

Lugupeetud lugejad, tere päevast. Täna räägime natuke Apache Sparkist ja selle arenguvõimalustest.

Kaasaegses maailmas on Big Data jaoks Apache Spark de facto standard andmete partiide töötlemise ülesannete arendamisel. Lisaks kasutatakse seda ka voogedastusrakenduste loomiseks, mis töötavad mikropartiide kontseptsioonis, töötledes ja edastades andmeid väikeste osade kaupa (Spark Structured Streaming). Traditsiooniliselt on see olnud osa Hadoopi üldisest tehnoloogiakogumist, kasutades ressursihaldurina YARNi (või mõnel juhul Apache Mesosit). Aastaks 2020 on selle traditsioonilise kasutuselevõtt enamikus ettevõtetes suure küsimärgi all, kuna puuduvad korralikud Hadoopi jaotised — HDP ja CDH arendamine on peatatud, CDH pole piisavalt välja töötatud ja sellel on kõrged kulud, ning teised Hadoopi pakkujad on kas lõpetanud oma tegevuse või neil on ebamugav tulevik. Seetõttu on Apache Sparki käitamine Kuberneteses kogukonna ja suurte ettevõtete seas üha suuremat huvi pälvinud — olles standard konteinerite orkestreerimisel ja ressursside haldamisel privaatsetes ja avalikes pilvedes, lahendab see probleemi YARNis Spark'i ülesannete ressursside haldamise ebamugavuste osas ning pakub stabiilselt arenevat platvormi paljude kommerts- ja avatud jaotistega igas suuruses ja määraga ettevõtetele. Hästi populaarseks muutumise laine tõukab enamikku juba omama mitut oma paigaldust ja suurendama oma ekspertteadmisi, mis lihtsustab üleviimist.
Alates versioonist 2.3.0 on Apache Spark saanud ametliku toe ülesannete käivitamiseks Kubernetes klastris. Täna räägime selle lähenemise praegusest küpsusest, erinevatest kasutusvõimalustest ning takistustest, millega tuleb silmitsi seista rakendamisel.
Käesolevalt vaatame Apache Spark'i põhjal ülesannete ja rakenduste arendusprotsessi ning toome välja tüüpilised juhtumid, kus on vaja käivitada ülesanne Kubernetes klastris. Selles postituses kasutatakse jaotuseks OpenShift'i ja esitatakse käsklused, mis on kehtivad selle käsurea utiliidi (oc) jaoks. Muude Kubernetes jaotiste puhul võib kasutada vastavaid standardse Kubernetes'i käsurea utiliidi (kubectl) käske või nende analooge (nt oc adm policy).
Esimene kasutusvariant — spark-submit
Arendustegevuste ja rakenduste arendamine nõuab arendajalt andmete transformatsiooni silumise ülesannete käivitamist. Teoreetiliselt võivad selleks kasutada pealdisi, kuid reaalses (kuigi testversiooniga) lõpp süsteemide puhul, on näidatud, et arendamine kulgeb selles klassis kiiremini ja kvaliteetsemalt. Kui teeme silumist reaalsetes lõpp süsteemide eksemplarides, on tõenäolised kaks töö stsenaariumi:
- arendaja käivitab Spark ülesande kohapeal standalone režiimis;

- arendaja käivitab Spark ülesande Kubernetes klastris testkeskkonnas.
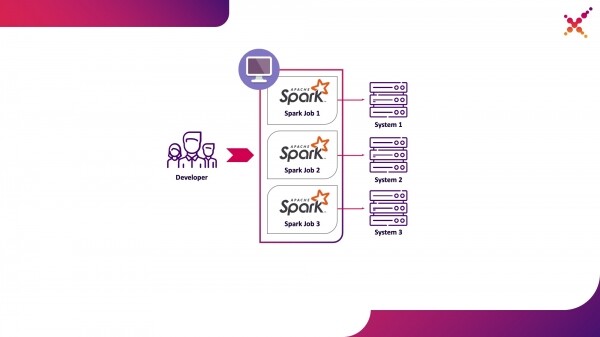
Esimene variant on olemas, aga sellega kaasnevad mitmed puudused:
- iga arendaja peab tagama juurdepääsu kõikidele vajalikutele lõpp süsteemide eksemplaridele oma töökohalt;
- töökohal peab olema piisavalt ressursse arendatava ülesande käivitamiseks.
