

Me tegime selle ära!
„Selle kursuse eesmärk on valmistada teid ette teie tehniliseks tulevikuks.”
 Tere, Habr. Kas mäletate seda ägedat artiklit (+219, 2588 järjehoidjat, 429k lugemist)?
Tere, Habr. Kas mäletate seda ägedat artiklit (+219, 2588 järjehoidjat, 429k lugemist)?
Nii et Hammingul (jah, jah, iseparandavad ja isekontrollivad ) on terve , kirjutatud tema loengute põhjal. Me tõlkimme selle, sest tüüp räägib tõtt.
See raamat ei räägi ainult IT-st, see raamat räägib ägedate inimeste mõtteviisist. „See ei ole lihtsalt positiivse mõtlemise laadimine; see kirjeldab tingimusi, mis suurendavad võimalusi suurepärase töö tegemiseks.”
Tõlke eest aitäh Andreile Pahhomovile.
Teabeoloogia töötati välja C. E. Shannon'i poolt 1940-ndate lõpupoole. Bell'i laboratooriumide juhtkond nõudis, et ta nimetaks selle "Side Teooriaks", kuna see oleks palju täpsem nimetus. Ilmselgetel põhjustel omab nimi "Teabeoloogia" oluliselt suuremat mõju avalikkusele, seega valis Shannon just selle ning see on tuntud tänaseni. Nimi ise viitab sellele, et teooria tegeleb teabega, mis muudab selle oluliseks, kuna süveneme üha sügavamale teabe ajastusse. Käesolevas peatükis käsitlen ma mõningaid peamisi järeldusi sellest teooriast ja esitan mitte rangelt, vaid pigem intuitiivselt arusaadavaid tõendeid mõnede individuaalsete väidete kohta, et te mõistaksite, mis tegelikult on "Teabeoloogia", kus seda rakendada ja kus mitte.
Esiteks, mis on "teave"? Shannon seondab teabe ebamugavusega. Ta valis sündmuse tõenäosuse negatiivse logaritmi teabe kvantitatiivsena, mida sa saad, kui sündmus toimub tõenäosusega p. Näiteks, kui ma ütlen, et Los Angeleses on udune ilm, siis p on lähedane 1, mis ei anna meile palju teavet. Kuid kui ma ütlen, et juunis sajab Montereys vihma, siis selles teates on ebamugavust ja see sisaldab rohkem teavet. Usaldusväärne sündmus ei sisalda endas üldse teavet, kuna log 1 = 0.
Vaatame seda lähemalt. Shannon pidas kvantitatiivset teavet pidevaks funktsiooniks sündmuse p tõenäosusest, ning sõltumatute sündmuste puhul peaks see olema additiivne – teabe hulk, mis saadakse kahe sõltumatu sündmuse toimumise tagajärjel, peab olema võrdne teabe hulgaga, mis saadakse ühiselt toimuva sündmuse puhul. Näiteks täringuheite ja mündiviske tulemusi peetakse tavaliselt sõltumatuteks sündmusteks. Tõlgime ülaltoodut matemaatika keelde. Kui I(p) on teabe hulk, mis sisaldub sündmuses, mille tõenäosus on p, siis kahele sõltumatule sündmusele x, mille tõenäosus on p1, ja y, mille tõenäosus on p2, on ühise sündmuse puhul meil
![]()
(x ja y on sõltumatud sündmused)
See on Cauchy funktsionaalne võrrand, mis on tõene kõigi p1 ja p2 jaoks. Selle funktsionaalse võrrandi lahendamiseks eeldame, et
p1 = p2 = p,
see annab
![]()
Kui p1 = p2 ja p2 = p, siis
![]()
jne. Protsessi laiendades, kasutades eksponentsiaali standardmeetodit, kehtib see kõigi ratsionaalsete arvude m/n puhul
![]()
Eeldatav pidev teave näitab, et logaritmifunktsioon on ainus pidev lahendus Cauchy funktsionaalequatsioonile.
