


Etorkizun urrunean, beharrezkoak ez diren datuak automatikoki kentzea izango da DBMSren zeregin garrantzitsuetako bat [1]. Bitartean, guk geuk arduratu behar dugu beharrezkoak ez diren datuak ezabatzeaz edo kostu gutxiagoko biltegiratze-sistemetara eramateaz. Demagun milioika errenkada batzuk ezabatzea erabakitzen duzula. Nahiko zeregin sinplea, batez ere egoera ezagutzen bada eta indize egoki bat badago. "DELETE FROM table1 WHERE col1 = :value" - zer izan daiteke sinpleagoa, ezta?
Video:


Highload programako batzordean nago lehen urtetik, hau da, 2007tik.
Eta 2005etik nabil Postgres-en. Proiektu askotan erabili zuen.
RuPostges taldearekin ere 2007tik.
Meetup-en 2100 partaide baino gehiago izatera iritsi gara. Munduan bigarrena da New Yorken atzetik, denbora luzez San Frantziskok gaindituta.
Hainbat urtez Kalifornian bizi naiz. Gehiago aritzen naiz Amerikako enpresekin, handiekin barne. Postgres-en erabiltzaile aktiboak dira. Eta era guztietako gauza interesgarri daude.

nire konpainia da. Garapen moteltzeak kentzen dituzten zereginak automatizatzeko negozioan gaude.
Zerbait egiten ari bazara, batzuetan Postgresen inguruan tapoi mota batzuk daude. Demagun administratzaileak proba-base bat ezarri arte itxaron behar duzula edo DBAk erantzun arte itxaron behar duzula. Eta garapen, proba eta administrazio prozesuan halako oztopoak aurkitzen ditugu eta automatizazioaren eta ikuspegi berrien laguntzaz kentzen saiatzen gara.
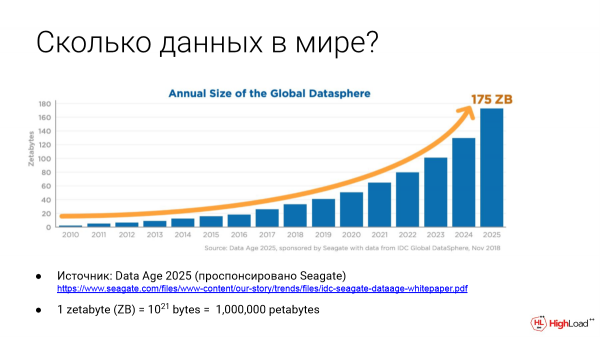
Duela gutxi Los Angeleseko VLDBn egon nintzen. Datu-baseei buruzko hitzaldirik handiena da. Eta etorkizunean DBMS-k datuak gordetzeaz gain, automatikoki ezabatuko dituen txosten bat zegoen. Gai berria da hau.
Gero eta datu gehiago dago zettabyteen munduan, hau da, 1 petabyte. Eta orain jada kalkulatzen da munduan 000 zettabyte baino gehiago datu gordeta ditugula. Eta gero eta gehiago dira.

Eta zer egin horrekin? Argi dago ezabatu egin behar dela. Hona hemen erreportaje interesgarri honetarako esteka. Baina orain arte hori ez da DBMSan ezarri.
Dirua zenbatu dezaketenek bi gauza nahi dituzte. Gu ezabatzea nahi dute, beraz, teknikoki egin ahal izan beharko genuke.

Jarraian kontatuko dudana egoera abstraktu bat da, egoera erreal mordoa barne hartzen dituena, hau da, niri eta inguruko datu-baseei askotan, urte askotan, benetan gertatu zitzaidanaren bilketa moduko bat. Rastelak nonahi daude eta denek zapaltzen dituzte uneoro.

Demagun hazten ari diren oinarri bat edo hainbat oinarri ditugula. Eta disko batzuk, jakina, zaborrak dira. Adibidez, erabiltzailea han hasi zen zerbait egiten, baina ez zuen amaitu. Eta denboraren buruan badakigu amaitu gabeko hori ezin dela gehiago gorde. Hau da, zabor gauza batzuk garbitu nahiko genituzke lekua aurrezteko, errendimendua hobetzeko, etab.

Oro har, zeregina gauza zehatzen kentzea automatizatzea da, taula batzuetan lerro zehatzak.

Eta badugu halako eskaera bat, gaur hitz egingo duguna, hau da, zaborra kentzeari buruz.

Garatzaile esperientziadun bati eskatu genion hori egiteko. Eskaera hau hartu zuen, berak egiaztatu zuen - dena funtzionatzen du. Eszenaratzean probatua - dena ondo dago. Zabaldu - dena funtzionatzen du. Egunean behin exekutatzen dugu - dena ondo dago.

Datu-basea hazten eta hazten da. Eguneko DELETE pixka bat polikiago funtzionatzen hasten da.

Orduan ulertzen dugu orain marketin enpresa bat dugula eta trafikoa hainbat aldiz handiagoa izango dela, beraz, beharrezkoak ez diren gauzak aldi baterako etetea erabakitzen dugu. Eta itzultzea ahaztu.

Hilabete batzuk geroago gogoratu ziren. Eta garatzaile horrek irten edo beste zerbaitekin lanpetuta dago, beste bati itzultzeko agindu zion.
Garatzailean, eszenaratzean egiaztatu zuen - dena ondo dago. Jakina, oraindik pilatutakoa garbitu behar duzu. Dena funtzionatzen duela egiaztatu zuen.

Zer gertatzen da gero? Orduan dena erortzen zaigu. Jaitsi egiten da uneren batean dena erortzen baita. Denak harrituta daude, inork ez du ulertzen zer gertatzen ari den. Eta orduan gertatzen da kontua EZABATU honetan zegoela.

Zerbait gaizki joan da? Hona hemen gaizki egon zitekeenaren zerrenda. Horietatik zein da garrantzitsuena?
Adibidez, ez zegoen berrikuspenik, hau da, DBA adituak ez zuen aztertu. Berehala aurkituko zuen arazoa esperientziadun begi batekin, eta gainera, prod sarbidea du, non hainbat milioi lerro pilatu diren.
Agian zerbait gaizki egiaztatu dute.
Agian hardwarea zaharkituta dago eta oinarri hau berritu behar duzu.
Edo zerbait gaizki dago datu-basean bertan, eta Postgres-etik MySQL-ra pasa behar dugu.
Edo agian zerbait gaizki dago eragiketarekin.
Agian akats batzuk daude lanaren antolaketan eta norbait kaleratu eta jenderik onena kontratatu behar duzu?

