

Tere, Habri elanikud. Kursuse alguse eelõhtul Oleme koostanud huvitava materjali tõlke.

Paljudel kasutusjuhtudel, mida meie, nagu , näeme oma klientide veebisaitidel, et oluline teave on peidetud üksuste vahelistesse suhetesse, näiteks kasutajate vaheliste suhete, elementide vaheliste sõltuvuste või andurite vaheliste seoste analüüsimisel. Selliseid kasutusjuhtumeid modelleeritakse tavaliselt graafikul. Selle aasta alguses avaldas Amazon uue graafikute andmebaasi Neptune. Selles postituses tahame jagada oma esimesi ideid, häid tavasid ja seda, mida saab aja jooksul paremaks muuta.
Miks me vajasime Amazon Neptuuni
Graafiandmebaasid lubavad omavahel tihedalt seotud andmekogumeid paremini käsitleda kui nende relatsioonilised vasted. Sellistes andmekogumites talletatakse asjakohane teave tavaliselt objektidevahelistes suhetes. Neptuuni testimiseks kasutasime hämmastavat avatud andmete projekti MusicBrainz kogub muusika kohta igasuguseid mõeldavaid metaandmeid, näiteks teavet artistide, lugude, albumite ilmumise või kontsertide kohta, aga ka seda, kellega loo loonud artist koostööd tegi või millal ja millises riigis album välja anti. MusicBrainzi võib pidada tohutuks võrgustikuks üksustest, mis on kuidagi seotud muusikatööstusega.
MusicBrainzi andmestik on esitatud relatsioonandmebaasi CSV-tõmmisena. Kokku sisaldab mälutõmmis umbes 93 miljonit rida 157 tabelis. Kuigi mõned neist tabelitest sisaldavad põhiandmeid, nagu artistid, sündmused, salvestised, väljaanded või lood, sisaldavad teised järgmist: linkige tabeleid — salvestab seoseid artistide ja plaatide, teiste artistide või väljaannete vahel jne. Need demonstreerivad andmestiku graafistruktuuri. Kui me teisendasime andmestiku RDF-kolmikfailideks, saime umbes 500 miljonit eksemplari.
Projektipartnerite, kellega koostööd teeme, kogemuste ja muljete põhjal kujutame ette keskkonda, kus seda teadmusbaasi kasutatakse uue teabe hankimiseks. Lisaks eeldame, et seda ajakohastatakse regulaarselt, näiteks uute väljaannete lisamise või grupi liikmete nimekirja uuendamise teel.
reguleerimine
Nagu arvata võis, on Amazon Neptune'i installimine lihtne. See on üsna detailne. Graafiandmebaasi saab käivitada vaid mõne klõpsuga. Täpsema konfiguratsiooni osas aga... raske leida. Seetõttu tahame viidata ühele konfiguratsiooniparameetrile.
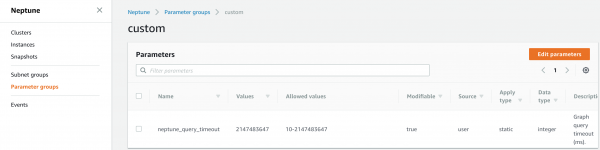
Parameetrirühmade konfiguratsiooni ekraanipilt
Amazon väidab, et Neptune keskendub madala latentsusega tehingute töökoormustele, seega on päringu vaikimisi ajalõpp 120 sekundit. Siiski testisime paljusid analüütika kasutusjuhtumeid, kus me regulaarselt selle piirini jõudsime. Seda ajalõppu saab muuta, luues Neptune'ile uue parameetrirühma ja määrates selle väärtuseks neptune_query_timeout vastav piirang.
Andmete laadimine
Allpool arutame üksikasjalikumalt, kuidas me MusicBrainzi andmeid Neptune'i laadisime.
Suhted kolmekesi
Esmalt teisendasime MusicBrainzi andmed RDF-kolmikeks. Seega iga tabeli jaoks defineerisime malli, mis määrab, kuidas iga veergu kolmikus esitatakse. Selles näites on iga artisti tabeli rida kaardistatud kaheteistkümneks RDF-kolmikeks.
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/gid> "${gid}"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/name> "${name}"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/sort-name> "${sort_name}"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/begin-date> "${begin_date_year}-${begin_date_month}-${begin_date_day}"^^xsd:<http://www.w3.org/2001/XMLSchema#date> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/end-date> "${end_date_year}-${end_date_month}-${end_date_day}"^^xsd:<http://www.w3.org/2001/XMLSchema#date> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/type> <http://musicbrainz.foo/artist-type/${type}> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/area> <http://musicbrainz.foo/area/${area}> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/gender> <http://musicbrainz.foo/gender/${gender}> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/comment> "${comment}"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/edits-pending> "${edits_pending}"^^<http://www.w3.org/2001/XMLSchema#int> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/last-updated> "${last_updated}"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
<http://musicbrainz.foo/artist/${id}> <http://musicbrainz.foo/ended> "${ended}"^^<http://www.w3.org/2001/XMLSchema#boolean> .
