

Artiklis käsitletakse mitmeid meetodeid lihtsa (paari) regressiooni matemaatilise võrrandi määramiseks.
Kõik siin käsitletud meetodid võrrandi lahendamiseks põhinevad vähenenud ruutude meetodil. Määratleme meetodid järgmiselt:
- Analüütiline lahendus
- Gradientne allakäik
- Stohhastiline gradientide langetamine
Iga meetodi puhul, mis lahendab sirge võrrandi, on artiklis esitatud erinevad funktsioonid, mis jagunevad peamiselt kaheks: need, mis on kirjutatud ilma raamatukogu kasutamata, NumPy ja need, mis kasutavad arvutuste tegemiseks NumPy. Arvatakse, et oskuslik kasutamine NumPy aitab vähendada arvutuskulusid.
Kõik artiklis esitatud kood on kirjutatud keeles python 2.7 kasutades Jupyter Notebook. Algne kood ja andmefail on saadaval
Artikkel on suunatud nii algajatele kui ka neile, kes on juba hakanud uurima masinõppe ulatuslikku osa, mis on osa tehisintellektist.
Kasutame materjali illustreerimiseks väga lihtsat näidet.
Näite tingimused
Meil on viis väärtust, mis iseloomustavad sõltuvust Y alates X (Tabeli nr 1):
Tabel nr 1 „Näidatingimused“

Oletame, et väärtused  — on aasta kuu ja
— on aasta kuu ja  — sissetulek selle kuu jooksul. Teisisõnu sõltub sissetulek aastakuust ning
— sissetulek selle kuu jooksul. Teisisõnu sõltub sissetulek aastakuust ning  — on ainus tunnus, millest sissetulek sõltub.
— on ainus tunnus, millest sissetulek sõltub.
Näide on üsna lihtne, nii sissetuleku sõltuvuse osas aastakuu kui ka vähe väärtuste poolest — neid on väga vähe. Kuid selline lihtsustus võimaldab, nagu öeldakse, käega katsuda selgitada, mitte alati kergesti omandatavat algajate materjali. Samuti võimaldab numbrite lihtsus ilma suurte pingutusteta soovijatel näidet „paberil“ lahendada.
Oletame, et näites toodud sõltuvust saab piisavalt hästi kirjeldada lihtsa (paarilise) regressioonijoone matemaatilise võrdusega:

kus  — on kuu, mil sissetulek saadi,
— on kuu, mil sissetulek saadi,  — sissetulek, mis vastab kuule,
— sissetulek, mis vastab kuule,  ja
ja  — regressioonikoefitsiendid hinnatud joonel.
— regressioonikoefitsiendid hinnatud joonel.
Märgitakse, et koefitsienti  tavaliselt nimetatakse hinnatud joone kallutatuse koefitsiendiks või gradientiks; see on suurus, mille võrra muutub
tavaliselt nimetatakse hinnatud joone kallutatuse koefitsiendiks või gradientiks; see on suurus, mille võrra muutub  muutmisel
muutmisel  .
.
On selge, et meie ülesanne näites on leida võrrandisse sellised koefitsiendid  ja
ja  , mille puhul meie arvutatud tulude kõrvalekalded kuude lõikes tõelistest vastustest, st valimis esitatud väärtustest, oleksid minimaalsed.
, mille puhul meie arvutatud tulude kõrvalekalded kuude lõikes tõelistest vastustest, st valimis esitatud väärtustest, oleksid minimaalsed.
Vähenenud ruutude meetod
Vähenenud ruutude meetodi kohaselt tuleks kõrvalekaldeid arvutada, tõstes need ruutu. See meetod aitab vältida vastassuunaliste kõrvalekalde suutlikkust üksteist tasakaalustada. Näiteks, kui ühes juhul on kõrvalekalle +5 (pluss viis), ja teises -5 (miinus viis), siis teatud juhul tasandavad kõrvalekalded üksteist ning kokkuvõttes annavad 0 (null). Võime mitte tõsta kõrvalekaldet ruutu, vaid kasutada mooduli omadust, et kõik kõrvalekalded oleksid positiivsed ja akumuleeruksid. Me ei peatu sellel hetkel pikemalt, vaid lihtsalt mainime, et mugavuse huvides tõstetakse kõrvalekalle tavaliselt ruutu.
Selliselt näeb välja valem, mille abil me määrame kõrvalekalde ruutude minimaalse summa (vea):

kus  — see on tõeline vastuste aproximaatsioonifunktsioon (st meie arvutatud tulu),
— see on tõeline vastuste aproximaatsioonifunktsioon (st meie arvutatud tulu),
 — need on tõelised vastused (antud valimisse kuuluv tulu),
— need on tõelised vastused (antud valimisse kuuluv tulu),
 — see on valimi indeks (kuu number, milles määratakse kõrvalekalde väärtus)
— see on valimi indeks (kuu number, milles määratakse kõrvalekalde väärtus)
Erindame funktsiooni, määratleme osade tuletiste võrrandid ja oleme valmis minema analüütilisele lahendusele. Kuid alustuseks teeme väikese ülevaate, mis on tuletamine ja meenutame tuletise geomeetrilist tähendust.