Ez zegoen DBA egiaztapenik. DBA bat balego, hainbat milioi lerro hauek ikusiko lituzke eta esperimenturik gabe ere esango luke: "Ez dute hori egiten". Demagun kode hau GitLab-en, GitHub-en balego eta kodea berrikusteko prozesu bat egongo balitz eta DBAren onespenik gabe eragiketa hau prod-en egingo litzatekeela, orduan, jakina, DBAk esango luke: "Hau ezin da egin. ”

Eta esango luke IO diskoarekin arazoak izango dituzula eta prozesu guztiak zoratu egingo direla, blokeoak egon daitezke eta, gainera, hutsune automatikoa blokeatu egingo duzula minutu pilo bat, beraz, hau ez da ona.

Bigarren akatsa - leku okerrean egiaztatu zuten. Ondoren ikusi genuen zabor-datu asko pilatzen zirela prod-ean, baina garatzaileak ez zituen datu-base honetan datu pilatu, eta inork ez zuen zabor hori sortu eszenaratzean. Horren arabera, 1 lerro zeuden azkar funtzionatu zutenak.
Gure probak ahulak direla ulertzen dugu, hau da, eraikitzen den prozesuak ez duela arazorik harrapatzen. Ez zen DB esperimentu egokirik egin.
Esperimentu ezin hobea ekipo berean egiten da. Ez da beti posible hau ekipo berean egin, baina oso garrantzitsua da datu-basearen tamaina osoko kopia bat izatea. Horixe da orain dela hainbat urte predikatzen ari naizena. Eta duela urtebete honetaz hitz egin nuen, dena ikusi dezakezue YouTuben.
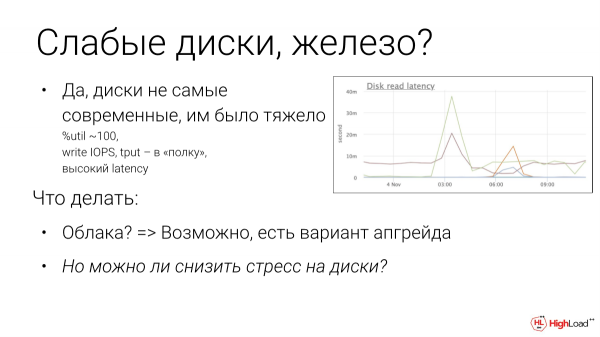
Agian gure ekipoak txarrak dira? Begiratzen baduzu, latentzia salto egin zuen. Erabilera %100ekoa dela ikusi dugu. Jakina, NVMe unitate modernoak balira, seguruenik askoz errazagoa izango litzateke guretzat. Eta agian ez ginateke hortik etzango.
Hodeiak badituzu, berritzea erraz egiten da bertan. Erreplika berriak planteatu ditu hardware berrian. aldaketa. Eta dena ondo dago. Nahiko erraza.
Posible al da disko txikiagoak nolabait ukitzea? Eta hemen, DBAren laguntzarekin, kontrol-puntuaren sintonizazioa izeneko gai jakin batean murgilduko gara. Ikusten da ez genuela kontrol-puntuaren sintonizazioa.
Zer da checkpoint? Edozein DBMStan dago. Memorian aldatzen diren datuak dituzunean, ez dira berehala diskoan idazten. Datuak aldatu diren informazioa idatzi aurretik idazten da erregistroan. Eta noizbait, DBMS-k erabakitzen du benetako orrialdeak diskora botatzeko garaia dela, eta horrela hutsegite bat izanez gero, BERRIKIZUN gutxiago egin dezakegu. Jostailu bat bezalakoa da. Hiltzen bagara, azken kontrol-puntutik hasiko dugu jokoa. Eta DBMS guztiek inplementatzen dute.
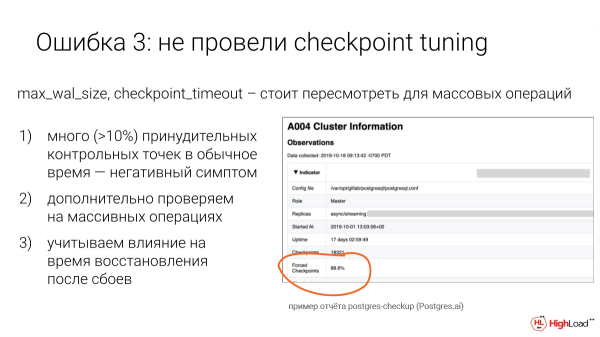
Postgres-en ezarpenak atzeratuta daude. 10-15 urteko datu eta transakzio bolumenetarako diseinatuta daude. Eta checkpoint ez da salbuespena.
Hona hemen gure Postgres-en egiaztapen-txostenaren informazioa, hau da, osasun-kontrol automatikoa. Eta hona hemen hainbat terabyteko datu-base bat. Eta ondo ikus daiteke kontrol-puntuak behartu zituela kasuen ia %90ean.
Zer esan nahi du? Bertan bi ezarpen daude. Kontrol-puntua denbora-mugarekin etor daiteke, adibidez, 10 minututan. Edo datu asko bete direnean etor daiteke.
Eta lehenespenez max_wal_saze 1 gigabyte-n ezartzen da. Izan ere, hau benetan gertatzen da Postgres-en 300-400 megabyteren ondoren. Hainbeste datu aldatu dituzu eta zure kontrol-puntua gertatzen da.
Eta inork sintonizatu ez badu, eta zerbitzua hazi eta konpainiak diru asko irabazten badu, transakzio asko ditu, orduan kontrol-puntua minutuan behin etortzen da, batzuetan 30 segundotan behin, eta batzuetan gainjartzen dira. Hau nahiko txarra da.
Eta gutxiagotan etortzen dela ziurtatu behar dugu. Hau da, max_wal_size igo dezakegu. Eta gutxiagotan etorriko da.
Baina metodologia oso bat garatu dugu zuzenago egiteko, hau da, ezarpenak aukeratzeko erabakia nola hartu, argi eta garbi datu zehatzetan oinarrituta.

