

historiaurrea
Guk geuk diseinatutako salmenta-makinak ditugu. Barruan, Raspberry Pi bat eta hardware batzuk daude plaka bereizi batean. Txanpon-onartzaile bat, billete-onartzaile bat eta kutxazain automatiko bat konektatuta daude. Programa pertsonalizatu batek kontrolatzen du dena. Funtzionamendu-historia guztia memoria USB batean (MicroSD) erregistratzen da, eta gero internet bidez (USB modem baten bidez) zerbitzarira transmititzen da, eta han datu-base batean gordetzen da. Salmenten informazioa 1C-ra igotzen da, eta web interfaze sinple bat ere badago monitorizaziorako, etab.
Hau da, egunkaria ezinbestekoa da kontabilitaterako (diru-sarrerak, salmentak, etab.), jarraipena egiteko (mota guztietako hutsegiteak eta beste ezinbesteko kasuak); hau, esan liteke, makina honi buruz dugun informazio guztia dela.
arazoa
Flash drive-ak oso gailu fidagarriak ez direla frogatu da. Maiztasun kezkagarriarekin huts egiten dute. Horrek makina gelditzea eta (arrazoiren batengatik erregistroa sarean transmititu ezin bada) datuen galera dakar.
Ez da hau flash unitateak erabiltzen ditugun lehen esperientzia. Aurretik beste proiektu batean lan egin genuen ehun gailu baino gehiagorekin, non erregistroa USB flash unitateetan gordetzen zen. Fidagarritasun arazoak ere bazeuden, batzuetan dozenaka unitate huts egiten baitzuten hilabetean. Hainbat flash unitate probatu genituen, SLC memoria duten marka ezagunenak barne, eta modelo batzuk beste batzuk baino fidagarriagoak dira, baina unitateak ordezkatzeak ez zuen arazoa guztiz konpondu.
Arreta! Irakurketa luzea! "Zergatik" ez bazaizu interesatzen, "nola" baizik, aurrera egin dezakezu. artikuluak.
Erabaki
Burura datorkidan lehenengo gauza MicroSD txartela baztertzea eta, adibidez, SSD bat instalatzea eta bertatik abiaraztea da. Teorian, ziurrenik posible da, baina nahiko garestia da eta ez bereziki fidagarria (USB-SATA egokitzaile bat behar da; SSD merkeagoen hutsegite-tasak ere etsigarriak dira).
USB HDD bat ere ez dirudi irtenbide bereziki erakargarria.
Beraz, aukera hau bururatu zitzaigun: MicroSDtik abiaraztea utzi, baina irakurtzeko soilik moduan erabili, eta eragiketa-erregistroa (eta hardware zehatz bati dagokion bestelako informazioa —serie-zenbakia, sentsoreen kalibrazioak, etab.) beste nonbait gorde.
Raspberry Pi-rako irakurketa-soilik FS-ren gaia sakon aztertu da dagoeneko, ez naiz artikulu honetan inplementazio-xehetasunetan sakonduko. (baina interesa izanez gero, agian gai honi buruzko mini-artikulu bat idatziko dut)Aipatu nahi dudan puntu bakarra da, bai esperientzia pertsonalean bai dagoeneko ezarri dutenen iritzietan oinarrituta, fidagarritasunean irabazten dela. Matxura erabat ezabatzea ezinezkoa den arren, guztiz posible da haien maiztasuna nabarmen murriztea. Gainera, txartelak estandarizatzen ari dira, eta horrek askoz errazagoa egiten die ordezkapena mantentze-langileei.
hardware zatia
Ez zegoen zalantzarik memoria motaren aukeraketari buruz - NOR Flash.
Argudioak:
- konexio sinplea (gehienetan SPI busa, dagoeneko erabilia dena, beraz, ez da hardware arazorik espero);
- prezio barregarria;
- funtzionamendu-protokolo estandarra (inplementazioa dagoeneko kernelean dago) Linux, nahi baduzu, hirugarrenen bat har dezakezu, bertan daudenak ere, edo zeurea idatz dezakezu, zorionez, dena erraza da);
- fidagarritasuna eta zerbitzu-bizitza:
ohiko datu-orri batetik: datuak 20 urtez gordetzen dira, 100000 ezabatze-ziklo bloke bakoitzeko;
hirugarrenen iturrietatik: BER oso baxua, ez da errore zuzenketa kodeen beharrik postulatzen (Artikulu batzuek ECC NORrentzat eztabaidatzen dute, baina normalean MLC NOR esan nahi dute, eta hori ere gertatzen da).
Kalkulatu dezagun bolumenaren eta baliabideen beharrak.
Datuak hainbat egunez gordeko ditugula bermatu nahi genuke. Hau beharrezkoa da konexio arazorik izanez gero salmenten historia ez galtzeko. 5 egun izatea dugu helburu. (asteburuak eta jaiegunak kontuan hartuta ere) arazoa konpondu daiteke.
Gaur egun, 100 KB erregistro-datu inguru pilatzen ditugu egunean (3-4 mila sarrera), baina zifra hori pixkanaka handitzen ari da xehetasun-maila handitzen den heinean eta gertaera berriak gehitzen diren heinean. Gainera, noizean behin puntu gorenak izaten dira (adibidez, sentsore batek positibo faltsuak bidaltzen hasten dizkigunean). 100 byteko 10 sarrera kalkulatuko ditugu, hau da, megabyte bat eguneko.
Guztira 5 MB datu garbi (ondo konprimituak) dira. Eta gero badago (gutxi gorabeherako kalkulua) 1 MB zerbitzu-datu.
Horrek esan nahi du 8 MB-ko txipa behar dugula konpresiorik gabe, edo 4 MB-koa konpresioarekin. Zifra hauek nahiko errealistak dira memoria mota honetarako.
Baliabideari dagokionez: memoria 5 egunean behin baino gehiagotan berridaztea aurreikusten badugu, orduan 10 urteko zerbitzuaren ondoren mila berridazketa ziklo baino gutxiago lortuko ditugu.
Gogorarazi nahi dizuet fabrikatzaileak ehun mila agintzen dituela.
NOR vs. NAND-i buruzko apur bat
NAND memoria gaur egun ezagunagoa da, baina ez nuke proiektu honetarako erabiliko: NANDek, NOR ez bezala, errore zuzenketa kodeak, bloke taula okerrak eta abar behar ditu, eta NAND txipek normalean pin askoz gehiago dituzte.
NORren desabantailak hauek dira:
- bolumen txikia (eta, horren arabera, megabyte bakoitzeko prezio altua);
- truke-abiadura baxua (neurri handi batean serieko interfazea erabiltzen delako, normalean SPI edo I2C);
- ezabatze motela (blokearen tamainaren arabera, segundo zati batetik segundo batzuetaraino behar da).
Badirudi ez dagoela ezer kritikorik guretzat, beraz, aurrera jarraituko dugu.
Xehetasunetan interesa baduzu, mikrozirkuitu bat hautatu da (Hala ere, hau ez da garrantzitsua; merkatuan antzeko txip ugari daude, pinout eta komando sistemari dagokionez bateragarriak direnak; beste fabrikatzaile bateko txip bat eta/edo beste ahalmen bat instalatu nahi badugu ere, denak funtzionatuko du kodea aldatu gabe).
