

CAP teorema sistema banatuen teoriaren oinarria da. Jakina, haren inguruko eztabaida ez da baretzen: bertan dauden definizioak ez dira kanonikoak, eta ez dago froga zorrotzik... Hala ere, eguneroko sen onaren posizioetan tinko eutsiz, intuizioz ulertzen dugu teorema egia dela.

Agerikoa ez den gauza bakarra "P" letraren esanahia da. Klusterra zatitzen denean, quoruma lortu arte ez erantzun edo eskuragarri dauden datuak itzultzen dituen erabakitzen du. Aukera horren emaitzen arabera, sistema CP edo AP gisa sailkatzen da. Cassandra, adibidez, edozein modutan joka daiteke, ez kluster ezarpenen arabera, baizik eta eskaera zehatz bakoitzaren parametroen arabera. Baina sistema "P" ez bada eta zatitzen bada, zer?
Galdera honen erantzuna ezustekoa da: CA kluster bat ezin da zatitu.
Zein motatako kluster da zatitu ezin dena?
Kluster horren funtsezko ezaugarri bat datuak biltegiratzeko sistema partekatua da. Kasu gehienetan, horrek SAN baten bidezko konexioa esan nahi du, eta horrek CA irtenbideen erabilera SAN azpiegitura bat mantentzeko gai diren enpresa handietara mugatzen du. Hainbat... zerbitzariak Datu berberekin lan egiteko, kluster fitxategi-sistema bat behar da. Fitxategi-sistema horiek HPE (CFS), Veritas (VxCFS) eta IBM (GPFS) produktuen zorroetan daude eskuragarri.
Oracle RAC
Benetako Aplikazio Kluster aukera 2001ean agertu zen lehen aldiz, Oracle 9i-ren kaleratzearekin batera. Horrelako kluster batean, hainbat instantzia zerbitzaria datu-base berarekin lan egin.
Oracle-k klusteratutako fitxategi-sistemarekin eta bere soluzioarekin lan egin dezake - ASM, Biltegiratze Automatikoa.
Ale bakoitzak bere aldizkaria gordetzen du. Transakzioa instantzia batek exekutatzen eta konprometitzen du. Instantzia batek huts egiten badu, bizirik dauden kluster-nodoetako batek (instantzia) bere erregistroa irakurtzen du eta galdutako datuak leheneratzen ditu, eta horrela erabilgarritasuna bermatzen du.
Instantzia guztiek beren cachea mantentzen dute, eta orrialde berdinak (blokeak) hainbat instantziaren cacheetan egon daitezke aldi berean. Gainera, instantzia batek orri bat behar badu eta beste instantzia baten cachean badago, bere bizilagunarengandik lor dezake diskotik irakurri beharrean cache fusio mekanismoa erabiliz.
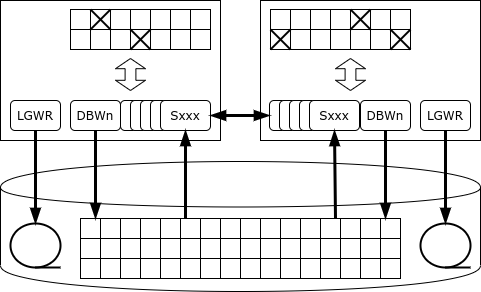
Baina zer gertatzen da instantziaren batek datuak aldatu behar baditu?
Oracle-ren berezitasuna da ez duela blokeo-zerbitzu dedikaturik: zerbitzariak errenkada bat blokeatu nahi badu, blokeo-erregistroa blokeatutako errenkada dagoen memoria-orrian jartzen da zuzenean. Ikuspegi honi esker, Oracle errendimenduko txapelduna da datu-base monolitikoen artean: blokeo zerbitzua ez da inoiz estutasun bihurtzen. Baina kluster konfigurazioan, halako arkitektura batek sareko trafiko bizia eta blokeoak ekar ditzake.
Erregistro bat blokeatuta dagoenean, instantzia batek beste instantzia guztiei jakinarazten die erregistro hori gordetzen duen orrialdeak atxikipen esklusiboa duela. Beste instantzia batek orrialde bereko erregistro bat aldatu behar badu, orrialdeko aldaketak egin arte itxaron beharko du, hau da, aldaketaren informazioa diskoko aldizkari batean idazten da (eta transakzioak jarraitu ahal izango du). Gerta liteke ere orrialde bat hainbat kopiaz sekuentzialki aldatzea, eta gero orria diskoan idaztean orrialde honen uneko bertsioa nork gordetzen duen jakin beharko duzu.
RAC nodo desberdinetan orrialde berdinak ausaz eguneratzeak datu-basearen errendimendua nabarmen jaisten du, klusterren errendimendua instantzia bakar batena baino txikiagoa izan daitekeen punturaino.
