

See artikkel on kirjutatud selleks, et aidata valida sobiv lahendus ning mõista erinevusi selliste SDS-ide nagu Gluster, Ceph ja Vstorage (Virtuozzo) vahel.
Tekstis on viidatud artiklitele, kus on põhjalikumalt käsitletud teatud probleeme, seetõttu on kirjeldused võimalikult lühikesed, kasutades suhteliselt olulisi punkte ilma liialdava ja sissejuhatava infota, mida soovides saate ise internetist leida.
Tõepoolest, puudutatud teemad vajavad teatud tooni, kuid tänapäeva maailmas ei armasta inimesed enam lugeda))), seega võib kiiresti üle vaadata ja valiku teha, ning kui midagi on arusaamatu, siis minna linkide kaudu või guugeldada arusaamatuid sõnu))), ning see artikkel on nagu läbipaistev pakk, mis tutvustab neid sügavaid teemasid, näidates sisu – iga lahenduse peamised võtmehetked.
Gluster
Alustame Glusteriga, mida kasutatakse aktiivselt hüperkonvergenteplatvormide tootjate seas open source-iga SDS-i virtuaalsete keskkondade jaoks ja mida saab leida RedHat'i veebisaidilt salvestuse jaotises, kus pakutakse valida kahe SDS-i vahel: Gluster või Ceph.
Gluster koosneb tõlgete kuhjast – teenustest, mis teevad kogu faili jaotamise jne. Brick on teenus, mis haldab ühte ketast, Volume on konteiner, mis ühendab need brick'id. Järgneb failijagamise teenus rühmade vahel DHT (jaotatud räsi tabeli) funktsiooniga. Sharding teenuse kirjelduse hulka ei võeta, kuna allpool esitatud linkides on probleemid, mis sellega seonduvad.
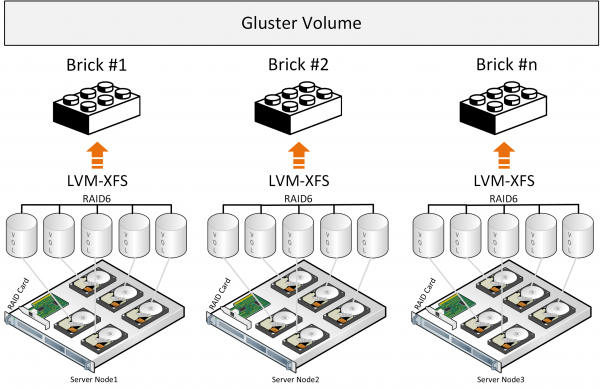
Faili kirjutamisel asetatakse see täielikult brick'ile ja selle koopia kirjutatakse paralleelselt teisele brick'ile teises serveris. Seejärel kirjutatakse teine fail teise brick'ide rühma (või rohkem) erinevatesse serveritesse.
Kui failid on enam-vähem ühesuguse suurusega ja konteiner koosneb ainult ühest rühmast, siis on kõik korras, kuid muudel tingimustel tekivad järgmised probleemid:
- rühmades ruumi kasutamine ei ole ühtlane, see sõltub failide suurustest ja kui rühmas ei ole piisavalt ruumi faili kirjutamiseks — saate vea, fail ei salvestata ja ei jaotata teise rühma;
- ühe faili kirjutamisel IO toimub ainult ühes rühmas, ülejäänud seisavad idle.
- ühte faili kirjutades ei saa kogu mahu IO-d kätte;
- ja üldine kontseptsioon näeb välja vähem efektiivne andmete blokeerimise jaotamise puudumise tõttu, kus on lihtsam tasakaalu saavutada ja lahendada ühtlase jaotuse probleem, kui praegu fail lendab täielikult bitti.
Ametlikust kirjeldusest tuleb ka tahtmatult arusaam, et gluster töötab failide salvestamiseks traditsioonilise riistvararaidi kohal. On olnud katseid failide jagamiseks blokksüsteemideks (Sharding), kuid kõik see on täiendav, mis toob kaasa jõudluse kaotuse juba olemasolevale arhitektuurilisele lähenemisele, pluss vaba aluskomponendi nagu Fuse kasutamine jõudluse piiranguga. Ei ole metaandmete teenuseid, mis piirab salvestusvõimekust jõudluse ja talitlushäiretõrje võimalustega, failide blokeerimise jaotamise puhul. Paremaid jõudluse näitajaid saab täheldada 'Distributed Replicated' konfiguratsioonis, kus nodide arv peab olema vähemalt 6, et luua usaldusväärne 3 replika koos optimaalse koormuse jaotusega.
