

در ۱۴ مارس ۲۰۱۷، آرتور خاچویان، مدیرعامل Social Data Hub، در سالن سخنرانی BBDO سخنرانی کرد. آرتور در مورد نظارت هوشمند، ساخت مدلهای رفتاری، تشخیص محتوای عکس و ویدیو و سایر ابزارها و تحقیقات Social Data Hub که امکان هدفگیری مخاطبان را با استفاده از رسانههای اجتماعی و فناوریهای کلان داده فراهم میکنند، صحبت کرد.

آرتور خاچویان (از این پس - ق): سلام! سلام به همه! اسم من آرتور خاچویان است و من مرکز دادههای اجتماعی را اداره میکنم، جایی که ما تجزیه و تحلیلهای فکری جالب مختلفی از منابع داده باز، حوزههای اطلاعاتی انجام میدهیم و انواع تحقیقات جالب را انجام میدهیم.
امروز، همکارانم از گروه BBDO از من خواستند که در مورد فناوریهای مدرن تجزیه و تحلیل کلانداده، چه بزرگ و چه کوچک، برای تبلیغات صحبت کنم: نحوهی بهکارگیری آنها، و چند مثال جالب را به اشتراک بگذارم. امیدوارم در طول مسیر سوالاتی بپرسید، چون ممکن است کمی خستهکننده شود و اصل مطلب را پوشش ندهم، پس خجالت نکشید.
در واقع، حوزههای اصلی که تاکنون راهحلهای «تقریباً کلانداده» در آنها به کار گرفته شدهاند، کاملاً مشخص هستند: هدفگیری مخاطبان، تجزیه و تحلیل و انجام نوعی تحقیقات بازاریابی تحلیلی. اما همیشه جالب است که ببینیم چه دادههای اضافی میتوان یافت و چه معانی اضافی میتوان از بهکارگیری تجزیه و تحلیل استخراج کرد.
چرا برای تبلیغات به فناوری نیاز داریم؟
از کجا شروع کنیم؟ واضحترین مورد، تبلیغات رسانههای اجتماعی است. من امروز صبح این را گرفتم: به دلایلی، VKontakte فکر میکند که باید این تبلیغ خاص را ببینم... اینکه آیا این خوب است یا بد، یک سوال جداگانه است. میبینیم که من قطعاً در دسته سربازان وظیفه قرار میگیرم:

اولین و جالبترین چیزی که میتوان به عنوان یک راهحل تکنولوژیکی در نظر گرفت... اولین چیزی که میخواستم قبل از شروع تصمیم بگیرم، تعریف اصطلاحات بود: دادههای باز چیست و کلانداده چیست؟ چون هر کسی درک خودش را از این موضوع دارد و من نمیخواهم شرایط خودم را به کسی تحمیل کنم، اما... فقط برای اینکه هیچ اختلافی وجود نداشته باشد.
من شخصاً دادههای باز را هر چیزی میدانم که بتوانم بدون نیاز به نام کاربری یا رمز عبور به آن دسترسی داشته باشم. این شامل پروفایلهای باز رسانههای اجتماعی، نتایج جستجو، ثبتهای باز و غیره میشود. کلانداده، به تعبیر من، این است: اگر یک جدول داده باشد، یک میلیارد ردیف است؛ اگر نوعی ذخیرهسازی فایل باشد، چیزی حدود یک پتابایت داده است. هر چیز دیگری، در اصطلاح من، کلانداده نیست، اما چیزی نزدیک به آن است.
پروفایل سازی و امتیازدهی پروفایل با دقت بالا
بیایید قدم به قدم پیش برویم. اولین و جالبترین چیزی که میتوان از تجزیه و تحلیل منابع داده باز به دست آورد، پروفایلسازی با دقت بالا و امتیازدهی پروفایل است. این چیست؟ این مفهومی است که در آن میتوان از حساب رسانه اجتماعی شما نه تنها برای پیشبینی اینکه چه کسی هستید، بلکه برای پیشبینی علایق شما نیز استفاده کرد.