Oracle RAC-en erabilera zuzena datuak fisikoki partitzea da (adibidez, partiziodun taularen mekanismoa erabiliz) eta partizio multzo bakoitza nodo dedikatu baten bidez atzitzea. RACren helburu nagusia ez zen eskalatze horizontala, akatsen tolerantzia bermatzea baizik.
Nodo batek bihotz-taupadari erantzutea uzten badu, orduan detektatu duen nodoak bozketa-prozedura bat hasiko du diskoan. Falta den nodoa hemen adierazten ez bada, orduan nodoetako batek hartuko du datuak berreskuratzeko ardura:
- Falta den nodoaren cachean zeuden orrialde guztiak "izozten" ditu;
- falta den nodoaren erregistroak (berregin) irakurtzen ditu eta erregistro horietan erregistratutako aldaketak berriro aplikatzen ditu, aldi berean beste nodo batzuek aldatzen ari diren orrien bertsio berriagoa duten ala ez egiaztatuz;
- zain dauden transakzioak atzera egiten ditu.
Nodoen artean aldatzea errazteko, Oracle-k zerbitzu baten kontzeptua du: instantzia birtual bat. Instantzia batek hainbat zerbitzu zerbitza ditzake, eta zerbitzu bat nodoen artean mugi daiteke. Datu-basearen zati jakin bat zerbitzatzen duen aplikazio-instantzia batek (adibidez, bezero-talde batek) zerbitzu batekin funtzionatzen du, eta datu-basearen zati honen arduraduna den zerbitzua beste nodo batera mugitzen da nodo batek huts egiten duenean.
Transakzioetarako IBM Pure Data Systems
DBMSrako kluster irtenbide bat Blue Giant zorroan agertu zen 2009an. Ideologikoki, Parallel Sysplex klusterraren oinordekoa da, ekipo "ohiko" gainean eraikia. 2009an, DB2 pureScale software-suite gisa kaleratu zen, eta 2012an, IBMk Pure Data Systems for Transactions izeneko tresna bat eskaini zuen. Ez da nahastu behar Pure Data Systems for Analytics-ekin, hau da, Netezza izenarekin bat baino ez da.
Lehen begiratuan, pureScale arkitektura Oracle RAC-en antzekoa da: era berean, hainbat nodo datuak biltegiratzeko sistema komun batera konektatzen dira, eta nodo bakoitzak bere DBMS instantzia exekutatzen du bere memoria-eremu eta transakzio-erregistroekin. Baina, Oracle-k ez bezala, DB2-k blokeo-zerbitzu dedikatu bat du db2LLM* prozesu multzo batek irudikatuta. Kluster-konfigurazioan, zerbitzu hau aparteko nodo batean jartzen da, hau da, Couling Facility (CF) Parallel Sysplex-en eta PowerHA Pure Data-n.
PowerHAk zerbitzu hauek eskaintzen ditu:
- sarraila kudeatzailea;
- Buffer cache globala;
- prozesuen arteko komunikazioen eremua.
PowerHA-tik datu-baseko nodoetara eta atzera datuak transferitzeko, urruneko memoriarako sarbidea erabiltzen da, beraz, kluster-interkonexioak RDMA protokoloa onartu behar du. PureScale-k Infiniband eta RDMA Ethernet bidez erabil ditzake.
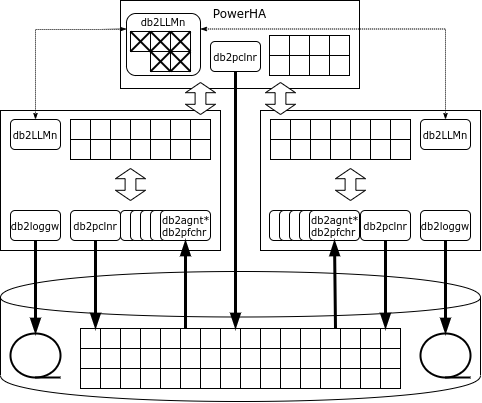
Nodo batek orrialde bat behar badu, eta orrialde hau ez badago cachean, orduan nodoak orrialdea eskatzen du cache globalean, eta bertan ez badago, diskotik irakurtzen du. Oracle ez bezala, eskaera PowerHAra bakarrik doa, eta ez aldameneko nodoetara.
Instantzia batek errenkada bat aldatuko badu, modu esklusiboan blokeatzen du, eta errenkada dagoen orria modu partekatuan. Blokeo guztiak blokeoen kudeatzaile globalean erregistratzen dira. Transakzioa amaitzen denean, nodoak mezu bat bidaltzen dio blokeo-kudeatzaileari, eta honek aldatutako orria cache globalean kopiatzen du, blokeoak askatzen ditu eta aldatutako orrialdea baliogabetzen du beste nodoen cacheetan.
