


Kaixo guztioi! Nire izena Dmitry Samsonov da, eta Odnoklassnikin sistema administratzaile nagusi gisa lan egiten dut. 7 zerbitzari fisiko baino gehiago ditugu, 11 edukiontzi gure hodeian, eta 200 aplikazio, konfigurazio ezberdinetan 700 kluster desberdin osatzen dituztenak. Zerbitzari gehienak exekutatzen ari dira... CentOS 7.
14ko abuztuaren 2018an, FragmentSmack ahultasunari buruzko informazioa argitaratu zen
() eta SegmentSmack (). Sare-eraso-bektorea eta nahiko puntuazio altua (7.5) dituzten ahultasunak dira, baliabideak agortzeagatik (CPU) zerbitzuaren ukapena (DoS) mehatxatzen dutenak. FragmentSmack-erako nukleoaren konponketarik ez zen proposatu garai hartan; gainera, ahultasunari buruzko informazioa argitaratu baino askoz beranduago atera zen. SegmentSmack kentzeko, nukleoa eguneratzea proposatu zen. Egun berean eguneratze paketea bera kaleratu zen, instalatzea besterik ez zen geratzen.
Ez, ez gaude inola ere nukleoa eguneratzearen aurka! Hala ere, badira ñabardurak...
Nukleoa nola eguneratzen dugun ekoizpenean
Oro har, ez dago ezer konplikatua:
- Deskargatu paketeak;
- Instalatu hainbat zerbitzaritan (gure hodeia hartzen duten zerbitzarietan barne);
- Ziurtatu ezer hautsi ez dela;
- Ziurtatu nukleoaren ezarpen estandar guztiak errorerik gabe aplikatzen direla;
- Itxaron egun batzuk;
- Egiaztatu zerbitzariaren errendimendua;
- Aldatu zerbitzari berrien hedapena nukleo berrira;
- Eguneratu zerbitzari guztiak datu-zentroaren arabera (datu-zentro bat aldi berean erabiltzaileengan eragina gutxitzeko arazoak izanez gero);
- Berrabiarazi zerbitzari guztiak.
Errepikatu ditugun nukleoen adar guztietan. Momentu honetan hauxe da:
- Stocka CentOS 7 3.10 - ohiko zerbitzari gehienentzat;
- Banila 4.19 - guretzat , BFQ, BBR eta abar behar ditugulako;
- Elrepo kernel-ml 5.2 - for , 4.19 portaera ezegonkorra zelako, baina ezaugarri berdinak behar dira.
Asmatuko zenuten bezala, milaka zerbitzari berrabiarazi behar da denbora gehien. Ahultasun guztiak zerbitzari guztientzat kritikoak ez direnez, Internetetik zuzenean eskura daitezkeenak soilik berrabiaraziko ditugu. Hodeian, malgutasuna ez mugatzeko, ez ditugu kanpotik eskura daitezkeen edukiontziak nukleo berri batekin zerbitzari indibidualetara lotzen, baizik eta ostalari guztiak berrabiarazi salbuespenik gabe. Zorionez, han prozedura zerbitzari arruntekin baino sinpleagoa da. Adibidez, estaturik gabeko edukiontziak beste zerbitzari batera mugi daitezke berrabiarazi bitartean.
Hala ere, lan asko dago oraindik, eta hainbat aste iraun ditzake, eta bertsio berriarekin arazorik izanez gero, hilabete batzuk arte. Erasotzaileek oso ondo ulertzen dute hori, beraz, B plan bat behar dute.
FragmentSmack/SegmentSmack. Konponbidea
Zorionez, ahultasun batzuetarako B plan bat existitzen da, eta Workaround deitzen da. Gehienetan, kernel/aplikazioen ezarpenen aldaketa bat da, izan daitezkeen efektuak minimizatzeko edo ahultasunen ustiapena erabat ezabatzeko.
FragmentSmack/SegmentSmack-en kasuan Konponbide hau:
«4MB eta 3MB balio lehenetsiak net.ipv4.ipfrag_high_thresh eta net.ipv4.ipfrag_low_thresh-en alda ditzakezu (eta haien parekoak ipv6 net.ipv6.ipfrag_high_thresh eta net.ipv6.ipfrag_low_thresh-en) 256 kB eta hurrenez hurren. baxuagoa. Testek PUZaren erabileran beherakada txikia edo nabarmena erakusten dute eraso batean hardwarearen, ezarpenen eta baldintzen arabera. Dena den, baliteke errendimenduaren eragina izatea ipfrag_high_thresh=192 byte-ren ondorioz, aldi berean 262144K-ko bi zati bakarrik sartzen baitira berriro muntaketa-ilaran. Adibidez, arriskua dago UDP pakete handiekin lan egiten duten aplikazioak apurtzeko'.