Tuletamine
Tuletamine on funktsiooni tuletise leidmise operatsioon.
Milleks on vajalik tuletis? Funktsiooni tuletis iseloomustab funktsiooni muutuva kiirus ja näitab meile selle suunda. Kui tuletis antud punktis on positiivne, siis funktsioon kasvab, vastasel juhul — funktsioon väheneb. Ja mida suurem on tuletise väärtus moodulis, seda kiiremini muutuvad funktsiooni väärtused ja järsem on funktsiooni graafiku kaldenurk.
Näiteks, dekartaalses koordinaatsüsteemis, punktis M(0,0) olev tuletise väärtus +25 tähendab, et antud punktis, kui väärtust nihutada  ühe tingimuse ühiku, väärtus
ühe tingimuse ühiku, väärtus  kasvab 25 tingimuse ühikut. Graafikul näeb see välja nagu üsna järsk väärtuste tõus
kasvab 25 tingimuse ühikut. Graafikul näeb see välja nagu üsna järsk väärtuste tõus  antud punktist.
antud punktist.
Teine näide. Tuletise väärtus, mis on võrdne -0,1 tähendab, et nihke korral  ühe tingimuse ühiku, väärtus
ühe tingimuse ühiku, väärtus  väheneb vaid 0,1 tingimuse ühiku võrra. Sel juhul saame funktsiooni graafikul märgata pea märkamatut allapoole kallutatust. Kui joonistada metafoorina mäge, siis justkui laskume aeglaselt madalalt mäeküljelt, erinevalt eelmisest näiteks, kus pidime töötama väga järskude tipudega :)
väheneb vaid 0,1 tingimuse ühiku võrra. Sel juhul saame funktsiooni graafikul märgata pea märkamatut allapoole kallutatust. Kui joonistada metafoorina mäge, siis justkui laskume aeglaselt madalalt mäeküljelt, erinevalt eelmisest näiteks, kus pidime töötama väga järskude tipudega :)
Nii, diferentseerides funktsiooni  koefitsientide
koefitsientide  ja
ja  , määrame esmakordsete osatuletiste süsteemi võrrandid. Pärast võrrandite määratlemist saame lahendades kahest võrrandist koosneva süsteemi, mille kaudu suudame leida koefitsientide sobivad väärtused.
, määrame esmakordsete osatuletiste süsteemi võrrandid. Pärast võrrandite määratlemist saame lahendades kahest võrrandist koosneva süsteemi, mille kaudu suudame leida koefitsientide sobivad väärtused.  ja
ja  , mille, kus vastavate osatuledede väärtused antud punktides muutuvad väga väikeseks, samas kui analüütilise lahenduse korral ei muutu need üldse. Teisisõnu, vea funktsioon leitud koefitsientide puhul saavutab miinimumi, kuna need punktid osatuledede väärtused on null.
, mille, kus vastavate osatuledede väärtused antud punktides muutuvad väga väikeseks, samas kui analüütilise lahenduse korral ei muutu need üldse. Teisisõnu, vea funktsioon leitud koefitsientide puhul saavutab miinimumi, kuna need punktid osatuledede väärtused on null.
Nii et diferentseerimise reeglite kohaselt on esimese järgu osatuletis koefitsiendi suhtes  kuju:
kuju:

esimese järgu osatuletis  kuju:
kuju:

Kokkuvõttes saime võrrandisüsteemi, millel on piisavalt lihtne analüütiline lahendus:
begin{equation*}
begin{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
end{cases}
end{equation*}
Enne võrrandi lahendamist laadime eelnevalt andmed üles, kontrollime üleslaadimise õigsust ja vormindame need.
Andmete laadimine ja vormindamine
On oluline märgata, et seoses sellega, et analüütilise lahenduse jaoks ja hiljem gradientide ning stohhastilise gradientide laskmise jaoks kasutame koodi kahes variatsioonis: raamatukogu kasutamisega. NumPy ja ilma selle kasutamiseta, vajame andmete vastavat vormindamist (vt koodi).
Andmete laadimise ja töötlemise kood
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualiseerimine
Nüüd, pärast seda, kui oleme esiteks andmed laadinud, teiseks kontrollinud laadimise õigsust ja lõpuks andmed vormindanud, teeme esimese visualiseerimise. Tihti kasutatakse selleks meetodit pairplot raamatukogud Seaborn. Meie näites, kuna numbreid on piiratud, pole mõtet kasutada raamatukogu Seaborn. Kasutame tavalist raamatukogu Matplotlib ja vaatame ainult hajusdiagrammi.
