


Oma töös kohtan ma tihti uusi tehnilisi lahendusi/programmide tooteid, mille kohta on vene keeles internetis suhteliselt vähe teavet. Selle artikliga püüan täita ühe sellise lünga, tuues näite oma hiljutisest praktikast, kus oli vajalik seadistada CDC-sündmuste saatmine kahest populaarsest andmebaasist (PostgreSQL ja MongoDB) Kafka klastrisse Debeziumi abil. Loodan, et see ülevaateartikkel, mis sündis tehtud töö tulemusena, osutub kasulikuks ka teistele.
Mis on Debezium ja üldiselt CDC?
— CDC tarkvara kategooria esindaja (), täpsemalt öeldes on see erinevate andmebaaside konnektorite kogum, mis on ühilduv Apache Kafka Connect raamistiku süsteemiga.
See millel on Apache License v2.0 litsents ja mida sponsoreerib ettevõte Red Hat. Arendustööd on alustatud 2016. aastal ning praegu on ametlik tugi järgmistele andmebaasidele: MySQL, PostgreSQL, MongoDB, SQL Server. Samuti on olemas konnektorid Cassandra ja Oracle jaoks, kuid need on praegu 'varajase juurdepääsu' staatuses, ning uued väljalasked ei garanteeri tagasipöördumatut ühilduvust.
Kui võrrelda CDC-d traditsioonilise lähenemisega (kui rakendus loeb andmeid otse andmebaasist), siis selle peamisteks eelisteks on madala latentsusega, kõrge usaldusväärsuse ja kättesaadavuse taseme saavutamine andmete muutuste voogude realiseerimise kaudu ridade tasandil. Viimane kahest punktist saavutatakse, kasutades Kafka klastrit CDC-sündmuste salvestamiseks.
Samuti on eeliste hulka arvestatav, et sündmuste salvestamiseks kasutatakse ühtset mudelit, seega ei pea lõpprakendus muretsema erinevate andmebaaside haldamise spetsiifikaga.
Lõpuks, thanks to the use of a message broker, the potential for horizontal scalability emerges for applications that track data changes. At the same time, the impact on the data source is minimized, as data is not retrieved directly from the database but rather from the Kafka cluster.
Debeziumi arhitektuurist
Debeziumi kasutamine piirdub sellise lihtsa skeemiga:
Andmebaas (andmeallikas) → konnektor Kafka Connectis → Apache Kafka → tarbija
Illustreerimiseks toome välja skeemi projekti veebisaidilt:
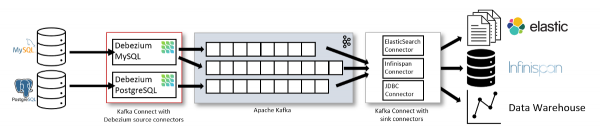
Kuid see skeem ei meeldi mulle eriti, kuna jääb mulje, et on võimalik kasutada ainult sink-konnektorit.
Tegelikult on olukord teine: teie Data Lake'i täitmine (ülemises skeemis viimane element) — pole ainus viis Debeziumi rakendamiseks. Apache Kafka'sse saadetud sündmusi saab teie rakendustes kasutada erinevate olukordade lahendamiseks. Näiteks:
- mitteaktuaalsete andmete eemaldamine vahemälust;
- teadete saatmine;
- otsinguindeksite värskendamine;
- mingisugused auditilogid;
- …
Kui teie rakendus on Java-s ja puudub vajadus/võimalus kasutada Kafka klastrit, on olemas ka võimalus töötada läbi . Selge eelis on see, et sellega ei pea lisainfrastruktuurist (konnektor ja Kafka) loobuma. Siiski on see lahendus 1.1 versioonist alates kuulutatud aegunuks (deprecated) ja selle kasutamist ei soovitata enam (tulevastes väljaannetes võib selle toe eemaldada).
Käesolevas artiklis käsitletakse soovitatud arendajate arhitektuuri, mis tagab talitlushäireteta toimimise ja skaleeritavuse.