Parametroak berak honela deskribatzen da:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Ez dugu UDP handirik ekoizpen zerbitzuetan. LANean ez dago trafiko zatikaturik; WANen trafiko zatikatua dago, baina ez da esanguratsua. Ez dago seinalerik - Konponbidea zabaldu dezakezu!
FragmentSmack/SegmentSmack. Lehenengo odola
Topatu genuen lehen arazoa hodeiko edukiontziak batzuetan ezarpen berriak partzialki bakarrik aplikatzen zituela izan zen (ipfrag_low_thresh bakarrik), eta batzuetan ez zituztela batere aplikatzen - hasieran huts egiten zuten. Ezin izan da arazoa modu egonkorrean erreproduzitu (ezarpen guztiak eskuz aplikatu dira arazorik gabe). Hasieran edukiontzia zergatik huts egiten duen ulertzea ere ez da hain erraza: ez da akatsik aurkitu. Gauza bat ziur zegoen: ezarpenak atzera botatzeak edukiontzien hutsegiteen arazoa konpontzen du.
Zergatik ez da nahikoa Sysctl ostalarian aplikatzea? Edukiontzia bere sare dedikatuan bizi da Namespace, behintzat edukiontzian ostalaritik desberdina izan daiteke.
Nola aplikatzen dira zehazki Sysctl ezarpenak edukiontzian? Gure edukiontziak pribilegiorik gabekoak direnez, ezin izango duzu Sysctl ezarpenik aldatu edukiontzian bertan sartuta; besterik gabe, ez duzu eskubide nahikorik. Ontziak exekutatzeko, garai hartan gure hodeiak Docker erabiltzen zuen (orain ). Edukiontzi berriaren parametroak APIaren bidez Dockerrera pasatu ziren, beharrezko Sysctl ezarpenak barne.
Bertsioetan bilatzean, Docker APIak akats guztiak ez zituela itzuli ikusi zen (1.10 bertsioan behintzat). Edukiontzia "docker run" bidez abiarazten saiatu ginenean, azkenean zerbait ikusi genuen gutxienez:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Parametroaren balioa ez da baliozkoa. Baina zergatik? Eta zergatik ez du balio batzuetan bakarrik? Kontuan izan da Docker-ek ez duela bermatzen Sysctl parametroak aplikatzen diren ordena (probatutako azken bertsioa 1.13.1 da), beraz, batzuetan ipfrag_high_thresh 256K-n ezartzen saiatu zen ipfrag_low_thresh oraindik 3M zenean, hau da, goiko muga baxuagoa zen. beheko muga baino, eta horrek akatsa ekarri zuen.
Garai hartan, dagoeneko gure mekanismo propioa erabiltzen genuen edukiontzia hasi ondoren birkonfiguratzeko (ontzia izoztu ondoren eta komandoak exekutatzen edukiontziaren izen-espazioan bidez ), eta Sysctl parametroak idazteko ere gehitu genion zati honi. Arazoa konpondu zen.
FragmentSmack/SegmentSmack. Lehen odola 2
Hodeian Workaround-en erabilera ulertzeko denbora izan baino lehen, erabiltzaileen lehen kexa arraroak iristen hasi ziren. Garai hartan, hainbat aste igaro ziren lehen zerbitzarietan Workaround erabiltzen hasi zenetik. Hasierako ikerketak frogatu zuen banakako zerbitzuen aurkako kexak jaso zirela, eta ez zerbitzu horien zerbitzari guztien aurka. Arazoa berriz ere oso zalantzazkoa bihurtu da.
Lehenik eta behin, Sysctl ezarpenak leheneratzea saiatu ginen, baina ez zuen eraginik izan. Zerbitzariaren eta aplikazioaren ezarpenen hainbat manipulaziok ere ez zuten lagundu. Berrabiarazi batek lagundu zuen. Berrabiarazi... Linux lan egiteko baldintza normala bezain ez-naturala zen Windows Garai batean. Funtzionatzen zuen, ordea, eta "kernel akats" bat zela esan genuen Sysctl ezarpen berriak aplikatzerakoan. Zein ergela izan ginen...