Hajusdiagrammi kood
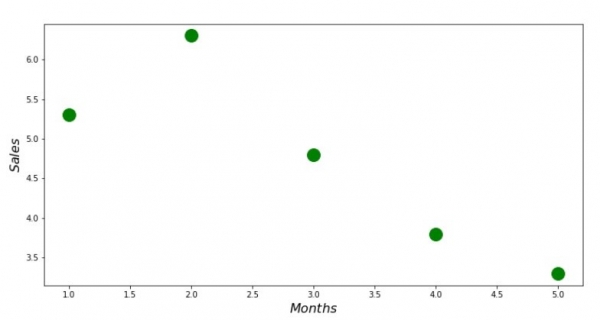
print 'Graafik nr 1 "Tulu sõltuvus aasta kuust"'
plt.plot(x_us, y_us, 'o', color='green', markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Graafik nr 1 «Tulu sõltuvus aasta kuust»
Analüütiline lahendus
Kasutame kõige tavalisemaid tööriistu python ja lahendame võrrandisüsteemi:
begin{equation*}
begin{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
end{cases}
end{equation*}
Kramer'i reegli kohaselt leiame ühise määraja ning ka määrajad  ja
ja  , seejärel jagame määraja
, seejärel jagame määraja  ühise määrajaga — leiame koefitsiendi
ühise määrajaga — leiame koefitsiendi  , samamoodi leiame koefitsiendi
, samamoodi leiame koefitsiendi  .
.
Analüütilise lahenduse kood
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Nii, mida me saime:

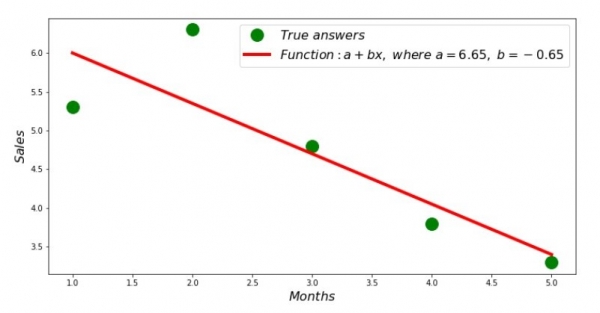
Nii et, koefitsiendid on leitud, ruutude summa on määratud. Joonistame hajutatud diagrammile sirge vastavalt leitud koefitsientidele.
Regressioonijoon koodeks
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Joonis nr 2 „Õiged ja arvutatud vastused“
Võime vaadata iga kuu kõrvalekalde graafikut. Meie puhul ei saa me sealt mingit olulist praktilist väärtust, kuid rahuldame uudishimu selle üle, kui hästi lihtne lineaarne regressioonivõrrand kirjeldab tulu sõltuvust aasta kuust.
Kõrvalekalde graafiku koodeks
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Joonis nr 3 „Kõrvalekalded, %“
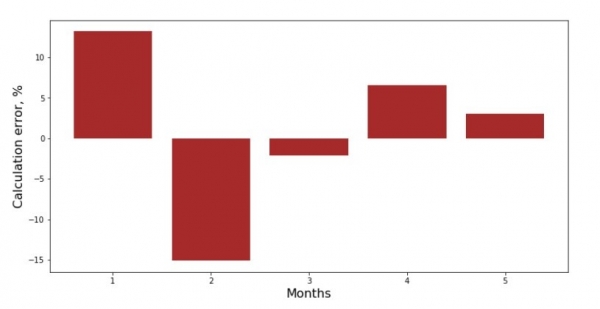
Ei ole ideaalne, kuid meie ülesanne on täidetud.
Kirjutame funktsiooni, mis koefitsiendite määramiseks  ja
ja  kasutab raamatukogu NumPy, täpsemalt — kirjutame kaks funktsiooni: ühe pseudo-aatomaarse maatriksi kasutamisega (praktiliselt mitte soovitatav, kuna protsess on arvutuslikult keeruline ja stabiilne), teise maatrikuvõrrandi kasutamisega.
kasutab raamatukogu NumPy, täpsemalt — kirjutame kaks funktsiooni: ühe pseudo-aatomaarse maatriksi kasutamisega (praktiliselt mitte soovitatav, kuna protsess on arvutuslikult keeruline ja stabiilne), teise maatrikuvõrrandi kasutamisega.
Aineline lahenduse koodeks (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npVõrdleme aega, mis kulus koefitsiendite määramiseks  ja
ja  , vastavalt kolmele esitatud meetodile.
, vastavalt kolmele esitatud meetodile.
