

Hea vanamoodne peitusemäng võib olla tehisintellekti (AI) robotitele suurepäraseks proovikiviks, et demonstreerida, kuidas nad otsuseid langetavad ning üksteise ja erinevate ümbritsevate objektidega suhtlevad.
oma , mille avaldasid kuulsaks saanud mittetulundusliku tehisintellekti uurimisorganisatsiooni OpenAI teadlased arvutimängus Dota 2 kirjeldavad teadlased, kuidas tehisintellekti juhitud agente treeniti virtuaalses keskkonnas üksteise eest otsides ja peitudes keerukamaks. Uuringu tulemused näitasid, et kahest robotist koosnev meeskond õpib tõhusamalt ja kiiremini kui ükski liitlasteta agent.

Teadlased on kasutanud meetodit, mis on juba ammu oma kuulsuse võitnud , milles tehisintellekt on paigutatud talle tundmatusse keskkonda, omades samal ajal teatud viise sellega suhtlemiseks, samuti preemiate ja trahvide süsteem oma tegevuse ühe või teise tulemuse eest. See meetod on üsna tõhus tänu tehisintellekti võimele sooritada erinevaid toiminguid virtuaalses keskkonnas tohutu kiirusega, miljoneid kordi kiiremini, kui inimene ette kujutab. See võimaldab katse-eksituse meetodil leida antud probleemi lahendamiseks kõige tõhusamad strateegiad. Kuid sellel lähenemisel on ka mõningaid piiranguid, näiteks keskkonna loomine ja arvukate treeningtsüklite läbiviimine nõuab tohutuid arvutusressursse ning protsess ise nõuab täpset süsteemi AI toimingute tulemuste võrdlemiseks eesmärgiga. Lisaks piirduvad agendi sellisel viisil omandatud oskused kirjeldatud ülesandega ja kui tehisintellekt õpib sellega toime tulema, ei toimu enam edasisi parandusi.
Tehisintellekti õpetamiseks peitust mängima kasutasid teadlased lähenemisviisi, mida nimetatakse suunamata uurimiseks, mis tähendab, et agentidel on täielik vabadus arendada oma arusaama mängumaailmast ja töötada välja võidustrateegiaid. See sarnaneb mitme agentuuriga õppimise lähenemisviisiga, mida DeepMindi teadlased kasutasid mitme tehisintellekti süsteemi puhul . Nagu antud juhul, ei olnud AI-agendid varem mängureeglite osas koolitatud, kuid aja jooksul õppisid nad põhistrateegiaid ja suutsid teadlasi üllatada isegi mittetriviaalsete lahendustega.
Peitusemängus pidid mitmed agenti, kelle ülesanne oli varjata, vältima vastaste vaatevälja pärast kerget eduseisu, kui otsivate agentide meeskond oli liikumatuks jäänud. Veelgi enam, "vaatejoon" on selles kontekstis 135-kraadine koonus üksiku roboti ees. Agendid ei saanud mängualast liiga kaugele välja seigelda ja olid sunnitud liikuma juhuslikult loodud ruumides, kus oli võimalik kasutada laiali hajutatud väliseid objekte (kastid, teisaldatavad seinad, spetsiaalsed kaldteed), mida saaks kasutada nii katte loomiseks kui ka nendesse imbumiseks. .
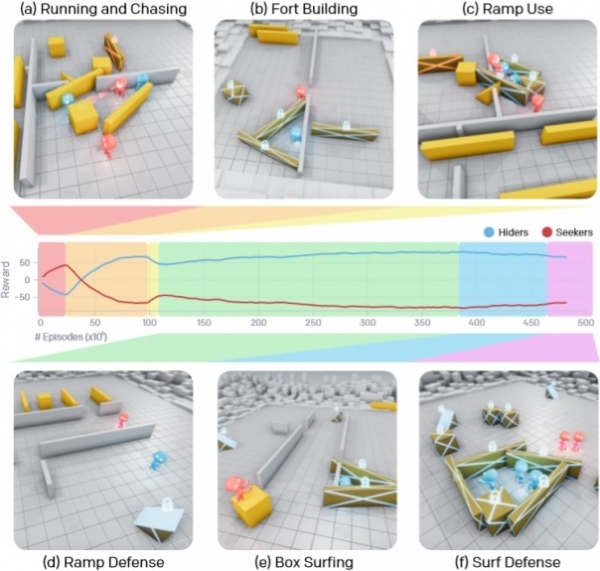
Pika õppeprotsessi käigus õppisid AI-agendid kuus ainulaadset strateegiat, millest igaüks aitas neil mängu järgmisse etappi jõuda. Algul otsijad ja peitjameeskonnad lihtsalt jooksid minema ja ajasid üksteist taga, kuid umbes 25 miljoni matši järel õppis peitjameeskond kastidega läbipääsud blokeerima ja nendest varjualuseid ehitama. Pärast veel 75 miljonit matši avastas meeskond viise, kuidas nendesse peidupaikadesse pääsemiseks kasutada kaldteid. Veel 10 miljoni ringi järel õppisid peitjad kaldteed mänguala servale lohistama ja oma kohale lukustama, et vastased ei saaks neid kasutada.