Hiru aste geroago arazoa errepikatu zen. Zerbitzari hauen konfigurazioa nahiko erraza zen: Nginx proxy/orekatzaile moduan. Trafiko handirik ez. Sarrerako ohar berria: bezeroen 504 akatsen kopurua egunero handitzen ari da (). Grafikoak zerbitzu honen eguneko 504 errore kopurua erakusten du:
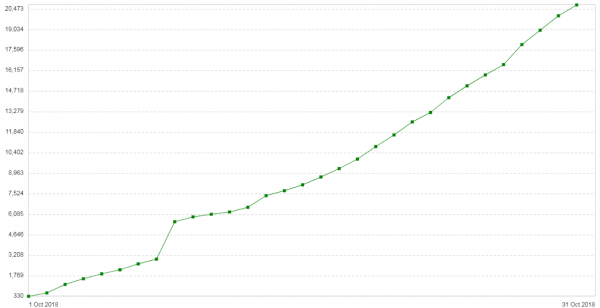
Akats guztiak backend berekoak dira, hodeian dagoenaren ingurukoak. Backend honetako pakete zatien memoria-kontsumoaren grafikoa honelakoa zen:
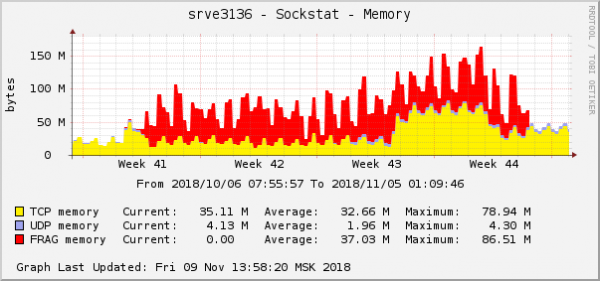
Hau da sistema eragilearen grafikoen arazoaren adierazpen nabarienetako bat. Hodeian, aldi berean, QoS (Trafiko Kontrola) ezarpenekin sareko beste arazo bat konpondu zen. Pakete zatien memoria-kontsumoaren grafikoan, itxura berdina zuen:
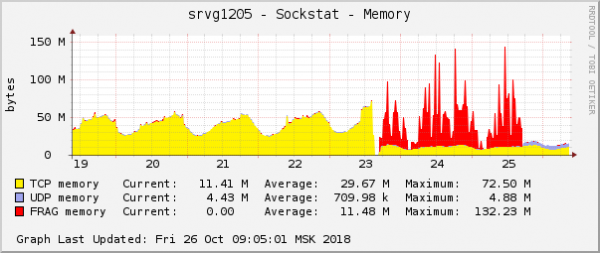
Suposizioa sinplea zen: grafikoetan itxura berdina badute, arrazoi bera dute. Gainera, oroimen mota honekin edozein arazo arraroa da.
Arazo konponduaren funtsa fq paketeen programatzailea QoS-en ezarpen lehenetsiekin erabili genuela izan zen. Lehenespenez, konexio baterako, ilaran 100 pakete gehitzeko aukera ematen du, eta konexio batzuk, kanal eskaseko egoeretan, ilararen edukiera estutzen hasi ziren. Kasu honetan, paketeak kentzen dira. Tc estatistiketan (tc -s qdisc) honela ikus daiteke:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" konexio baten ilararen muga gainditzeagatik eroritako paketeak da, eta "dropped 464545" programatzaile honen eroritako pakete guztien batura da. Ilararen luzera 1 milara handitu eta edukiontziak berrabiarazi ondoren, arazoa gelditu zen. Eser zaitezke eta smoothie bat edan dezakezu.
FragmentSmack/SegmentSmack. Azken odola
Lehenik eta behin, kernelaren ahultasunak iragarri eta hilabete batzuetara, FragmentSmack-erako konponketa bat kaleratu zen azkenean (gogoratu, abuztuko iragarpenak SegmentSmack-erako konponketa bat bakarrik kaleratu zuela), eta horrek Workaround uzteko aukera eman zigun, eta horrek arazo dezente sortu zizkigun. Denbora horretan zerbitzari batzuk kernel berrira migratu genituen jada, eta orain hutsetik hasi behar genuen. Zergatik eguneratu genuen kernela FragmentSmack-en konponketaren zain egon gabe? Egia esan, ahultasun horien aurka babesteko prozesua Workaround eguneratzeko prozesuarekin bat etorri zen (eta batu egin zen). CentOS (kernelaren eguneratzea baino denbora gehiago behar du horrek). Gainera, SegmentSmack ahultasun arriskutsuagoa da, eta konponketa berehala eskuragarri zegoen, beraz, zentzuzkoa zen nolanahi ere. Hala ere, kernela eguneratzea besterik ez zen. CentOS ezin izan genuen FragmentSmack ahultasunagatik agertu zen bitartean CentOS 7.5 bertsioa 7.6 bertsioan bakarrik konpondu zen, beraz, 7.5erako eguneraketa gelditu eta berriro hasi behar izan genuen 7.6rako eguneraketarekin. Hau ere gertatzen da.