Horren arabera, datu-baseetan bi esperimentu-sail egiten ari gara.
Lehenengo seriea - max_wal_size aldatzen dugu. Eta operazio itzela egiten ari gara. Lehenik eta behin, 1 gigabyte-ren ezarpen lehenetsian egiten dugu. Eta milioika lerro asko EZABATZEA egiten dugu.
Ikusten duzue zein zaila den guretzat. Disko IO oso txarra dela ikusten dugu. Ea zenbat WAL sortu dugun, hau oso garrantzitsua baita. Ea zenbat aldiz gertatu den kontrol-puntua. Eta ikusten dugu ez dela ona.
Ondoren, max_wal_size handituko dugu. Errepikatzen dugu. Handitzen gara, errepikatzen dugu. Eta hainbeste aldiz. Printzipioz, 10 puntu ona da, non 1, 2, 4, 8 gigabyte. Eta sistema jakin baten portaera aztertzen dugu. Argi dago hemen ekipoak produktuan bezala egon behar duela. Disko berdinak, memoria kopuru bera eta Postgres ezarpen berdinak izan behar dituzu.
Eta modu honetan gure sistema trukatuko dugu, eta badakigu DBMS-ak nola jokatuko duen masa txarren bat EZABATZEA, nola kontrol-puntua izango den.
Errusieraz kontrol-puntuak kontrol-puntuak dira.
Adibidea: EZABATU hainbat milioi errenkada indizearen arabera, errenkadak "sakabanatuta" daude orrialdeetan.
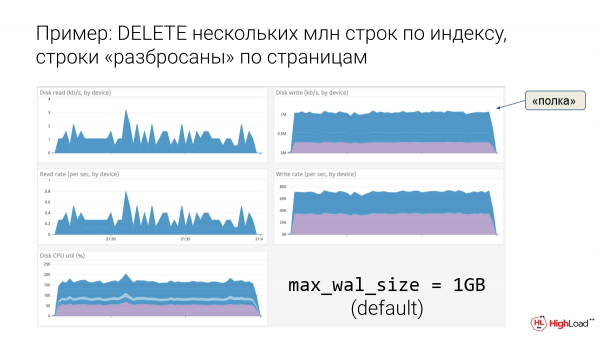
Hona hemen adibide bat. Hau da oinarri batzuk. Eta max_wal_size 1 gigabyte-ren ezarpen lehenetsiarekin, oso argi dago gure diskoak apalategira doazela grabatzera. Irudi hau gaixo oso gaixo baten sintoma tipikoa da, hau da, benetan gaizki sentitu zen. Eta eragiketa bakarra zegoen, hainbat milioi lerrotako DELETE bat besterik ez zegoen.
Prod-en horrelako eragiketa bat onartzen bada, orduan eroriko gara, argi baitago EZABATU batek apalean hiltzen gaituela.
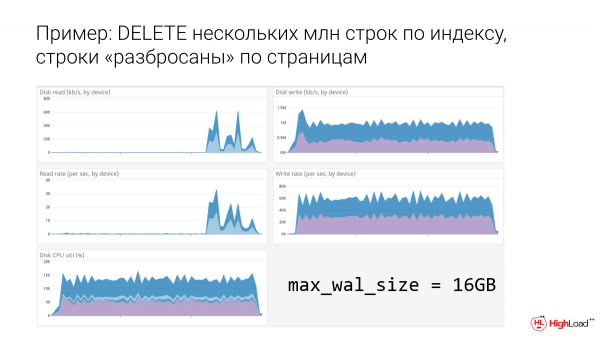
Gainera, non 16 gigabyte, argi dago hortzak dagoeneko joan direla. Hortzak jada hobeak dira, hau da, sabaia jotzen ari gara, baina ez hain gaizki. Askatasun pixka bat zegoen han. Eskuinean diskoa dago. Eta eragiketa kopurua - bigarren grafikoa. Eta argi dago jada arnasa apur bat errazago ari garela 16 gigabyte.
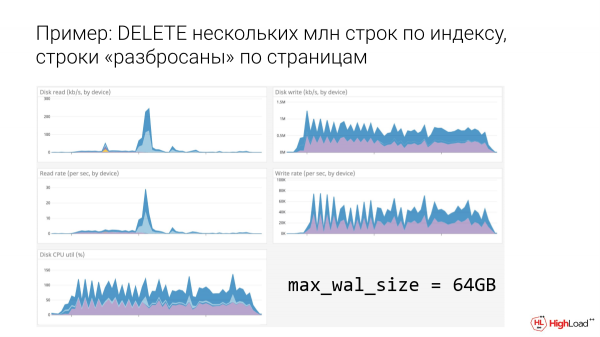
Eta non 64 gigabyte guztiz hobetu dela ikus daiteke. Dagoeneko hortzak ahoskatuta daude, beste eragiketa batzuk bizirik irauteko eta diskoarekin zerbait egiteko aukera gehiago daude.
Zergatik da hori?

Xehetasunetan murgilduko naiz pixka bat, baina gai honek, kontrol-puntuaren sintonizazioa nola egin, txosten oso bat sor dezake, beraz, ez dut asko kargatuko, baina apur bat azalduko dut zein zailtasun dauden.
Kontrol-puntua maiz gertatzen bada, eta gure lerroak ez sekuentzialki eguneratzen baditugu, baina indizearen arabera aurkitzen baditugu, eta hori ona da, ez dugulako taula osoa ezabatzen, orduan gerta liteke hasieran lehenengo orria ukitzea, gero milarena, eta gero lehenengora itzuli zan . Eta lehen orrialdera egindako bisita horien artean, checkpoint-ak dagoeneko diskoan gorde badu, berriro gordeko du, bigarren aldiz zikindu dugulako.
Eta kontrol-puntua askotan salbatzera behartuko dugu. Nola izango ziren berarentzat eragiketa soberangarriak.

Baina hori ez da guztia. Postgres-en, orrialdeek 8 kilobyte pisatzen dute, eta Linux 4 kilobyte. Eta full_page_writes ezarpena dago. Berez gaituta dago. Eta hori gauza ona da, desgaitzen badugu, arriskua baitago kraskatzen bada, orrialdearen erdia bakarrik gordeko dela.
Aurrerapen-erregistroaren WAL-an idazteko portaera halakoa da, kontrol-puntu bat dugunean eta orria lehen aldiz aldatzen dugunean, orrialde osoa, hau da, 8 kilobyte guztiak, aurrerapen-erregistroan sartzen dira, nahiz eta guk bakarrik aldatu. lerroa, 100 byte pisatzen duena. Eta orrialde osoa idatzi behar dugu.
Ondorengo aldaketetan tupla zehatz bat bakarrik egongo da, baina lehen aldiz dena idazten dugu.
Eta, horren arabera, kontrol-puntua berriro gertatuko balitz, orduan dena hutsetik berriro hasi eta orrialde osoa bultzatu beharko dugu. Sarritan kontrol-puntuekin, orrialde berdinetan zehar ibiltzen garenean, full_page_writes = on izan daitekeena baino gehiago izango da, hau da, WAL gehiago sortzen dugu. Gehiago bidaltzen da errepliketara, artxibora, diskora.
Eta, horren arabera, bi kaleratze ditugu.