Informatsiooniteoorias eeldatakse logaritmi aluseks olevat arvu 2, seega sisaldab binaarne valik täpselt 1 bitti teavet. Seetõttu mõõdetakse teavet järgmistel valemitel.
![]()
Pehkime nüüd natuke ja arutame, mis just juhtus. Esiteks, me ei defineerinud kunagi mõistet 'teave', vaid määratlesime lihtsalt selle kvantitatiivse mõõtmiseks vajaliku valemi.
Teiseks sõltub see mõõt ebaselgustest ja kuigi see sobib masinate jaoks - nagu näiteks telefonisüsteemid, raadio, televisioon, arvutid jne - ei peegelda see normaalses inimeste suhtumises teabesse.
Kolmandaks, see on suhteline mõõde, mis sõltub teie teadmiste hetkeolukorrast. Kui vaatate 'juhuslike numbrite' voogu juhuslike arvu generaatorist, eeldatakse, et iga järgmine number on määratlemata; kuid kui teate valemit «juhuslikest numbritest» arvutamiseks, on järgmine number teada ja see ei sisalda seetõttu teavet.
Seetõttu sobib Shannon'i määratlemine informatsiooni jaoks paljuski masinate jaoks, kuid tundub, et see ei vasta inimese arusaamale sellest sõnast. Just sellepärast oleks 'Informatsiooni teooriat' pidanud nimetama 'Suhteteooriaks'. Siiski on juba liiga hilja määratlemisi muuta (mille tõttu teooria omandas oma algse populaarsuse ja mis panevad inimesi ikka veel arvama, et see teooria tegeleb 'informatsiooniga'), seega peame nendega leppima, kuid teil peab olema selge arusaam, kui kaugel Shannon'i määratlemine informatsioonist on tema üldkasutatavast tähendusest. Shannon'i informatsioon tegeleb millegagi täiesti erinevaga, nimelt teadmatusest.
Siit tuleb mõelda, kui pakute ette mingit terminoloogiat. Kuidas sobib ettepaneku definitsioon, näiteks Shannon'i andmete definitsioon, teie algse idee ja kui palju see erineb? Peaaegu pole ühtegi terminit, mis täpselt peegeldaks teie varem väljendatud kontseptsiooni, kuid lõpuks just see terminoloogia peegeldab ideede tähendust, seega midagi täpsete määratlustega formaliseerimine toob alati sisse teatava müra.
Vaatleme süsteemi, mille tähestik koosneb sümbolitest q, millel on tõenäosused pi. Sel juhul keskmine teabe kogus süsteemis (kui selle oodatav väärtus) on:
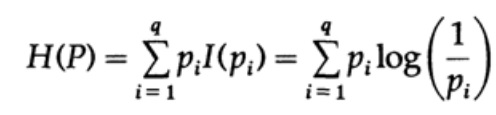
See nimetatakse süsteemi entropiaks, mille tõenäosuse jaotus on {pi}. Kasutame terminit 'entropia', sest sama matemaatiline vorm ilmneb termodünaamikas ja statistilises mehaanikas. Just seetõttu loob termin 'entropia' ümber teatud tähtsuse aura, mis lõpuks ei ole põhjendatud. Sama matemaatiline vorm ei tähenda sama sümbolite tõlgendust!