Needused järeldused on seotud kasutuskogemuse kirjeldusega ning võrdlusega , samuti on olemas kirjeldus arusaamast selle tootlikuma ja usaldusväärsema konfiguratsiooni kohta
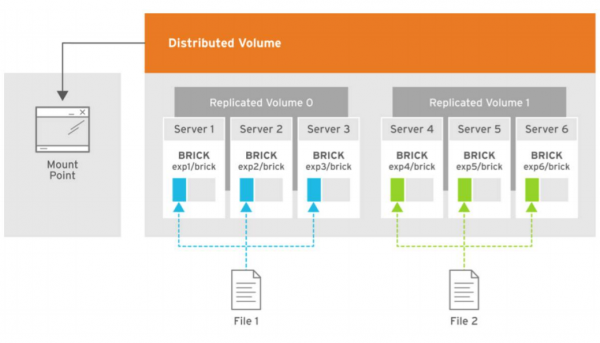
Pildil on näidatud koormuse jaotust kahe faili salvestamisel, kus esimese faili koopiad jagatakse kolmele esimesest serverist koosnevale grupile volume 0 ning kolm koopiat teisest failist asetatakse teise grupi volume1 kolme serveri peale. Igal serveril on üks ketas.
Üldine järeldus on, et Glusterit saab kasutada, kuid tuleb mõista, et tootlikkus ja tõrkevastupidavus on piiratud, mis tekitab teatud tingimustes hübriidses lahenduses raskusi, kus ressursse on vaja ka virtuaalkeskkondade arvutuskoormuste jaoks.
Samuti on mõned Glusteri tootlikkuse näitajad, mida saab saavutada teatud tingimustes, piirates
Ceph
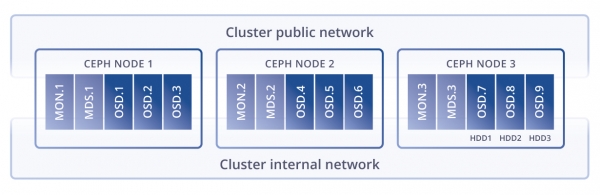
Nüüd vaatame Cephi arhitektuuri kirjeldusi, mida mul õnnestus Samuti on olemas võrdlus , kus on kohe selge, et Ceph'i on soovitatav installida eraldi serveritele, kuna selle teenused vajavad koormuse korral kogu riistvara ressursse.
Arhitektuur on keerulisem kui Gluster ning seal on sellised teenused, nagu metaandmete teenused, kuid kogu komponentide virn on üsna keeruline ja mitte väga paindlik virtuaalisüsteemi lahenduste jaoks. Andmed jaotatakse plokkideks, mis näib olevat tõhusam, kuid kogu teenuste (komponentide) hierarhias on teatud koormuste ja hädaseisundite korral kaotusi ja latentsus, nagu näiteks järgmine.
Arhitektuuri kirjeldusest tuleneb, et südameks on CRUSH, mis valib andmete paigutamise koha. Järgmine on PG — kõige keerulisem abstraktsioon (loogiline grupp), mida on raske mõista. PG on vajalikud, et CRUSH oleks tõhusam. PG peamine eesmärk on objektide gruppeerimine ressursi tarbimise vähendamiseks, tootlikkuse ja skaleeritavuse suurendamiseks. Objektide otsene aadressimine eraldi, ilma nende PG-sse ühendamata, oleks väga kulukas. OSD on teenus iga eraldi ketta jaoks.