Max_wal_size handitzen badugu, egiaztatzen da bai checkpoint eta wal writer-entzat errazagoa izango dela. Eta hori bikaina da.
Jar dezagun terabyte bat eta bizi gaitezen. Zer da txarra? Hau txarra da, hutsegiterik gertatuz gero orduz igoko baikara, kontrol-puntua aspaldikoa zelako eta asko aldatu delako jada. Eta hori guztia BERRIZ egin behar dugu. Eta horrela egiten dugu bigarren esperimentu sorta.
Eragiketa bat egiten dugu eta kontrol-puntua bukatzear dagoenean ikusten dugu, nahita hiltzen dugu -9 Postgres.
Eta horren ostean berriro hasten gara, eta ikusiko dugu zenbat denbora igoko den ekipo honetan, hau da, zenbat BERRIZ egingo duen egoera txar honetan.
Bi aldiz ohartuko naiz egoera txarra dela. Lehenik eta behin, kontrol-gunea amaitu baino lehen erori ginen, beraz, asko dugu galtzeko. Eta bigarrenik, operazio handia egin genuen. Eta kontrol-puntuak denbora-mugan egonez gero, ziurrenik, WAL gutxiago sortuko litzateke azken kontrol-puntutik. Hau da, galtzaile bikoitza da.
Egoera hori max_wal_size tamaina desberdinetarako neurtzen dugu eta ulertzen dugu max_wal_size 64 gigabyte bada, kasu txarren bikoitzean 10 minutuz igoko garela. Eta pentsatzen dugu komeni zaigun ala ez. Hau negozio galdera bat da. Argazki hau negozio-erabakien arduradunei erakutsi behar diegu eta galdetu: “Noiz arte etzan gaitezke gehienez arazoren bat izanez gero? Egoera txarrenean etzan gaitezke 3-5 minutuz? Eta erabaki bat hartzen duzu.
Eta hemen puntu interesgarri bat dago. Patroniri buruzko erreportaje pare bat ditugu jardunaldietan. Eta agian erabiltzen ari zara. Hau Postgres-en hutsegite automatikoa da. GitLab eta Data Egret-ek honetaz hitz egin zuten.
Eta 30 segundotan etortzen den hutsegite automatiko bat baduzu, agian 10 minutuz etzan gaitezke? Une honetarako erreplikara aldatuko garelako, eta dena ondo egongo da. Hau eztabaidagarria da. Ez dakit erantzun argirik. Nik uste dut gai hau ez dela hutsegiteen berreskurapenaren inguruan soilik.
Porrot baten ondoren susperraldi luzea badugu, beste hainbat egoeratan deseroso egongo gara. Adibidez, esperimentu berdinetan, zerbait egiten dugunean eta batzuetan 10 minutu itxaron behar izaten dugunean.
Oraindik ez nintzateke urrutira joango, hutsegite automatikoa badugu ere. Oro har, 64, 100 gigabyte bezalako balioak balio onak dira. Batzuetan gutxiago aukeratzeak ere merezi du. Oro har, zientzia sotila da hau.

Iterazioak egiteko, adibidez, max_wal_size =1, 8, masa-eragiketa askotan errepikatu behar duzu. Egin duzu. Eta oinarri berean berriro egin nahi duzu, baina dagoeneko dena ezabatu duzu. Zer egin?
Geroago hitz egingo dut gure konponbideari buruz, zer egiten dugun horrelako egoeretan errepikatzeko. Eta hau da planteamendurik zuzenena.
Baina kasu honetan, zortea izan dugu. Hemen dioen bezala "HASI, EZABATU, ATZERATU", EZABATU errepikatu dezakegu. Hau da, guk geuk bertan behera uzten badugu, errepikatu dezakegu. Eta fisikoki zuregan datuak leku berean egongo dira. Ez duzu puztu ere egiten. Horrelako DELETEen gainean errepika dezakezu.
ROLLBACK-ekin DELETE hau aproposa da kontrol-puntuak doitzeko, nahiz eta behar bezala zabaldutako datu-baseko laborategirik ez izan.

"i" zutabe batekin plaka bat egin dugu. Postgres-ek erabilgarritasun-zutabeak ditu. Ikusezinak dira berariaz eskatu ezean. Hauek dira: ctid, xmid, xmax.
Ctid helbide fisikoa da. Zero orrialdea, orrialdeko lehen tupla.
Ikusten da ROOLBACK ondoren tupla leku berean geratu zela. Hau da, berriro saia gaitezke, berdin jokatuko du. Hau da gauza nagusia.
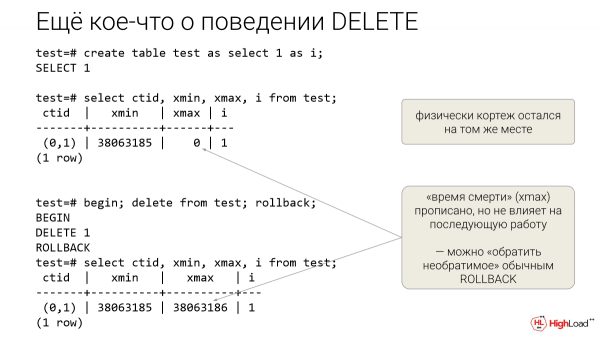
Xmax tuplaren heriotza-ordua da. Zigilua izan zen, baina Postgres-ek badaki transakzioa atzera egin zela, beraz, berdin du 0 den edo atzera botatako transakzio bat den. Horrek iradokitzen du DELETE gainean errepikatu eta sistemaren portaeraren eragiketa masiboak egiaztatzea posible dela. Pobreentzako datu base-laborategiak egin ditzakezu.

Hau programatzaileei buruzkoa da. DBAri buruz ere beti errieta egiten diete programatzaileei horregatik: “Zergatik egiten dituzu hain eragiketa luze eta zailak?”. Gai perpendikular guztiz ezberdina da hau. Lehen administrazioa zegoen, eta orain garapena izango da.
Jakina, ez gara zatitan hautsi. Garbi dago. Ezinezkoa da DELETE ez apurtzea milioika lerro pila bat zatitan. 20 minutuz egingo da, eta dena etzango da. Baina, zoritxarrez, esperientziadun garatzaileek ere akatsak egiten dituzte, baita enpresa handietan ere.
Zergatik da garrantzitsua haustea?
Diskoa gogorra dela ikusten badugu, moteldu dezagun. Eta apurtzen bagara, orduan etenaldiak gehi ditzakegu, moteldu ditzakegu throttling.
Eta ez ditugu beste batzuk blokeatuko denbora luzez. Zenbait kasutan ez du axola, inork lantzen ez duen benetako zaborra ezabatzen ari bazara, ziurrenik ez duzu inor blokeatuko huts automatikoaren lana izan ezik, transakzioa amaitu arte itxarongo baita. Baina beste norbaitek eska dezakeen zerbait kentzen baduzu, blokeatu egingo da, kate-erreakzio moduko bat izango da. Webguneetan eta mugikorreko aplikazioetan transakzio luzeak saihestu behar dira.