اما اکنون، با ترکیب منابع مختلف، میتوانید میانگین حقوق خود، هزینه آپارتمان و محل قرارگیری آن را بفهمید. و همه این دادهها را میتوان به معنای واقعی کلمه از منابع موجود استفاده کرد. به عنوان مثال، اگر حساب کاربری خود در رسانههای اجتماعی را بررسی کنید، مثلاً ببینید کجا زندگی میکنید و کجا کار میکنید؛ بفهمید شرکتی که در آن کار میکنید در چه بخش تجاری است؛ اگر تحلیلگر، مدیر و غیره هستید، موقعیتهای شغلی مشابه را از HH و Superjob دانلود کنید؛ به محل زندگی خود نگاه کنید (مثلاً یک پایگاه داده از CIAN)، بفهمید اجاره بها چقدر است، هزینه خرید در آنجا چقدر است و تقریباً پیشبینی کنید که چقدر درآمد دارید. علاوه بر این، با استفاده از رسانههای اجتماعی خود، میتوانید بفهمید که چقدر سفر میکنید، کجا واقع شدهاید و چقدر به کارفرمای خود وفادار هستید.
بر این اساس، ما میتوانیم با چنین تعداد زیادی از معیارها هر کاری که بخواهیم انجام دهیم. میتوانیم محصولی را که مورد علاقه شماست به شما ارائه دهیم. یک فروشگاه آنلاین را تصور کنید؟ شما به آنجا میروید - فروشگاه آنلاین حساب کاربری شما در شبکههای اجتماعی را شناسایی میکند و به شما میگوید: "ماشا، شما تازه از دوست پسرتان جدا شدهاید، در اینجا چند محصول خاص برای شما آورده شده است." این آینده نزدیک نیست...
موقعیت جغرافیایی یک فرد چگونه تعیین میشود؟
پاسخ به سوالات حضار:
- معمولاً ۸۰٪ از کل ورودها بر اساس محل دقیق سکونت آنها انجام میشود. اما برای افرادی که در هیچ کجا ثبت نام نمیکنند، چندین گزینه وجود دارد: یا ثبت نام، موقعیت جغرافیایی، یا تجزیه و تحلیل پستها و انتشارات در کل دوره زمانی که فرد چیزی نوشته است... و در جایی، چیزی مانند "میخواهم یک کالسکه در نزدیکی آکادمیچسکایا بخرم" یا "اخیراً چند نقاشی دیواری زشت روی دیوار اینجا دیدم" ظاهر میشود. به عبارت دیگر، تقریباً ۸۰٪ از افراد، موقعیت جغرافیایی، محل کار و محل سکونت خود را میتوان از دادهها یا فرادادههای جمعآوری شده از رسانههای اجتماعی تعیین کرد.
این، باز هم، تحلیل پست است. در سادهترین شکل خود، تحلیل ورودها و موقعیتهای جغرافیایی در شبکههای اجتماعی است که فرادادههای JPEG (که میتوانند برای رمزگشایی برخی اطلاعات استفاده شوند) را حذف نمیکنند. اما برای افراد باقیمانده، اینها معمولاً پخشهای متنی هستند: یا شخصی هنگام ارسال چیزی موقعیت مکانی خود را فاش میکند، یا شماره تلفن خود را فاش میکند که میتوان از آن برای یافتن تبلیغات در Avito یا حساب کاربری او در Avto.ru استفاده کرد. با استفاده از این دادهها، میتوانیم دادهها را ترکیب کنیم (برای مثال، "من در حال فروش یک ماشین در نزدیکی مایاکوفسکایا هستم") و یک حدس تقریبی بزنیم.