Kood arvutusaegade määramiseks
print ' 33[1m' + ' 33[4m' + "Koeefitsentide arvutamise aeg ilma NumPy raamatukoguta:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Koeefitsentide arvutamise aeg pseudo-tagasi matrixiga:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Koeefitsentide arvutamise aeg maatriksvõrrandi kaudu:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Väikese andmehulgaga toob parima tulemuse „oma kirjutatud“ funktsioon, mis leiab koefitsiendid Krameri meetodi abil.
Nüüd on võimalik liikuda edasi teistele meetoditele koefitsientide leidmiseks.  ja
ja  .
.
Gradientne allakäik
Alustuseks määratleme, mis on gradient. Lihtsustatult öeldes on gradient lõik, mis näitab funktsiooni maksimaalse kasvu suunda. Sarnaselt mäe tõusuga, kuhu gradient osutab, seal on kõige järsem tõus mäetipuni. Arendades ülesande näidet mäest, peame meeles, et tegelikult vajame kõige järsemat langust, et võimalikult kiiresti madalusse, st miinimumisse, jõuda — kohta, kus funktsioon ei kasva ega vähene. Sellisel juhul on tuletis null. Seetõttu vajame mitte gradienti, vaid antigradienti. Antigradendi leidmiseks tuleb gradient lihtsalt korrutada -1 (miinus ühega).
Tuleb tähele panna, et funktsioon võib omada mitmeid miinimume, ja kui me järgime edaspidi juhist ning langeme ühe neist, ei suuda me leida teist miinimumi, mis võib asuda allpool leitud. Lõdvestu, see meid ei ohusta! Meie puhul on tegemist ainsa miinimumiga, kuna meie funktsioon  graafikul esindab tavalist parabolat. Nagu me kõik peaksime hästi teadma kooli matemaatika kursusest — parabolal on ainult üks miinimum.
graafikul esindab tavalist parabolat. Nagu me kõik peaksime hästi teadma kooli matemaatika kursusest — parabolal on ainult üks miinimum.
Kui oleme selgeks teinud, milleks me gradienti vajame ja et gradient on lõik, st vektor antud koordinaatidega, mis ongi need koefitsiendid.  ja
ja  Saame rakendada gradienti langemist.
Saame rakendada gradienti langemist.
Enne käivitamist soovitan lugeda paar lauset allamäge algoritmimise kohta:
- Määrame juhuslikult koordinaadid koefitsientide jaoks.
 ja Meie näites määrame koefitsiendid nulli lähedal. See on levinud praktika, kuid iga juhtumi jaoks võib olla ette nähtud oma praktika.
ja Meie näites määrame koefitsiendid nulli lähedal. See on levinud praktika, kuid iga juhtumi jaoks võib olla ette nähtud oma praktika. - Koordinaadist väheneme 1. astme osatuletise väärtuse kindla punkti kohta. Nii, kui tuletis on positiivne, siis funktsioon suureneb. Seetõttu, kui me vähendame tuletise väärtust, liikume me kasvu vastupidises suunas, st allamäge. Kui tuletis on negatiivne, siis funktsioon selles punktis väheneb ja vähendades tuletise väärtust liigume allamäge.
- Teeme sarnase protseduuri koordinaadiga : vähendame osatuletise väärtust punkti kohta. .
- Kuna mitte hüpata miinimumist üle ja mitte kosmosesse kaugele lennata, tuleb reguleerida allakäigu sammu suurust. Üldiselt võiks kirjutada terve artikli, kuidas õigemini sammu seadistada ja kuidas seda allakäigu käigus muuta, et vähendada arvutuste kulusid. Kuid praegu seisame silmitsi veidi teistsuguse ülesandega ja teadusliku „katsumise” meetodi abil, nagu öeldakse, katse-eksituse meetodil, määrame sammu suuruse.
- Pärast seda, kui oleme antud koordinaatidest ja lahutanud tuletiste väärtused, saame uued koordinaadid ja . Teeme järgmise sammu (lahutamine) juba arvutatud koordinaatidest. Nii käivitub tsükkel jälle ja jälle, kuni soovitud konvergents saavutatakse.
 ja
ja  Meie näites määrame koefitsiendid nulli lähedal. See on levinud praktika, kuid iga juhtumi jaoks võib olla ette nähtud oma praktika.
Meie näites määrame koefitsiendid nulli lähedal. See on levinud praktika, kuid iga juhtumi jaoks võib olla ette nähtud oma praktika. väheneme 1. astme osatuletise väärtuse kindla punkti kohta.
väheneme 1. astme osatuletise väärtuse kindla punkti kohta.  Nii, kui tuletis on positiivne, siis funktsioon suureneb. Seetõttu, kui me vähendame tuletise väärtust, liikume me kasvu vastupidises suunas, st allamäge. Kui tuletis on negatiivne, siis funktsioon selles punktis väheneb ja vähendades tuletise väärtust liigume allamäge.