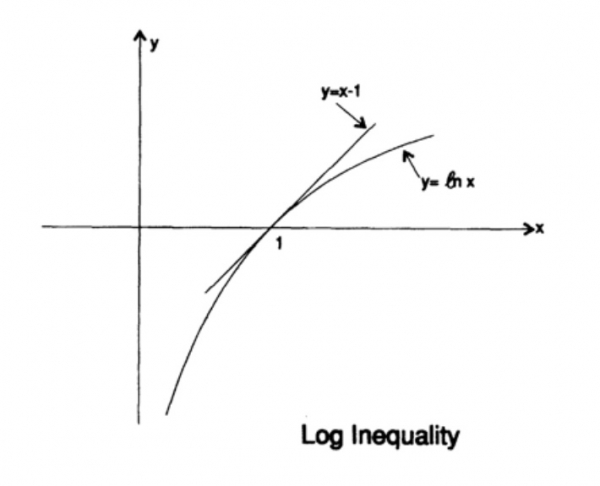
Tõenäosuse jaotuse entropia mängib kooditeoorias keskset rolli. Gibbs'i ebaühtlus kahe erineva tõenäosuse jaotuse pi ja qi vahel on üks selle teooria olulisi järeldusi. Nii et me peame tõestama, et
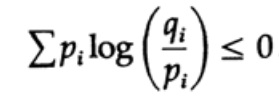
Tõestus põhineb ilmsel graafikul, joonis 13.I, mis näitab, et
![]()
võrdsus saavutatakse vaid juhul, kui x = 1. Rakendame ebaühtlust iga summa vasakpoolses osas oleva liitmise korral:
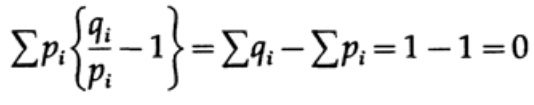
Kui suhtlus süsteemi tähestik koosneb q sümbolist, siis võttes iga sümboli edastamise tõenäosuse qi = 1/q ja asendades q, saame Gibbs'i ebaühtlusest
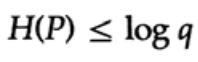
Joonis 13.I
See näitab, et kui kõigi q sümbolite edastamise tõenäosus on selline, et see on ühesugune ja võrdne — 1/q, siis maksimaalne entropia on ln q, vastasel juhul kehtib ebaühtlus.
Üksikasjalikult dekodeeritava koodi puhul kehtib meil Krafti ebaühtlus
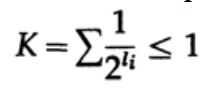
Nüüd, kui määratleme pseudo-tõenäosused
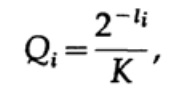
kus on lõplikult 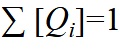 = 1, mis tuleneb Gibbs'i ebaühtlusest,
= 1, mis tuleneb Gibbs'i ebaühtlusest,
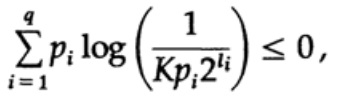
ja rakendame veidi algebralist (peame meeles, et K ≤ 1, nii et saame logaritmilise liikme ära jätta ja hiljem võib-olla tugevdada ebaühtlust), siis saame
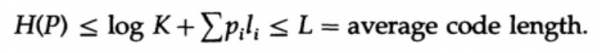
kus L — on koodi keskmine pikkus.
Seega on entropy igasuguste keskmise sõna pikkusega koodide minimaalne piir. See on Shannon'i teoreem häirevabas kanalis.
Nüüd vaatame side süsteemide peamist teoreemi, kus teave edastatakse sõltumatute bitivoogudena ja kus on müra. Eeldatakse, et ühe bit’i korrektse edastamise tõenäosus P > 1 / 2, ning tõenäosus, et bit’i väärtus edastamise ajal pöördub (juhtub viga), on Q = 1 — P. Mugavuse huvides oletame, et vead on sõltumatud ja vea tõenäosus on sama iga saadetud bit’i puhul — st sidekanalis on „valge müra“.