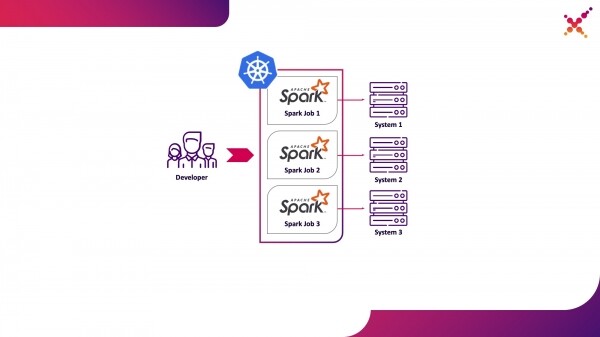
Teine variant on vaba andmete puudustest, kuna Kubernetes klastrite kasutamine võimaldab eraldada vajaliku ressursside basseini ülesannete käivitamiseks ning tagada sellele vajalikud ligipääsud lõpp-süsteemide instantsidele, paindlikult andes sellele juurdepääsu Kubernetes rollimudeli kaudu kõigile arendustiimi liikmetele. Nimetame seda esimeseks kasutusjuhtumiks — Spark'i ülesannete käivitamine arendaja kohalikult masinal Kubernetes klastris testkontekstis.
Räägime lähemalt Spark'i kohaliku käivitamise seadistamise protsessist. Spark'i kasutamise alustamiseks tuleb see installida:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Kogume Kubernetesega töötamiseks vajalikud paketid:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
Täielik kogumine võtab palju aega, ning Docker'i piltide loomine ja nende käivitamine Kubernetes klastris vajab tegelikult ainult jar-faile kataloogist 'assembly/', seega saab koguda ainult selle alamprojekti:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Spark'i käivitamiseks Kuberneteses tuleb luua Docker'i pilt, mida kasutatakse alusena. Siin on võimalikud kaks lähenemist:
- Loodud Docker'i pilt sisaldab Spark'i ülesande käivitatavat koodi;
- Loodud pilt sisaldab ainult Spark'i ja vajalikke sõltuvusi, käivitatav kood paikneb kaugel (näiteks HDFS-is).
Alustame Docker'i pildi koostamist, mis sisaldab testjuhtumit Spark'i ülesandest. Spark'il on Docker'i piltide loomiseks sobiv utiliit nimega «docker-image-tool». Vaadakem selle kohta abi:
./bin/docker-image-tool.sh --help
Selle abil saab luua Docker'i pilte ja laadida neid kaugele registrisse, kuid vaikimisi on sel mitmeid puudusi:
- see loob automaatselt kolm Docker'i pilti — Spark'i, PySpark'i ja R-i jaoks;
- ei luba määrata pildi nime.
Seetõttu kasutame allpool esitatud muudetud versiooni sellest utiliidist:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}"
-t $(image_ref $IMAGE_REF)
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Selle abil koostame Spark'i baaspildi, mis sisaldab testülesannet Pi arvestamiseks Spark'i abil (siin {docker-registry-url} — teie Docker'i piltide registri URL, {repo} — registri sisene nimekiri, mis vastab OpenShifti projektile, {image-name} — pildi nimi (kui kasutatakse kolmekihilist piltide jagamist, näiteks Red Hat OpenShift'i integreeritud registris), {tag} — selle pildi versiooni silt):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Logime sisse OKD klastrisse konsooli utiliidi abil (siin {OKD-API-URL} — OKD klastri API URL):
oc login {OKD-API-URL}
Saame praeguse kasutaja tokeni Docker Registry autoriseerimiseks:
oc whoami -t
Logime sisse OKD klastri sisemisse Docker Registry'sse (paroolina kasutame eelneva käsu kaudu saadud tokenit):
docker login {docker-registry-url}
Laadime üles koostatud Docker'i pildi OKD Docker Registry'sse:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Kontrollime, et koostatud pilt on OKD-s saadaval. Selleks avame brauseris URL-i, kus on nimetatud vastava projekti pildid (siin {project} on projekti nimi OpenShifti klastris, {OKD-WEBUI-URL} on OpenShifti veebikonsoli URL) — https://{OKD-WEBUI-URL}/console/project/{project}/browse/images/{image-name}.