Nii, kui tuletis on positiivne, siis funktsioon suureneb. Seetõttu, kui me vähendame tuletise väärtust, liikume me kasvu vastupidises suunas, st allamäge. Kui tuletis on negatiivne, siis funktsioon selles punktis väheneb ja vähendades tuletise väärtust liigume allamäge.  : vähendame osatuletise väärtust punkti kohta.
: vähendame osatuletise väärtust punkti kohta.  .
. ja
ja  lahutanud tuletiste väärtused, saame uued koordinaadid
lahutanud tuletiste väärtused, saame uued koordinaadid  ja
ja  . Teeme järgmise sammu (lahutamine) juba arvutatud koordinaatidest. Nii käivitub tsükkel jälle ja jälle, kuni soovitud konvergents saavutatakse.
. Teeme järgmise sammu (lahutamine) juba arvutatud koordinaatidest. Nii käivitub tsükkel jälle ja jälle, kuni soovitud konvergents saavutatakse.Kõik! Nüüd oleme valmis minema otsima kõige sügavamat kuristikku Mariaani lõhes. Alustame.
Kood gradiendi allakäimise jaoks
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Oleme laskunud Mariaani lõhe põhjadesse ja seal avastasime kõik need koefitsiendi väärtused  ja
ja  , mida me tegelikult ootasime.
, mida me tegelikult ootasime.
Teeme veel ühe sukeldumise, kuid seekord on meie süvaveeaparaadi sisuks teised tehnoloogiad, nimelt raamatukogu NumPy.
Gradienttõhupu kood (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Koeffitsientide väärtused  ja
ja  on muutumatud.
on muutumatud.
Vaatame, kuidas viga muutus gradienttõhususe jooksul, st kuidas ruutude summa kõikide sammu jooksul muutus.
Ruutude summa graafiku kood
print 'Graafik №4 "Ruutude summa sammude kaupa"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Sammud (Iteratsioon)', size=16)
plt.ylabel('Ruutude summad', size=16)
plt.show()Graafik №4 «Ruutude summa gradienttõhususe jooksul»
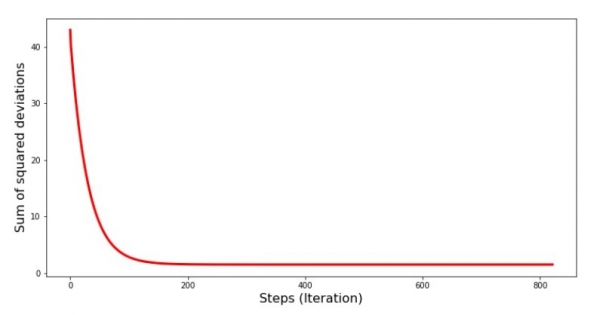
Graafikul näeme, et iga sammuga viga väheneb ja pärast teatud arvu iteratsioone näeme praktiliselt horisontaalset joont.
Lõpuks hindame koodi täitmiseaja erinevust:
Kood gradienttõhususe arvutamise aja määramiseks
print ' 33[1m' + ' 33[4m' + "Gradienttõhususe täitmise aeg ilma NumPy raamatukogu kasutamiseta:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Gradienttõhususe täitmise aeg NumPy raamatukogu kasutamisega:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Võib-olla teeme midagi valesti, kuid jälle, lihtne "ise kirjutatud" funktsioon, mis ei kasuta raamatukogu NumPy on ajaliselt efektiivsem kui funktsioon, mis kasutab raamatukogu NumPy.
Kuid me ei seisa paigal, vaid liigume suunas uurida veel üht põnevat viis lahendada lihtse lineaarse regressiooni võrrandit. Tere tulemast!
Stohhastiline gradientide langetamine
Et paremini mõista stohhastilise gradientide langemise tööpõhimõtet, on parem määratleda selle erinevused tavalise gradientide langemisega. Meie puhul gradientide langemisega, olime diferentsiaalide võrrandites  ja
ja  kasutanud kõigi tunnuste ja tõeliste vastuste summasid, mis valimis on (st summasid kõigi
kasutanud kõigi tunnuste ja tõeliste vastuste summasid, mis valimis on (st summasid kõigi  ja
ja  ). Stohhastilises gradientide langemises ei kasuta me kõiki väärtusi, mis on valimis, vaid selle asemel valime pseudojuhuslikult nii nimetatud valimi indeksi ja kasutame selle väärtusi.
). Stohhastilises gradientide langemises ei kasuta me kõiki väärtusi, mis on valimis, vaid selle asemel valime pseudojuhuslikult nii nimetatud valimi indeksi ja kasutame selle väärtusi.