Kernelean txertatuta dagoena erabiltzen dut Linux Driver-a, Raspberry-n, gailu-zuhaitzaren gainjartze-laguntzari esker, dena oso erraza da - konpilatutako gainjartzea /boot/overlays-en jarri eta /boot/config.txt apur bat aldatu behar duzu.
dts fitxategi baten adibidea
Egia esan, ez nago ziur akatsik gabe idatzita dagoenik, baina funtzionatzen du.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Eta beste lerro bat config.txt fitxategian
dtoverlay=at25:spimaxfrequency=50000000Txip eta Raspberry Pi arteko benetako konexioa saltatuko dut. Alde batetik, ez naiz elektronikako aditua, baina bestetik, nahiko erraza da niretzat ere: txipak 8 pin baino ez ditu, eta horietatik lurra, elikadura eta SPI (CS, SI, SO, SCK) behar ditugu. Mailak Raspberry Pi-koak bezalakoak dira, eta ez da kableatu gehigarririk behar: adierazitako sei pinak konektatu besterik ez dago.
Arazoaren formulazioa
Ohi bezala, arazoaren adierazpena hainbat iterazioz aldatzen da, eta uste dut beste bat egiteko garaia dela. Beraz, gelditu gaitezen, idatzitakoa bildu eta gainerako xehetasun ilunak argitu ditzagun.
Beraz, erabaki dugu erregistroa SPI NOR Flash memorian gordetzea.
Zer da NOR Flasha, ez dakitenentzat?
Memoria ez-hegazkorra da, hiru eragiketatarako erabil daitekeena:
- Irakurketa:
Irakurketa ohikoena: helbidea pasatzen dugu eta behar adina byte irakurtzen ditugu; - erregistroa:
NOR flash memorian idaztea ohiko eragiketa baten itxura du, baina berezitasun bat du: 1 bat 0 batera alda dezakezu bakarrik, baina ez alderantziz. Adibidez, memoria-gelaxka batean 0x55 bagenu, 0x0f idatzi ondoren, 0x05 izango du orain. (ikus beheko taula); - Ezabatu:
Noski, alderantzizko eragiketa ere egin behar dugu: 0 bat 1era aldatzea. Horretarako da, hain zuzen ere, ezabatze eragiketa. Lehenengo biek ez bezala, blokeetan funtzionatzen du, byteetan baino (hautatutako txipean gutxieneko ezabatze blokea 4 KB da). Ezabatzeak bloke osoa suntsitzen du, eta hau da 0 bat 1era aldatzeko modu bakarra. Beraz, flash memoriarekin lan egitean, askotan beharrezkoa da datu-egiturak ezabatze bloke mugara lerrokatzea.
NOR Flash memorian idaztea:
Datu bitarrak
zen
01010101
Grabatua
00001111
Bihurtu da
00000101
Erregistroa bera luzera aldakorreko erregistroen sekuentzia bat da. Erregistro baten luzera tipikoa 30 byte ingurukoa da (nahiz eta batzuetan kilobyte batzuetako erregistroak aurkitzen diren). Kasu honetan, byte multzo gisa ari gara lanean, baina interesatzen bazaizu, CBOR erabiltzen da erregistroen barruan.
Erregistroaz gain, "konfigurazio" informazio batzuk gorde behar ditugu, eguneratuak eta eguneratu gabeak: gailuaren ID jakin bat, sentsoreen kalibrazioak, "gailua aldi baterako desgaituta dago" bandera, etab.
Informazio hau gako-balio erregistro multzo bat da, CBOR-en gordeta dagoena. Ez dugu informazio askorik (gehienez kilobyte batzuk), eta gutxitan eguneratzen da.
Etorkizunean testuinguru deituko diogu.
Artikulu hau nola hasi zen gogoratzen baduzu, oso garrantzitsua da datuak modu fidagarrian gordetzea eta, ahal bada, etenik gabeko funtzionamendua bermatzea, hardware-akatsak/datuak hondatuz gero ere.
Zein arazo-iturri hartu daitezke kontuan?
- Idazketa/ezabatze eragiketetan zehar argindar mozketak. Hau "palanca baten aurkako defentsarik ez" kasua da.
Informazioa hemendik stackexchange-n: flash memoriarekin lanean ari den bitartean energia itzaltzen denean, bai ezabatzeak (1era ezarrita) bai idazteak (0ra ezarrita) portaera zehaztugabea eragiten dute: datuak idatz daitezke, partzialki idatz daitezke (adibidez, 10 byte/80 bit transferitu ditugu, baina 45 bit bakarrik idatzi dira), eta baliteke bit batzuk "tarteko" egoeran amaitzea ere (irakurketak 0 edo 1 eman dezake); - Flash memorian bertan dauden akatsak.
BER, oso baxua izan arren, ezin da zero izan; - Autobus erroreak
SPI bidez transmititutako datuak ez daude inola ere babestuta; bit bakarreko akatsak eta sinkronizazio akatsak —biten galera edo txertatzea (datuen ustelkeria masiboa dakar)— gerta daitezke; - Beste akats/akats batzuk
Kode erroreak, Raspberry "akatsak", estralurtarren esku-hartzea...
Nire ustez, fidagarritasuna bermatzeko bete behar diren eskakizunak formulatu ditut:
- Erregistroak berehala idatzi behar dira flash memorian, ez da kontuan hartzen atzeratutako idazketa; - errore bat gertatzen bada, ahalik eta azkarren detektatu eta prozesatu behar da; - sistemak, ahal den guztietan, erroreetatik berreskuratu behar du.
(Benetako bizitzako adibide bat "nola ez luke izan behar" esateko, uste dut denek topatu dutela: berrabiarazi larrialdi baten ondoren, fitxategi-sistema "hautsita" dago eta sistema eragilea ez da abiarazten)
Ideiak, ikuspegiak, hausnarketak
Arazo honi buruz pentsatzen hasi nintzenean, ideia mordoa etorri zitzaidan burura, adibidez:
- datuen konpresioa erabili;
- erabili datu-egitura adimentsuak, hala nola erregistroen goiburuak erregistroetatik bereizita gordetzea, erregistro batean errore bat badago, gainerakoak arazorik gabe irakurri ahal izateko;
- erabili bit eremuak idazketaren osaketa kontrolatzeko energia itzaltzen denean;
- gorde egiaztapen-baturak dena eta guztiontzat;
- erroreak zuzentzeko kodeketa motaren bat erabili.
Ideia horietako batzuk erabili ziren, beste batzuk baztertu egin ziren. Ikus ditzagun ordenan.
Datuen konpresioa
Erregistroan erregistratzen ditugun gertaerak nahiko uniformeak eta errepikagarriak dira ("5 errubloko txanpon bat bota", "aldaketa botoia sakatu", etab.). Beraz, konpresioa nahiko eraginkorra izan beharko litzateke.
Konpresio-gastua hutsala da (gure prozesadorea nahiko indartsua da; jatorrizko Pi-ak ere 700 MHz-ko nukleo bakarra zuen, egungo modeloek gigahertz bat baino gehiagoko abiaduran funtzionatzen duten nukleo anitz dituzten bitartean), biltegiratze-transferentzia-tasa baxua da (segundoko megabyte batzuk) eta erregistroaren tamaina txikia da. Oro har, konpresioak errendimenduan eraginik badu, positiboa baino ez da izango. (erabat kritikoa ez dena, adierazten ari naiz)Gainera, ez dugu benetako txertatutako bat, ohiko bat baizik. Linux — beraz, inplementazioak ez luke ahalegin handirik eskatu behar (nahikoa da liburutegia lotzea eta bertatik funtzio batzuk erabiltzea).