Massiline üleslaadimine
Soovitatav viis suurte andmemahtude üleslaadimiseks Neptune'i on hulgiüleslaadimise protsess S3 kaudu. Kui teie kolmikfailid on S3-sse üles laaditud, alustate üleslaadimist POST-päringuga. Meie puhul kulus 24 miljoni kolmikfaili laadimiseks umbes 500 tundi. Me eeldasime, et see on kiirem.
curl -X POST -H 'Content-Type: application/json' http://your-neptune-cluster:8182/loader -d '{
"source" : "s3://your-s3-bucket",
"format" : "ntriples",
"iamRoleArn" : "arn:aws:iam::your-iam-user:role/NeptuneLoadFromS3",
"region" : "eu-west-1",
"failOnError" : "FALSE"
}'Selle pika protsessi vältimiseks iga kord, kui Neptune'i käivitame, otsustasime taastada eksemplari hetktõmmisest, kuhu need kolmikud juba laaditud on. Hetktõmmisest käivitamine on oluliselt kiirem, kuid võtab siiski umbes tunni, enne kui Neptune päringuteks saadaval on.
Kolmikute esialgsel laadimisel Neptuuni sattusime mitmesugustesse vigadesse.
{
"errorCode" : "PARSING_ERROR",
"errorMessage" : "Content after '.' is not allowed",
"fileName" : [...],
"recordNum" : 25
}Mõned neist olid parsimisvead, nagu eespool näidatud. Tänase seisuga pole me ikka veel aru saanud, mis täpselt valesti läks. Natuke rohkem üksikasju oleks siinkohal kindlasti abiks. See viga esines umbes 1% sisestatud kolmikute puhul. Aga Neptuuni testimisel oleme leppinud tõsiasjaga, et töötame ainult 99% MusicBrainzi teabega.
Kuigi see pole SPARQL-iga tuttavatele probleem, pidage meeles, et RDF-kolmikud tuleb annoteerida selgesõnaliste andmetüüpidega, mis võib jällegi olla veaohtlik.
Voogesituse allalaadimine
Nagu eespool mainitud, ei taha me Neptune'i kasutada staatilise andmehoidlana, vaid pigem paindliku ja areneva teadmusbaasina. Seega pidime leidma viise uute kolmikute lisamiseks, kui teadmusbaas muutub, näiteks uue albumi ilmumisel või tuletatud teadmiste materialiseerimisel.
Neptune toetab sisestusoperaatoreid SPARQL päringute kaudu, nii toor- kui ka näidispõhiste andmete puhul. Mõlemat lähenemisviisi käsitleme allpool.
Üks meie eesmärkidest oli sisestada andmeid voogedastusviisil. Kaaluge albumi väljaandmist uues riigis. MusicBrainzi vaatenurgast tähendab see, et albumeid, singleid, EP-sid jne sisaldava väljaande puhul lisatakse tabelisse uus kirje. väljalaskeriikRDF-is kaardistame selle teabe kaheks uueks kolmikuks.
INSERT DATA { <http://musicbrainz.foo/release-country/737041> <http://musicbrainz.foo/release> <http://musicbrainz.foo/release/435759> };INSERT DATA { <http://musicbrainz.foo/release-country/737041> <http://musicbrainz.foo/date-year> "2018"^^<http://www.w3.org/2001/XMLSchema#int> };Teine eesmärk oli graafikult uut teavet ammutada. Oletame, et tahame teada saada, mitu väljaannet on iga artist oma karjääri jooksul avaldanud. See päring on üsna keeruline ja võtab Neptune'is rohkem kui 20 minutit, seega peame tulemuse materialiseerima, et seda uut teavet mõnes teises päringus taaskasutada. Seega lisame selle teabega kolmikud tagasi graafikule, sisestades alampäringu tulemuse.
INSERT {
?artist_credit <http://musicbrainz.foo/number-of-releases> ?number_of_releases
} WHERE {
SELECT ?artist_credit (COUNT(*) as ?number_of_releases)
WHERE {
?artist_credit <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist-credit> .
?release_group <http://musicbrainz.foo/artist-credit> ?artist_credit .
?release_group <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/release-group> .
?release_group <http://musicbrainz.foo/name> ?release_group_name .