Näiteks, kui indeks määrati numbriga 3 (kolm), siis võime väärtusi  ja
ja  , see the values in the partial derivative equations and determine the new coordinates. Then, by defining the coordinates, we again determine the sampling index pseudo-randomly, substituting the values corresponding to the index into the partial derivative equations to redefine the coordinates anew.
, see the values in the partial derivative equations and determine the new coordinates. Then, by defining the coordinates, we again determine the sampling index pseudo-randomly, substituting the values corresponding to the index into the partial derivative equations to redefine the coordinates anew.  ja
ja  and so on until we achieve convergence. At first glance, it may seem like this could possibly work at all, yet it does. It's true that the error doesn't decrease with every step, but there is undoubtedly a trend.
and so on until we achieve convergence. At first glance, it may seem like this could possibly work at all, yet it does. It's true that the error doesn't decrease with every step, but there is undoubtedly a trend.
What are the advantages of stochastic gradient descent over ordinary gradient descent? When the sample size is very large, measured in tens of thousands of values, it is much easier to process, say, a random thousand of them rather than the entire sample. That's when stochastic gradient descent comes into play. In our case, however, we won't notice much difference.
Let's look at the code.
Code for stochastic gradient descent
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Let’s take a closer look at the coefficients and catch ourselves asking, 'How can this be?' We have gotten different values for the coefficients.  ja
ja  . Võib-olla on stohhastic gradient descent leidnud optimaalsemad parameetrid võrandi jaoks? Kahjuks mitte. Piisab, kui vaadata ruutude summat ja näha, et uute koefitsientide väärtuste korral on viga suurem. Ärgem kiirustagem meeleheitele. Joonistame vea muutuse graafiku.
. Võib-olla on stohhastic gradient descent leidnud optimaalsemad parameetrid võrandi jaoks? Kahjuks mitte. Piisab, kui vaadata ruutude summat ja näha, et uute koefitsientide väärtuste korral on viga suurem. Ärgem kiirustagem meeleheitele. Joonistame vea muutuse graafiku.
Kood ruutude summa graafiku jaoks stohhastilisel gradientide langusel
print 'Graafik nr 5 "Ruutude summa samm-sammult"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Sammud (Iteratsioon)', size=16)
plt.ylabel('Ruutude summa', size=16)
plt.show()Graafik nr 5 «Ruutude summa stohhastilisel gradientide langusel»
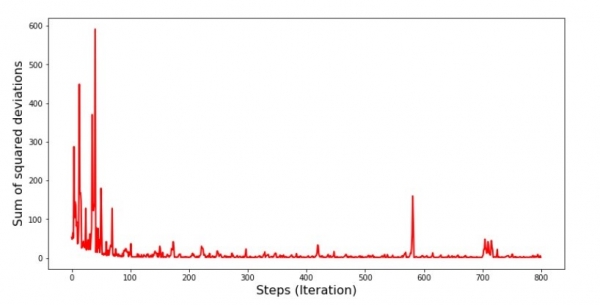
Vaadates graafikut, saab kõik kohale ja nüüd me kõik parandame.
Mis juhtus? Juhtus järgmist. Kui valime juhuslikult kuu, püüab meie algoritm selle kuu jaoks vähendada tulude arvutuse viga. Siis valime teise kuu ja kordame arvutust, kuid nüüd vähendame vea suurust juba teise valitud kuu jaoks. Ja nüüd meenutame, et meie esimesed kaks kuud kõrguvad oluliselt lihtsa lineaarse regressiooni võrrandi joone kohal. See tähendab, et kui valitakse kumbki neist kahest kuust, siis igaühe vea vähendamisega suurendab meie algoritm kogu valimi viga märkimisväärselt. Mida siis teha? Vastus on lihtne: tuleb vähendada langetamisstepi. Vähendades langetamisstepi, ei hüppa viga enam üles ega alla. Täpsemalt, viga ei lakka hüppamast, kuid see ei juhtu enam nii kiiresti :) Kontrollime.
Kood SGD käivitamiseks väiksema sammuga
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Graafik #6 "Nähtavate ruutude summa stohhastilise gradiendi allakäigul (80 tuhat sammu)"
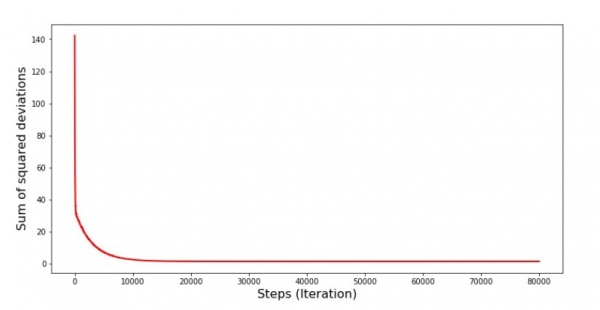
Koefficientsi väärtused on paranenud, kuid pole endiselt ideaalsed. Hüpotetooliselt saaksime selle parandada järgmiselt. Valime näiteks viimase 1000 iteratsiooni koefitsiendid, millega on tehtud minimaalne viga. Tõsi, selleks peame salvestama ka koefitsientide väärtused. Me ei tee seda, vaid keskendume graafikule. See näeb välja sujuv ja viga näib olevat ühtlaselt vähenemas. Tegelikult pole see nii. Vaatame esimesi 1000 iteratsiooni ja võrreldame neid viimastega.