Erregistro-datu zati bat gailu funtzional batetik hartu zen (1.7 MB, 70 mila sarrera) eta lehenik konprimagarritasuna egiaztatu zen ordenagailuan eskuragarri dauden gzip, lz4, lzop, bzip2, xz, zstd erabiliz.
- gzip, xz, zstd-k antzeko emaitzak erakutsi zituzten (40Kb).
Harrituta geratu nintzen modako xz hemen gzip edo zstd mailan agertu zelako; - lzip-ek lehenetsitako ezarpenekin emaitza apur bat okerragoak eman zituen;
- lz4 eta lzop-ek ez zuten emaitza oso onik erakutsi (150Kb);
- bzip2-k emaitza harrigarriro ona erakutsi zuen (18Kb).
Beraz, datuak oso ondo konprimitzen dira.
Beraz (akats larririk aurkitzen ez badugu behintzat), konpresioa gauza bat izango da! Besterik gabe, flash unitate berak datu gehiago gordeko dituelako.
Pentsa dezagun desabantailak.
Lehenengo arazoa: dagoeneko adostu dugu idazketa bakoitza berehala flash memorian idatzi behar dela. Normalean, artxibatzaile batek sarrerako jariotik datuak biltzen ditu irteerako jarioan idazteko garaia dela erabaki arte. Datu bloke konprimitu bat berehala lortu eta memoria ez-hegazkorrean gorde behar dugu.
Hiru modu ikusten ditut:
- Konprimatu erregistro bakoitza hiztegi-konpresioa erabiliz, goian azaldutako algoritmoen ordez.
Aukera guztiz bideragarria da, baina ez zait gustatzen. Konpresio maila duina lortzeko, hiztegia datu espezifikoetara egokitu behar da; edozein aldaketak konpresioaren jaitsiera katastrofikoa ekarriko du. Bai, hiztegiaren bertsio berri bat sortzeak arazoa konpontzen du, baina hori buruhauste handia da: hiztegiaren bertsio guztiak gorde beharko genituzke; sarrera bakoitzak zein hiztegi bertsiorekin konprimitu den adierazi beharko luke... - Konprimatu erregistro bakoitza "algoritmo klasikoak" erabiliz, baina besteengandik independenteki.
Aztertzen ari garen konpresio algoritmoak ez daude tamaina horretako erregistroekin (hamarnaka byte) lan egiteko diseinatuta; konpresio-erlazioa argi eta garbi 1 baino txikiagoa izango da (hau da, datuen bolumena handituko da konpresioaren ordez); - Egin FLUSH bat sarrera bakoitzaren ondoren.
Konpresio liburutegi askok FLUSH onartzen dute. Hau artxibatzaileak jasotzean konprimitutako jario bat sortzen duen komando bat da (edo konpresio prozeduraren parametro bat), berreskuratzeko erabili ahal izateko. guztiak dagoeneko jasotako datu konprimitu gabeak. Analogiko hausyncfitxategi sistemetan edocommitSQL-n.
Garrantzitsuena da ondorengo konpresio eragiketek metatutako hiztegia erabili ahal izango dutela, eta konpresio-erlazioa ez dela aurreko bertsioan bezainbeste kaltetuko.
Uste dut hirugarren aukera aukeratu dudala agerikoa dela, azter dezagun xehetasun gehiagorekin.
Aurkituta zlib-en FLUSH-i buruz.
Artikuluan oinarritutako proba instintibo bat egin nuen, benetako gailu batetik 70 erregistro-sarrera hartuz, 60 KB-ko orrialde-tamainarekin. (Orrialdearen tamainara geroago itzuliko gara) jasoa:
Datu gordinak
Gzip -9 konpresioa (FLUSH gabe)
zlib Z_PARTIAL_FLUSH-rekin
zlib Z_SYNC_FLUSH-rekin
Bolumena, KB
1692
40
352
604
Lehen begiratuan, FLUSH-en kostua debekatzailea dirudi, baina errealitatean, aukera mugatua dugu: edo konpresiorik ez, edo konpresioa (eta nahiko eraginkorra) FLUSH-ekin. Kontuan izan 70 erregistro ditugula, eta Z_PARTIAL_FLUSH-ek sartutako erredundantzia erregistro bakoitzeko 4-5 byte baino ez dela. Eta konpresio-erlazioa ia 5:1 izan zen, eta hori bikaina baino gehiago da.
Harrigarria badirudi ere, Z_SYNC_FLUSH FLUSH bat egiteko modu eraginkorragoa da.
Z_SYNC_FLUSH erabiltzean, erregistro bakoitzaren azken lau byteak beti 0x00, 0x00, 0xff, 0xff izango dira. Balio hauek badakigu, ez ditugu gorde behar, beraz, azken tamaina 324 KB baino ez da.
Estekatu dudan artikuluak azaltzen du hau:
Eduki hutsak dituen 0 motako bloke berri bat gehitzen da.
0 motako bloke batek, edukiera hutsarekin, honako hauek ditu:
- hiru biteko bloke-burua;
- 0tik 7ra bitarteko bitak zeroren berdinak dira, byteen lerrokatzea lortzeko;
- lau byteko 00 00 FF FF sekuentzia.
Ikus dezakezuenez, azken blokean, 3 eta 10 zero bit artean daude 4 byte horien aurretik. Hala ere, esperientziak erakutsi du gutxienez 10 zero bit daudela benetan.
Bada, datu-bloke labur horiek normalean (beti?) 1 motako bloke batekin (bloke finkoa) kodetzen dira, eta bloke hori beti 7 zero bitekin amaitzen da, eta ondorioz, 10-17 zero bit bermatuta daude (eta gainerakoa zero izango da % 50 inguruko probabilitatearekin).
Beraz, proba-datuetan, kasuen % 100ean, 0x00, 0x00, 0xff, 0xff-ren aurretik zero byte bat dago, eta kasuen heren bat baino gehiagotan, bi zero byte daude. (arazoa agian da CBOR bitarra erabiltzen ari naizela, eta testu JSON erabiliko banu, 2 motako blokeekin - bloke dinamikoa - maizago topatuko nituzke, eta beraz, 0x00, 0x00, 0xff, 0xff aurretik zero byte gehigarririk gabeko blokeekin topatuko nintzateke).
Guztira, eskuragarri dauden proba-datuak erabiliz, 250 KB baino gutxiagoko datu konprimituak sartzea posible da.
Bit malabarismoak eginez gehiago aurreztu dezakegu: orain bloke baten amaieran zero bit batzuk egotea alde batera uzten dugu, eta bloke baten hasieran dauden bit batzuk ere aldatu gabe geratzen dira...
Baina hemen erabaki irmoa hartu nuen gelditzeko, bestela erritmo honetan nire artxibo propioa garatzen amaitu nezakeelako.
Guztira, 3-4 byte lortu ditut erregistro bakoitzeko nire proba-datuetatik, eta ondorioz 6:1etik gorako konpresio-erlazioa lortu dut. Egia esan, ez nuen halako emaitzarik espero; nire ustez, 2:1 baino hobea den edozer gauza dagoeneko konpresioaren erabilera justifikatzen duen emaitza da.