Meil on pikk joon, kus on n bitti kodeeritud ühte sõnumisse — n — mõõtmeline laiendus ühesbitise koodi. N väärtuse määrame hiljem. Vaatame n-bitist sõnumit kui punkti n-mõõtmelises ruumis. Kuna meil on n-mõõtmelises ruumis — ja lihtsuse huvides oletame, et igal sõnumil on sama tõenäosus ilmuda — on M võimalikku sõnumit (M määratakse ka hiljem), seega on igasuguse edastatud sõnumi tõenäosus
![]()
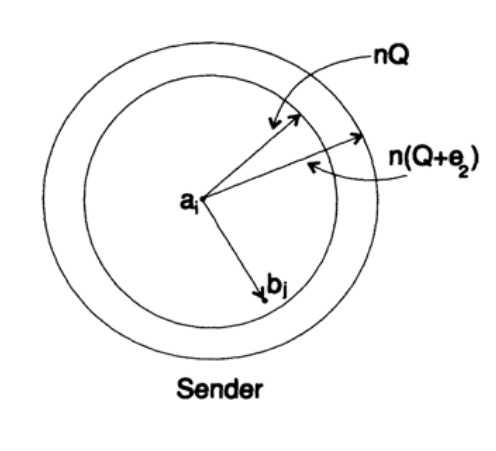
(saatja)
Joonis 13.II
Edasi arutleme kanali läbilaskevõime üle. Ilma detailidesse laskumata määratletakse kanalite läbilaskevõime kui maksimaalne teabe kogus, mida saab usaldusväärselt edastada sidekanali kaudu, arvestades maksimaalselt efektiivse kodeerimise kasutamist. Pole tõendeid selle kasuks, et läbi sidekanali saaks edastada rohkem teavet, kui on selle maht. Seda saab tõestada binaarse sümmeetrilise kanali puhul (mida kasutame meie juhul). Kanal W maht, bitipõhise saatmise korral, määratletakse kui
![]()
kuidas, nagu varem, P — tõenäosus, et viga ilmneb igas saadetud bitis. Kui saadame n sõltumatut bitti, siis kanalite maht määratakse kui
![]()
Kui oleme kanali lähedal, peame saatma peaaegu sama palju teavet iga sümboli ai kohta, i = 1, …, M. Arvestades, et iga sümboli ai esinemise tõenäosus on 1 / M, saame
![]()
kui saadame ühe M võrdselt tõenäolise sõnumi ai, siis meil on
![]()
Saates n bitti ootame nQ vea ilmnemist. Praktiliselt, n-bitti sisaldava sõnumi puhul on meil saadud sõnumis ligikaudu nQ viga. Suurte n väärtuste juures kitseneb vea jaotuse suhteline varieeruvus ( varieeruvus = jaotuse laius, )
vea arvu jaotus muutub n kasvades üha kitsamaks.
Nii et edastaja poolt võtan sõnumi ai, et saata, ja joonistan selle ümber sfääri raadiusega
![]()
mis on pisut suurem kui e2, mis on oodatava vigade arvu Q, (joonis 13.II). Kui n on piisavalt suur, siis on väga väike tõenäosus, et teatepunkt bj vastuvõtjal jääb selle sfääri välisse. Kujutame olukorda nii, nagu mina seda näen edastajana: meil on igasuguseid raadiuseid edastatud sõnumist ai vastuvõetud sõnumi bj, mille vigade tõenäosus on (või peaaegu on) normaaljaotuses, saavutades maksimumi nQ. Iga e2 puhul, mille valime, on olemas n, mis on piisavalt suur, nii et tõenäosus, et saadud punkt bj, mis jääb väljapoole minu sfääri, on nii väike, kui soovite.
Kaalume nüüd sama olukorda teie vaatenurgast (joonis 13.III). Vastuvõtja poolel on sama raadiusega sfäär S(r) ümber vastu võetud punkti bj n-suuruses ruumis, nii et kui vastu võetud sõnum bj on minu sfääri sees, siis toimub minu saadetud sõnum ai teie sfääri sees.