Aldatutako errenkada kokatuta dagoen orria dagoeneko blokeatuta badago, blokeo-kudeatzaileak aldatutako orria irakurriko du aldaketa egin duen nodoaren memoriatik, blokeoa askatu, aldatutako orria baliogabetuko du beste nodo batzuen cacheetan eta eman orrialdearen blokeoa eskatu duen nodoari.
“Zikina”, hau da, aldatuta, orrialdeak diskoan idatz daitezke bai nodo arrunt batetik eta bai PowerHAtik (castout).
PureScale nodoren batek huts egiten badu, hutsegite unean oraindik amaitu ez ziren transakzioetara soilik mugatuko da berreskurapena: amaitutako transakzioetan nodo horrek aldatutako orriak PowerHAko cache globalean daude. Nodoa konfigurazio murriztuan berrabiarazten da klusterreko zerbitzarietako batean, atzera egiten ditu zain dauden transakzioak eta blokeoak askatzen ditu.
PowerHA bi zerbitzaritan exekutatzen da eta nodo nagusiak bere egoera sinkronoki errepikatzen du. PowerHA nodo nagusiak huts egiten badu, klusterrak babeskopiko nodoarekin funtzionatzen jarraitzen du.
Jakina, datu multzora nodo bakar baten bidez sartzen bazara, klusterraren errendimendu orokorra handiagoa izango da. PureScale-k datu-eremu jakin bat nodo batek prozesatzen duela ere nabaritu dezake, eta, ondoren, eremu horri lotutako blokeo guztiak nodoak lokalean prozesatzen ditu PowerHArekin komunikatu gabe. Baina aplikazioa beste nodo baten bidez datu horietara sartzen saiatzen den bezain laster, blokeo zentralizatuaren prozesamenduari ekingo zaio.
IBMren barneko probek %90eko irakurketa eta %10eko idazketako lan-kargarekin, mundu errealeko ekoizpen-lan-kargaren oso antzekoa dena, 128 nodorainoko eskalatze ia lineala erakusten dute. Probaren baldintzak, zoritxarrez, ez dira ezagutarazi.
HPE NonStop SQL
Hewlett-Packard Enterprise zorroak ere eskuragarritasun handiko plataforma propioa du. NonStop plataforma da, Tandem Computers-ek 1976an merkaturatu zuena. 1997an Compaq-ek erosi zuen konpainia, eta Hewlett-Packard-ekin bat egin zuen 2002an.
NonStop aplikazio kritikoak eraikitzeko erabiltzen da, adibidez, HLR edo banku-txartelen prozesamendua. Plataforma software- eta hardware-konplexu baten moduan entregatzen da (tresna), eta horrek konputazio-nodoak, datuak biltegiratzeko sistema eta komunikazio-ekipoak barne hartzen ditu. ServerNet sareak (sistema modernoetan - Infiniband) balio du bai nodoen arteko trukerako bai datuak biltegiratzeko sistemara sartzeko.
Sistemaren lehen bertsioek elkarren artean sinkronizatuta zeuden jabedun prozesadoreak erabiltzen zituzten: eragiketa guztiak modu sinkronizatuan egiten zituzten hainbat prozesadorek, eta prozesadoreetako batek akats bat egin bezain laster, itzali egin zen eta bigarrenak lanean jarraitu zuen. Geroago, sistema ohiko prozesadoreetara aldatu zen (lehen MIPS, gero Itanium eta azkenik x86), eta sinkronizaziorako beste mekanismo batzuk erabiltzen hasi ziren:
- mezuak: sistema-prozesu bakoitzak "itzal" biki bat du, eta prozesu aktiboak aldian-aldian bere egoerari buruzko mezuak bidaltzen dizkio; prozesu nagusiak huts egiten badu, itzal prozesua azken mezuak zehazten duen unetik hasiko da lanean;
- bozketa: biltegiratze-sistemak hardware-osagai berezi bat du, hainbat sarbide berdin-berdin onartzen dituena eta sarbideak bat datozenean soilik exekutatzen dituena; Sinkronizazio fisikoaren ordez, prozesadoreek modu asinkronoan funtzionatzen dute, eta haien lanaren emaitzak I/O uneetan soilik konparatzen dira.
1987az geroztik, DBMS erlazional bat exekutatzen ari da NonStop plataforman - lehen SQL/MP, eta gero SQL/MX.