Ülesannete käivitamiseks peab olema loodud teenuse konto, millel on podide root õigused (arutame seda teemat hiljem):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Käivitame käsu spark-submit, et avaldada Spark-i ülesanne OKD klastris, märkides loodud teenuse konto ja Docker pildi:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Siin:
—name — ülesande nimi, mis osaleb Kubernetes-i podide nimede loomises;
—class — käivitatava faili klass, mis kutsutakse ülesande käivitamisel;
—conf — Spark-i konfiguratsiooniparametrid;
spark.executor.instances — käivitatavate Spark-i eksekutorite arv;
spark.kubernetes.authenticate.driver.serviceAccountName — Kubernetes-i teenuse konto nimi, mida kasutatakse podide käivitamisel (turbe konteksti määratlemiseks ja API-ga suhtlemiseks);
spark.kubernetes.namespace — Kubernetes-i nimekiri, kus käivitatakse draiveri ja eksekutorite podid;
spark.submit.deployMode — Spark'i käivitamisviis (tava spark-submit jaoks kasutatakse "cluster", Spark Operator'i ja uuemate Spark'i versioonide jaoks "client");
spark.kubernetes.container.image — Docker'i pilt, mida kasutatakse podide käivitamiseks;
spark.master — Kubernetes'i API URL (märgitakse, et väline juurdepääs toimub kohalikult masinalt);
local:// — tee Spark'i käivitatavale failile Docker'i pildis.
Liigume vastavasse OKD projekti ja vaatame loodud podid — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods.
Arendamisprotsessi lihtsustamiseks võib kasutada veel ühte varianti, kus luuakse ühine Spark'i põhifail, mida kõik ülesanded kasutavad käivitamiseks, ja käivitatavate failide sünkroonid avaldatakse välishoidlas (näiteks Hadoop) ning osutatakse spark-submit'i kutsumisel lingina. Sellisel juhul saab käivitada erinevaid Spark'i ülesande versioone, ilma et oleks vaja Docker'i pilte uuesti koostada, kasutades näiteks WebHDFS'i piltide avaldamiseks. Saadame päringu faili loomise jaoks (siin {host} — WebHDFS teenuse host, {port} — WebHDFS teenuse port, {path-to-file-on-hdfs} — soovitud tee faili HDFS-ile):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE"
Sel juhul saadakse vastus järgmist tüüpi (kus {location} on URL, mida tuleb kasutada faili üleslaadimiseks):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Laadime Spark'i käivitatava faili HDFS-i (kus {path-to-local-file} on käivitatava faili teekohane asukoht antud hostis):
curl -i -X PUT -T {path-to-local-file} "{location}"
Pärast seda saame teha spark-submit Spark'i faili kasutades, mis on HDFS-ile laaditud (kus {class-name} on klassi nimi, mida tuleb ülesande täitmiseks käivitada):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Siinkohal tuleb märkida, et HDFS-i juurde pääsemiseks ja ülesande tööks võib olla vajalik muuta Dockerfile'i ja skripti entrypoint.sh — lisades Dockerfile'isse käsu sõltuvate teekide kopeerimiseks kausta /opt/spark/jars ja sisaldades HDFS-i konfiguratsiooni faili SPARK_CLASSPATH entrypoint.sh-s.
Teine kasutusvariant — Apache Livy
Kui ülesanne on välja töötatud ja saadud tulemust tuleb testida, tekib küsimus selle käitamisest CI/CD protsessis ning selle täitmise staatuse jälgimisest. Loomulikult võib ülesande käivitada ka kohaliku spark-submit'i kaudu, kuid see muudab CI/CD infrastruktuuri keerukamaks, kuna see nõuab Spark'i installimist ja seadistamist CI serveri agentides/runnerites ning juurdepääsu seadistamist Kubernetes API-le. Antud juhul on sihtrealiseerimises valitud Apache Livy kasutamine REST API-na Spark'i ülesannete käitamiseks, mis on paiknenud Kubernetes klastris. Selle abil saab käivitada Spark'i ülesandeid Kubernetes klastris, kasutades tavalisi cURL päringuid, mis on hõlpsasti teostatavad iga CI lahenduse alusel, ja selle paiknemine Kubernetes klastri sees lahendab autentimise küsimuse Kubernetes API-ga suhtlemisel.