Ühenduse konfiguratsioon
Et alustada muutuste jälgimist meie peamise varanduse – andmete – osas, on meil vaja:
- andmeallikat, milleks võivad olla MySQL alates versioonist 5.7, PostgreSQL 9.6+, MongoDB 3.2+ ();
- Apache Kafka klaster;
- Kafka Connecti instants (versioonid 1.x, 2.x);
- konfigureeritud Debeziumi ühendaja.
Kaks esimest punkti, st andmebaasi ja Apache Kafka installimisprotsess, jäävad artikli huvist väljapoole. Siiski, neile, kes soovivad kõik liivakasti käivitada, on ametlikus näidiste hoidlas olemas valmis .
Keskendume aga kahe viimase punkti sisule.
0. Kafka Connect
Siin ja edaspidi artiklis kaalutakse kõiki konfigureerimise näiteid Debeziumi arendajate levitatava Docker-pildi kontekstis. See sisaldab kõiki vajalikke pistikfailide (ühendajate) faile ja võimaldab Kafka Connecti konfigureerimist keskkonnamuutujate abil.
Kui eeldatakse, et kasutatakse Confluenti Kafka Connecti, tuleb vajalike ühendajate pistikfailid iseseisvalt lisada kausta, mis on määratud plugin.path või määratletud keskkonnamuutujaga CLASSPATH. Kafka Connecti töötlus ja konnektorite seadistused määratakse konfigureerimisfailide kaudu, mis antakse töötluse käivitamise käsu argumentidena. Rohkem teavet leiate .
Kogu Debeizumi seadistamisprotsess konnektoriga toimub kahes etapis. Vaatame igaüht neist:
1. Kafka Connect raamistiku seadistamine
Andmete voogedastamiseks Apache Kafka klastrisse Kafka Connect raamistiku kaudu määratakse spetsiifilised parameetrid, nagu:
- ühenduse parameetrid klastriga,
- teemade nimed, kus salvestatakse otse konnektori konfiguratsioon,
- grupi nimi, milles konnektor töötab (juhul kui kasutatakse jaotatud režiimi).
Projektile ametlik Docker-pilt toetab konfigureerimist keskkonnamuutujate abil — seda me ka kasutame. Nii et laadime alla pildi:
docker pull debezium/connectMinimum keskkonnamuutujate kogum, mis on vajalik konnektori käivitamiseks, on järgmine:
-
BOOTSTRAP_SERVERS=kafka-1:9092,kafka-2:9092,kafka-3:9092— algne Kafka klastrite serverite loend, et saada täispakkumine klastrite liikmetest; -
OFFSET_STORAGE_TOPIC=connector-offsets— teema, mis salvestab hetkel konnektori asukohad; -
CONNECT_STATUS_STORAGE_TOPIC=connector-status— konnektori ja tema ülesannete oleku ladustamise teema; -
CONFIG_STORAGE_TOPIC=connector-config— konnektori ja tema ülesannete konfiguratsioonide andmete ladustamise teema; -
GROUP_ID=1— töötajate grupi identifikaator, kus konnektori ülesanne võib toimuda; vajalik jaotatud (distributed) režiimi kasutamisel.
Käivitame konteineri nende muutujaitega:
docker run
-e BOOTSTRAP_SERVERS='kafka-1:9092,kafka-2:9092,kafka-3:9092'
-e GROUP_ID=1
-e CONFIG_STORAGE_TOPIC=my_connect_configs
-e OFFSET_STORAGE_TOPIC=my_connect_offsets
-e STATUS_STORAGE_TOPIC=my_connect_statuses debezium/connect:1.2Märkus Avro kohta
Vaikimisi kirjutab Debezium andmeid JSON-formaadis, mis on sobiv liivakastide ja väikeste andmemahtude jaoks, kuid võib osutuda probleemseks kõrge koormusega andmebaasides. JSON-konverteri alternatiiviks on sõnumite serialiseerimine binaarseks formaadiks, mis võimaldab vähendada I/O alamsüsteemi koormust Apache Kafka-s.