SGD graafiku kood (esimesed 1000 sammu)
print 'Graafik nr 7 "Kvaadrite summa samm-sammult. Esimesed 1000 iteratsiooni"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Sammud (Iteratsioon)', size=16)
plt.ylabel('Kvaadrite summa', size=16)
plt.show()
print 'Graafik nr 7 "Kvaadrite summa samm-sammult. Viimased 1000 iteratsiooni"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Sammud (Iteratsioon)', size=16)
plt.ylabel('Kvaadrite summa', size=16)
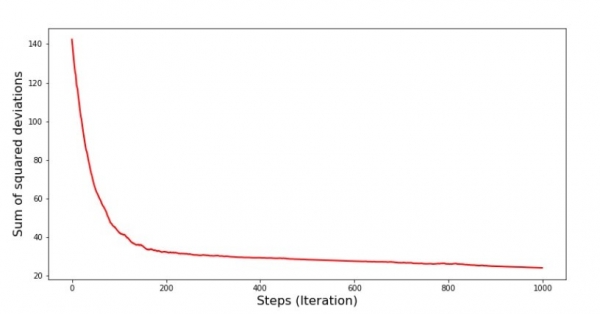
plt.show()Graafik nr 7 «SGD kvaadrite summa (esimesed 1000 sammu)»
Graafik nr 8 „SGD kõrvalekalde ruutude summa (viimased 1000 sammu)“
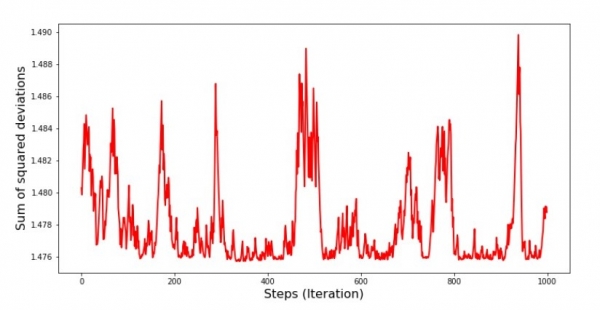
Allamäge laskumise alguses näeme üsna ühtlast ja järsku viga vähenemist. Viimasel iteratsioonil näeme, et viga hõljub väärtuse 1,475 ümber ja mõnel hetkel isegi vastab sellele optimaalsele väärtusele, kuid siis siiski tõuseb taas... Kordan, et saame salvestada koefitsiendi väärtused  ja
ja  , ja seejärel valida need, mille puhul viga on minimaalne. Kuid meil tekkis tõsisem probleem: pidime tegema 80 tuhat sammu (vt koodi), et saada väärtusi, mis oleksid lähedased optimaalsetele. See aga, juba vastandub mõttele arvutuste ajakasutuse kokkuhoiust stohhastilises gradientide laskumises võrreldes gradientidena. Mida saaks parandada ja täiustada? Pole raske märgata, et esimestel iteratsioonidel läheme kindlalt alla ja seega tasub meil esimestel iteratsioonidel jätta suur samm, ja jätkates edasi liikuda, sammu vähendada. Me ei kavatse seda artiklis teha — see on niigi veninud. Huvi korral võivad soovijad ise mõelda, kuidas seda teha, see pole raske 🙂
, ja seejärel valida need, mille puhul viga on minimaalne. Kuid meil tekkis tõsisem probleem: pidime tegema 80 tuhat sammu (vt koodi), et saada väärtusi, mis oleksid lähedased optimaalsetele. See aga, juba vastandub mõttele arvutuste ajakasutuse kokkuhoiust stohhastilises gradientide laskumises võrreldes gradientidena. Mida saaks parandada ja täiustada? Pole raske märgata, et esimestel iteratsioonidel läheme kindlalt alla ja seega tasub meil esimestel iteratsioonidel jätta suur samm, ja jätkates edasi liikuda, sammu vähendada. Me ei kavatse seda artiklis teha — see on niigi veninud. Huvi korral võivad soovijad ise mõelda, kuidas seda teha, see pole raske 🙂
Nüüd viime läbi stohhastilise gradientide langemise, kasutades raamatukogu NumPy (ja me ei komista kividest, mille me varem välja tõime)
Kood stohhastiliseks gradientide langemiseks (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Saadud väärtused osutusid peaaegu samaks nagu ilma kasutamata NumPy. Siiski on see loogiline.
