

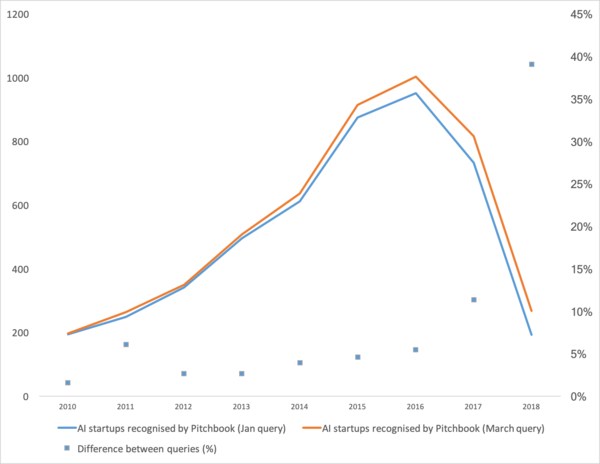
Duela gutxi kaleratua , azken urteotan ikaskuntza automatikoaren joera ona erakusten duena. Laburbilduz: ikasketa automatikoko startup-en kopuruak behera egin du azken bi urteetan.
Bueno. Ikus dezagun "burbuila lehertu den ala ez", "nola jarraitu bizitzen" eta hitz egin dezagun, lehenik eta behin, zirriborro hori nondik datorren.
Lehenik eta behin, hitz egin dezagun kurba honen bultzatzailea izan zenari buruz. Nondik atera zen? Ziurrenik dena gogoratuko dute machine learning 2012an ImageNet lehiaketan. Azken finean, hau da mundu mailako lehen ekitaldia! Baina errealitatean ez da horrela. Eta kurbaren hazkundea apur bat lehenago hasten da. Hainbat puntutan banatuko nuke.
- 2008an “big data” terminoa sortu zen. Benetako produktuak hasi ziren 2010az geroztik. Big data zuzenean lotuta dago ikaskuntza automatikoarekin. Big datarik gabe, garai hartan zeuden algoritmoen funtzionamendu egonkorra ezinezkoa da. Eta hauek ez dira sare neuronalak. 2012ra arte, sare neuronalak gutxiengo marjinal baten babespean zeuden. Baina orduan algoritmo guztiz desberdinak funtzionatzen hasi ziren, urteak edo baita hamarkadak ere existitzen zirenak: (1963,1993, XNUMX), (1995), (2003),... Urte haietako startup-ak datu egituratuen tratamendu automatikoarekin lotuta daude batez ere: kutxazainak, erabiltzaileak, publizitatea, eta askoz gehiago.
Lehen olatu honen eratorria XGBoost, CatBoost, LightGBM eta abar bezalako framework multzo bat da.
- 2011-2012an irudiak aitortzeko hainbat lehiaketa irabazi zituen. Haien benetako erabilera zertxobait atzeratu zen. 2014an esanguratsuak diren startupak eta irtenbideak agertzen hasi zirela esango nuke. Bi urte behar izan ziren neuronek oraindik funtzionatzen dutela digeritzeko, arrazoizko epe batean instalatu eta abiarazi zitezkeen esparru erosoak sortzeko, konbergentzia denbora egonkortu eta bizkortuko zuten metodoak garatzeko.
Sare konbolutiboek ordenagailu bidezko ikusmenaren arazoak konpontzea ahalbidetu zuten: irudian dauden irudien eta objektuen sailkapena, objektuen detekzioa, objektuak eta pertsonak antzematea, irudiaren hobekuntza, etab., etab.