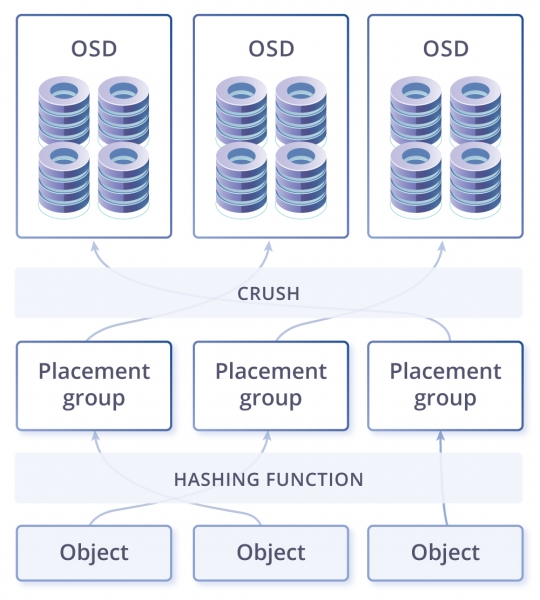
Klastril võib olla üks või mitu andmebaasi erinevate eesmärkide ja erinevate seadistustega. Andmebaasid jagunevad olemasolu gruppidesse. Ol存在グループides säilitatakse objekte, millele kliendid pääsevad ligi. Sellega lõppeb loogiline tase ja algab füüsiline, kuna iga olemasolu grupiga on seotud üks peamine ketas ja mitmed replikad (kui palju täpselt sõltub andmebaasi replikatsiooni tegurist). Teisisõnu, loogilisel tasemel on objekt konkreetses olemasolu grupis, kuid füüsilisel tasemel asub see ketastel, mis on selle grupiga seotud. Seejuures võivad kettad füüsiliselt asuda erinevates sõlmedes või isegi erinevates andmekeskustes.
Selles skeemis näevad grupi paigutused välja kui vajalik tase kogu lahenduse paindlikkuseks, kuid samal ajal kui liigsed elemendid ahelas, mis tekitavad mõtteid jõudluse kadumisest. Näiteks andmete salvestamisel peab süsteem jagama need gruppidesse ja seejärel füüsilisel tasandil peamisele ketta ja replikatsioonikettale. Seega töötab hash-funktsioon objekti otsimise ja lisamise juures, kuid on kõrvalmõju – äärmiselt suured kulutused ja piirangud hash'i rekonstrueerimisele (ketta lisamisel või eemaldamisel). Veel üks hash'i probleem onandmete kindel asukoht, mida ei saa muuta. Kui mõni ketas kogeb suuremat koormust, ei ole süsteemil võimalust mitte kirjutada sellele diskile (valides teise ketta), kuna hash-funktsioon nõuab andmete paigutamist reegli järgi, olenemata sellest, kui halb on ketas, mistõttu Ceph vajab palju mälu PG rekonstrueerimisel isetervenemise või salvestusruumi suurenemise korral. Järeldus on see, et Ceph töötab hästi (kuigi aeglaselt), kuid ainult siis, kui ei toimu skaleerimist, katastroofiolukordi ega uuendusi.
Muidugi on olemas võimalusi jõudluse suurendamiseks, kasutades vahemälu ja vahemälu kihistamist, kuid selleks on vajalik hea riistvara ja siiski on olemas kaotused. Kuid üldiselt tundub Ceph olevat atraktiivsem kui Gluster tootlikkuse osas. Samuti on nende toodete kasutamisel oluline arvesse võtta, et vajalik on kõrge kompetentsitaseme, kogemuse ja professionaalsuse tase, eriti Linuxi valdkonnas, kuna on väga oluline kõik õigesti üles seada, konfigureerida ja hallata, mis suurendab veelgi halduri vastutust ja koormust.
Vstorage
Veelgi huvitavam on arhitektuur , mida saab kasutada koos hüperviisoriga samadel sõlmedel, samal , kuid on väga oluline kõik õigesti konfigureerida, et saavutada hea jõudlus. See tähendab, et sellise toote üles seadmine mis tahes konfigureerimisel ilma arhitektuuri soovitusi arvesse võtmata on väga lihtne, kuid mitte efektiivne.
