

Normalean, produktu komertzialak edo prest egindako kode irekiko alternatibak, hala nola Prometheus + Grafana, Nginx-en funtzionamendua kontrolatzeko eta aztertzeko erabiltzen dira. Aukera ona da monitorizazio edo denbora errealeko analisietarako, baina ez da oso erosoa analisi historikorako. Edozein baliabide ezagunetan, nginx erregistroen datuen bolumena azkar hazten ari da, eta datu kopuru handia aztertzeko, logikoa da zerbait espezializatuagoa erabiltzea.
Artikulu honetan nola erabili dezakezun esango dizut erregistroak aztertzeko, Nginx adibide gisa hartuta, eta datu horietatik panel analitiko bat nola muntatu erakutsiko dut kode irekiko cube.js markoa erabiliz. Hona hemen soluzio-arkitektura osoa:

TL:DR;
.
Erabiltzen dugun informazioa biltzeko , prozesatzeko - и , biltegiratzeko - . Sorta hau erabiliz, nginx erregistroak ez ezik, beste gertaera batzuk ere gorde ditzakezu, baita beste zerbitzu batzuen erregistroak ere. Pieza batzuk zure pilarako antzeko batzuekin ordezka ditzakezu, adibidez, kinesis-en erregistroak zuzenean idatz ditzakezu nginx-etik, fluentd saihestuz edo horretarako logstash erabili.
Nginx erregistroak biltzea
Lehenespenez, Nginx-en erregistroek honelako itxura dute:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"Analiza daitezke, baina askoz errazagoa da Nginx konfigurazioa zuzentzea, JSON-en erregistroak sortzeko:
log_format json_combined escape=json '{ "created_at": "$msec", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"request": "$request", '
'"status": $status, '
'"bytes_sent": $bytes_sent, '
'"request_length": $request_length, '
'"request_time": $request_time, '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" }';
access_log /var/log/nginx/access.log json_combined;S3 biltegiratzeko
Erregistroak gordetzeko, S3 erabiliko dugu. Horri esker, erregistroak leku bakarrean gorde eta azter ditzakezu, Athena-k datuekin zuzenean lan egin dezakeelako S3-n. Geroago artikuluan esango dizut nola gehitu eta prozesatu erregistroak behar bezala, baina lehenik eta behin S3-n ontzi garbi bat behar dugu, eta bertan ez da ezer gordeko. Merezi du aldez aurretik kontuan hartzea zein eskualdetan sortuko duzun zure kuboa, Athena ez baitago eskuragarri eskualde guztietan.
Athena kontsolan zirkuitu bat sortzea
Sortu dezagun taula bat Athena-n erregistroetarako. Idazteko eta irakurtzeko beharrezkoa da Kinesis Firehose erabiltzeko asmoa baduzu. Ireki Athena kontsola eta sortu mahai bat:
SQL taula sortzea
CREATE EXTERNAL TABLE `kinesis_logs_nginx`(
`created_at` double,
`remote_addr` string,
`remote_user` string,
`request` string,
`status` int,
`bytes_sent` int,
`request_length` int,
`request_time` double,
`http_referrer` string,
`http_x_forwarded_for` string,
`http_user_agent` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
's3://<YOUR-S3-BUCKET>'
TBLPROPERTIES ('has_encrypted_data'='false');Kinesis Firehose korrontea sortzea
Kinesis Firehose-k Nginx-etik S3-ra jasotako datuak hautatutako formatuan idatziko ditu, eta direktorioetan banatuko ditu YYYY/MM/DD/HH formatuan. Hau erabilgarria izango da datuak irakurtzerakoan. Fluentd-etik S3-ra zuzenean idatzi dezakezu, noski, baina kasu honetan JSON idatzi beharko duzu, eta hori ez da eraginkorra fitxategien tamaina handia dela eta. Gainera, PrestoDB edo Athena erabiltzean, JSON da datu-formatu motelena. Beraz, ireki Kinesis Firehose kontsola, egin klik "Sortu entrega korrontea", hautatu "JARRI zuzena" "entrega" eremuan:
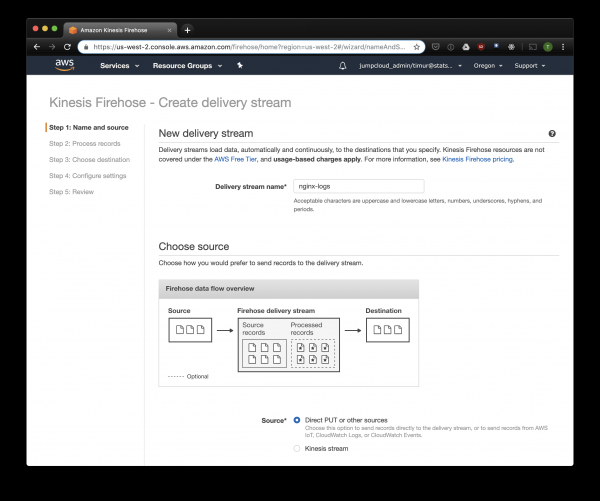
Hurrengo fitxan, hautatu "Grabatu formatuaren bihurketa" - "Gaitu" eta hautatu "Apache ORC" grabazio formatu gisa. Ikerketa batzuen arabera , hau da PrestoDB eta Athenarako formatu egokiena. Goian sortu dugun taula eskema gisa erabiltzen dugu. Kontuan izan S3-ko edozein kokapen zehaztu dezakezula kinesis-en; taulatik eskema soilik erabiltzen da. Baina beste S3 kokapen bat zehazten baduzu, ezin izango dituzu taula honetako erregistro hauek irakurri.
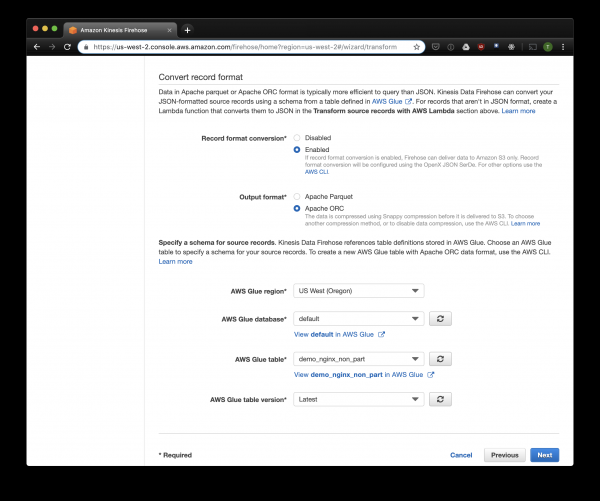
S3 hautatzen dugu biltegiratzeko eta lehenago sortu dugun kuboa. Geroago hitz egingo dudan Aws Glue Crawler-ek ezin du S3 ontzi bateko aurrizkiekin funtzionatu, beraz, garrantzitsua da hutsik uztea.
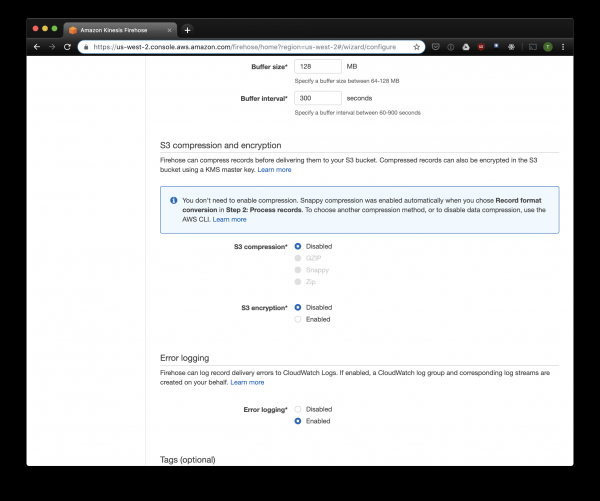
Gainerako aukerak zure kargaren arabera alda daitezke; normalean lehenetsitakoak erabiltzen ditut. Kontuan izan S3 konpresioa ez dagoela erabilgarri, baina ORC-k jatorrizko konpresioa erabiltzen du lehenespenez.
Fluxua
Erregistroak biltegiratzea eta jasotzea konfiguratu dugunean, bidalketa konfiguratu behar dugu. Erabiliko dugu , Ruby maite dudalako, baina Logstash erabil dezakezu edo zuzenean kinesis-era erregistroak bidali. Fluentd zerbitzaria hainbat modutara abiarazi daiteke, dockerri buruz esango dizut, sinplea eta erosoa delako.