Datu-base osoa zatitan banatuta dago, eta zati bakoitza bere Datu-sarbide-kudeatzailea (DAM) prozesuaren arduraduna da. Datuak grabatzeko, katxeatzeko eta blokeatzeko mekanismoak eskaintzen ditu. Datuen prozesamendua dagozkien datu-kudeatzaileen nodo berdinetan exekutatzen diren Executor Server Prozesek egiten dute. SQL/MX programatzaileak zereginak exekutatzaileen artean banatzen ditu eta emaitzak batzen ditu. Adostutako aldaketak egitea beharrezkoa denean, TMF (Transaction Management Facility) liburutegiak eskaintzen duen bi faseko konpromiso-protokoloa erabiltzen da.
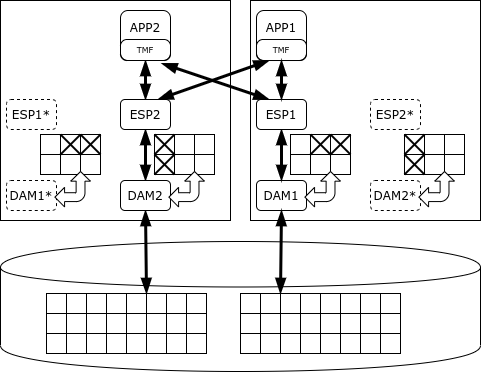
NonStop SQL-k prozesuei lehentasuna eman diezaieke, kontsulta analitiko luzeek transakzioen exekuzioa oztopatzeko. Hala ere, bere helburua transakzio laburren prozesamendua da, eta ez analitika. Garatzaileak NonStop klusterraren erabilgarritasuna bermatzen du bost "bederatzi" mailan, hau da, geldialdi-denbora urtean 5 minutu baino ez da.
SAP-HANA
HANA DBMS (1.0) lehen bertsio egonkorra 2010eko azaroan egin zen, eta SAP ERP paketea HANAra aldatu zen 2013ko maiatzean. Plataforma erositako teknologietan oinarritzen da: TREX Search Engine (bilaketa zutabeen biltegian), P*TIME DBMS eta MAX DB.
"HANA" hitza bera, High performance ANalytical Appliance akronimoa da. DBMS hau edozein x86 zerbitzarietan exekutatu daitekeen kode moduan hornitzen da, hala ere, instalazio industrialak ziurtatutako ekipoetan soilik onartzen dira. HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC-en eskuragarri dauden irtenbideak. Lenovo-ren konfigurazio batzuek SAN gabe funtzionatzea ere ahalbidetzen dute - biltegiratze-sistema arrunt baten papera disko lokaletan GPFS kluster batek betetzen du.
Goian zerrendatutako plataformek ez bezala, HANA memoria barneko DBMS bat da, hau da, lehen datuen irudia RAM-n gordetzen da, eta erregistroak eta aldizkako argazkiak bakarrik idazten dira diskoan hondamendia gertatuz gero berreskuratzeko.
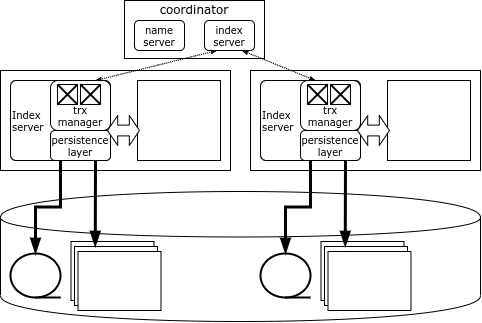
HANA kluster-nodo bakoitza bere datuen zatiaren erantzule da eta datu-mapa osagai berezi batean gordetzen da: Izen Zerbitzaria, koordinatzailearen nodoan kokatuta. Datuak ez dira bikoizten nodoen artean. Blokeatzeko informazioa ere nodo bakoitzean gordetzen da, baina sistemak blokeo-detektagailu global bat du.
HANA bezero bat kluster batera konektatzen denean, bere topologia deskargatzen du eta, ondoren, edozein nodo atzitu dezake zuzenean, behar dituen datuen arabera. Transakzio batek nodo bakar baten datuei eragiten badie, orduan nodo horrek lokalean exekutatu ahal izango du, baina hainbat nodoren datuak aldatzen badira, hasierako nodoak koordinatzaile nodoarekin harremanetan jartzen da, eta banatutako transakzioa ireki eta koordinatzen du, eta konpromezu bat erabiliz. bi faseko konpromiso protokolo optimizatua.
Koordinatzailearen nodoa bikoiztuta dago, beraz, koordinatzaileak huts egiten badu, babeskopia-nodoak berehala hartzen du bere gain. Baina datuak dituen nodo batek huts egiten badu, bere datuetara sartzeko modu bakarra nodoa berrabiaraztea da. Oro har, HANA klusterrek ordezko zerbitzari bat mantentzen dute bertan galdutako nodo bat ahalik eta azkarren berrabiarazteko.
Iturria: www.habr.com