Avro kasutamiseks on vajalik eraldi (skeemide hoidmiseks). Konverteri muutujaid kasutatakse järgmiselt:
name: CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL
value: http://kafka-registry-01:8081/
name: VALUE_CONVERTER
value: io.confluent.connect.avro.AvroConverterAvro kasutamise ja registreerimise seadistamise üksikasjad ületavad artikli piire — edaspidi kasutame selguse huvides JSON-i.
2. Konnektori seadistamine
Nüüd saame minna otse konnektori seadistamise juurde, mis loeb andmeid allikast.
Vaatame kahe andmebaasi, PostgreSQLi ja MongoDB, konnektoreid — nendes on mul kogemusi ja on teatud erinevusi (kuigi väikesed, võivad need mõnel juhul olla märkimisväärsed!).
Konfiguratsioon on kirjeldatud JSON-i notatsioonis ja laaditakse Kafka Connecti POST-requests abil.
2.1. PostgreSQL
PostgreSQL konnektori konfiguratsiooni näide:
{
"name": "pg-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "127.0.0.1",
"database.port": "5432",
"database.user": "debezium",
"database.password": "definitelynotpassword",
"database.dbname" : "dbname",
"database.server.name": "pg-dev",
"table.include.list": "public.(.*)",
"heartbeat.interval.ms": "5000",
"slot.name": "dbname_debezium",
"publication.name": "dbname_publication",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "pg-dev.public.(.*)",
"transforms.AddPrefix.replacement": "data.cdc.dbname"
}
}Konnektori tööpõhimõte pärast sellist seadistust on üsna lihtne:
- Esimese käivitamise ajal ühendub see konfigureeritud andmebaasiga ja siseneb režiimi esialgne snapshot, saates Kafka'sse esmased andmeüksused, mis on saadud tingimuslikust
SELECT * FROM table_name. - Pärast initsialiseerimise lõpetamist liigub konnektor PostgreSQL WAL-failidest muudatuste lugemise režiimi.
Kasutatavate valikute kohta:
-
name— konnektori nimi, mille jaoks kasutatakse allpool kirjeldatud seadistust; tulevikus kasutatakse seda nime konnektoriga töötamiseks (nt oleku vaatamine/taaskäivitamine/seadistuse värskendamine) Kafka Connect REST API kaudu; -
connector.class— andmepood, mida konfigureeritav ühendus kasutab; -
plugin.name— pistiku nimi, mis on mõeldud andmete loogiliseks dekodeerimiseks WAL-failidest. Saadaval on järgmised valikud:wal2json,decoderbuffsjapgoutput. Esimene kaks vajavad vastava laienduse installimist andmebaasis, samas kuipgoutputPostgreSQL versiooni 10 ja uuemate jaoks ei vajata täiendavaid toiminguid; -
database.*— ühenduse valikud andmebaasiga, kusdatabase.server.name— PostgreSQL instantsi nimi, mida kasutatakse teema nime genereerimiseks Kafka klastris; -
table.include.list— tabelite loetelu, kus soovime jälgida muudatusi; sisestatakse vormingusschema.table_name; ei saa kasutada koostable.exclude.list; -
heartbeat.interval.ms— intervall (millisekundites), mil konnektor saadab heartbeat-sõnumeid spetsiaalsesse teema; -
heartbeat.action.query— päring, mida tehakse iga heartbeat-sõnumi saatmisel (valik, mis on saadaval alates versioonist 1.1); -
slot.name— replikatsiooni sloti nimi, mida konnektor kasutab; publication.name— nimi PostgreSQL-is, mida ühendus kasutab. Kui see puudub, proovib Debezium selle luua. Kui kasutajal, kelle all ühendus toimub, ei ole piisavalt õigusi selle toimingu teostamiseks, lõpetab ühendus töö tõrketeatega;-
muundamisedmäärab, kuidas täpselt sihtteema nime muuta:-
transforms.AddPrefix.typenäitab, et kasutame regulaaravaldisi; -
transforms.AddPrefix.regex— muster, mille järgi muudame sihtteema nime; -
transforms.AddPrefix.replacement— see, millele me selle muutume.