Hau interesgarria da. Askotan ikusten dut garatzaileek galdetzen dutela: "Zein pakete tamaina aukeratu behar dut?".
Argi dago sortaren tamaina zenbat eta handiagoa izan, orduan eta txikiagoa izango da transakzio-gastua, hau da, transakzioen gainkostua. Baina, aldi berean, transakzio honetarako denbora handitzen da.
Oso arau sinple bat dut: hartu ahal duzun guztia, baina ez pasa segundoko exekutagarriak.
Zergatik segundo bat? Azalpena oso sinplea eta ulergarria da guztiontzat, baita teknikoa ez den jendearentzat ere. Erreakzio bat ikusten dugu. Har ditzagun 50 milisegundo. Zerbait aldatu bada, orduan gure begiak erreakzionatuko du. Gutxiago bada, orduan zailagoa. Zerbaitek 100 milisegundoren buruan erantzuten badu, adibidez, sagua sakatu baduzu, eta 100 milisegundoren buruan erantzun dizu, atzerapen txiki hori sentitzen duzu jada. Segundo bat balazta gisa hautematen da jada.
Horren arabera, gure operazio masiboak 10 segundoko eztandatan zatitzen baditugu, orduan norbait blokeatzeko arriskua dugu. Eta segundo batzuetan funtzionatuko du, eta jendeak dagoeneko nabarituko du. Horregatik, nahiago dut segundo bat baino gehiago ez egitea. Baina, aldi berean, ez hautsi oso fin, transakzio gainkostua nabaria izango delako. Oinarria gogorragoa izango da, eta beste arazo ezberdin batzuk sor daitezke.
Paketearen tamaina aukeratzen dugu. Kasu bakoitzean, ezberdin egin dezakegu. Automatizatu daiteke. Eta pakete baten prozesamenduaren eraginkortasunaz sinetsita gaude. Hau da, pakete baten DELETE edo UPDATE egiten dugu.
Bide batez, hitz egiten ari naizen guztia ez da EZABATZEA soilik. Asmatu duzuen bezala, datuei buruzko edozein eragiketa dira.
Eta plana bikaina dela ikusten dugu. Indizearen eskaneamendua ikus dezakezu, indizea soilik eskaneatzea are hobea da. Eta datu kopuru txiki bat dugu tartean. Eta segundo bat baino gutxiago betetzen du. Super.
Eta oraindik degradaziorik ez dagoela ziurtatu behar dugu. Gertatzen da lehenengo paketeak azkar funtzionatzen duela, eta gero gero eta okerrago. Prozesua asko probatu behar duzula da. Hau da, hain zuzen, datu base-laborategiak.
Eta oraindik ere zerbait prestatu behar dugu ekoizpenean hori zuzen jarraitzeko aukera izan dezan. Adibidez, erregistroan ordua idatz dezakegu, orain non gauden eta orain ezabatu dugun idatz dezakegu. Eta horrek aurrerago zer gertatzen den ulertzeko aukera emango digu. Eta zerbait gaizki aterako balitz, azkar aurkitu arazoa.
Eskaeren eraginkortasuna egiaztatu behar badugu eta hainbat aldiz errepikatu behar badugu, bada lankide bot bat. Dagoeneko prest dago. Dozenaka garatzailek erabiltzen dute egunero. Eta badaki terabyte datu-base erraldoi bat 30 segundotan eskaintzean ematen, zure kopia. Eta han zerbait ezabatu eta RESET esan eta berriro ezabatu. Modu honetan esperimentatu dezakezu. Etorkizuna ikusten diot gauza honi. Eta dagoeneko egiten ari gara.

Zeintzuk dira zatiketa estrategiak? Garatzaileek paketean erabiltzen dituzten 3 partizio estrategia desberdin ikusten ditut.
Lehenengoa oso sinplea da. Zenbakizko ID bat dugu. Eta zatitu dezagun tarte ezberdinetan eta lan egin dezagun. Alde txarra argi dago. Lehenengo segmentuan, benetako zabor 100 lerro izan ditzakegu, bigarrenean 5 lerro edo batere ez, edo 1 lerro guztiak zabor bihurtuko dira. Oso lan irregularra, baina apurtzea erraza da. Identifikazio maximoa hartu eta apurtu egin zuten. Hau planteamendu inozoa da.
Bigarren estrategia ikuspegi orekatua da. Gitlab-en erabiltzen da. Mahaia hartu eta miatu zuten. Identifikazio paketeen mugak aurkitu genituen, pakete bakoitzak zehazki 10 erregistro zituen. Eta ilaran jarri. Eta gero prozesatzen dugu. Hau hainbat haritan egin dezakezu.
Lehen estrategian ere, bide batez, hainbat haritan egin dezakezu. Ez da zaila.

Baina ikuspegi freskoagoa eta hobea dago. Hau da hirugarren estrategia. Eta ahal denean, hobe da aukeratzea. Indize berezi batean oinarrituta egiten dugu. Kasu honetan, ziurrenik gure zabor egoeraren eta IDaren araberako indize bat izango da. IDa sartuko dugu indizea soilik eskaneatzea izan dadin, pilara joan ez gaitezen.
Orokorrean, indizea soilik eskaneatzea indizea baino azkarragoa da.
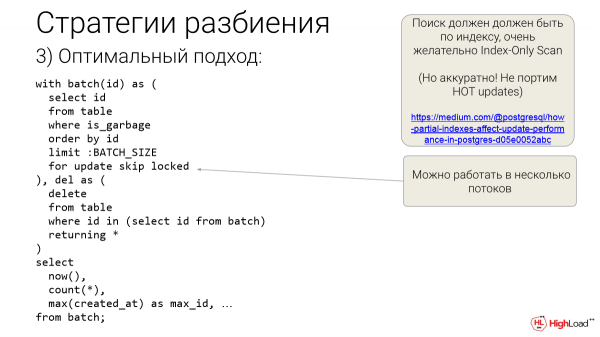
Eta azkar aurkitzen ditugu ezabatu nahi ditugun IDak. BATCH_SIZE aldez aurretik hautatzen ditugu. Eta lortu ez ezik, modu berezi batean lortzen ditugu eta berehala hackeatzen ditugu. Baina blokeatzen ari gara, dagoeneko blokeatuta badaude, ez ditugu blokeatzen, baizik eta aurrera egin eta hurrengoak hartu. Hau eguneratzea saltatzeko blokeatuta dago. Postgres-en super ezaugarri honek hainbat haritan lan egiteko aukera ematen digu nahi badugu. Korronte batean posible da. Eta hemen CTE bat dago - hau da eskaera bat. Eta benetako ezabaketa bat dugu CTE honen bigarren solairuan - returning *. ID itzul dezakezu, baina hobe da *lerro bakoitzean datu askorik ez baduzu.

