

Data Science для начинающих
1. Sentiment Analysis (Анализ настроений через текст)

Посмотрите полную реализацию проекта Data Science с использованием исходного кода — .
Sentiment Analysis — это анализ слов для определения настроений и мнений, которые могут быть положительными или отрицательными. Это тип классификации, при котором классы могут быть двоичными (положительными и отрицательными) или множественными (счастливыми, злыми, грустными, противными …). Мы реализуем этот Data Science проект на языке R и будем использовать набор данных в пакете «janeaustenR». Мы будем использовать словари общего назначения, такие как AFINN, bing и loughran, выполнять внутреннее соединение, и в конце мы создадим облако слов, чтобы отобразить результат.
Язык: R
Набор данных/Пакет: janeaustenR
Artikkel on tõlgitud EDISON Software'i toetusel, kes , samuti .
2. Fake News Detection (Обнаружение фейковых новостей)
Поднимите свои навыки на новый уровень, работая над проектом Data Science для начинающих — .
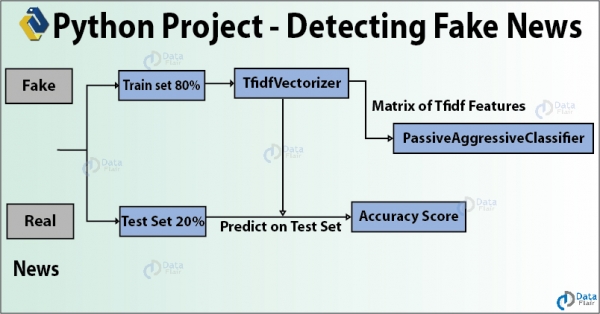
Фальшивые новости — это ложная информация, распространяемая через социальные сети и другие сетевые СМИ для достижения политических целей. В этой идее проекта по Data Science мы будем использовать Python для построения модели, которая может точно определять, является ли новость реальной или фальшивой. Мы создадим TfidfVectorizer и используем PassiveAggressiveClassifier для классификации новостей на «реальные» и «поддельные». Мы будем использовать набор данных формы 7796 × 4 и выполнять все в Jupyter Lab.
Язык: Python
Набор данных/Пакет: news.csv
3. Detecting Parkinson’s Disease (Обнаружение болезни Паркинсона)
Продвигайтесь вперед, работая над идеей проекта Data Science Project Idea — .
Мы начали использовать Data Science для улучшения здравоохранения и услуг — если мы можем предсказать заболевание на ранней стадии, то у нас будет много преимуществ. Итак, в этой идее проекта по Data Science мы научимся выявлять болезнь Паркинсона с помощью Python. Это нейродегенеративное, прогрессирующее заболевание центральной нервной системы, которое влияет на движение и вызывает дрожь и скованность. Это влияет на продуцирующие дофамин нейроны в головном мозге, и каждый год, это затрагивает более 1 миллиона человек в Индии.
Язык: Python
Набор данных/Пакет: UCI ML Parkinsons dataset
Data Science проекты средней сложности
4. Speech Emotion Recognition(Распознавание эмоции из речи)
Ознакомьтесь с полной реализацией примера проекта Data Science — .
Давайте теперь научимся использовать разные библиотеки. Этот Data Science проект использует librosa для распознавания речи. SER — это процесс определения человеческих эмоций и аффективных состояний по речи. Поскольку мы используем тон и высоту тона для выражения эмоций голосом, SER актуален. Но так как эмоции субъективны, аннотирование звука является сложной задачей. Мы будем использовать функции mfcc, chroma и mel и использовать набор данных RAVDESS для распознавания эмоций. Мы создадим MLPC-классификатор для этой модели.
Язык: Python
Набор данных/Пакет: RAVDESS dataset
5. Gender and Age Detection (Обнаружение пола и возраста)
Поразите работодателей с помощью новейшего проекта Data Science — .
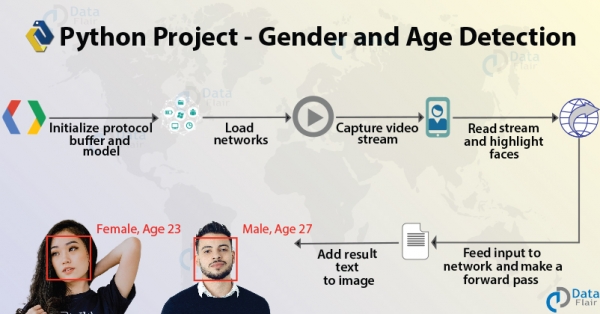
Это интересный Data Science с Python. Используя только одно изображение, вы научитесь предсказывать пол и возраст человека. В этом мы познакомим вас с Computer Vision и его принципами. Мы построим и будем использовать модели, обученные Талом Хасснером и Джилом Леви для набора данных Adience. По пути мы будем использовать некоторые файлы .pb, .pbtxt, .prototxt и .caffemodel.
Язык: Python
Набор данных/Пакет: Adience
6. Uber Data Analysis (Анализ данных Uber)
Посмотрите полную реализацию проекта Data Science с исходным кодом — .
Это проект визуализации данных с ggplot2, в котором мы будем использовать R и его библиотеки и анализировать различные параметры. Мы будем использовать набор данных Uber Pickups в Нью-Йорке и создавать визуализации для различных временных рамок года. Это говорит нам о том, как время влияет на поездки клиентов.
Язык: R
Набор данных/Пакет: Uber Pickups in New York City dataset
7. Driver Drowsiness detection (Обнаружение сонливости водителя)
Прокачайте свои навыки, работая над Top Data Science Project — .
Сонное вождение чрезвычайно опасно, и каждый год происходит около тысячи аварий из-за того, что водители засыпают во время вождения. В этом проекте на Python мы создадим систему, которая сможет обнаруживать сонных водителей, а также оповещать их звуковым сигналом.
Этот проект реализован с использованием Keras и OpenCV. Мы будем использовать OpenCV для обнаружения лица и глаз, а с помощью Keras мы будем классифицировать состояние глаза (Открытое или Закрытое) с использованием методов глубокой нейронной сети.
8. Chatbot
Создайте чат-бота с помощью Python и сделайте шаг вперед в своей карьере — .