-
Rohkem teavet heartbeat'i ja muundamiste kohta
Vaikimisi saadab ühendus andmed Kafka'sse iga kinnitatud tehingu korral ning selle LSN (Log Sequence Number) salvestatakse teenuse teema offset. Aga mis juhtub, kui ühendus on seadistatud lugema mitte kogu andmebaasi, vaid ainult osa selle tabelitest (kus andmete värskendamine ei toimu sageli)?
- Ühendus hakkab lugema WAL-faile ega leia neist tehingute kinnitamist nendes tabelites, mille üle ta jälgib.
- Seetõttu ei uuenda ta oma praegust positsiooni ei teemas ega replikatsiooni slotis.
- See toimetab, et WAL-failid jäävad kettale „kinni“ ja kogu kettaruumi ammendamine võib juhtuda.
Siinkohal tulevad appi valikud heartbeat.interval.ms ja heartbeat.action.query. Nende valikute kasutamine koos võimaldab iga kord, kui saadetakse südamepekslemise sõnum, teha päring andmete muutmiseks eraldi tabelis. Sellisel viisil uuendatakse pidevalt LSN-i, kus konnektor praegu asub (replikatsiooni pesas). See võimaldab DBMS-il eemaldada WAL-failid, mis ei ole enam vajalikud. Lisainfot valikute töö kohta leiate .
Teine valik, mis väärib suuremat tähelepanu, on muundamised. Kuigi see on pigem mugavuse ja ilu pärast...
Vaikimisi loob Debezium teemasid, järgides järgmist nimede määramise poliitikat: serverName.schemaName.tableName. See ei pruugi alati mugav olla. Valikute abil muundamised võib regulaarselt väljendit kasutades määrata tabelite nimekirja, millelt sündmused tuleb suunata konkreetse nimega teema.
Meie konfiguratsioonis tänu PostgreSQL konnektori konfiguratsiooni kirjelduse lõpetamiseks tasub rääkida järgmistest omadustest/piirangutest selle toimimises: Kontrollime, et laadimine toimus edukalt ja konnektor käivitus: Kontrollime, et laadimine õnnestus ja konnektor käivitati: Suurepärane: see on seadistatud ja valmis töötama. Nüüd käitume tarbijana ja ühendame end Kafka'ga, seejärel lisame ja muudame tabelisse kirje: Meie teemas kuvab see järgmiselt: Väga pikk JSON meie muudatustega Mõlemal juhul koosnevad kirjed järjekorra (PK) võtmetest, mis on muudetud, ja muudatuste sisust: millisena oli kande sisu enne ja millisena ta pärast muutus. See konnektor kasutab MongoDB standardset replikatsiooni mehhanismi, lugedes teavet põhivõlvi oplog'ist. Sarnaselt juba kirjeldatud PgSQL konnektorile, tehakse siin esmakordsel käivitamisel andmete esmane snapshot, pärast mida vahetab konnektor üle oplog'i lugemise režiimile. Konfiguratsiooni näidis: Nagu märkida, ei ole siin uusi võimalusi võrreldes eelmise näitega, kuid on vähenenud vaid andmebaasiühenduste ja nende prefikside arv. Seaded Tõrke- ja kõrge kättesaadavuse küsimus on tänapäeval aktuaalne, eriti kui räägime andmetest ja tehingutest, ning andmete muudatuste jälgimine ei jää selles osas üle. Vaatame, mis võib põhimõtteliselt valesti minna ning mis juhtub Debeziumiga igas neist olukordadest. On kolm tõrkevarianti: Kuid on erandeid. Kui konnektor on pikka aega olnud väljas (või ei saanud ühendust MongoDB eksemplariga), ja oplog on selle aja jooksul pöörlemise läbinud, siis ühenduse taastamisel jätkab konnektor rahulikult andmete lugemist esimeselt kätte saadavalt positsioonilt, mistõttu osa andmeid jõuab Kafka ei kuni. Debezium on minu esimene kogemus CDC-süsteemidega, ning üldiselt on see väga positiivne. Projekt teeb mulje oma toetuse poolest peamistele DBMS-idele, konfigureerimise