Zergatik behar dugu? Hau da jakinarazi behar duguna. Hainbeste lerro ezabatu ditugu orain. Eta ertzak ditugu ID edo honelako create_at arabera. Gutxienez, gehienez egin dezakezu. Beste zerbait egin daiteke. Hemen gauza asko egin ditzakezu. Eta monitorizaziorako oso erosoa da.
Indizeari buruzko ohar bat gehiago dago. Zeregin honetarako indize berezi bat behar dugula erabakitzen badugu, ziurtatu behar dugu ez dituela tupleen eguneraketak soilik hondatzen. Hau da, Postgresek baditu halako estatistikak. Hau zure taularako pg_stat_user_tables atalean ikus daiteke. Eguneratze beroak erabiltzen ari diren edo ez ikus dezakezu.
Badira zure indize berriak moztu ditzaketen egoerak. Eta dagoeneko lanean ari diren beste eguneratze guztiak dituzu, moteldu. Ez aurkibidea agertu delako bakarrik (indize bakoitzak eguneraketak pixka bat moteltzen ditu, baina pixka bat), baina hemen oraindik hondatzen du. Eta ezinezkoa da taula honetarako optimizazio berezia egitea. Hau batzuetan gertatzen da. Inor gutxik gogoratzen duen sotiltasun hori da. Eta arrastel hau erraza da zapaltzea. Batzuetan gertatzen da beste alde batetik hurbilketa bat bilatu behar duzula eta oraindik indize berri hori gabe egin, edo beste indize bat egin, edo beste modu batean, adibidez, bigarren metodoa erabil dezakezu.
Baina hau da estrategiarik onena, nola zatitu loteetan eta loteetan tiro egin eskaera batekin, pixka bat ezabatu, etab.

Transakzio luzeak
Auto-hutsean blokeatuta -
blokeatzeko arazoa -
5. akatsa handia da. Okmeter-eko Nikolaik Postgresen monitorizazioari buruz hitz egin zuen. Postgresen jarraipen ideala, zoritxarrez, ez da existitzen. Batzuk gertuago daude, beste batzuk urrunago. Okmeter perfektua izatetik gertu dago, baina asko falta da eta gehitu behar da. Horretarako prest egon behar duzu.
Adibidez, hildako tuplak kontrolatzen dira onena. Mahaian hildako gauza asko badituzu, zerbait gaizki dago. Hobe da orain erreakzionatzea, bestela degradazioa egon daiteke, eta etzan gaitezke. Gertatzen da.
IO handi bat badago, argi dago hori ez dela ona.
Transakzio luzeak ere bai. Transakzio luzeak ez dira onartu behar OLTPn. Eta hona hemen zati hau hartu eta transakzio luzeen jarraipena egiteko aukera ematen dizun zati baterako esteka.
Zergatik dira txarrak transakzio luzeak? Sarraila guztiak amaieran bakarrik askatuko direlako. Eta guztiok izorratzen ditugu. Gainera, mahai guztietarako hutsune automatikoa blokeatzen dugu. Ez da batere ona. Erreplikan erreserba beroa gaituta baduzu ere, txarra da oraindik. Oro har, inon ez da hobe transakzio luzeak saihestea.
Xurgatzen ez diren mahai asko baditugu, alerta bat izan behar dugu. Hemen horrelako egoera bat posible da. Auto-hutsean funtzionamenduan zeharka eragin dezakegu. Hau Avitoren zati bat da, zertxobait hobetu dudana. Eta tresna interesgarria izan da auto-hutsarekin zer daukagun ikusteko. Adibidez, mahai batzuk bertan daude zain eta ez dute txandaren zain egongo. Monitorizazioan ere jarri eta alerta bat izan behar duzu.
Eta gai blokeak. Bloke zuhaitzen basoa. Norbaiti zerbait hartu eta hobetzea gustatzen zait. Hemen Data Egret-en CTE errekurtsibo fresko bat hartu nuen, blokeo zuhaitzen baso bat erakusten duena. Diagnostiko tresna ona da. Eta bere oinarrian, monitorizazioa ere eraiki dezakezu. Baina hau kontu handiz egin behar da. Zuretzat statement_timeout txiki bat egin behar duzu. Eta lock_timeout desiragarria da.