- مردم معمولاً این را در رسانههای اجتماعی پست میکنند. ما منحصراً با منابع باز کار میکنیم و اینجا منحصراً در مورد منابع باز صحبت میکنیم. آنها معمولاً تبلیغات منتشر میکنند - یعنی در حدود شصت درصد موارد، رایجترین داستانی که افراد شماره تلفن همراه فعلی خود را "به اشتراک میگذارند" تبلیغ چیزی برای فروش است. یا فرد در گروهی پست میگذارد ("من این یا آن را آنجا میفروشم") یا به چیز دیگری میپیوندد.
بله! آنها معمولاً در کامنتهایشان میگویند: «به من جواب بده، برایم پیامک بفرست، یا با این شماره با من تماس بگیر. این اتفاق اغلب برای افرادی میافتد که در رسانههای اجتماعی چیزی میفروشند یا میخرند، یا با کسی ارتباط برقرار میکنند...» بر این اساس، این شماره میتواند به پروفایل آنها در CIAN، اگر تا به حال چیزی پست کرده باشند، یا، باز هم، در Avito، لینک شود. اینها به سادگی محبوبترین و برترین منابع هستند و همچنان لینک خواهند داشت - Avito، CIAN و غیره.
- دارم در مورد یک فروشگاه آنلاین صحبت میکنم. مورد بعدی تشخیص چهره و فناوری تطبیق پروفایل خواهد بود (در مورد آن صحبت خواهیم کرد). از لحاظ تئوری، این فناوری میتواند در یک فروشگاه فیزیکی نیز اعمال شود. رویای بزرگ من این است که وقتی بنرهای خیابانی ظاهر میشوند، دوربینها هنگام عبور از کنار شما، چهره شما را ردیابی کنند. اما این کار طبق قانون ممنوع خواهد شد زیرا نقض حریم خصوصی است. امیدوارم دیر یا زود این اتفاق بیفتد.
- من این را از تجربه شخصیام دارم. خیلی اوقات، وقتی کسی برای شما نامه مینویسد، از حقایقی از زندگیاش که قرار است مخفی نگه دارید استفاده میکنید... مردم معمولاً میترسند. اما! طبق آمار اخیر، تعداد حسابهای خصوصی در رسانههای اجتماعی ۱۴ درصد کاهش یافته است. تعداد حسابهای جعلی در حال افزایش است، در حالی که تعداد حسابهای باز در حال افزایش است - مردم به طور فزایندهای به سمت باز بودن حرکت میکنند. من فکر میکنم که در عرض سه یا چهار سال، آنها دیگر به کسی که اطلاعاتی در مورد آنها میداند که احتمالاً نباید بدانند، واکنش شدیدی نشان نخواهند داد. اما در واقعیت، با نگاه کردن به دیوار آنها، این موضوع بسیار آسان است.
چه چیزهایی را میتوان از منابع آزاد گرفت؟
فهرست تقریبی از مواردی وجود دارد که میتوان با درجه اطمینان نسبتاً بالایی از منابع آزاد استنباط کرد. در واقعیت، معیارهای متفاوتتری نیز وجود دارد؛ بستگی به این دارد که چه کسی چنین تحقیقاتی را سفارش میدهد. یک آژانس منابع انسانی ممکن است علاقهمند باشد بداند که آیا شما در رسانههای اجتماعی یا هر جای دیگری در فضای عمومی فحاشی میکنید یا خیر. ممکن است کسی علاقهمند باشد بداند که آیا پستهای ناوالنی را دوست دارید یا برعکس، پستهای حزب روسیه متحد، یا اینکه آیا محتوای مستهجن را دوست دارید یا خیر - این اتفاقات اغلب رخ میدهد.