Kuidas võib viga tekkida? Viga võib tekkida olukordades, mis on kirjeldatud allolevas tabelis:
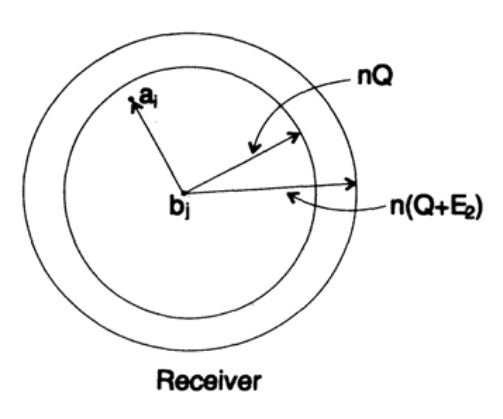
Joonis 13.III

Siin näeme, et kui ehitatud ümber vastuvõetud punkti on vähemalt üks punkt, mis vastab võimalikult saadetud kodeerimata sõnumile, siis edastamise käigus tekkis viga, sest te ei saa kindlaks teha, milline nendest sõnumitest oli edastatud. Saadetud sõnum ei sisalda vigasid ainult siis, kui sellele vastav punkt asub sfääris ja ei ole teisi punkte, mis oleksid selle koodiga samas sfääris.
Meil on matemaatiline võrrand vea tõenäosuse Re jaoks, kui teadlikult saadeti sõnum ai.
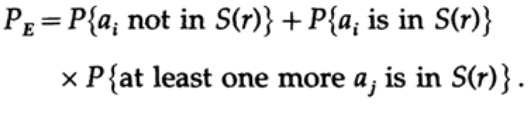
Saame teise liidetava esimesest tegurist loobuda, võttes selle üheks. Seega saame ebaühtluse.
![]()
Ilmselt on nii, et
![]()
seega
![]()
rakendame uuesti viimasel liikmel paremal
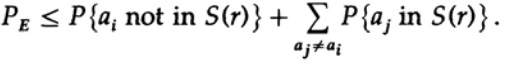
Võttes n piisavalt suureks, võib esimese liikme võtta nii väikeseks kui soovite, olgu see siis väiksem kui mingi number d. Seega on meil
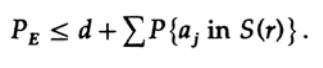
Nüüd vaatame, kuidas saab luua lihtsat asenduskoodi M sõnumite kodeerimiseks, mis koosnevad n bitist. Ilma arusaamata, kuidas täpselt koodi koostada (vigade parandamise koodid polnud veel välja mõeldud), valis Shannon juhusliku kodeerimise. Visake iga n bitise sõnumi jaoks münti ja korrake protsessi M sõnumi jaoks. Kokku tuleb teha nM mündiviset, seega on võimalikud
![]()
koodileksikone, millel on sama tõenäosus ½nM. Loomulikult tähendab juhusliku koodileksikonide loomise protsess, et on olemas võimalus, et tekivad duplikaadid, samuti koodipunktid, mis on üksteisele lähedased ja mis seega on tõenäoliste vigade allikaks. On vaja tõestada, et kui seda ei toimu suurema tõenäosusega kui mõni valitud madal veataseme tase, siis on antud n piisavalt suur.
Oluline punkt on see, et Shannon keskmistab kõik võimalikud koodiraamatud, et leida keskmine viga! Kasutame sümbolit Av [.], et tähistada keskmist väärtust paljude kõikide võimalike juhuslike koodisõnastike seas. Keskmistamine konstantsiga d annab loomulikult konstantse tulemuse, kuna keskmistamiseks sobib iga element, mis vastab summas teistele elementidele.
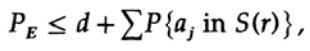
mis võib suureneda (M–1 muutub M-ks)
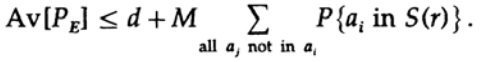
Konkreetse sõnumi korral, kui keskmistada kõiki koodiraamatuid, läbib kodeerimine kõik võimalikud väärtused, mistõttu on keskmine tõenäosus, et punkt asub sfääris, sfääri mahu ja kogu ruumi mahu suhe. Sfääri maht on sel juhul
![]()
kus s=Q+e2 <1/2 ja ns peab olema täisarv.