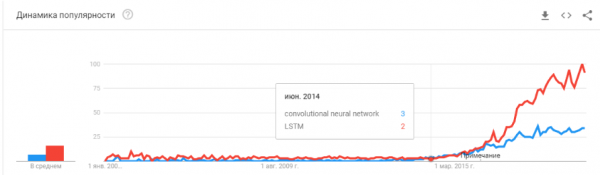
- 2015-2017. Sare errekurrenteetan edo haien analogoetan oinarritutako algoritmoen eta proiektuen boom-a (LSTM, GRU, TransformerNet, etab.). Ondo funtzionatzen duten hizketarako testurako algoritmoak eta itzulpen automatikoko sistemak agertu dira. Neurri batean, oinarrizko ezaugarriak ateratzeko sare konbolutiboetan oinarritzen dira. Neurri batean datu multzo oso handiak eta onak biltzen ikasi genuelako.
«Burbuila lehertu al da? Hipea gehiegi berotuta al dago? Blockchain gisa hil ziren?”.
Bestela! Bihar Sirik zure telefonoan lan egiteari utziko dio, eta etzi Teslak ez du jakingo txanda baten eta kanguru baten arteko aldea.
Sare neuronalak lanean ari dira dagoeneko. Dozenaka gailutan daude. Benetan dirua irabazteko, merkatua eta zure inguruko mundua aldatzeko aukera ematen dizute. Hype apur bat desberdina da:
Besterik da, sare neuronalak jada ez direla zerbait berria. Bai, jende askok itxaropen handiak ditu. Baina enpresa ugarik ikasi dute neuronak erabiltzen eta horietan oinarritutako produktuak egiten. Neuronek funtzionalitate berriak eskaintzen dituzte, lanpostuak mozteko eta zerbitzuen prezioa murrizteko aukera ematen dute:
- Fabrikazio enpresak algoritmoak integratzen ari dira produkzio-lerroan akatsak aztertzeko.
- Abeltzaintzako ustiategiek behiak kontrolatzeko sistemak erosten dituzte.
- Konbinatu automatikoak.
- Dei-zentro automatizatuak.
- Iragazkiak SnapChat-en. (beno, zerbait erabilgarria behintzat!)
Baina gauza nagusia, eta ez nabarmenena: "Ez dago ideia berri gehiago, edo ez dute berehalako kapitalik ekarriko". Sare neuronalek dozenaka arazo konpondu dituzte. Eta are gehiago erabakiko dute. Bazeuden ideia ageriko guztiek startup asko sortu zituzten. Baina azalean zegoen guztia bilduta zegoen jada. Azken bi urteotan, ez dut sare neuronalak erabiltzeko ideia berri bakar bat ere aurkitu. Ikuspegi berri bakar bat ere ez (beno, ados, arazo batzuk daude GANekin).
Eta ondorengo startup bakoitza gero eta konplexuagoa da. Jada ez ditu datu irekiak erabiliz neurona bat entrenatzen duten bi mutil behar. Programatzaileak, zerbitzari bat, markatzaile talde bat, euskarri konplexua eta abar behar ditu.
Ondorioz, startup gutxiago daude. Baina ekoizpen gehiago dago. Matrikularen aitorpena gehitu behar duzu? Merkatuan esperientzia garrantzitsua duten ehunka espezialista daude. Norbait kontratatu dezakezu eta hilabete pare batean zure langileak egingo du sistema. Edo erosi prest. Baina startup berri bat egiten?... Zoratuta!
Bisitarien jarraipena egiteko sistema bat sortu behar duzu - zergatik ordaindu lizentzia mordoa 3-4 hilabetetan zurea egin dezakezunean, zorroztu zure negoziorako.
Orain sare neuronalak beste dozenaka teknologiak egin duten bide beretik doaz.
Gogoratzen al duzu nola aldatu den “webguneen garatzailea” kontzeptua 1995etik? Merkatua ez dago oraindik espezialistekin ase. Oso profesional gutxi daude. Baina apustu egin dezaket 5-10 urte barru ez dela alde handirik egongo Java programatzaile baten eta sare neuronalaren garatzaile baten artean. Bi espezialistak nahikoa izango dira merkatuan.