موارد اصلی عبارتند از ارزشهای خانوادگی، هزینه تقریبی یک آپارتمان یا خانه، پیدا کردن ماشین و غیره. بر اساس همه این عوامل، افراد را میتوان به گروههای اجتماعی تقسیم کرد. اینها کاربران مسکو تیندر هستند که (بر اساس تصاویرشان، حسابهای فیسبوکشان که پیدا شدهاند) چه کسانی هستند؛ بر اساس علایقشان، به گروههای اجتماعی مختلفی تقسیم میشوند:

با نزدیک شدن به تبلیغات، ما به تدریج از هدفگیری تبلیغاتی استاندارد فاصله گرفتهایم، جایی که مثلاً در VKontakte انتخاب میکنید که به مردان ۱۸ سالهای که گروههای خاصی را دنبال میکنند علاقهمند هستید. من این تصویر را در پایین دارم، اکنون به شما نشان خواهم داد:

نکته این است که اکثر سرویسهای فعلی که تحلیل انجام میدهند - و در واقع، افرادی که رسانههای اجتماعی را تحلیل میکنند - به طور خاص بر تحلیل علایق متمرکز هستند. اولین چیزی که به ذهن میرسد، تحلیل گروههای برتر دنبالکنندگان آنهاست. این ممکن است برای برخی جواب بدهد، اما من شخصاً فکر میکنم اساساً اشتباه است. چرا؟
لایکهای شما جمعآوری و تحلیل میشوند
همین الان گوشیهایتان را بردارید و به گروههای پرطرفدارتان نگاهی بیندازید - مطمئناً بیش از ۵۰٪ از آنها را فراموش کردهاید. این محتوا واقعاً برای شما بیربط است. شما اصلاً آن را مصرف نمیکنید، اما سیستم همچنان شما را بر اساس آن فیلتر میکند: چه در دستور پختها مشترک شوید و چه در گروههای محبوب. به عبارت دیگر، شما سیستمی را که پروفایل شما را تجزیه و تحلیل میکند، مختل خواهید کرد و علایق شما گمراه خواهند شد.
ادامه مطلب... چی اونجاست؟ ما فرض میکنیم که دیگران چه میکنند. به نظر ما، دقیقترین راه برای ارزیابی علایق کاربران، از طریق لایکها است. برای مثال، VKontakte فید لایک ندارد و مردم فکر میکنند هیچکس نمیداند آنها چه چیزی را دوست دارند. بله، برخی لایکها در اینستاگرام وجود دارد و ما برخی چیزها را در فیسبوک میبینیم، اما بیشتر محتوای گروههای خاص در فید عمومی پخش نمیشود و مردم با این فکر زندگی میکنند که هیچکس نمیداند آنها چه چیزی را دوست دارند.
و با جمعآوری محتوای خاص مورد علاقهمان، جمعآوری این پستها، جمعآوری این لایکها و سپس بررسی این شخص با این پایگاه داده، میتوانیم با دقت بالایی مشخص کنیم که آنها چه کسانی هستند، پیشینه آنها چیست و علایق آنها چیست. میتوانیم دقیقاً آنها را در یک گروه اجتماعی خاص قرار دهیم و با آنها تعامل کنیم.
خرید خودرو، رفتار را تغییر میدهد
من یک مثال دارم. فوراً روشن میکنم که مثالهای من صرفاً مربوط به تبلیغات و بازاریابی هستند، زیرا همانطور که میدانید، اکثر موارد توسط NDAها و غیره محافظت میشوند. اما هنوز اطلاعات جالب زیادی وجود دارد. بنابراین، داستان این افراد این است: اینها مردانی هستند که بین سالهای ۲۰۱۰ تا ۲۰۱۵ ماشین خریدهاند. نحوه تغییر رفتار اجتماعی آنلاین آنها با رنگ مشخص شده است. درصد مشترکین زن تغییر کرده است، آنها به گروههای عمومی "مردانه" پیوستهاند، یک شریک جنسی منظم پیدا کردهاند...