Viimane paremal liidetav on suurim selles summas. Alustame selle väärtuse hindamisest Stirlingi valemi järgi faktoriaalide jaoks. Siis vaatame liidetava eelnevat vähenemisnäitajat, pöörake tähelepanu, et see näitaja suureneb vasakule liikudes, seega saame: (1) piirata summa väärtust geomeetrilise progressiooniga selle algse näitajaga, (2) laiendada geomeetrilist progressiooni n liikmeks kuni lõpmatuseni, (3) arvutada lõpmatu geomeetrilise progressiooni summa (standardsed algebralised toimingud, mitte midagi olulist) ja lõpuks saada piirväärtus (piisavalt suure n puhul):
![]()
Pöörake tähelepanu, kuidas entropia H(s) ilmus binaarsesse identiteeti. Märkige, et Taylor’i seeria arendamine H(s)=H(Q+e2) annab hinnangu, mis saadakse arvestades ainult esimest derivate ja ignoreerides kõiki teisi. Nüüd koondame lõppavaldi:
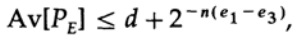
kus
![]()
Kõik, mida peame tegema, on valida e2 nii, et e3 < e1, ja siis saab viimane liige olla nii väike, kui soovime, piisavalt suure n korral. Seega võib keskmine PE viga olla nii väike, kui soovime, kanali läbilaskevõime lähenedes C-le.
Kui kõigi koodide keskmine viga on piisavalt väike, peab vähemalt üks kood olema sobiv, seega peab olema vähemalt üks sobiv kodeerimissüsteem. See on oluline tulemus, mille esitas Shannon — „Shannoni teoreem müra allikaga kanalite jaoks“, kuigi tasub märkida, et ta tõestas seda palju üldisema juhtumi jaoks kui see lihtne binaarne sümmeetriline kanal, mida mina kasutasin. Üldise juhtumi puhul on matemaatilised arvutused palju keerulisemad, kuid ideed ei erine kuigi palju, seega on sageli võimalik erijuhtumi kaudu paljastada teoreemi tõeline tähendus.
Kritiseerime tulemust. Oleme korduvalt rõhutanud: "Kui n on piisavalt suur". Aga kui suur on piisavalt suur? Äärmiselt, äärmiselt suur, kui soovite tegelikult olla samaaegselt lähedal kanali läbilaskevõimele ja veenduda, et andmed edastatakse õigesti! Nii suur, et te tegelikult peate ootama väga kaua, et koguda sõnum nii suurest arvust bitidest, et hiljem seda kodeerida. Sellisel juhul on juhusliku koodi sõnastiku suurus lihtsalt tohutu (sest seda sõnastikku ei saa esitada lühema kujul kui kõikide Mn bitti täielik loetelu, arvestades, et n ja M on väga suured)!
Vigade parandamise koodid väldivad pika sõnumi saatmist, millejärel järgneb selle kodeerimine ja dekodeerimine väga suurte koodiraamatute kaudu, kuna nad väldivad ise koodiraamatuid ja kasutavad nende asemel tavapäraseid arvutusi. Lihtsas teoorias kaotavad sellised koodid tavaliselt kanalite läbilaskevõime lähenemise ja samas hoiavad piisavalt madalat vigade sagedust, kuid kui kood parandab suurt hulka vigu, näitavad nad häid tulemusi. Teisisõnu, kui te reserveerite mingit kanali mahtu vigade parandamiseks, peate seda parandamisseganut kasutama enamikul juhtudel, st iga saadetud sõnumis peaks olema parandatud suur hulk vigu, vastasel juhul kaotate selle mahu raisku.
Kuid tõestatud teoreem ei ole ikkagi mõttetu! See näitab, et tõhusad edastusüsteemid peavad kasutama hoolikalt välja töötatud kodeerimiskeeme väga pikkade bitijadade jaoks. Näiteks on satelliidid, mis on läinud kaugemale välistest planetidest; maapinnast ja päikesest eemal olles peavad nad parandama järjest rohkem ja rohkem vigu andmeplokis: mõned satelliidid kasutavad päikesepaneele, mis annavad umbes 5 W, teised kasutavad aatomienergiaallikaid, mille võimsus on sarnane. Nõrk toitesource, väikeste saatjate taldrikute suurus ja maa vastuvõtjate piiratud taldrikute suurused, tohutu kaugus, mida signaal peab ületama — kõik see nõuab kõrge vigade paranduse tasemega koode, et luua tõhus suhtlussüsteem.