Bigarrenik, erabiltzaileen arazoei buruzko kexa arraroak itzuli zaizkigu. Orain ziur badakigu guztiak bezeroetatik gure zerbitzari batzuetara fitxategiak kargatzearekin lotuta daudela. Gainera, masa osoaren karga kopuru oso txikia zerbitzari hauetatik igaro zen.
Goiko istorioan gogoratzen dugunez, Sysctl atzera botatzeak ez zuen lagundu. Berrabiarazteak lagundu du, baina aldi baterako.
Sysctl-i buruzko susmoak ez ziren kendu, baina oraingoan ahalik eta informazio gehien biltzea beharrezkoa izan zen. Bezeroan igoeraren arazoa erreproduzitzeko gaitasun falta ere handia zegoen, gertatzen ari zena zehatzago aztertzeko.
Eskuragarri dauden estatistika eta erregistro guztien analisiak ez gaitu hurbildu zer gertatzen ari zen ulertzera. Arazoa erreproduzitzeko gaitasun falta akutua zegoen, konexio zehatz bat "sentitzeko". Azkenik, garatzaileek, aplikazioaren bertsio berezi bat erabiliz, probako gailu batean arazoen erreprodukzio egonkorra lortzea lortu zuten Wi-Fi bidez konektatzean. Hau aurrerapauso bat izan zen ikerketan. Bezeroa Nginx-era konektatu zen, gure Java aplikazioa zen backend-era proxy-a.
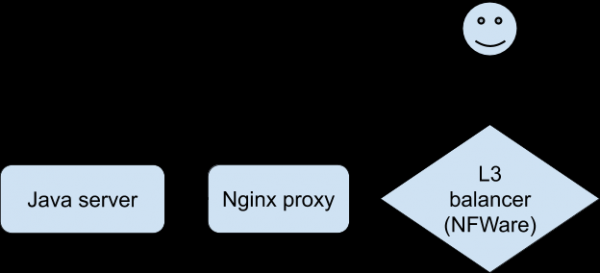
Arazoetarako elkarrizketa honelakoa zen (Nginx proxy aldean konponduta):
- Bezeroa: fitxategi bat deskargatzeari buruzko informazioa jasotzeko eskaera.
- Java zerbitzaria: erantzuna.
- Bezeroa: POST fitxategiarekin.
- Java zerbitzaria: errorea.
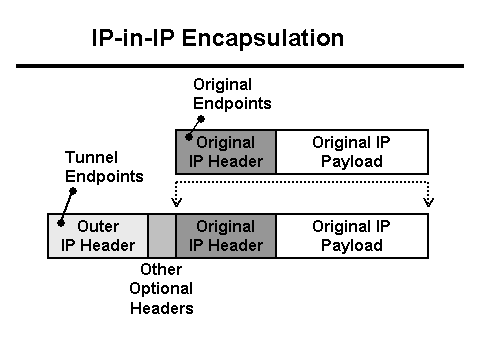
Aldi berean, Java zerbitzariak erregistroan idazten du bezeroarengandik 0 byte datu jaso zirela, eta Nginx proxyak eskaerak 30 segundo baino gehiago behar izan zituela idazten du (30 segundo bezeroaren aplikazioaren denbora-muga da). Zergatik denbora-muga eta zergatik 0 byte? HTTP ikuspegitik, dena behar bezala funtzionatzen du, baina fitxategia duen POST-a saretik desagertzen dela dirudi. Gainera, bezeroaren eta Nginx-en artean desagertzen da. Tcpdump-ekin armatzeko garaia da! Baina lehenik sarearen konfigurazioa ulertu behar duzu. Nginx proxy L3 orekatzailearen atzean dago . Tunneling L3 orekatzailetik zerbitzarira paketeak bidaltzeko erabiltzen da, eta horrek bere goiburuak gehitzen ditu paketeei:
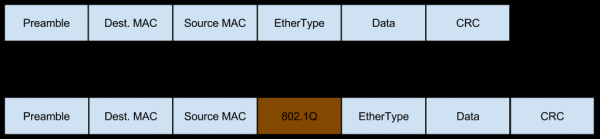
Kasu honetan, sarea zerbitzari honetara iristen da Vlan-en etiketatutako trafiko moduan, eta horrek bere eremuak ere gehitzen ditu paketeei:
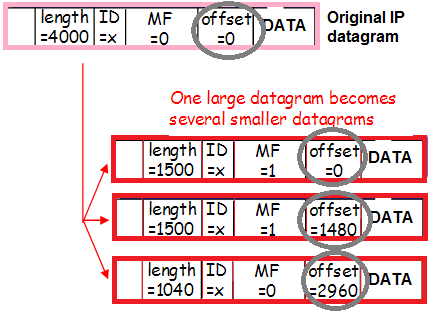
Eta trafiko hori ere zatikatu egin daiteke (Workaround-en arriskuak ebaluatzean hitz egin genuen sarrerako trafiko zatikatuaren ehuneko txiki hori), eta horrek goiburuen edukia ere aldatzen du:
Berriro ere: paketeak Vlan etiketa batekin kapsulatzen dira, tunel batekin kapsulatzen dira, zatituta. Hau nola gertatzen den hobeto ulertzeko, egin dezagun paketeen ibilbidea bezerotik Nginx proxyra.