}
GROUP BY ?artist_credit
}Üksikute kolmikute lisamine graafikule võtab paar millisekundit, samas kui alampäringu tulemuse sisestamise täitmisaeg sõltub alampäringu enda täitmisajast.
Kuigi me seda palju ei kasutanud, võimaldab Neptune teil eemaldada ka kolmikuid valimite või selgesõnaliste andmete põhjal, mida saab kasutada teabe värskendamiseks.
SPARQL päringud
Eelmise alamhulga kasutuselevõtuga, mis tagastab iga esineja väljalasete arvu, oleme juba tutvustanud esimest päringutüüpi, millele tahame Neptune'i abil vastata. Päringu koostamine Neptune'is on lihtne – saatke lihtsalt POST-päring SPARQL-i lõpp-punkti, nagu allpool näidatud:
curl -X POST --data-binary 'query=SELECT ?artist ?p ?o where {?artist <http://musicbrainz.foo/name> "Elton John" . ?artist ?p ?o . }' http://your-neptune-cluster:8182/sparqlLisaks oleme rakendanud päringu, mis tagastab artisti profiili, mis sisaldab teavet tema nime, vanuse või päritoluriigi kohta. Pidage meeles, et artistid võivad olla üksikisikud, ansamblid või orkestrid. Lisaks täiendame neid andmeid teabega artisti aasta jooksul välja antud väljaannete arvu kohta. Sooloartistide puhul lisame ka teabe bändide kohta, mille liige nad igal aastal on olnud.
SELECT
?artist_name ?year
?releases_in_year ?releases_up_year
?artist_type_name ?releases
?artist_gender ?artist_country_name
?artist_begin_date ?bands
?bands_in_year
WHERE {
# Bands for each artist
{
SELECT
?year
?first_artist
(group_concat(DISTINCT ?second_artist_name;separator=",") as ?bands)
(COUNT(DISTINCT ?second_artist_name) AS ?bands_in_year)
WHERE {
VALUES ?year {
1960 1961 1962 1963 1964 1965 1966 1967 1968 1969
1970 1971 1972 1973 1974 1975 1976 1977 1978 1979
1980 1981 1982 1983 1984 1985 1986 1987 1988 1989
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
2010 2011 2012 2013 2014 2015 2016 2017 2018
}
?first_artist <http://musicbrainz.foo/name> "Elton John" .
?first_artist <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist> .
?first_artist <http://musicbrainz.foo/type> ?first_artist_type .
?first_artist <http://musicbrainz.foo/name> ?first_artist_name .
?second_artist <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist> .
?second_artist <http://musicbrainz.foo/type> ?second_artist_type .
?second_artist <http://musicbrainz.foo/name> ?second_artist_name .
optional { ?second_artist <http://musicbrainz.foo/begin-date-year> ?second_artist_begin_date_year . }
optional { ?second_artist <http://musicbrainz.foo/end-date-year> ?second_artist_end_date_year . }
?l_artist_artist <http://musicbrainz.foo/entity0> ?first_artist .
?l_artist_artist <http://musicbrainz.foo/entity1> ?second_artist .
?l_artist_artist <http://musicbrainz.foo/link> ?link .
optional { ?link <http://musicbrainz.foo/begin-date-year> ?link_begin_date_year . }
optional { ?link <http://musicbrainz.foo/end-date-year> ?link_end_date_year . }
FILTER (!bound(?link_begin_date_year) || ?link_begin_date_year <= ?year)
FILTER (!bound(?link_end_date_year) || ?link_end_date_year >= ?year)
FILTER (!bound(?second_artist_begin_date_year) || ?second_artist_begin_date_year <= ?year)
FILTER (!bound(?second_artist_end_date_year) || ?second_artist_end_date_year >= ?year)
FILTER (?first_artist_type NOT IN (<http://musicbrainz.foo/artist-type/2>, <http://musicbrainz.foo/artist-type/5>, <http://musicbrainz.foo/artist-type/6>))
FILTER (?second_artist_type IN (<http://musicbrainz.foo/artist-type/2>, <http://musicbrainz.foo/artist-type/5>, <http://musicbrainz.foo/artist-type/6>))
}
GROUP BY ?first_artist ?year
}
# Releases up to a year
{
SELECT
?artist
?year
(group_concat(DISTINCT ?release_name;separator=",") as ?releases)
(COUNT(*) as ?releases_up_year)
WHERE {
VALUES ?year {
1960 1961 1962 1963 1964 1965 1966 1967 1968 1969
1970 1971 1972 1973 1974 1975 1976 1977 1978 1979
1980 1981 1982 1983 1984 1985 1986 1987 1988 1989
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
2010 2011 2012 2013 2014 2015 2016 2017 2018
}
?artist <http://musicbrainz.foo/name> "Elton John" .