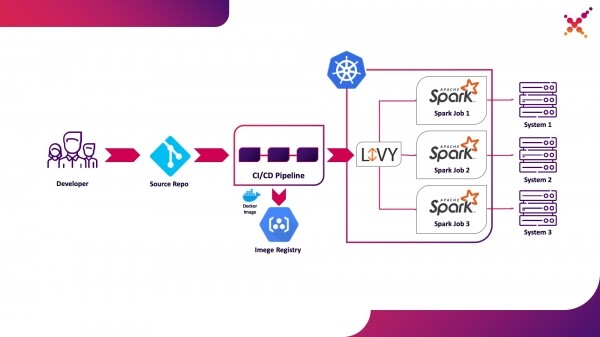
Väärib mainimist kui teiseks kasutusvõimaluseks — Spark'i ülesannete käitamine CI/CD protsessi raames Kubernetes klastris testimiskeskkonnas.
Veidi Apache Livy kohta — see töötab HTTP serverina, pakkudes veebiliidest ja RESTful API-d, mis võimaldab kaugel käivitada spark-submit, edastades vajalikud parameetrid. Traditsiooniliselt oli see osa HDP jaotusest, kuid seda saab samuti juurutada OKD või mis tahes muus Kubernetesi installatsioonis vastava manifesti ja Dockerite komplekti abil, näiteks seda — . Meie juhtumi jaoks oli loodud sarnane Dockeri image, mis sisaldas Spark 2.4.5 vastavalt järgmisele Dockerfile'ile:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash &&
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz &&
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz &&
rm spark-2.4.5-bin-hadoop2.7.tgz &&
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip &&
unzip apache-livy-0.7.0-incubating-bin.zip &&
rm apache-livy-0.7.0-incubating-bin.zip &&
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy &&
mkdir /var/log/livy &&
ln -s /var/log/livy /opt/livy/logs &&
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
Loodud pilt saab olla kogutud ja üles laaditud teie olemasolevasse Dockerite registrisse, näiteks OKD siseregistrisse. Selle kasutamiseks rakendamiseks kasutatakse järgmist manifesti ({registry-url} — Dockeri registri URL, {image-name} — Dockeri pildi nimi, {tag} — Dockeri pildi silt, {livy-url} — soovitud URL, mille kaudu Livy serverile juurde pääseb; manifest "Route" rakendatakse juhul, kui Kubernetes'i distributsiooniks on Red Hat OpenShift, vastasel juhul kasutatakse vastavat Ingress'i või NodePort tüüpi teenuse manifesti):
---
apiVersion: apps\/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4\/spark:v1.0.14'
image: '{registry-url}\/\{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: \/dev\/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: \/var\/log\/livy
name: livy-log
- mountPath: \/opt\/.livy-sessions\/
name: livy-sessions
- mountPath: \/opt\/livy\/conf\/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: \/opt\/spark\/conf\/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- \/usr\/local\/bin\/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4\/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: \/dev\/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=\/opt\/.livy-sessions\/
livy.spark.master=k8s:\/\/http:\/\/localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4\/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io\/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Pärast selle rakendamist ja edukat poodi käivitamist on Livy graafiline liides saadaval aadressil: http://{livy-url}/ui. Livy abil saame avaldada oma Spark'i ülesande REST-päringu kaudu, näiteks Postman'ist. Allpool on esitatud päringute kogum (massiivis "args" saab edastada konfigureerimisargumendid koos muutujatega, mis on vajalikud käivitatava ülesande toimimiseks):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Esita töö jar-iga",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{nt"file": "local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar", nt"className": "org.apache.spark.examples.SparkPi",nt"numExecutors":1,nt"name": "spark-test-1",nt"conf": {ntt"spark.jars.ivy": "/tmp/.ivy",ntt"spark.kubernetes.authenticate.driver.serviceAccountName": "spark",ntt"spark.kubernetes.namespace": "{project}",ntt"spark.kubernetes.container.image": "{docker-registry-url}/{repo}/{image-name}:{tag}"nt}n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Esita töö ilma jar-ita",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{nt"file": "hdfs://{host}:{port}/{path-to-file-on-hdfs}", nt"className": "{class-name}",nt"numExecutors":1,nt"name": "spark-test-2",nt"proxyUser": "0",nt"conf": {ntt"spark.jars.ivy": "/tmp/.ivy",ntt"spark.kubernetes.authenticate.driver.serviceAccountName": "spark",ntt"spark.kubernetes.namespace": "{project}",ntt"spark.kubernetes.container.image": "{docker-registry-url}/{repo}/{image-name}:{tag}"nt},nt"args": [ntt"HADOOP_CONF_DIR=/opt/spark/hadoop-conf",ntt"MASTER=k8s://https://kubernetes.default.svc:8443"nt]n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Teeme esimese päringu kogumist, läheme OKD liidese sisse ja kontrollime, et ülesanne käivitatakse edukalt — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods. Samuti ilmub Livy liideses (http://{livy-url}/ui) seanss, mille raames saab API Livy või graafilise liidese abil jälgida ülesande täitmise edenemist ja uurida seansi logisid.