- Paketea L3 orekatzailera iristen da. Datu-zentroan bideratze zuzena izateko, paketea tunel batean kapsulatzen da eta sare-txartelera bidaltzen da.
- Pakete + tunel goiburuak MTUn sartzen ez direnez, paketea zatitan mozten da eta sarera bidaltzen da.
- L3 orekatzailearen ondorengo etengailuak, pakete bat jasotzean, Vlan etiketa bat gehitzen dio eta bidaltzen du.
- Nginx proxy-aren aurrean dagoen etengailuak zerbitzariak Vlan-en kapsulatutako pakete bat espero duela ikusten du (portuaren ezarpenetan oinarrituta), beraz, dagoen bezala bidaltzen du, Vlan etiketa kendu gabe.
- Linux pakete indibidualen zatiak jasotzen ditu eta pakete handi bakar batean itsasten ditu.
- Ondoren, paketea Vlan interfazera iristen da, non bertatik lehen geruza kentzen den - Vlan enkapsulazioa.
- Ondoren Linux Tunnel interfazera bidaltzen du, eta handik beste geruza bat kentzen zaio - Tunnel enkapsulazioa.
Hori guztia tcpdump-era parametro gisa pasatzea da zailtasuna.
Has gaitezen amaieratik: ba al daude bezeroen IP pakete garbiak (alferrikako goibururik gabe), vlan eta tunel enkapsulazioa kenduta?
tcpdump host <ip клиента>
Ez, ez zegoen horrelako paketerik zerbitzarian. Beraz, arazoa lehenago egon behar da. Ba al dago paketerik Vlan enkapsulazioa bakarrik kenduta?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx bezeroaren IP helbidea da hex formatuan.
32:4 — Tunnel paketean SCR IP idazten den eremuaren helbidea eta luzera.
Eremu helbidea indar gordinaz hautatu behar zen, Interneten 40, 44, 50, 54 inguru idazten baitituzte, baina han ez zegoen IP helbiderik. Hex-eko paketeetako bat ere begiratu dezakezu (-xx edo -XX parametroa tcpdump-en) eta ezagutzen duzun IP helbidea kalkula dezakezu.
Ba al dira pakete zatiak Vlan eta Tunnel enkapsulatu gabe kendu?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Magia honek zati guztiak erakutsiko dizkigu, azkena barne. Seguruenik, gauza bera IP bidez iragazi daiteke, baina ez naiz saiatu, ez baitaude horrelako pakete asko, eta behar ditudanak erraz aurkitzen dira fluxu orokorrean. Hona hemen:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 00:de:ff:1a:94:11 ethertype IPv4 (0x0800) fitxategian, 62. luzera: (tos 0x0, ttl 63, 53652 id, 1480 desplazamendua, banderak [bat ere ez], proto IPIP (4), luzera 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Pakete bateko bi zati dira (ID 53652 bera) argazki batekin (Exif hitza ikusgai dago lehen paketean). Maila honetan paketeak daudelako, baina ez zabortegietan bateratutako forman, arazoa argi eta garbi muntaia da. Azkenean badago horren froga dokumentala!