Dena bikain doa, baina zlib (deflate) oraindik ere konpresio algoritmo arkaiko, merezitako eta pixka bat zaharkitua da. Konprimitu gabeko datu-jarioaren azken 32 KB hiztegi gisa erabiltzea bera arraroa dirudi gaur egun (hau da, datu-bloke bat duela 40 KB sarrera-jarioan zegoenaren oso antzekoa bada, berriro konprimitzen hasiko da aurreko sarrera erreferentziatu beharrean). Artxibo modernoetan, hiztegiaren tamaina megabytetan neurtzen da askotan, kilobytetan baino.
Beraz, jarrai dezagun artxibozainen gure mini-ikerketarekin.
Ondoren, bzip2 probatu nuen (gogoratu, FLUSH gabe, konpresio-erlazio bikaina erakutsi zuela, ia 100:1). Zoritxarrez, FLUSHekin, oso gaizki funtzionatu zuen; konprimitutako datuak konprimitu gabekoak baino handiagoak izan ziren azkenean.
Nire susmoak porrotaren arrazoiei buruz
Libbz2-k garbitzeko aukera bakarra eskaintzen du, hiztegia garbitzen duena (zlib-eko Z_FULL_FLUSH-en antzekoa), beraz, ez du zentzurik ondoren konpresio eraginkor bati buruz hitz egiteak.
Eta azkenik, zstd probatu dut. Parametroen arabera, gzip mailan konprimitzen du, baina askoz azkarrago, edo gzip baino hobeto.
Zoritxarrez, FLUSHekin ere ez zuen oso ondo funtzionatu: konprimitutako datuen tamaina 700 KB ingurukoa zen.
Я Proiektuaren Github orrialdean erantzuna jaso nuen: konprimitutako datu-bloke bakoitzeko 10 byte zerbitzu-datu espero behar direla, eta hori lortutako emaitzetatik gertu dago; ezinezkoa izango da deflate-rekin jarraitzea.
Puntu honetan, artxibatzaileekin esperimentatzeari uztea erabaki nuen (gogorarazi nahi dizuet xz, lzip, lzo eta lz4-k ez zutela beren balioa erakutsi FLUSH gabeko proba fasean ere, eta ez nituela konpresio algoritmo exotikoagoak kontuan hartu).
Itzul gaitezen artxibatzearen arazoetara.
Bigarren arazoa (ordenaren arabera adierazi bezala, ez garrantziaren arabera) da konprimitutako datuak aurreko atalak etengabe erreferentziatzen dituen jario bakarra direla. Beraz, konprimitutako datuen atal bat kaltetuta badago, ez dugu konprimitu gabeko datuen blokea bakarrik galtzen, baita ondorengo bloke guztiak ere.
Arazo hau konpontzeko moduak daude:
- Arazoak gerta ez daitezen, datu konprimituei erredundantzia gehitzea esan nahi du, akatsak detektatu eta zuzendu ahal izateko; geroago aztertuko dugu hau;
- Arazoren bat gertatuz gero, ondorioak minimizatu
Aipatu dugu dagoeneko datu-bloke bakoitza modu independentean konprimitu daitekeela, eta horrek arazoa konponduko lukeela (bloke bateko datuen hondatzeak bloke hori galtzea baino ez luke ekarriko). Hala ere, hau muturreko kasua da, datuen konpresioa eraginkorra ez izatea eraginez. Kontrako muturra: gure txiparen 4 MB guztiak artxibo bakar gisa erabiltzea, eta horrek konpresio bikaina emango luke, baina ondorio katastrofikoak izango lituzke datuen hondatzea gertatuz gero.
Bai, fidagarritasunari dagokionez konpromiso bat behar da. Baina gogoratu behar dugu BER oso baxua eta 20 urteko datuak gordetzeko epea duen memoria ez-hegazkorrerako datuak gordetzeko formatu bat garatzen ari garela.
Nire esperimentuetan zehar, aurkitu nuen konpresio-mailaren galera nabarmenagoak edo ez hain nabarmenak 10 KB baino gutxiagoko konprimitutako datu-blokeekin hasten direla.
Aurretik aipatu zen erabilitako memoria orrialdeetan oinarrituta dagoela, ez dut arrazoirik ikusten zergatik ez zenukeen erabili behar "orrialde bat - datu konprimituen bloke bat" mapaketa.
Horrek esan nahi du orrialdearen gutxieneko tamaina arrazoizkoa 16 KB dela (gainkarga pixka bat kontuan hartuta). Hala ere, orrialdearen tamaina txiki horrek muga handiak ezartzen dizkio erregistroaren gehienezko tamainari.
Kilobyte batzuk baino handiagoak diren erregistroak konprimituta izatea espero ez dudan arren, 32 KB-ko orrialdeak erabiltzea erabaki nuen (horrek 128 orrialde ematen dizkit txipa bakoitzeko).
Laburpena:
- Datuak zlib (deflate) erabiliz konprimituta gordetzen ditugu;
- Sarrera bakoitzerako Z_SYNC_FLUSH ezartzen dugu;
- Konprimitutako erregistro bakoitzerako, atzeko byteak moztu egiten ditugu. (adibidez, 0x00, 0x00, 0xff, 0xff)goiburuan zenbat byte moztu ditugun adierazten dugu;
- Datuak 32 KB-ko orrialdeetan gordetzen ditugu; orrialde bakoitzaren barruan, datu konprimituen jario bakarra dago; konpresioa orrialde bakoitzean berrabiarazten da.
Eta, konpresioarekin amaitu aurretik, aipatu nahi nuke erregistro bakoitzeko datu konprimitu byte gutxi batzuk baino ez ditugula lortzen, beraz, oso garrantzitsua da zerbitzuaren informazioa ez puztea; byte bakoitzak balio du hemen.
Datuen goiburuak gordetzea
Luzera aldakorreko erregistroak ditugunez, erregistroen kokapena/mugak nolabait zehaztu behar ditugu.
Hiru ikuspegi ezagutzen ditut:
- Erregistro guztiak etengabeko jario batean gordetzen dira, lehenik luzera duen erregistro-burua dator, eta gero erregistroa bera.
Aldaera honetan, bai goiburuak bai datuak luzera aldakorrekoak izan daitezke.
Funtsean, uneoro erabiltzen den zerrenda lotu bakarrean lortzen dugu; - Goiburuak eta erregistroak berak korronte bereizietan gordetzen dira.
Luzera konstanteko goiburuak erabiliz, ziurtatzen dugu goiburu baten hondatzeak ez diela besteei eragiten.
Antzeko ikuspegia erabiltzen da, adibidez, fitxategi-sistema askotan; - Erregistroak etengabeko jario batean gordetzen dira, erregistro-muga markatzaile batek definituta dutela (datu-blokeetan debekatuta dagoen karaktere edo karaktere-segida bat). Erregistro baten barruan markatzaile bat aurkitzen bada, segida jakin batekin ordezkatzen dugu (ihes-karakterea erabiltzen diogu).
Antzeko ikuspegia erabiltzen da, adibidez, PPP protokoloan.
Ilustrazio bat emango dizuet.
Aukera 1:

Oso erraza da dena: erregistroaren luzera jakinda, hurrengo goiburuaren helbidea kalkula dezakegu. Goiburuetan zehar mugitzen gara 0xff (espazio librea) duen eremu bat edo orriaren amaiera aurkitu arte.