Naasime n-mõõtmelisse ruumi, mida me varem tõestuses kasutasime. Rääkides sellest, näitasime, et peaaegu kogu sfääri maht koondub ümber välispinna, — seega on peaaegu kindel, et saadetud signaal asub sfääri pinnal, mis on ehitatud ümber vastuvõetud signaali, isegi suhteliselt väikese raadiusega. Seetõttu ei ole üllatav, et pärast sügavat parandamist juhuslike vigade, nQ, korral võib vastuvõetud signaal olla ääretult lähedal vigadeta signaalile. Suhtluskanali maht, mida oleme varem käsitlenud, on võtmetähtsusega selle nähtuse mõistmiseks. Pange tähele, et sellised sfäärid, mis on ehitatud Hamming'i vigade parandamiseks, ei katke omavahel. Suur arv praktiliselt ortogonaalseid mõõtmeid n-mõõtmelises ruumis näitab, miks võime mahtuda M sfääri ruumi väikese kattuvusega. Kui lubada väikest, ääretult väikest kattumist, mis toob kaasa vaid väikese arvu vigu dekodeerimisel, võib saavutada tiheda sfääride paigutuse ruumis. Hamming garanteeris teatud taseme vigade parandamiseks, Shannon aga madala tõenäosuse vigu, säilitades samal ajal tegeliku läbilaskevõime, mis on ääretult lähedane suhtluskanali mahule, mida Hamming'i koodid ei suuda saavutada.
Teabeooria ei räägi, kuidas projekteerida tõhusat süsteemi, kuid see osutab suunale, kuidas tõhusate suhtlussüsteemide poole liikuda. See on väärtuslik tööriist masinatevaheliste suhtlussüsteemide loomisel, kuid nagu varem mainitud, ei ole sel selle kohta eriti head seost, kuidas inimesed omavahel teavet vahetavad. Teadmine, mil määral bioloogiline pärand sarnaneb tehniliste suhtlussüsteemidega, on lihtsalt teadmata, seetõttu ei ole praegu selge, kui rakendatav teabeooria geenidele on. Meil ei jää muud üle, kui proovida, ja kui edu näitab meile selle nähtuse masinataolist iseloomu, siis ebaõnnestumine viib meid teiste oluliste teabe iseloomu aspektideni.
Laseme veidi kõrvale kalduda. Oleme näinud, et kõik esialgsed määratlused peavad enam-vähem väljendama meie algsete uskumuste olemust, kuid neile on omane teatav moonutus ja seetõttu osutuvad nad mittetegelikuteks. Tavatsetud on uskuda, et lõppkokkuvõttes määratleb meie kasutatav definitsioon tegelikult olemuse; kuid see näitab meile vaid, kuidas asjadega tegeleda ja ei kanna iseenesest mingit tähendust. Postulatiivne lähenemine, mida matemaatilistes ringkondades väga kiidetakse, jätab praktikas palju soovida.
Nüüd vaatame IQ-testide näidet, kus määratlemine on nii tsükliline, kui soovite, ja seega eksitab teid. Luues testi, peaks see mõõtma intelligentsust. Pärast seda vaadatakse see üle, et muuta see võimalikult järjepidevaks ja seejärel avaldatakse see ning kalibreeritakse lihtsal viisil nii, et mõõdetud 'intelligentsus' osutub normaalselt jaotatuks (muidugi kalibreerimise kõverale järgides). Kõik määratlemised peavad olema uuesti kontrollitud, mitte ainult siis, kui need esmakordselt ette pannakse, vaid ka palju hiljem, kui neid rakendatakse saadud järeldustes. Kuidas sobivad määratlemise piirid lahendatavale ülesandele? Kui sageli hakatakse määratlusi, mis antakse ühes kontekstis, rakendama piisavalt erinevates tingimustes? See juhtub üsna sageli! Inimteadustes, millega te oma elus kindlasti kokku puutute, juhtub see tihti.