Pakete deskodetzaileak ez zuen eraikuntza eragozten zuen arazorik agertu. Probatu hemen: . Hasieran, bertan zerbait betetzen saiatzen zarenean, deskodetzaileari ez zaio pakete formatua gustatzen. Sortu zen Srcmac eta Ethertype artean bi zortzikote gehigarri batzuk zeudela (ez dago zatiaren informazioarekin lotuta). Horiek kendu ondoren, deskodetzailea lanean hasi zen. Hala ere, ez zuen arazorik erakutsi.
Zer esanik ez, Sysctl horiek izan ezik beste ezer ez zen aurkitu. Arazo zerbitzariak identifikatzeko modu bat aurkitzea besterik ez zen geratzen, eskala ulertzeko eta ekintza gehiago erabakitzeko. Beharrezko kontagailua nahikoa azkar aurkitu da:
netstat -s | grep "packet reassembles failed”
snmpd-n ere badago OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
"IP berriro muntatzeko algoritmoak detektatu dituen hutsegite kopurua (edozein arrazoi dela medio: denbora-muga, akatsak, etab.)."
Arazoa aztertu den zerbitzari taldeen artean, bitan kontagailu hori azkarrago handitu zen, bitan astiroago eta beste bitan ez zen batere handitu. Kontagailu honen dinamika Java zerbitzariko HTTP akatsen dinamikarekin alderatuz gero, korrelazio bat agertu zen. Hau da, neurgailuaren jarraipena egin liteke.
Arazoen adierazle fidagarri bat edukitzea oso garrantzitsua da Sysctl atzera egiteak laguntzen duen ala ez zehaztasunez zehaztu ahal izateko, aurreko istoriotik badakigu aplikaziotik ezin dela berehala ulertu. Adierazle honek produkzioko arazo-eremu guztiak identifikatzea ahalbidetuko liguke erabiltzaileek ezagutu aurretik.
Sysctl atzera bota ondoren, monitorizazio akatsak gelditu ziren, eta, beraz, arazoen kausa frogatu zen, baita atzera egiteak laguntzen duela ere.
Zatikatze-ezarpenak atzera egin genituen beste zerbitzari batzuetan, non monitorizazio berria sartu zen jokoan, eta nonbait lehen lehenetsitakoa baino memoria gehiago esleitu genion zatiei (hau UDP estatistikak ziren, eta horien galera partziala ez zen atzealde orokorrean nabaritzen). .
Galdera garrantzitsuenak
Zergatik zatitzen dira paketeak gure L3 balantzailean? Erabiltzaileetatik orekatzaileetara iristen diren pakete gehienak SYN eta ACK dira. Pakete hauen tamaina txikiak dira. Baina horrelako paketeen kuota oso handia denez, haien atzealdean ez dugu nabaritu zatitzen hasi ziren pakete handien presentzia.
Arrazoia hautsitako konfigurazio script bat izan zen Vlan interfazeak dituzten zerbitzarietan (garai hartan etiketatutako trafikoa zuten zerbitzari gutxi zeuden ekoizpenean). Advmss-k bezeroari gure norabidean paketeek tamaina txikiagoa izan behar duten informazioa helarazteko aukera ematen digu, tunel-goiburuak erantsi ondoren zatikatu behar ez daitezen.
Zergatik ez zuen Sysctl-en desbideratzeak lagundu, baina berrabiarazteak bai? Sysctl atzera botatzean paketeak bateratzeko erabilgarri dagoen memoria kopurua aldatu du. Aldi berean, itxuraz, zatien memoria gainezkatzeak berak konexioak moteltzea ekarri zuen, eta horrek zatiak ilaran denbora luzez atzeratzea ekarri zuen. Hau da, prozesua zikloka joan zen.
Berrabiarazteak memoria garbitu zuen eta dena ordenara itzuli zen.
Konponbiderik gabe egitea posible al zen? Bai, baina erasoa gertatuz gero erabiltzaileak zerbitzurik gabe uzteko arrisku handia dago. Noski, Workaround erabiltzeak hainbat arazo eragin zituen, besteak beste, erabiltzaileentzako zerbitzuren bat moteltzea, baina hala ere ekintzak justifikatuta zeudela uste dugu.
Mila esker Andrey Timofeev-i () ikerketa egiteko laguntzagatik, baita Alexey Krenev-i ere () - eguneratzeko lan izugarriagatik Centos eta zerbitzarien nukleoak. Kasu honetan, prozesua hainbat aldiz berrabiarazi behar izan zen, eta ondorioz hilabete asko behar izan ziren.
Iturria: www.habr.com