Aukera 2:

Erregistroen luzera aldakorra denez, ezin dugu aurreikusi zenbat erregistro (eta beraz goiburu) beharko ditugun orrialde bakoitzeko. Goiburuak eta datuak orrialde ezberdinetan banatu genitzake, baina beste ikuspegi bat nahiago dut: goiburuak eta datuak orrialde bakarrean jartzen ditugu, baina goiburuak (luzera konstantekoak) orrialdearen goialdean hasten dira, eta datuak (luzera aldakorrekoak) behealdean. "Elkartzen" direnean (erregistro berri batentzako leku nahikorik ez dagoenean), orrialdea beteta dagoela uste dugu.
Aukera 3:

Ez dago luzera edo bestelako datuen kokapenari buruzko informazioa goiburuan gorde beharrik; erregistroen mugak adierazten dituzten markatzaileak nahikoak dira. Hala ere, datuak prozesatu egin behar dira idaztean/irakurtzean.
0xff erabiliko nuke (orrialdea ezabatu ondoren betetzen den hori da) markatzaile gisa, eremu librea datu gisa ez tratatzeko.
Konparazio taula:
Aukera 1
Aukera 2
Aukera 3
Errore-tolerantzia
-
+
+
dentsitate
+
-
+
Inplementazio zailtasuna.
*
**
**
1. aukerak akats larri bat dauka: goibururen bat kaltetuta badago, ondorengo kate osoa suntsitzen da. Beste aukerekin, datuen berreskurapen partziala egin daiteke, kalte zabalak gertatuz gero ere.
Baina hemen komeni da gogoratzea datuak formatu konprimituan gordetzea erabaki genuela, eta nolanahi ere orrialdeko datu guztiak galtzen ditugula "hautsitako" erregistro baten ondoren, beraz, taulan ken bat egon arren, ez dugu kontuan hartzen.
Trinkotasuna:
- lehenengo aukeran, luzera goiburuan gorde besterik ez dugu behar; luzera aldakorreko zenbaki osoak erabiltzen baditugu, kasu gehienetan byte batekin molda gaitezke;
- Bigarren aukeran, hasierako helbidea eta luzera gorde behar ditugu; erregistroak tamaina konstantea izan behar du, 4 byte erregistro bakoitzeko kalkulatzen ditut (bi byte desplazamendurako eta bi byte luzerarako);
- Hirugarren aukerak karaktere bakarra behar du erregistro baten hasiera adierazteko, eta gainera, erregistroaren tamaina % 1-2 handituko da ihes egiteagatik. Oro har, lehenengo aukeraren parekoa da gutxi gorabehera.
Hasieran, bigarren aukera hartu nuen lehen mailakotzat (eta inplementazio bat ere idatzi nuen). Konpresioa erabiltzea erabaki nuenean bakarrik utzi nuen alde batera.
Agian antzeko aukera bat erabiliko dut egunen batean. Adibidez, Lurraren eta Marteren artean bidaiatzen duen espazio-ontzi baten datuak gorde behar baditut —fidagarritasun-eskakizun guztiz desberdinak, erradiazio kosmikoa...—.
Hirugarren aukerari dagokionez: bi izar eman dizkiot inplementazioaren konplexutasunagatik, besterik gabe, ez zaidalako gustatzen ihes egitea, prozesuaren erdian luzera aldatzea, etab. Bai, agian alboratua naiz, baina kodea nik idatzi beharko dut; zergatik behartu neure burua gustatzen ez zaidan zerbait egitera?
Laburpena: "Luzera duen goiburua - luzera aldakorreko datuak" kateen moduan biltegiratzeko aukera aukeratu dugu, eraginkortasunagatik eta inplementazio erraztasunagatik.
Bit eremuak erabiltzea idazketa eragiketen arrakasta kontrolatzeko
Ez dut gogoratzen orain nondik atera nuen ideia, baina honelako zerbait dirudi:
Sarrera bakoitzerako, hainbat bit esleitzen ditugu banderak gordetzeko.
Lehen esan bezala, ezabatu ondoren bit guztiak 1ez betetzen dira, eta 1 0ra alda dezakegu, baina ez alderantziz. Beraz, "bandera ezarri gabe" kasurako 1 erabiltzen dugu, "bandera ezarrita" kasurako 0 erabiltzen dugu.
Hona hemen luzera aldakorreko erregistro bat flash formatuan jartzeak nolakoa izan litekeen:
- Ezarri “luzera grabatzen hasi da” bandera;
- Luzera idazten dugu;
- “datuen grabaketa hasi da” bandera ezarri dugu;
- Datuak idazten ditugu;
- "Grabaketa amaitu da" bandera ezarri dugu.
Horrez gain, “errore bat gertatu da” bandera bat izango dugu, guztira 4 biteko banderak.
Kasu honetan, bi egoera egonkor ditugu: "1111" (grabazioa ez da hasi) eta "1000" (grabazioa arrakastaz egin da). Grabazio-prozesuan ustekabeko etenaldi bat gertatuz gero, tarteko egoerak jasoko ditugu, eta horiek detektatu eta prozesatu ahal izango ditugu.
Ikuspegia interesgarria da, baina bat-bateko energia-etenaldien eta antzeko hutsegiteen aurka bakarrik babesten du, eta hori, noski, garrantzitsua da, baina hau ez da hutsegite posibleen arrazoi bakarra (eta ez nagusia ere).
Laburpena: Aurrera egin dezagun irtenbide on baten bila.
Kontrol-baturak
Kontrol-baturek ere modu bat ematen dute egiaztatzeko (arrazoizko ziurtasunarekin) idatzi behar zena zehazki irakurtzen ari garela. Eta, goian aipatutako bit-eremuek ez bezala, beti funtzionatzen dute.
Goian aipatu ditugun arazo-iturri potentzialen zerrenda kontuan hartzen badugu, kontrol-baturak errore bat ezagutzeko gai da, haren jatorria edozein dela ere. (agian, atzerritar gaiztoak izan ezik - hauek ere egiaztapen-batura faltsutu dezakete).
Beraz, gure helburua datuak osorik daudela egiaztatzea bada, kontrol-baturak ideia bikaina dira.
Kontrol-batura kalkulatzeko algoritmoaren aukeraketa erraza izan zen: CRC. Alde batetik, bere propietate matematikoek errore mota batzuk % 100ean detektatzea ahalbidetzen dute; bestetik, ausazko datuetan, algoritmo honek normalean muga teorikoa baino askoz handiagoa ez den talka-probabilitatea erakusten du.  Baliteke algoritmorik azkarrena ez izatea, edo talka gutxien dituena beti, baina badu ezaugarri oso garrantzitsu bat: egin ditudan probetan, ez dut aurkitu huts egitea eragin duen eredurik. Egonkortasuna da hemen ezaugarri nagusia.
Baliteke algoritmorik azkarrena ez izatea, edo talka gutxien dituena beti, baina badu ezaugarri oso garrantzitsu bat: egin ditudan probetan, ez dut aurkitu huts egitea eragin duen eredurik. Egonkortasuna da hemen ezaugarri nagusia.
Bolumen-azterketa baten adibidea: , (narod.ru-rako estekak, barkatu).