Besterik gabe, neuronek ebatzi ditzaketen arazoen klase bat egongo da. Zeregin bat sortu da - espezialista bat kontratatu.
"Zer da hurrengoa? Non dago agindutako adimen artifiziala?”
Baina hemen gaizki-ulertu txiki baina interesgarri bat dago :)
Gaur egun dagoen teknologia pila, itxuraz, ez gaitu adimen artifizialera eramango. Ideiak eta haien berritasunak neurri handi batean agortu dira. Hitz egin dezagun gaur egungo garapen mailari buruz.
Murrizketak
Has gaitezen auto gidatzen diren autoekin. Garbi dirudi gaur egungo teknologiarekin guztiz autonomoak diren autoak egitea posible dela. Baina zenbat urtetan gertatuko den hori ez dago argi. Teslak uste du hori pare bat urte barru gertatuko dela -

Beste asko daude , 5-10 urtekoa dela uste dute.
Seguruenik, nire ustez, 15 urte barru hirietako azpiegiturak berak aldatuko dira, halako moldez non auto autonomoen agerpena saihestezin bihurtuko da eta bere jarraipena izango da. Baina hori ezin da adimentzat hartu. Tesla modernoa datuak iragazteko, bilatzeko eta birziklatzeko kanalizazio konplexua da. Hauek dira arau-arauak-arauak, datu bilketa eta horien gaineko iragazkiak (hemen Honi buruz pixka bat gehiago idatzi nuen, edo ikusi markak).
Lehen arazoa
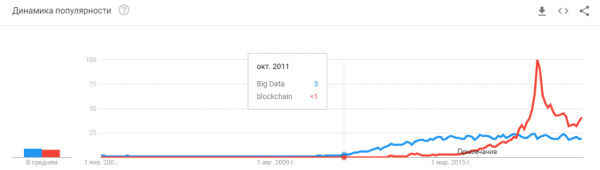
Eta hemen ikusten dugu oinarrizko lehen arazoa. Big data. Horixe da, hain zuzen, sare neuronalen eta ikasketa automatikoaren egungo olatua sortu zuena. Gaur egun, zerbait konplexua eta automatikoa egiteko, datu asko behar dira. Ez asko, oso-oso. Algoritmo automatizatuak behar ditugu biltzeko, markatzeko eta erabiltzeko. Autoari kamioiak eguzkiari begira ikusarazi nahi ditugu; lehenik eta behin, kopuru nahikoa bildu behar dugu. Kotxea ez erotzea nahi dugu maleteroan loturiko bizikleta batekin - lagin gehiago.
Gainera, adibide bat ez da nahikoa. Ehunka? Milaka?

Bigarren arazoa
Bigarren arazoa — gure sare neuronalak ulertu duenaren bistaratzea. Oso zeregin ez hutsala da. Orain arte, jende gutxik ulertzen du hori nola ikusi. Artikulu hauek oso berriak dira, adibide batzuk besterik ez dira, nahiz eta urrunak izan:
testurekiko obsesioa. Ondo erakusten du neuronak zertan finkatzeko joera duen + hasierako informazio gisa hautematen duena.

Arreta at . Izan ere, erakarpena sarritan erabil daiteke, hain zuzen, sareko erreakzio hori zerk eragin duen erakusteko. Halako gauzak ikusi ditut bai arazketarako bai produktuen konponbideetarako. Artikulu asko daude gai honi buruz. Baina datuak zenbat eta konplexuagoak izan, orduan eta zailagoa da bistaratzea sendoa nola lortu ulertzea.

Tira, bai, "begira zer dagoen sare barruan " Irudi hauek ezagunak ziren duela 3-4 urte, baina denak azkar konturatu ziren irudiak ederrak zirela, baina ez zuten esanahi handirik.