Batzuetan, akats horiek guztiak baturrean gertatzen dira.
Nire ustez, hemen akats nagusia antolakuntza da. Antolatzailea da, teknikak ez baitu tira egiten. Hau 2. zenbakia da - leku okerrean egiaztatu dute.
Okerreko lekuan egiaztatu dugu, ez genuelako produkzio-klonirik, egiaztatzea erraza dena. Baliteke garatzaile batek produkziorako sarbiderik ez izatea.
Eta ez dugu han egiaztatu. Han egiaztatu izan bagenu, guk geuk ikusiko genuke. Garatzaileak dena ikusi zuen DBArik gabe ere ingurune on batean egiaztatu bazuen, non datu kopuru bera eta kokapen berdina dagoen. Degradazio hori guztia ikusiko zuen eta lotsatu egingo zen.
Auto-hutsean buruzko informazio gehiago. Hainbat milioi lerroko miaketa masiboa egin ondoren, oraindik REPACK egin behar dugu. Hau bereziki garrantzitsua da indizeetarako. Han dena garbitu ondoren gaizki sentituko dira.
Eta eguneroko garbiketa lanak berreskuratu nahi badituzu, maizago egitea proposatuko nuke, baina txikiagoa. Minutu batean behin izan daiteke edo, are gehiago, pixka bat. Eta bi gauza kontrolatu behar dituzu: gauza honek ez duela akatsik eta ez dela atzean geratzen. Erakutsi dudan trikimailuak hau konponduko du.
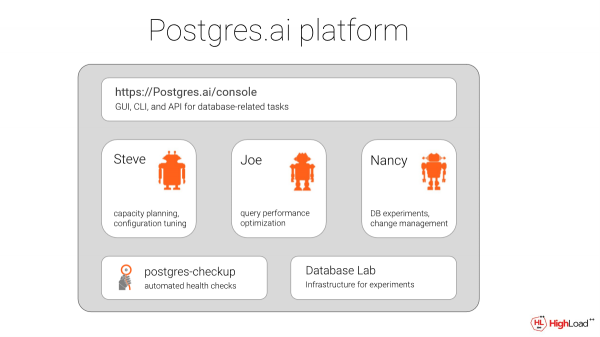
Egiten duguna kode irekia da. GitLab-en argitaratuta dago. Eta jendeak DBArik gabe ere egiaztatu ahal izateko egiten dugu. Datu-baseen laborategia egiten ari gara, hau da, Joe lanean ari den oinarrizko osagaiari deitzen diogu. Eta ekoizpenaren kopia bat har dezakezu. Orain Joeren inplementazio bat dago slack-erako, bertan esan dezakezu: "azaldu halako eta halako eskaera bat" eta berehala lortu datu-basearen kopiaren emaitza. Bertan EZABATU ere egin dezakezu, eta inork ez du ohartuko.
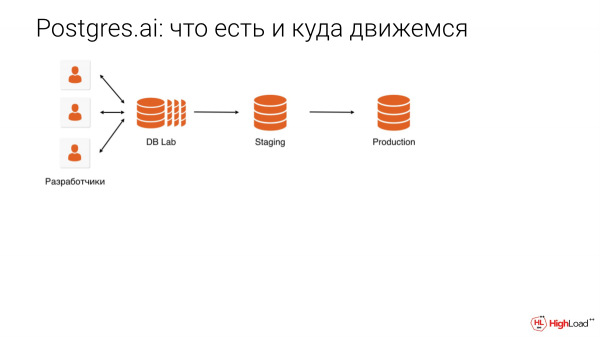
Demagun 10 terabyte dituzula, datu-basearen laborategia ere 10 terabyte egiten dugu. Eta aldi berean 10 terabyteko datu-baseekin, 10 garatzailek aldi berean lan egin dezakete. Bakoitzak nahi duena egin dezake. Ezabatu, jaregin, etab. Hori da fantasia bat. Bihar hitz egingo dugu honetaz.
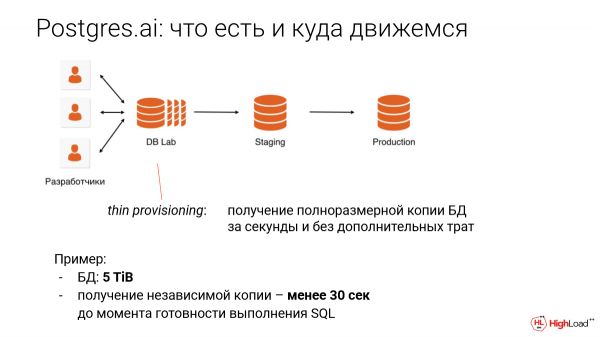
Hornikuntza mehea deitzen zaio. Hau hornidura sotila da. Hau da, garapenean, probetan atzerapenak asko kentzen dituen eta mundua leku hobeago bihurtzen duen fantasia mota bat da. Hau da, ontziratu gabeko eragiketekin arazoak saihesteko aukera ematen du.
Adibidea: 5 terabyteko datu-basea, kopia bat 30 segundo baino gutxiagotan eskuratzea. Eta ez da tamainaren araberakoa ere, hau da, berdin dio zenbat terabyte.
Gaur joan zaitezke eta gure tresnetan sakondu. Bertan dagoena ikusteko izena eman dezakezu. Bot hau instalatu dezakezu. Doan da. Idatzi.
Zure galderak
Askotan egoera errealetan gertatzen da taulan geratu beharko liratekeen datuak ezabatu beharrekoak baino askoz txikiagoak direla. Hau da, halako egoera batean, askotan errazagoa da halako planteamendu bat ezartzea, errazagoa denean objektu berri bat sortzea, bertan beharrezkoak diren datuak soilik kopiatzea eta taula zaharra enborratzea. Argi dago une honetarako ikuspegi programatikoa behar dela, aldatuko zaren bitartean. Nolakoa da planteamendu hori?
Oso hurbilketa ona da eta oso zeregin ona da. Pg_repack-ek egiten duenaren oso antzekoa da, IDak 4 byte egiten dituzunean egin behar duzunaren oso antzekoa da. Esparru askok egin zuten hori duela urte batzuk, eta plakak besterik ez dira hazi, eta 8 byte bihurtu behar dira.
Zeregin hau nahiko zaila da. Egin genuen. Eta kontu handiz ibili behar duzu. Sarrailak daude, etab. Baina egiten ari da. Hau da, ikuspegi estandarra pg_repack-ekin joatea da. Horrelako etiketa bat aldarrikatzen duzu. Eta bertan argazki-datuak kargatzen hasi aurretik, aldaketa guztien jarraipena egiten duen plaka bat ere adierazten duzu. Badago trikimailu bat, baliteke aldaketa batzuen jarraipena ere ez egitea. Sotiltasunak daude. Eta gero aldaketak bilduz aldatzen dituzu. Denak ixten ditugunean etenaldi labur bat izango da, baina orokorrean hori egiten ari da.
GitHub-en pg_repack-i begiratzen badiozu, orduan, ID bat int 4-tik int 8-ra bihurtzeko zeregin bat zegoenean, orduan pg_repack bera erabiltzeko ideia zegoen. Hau ere posible da, baina hack pixka bat da, baina horretarako ere balioko du. pg_repack-ek erabiltzen duen triggerean esku hartu eta bertan esan dezakezu: "Ez dugu datu hauek behar", hau da, behar duguna bakarrik transferitzen dugu. Eta gero aldatu besterik ez du egiten eta kitto.
Planteamendu honekin, oraindik taularen bigarren kopia bat lortzen dugu, eta bertan datuak dagoeneko indexatu eta oso uniformeki pilatuta daude indize ederrekin.
Bloat ez dago, hurbilketa ona da. Baina badakit horretarako automatizazio bat garatzeko saiakerak daudela, hau da, irtenbide unibertsala egiteko. Automatizazio honekin harremanetan jar naiteke. Python-en idatzita dago, eta hori ona da.
MySQL mundutik pixka bat naiz, beraz, entzutera etorri nintzen. Eta ikuspegi hau erabiltzen dugu.
Baina %90a badugu bakarrik. %5 badugu, orduan ez da oso ona erabiltzea.
Eskerrik asko erreportajeagatik! Produkzioaren kopia osoa egiteko baliabiderik ez badago, ba al dago karga edo tamaina kalkulatzeko algoritmorik edo formularik?