Hala ere, kontrol-batura bat aukeratzeko lana ez dago osatuta; CRC kontrol-baturen familia oso bat da. Luzera erabaki eta gero polinomio bat aukeratu behar dugu.
Kontrol-baturaren luzera aukeratzea ez da lehen begiratuan dirudien bezain kontu erraza.
Ilustrazio bat emango dizuet:
Demagun byte bakoitzean errorearen probabilitatea  eta kontrol-batura ideala lortzeko, kalkula dezagun milioi erregistroko errore kopuruaren batez bestekoa:
eta kontrol-batura ideala lortzeko, kalkula dezagun milioi erregistroko errore kopuruaren batez bestekoa:
Datuak, byteak
Kontrol-batura, byte
Detektatu gabeko akatsak
Akats faltsuen detekzioa
Erantzun okerren kopuru osoa
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
Erraza dirudi: babesten ari diren datuen luzeran oinarrituta, gutxieneko positibo faltsuak dituen kontrol-baturaren luzera aukeratu, eta kito.
Hala ere, kontrol-batura laburrek arazo bat sortzen dute: bit bakarreko akatsak detektatzeko onak diren arren, probabilitate handiarekin, datu guztiz ausazkoak baliozkotzat har ditzakete. Jadanik bazegoen Habr-en artikulu bat hori azaltzen zuena. .
Beraz, ausazko kontrol-baturaren bat-etortzea ia ezinezkoa izan dadin, 32 biteko edo gehiagoko kontrol-baturak erabili beharko lirateke. (64 bit baino gehiagoko luzeretarako, normalean hash funtzio kriptografikoak erabiltzen dira).
Lehenago idatzi nuen arren espazioa aurreztu behar dugula edozein kostutan, 32 biteko kontrol-sumazioa erabiliko dugu oraindik ere (16 bit ez dira nahikoak, talka egiteko probabilitatea % 0.01 baino handiagoa da; eta 24 bit, esaten duten bezala, ez daude ez hemen ez han).
Hemen eragozpen bat sor daiteke: benetan byte guztiak gorde al genituen konpresioa aukeratzerakoan, eta orain lau byte aldi berean eman beharrean? Ez al litzateke hobe izango ez konprimitzea edo kontrol-baturarik ez gehitzea? Noski ezetz, konpresiorik ez. ez du esan nahi, ez dugula osotasun-egiaztapenik behar.
Polinomioaren aukeraketari dagokionez, ez dugu gurpila berrasmatuko, baizik eta gaur egun ezaguna den CRC-32C hartuko dugu.
Kode honek 6 biteko erroreak detektatzen ditu 22 byte arteko paketeetan (ziurrenik guretzat kasu ohikoena), 4 biteko erroreak 655 byte arteko paketeetan (guretzat ere kasu ohikoa), 2 edo edozein bit errore kopuru bakoiti edozein luzera arrazoizko paketeetan.
Xehetasunetan norbait interesatzen bada
CRCri buruz.
on — agian planetako CRC espezialista nagusia.
В dago , guretzat garrantzitsuak diren paketeen luzeretarako parametro apur bat hobeak eskaintzen dituena, baina ez nuen aldea esanguratsutzat jo, eta ez nuen neure burua nahikoa gaitzat jotzen kode pertsonalizatua aukeratzeko estandar eta ondo ikertutakoaren gainetik.
Gainera, gure datuak konprimituta daudenez, galdera hau sortzen da: datu konprimituen edo konprimitu gabekoen kontrol-batura kalkulatu beharko genuke?
Konprimitu gabeko datuen kontrol-batura kalkulatzearen aldeko argudioak:
- Azken finean, datuen biltegiratzearen osotasuna egiaztatu behar dugu - beraz, zuzenean egiaztatzen dugu (aldi berean, konpresioa/deskonpresioa ezartzean izan daitezkeen akatsak, memoria txarrak eragindako kalteak, etab. egiaztatuko dira);
- Zlib-eko deflate algoritmoak inplementazio nahiko heldua du eta ez luke behar "Okertutako" sarrerako datuekin kraskatzea, gainera, askotan gai da sarrerako jarioan akatsak modu independentean detektatzeko, errore bat detektatzeko probabilitate orokorra murriztuz (erregistro labur batean bit bakar baten alderantzikapenarekin proba bat egin nuen, zlib-ek kasuen heren batean errore bat detektatu zuen).
Konprimitu gabeko datuen kontrol-batura kalkulatzearen aurkako argudioak:
- CRC bereziki flash memorian ohikoak diren bit errore gutxi batzuetarako diseinatuta dago (konprimitutako jario bateko bit errore batek irteerako jarioan aldaketa izugarria eragin dezake, eta, teorian soilik, talka bat "harrapa" dezakegu);
- Ez zait batere gustatzen datu hondatuak deskonpresoreari ematearen ideia, , nola erreakzionatuko duen.
Proiektu honetan, konprimitu gabeko datuen kontrol-batura gordetzeko orokorrean onartutako praktikatik aldentzea erabaki nuen.
Laburpena: CRC-32C erabiltzen dugu, datuen batura kalkulatzen dugu flash memorian idatzita dauden moduan (konpresioaren ondoren).
Erredundantzia
Kodeketa erredundantearen erabilerak ez du, noski, datu-galera ezabatzen; hala ere, nabarmen murriztu dezake (askotan magnitude-ordena askotan) datu-galera konponezinak izateko probabilitatea.
Erredundantzia mota desberdinak erabil ditzakegu akatsak zuzentzeko.
Hamming kodeek bit bakarreko erroreak zuzendu ditzakete, Reed-Solomon kodeek sinbolikoak izan daitezke, datuen kopia anitz kontrol-baturekin batera, edo RAID-6 bezalako kodeketak datuak berreskuratzen lagun dezake hondatze masiboa gertatuz gero ere.
Hasieran, akatsak zuzentzeko kodeketa asko erabiltzeko joera nuen, baina gero konturatu nintzen lehenik eta behin zein erroreren aurka babestu nahi dugun ideia bat izan behar dugula, eta gero kodeketa aukeratu.
Aurretik aipatu dugu akatsak ahalik eta azkarren identifikatu behar direla. Noiz izango ditugu akatsak?
- Amaitu gabeko grabazioa (arrazoiren batengatik, argindarra joan da grabazioan zehar, Raspberry Pi blokeatu egin da, etab.)
Zoritxarrez, halako errore bat gertatuz gero, aukera bakarra erregistro baliogabeak alde batera uztea eta datuak galdutzat ematea da; - Idazketa-erroreak (arrazoiren batengatik, idatzitakoaz bestelako zerbait idatzi da flash memorian)
Grabaketaren ondoren berehala kontrol-irakurketa bat egiten badugu, berehala detekta ditzakegu errore horiek; - Datuen hondatzea memorian biltegiratzean zehar;
- Irakurketa-erroreak
Akatsa zuzentzeko, kontrol-batura bat ez badator, nahikoa da irakurketa hainbat aldiz errepikatzea.
Horrek esan nahi du 3. motako erroreak bakarrik (biltegiratzean datuen ustelkeria espontaneoa) ezin direla zuzendu erroreak zuzentzeko kodeketarik gabe. Badirudi errore horiek oso litekeena ez direla oraindik.
Laburpena: Kodeketa erredundantea alde batera uztea erabaki zen, baina eragiketak erabaki hori okerra dela erakusten badu, arazoa aztertzera itzuliko gara (akatsei buruzko dagoeneko metatutako estatistikekin, eta horrek kodeketa mota optimoa hautatzeko aukera emango digu).