?artist_credit_name <http://musicbrainz.foo/artist-credit> ?artist_credit .
?artist_credit_name <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist-credit-name> .
?artist_credit_name <http://musicbrainz.foo/artist> ?artist .
?artist_credit <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist-credit> .
?release_group <http://musicbrainz.foo/artist-credit> ?artist_credit .
?release_group <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/release-group> .
?release_group <http://musicbrainz.foo/name> ?release_group_name .
?release <http://musicbrainz.foo/release-group> ?release_group .
?release <http://musicbrainz.foo/name> ?release_name .
?release_country <http://musicbrainz.foo/release> ?release .
?release_country <http://musicbrainz.foo/date-year> ?release_country_year .
FILTER (?release_country_year <= ?year)
}
GROUP BY ?artist ?year
}
# Releases in a year
{
SELECT ?artist ?year (COUNT(*) as ?releases_in_year)
WHERE {
VALUES ?year {
1960 1961 1962 1963 1964 1965 1966 1967 1968 1969
1970 1971 1972 1973 1974 1975 1976 1977 1978 1979
1980 1981 1982 1983 1984 1985 1986 1987 1988 1989
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
2010 2011 2012 2013 2014 2015 2016 2017 2018
}
?artist <http://musicbrainz.foo/name> "Elton John" .
?artist_credit_name <http://musicbrainz.foo/artist-credit> ?artist_credit .
?artist_credit_name <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist-credit-name> .
?artist_credit_name <http://musicbrainz.foo/artist> ?artist .
?artist_credit <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/artist-credit> .
?release_group <http://musicbrainz.foo/artist-credit> ?artist_credit .
?release_group <http://musicbrainz.foo/rdftype> <http://musicbrainz.foo/release-group> .
?release_group <http://musicbrainz.foo/name> ?release_group_name .
?release <http://musicbrainz.foo/release-group> ?release_group .
?release_country <http://musicbrainz.foo/release> ?release .
?release_country <http://musicbrainz.foo/date-year> ?release_country_year .
FILTER (?release_country_year = ?year)
}
GROUP BY ?artist ?year
}
# Master data
{
SELECT DISTINCT ?artist ?artist_name ?artist_gender ?artist_begin_date ?artist_country_name
WHERE {
?artist <http://musicbrainz.foo/name> ?artist_name .
?artist <http://musicbrainz.foo/name> "Elton John" .
?artist <http://musicbrainz.foo/gender> ?artist_gender_id .
?artist_gender_id <http://musicbrainz.foo/name> ?artist_gender .
?artist <http://musicbrainz.foo/area> ?birth_area .
?artist <http://musicbrainz.foo/begin-date-year> ?artist_begin_date.
?birth_area <http://musicbrainz.foo/name> ?artist_country_name .
FILTER(datatype(?artist_begin_date) = xsd:int)
}Selle päringu keerukuse tõttu saime punktpäringuid teha ainult konkreetse artisti, näiteks Elton Johni, kuid mitte kõigi artistide kohta. Neptune ei paista seda päringut filtrite lisamisega alamvalikutesse optimeerivat. Seetõttu tuleb iga valikut artisti nime järgi käsitsi filtreerida.
Neptune'il on nii tunnipõhine kui ka IO-põhine hinnakujundus. Testimiseks kasutasime väikseimat Neptune'i eksemplari, mille tunnihind on 0,384 dollarit. Ülaltoodud päringu puhul, mis arvutab ühe töötaja profiili, küsib Amazon meilt kümneid tuhandeid I/O-sid, mis tähendab 0.02 dollari suurust hinda.
Väljund
Esiteks, Amazon Neptune täidab enamiku oma lubadustest. Hallatava teenusena on see graafiline andmebaas, mida on uskumatult lihtne seadistada ja mis saab ilma suurema konfigureerimiseta tööle panna. Siin on meie viis peamist järeldust:
- Massiline üleslaadimine on lihtne, aga aeglane. Seda võivad aga keeruliseks teha mitte eriti abivalmid veateated.
- Voogesituse allalaadimised toetasid kõike, mida ootasime, ja olid mõistlikult kiired
- Päringud on lihtsad, kuid mitte piisavalt interaktiivsed analüütiliste päringute tegemiseks.
- SPARQL päringud tuleb käsitsi optimeerida
- Amazoni tasusid on raske hinnata, kuna SPARQL-päringuga skannitud andmete hulka on keeruline hinnata.
See on praegu kõik. Registreeru .
Allikas: www.habr.com