Lehenik eta behin, fluent.conf konfigurazio fitxategia behar dugu. Sortu eta gehitu iturria:
aurrera
24224 ataka
lotu 0.0.0.0
Orain Fluentd zerbitzaria abi dezakezu. Konfigurazio aurreratuagoa behar baduzu, joan hona Gida zehatza dago, zure irudia nola muntatu barne.
$ docker run
-d
-p 24224:24224
-p 24224:24224/udp
-v /data:/fluentd/log
-v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd
-c /fluentd/etc/fluent.conf
fluent/fluentd:stableKonfigurazio honek bidea erabiltzen du /fluentd/log erregistroak bidali aurretik gordetzeko. Hau gabe egin dezakezu, baina gero berrabiarazten duzunean, katxean dagoen guztia gal dezakezu atzera-hausturarekin. Edozein ataka ere erabil dezakezu; 24224 Fluentd ataka lehenetsia da.
Orain Fluentd martxan dugula, Nginx erregistroak bidal ditzakegu. Normalean Nginx Docker edukiontzi batean exekutatzen dugu, eta kasu horretan, Docker-ek Fluentd-rako jatorrizko erregistro-gidari bat du:
$ docker run
--log-driver=fluentd
--log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>
--log-opt tag="{{.Name}}"
-v /some/content:/usr/share/nginx/html:ro
-d
nginxNginx modu ezberdinean exekutatzen baduzu, erregistro-fitxategiak erabil ditzakezu Fluentd-ek .
Gehi dezagun goian konfiguratutako erregistro-analisia Fluent konfigurazioari:
<filter YOUR-NGINX-TAG.*>
@type parser
key_name log
emit_invalid_record_to_error false
<parse>
@type json
</parse>
</filter>Eta Kinesis-era erregistroak bidaltzea erabiliz :
<match YOUR-NGINX-TAG.*>
@type kinesis_firehose
region region
delivery_stream_name <YOUR-KINESIS-STREAM-NAME>
aws_key_id <YOUR-AWS-KEY-ID>
aws_sec_key <YOUR_AWS-SEC_KEY>
</match>Athena
Dena behar bezala konfiguratu baduzu, pixka bat igaro ondoren (lehenespenez, Kinesis-ek jasotako datuak 10 minutuz behin erregistratzen ditu) S3-n erregistro-fitxategiak ikusi beharko dituzu. Kinesis Firehose-ren "monitorizazioa" menuan S3-n zenbat datu erregistratzen diren ikus dezakezu, baita akatsak ere. Ez ahaztu Kinesis rolari S3 ontziari idazteko sarbidea ematea. Kinesisek ezin badu zerbait analizatu, akatsak ontzi berean gehituko ditu.
Orain Athena-n datuak ikus ditzakezu. Bila ditzagun akatsak itzuli ditugun azken eskaerak:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;Eskaera bakoitzaren erregistro guztiak eskaneatzea
Orain gure erregistroak prozesatu eta gorde dira S3-n ORC-n, konprimituta eta analisirako prest. Kinesis Firehose-k ordu bakoitzeko direktorioetan ere antolatu zituen. Hala ere, taula partizionatuta ez dagoen bitartean, Athena-k denbora guztietako datuak kargatuko ditu eskaera guztietan, salbuespenak salbuespen. Hau arazo handia da bi arrazoirengatik:
- Datuen bolumena etengabe hazten ari da, kontsultak motelduz;
- Athena eskaneatutako datuen bolumenaren arabera fakturatzen da, eskaera bakoitzeko 10 MB gutxienez.
Hau konpontzeko, AWS Glue Crawler erabiltzen dugu, datuak S3-n arakatuko dituena eta partizioaren informazioa Glue Metastore-ra idatziko duena. Horri esker, partizioak iragazki gisa erabiltzeko aukera izango dugu Athena kontsultatzerakoan, eta kontsultan zehaztutako direktorioak soilik eskaneatu egingo ditu.
Amazon Glue Crawler konfiguratzen
Amazon Glue Crawler-ek S3 ontziko datu guztiak eskaneatzen ditu eta partizioekin taulak sortzen ditu. Sortu Glue Crawler AWS Glue kontsolatik eta gehitu ontzi bat non datuak gordetzeko. Arakatzaile bat erabil dezakezu hainbat ontzitarako, eta kasu horretan, zehaztutako datu-basean taulak sortuko ditu ontzien izenekin bat datozen izenekin. Datu hauek aldizka erabiltzeko asmoa baduzu, ziurtatu Crawler-en abiarazte-egutegia zure beharretara egokitzeko konfiguratzen duzula. Crawler bat erabiltzen dugu mahai guztietarako, orduro exekutatzen dena.