Beste
Noski, artikuluaren formatuak ez du formatuko zati bakoitza justifikatzen uzten. (eta dagoeneko nekatuta nago), beraz, lehenago ukitu ez diren puntu batzuk laburki aztertuko ditut.
- Orrialde guztiak "berdin" egitea erabaki zen
Hau da, ez da metadatuekin orrialde berezirik, jario bereizirik eta abarrik egongo, baizik eta orrialde guztiak txandaka berridazten dituen jario bakarra.
Horrek orrialdeen higadura uniformea bermatzen du, akats-puntu bakar bat ere ez, eta polita besterik ez; - Ezinbestekoa da formatuaren bertsioen kudeaketa eskaintzea.
Goiburuan bertsio-zenbakirik gabeko formatua gaiztoa da!
Nahikoa da orrialde-buruan Zenbaki Magiko (sinadura) jakin bat duen eremu bat gehitzea, erabilitako formatuaren bertsioa adieraziko duena. (Ez dut uste praktikan dozena bat ere izango direnik); - Erabili luzera aldakorreko goiburua erregistroetarako (asko dira), kasu gehienetan byte 1eko luzera izan dezan saiatuz;
- Konprimitutako erregistroaren goiburuaren luzera eta moztutako zatiaren luzera kodetzeko, erabili luzera aldakorreko kode bitarrak.
Oso lagungarria izan zen. Huffman kodeak. Minutu gutxitan, beharrezko luzera aldakorreko kodeak aurkitu ahal izan genituen.
Datuak gordetzeko formatuaren deskribapena
Byte ordena
Byte bat baino handiagoak diren eremuak big-endian formatuan gordetzen dira (sareko byte ordena), hau da, 0x1234 0x12, 0x34 bezala idazten da.
Orrialdetan zatitzea.
Flash memoria guztia tamaina bereko orrialdeetan banatuta dago.
Orrialdearen lehenetsitako tamaina 32 KB da, baina memoria-txiparen tamaina osoaren 1/4 baino gehiago ez (4 MB-ko txiparentzat 128 orrialde dira).
Orrialde bakoitzak datuak besteengandik independenteki gordetzen ditu (hau da, orrialde bateko datuek ez diete beste orrialde bateko datuei erreferentzia egiten).
Orrialde guztiak ordena naturalean zenbakituta daude (helbideen ordena gorakorrean), 0 zenbakitik hasita (zero orrialdea 0 helbidean hasten da, lehenengoa 32 KB-tan, bigarrena 64 KB-tan, etab.)
Memoria-txipa eraztun-buffer gisa erabiltzen da, hau da, lehenik grabazioa 0 orrialdera doa, gero 1 orrialdera, ..., azken orrialdea betetzen dugunean, ziklo berri bat hasten da eta grabazioa zero orrialdetik jarraitzen du.
Orriaren barruan.

Orriaren hasieran, 4 byteko orrialde-burua gordetzen da, ondoren goiburuaren kontrol-batura (CRC-32C), eta azkenik erregistroak "goiburua, datuak, kontrol-batura" formatuan gordetzen dira.
Orrialdearen goiburua (diagraman berde zikina) honako hauek ditu:
- bi byteko zenbaki magikoen eremua (formatuaren bertsioaren adierazle gisa ere ezagutzen da)
formatuaren egungo bertsioarentzat honela hartzen da kontuan0xed00 ⊕ номер страницы; - bi byteko "Orrialdearen bertsioa" kontagailua (memoria berridazketa zikloaren zenbakia).
Orrialde bateko erregistroak forma konprimituan gordetzen dira (deflate algoritmoa erabiliz). Orrialde bakarreko erregistro guztiak korronte bakarrean konprimitzen dira (hiztegi partekatu bat erabiliz), eta konpresioa berriro hasten da orrialde berri bakoitzean. Horrek esan nahi du edozein erregistro deskonprimitzeko orrialde horretako aurreko erregistro guztiak behar direla (eta orrialde horretakoa bakarrik).
Erregistro bakoitza Z_SYNC_FLUSH banderarekin konprimatuko da, eta ondorioz, konprimitutako jarioa 4 byte-rekin amaituko da: 0x00, 0x00, 0xff, 0xff, eta agian aurretik beste zero byte bat edo bi egon daitezke.
Sekuentzia hau (4, 5 edo 6 byte-koa) baztertzen dugu flash memorian idazterakoan.
Erregistroaren goiburua 1, 2 edo 3 bytekoa da, eta honako hauek gordetzen ditu:
- erregistro mota adierazten duen bit bat (T): 0 - testuingurua, 1 - erregistroa;
- 1etik 7 biterako luzera aldakorreko eremua (S), goiburuaren luzera eta erregistroari deskonprimitzeko gehitu behar zaion "buztana" definitzen duena;
- erregistroaren luzera (L).
S balioen taula:
S
Goiburuaren luzera, byteetan
Idaztean baztertua, byte
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Ilustratzen saiatu naiz, baina ez dakit zein argi geratu den:
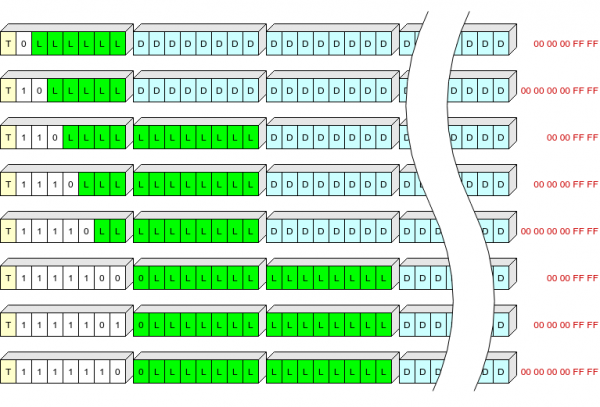
Hemen T eremua horiz markatuta dago, S eremua zuriz, L (datu konprimituen luzera bytetan) berdez, datu konprimituak urdinez eta flash memorian idazten ez diren datu konprimituen azken byteak gorriz.
Horrela, luzera ohikoeneko erregistro-goiburuak (konprimitutako forman 63+5 byte artekoak) byte batean idatz ditzakegu.
Idazketa bakoitzaren ondoren, CRC-32C kontrol-batura bat gordetzen da, aurreko kontrol-baturaren alderantzizko balioa hasierako balio gisa (init) erabiltzen duena.
CRC-k "iraupen" propietatea du, formula honek funtzionatzen du (prozesuan bit inbertsioa gehi edo ken):  .
.
Hau da, orrialde honetako aurreko goiburuko byte eta datu guztien CRC kalkulatzen dugula.
Kontrol-baturaren ondoren hurrengo erregistroaren goiburua dago.
Goiburua bere lehen bytea beti 0x00 eta 0xff-tik desberdina izan dadin diseinatuta dago (goiburuko lehen bytearen ordez 0xff aurkitzen badugu, erabili gabeko eremua dela esan nahi du; 0x00-k errore bat adierazten du).
Algoritmo hurbilduak
Flash memoriatik irakurtzea
Edozein irakurketa kontrol-baturaren egiaztapen batekin batera doa.