Seega on selle infoteooria esitamise eesmärk, lisaks selle kasulikkuse demonstreerimisele, hoiatada teid selle ohu eest, või näidata, kuidas seda kasutada soovitud tulemuse saavutamiseks. On ammu märgatud, et algsed määratlused mõjutavad seda, mida te lõpuks leiate, palju rohkem kui tundub. Algne määratlemine nõuab teilt suurt tähelepanu mitte ainult igas uues olukorras, vaid ka valdkondades, millega te juba ammu tegelenud olete. See võimaldab teil mõista, kui palju saadud tulemused on tautoloogia, mitte midagi kasulikku.
Tuntud Eddingtoni lugu räägib inimestest, kes püüdsid merest kala võrgu abil. Uurides püüdsid nad kalade suurust, määrasid nad minimaalset suurust, mis meres esineb! Nende järeldus põhines kasutataval tööriistal, mitte tõelikkusel.
Jätkub…
Kes soovib aidata raamatute tõlkes, kujundamises ja väljaandmisel — kirjutage mulle isiklikult või e-posti teel magisterludi2016@yandex.ru
Üks huvitav uudis: oleme käivitanud veel ühe suurepärase raamatu tõlke — )
Otsime eriti inimesi, kes aitaksid tõlkida . (tõlgime 10 minutit, esimesed 20 on juba ära võetud)
Raamatu sisu ja tõlgitud peatükid
- Sissejuhatus teaduse ja inseneriteaduse tegemisse: õppides õppima (28. märts 1995)
- „Digitaalse (diskreetse) revolutsiooni alused“ (30. märts 1995)
- „Arvutite ajalugu — riistvara“ (31. märts 1995)
- „Arvutite ajalugu — tarkvara“ (4. aprill 1995)
- „Arvutite ajalugu — rakendused“ (6. aprill 1995)
- „Tehisintellekt – I osa“ (7. aprill 1995)
- „Tehisintellekt – II osa“ (11. aprill 1995)
- „Tehisintellekt III“ (13. aprill 1995)
- „n-Mõõtmelised ruumid“ (14. aprill 1995)
- „Kooditeooria — Informatsiooni esitus, I osa“ (18. aprill 1995)
- „Kooditeooria — Informatsiooni esitus, II osa“ (20. aprill 1995)
- „Viga-korrektsioonikoodid“ (21. aprill 1995)
- „Informatsiooni teooria“ (25. aprill 1995)
- „Digitaalsed filtrid, I osa“ (27. aprill 1995)
- «Digitaalsed filtrid, II osa» (28. aprill 1995)
- «Digitaalsed filtrid, III osa» (2. mai 1995)
- «Digitaalsed filtrid, IV osa» (4. mai 1995)
- «Simulatsioon, I osa» (5. mai 1995)
- «Simulatsioon, II osa» (9. mai 1995)
- «Simulatsioon, III osa» (11. mai 1995)
- «Kiudoptilised süsteemid» (12. mai 1995)
- «Arvutiga õpetamine» (16. mai 1995)
- «Matemaatika» (18. mai 1995)
- «Kvantmehaanika» (19. mai 1995)
- «Loovus» (23. mai 1995). Tõlge:
- «Eksperdid» (25. mai 1995)
- «Usaldamatud andmed» (26. mai 1995)
- «Süsteemitehnika» (30. mai 1995)
- «Sa saad seda, mida mõõdad» (1. juuni 1995)
- (2. juuni 1995) tõlgime 10-minutiliste lõikudena
- Hamming, «Te ja teie uurimistöö» (6. juuni 1995).
Kes soovib aidata raamatute tõlkes, kujundamises ja väljaandmisel — kirjutage mulle isiklikult või e-posti teel magisterludi2016@yandex.ru
Allikas: habr.com