Чат-боты являются неотъемлемой частью бизнеса. Многим предприятиям приходится предлагать услуги своим клиентам, и для их обслуживания требуется много рабочей силы, времени и усилий. Чат-боты могут автоматизировать большую часть взаимодействия с клиентами, отвечая на некоторые частые вопросы, которые задают клиенты. В основном есть два типа чат-ботов: Domain-specific и Open-domain. Domain-specific чат-бот часто используется для решения конкретной проблемы. Таким образом, вам нужно настроить его для эффективной работы в вашей сфере. Open-domain чат-ботам можно задавать любые вопросы, поэтому для их обучения требуется огромное количество данных.
Набор данных: Intents json file
Язык: Python
Продвинутые Data Science проекты
9. Image Caption Generator(Генератор описания изображения)
Проверьте полную реализацию проекта с исходным кодом — .

Описание того, что есть на изображении, является легкой задачей для людей, но для компьютеров, изображение — это просто набор цифр, которые представляют собой значение цвета каждого пикселя. Это трудная задача для компьютеров. Понять, что находится в изображении, а затем создать описание на естественном языке(например, на английском), является другой трудной задачей. Этот проект использует методы глубокого изучения, в которых мы реализуем Конволюционную нейронную сеть (CNN) с рекуррентной нейронной сетью (LSTM) для создания генератора описания изображения.
Набор данных: Flickr 8K
Язык: Python
Фреймворк: Keras
10. Credit Card Fraud Detection(Определение мошенничества с кредитными картами)
Сделайте все возможное, работая над идеей проекта Data Science — .
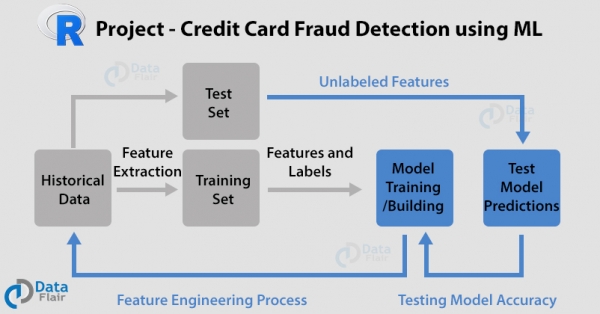
К настоящему времени вы начали понимать методы и концепции. Давайте перейдем к некоторым продвинутым проектам в области науки о данных. В этом проекте мы будем использовать язык R с такими алгоритмами, как , логистическая регрессия, искусственные нейронные сети и классификатор градиентного бустинга. Мы будем использовать набор данных операций с картами, чтобы классифицировать транзакции по кредитным картам как мошеннические и подлинные. Мы подберем для них разные модели и построим кривые производительности.
Язык: R
Набор данных/Пакет: Card Transactions dataset
11. Movie Recommendation System(Cистема рекомендаций по фильмам)
Изучите реализацию лучшего Data Science проекта с Исходным кодом —
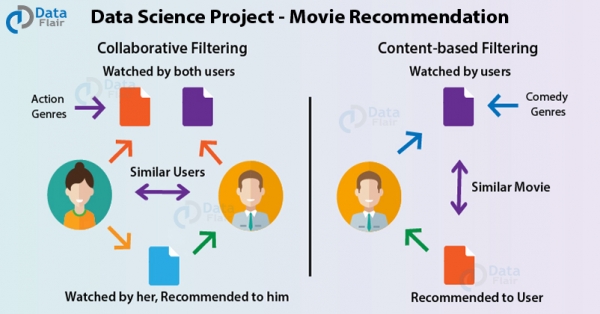
В этом Data Science проекте мы будем использовать R, чтобы выполнить рекомендации фильма посредством машинного обучения. Система рекомендаций рассылает предложения пользователям через процесс фильтрации, основанный на предпочтениях других пользователей и истории просмотров. Если A и B нравится Home Alone, а B любит Mean Girls, то можно предложить A — им это тоже может понравиться. Это позволяет клиентам взаимодействовать с платформой.