Nüüd näitame Livy töömekanismi. Selleks uurime Livy konteineri logisid Livy serveri sees asuvas podis — https://{OKD-WEBUI-URL}/console/project/{project}/browse/pods/{livy-pod-name}?tab=logs. Nendest on näha, et kui kutsuda välja Livy REST API, käivitatakse konteineris nimega «livy» spark-submit, mis on sarnane meie eespool kasutatule (siin {livy-pod-name} on loodud Livy serveri podi nimi). Kogumis on esitatud ka teine päring, mis võimaldab käivitada ülesandeid kaugasukohtade kaudu Spark'i täitmisfaili abil Livy serveri kaudu.
Kolmas kasutusvõimalus — Spark Operator
Nüüd, kui ülesanne on testitud, kerkib küsimus selle regulaarse käivitamise kohta. Kuberneteses ülesannete regulaarseks käivitamiseks on natiivne viis CronJob'i kasutamine. Kuigi seda saab kasutada, on hetkel laialt levinud operaatorite kasutamine Kuberneteses rakenduste haldamiseks. Spark'i jaoks on olemas piisavalt küps operaator, mida kasutatakse ka ettevõtte taseme lahendustes (näiteks Lightbend FastData Platform). Soovitame seda kasutada — praegune stabiilne versioon Spark (2.4.5) pakub üsna piiratud võimalusi Spark'i ülesannete käivitamise konfiguratsiooniks Kuberneteses, samas kui järgmises peaversioonis (3.0.0) on lubatud täieõiguslik Kubernetes'e tugi, kuid selle väljalaskekuupäev jääb teadmata. Spark Operator kompenseerib selle puuduse, lisades olulised seadistusparameetrid (näiteks ConfigMap'i monteerimise Hadoop'i juurdepääsu konfiguratsiooniga Spark'i pod'desse) ja võimaluse ülesande regulaarseks käivitamiseks ajakava alusel.
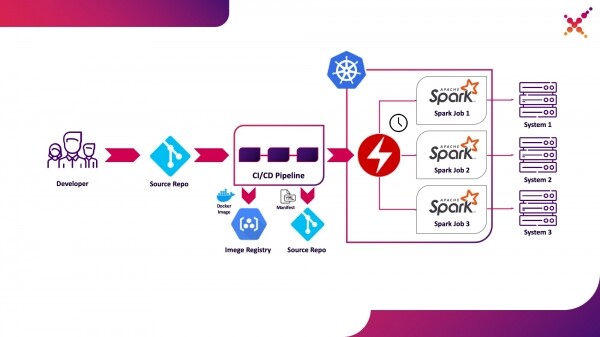
Tõstame selle esile kui kolmandat kasutusviisi — regulaarne Spark'i ülesannete käivitamine Kuberneteses tootmiskeskkonnas.
