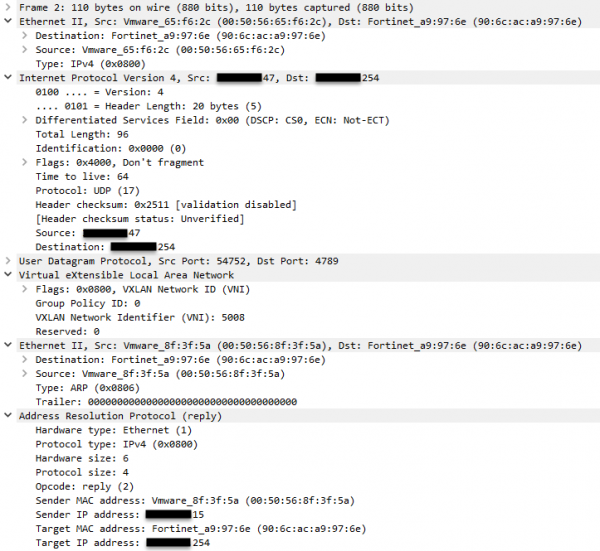
Прогресс — в снифе вижу ARP запрос и приходящий ответ. Привожу только ARP ответ и там всё верно. Я не упомянул, но всё это время сервер мониторинга пингует адрес х.х.х.15 — где же ICMP трафик? Вспоминаю, что аплинка у меня два. Тут можно поспорить и сказать, что виртуальный порт источника один и тот же (мой teaming policy), то есть для одной и той же vNIC должен выбираться один и тот же аплинк, но раз уж я на хосте, проверить другой аплинк не проблема:
pktcap-uw --uplink vmnic4 --vni 5008 --mac 90:6c:ac:a9:97:6e --dir 2 -o /tmp/monitor.pcap
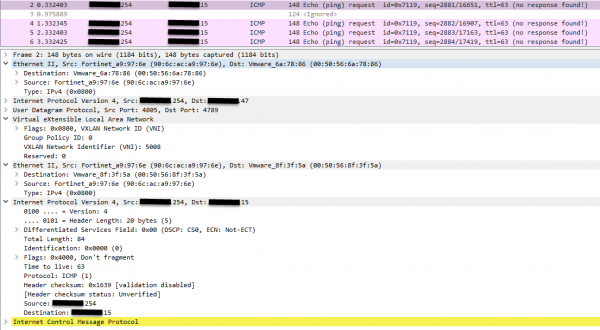
Приходят запросы от фортигейта, но ответа нет. То есть проблема не в фортигейте. Ну всё — думаю я — опять та же проблема с пропадающим трафиком на VDR, опять пару месяцев направлять кейс в нужное русло. Через пару дней поостыв, и не желая мириться с висяком, решил накопать еще снифов для саппорта, чтобы ускорить процесс. И тут «случайно» взгляд мой падает на Ethernet инкапсуляцию underlay. Царь-то не настоящий и MAC адрес VTEP не совпадает с его IP. Сбрасываю в ноль, снифлю, копаю — верно, что не верно. Приведу ARP таблицу рядом, чтобы было удобнее сравнивать. Обратите внимание на первую Ethernet инкапсуляцию на картинке сверху:
fortigate (root) #get sys arp | grep у.у.у.47
у.у.у.47 0 00:50:56:65:f6:2c dmz
fortigate (root) #get sys arp | grep у.у.у.42
у.у.у.42 0 00:50:56:6a:78:86 dmz
Итак, что мы имеем в итоге — после миграции виртуальной машины, фортигейт пытается отправить трафик на VTEP из (корректной) VXLAN FDB, но использует неправильный DST MAC и трафик ожидаемо отбрасывается получающим его интерфейсом гипервизора. Причём в одном случае из четырёх этот MAC принадлежал исходному гипервизору, с которого начинали миграцию машины.
Вчера получил письмо от техподдержки Fortinet — по моему кейсу открыли баг 615586. Прям не знаю радоваться или горевать: с одной стороны — проблема не в настройках, с другой — фикс придет только с обновлением прошивки, в лучшем случае следующем. ЧСВ подогревает так же еще один баг, который я выявил в прошлом месяце, правда в тот раз в HTML5 GUI vSphere. Ну прям локальный QA отдел вендоров…
Рискну предположить следующее:
1 — multicast control plane скорее всего не будет подвержена описанной проблеме — ведь MAC адреса VTEP получаются из IP адреса группы, на которую подписан интерфейс.
2 — скорее всего проблема фортика в оффлоаде сессий на Network Processor (приблизительно аналог CEF) — если пропускать каждый пакет через CPU, будут использоваться таблицы содержащие верную — во всяком случае визуально — информацию. В пользу этого предположения идёт то, что помогает закрыть/открыть интерфейс или выждать некоторое время — более 5 минут.
3 — изменение teaming policy, например на explicit failover, или внедрение LAG проблему не решит, так как наблюдалось «застревание» MAC исходного гипервизора в инкапсулированых пакетах.
В свете этого могу поделиться, что недавно открыл для себя , где в одной из статей утверждалось, что stetfull фаерволы и кэшируемые способы передачи данных — это костыли. Что ж, я не на столько опытен в IT, чтобы утверждать подобное, к тому же не со всеми утверждениями статей блога согласен сходу. Однако что-то мне подсказывает, что доля правды в словах Ивана есть.
Благодарю за внимание! Буду рад ответить на вопросы и услышать конструктивную критику.
Allikas: habr.com