Язык: R
Набор данных/Пакет: MovieLens dataset
12. Customer Segmentation(Сегментация покупателей)
Произведите впечатление на работодателей с помощью Data Science проекта (включая исходный код) — .
Сегментация покупателей является популярным приложением . Используя кластеризацию, компании определяют сегменты клиентов для работы с потенциальной базой пользователей. Они делят клиентов на группы в соответствии с общими характеристиками, такими как пол, возраст, интересы и привычки расходования средств, чтобы они могли эффективно продавать свою продукцию каждой группе. Мы будем использовать , а также визуализировать распределение по полу и возрасту. Затем мы проанализируем их годовые доходы и уровень расходов.
Язык: R
Набор данных/Пакет: Mall_Customers dataset
13. Breast Cancer Classification (Классификация рака молочной железы)
Посмотрите полную реализацию проекта Data Science в Python — .

Возвращаясь к медицинскому вкладу науки данных, давайте научимся выявлять рак молочной железы с помощью Python. Мы будем использовать набор данных IDC_regular для выявления инвазивной карциномы протоки, наиболее распространенной формы рака молочной железы. Он развивается в молочных протоках, проникающем в волокнистую или жирную ткань молочной железы снаружи протока. В этой идее научного проекта по сбору данных мы будем использовать и библиотеку Keras для классификации.
Язык: Python
Набор данных/Пакет: IDC_regular
14. Traffic Signs Recognition (Распознавание дорожных знаков)
Достижение точности в технологии самостоятельного вождения автомобиля с помощью проекта Data Science по с открытым исходным кодом.

Дорожные знаки и правила дорожного движения очень важны для каждого водителя, чтобы избежать несчастных случаев. Чтобы следовать правилу, сначала нужно понять, как выглядит дорожный знак. Человек должен выучить все дорожные знаки, прежде чем ему дадут права на управление любым транспортным средством. Но сейчас количество автономных транспортных средств растет, и в ближайшем будущем человек уже не будет самостоятельно управлять машиной. В проекте «Распознавание дорожных знаков» вы узнаете, как программа может распознать тип дорожных знаков, принимая изображение в качестве входного сигнала. Набор контрольных данных распознавания дорожных знаков Германии (GTSRB) используется для построения глубокой нейронной сети для распознавания класса, к которому относится дорожный знак. Мы также создаем простой графический интерфейс для взаимодействия с приложением.
Язык: Python
Набор данных: GTSRB (German Traffic Sign Recognition Benchmark)
Loe veel
Allikas: habr.com