Spark Operator on avatud lähtekoodiga ja seda arendatakse Google Cloud Platformi raames — . Selle paigaldamine võib toimuda 3 erineval viisil:
- Lightbend FastData Platformi/Cloudflow raames;
- Helmi abil:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator - Kasutades ametlikust hoidlast tulenevaid manifeste (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). Siinkohal tasub märkida, et Cloudflow'i koosseisus on operaator API versiooniga v1beta1. Kui kasutatakse seda paigaldusviisi, peavad Spark'i rakenduste manifeste olema koostatud vastavalt Git'i sildiga esitatud näidetele, millel on vastav API versioon, näiteks „v1beta1-0.9.0-2.4.0“. Operaatori versiooni saab vaadata operaatori CRD-i kirjelduses sõnastikus „versions“:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Kui operaator on õigesti paigaldatud, ilmub vastavasse projekti aktiivne Spark'i pod (näiteks cloudflow-fdp-sparkoperator Cloudflow'i ruumis Cloudflow' jaoks) ning ilmub vastav Kubernetes'i ressursside tüüp nimega „sparkapplications“. Olemasolevate Spark'i rakenduste uurimiseks saab kasutada järgmist käsku:
oc get sparkapplications -n {project}
Spark Operatoriga tööde käivitamiseks tuleb teha kolm asja:
- luua Docker'i pilt, mis sisaldab kõiki vajalikke raamatukogusid, samuti konfiguratsiooni ja käivitatavaid faile. Eesmärgi saavutamiseks on see pilt, mis on loodud CI/CD etapis ja testitud testklastris;
- avalikustada Docker'i pilt registrisse, mis on Kubernetes'i klastri jaoks ligipääsetav;
- koostada „SparkApplication“ tüüpi manifest koos käivitatava ülesande kirjeldusega. Manifestide näiteid on saadaval ametlikus repositooriumis (nt, ). Oluline on märkida mõningaid aspekte seoses manfestiga:
- sõnastikus „apiVersion“ peab olema määratud API versioon, mis vastab operaatori versioonile;
- sõnastikus „metadata.namespace“ peab olema määratud nimede ruum, kus rakendus käivitatakse;
- sõnastikus „spec.image“ peab olema määratud loodud Docker'i pildi aadress ligipääsetavas registris;
- sõnastikus „spec.mainClass“ peab olema määratud Spark'i ülesande klass, mida tuleb protsessi käivitamisel käivitada;
- sõnastikus „spec.mainApplicationFile“ peab olema määratud tee käivitatava jar faili juurde;
- sõnastikus «spec.sparkVersion» peab olema märgitud kasutatav Spark'i versioon;
- sõnastikus «spec.driver.serviceAccount» peab olema märgitud teenuse konto, mis asub vastavas Kubernetes'i nimede ruumis ja mida kasutatakse rakenduse käitamiseks;
- sõnastikus «spec.executor» peab olema märgitud ressursside arv, mis on rakendusele eraldatud;
- sõnastikus «spec.volumeMounts» peab olema märgitud kohaliku kausta tee, kuhu Spark'i ülesannete kohalikud failid luuakse.
Maani festi loomise näide (siin {spark-service-account} on teenuse konto, mis asub Kubernetes'i klastri sees Spark'i ülesannete käitamiseks):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:////opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Selles manifestis on märgitud teenusekonto, mille jaoks tuleb enne manifesti avaldamist luua vajalikud rolli sidumised, et anda Spark'i rakendusele vajalikud juurdepääsuõigused Kubernetes API-ga suhtlemiseks (kui vajalik). Meie puhul on rakendusele vajalikud õigused Pod'ide loomiseks. Loome vajaliku rolli sidumise:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Samuti tasub mainida, et selle manifesti spetsifikatsioonis võib olla määratud parameeter „hadoopConfigMap”, mis võimaldab määrata ConfigMap'i Hadoop konfiguratsiooniga ilma, et oleks vaja eelnevalt vastavat faili Docker'i pildisse lisada. See sobib ka regulaarsete ülesannete käivitamiseks — parameetri „schedule” abil saab määrata selle ülesande käivitamise ajakava.