Millised teenused võivad koos eksisteerida koos KVM-QEMU hüperviisoriga? See on vaid mõned teenused, kus leidub kompaktselt optimaalne komponentide hierarhia: klienditeenus, mis monteeritakse läbi FUSE (muudetud, mitte avatud lähtekoodiga), metateenuste teenus MDS, andmeplokkide teenus Chunk service, mis füüsilisel tasandil vastab ühele kettale. Kiirus on loomulikult parim kasutada talitluskindlat skeemi kahe replikaga, kuid kui kasutusele võtta vahemälu ja SSD kettale kirjutamise logid, siis segapöördetehnoloogia (erase coding või RAID 6) võib märkimisväärselt kiireneda hübriidskeemil või isegi paremini täielikult flash-plaadil. Erasekoodimisega (EC) on teatud puudus: ühe andmeploki muutmisel tuleb uuesti arvutada pariteetsummad. Kaotuste vältimiseks selle protsessi puhul kirjutab Ceph EC osaliselt ja teatud päringute korral võivad tekkida jõudluse probleemid, kui on näiteks vajalikud kõikide plokkide lugemine. Virtuozzo Storage puhul saavutatakse muudetud plokkide kirjutamine lähenemisega „log-structured file system”, mis minimeerib pariteedi arvutamisest tingitud kulusid. Et hinnata EC-ga ja ilma EC-ta töökiirusvõimalusi, on olemas. – numbrid võivad olla ligikaudsed ja sõltuvad seadme tootja täpsuskoefitsiendist, kuid arvutuste tulemus aitab hästi planeerida konfiguratsiooni.
Lihtne salvestuskomponentide skeem ei tähenda, et need komponendid ei sööks aga kui kõik kulud eelnevalt arvutada, siis võib loota sujuvale koostööle hüperviisori kõrval.
Seal on võrreldav skeem rauaressursside tarbimisest teenuste Ceph ja Virtuozzo storage vahel.
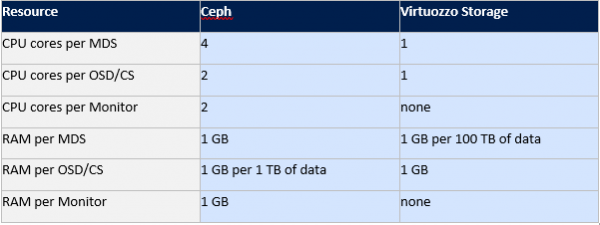
Kui varem sai Glusterit ja Cephi võrrelda vanade artiklite põhjal, kasutades neist kõige tähtsamaid ridasid, siis Virtuozzo on keerulisem. Selle toote kohta pole palju artikleid ja teavet saab tõmmata ainult dokumentatsioonist või vene keeles, kui arvestada Vstorage'it ladustamisena, mida kasutatakse mõnedes hüperkonvergeeritud lahendustes sellistes ettevõtetes nagu ja Acronis.
Püüan aidata selle arhitektuuri kirjeldamisel, seetõttu on tekst veidi pikem. Dokumentatsioonist arusaamiseks on aga vaja palju aega, ning olemasolevat dokumentatsiooni saab kasutada ainult abivahendina, sirvides sisukorda või otsides märksõna järgi.
Vaadakem hübriidse riistvarakonfiguratsiooni salvestamisprotsessi koos ülaltoodud komponentidega: salvestamine algab sellest sõlmest, kust klient selle algatas (FUSE monteerimispunkti teenus), kuid meistriteenuse metateenuste (MDS) komponent suunab siiski kliendi otse vajalikku ploki teenusesse (CS salvestusteenus), mis tähendab, et MDS ei osale salvestamisprotsessis, vaid suunab lihtsalt vajalikku ploki teenusesse. Üldiselt võib salvestamisprotsessi võrrelda veekraanide mahutitega valamisega — iga mahuti on 256MB suurune andmeplokk.