Ez ditut aipatu beste hamaika tramankulu, metodo, hack, sarearen barruak nola bistaratzeko ikerketa. Tresna hauek funtzionatzen dute? Arazoa zein den azkar ulertzen eta sarea arakatzen laguntzen dizute?... Azken ehunekoa lortzen? Beno, gutxi gorabehera berdina da:

Kaggle-n edozein lehiaketa ikus dezakezu. Eta jendeak azken erabakiak nola hartzen dituenaren deskribapena. 100-500-800 eredu pilatu genituen eta funtzionatu zuen!
Gehiegi egiten ari naiz, noski. Baina ikuspegi hauek ez dute erantzun azkar eta zuzenik ematen.
Esperientzia nahikoa izanda, aukera desberdinak aztertu ondoren, zure sistemak erabaki hori zergatik hartu duen epaia eman dezakezu. Baina zaila izango da sistemaren portaera zuzentzea. Instalatu makulu bat, mugitu atalasea, gehitu datu-multzo bat, hartu backend sare bat.
Hirugarren arazoa
Hirugarren Oinarrizko Arazoa — sareek estatistikak irakasten dituzte, ez logika. Estatistikoki hau :

Logikoa denez, ez da oso antzekoa. Sare neuronalek ez dute ezer konplexurik ikasten behartuta egon ezean. Ahalik eta zeinu errazenak irakasten dituzte beti. Baduzu begiak, sudurra, burua? Beraz, hau da aurpegia! Edo jarri adibide bat non begiek aurpegia esan nahi ez duten. Eta berriro ere - milioika adibide.
Behealdean leku asko dago
Esango nuke hiru arazo global horiek direla gaur egun sare neuronalen eta ikaskuntza automatikoaren garapena mugatzen dutenak. Eta arazo hauek mugatu ez zuten lekuetan, dagoeneko aktiboki erabiltzen da.
Hau bukaera da? Sare neuronalak martxan al daude?
Ezezaguna. Baina, noski, denek espero dute ezetz.
Goian nabarmendu ditudan oinarrizko arazoak konpontzeko planteamendu eta norabide asko daude. Baina orain arte, planteamendu horietako batek ere ez du posible egin funtsean berria den zerbait egitea, oraindik konpondu ez den zerbait konpontzea. Orain arte, oinarrizko proiektu guztiak planteamendu egonkorretan oinarrituta egiten ari dira (Tesla), edo institutu edo korporazioen proba proiektuak izaten jarraitzen dute (Google Brain, OpenAI).
Gutxi gorabehera, norabide nagusia sarrerako datuen goi-mailako irudikapena sortzea da. Zentzu batean, “memoria”. Memoriaren adibiderik errazena hainbat "Embedding" - irudi irudikapenak dira. Tira, adibidez, aurpegia ezagutzeko sistema guztiak. Sareak aurpegi batetik biraketaren, argitasunaren edo bereizmenaren araberakoa ez den irudikapen egonkorren bat lortzen ikasten du. Funtsean, sareak "aurpegi desberdinak urrun daude" eta "aurpegi berdinak gertu daude" metrika minimizatzen du.
Prestakuntza hori egiteko, hamarnaka eta ehunka mila adibide behar dira. Baina emaitzak "One-Shot Learning"-ren oinarri batzuk ditu. Orain ez ditugu ehunka aurpegi behar pertsona bat gogoratzeko. Aurpegi bakarra eta hori baino ez gara !
Arazo bakarra dago... Sareak objektu nahiko sinpleak bakarrik ikas ditzake. Aurpegiak ez bereizten saiatzean, adibidez, "jendea arroparen arabera" (zeregin ) - kalitatea magnitude-ordena asko jaisten da. Eta sareak ezin ditu angeluetan aldaketa nahiko nabariak ikasi.
Eta milioika adibideetatik ikastea ere dibertigarria da.
Hauteskundeak nabarmen murrizteko lana dago. Adibidez, berehala gogora daiteke lehen lanetako bat OneShot Ikaskuntza :
Horrelako lan asko daude, adibidez edo edo .