Pärast seda salvestame meie manifesti faili spark-pi.yaml ja rakendame selle meie Kubernetes klastrile:
oc apply -f spark-pi.yaml
Selle tulemusena luuakse objekt tüüpi „sparkapplications”:
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Selle käigus luuakse rakenduse pod, mille olek kuvatakse loodud „sparkapplications” töös. Selle üle saab vaadata järgmise käsuga:
oc get sparkapplications spark-pi -o yaml -n {project}
Töö lõpetamisel läheb POD staatuseks „Completed”, mis uuendatakse ka „sparkapplications” osas. Rakenduse logisid saab vaadata brauseris või kasutades järgmist käsku (siin {sparkapplications-pod-name} on käivitatud ülesande poda nimi):
oc logs {sparkapplications-pod-name} -n {project}
Spark'i ülesannete haldamist saab ka spetsialiseeritud tööriista sparkctl abil. Selle paigaldamiseks kloonime repositooriumi koos allikakoodiga, installime Go ja kogume selle tööriista:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Vaatame käivitatud Spark'i ülesannete loendit:
sparkctl list -n {project}
Loome Spark'i ülesande kirjelduse:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:////opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Käivitame kirjeldatud ülesande sparkctl'i abil:
sparkctl create spark-app.yaml -n {project}
Vaatame käivitatud Spark'i ülesannete loendit:
sparkctl list -n {project}
Vaatame käivitatud Spark-ülesande sündmuste loetelu:
sparkctl event spark-pi -n {project} -f
Uurime käivitatud Spark-ülesande staatust:
sparkctl status spark-pi -n {project}
Kokkuvõtteks vaatame, milliseid puudusi on tuvastatud praeguse stabiilse Spark versiooni (2.4.5) kasutamisel Kuberneteses:
- Esimene ja võib-olla peamine puudus on andmete lokaliseerimise puudumine. Kõikide YARN-i puuduste juures oli selle kasutamisel ka eeliseid, näiteks koodi edastamise põhimõte andmetele (mitte andmete edastamine koodile). Tänu sellele käideldi Spark'i ülesandeid sõlmedes, kus asusid arvutustes osalevad andmed, mis nõudis märgatavalt vähem aega andmete edastamiseks üle võrgu. Kubernetes'e kasutamisel peame silmitsi seisma vajadusega edastada andmeid, mis on tööülesande täitmisel vajalikud. Kui need on piisavalt suured, võib tööülesande täitmise aeg oluliselt pikeneda ning võib olla vajalik eraldada piisavalt suur kettaruum Spark'i ülesande eksemplaride ajutiseks salvestamiseks. Seda puudust saab vähendada spetsialiseeritud tarkvarade abil, mis tagavad andmete kohaloleku Kubernetes'es (näiteks Alluxio), kuid see tähendab sisuliselt vajadust säilitada andmete täiskope klastrite sõlmedes.
- Teine oluline miinus on turvalisus. Vaikimisi on Spark'i ülesannete käivitamisega seotud turvafunktsioonid väljalülitatud, Kerberose kasutamise võimalust ametlikus dokumentatsioonis ei käsitleta (kuigi vastavad seaded ilmusid versioonis 3.0.0, mis nõuab täiendavat töötlemist), ning Spark'i turvalisuse dokumentatsioonis (https://spark.apache.org/docs/2.4.5/security.html) kajastuvad võtmehoidjatena ainult YARN, Mesos ja Standalone Cluster. Samuti ei saa Spark'i ülesandeid käitava kasutaja identiteeti otse määrata — määrame vaid teenuse kasutajakonto, mille all see käitub, ja kasutaja valitakse turvapoliitikate põhjal. Sellega seoses kas kasutatakse root kasutajat, mis ei ole tootmiskeskkonnas turvaline, või juhuslikku UID'd, mis on ebamugav andmete juurdepääsu õiguste jaotamisel (lahendatav PodSecurityPolicies loomise ja nende seondumisega vastavate teenuse kasutajakontodega). Praegu lahendatakse see kas paigutades kõik vajalikud failid otse Docker'i pildile või muutes Spark'i käivitusskripti, et kasutada teie organisatsioonis aktsepteeritud saladuste hoidmise ja hankimise mehhanismi.
- Spark'i käivitamine Kubernetesega on jätkuvalt eksperimentaalne ja tulevikus võivad kasutada olevaid artefakte (konfiguratsioonifailid, Docker'i põhifailid ja käivitusskriptid) olulisi muudatusi. Tõepoolest — materjali ettevalmistamise ajal testiti versioone 2.3.0 ja 2.4.5, mille käitumine oli oluliselt erinev.
Ootame uuendusi — hiljuti ilmus uus Spark'i versioon (3.0.0), mis toob olulisi muudatusi Spark'i toimimisse Kuberneteses, kuid säilitab eksperimentaalse toe selle ressursihalduri jaoks. Võimalik, et järgmised uuendused tõepoolest võimaldavad soovitada YARN'ist loobumist ja Spark'i ülesannete käivitamist Kuberneteses, kartmata oma süsteemi turvalisuse pärast ning ilma vajaduseta iseseisva funktsionaalsete komponentide kohandamise järele.
Fin.
Allikas: habr.com