Pärast 388 miljonit matši on otsijad õppinud kasutama blokeeritud kaldteid, et ronida neile toodud kastidele ja seejärel otse neile liikudes tungida kaasaskantavatest seintest loodud vaenlase peidupaikadesse. Ja lõpuks, pärast 458 miljonit matši, jõudis peidumeeskond järeldusele, et nad peavad blokeerima kõik objektid ja seejärel ehitama varjualuse, mis ilmselt viis nende lõpliku võiduni.
Eriti muljetavaldav on see, et pärast 22 miljonit matši õppisid agendid oma tegevust koordineerima ja nende koostöö tõhusus ainult kasvas tulevikus, näiteks tõi igaüks oma kasti või seina varjualuse loomiseks ja valis oma osa esemeid. blokeerida, et muuta see vastaste jaoks keerulisemaks.

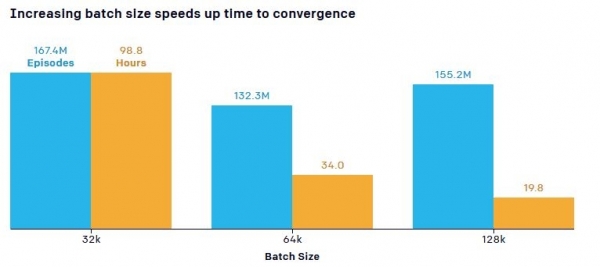
Teadlased märkisid ka olulise punkti, mis on seotud koolitusobjektide arvu (närvivõrgu kaudu edastatud andmete hulk - "Partii suurus") mõjuga õppimiskiirusele. Vaikimisi mudel nõudis 132,3 miljonit matši 34-tunnise treeningu jooksul, et jõuda punktini, kus varjav meeskond õppis rampe blokeerima, samas kui rohkem andmeid vähendas treeningu aega märgatavalt. Näiteks parameetrite (osa kogu treeningprotsessi jooksul saadud andmetest) arvu suurendamine 0,5 miljonilt 5,8 miljonile suurendas diskreetimisefektiivsust 2,2 korda ning sisendandmete suuruse suurendamine 64 KB-lt 128 KB-le vähendas treeningut. aega peaaegu poolteist korda.
Oma töö lõpus otsustasid teadlased katsetada, kui palju mängusisest koolitust võiks aidata agentidel tulla toime sarnaste ülesannetega väljaspool mängu. Teste oli kokku viis: objektide arvu teadvustamine (mõistmine, et objekt eksisteerib edasi ka siis, kui see on vaateväljast ära ja seda ei kasutata); "Lukusta ja tagasi" - võimalus oma algset asukohta meeles pidada ja pärast mõne lisaülesande täitmist selle juurde naasta; "järjestikune blokeerimine" - 4 kasti paiknesid juhuslikult kolmes usteta ruumis, kuid sissepääsuks olid kaldteed, agentidel oli vaja need kõik üles leida ja blokeerida; kastide paigutamine etteantud kohtadele; silindri kujul oleva objekti ümber varjualuse loomine.
Selle tulemusel õppisid mängus eelkoolituse läbinud robotid kolmes ülesandes viiest kiiremini ja näitasid paremaid tulemusi kui AI, mis koolitati probleeme nullist lahendama. Nad said veidi paremini hakkama ülesande täitmisel ja lähteasendisse naasmisel, kastide järjestikusel blokeerimisel suletud ruumides ja kastide paigutamisel etteantud aladele, kuid objektide arvu tuvastamisel ja teise objekti ümber katte loomisel õnnestus neil veidi nõrgem olla.
Teadlased omistavad erinevaid tulemusi sellele, kuidas tehisintellekt teatud oskusi õpib ja mäletab. "Arvame, et ülesanded, kus mängusisene eeltreening toimis kõige paremini, hõlmasid varem õpitud oskuste taaskasutamist tuttaval viisil, samas kui ülejäänud ülesannete täitmine nullist treenitud tehisintellektist paremini eeldaks nende teistsugust kasutamist, mis raskem,” kirjutavad teose kaasautorid. "See tulemus rõhutab vajadust töötada välja meetodid koolituse käigus omandatud oskuste tõhusaks taaskasutamiseks nende ühest keskkonnast teise ülekandmisel."
Tehtud töö on tõeliselt muljetavaldav, kuna selle õpetamismeetodi kasutamise võimalus on kaugel kõigist mängudest. Teadlaste sõnul on nende töö märkimisväärne samm "füüsikal põhineva" ja "inimeselaadse" käitumisega tehisintellekti loomisel, mis suudab diagnoosida haigusi, ennustada keeruliste valgumolekulide struktuure ja analüüsida CT-skaneeringuid.
Allolevast videost on selgelt näha, kuidas kogu õppeprotsess toimus, kuidas tehisintellekt meeskonnatööd õppis ning selle strateegiad muutusid järjest kavalamaks ja keerukamaks.

Allikas: 3dnews.ru