Uurime, kui kaua stohhastilised gradientide langemised meilt aega võtsid.
Kood SGD (80 tuhat sammu) arvutamise aja määramiseks
print ' 33[1m' + ' 33[4m' +
"Stohhastilise gradientide langemise ajalugu, ilma NumPy raamatukogu kasutamata:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Stohhastilise gradientide langemise ajalugu NumPy raamatukogu kasutades:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Mida kauem metsa, seda tumedamaks pilved muutuvad: jälle näitab „omatehtud” valem paremat tulemust. Kõik see viib mõteteni, et peaks olema ka veel peenemaid viise raamatukogu kasutamiseks. NumPy, mis ki kiirendavad tegelikult arvutusoperatsioone. Selles artiklis me neist juba ei räägi. See on midagi, mille üle mõelda ajal, mil teil on aega:)
Kokkuvõte
Enne kokkuvõtte tegemist tahaksime vastata küsimusele, mis tõenäoliselt tekkis meie kallil lugejal. Milleks on üldse sellised "piinad" laskumistega, miks käia mäe peal üles ja alla (peamiselt alla), et leida salajane madalik, kui meie käes on nii võimas ja lihtne seade, nagu analüütiline lahendus, mis viib meid kohe soovitud kohta?
Sellele küsimusele vastus on pinnal. Praegu arutasime väga lihtsat näidet, kus tõeline vastus  sõltub ühest tunnusest
sõltub ühest tunnusest  Elus on harva, et sellist kohtab, seega kujutame ette, et meil on 2, 30, 50 või rohkem tunnust. Lisame sellele tuhandeid, isegi kümneid tuhandeid väärtusi iga tunnuse jaoks. Sel juhul ei pruugi analüütiline lahendus seda väljakutset taluda ja võib kokku kukkuda. Ühtlasi toob gradientne langus ja selle variatsioonid meid aeglaselt, kuid kindlalt eesmärgi — funktsiooni miinimumini. Kiirusest muretsema ei pea — me arutame kindlasti veel meetodeid, mis võimaldavad meil sammupikkust (ehk kiirus) seada ja reguleerida.
Elus on harva, et sellist kohtab, seega kujutame ette, et meil on 2, 30, 50 või rohkem tunnust. Lisame sellele tuhandeid, isegi kümneid tuhandeid väärtusi iga tunnuse jaoks. Sel juhul ei pruugi analüütiline lahendus seda väljakutset taluda ja võib kokku kukkuda. Ühtlasi toob gradientne langus ja selle variatsioonid meid aeglaselt, kuid kindlalt eesmärgi — funktsiooni miinimumini. Kiirusest muretsema ei pea — me arutame kindlasti veel meetodeid, mis võimaldavad meil sammupikkust (ehk kiirus) seada ja reguleerida.
Ja nüüd, lühike kokkuvõte.
Esiteks, ma loodan, et artiklis esitatud materjal aitab algajatel "andmeteadlastele" mõista, kuidas lahendada lihtsa (ja mitte ainult) lineaarse regressiooni võrrandeid.
Teiseks, me vaatasime mitmeid võtteid võrrandi lahendamiseks. Nüüd, sõltuvalt olukorrast, saame valida selle, mis sobib kõige paremini antud ülesande lahendamiseks.
Kolmandaks nägime, kui suur on individuaalsete seadete, sealhulgas gradientide langemise sammu pikkuse jõud. Selle parameetriga ei saa ühtegi neljandat sammu jätta tähelepanuta. Nagu eespool mainitud, on arvutuste tegemise kulude vähendamiseks mõistlik sammu pikkust muutuvalt muuta.
Neljandaks, meie puhul näitasid "oma kirjutatud" funktsioonid parem aegade tulemusi. Tõenäoliselt seondub see mitte kõige professionaalsemale kasutamisele raamatukogu võimalustest. NumPy. Sellegipoolest järeldus on järgmine. Ühtpidi, mõnikord tasub kahelda kehtinud arvamustes, teiselt poolt aga ei ole alati mõistlik kõike keeruliseks muuta — vastupidi, mõnikord osutub efektiivsemaks lihtsam lahendus. Ja kuna meie eesmärgiks oli käsitleda kolme lähenemist lihtsa lineaarselt regressioonivõrrandi lahendamisel, siis "oma kirjutatud" funktsioonide kasutamine oli meie jaoks täiesti piisav.
Kirjandus (või midagi sarnast)
1. Liinearne regressioon
2. Väikseima ruudu meetod
3. Tuletis
4. Gradient
5. Gradientide langemine
6. NumPy teekond
Allikas: habr.com