Kontrol-batura ez badator bat, irakurketa hainbat aldiz errepikatzen da, azkenean datu zuzenak irakurtzeko itxaropenarekin.
(zentzua du horrek, Linux Ez ditu NOR Flash-eko irakurketak cachean gordetzen, egiaztatuta)
Flash memorian idaztea
Datuak idazten ditugu.
Irakur ditzagun.
Irakurritako datuak idatzitako datuekin bat ez badatoz, eremua zeroekin betetzen dugu eta errorea adierazten dugu.
Mikrozirkuitu berri bat funtzionatzeko prestatzea
Hasieratzeko, 1 bertsioa duen goiburu bat idazten da lehenengo orrialdean (zehatzago esanda, zero orrialdean).
Ondoren, hasierako testuingurua (makinaren UUIDa eta lehenetsitako ezarpenak dituena) orrialde honetan idazten da.
Hori da, flash memoria erabiltzeko prest dago.
Makina kargatzen.
Kargatzean, orrialde bakoitzaren lehen 8 byteak (goiburua + CRC) irakurtzen dira; zenbaki magiko ezezaguna edo CRC baliogabea duten orrialdeak ez dira kontuan hartzen.
"Orrialde zuzenetatik" bertsio maximoa duten orrialdeak hautatzen dira, eta hauetatik zenbakirik handiena duen orrialdea hartzen da.
Lehenengo erregistroa irakurtzen da, CRC zuzena den egiaztatzen da eta "testuinguru" bandera egiaztatzen da. Dena ondo badago, orrialde hau unekoa dela uste da. Bestela, aurreko orrialdera itzultzen gara "bizirik" dagoen orrialde bat aurkitu arte.
eta aurkitutako orrialdean erregistro guztiak irakurtzen ditugu, "testuinguru" bandera aplikatzen dugunak.
Zlib hiztegia gordetzen dugu (orrialde honetara gehitzeko beharrezkoa izango da).
Hori da, deskarga amaitu da, testuingurua berrezarri da, lan egin dezakezu.
Erregistroko sarrera bat gehitzea
Erregistroa hiztegi egokiarekin konprimitzen dugu, Z_SYNC_FLUSH zehaztuz. Konprimitutako erregistroa uneko orrialdean sartzen den egiaztatzen dugu.
Ez bada egokitzen (edo orrialdean CRC akatsak badaude), hasi orrialde berri bat (ikus behean).
Erregistroa eta CRC idazten ditugu. Errore bat gertatzen bada, orrialde berri bat hasten dugu.
Orrialde berria
Zenbakirik txikiena duen orrialde libre bat hautatzen dugu (goiburuan baliogabeko kontrol-batura duen orrialdea edo unekoaren bertsioa baino txikiagoa dena) libretzat hartzen dugu. Halako orrialderik ez badago, unekoaren bertsio berdina dutenen artean zenbakirik txikiena duen orrialdea hautatzen dugu.
Hautatutako orrialdea ezabatzen dugu. Edukia 0xff-rekin alderatzen dugu. Zerbait gaizki badago, hurrengo orrialde eskuragarria hartzen dugu, eta abar.
Ezabatutako orrialdean goiburua idazten dugu, lehenengo sarrera testuinguruaren uneko egoera da, eta hurrengo sarrera idatzi gabeko erregistro-sarrera da (baldin badago).
Formatuaren aplikagarritasuna.
Nire ustez, formatu ona da NOR Flash-en informazio-jario konprimagarriagoak (testu arrunta, JSON, MessagePack, CBOR, agian protobuf) gordetzeko.
Noski, formatua "zorroztu" eginda dago SLC NOR Flasherako.
Ez da erabili behar NAND edo MLC NOR bezalako BER handiko euskarriekin. (Salgai al dago memoria mota hau? Zuzenketa-kodeei buruzko artikuluetan bakarrik ikusi ditut aipamenak.).
Gainera, ez da erabili behar FTL propioa duten gailuekin: USB flash unitateak, SD, MicroSD, etab. (Memoria mota honetarako, 512 byteko orrialde-tamaina, orrialde bakoitzaren hasieran sinadura eta erregistro-zenbaki bakarrak zituen formatu bat sortu nuen; batzuetan, "akats" bateko flash drive bateko datu guztiak berreskuratzeko gai nintzen irakurketa sekuentzial soil batekin).
Aplikazioaren arabera, formatua aldaketarik gabe erabil daiteke 128 Kbps-tik (16 Kbps-ra) 1 Gbps-ra (128 Mbps-ra) bitarteko flash unitateetan. Nahi izanez gero, edukiera handiagoko txipetan ere erabil daiteke, nahiz eta orrialdearen tamaina egokitu beharko den ziurrenik. (Baina hemen bideragarritasun ekonomikoaren galdera sortzen da; NOR Flash gaitasun handikoaren prezioa ez da itxaropentsua).
Norbaitek formatu hau interesgarria iruditzen bazaio eta kode irekiko proiektu batean erabili nahi badu, esan iezadazu. Saiatuko naiz kodea leuntzeko eta GitHub-en argitaratzen.
Ondorioa
Ikus dezakegunez, formatua sinplea izan zen azkenean. eta aspergarria ere bai.
Zaila da nire ikuspuntuaren bilakaera artikulu batean islatzea, baina sinets iezadazu: hasieran, zerbait sofistikatua, suntsiezina, hurbileko leherketa nuklear bati ere bizirauteko gai dena sortu nahi nuen. Hala ere, arrazoia (espero dut) azkenean nagusitu zen, eta pixkanaka lehentasunak sinpletasun eta trinkotasunerantz aldatu ziren.
Oker nagoela gerta liteke? Bai, noski. Oso posible da, adibidez, kalitate baxuko mikrotxip sorta bat erosi izana. Edo beste arrazoiren batengatik, ekipamenduak ez betetzea fidagarritasun itxaropenak.
Ba al dut horretarako planik? Uste dut artikulu hau irakurri ondoren, ez duzula zalantzarik izango badudala. Eta bat baino gehiago.
Larriagoa dena, formatua lan-aukera gisa eta "proba-globo" gisa garatu zen.
Momentuz, dena ondo dabil mahai gainean; irtenbidea egun gutxi barru zabalduko da. (gutxi gorabehera) Ehun gailutan, ikusiko dugu zer gertatzen den "borroka" erabileran (zorionez, espero dut formatuak hutsegiteen detekzio fidagarria ahalbidetzea, estatistika osoak bildu ahal izateko). Hilabete gutxi barru, ondorioak atera ahal izango ditugu. (eta zorte txarra baduzu, lehenago ere).
Erabili ondoren arazo larriak aurkitzen baditut eta hobekuntzak behar baditut, zalantzarik gabe idatziko dut horri buruz.
Literatura
Ez nuen erreferentzia zerrenda luze eta aspergarri bat osatu nahi; azken finean, denek dute Google.
Hemen bereziki interesgarriak iruditu zaizkidan aurkikuntzen zerrenda bat uztea erabaki nuen, baina pixkanaka artikuluaren testura zuzenean migratu ziren, eta elementu bakarra geratu zen zerrendan:
- Erabilgarritasuna zlib-en egilearena. Deflate/zlib/gzip artxiboen edukia argi eta garbi bistaratzen du. Deflate (edo gzip) formatuaren barne-funtsak ulertu behar badituzu, oso gomendagarria da.
Iturria: www.habr.com