Badira ken bat - normalean entrenamenduak ondo funtzionatzen du "MNIST" adibide sinple batzuetan. Eta zeregin konplexuetara pasatzean, datu-base handi bat, objektuen eredu bat edo magia motaren bat behar duzu.
Orokorrean, One-Shot prestakuntza lantzea oso gai interesgarria da. Ideia asko aurkitzen dituzu. Baina gehienetan, zerrendatu ditudan bi arazoek (datu multzo handi batean aurretrebatzea / datu konplexuetan ezegonkortasuna) asko oztopatzen dute ikaskuntza.
Bestalde, GANek —sortzaile-sare aurkariek— txertatzearen gaiari heltzen diote. Seguruenik, gai honi buruz Habré-ri buruzko artikulu mordoa irakurri duzu. (, ,)
GAN-en ezaugarri bat barne-egoera-espazioren bat eratzea da (funtsean Embedding bera), eta horrek irudi bat marrazteko aukera ematen du. Izan daiteke , izan daiteke .
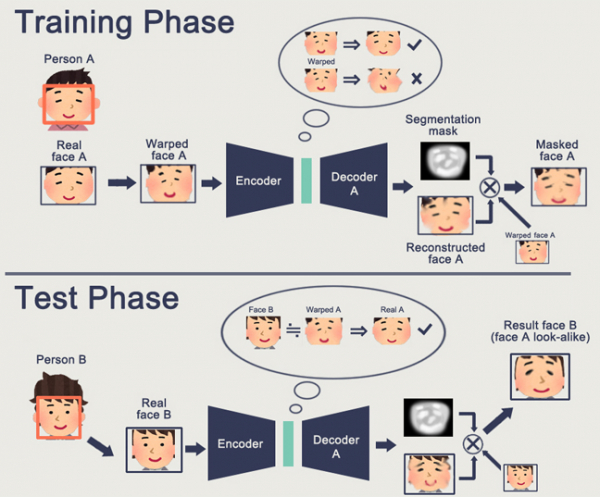
GANen arazoa da sortutako objektua zenbat eta konplexuagoa izan, orduan eta zailagoa dela "sorgailu-diskriminatzaile" logikan deskribatzea. Ondorioz, entzuten diren GANen benetako aplikazio bakarrak DeepFake dira, eta, berriro ere, aurpegiko irudikapenak manipulatzen ditu (horretarako oinarri handia dago).
Beste erabilera erabilgarria gutxi ikusi dut. Normalean, irudien marrazkiak amaitzen dituzten trikimailu mota batzuk.
Eta berriro. Inork ez du ideiarik nola honek etorkizun distiratsuago batera mugitzeko aukera emango digunik. Logika/espazioa sare neuronalean irudikatzea ona da. Baina adibide ugari behar ditugu, ez dugu ulertzen neuronak berez nola adierazten duen hori, ez dugu ulertzen neuronak ideia benetan konplexuren bat gogorarazi.
Errefortzuaren ikaskuntza - Norabide guztiz ezberdin bateko planteamendua da. Seguru gogoan duzu Google-k nola irabazi zituen guztiak Go-n. Azken garaipenak Starcraft eta Dota-n. Baina hemen dena ez dago hain arrosa eta itxaropentsutik. RL eta bere konplexutasunaz hitz egiten du onena .