Taulak banatuta
Arakatzailea lehen abiarazi ondoren, eskaneatutako ontzi bakoitzeko taulak ezarpenetan zehaztutako datu-basean agertu beharko lirateke. Ireki Athena kontsola eta aurkitu taula Nginx erregistroekin. Saia gaitezen zerbait irakurtzen:
SELECT * FROM "default"."part_demo_kinesis_bucket"
WHERE(
partition_0 = '2019' AND
partition_1 = '04' AND
partition_2 = '08' AND
partition_3 = '06'
);Kontsulta honek 6ko apirilaren 7ko 8:2019etatik XNUMX:XNUMXetara jasotako erregistro guztiak hautatuko ditu. Baina zenbateraino eraginkorragoa da partizionatu gabeko taula batetik irakurtzea baino? Ikus ditzagun eta hauta ditzagun erregistro berdinak, denbora-zigiluaren arabera iragazten:

3.59 segundo eta 244.34 megabyte datuak datu-multzo batean aste bakarreko erregistroekin. Saia gaitezen partizioaren araberako iragazkia:
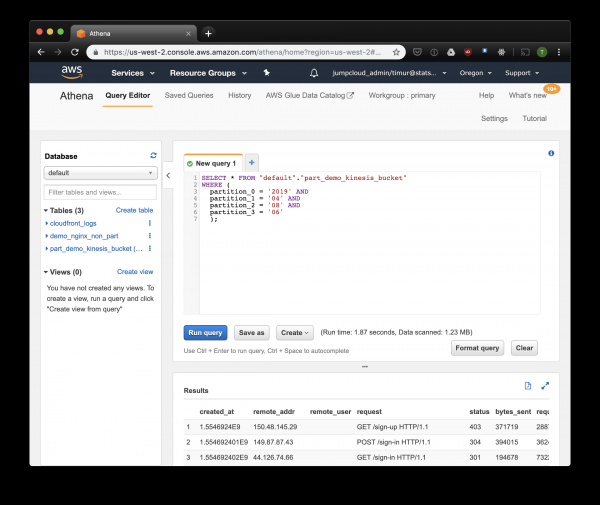
Apur bat azkarrago, baina garrantzitsuena - 1.23 megabyte datuak bakarrik! Askoz merkeagoa litzateke prezioetan eskaera bakoitzeko gutxieneko 10 megabyte ez balitz. Baina oraindik askoz hobea da, eta datu multzo handietan aldea askoz ikusgarriagoa izango da.
Arbel bat eraikitzea Cube.js erabiliz
Aginte-panela muntatzeko, Cube.js marko analitikoa erabiltzen dugu. Funtzio asko ditu, baina bi interesatzen zaizkigu: partizio-iragazkiak automatikoki erabiltzeko gaitasuna eta datuen aurre-agregazioa. Datu-eskema erabiltzen du , Javascript-en idatzia SQL sortzeko eta datu-basearen kontsulta bat exekutatzeko. Datu-eskeman partizio-iragazkia nola erabili soilik adierazi behar dugu.
Sortu dezagun Cube.js aplikazio berri bat. Dagoeneko AWS pila erabiltzen ari garenez, logikoa da inplementatzeko Lambda erabiltzea. Sortzeko txantiloia express erabil dezakezu Cube.js backend-a Heroku edo Docker-en ostatatzeko asmoa baduzu. Dokumentazioak beste batzuk deskribatzen ditu .
$ npm install -g cubejs-cli
$ cubejs create nginx-log-analytics -t serverless -d athenaIngurune-aldagaiak datu-basearen sarbidea konfiguratzeko erabiltzen dira cube.js-en. Sortzaileak .env fitxategi bat sortuko du eta bertan zure gakoak zehaztu ditzakezu .
Orain behar dugu , bertan gure erregistroak nola gordetzen diren zehatz-mehatz adieraziko dugu. Bertan, aginte-paneletarako neurketak nola kalkulatu ere zehaztu dezakezu.