Galdera ona. Orain arte, terabyte anitzeko datu-baseak aurkitzeko gai gara. Hango hardwarea berdina ez bada ere, adibidez, memoria gutxiago, prozesadore eta disko gutxiago ez dira berdinak, baina hala ere egiten dugu. Inon ez badago, pentsatu behar duzu. Utzidazu pentsa bihar arte, etorri zara, hitz egingo dugu, galdera ona da.
Eskerrik asko erreportajeagatik! Lehenik eta behin Postgres polit bat dagoela esaten hasi zinen, halako eta halako mugak dituena, baina garatzen ari da. Eta hau guztia makulu bat da. Hau guztia ez al dago gatazkan Postgres-en beraren garapenarekin, zeinetan DELETE deferenteren bat agertuko den edo hemen gure bitarteko bitxi batzuekin zikintzen saiatzen ari garen maila baxuan mantendu beharko lukeen beste zerbait?
SQL-n transakzio batean erregistro asko ezabatzeko edo eguneratzeko esan bagenu, nola banatu dezake Postgresek bertan? Fisikoki mugatuta gaude operazioetan. Oraindik denbora luzez egingo dugu. Eta momentu honetan blokeatuko dugu, etab.
Indizeekin egina.
Suposa dezaket kontrol-puntuaren sintonizazio bera automatizatu daitekeela. Egunen batean hau gerta daiteke. Baina orduan ez dut galdera benetan ulertzen.
Galdera da, ba al dago han-hemenka doan garapen-bektorerik, eta hemen zurea paralelo doa? Horiek. Oraindik ez al dute pentsatu?
Orain erabil daitezkeen printzipioei buruz hitz egin nuen. Bada beste bot bat , honekin kontrol-puntuaren sintonizazio automatikoa egin dezakezu. Noizbait Postgresen izango al da? Ez dakit, oraindik ez da eztabaidatu ere egin. Hortik urrun gaude oraindik. Baina badira sistema berriak egiten dituzten zientzialariak. Eta indize automatikoetara sartzen gaituzte. Garapenak daude. Adibidez, sintonizazio automatikoa ikus dezakezu. Parametroak automatikoki hautatzen ditu. Baina oraindik ez du zuretzako kontrol-puntuaren sintonizazioa egingo. Hau da, errendimendua, shell buffer, etab.
Eta checkpoint sintonizatzeko, hau egin dezakezu: mila kluster eta hardware ezberdin badituzu, makina birtual desberdinak hodeian, gure bot erabil dezakezu automatizazioa egin. Eta max_wal_size automatikoki hautatuko da zure xede-ezarpenen arabera. Baina orain arte hau ez dago muinean ere hurbil, zoritxarrez.
Arratsalde on Transakzio luzeen arriskuez hitz egin duzu. Esan duzu hutsune automatikoa blokeatuta dagoela ezabatzen direnean. Nola egiten digu kalte bestela? Espazioa askatzeaz eta hura erabili ahal izateaz gehiago hitz egiten ari garelako. Zer gehiago falta zaigu?
Auto-hutsean agian ez da arazo handiena hemen. Eta transakzio luze batek beste transakzio batzuk blokeatu ditzakeela, aukera hori arriskutsuagoa da. Baliteke elkartzea edo ez. Ezagutuz gero, oso txarra izan daiteke. Eta auto-hutsarekin - hau ere arazo bat da. OLTP-n transakzio luzeekin bi arazo daude: blokeoak eta hutsune automatikoa. Eta erreplikan erreserba beroko feedbacka gaituta baduzu, orduan oraindik automatikoki blokeoa jasoko duzu maisuan, erreplikatik iritsiko da. Baina gutxienez ez da sarrailarik egongo. Eta lok egongo da. Datuen aldaketei buruz ari gara, beraz, blokeoak puntu garrantzitsu bat dira hemen. Eta hau guztia denbora luzez eta luzez bada, gero eta transakzio gehiago blokeatuta daude. Beste batzuk lapur ditzakete. Eta lok zuhaitzak agertzen dira. Lotura bat eman diot zatiari. Eta arazo hori nabarmenago bihurtzen da automatikoki hutsaren arazoa baino azkarrago, metatu baino ezin baita.
Eskerrik asko erreportajeagatik! Txostena gaizki egin duzula esanez hasi duzu. Gure ideiarekin jarraitu genuen ekipamendu bera hartu behar dugula, oinarri berdinarekin. Demagun garatzaileari oinarri bat eman genion. Eta eskaera bete zuen. Eta badirudi ondo dagoela. Baina ez du zuzenekoa egiaztatzen, zuzenekoa baizik, adibidez, %60-70eko karga dugu. Eta afinazio hau erabiltzen badugu ere, ez du oso ondo funtzionatzen.
Taldean aditu bat izatea eta benetako atzeko karga batekin zer gertatuko den aurreikus dezaketen DBA adituak erabiltzea garrantzitsua da. Gure aldaketa garbiak gidatzen ditugunean, argazkia ikusten dugu. Baina ikuspegi aurreratuagoa, berriz ere gauza bera egin genuenean, baina ekoizpenarekin simulatutako karga batekin. Nahiko polita da. Ordura arte, hazi egin behar duzu. Heldu bat bezalakoa da. Daukaguna aztertu eta baliabide nahikorik ote dugun ere aztertu dugu. Galdera ona da.
Zabor hautaketa bat egiten ari garenean eta, adibidez, bandera ezabatua dugunean
Hau da automatikoki automatikoki Postgres-en egiten duena.
Ai, egiten al du?
Autovacuum zabor biltzailea da.
Eskerrik asko!
Eskerrik asko erreportajeagatik! Ba al dago datu-base bat berehala diseinatzeko zatiketa batekin zabor guztiak mahai nagusitik albo batera zikintzeko moduan?
Noski.
Posible al da orduan geure burua babestea erabili behar ez den mahai bat blokeatu badugu?
Noski. Baina oilasko eta arrautza galdera bat bezalakoa da. Denok badakigu zer gertatuko den etorkizunean, orduan, noski, dena polita egingo dugu. Baina negozioa aldatzen ari da, zutabe berriak daude, eskaera berriak. Eta gero - aupa, kendu nahi dugu. Baina egoera ideal hau, bizitzan gertatzen da, baina ez beti. Baina orokorrean ideia ona da. Moztu besterik ez dago eta kitto.
Iturria: www.habr.com