Egileak idatzitakoa laburki laburtzeko:
- Kutxaz kanpoko ereduak ez dira kabitzen / gaizki funtzionatzen dute kasu gehienetan
- Arazo praktikoak errazagoak dira beste modu batzuetan konpontzen. Boston Dynamics-ek ez du RL erabiltzen bere konplexutasuna/ezusteko/konplexutasun konputazionala dela eta
- RL funtziona dezan, funtzio konplexu bat behar duzu. Askotan zaila da sortzea/idaztea
- Zaila da ereduak trebatzea. Denbora asko eman behar duzu ponpatzeko eta tokiko optimatik irteteko
- Ondorioz, zaila da eredua errepikatzea, eredua ezegonkorra da aldaketa txikienekin
- Askotan ausazko eredu batzuk gainditzen ditu, baita ausazko zenbaki-sorgailu batek ere
Gakoa da RLk ez duela oraindik produkzioan lan egiten. Google-k esperimentu batzuk ditu ( , ). Baina ez dut produktu sistema bakar bat ere ikusi.
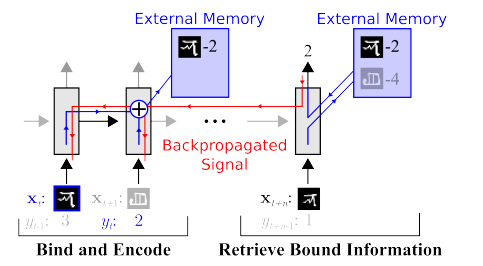
Memoria. Goian azaldutako guztiaren alde txarra egitura eza da. Hori guztia txukuntzen saiatzeko planteamenduetako bat neurona sareari memoria bereizirako sarbidea ematea da. Bertan bere urratsen emaitzak grabatu eta berridatzi ahal izateko. Orduan, sare neuronalak uneko memoria egoeraren arabera zehaztu daiteke. Hau prozesadore eta ordenagailu klasikoen oso antzekoa da.
Ospetsuena eta ezagunena - DeepMind-etik:
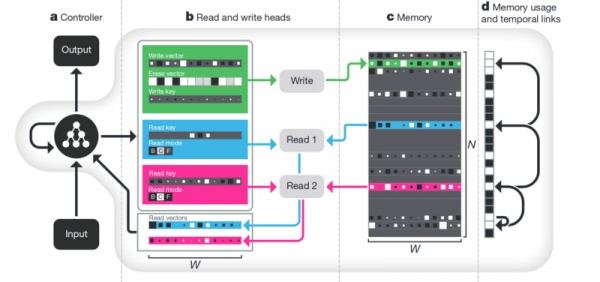
Badirudi hori dela adimena ulertzeko gakoa? Baina seguruenik ez. Sistemak oraindik datu kopuru handia behar du entrenatzeko. Eta datu taula egituratuekin lan egiten du batez ere. Gainera, Facebook denean antzeko arazo bat, orduan hartu zuten bidea: "Torloju memoria, neurona korapilatu eta adibide gehiago eduki, eta bere kabuz ikasiko du".
Deskonbinazioa. Memoria esanguratsu bat sortzeko beste modu bat txertaketa berdinak hartzea da, baina entrenamenduan zehar, horietan "esanahiak" nabarmentzeko aukera emango duten irizpide osagarriak sartu. Esaterako, sare neuronal bat trebatu nahi dugu denda batean giza jokabidea bereizteko. Bide estandarra jarraituz gero, dozena bat sare egin beharko genituzke. Bata pertsona baten bila dabil, bigarrena zer egiten ari den zehaztea, hirugarrena bere adina, laugarrena bere generoa. Logika bereiziak hau egiteko trebatuta dagoen/dendako zatiari begiratzen dio. Hirugarrenak zehazten du bere ibilbidea, etab.
Edo, datu kopuru infinitua balego, orduan posible izango litzateke sare bat trebatzea emaitza posible guztietarako (jakina, datu-sorta hori ezin da bildu).
Deskonbinazio ikuspegiak esaten digu: entrenatu dezagun sarea, berak kontzeptuak bereiz ditzan. Beraz, bideoan oinarritutako txertaketa bat osatuko luke, non eremu batek ekintza zehaztuko luke, lurrean dagoen posizioa denboran zehaztuko luke, pertsonaren altuera eta pertsonaren generoa zehaztuko luke. Aldi berean, entrenatzerakoan, nahiko nuke ia sarea ez eskatzea halako kontzeptu gakoekin, eremuak nabarmendu eta taldekatzea baizik. Halako artikulu dezente daude (horietako batzuk , , ) eta orokorrean nahiko teorikoak dira.