Direktorioan schema, sortu fitxategi bat Logs.js. Hona hemen nginx-erako datu-eredu adibide bat:
Eredu kodea
const partitionFilter = (from, to) => `
date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND
date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d')
`
cube(`Logs`, {
sql: `
select * from part_demo_kinesis_bucket
WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)}
`,
measures: {
count: {
type: `count`,
},
errorCount: {
type: `count`,
filters: [
{ sql: `${CUBE.isError} = 'Yes'` }
]
},
errorRate: {
type: `number`,
sql: `100.0 * ${errorCount} / ${count}`,
format: `percent`
}
},
dimensions: {
status: {
sql: `status`,
type: `number`
},
isError: {
type: `string`,
case: {
when: [{
sql: `${CUBE}.status >= 400`, label: `Yes`
}],
else: { label: `No` }
}
},
createdAt: {
sql: `from_unixtime(created_at)`,
type: `time`
}
}
});Hemen aldagaia erabiltzen ari gara partizio-iragazki batekin SQL kontsulta bat sortzeko.
Arbelean erakutsi nahi ditugun metrika eta parametroak ere ezartzen ditugu eta aurre-agregazioak zehazten ditugu. Cube.js-ek taula gehigarriak sortuko ditu aurrez agregatutako datuekin eta automatikoki eguneratuko ditu datuak iristen diren heinean. Horrek kontsultak bizkortzeaz gain, Athena erabiltzearen kostua murrizten du.
Gehitu informazio hau datu-eskema fitxategira:
preAggregations: {
main: {
type: `rollup`,
measureReferences: [count, errorCount],
dimensionReferences: [isError, status],
timeDimensionReference: createdAt,
granularity: `day`,
partitionGranularity: `month`,
refreshKey: {
sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) =>
`select
CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now()
THEN date_trunc('hour', now()) END`
)
}
}
}Eredu honetan zehazten dugu beharrezkoa dela erabilitako metrika guztien datuak aldez aurretik agregatzea, eta hilabeteka partizioa erabiltzea. datu bilketa eta eguneratzea nabarmen bizkortu ditzake.
Orain aginte-panela muntatu dezakegu!
Cube.js backend-ak eskaintzen du eta bezeroen liburutegi multzo bat front-end esparru ezagunetarako. Bezeroaren React bertsioa erabiliko dugu aginte-panela eraikitzeko. Cube.js-ek datuak soilik eskaintzen ditu, beraz, bistaratze-liburutegi bat beharko dugu - gustatzen zait , baina edozein erabil dezakezu.
Cube.js zerbitzariak eskaera onartzen du , beharrezko neurriak zehazten dituena. Adibidez, Nginx-ek egunean zenbat errore eman dituen kalkulatzeko, eskaera hau bidali behar duzu:
{
"measures": ["Logs.errorCount"],
"timeDimensions": [
{
"dimension": "Logs.createdAt",
"dateRange": ["2019-01-01", "2019-01-07"],
"granularity": "day"
}
]
}Instala ditzagun Cube.js bezeroa eta React osagaien liburutegia NPM bidez:
$ npm i --save @cubejs-client/core @cubejs-client/reactOsagaiak inportatzen ditugu cubejs и QueryRendererdatuak deskargatzeko eta aginte-panela biltzeko:
Arbelaren kodea
import React from 'react';
import { LineChart, Line, XAxis, YAxis } from 'recharts';
import cubejs from '@cubejs-client/core';
import { QueryRenderer } from '@cubejs-client/react';
const cubejsApi = cubejs(
'YOUR-CUBEJS-API-TOKEN',
{ apiUrl: 'http://localhost:4000/cubejs-api/v1' },
);
export default () => {
return (
<QueryRenderer
query={{
measures: ['Logs.errorCount'],
timeDimensions: [{
dimension: 'Logs.createdAt',
dateRange: ['2019-01-01', '2019-01-07'],
granularity: 'day'
}]
}}
cubejsApi={cubejsApi}
render={({ resultSet }) => {
if (!resultSet) {
return 'Loading...';
}
return (
<LineChart data={resultSet.rawData()}>
<XAxis dataKey="Logs.createdAt"/>
<YAxis/>
<Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/>
</LineChart>
);
}}
/>
)
}Arbelaren iturriak helbidean daude eskuragarri .
Iturria: www.habr.com