lihtsuse, klastritoe ja aktiivse kogukonna poolest. Praktikat huvitavatele soovitan tutvuda juhenditega ja . Debezium'i peamine eelis JDBC-ühendaja ees Kafka Connect'i jaoks on see, et muudatused loetakse andmebaasi logidest, mis võimaldab andmeid saada minimaalse viivitusega. JDBC Connector (Kafka Connect'i tarnekomplektist) teeb päringuid jälgitava tabeli kohta kindla ajavahega ja (sama põhjusel) ei genereeri see sõnumeid andmete kustutamisel (kuidas saab küsida andmeid, mida enam pole?). Sarnaste probleemide lahendamiseks tasub vaadata järgmisi lahendusi (Lisaks Debeziumile): Lugege ka meie blogist: Allikas: habr.commuundamised juhtuda järgmine: kõik CDC-sündmused jälgitavast andmebaasist jõuavad teema nimega data.cdc.dbnameKui need seaded pole paigas, siis Debezium loodi vaikimisi igale tabelile teema põhjal: pg-dev.public..
Konnektori piirangud
Seega laadime meie konfigureerimise konnektorisse:
curl -i -X POST -H "Accept:application/json"
-H "Content-Type:application/json" http://localhost:8083/connectors/
-d @pg-con.json$ curl -i http://localhost:8083/connectors/pg-connector/status
HTTP/1.1 200 OK
Date: Thu, 17 Sep 2020 20:19:40 GMT
Content-Type: application/json
Content-Length: 175
Server: Jetty(9.4.20.v20190813)
{"name":"pg-connector","connector":{"state":"RUNNING","worker_id":"172.24.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.24.0.5:8083"}],"type":"source"}$ kafka/bin/kafka-console-consumer.sh
--bootstrap-server kafka:9092
--from-beginning
--property print.key=true
--topic data.cdc.dbname
postgres=# insert into customers (id, first_name, last_name, email) values (1005, 'foo', 'bar', 'foo@bar.com');
INSERT 0 1
postgres=# update customers set first_name = 'egg' where id = 1005;
UPDATE 1{
"schema":{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
}
],
"optional":false,
"name":"data.cdc.dbname.Key"
},
"payload":{
"id":1005
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"before"
},
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"after"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"version"
},
{
"type":"string",
"optional":false,
"field":"connector"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"int64",
"optional":false,
"field":"ts_ms"
},
{
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":{
"allowed":"true,last,false"
},
"default":"false",
"field":"snapshot"
},
{
"type":"string",
"optional":false,
"field":"db"
},
{
"type":"string",
"optional":false,
"field":"schema"
},
{
"type":"string",
"optional":false,
"field":"table"
},
{
"type":"int64",
"optional":true,
"field":"txId"
},
{
"type":"int64",
"optional":true,
"field":"lsn"
},
{
"type":"int64",
"optional":true,
"field":"xmin"
}
],
"optional":false,
"name":"io.debezium.connector.postgresql.Source",
"field":"source"
},
{
"type":"string",
"optional":false,
"field":"op"
},
{
"type":"int64",
"optional":true,
"field":"ts_ms"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"id"
},
{
"type":"int64",
"optional":false,
"field":"total_order"
},
{
"type":"int64",
"optional":false,
"field":"data_collection_order"
}
],
"optional":true,
"field":"transaction"
}
],
"optional":false,
"name":"data.cdc.dbname.Envelope"
},
"payload":{
"before":null,
"after":{
"id":1005,
"first_name":"foo",
"last_name":"bar",
"email":"foo@bar.com"
},
"source":{
"version":"1.2.3.Final",