Baina norabide horrek, teorikoki behintzat, hasieran zerrendatutako arazoak estali beharko lituzke.
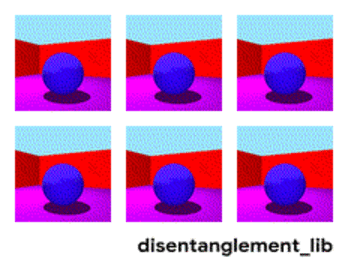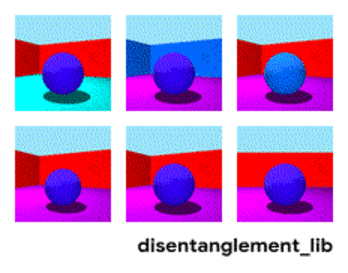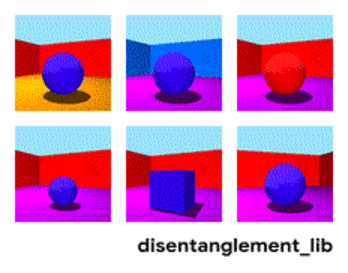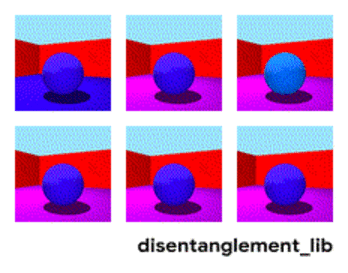
Irudiaren deskonposizioa "hormaren kolorea/zoruaren kolorea/objektuaren forma/objektuaren kolorea/eta abar" parametroen arabera.

Aurpegi baten deskonposizioa "tamaina, bekainak, orientazioa, azalaren kolorea, etab" parametroen arabera.
Beste
Badira beste hainbat arlo, ez hain globalak, datu-basea nolabait murrizteko, datu heterogeneoagoekin lan egiteko, etab.
Arreta. Seguruenik, ez du zentzurik hau metodo bereizi gisa bereiztea. Besteak hobetzen dituen planteamendu bat besterik ez. Artikulu asko berari eskainiak daude (,,). Arreta-puntua prestakuntzan zehar objektu esanguratsuei bereziki sarearen erantzuna hobetzea da. Askotan, kanpoko xede-izendapen baten edo kanpoko sare txiki baten bidez.
3D simulazioa. 3D motor on bat egiten baduzu, askotan entrenamendu-datuen % 90 estal dezakezu horrekin (adibide bat ere ikusi nuen non datuen ia % 99 motor on batek estaltzen zuen). Ideia eta hack asko daude 3D motor batean trebatutako sare bat datu errealak erabiliz funtzionatzeko (Tunening fina, estilo transferentzia, etab.). Baina, askotan, motor on bat egitea hainbat magnitude-ordena zailagoa da datuak biltzea baino. Motorrak egin zireneko adibideak:
Roboten prestakuntza (, )
prestakuntza salgaiak dendan (baina egin genituen bi proiektuetan erraz egin genezake gabe).
Teslan entrenatzen (berriz, goiko bideoa).
Findings
Artikulu osoa, nolabait, ondorioak dira. Seguruenik, egin nahi nuen mezu nagusia izan zen: "opariak amaitu dira, neuronek jada ez dute irtenbide sinplerik ematen". Orain gogor lan egin behar dugu erabaki konplexuak hartzeko. Edo gogor lan egin ikerketa zientifiko konplexuak egiten.
Oro har, gaia eztabaidagarria da. Agian irakurleek badituzte adibide interesgarriagoak?
Iturria: www.habr.com