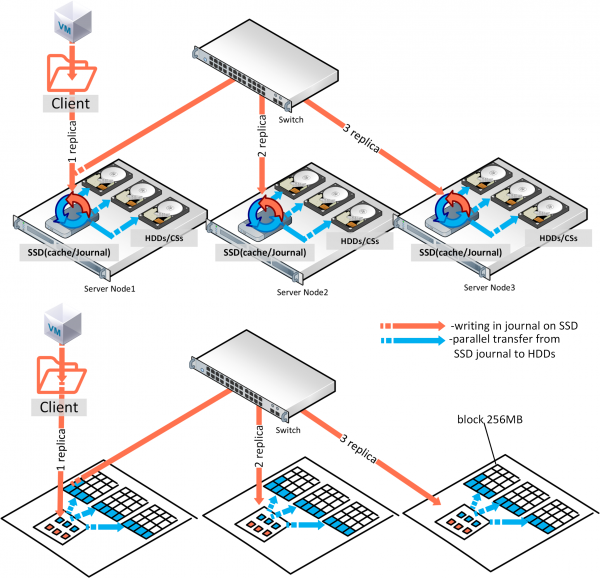
Seega, üks ketas on teatud arv selliseid barreleid, see tähendab, et ketta maht jagatakse 256 MB-ga. Iga koopiat jaotatakse ühele sõlmele, teise peaaegu samal ajal juba teisele sõlmele jne… Kui meil on kolm koopiat ja SSD kettad vahemäluks (lugemiseks ja kirjutamislogideks), siis kirjutamise kinnitus toimub pärast logi salvestamist SSD-le, samas kui paralleelne ülekandmine SSD-lt jätkub HDD-le, justkui taustal. Kolm koopiat sisaldava olukorra korral toimub kirjutamise kinnitus pärast kolmanda sõlme SSD-lt kinnituse saamist. Võib tunduda, et kolme SSD kirjutamiskiirus jaguneb kolme peale ja saame ühe koopia kirjutamiskiiruse, kuid koopiate kirjutamine toimub paralleelselt ja võrgu latentsus on tavaliselt kõrgem kui SSD-l, seega sõltub tegelik kirjutamise jõudlus võrgust. Seetõttu, et näha reaalseid IOPS-e, tuleb kogu Vstorage õigesti koormata , see tähendab, et tuleb testida tegelikku koormust, mitte mälu ja vahemälu, kus tuleb arvestada õiget andmepaketi suurust, voogude arvu jne.
Ülaltoodud SSD logi töötab nii, et andmed, kui need sinna satuvad, loetakse kohe teenuse poolt ja kirjutatakse HDD-le. Klusteris on mitu metainformatsiooni teenust (MDS) ja nende arv määratakse kvoorumiga, mis töötab Paxose algoritmi alusel. Klientide vaatenurgast on FUSE'i montaažikoht klusteri salvestust sisaldav kaust, mis on kõikidele klusterinõlmadele nähtav. Igal nõlval on sellise põhimõtte järgi monteeritud klient, mistõttu on sellele salvestusele juurdepääs igal sõlmel.
Mis tahes ülaltoodud lähenemise efektiivsuse tagamiseks on planeerimise ja juurutamise etapis ülioluline õigesti seadistada võrk, kus toimib tasakaalustus agregatsiooni kaudu ja õigesti valitud võrguühenduse läbilaskevõime. Agregatsioonis on tähtis valida õige hashing-režiim ja raamide suurused. Lisaks on oluline erinevus ülaltoodud SDS-de vahel fuse, mis kasutab Virtuozzo Storage'i kiirete radade tehnoloogiat. See annab, erinevalt teistest avatud lähtekoodiga lahendustest, tunduvalt rohkem IOPS-e ning ei piirdu ainult horisontaalse või vertikaalse skaleerimisega. Kokkuvõttes näib see arhitektuur võrreldes eelmainituga olevat võimsam, kuid sellise teenuse eest on loomulikult vajalik litsentside soetamine, erinevalt Cephist ja Glusterist.
Kokkuvõttes võib välja tuua kolme peamise: esimese koha efektiivsuse ja usaldusväärsuse osas hõivab Virtuozzo Storage, teise Ceph ja kolmanda Gluster.
Kriteeriumid, mille järgi valiti Virtuozzo Storage: see on optimaalne komponentide komplekt, mis on moderniseeritud Fuse'i lähenemisviisi järgi koos fast path'iga, paindlik riistvara konfiguratsioon, madalamate ressursikasutustega ja võimalusega jagada arvutuste/virtualiseerimisega, see tähendab, et see sobib täielikult hüperkonvergentsse lahendusse, mille osana see tuleb. Teisel kohal on Ceph, kuna see on Glusterist tootlikum arhitektuur, töötades plokkide põhjal, samuti pakkudes paindlikumaid stsenaariume ja võimalust töötada suuremates klastrites.
Plaanides on soov kirjutada võrdlus vSANi, Space Direct Storage'i, Vstorage'i ja Nutanix Storage'i vahel, testides Vstorage'i HPE ja Huawei seadmete peal, samuti Vstorage'i integreerimise stsenaariume väliste riistvarade SCSI-dega. Seega, kui artikkel teile meeldis, oleks tore saada teie tagasisidet, mis võiks tugevdada motivatsiooni uute artiklite kirjutamiseks, arvestades teie märkusi ja soove.
Allikas: habr.com