"connector":"postgresql",
"name":"dbserver1",
"ts_ms":1600374991648,
"snapshot":"false",
"db":"postgres",
"schema":"public",
"table":"customers",
"txId":602,
"lsn":34088472,
"xmin":null
},
"op":"c",
"ts_ms":1600374991762,
"transaction":null
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
}
],
"optional":false,
"name":"data.cdc.dbname.Key"
},
"payload":{
"id":1005
}
}{
"schema":{
"type":"struct",
"fields":[
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"before"
},
{
"type":"struct",
"fields":[
{
"type":"int32",
"optional":false,
"field":"id"
},
{
"type":"string",
"optional":false,
"field":"first_name"
},
{
"type":"string",
"optional":false,
"field":"last_name"
},
{
"type":"string",
"optional":false,
"field":"email"
}
],
"optional":true,
"name":"data.cdc.dbname.Value",
"field":"after"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"version"
},
{
"type":"string",
"optional":false,
"field":"connector"
},
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"int64",
"optional":false,
"field":"ts_ms"
},
{
"type":"string",
"optional":true,
"name":"io.debezium.data.Enum",
"version":1,
"parameters":{
"allowed":"true,last,false"
},
"default":"false",
"field":"snapshot"
},
{
"type":"string",
"optional":false,
"field":"db"
},
{
"type":"string",
"optional":false,
"field":"schema"
},
{
"type":"string",
"optional":false,
"field":"table"
},
{
"type":"int64",
"optional":true,
"field":"txId"
},
{
"type":"int64",
"optional":true,
"field":"lsn"
},
{
"type":"int64",
"optional":true,
"field":"xmin"
}
],
"optional":false,
"name":"io.debezium.connector.postgresql.Source",
"field":"source"
},
{
"type":"string",
"optional":false,
"field":"op"
},
{
"type":"int64",
"optional":true,
"field":"ts_ms"
},
{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"id"
},
{
"type":"int64",
"optional":false,
"field":"total_order"
},
{
"type":"int64",
"optional":false,
"field":"data_collection_order"
}
],
"optional":true,
"field":"transaction"
}
],
"optional":false,
"name":"data.cdc.dbname.Envelope"
},
"payload":{
"before":{
"id":1005,
"first_name":"foo",
"last_name":"bar",
"email":"foo@bar.com"
},
"after":{
"id":1005,
"first_name":"egg",
"last_name":"bar",
"email":"foo@bar.com"
},
"source":{
"version":"1.2.3.Final",
"connector":"postgresql",
"name":"dbserver1",
"ts_ms":1600375609365,
"snapshot":"false",
"db":"postgres",
"schema":"public",
"table":"customers",
"txId":603,
"lsn":34089688,
"xmin":null
},
"op":"u",
"ts_ms":1600375609778,
"transaction":null
}
}
INSERT: väärtus enne (before) on võrreldav null, ja pärast on rida, mis on lisatud. KUUDA: payload.before kuvatakse rea eelmine seisund, samas kui payload.after on uus koos muudatuste sisuga.2.2 MongoDB
{
"name": "mp-k8s-mongo-connector",
"config": {
"connector.class": "io.debezium.connector.mongodb.MongoDbConnector",
"tasks.max": "1",
"mongodb.hosts": "MainRepSet/mongo:27017",
"mongodb.name": "mongo",
"mongodb.user": "debezium",
"mongodb.password": "dbname",
"database.whitelist": "db_1,db_2",
"transforms": "AddPrefix",
"transforms.AddPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.AddPrefix.regex": "mongo.([a-zA-Z_0-9]*).([a-zA-Z_0-9]*)",
"transforms.AddPrefix.replacement": "data.cdc.mongo_$1"
}
}muundamised Seekord tehakse järgmist: sihtteema nimi muudetakse skeemiks .. ühes data.cdc.mongo_.Katastroofitaluvus
Kokkuvõte
P.S.