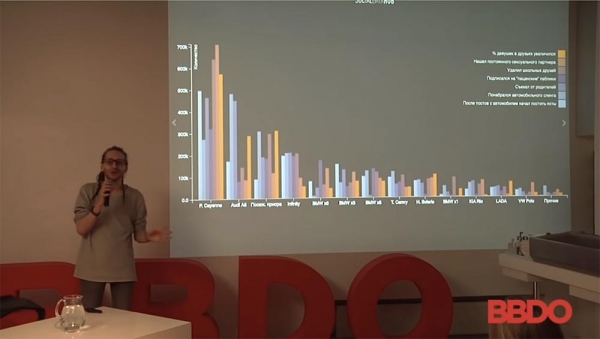
کل این ماجرا بر اساس برند خودرو و تعداد افراد تقسیمبندی شده است. از این طریق میتوانیم نتیجهگیریهای جالبی در مورد رفتار انسان و نحوهی عملکرد آن داشته باشیم. میتوانم بگویم که یک پورشه کاین و یک پرایورا کاشته شده از نظر مخاطبی که جذب میکنند عملاً یکسان هستند. کیفیت این مخاطب، رفتار آنها، متفاوت است، اما تعداد آنها تقریباً یکسان است. نتیجهای که میتوانید از این موضوع بگیرید، هر چه که به بازار شما نزدیکتر باشد، هرچه دوست دارید، خواهد بود. اگر در حال فروش آئودی هستید، شعار «یک آئودی بخرید - از والدینتان دور شوید!» را مطرح میکنید و غیره.
بله، این یک مثال خندهدار از این است که چگونه رفتار افراد، بر اساس تحلیل لایکها، گروههایی که از آنها به آنها منتقل میشوند و محتوایی که تجزیه و تحلیل میکنند، میتواند تقریباً ۱۰۰٪ به طور دقیق هویت شما را آشکار کند. زیرا اگر به ترافیک شبکه دسترسی نداشته باشید یا پیامهای خصوصی را نخوانید، لایکها همیشه به شما میگویند که آن شخص کیست - یک زن باردار، یک مادر، یک سرباز، یک افسر پلیس. و برای شما، به عنوان کسی که میتواند تبلیغات قرار دهد، این یک موفقیت بزرگ است.
پاسخ به سوالات مخاطبان:
- هر ستون نشان دهنده تعداد افرادی است که صاحب یک ماشین خاص هستند و اینکه چگونه الگوهای رفتاری آنها تغییر کرده است. نگاه کنید: افرادی که یک پورشه کاین خریدهاند - تقریباً ۵۵۰ نفر (زرد)، درصد دنبالکنندگان زن افزایش یافته است.
- نمونه شامل کاربران شبکههای اجتماعی VKontakte، فیسبوک و اینستاگرام از سال ۲۰۱۰ تا ۲۰۱۵ است. تنها توضیح: خودروهای انتخابشده را میتوان با دقت بیش از ۸۰٪ و با استفاده از ابزارهای خاص در عکسها شناسایی کرد.
- در یک بازه زمانی مشخص، ماشینش (خب، نه مال خودش، این را به شبکههای اجتماعی واگذار میکنیم)... در یک بازه زمانی مشخص، آن شخص دائماً با ماشین عکس میگرفت، با آن بود، پستها متنوع بودند، عکسها از زوایای مختلف بودند و غیره. بعداً عکسی از اینکه کدام افراد با کدام ماشینها عکس میگرفتند، وجود خواهد داشت و... بله، این سوال دوم است - قابل اعتماد بودن دادههای شبکههای اجتماعی.
- از آنجایی که بحث ما در این مورد است، متأسفانه دادههای رسانههای اجتماعی همیشه دقیق نیستند. مردم همیشه مایل به اشتراکگذاری اطلاعات خود نیستند. من شخصاً مطالعهای انجام دادم که تعداد فارغالتحصیلان دانشگاههای مسکو را با تعداد افرادی که در رسانههای اجتماعی ثبتنام کردهاند مقایسه میکرد. به طور متوسط، تعداد افرادی که در رسانههای اجتماعی ثبتنام کردهاند - فارغالتحصیلان دانشگاه ایالتی مسکو در یک سال معین و در یک تخصص معین - 60 درصد بیشتر از تعداد واقعی است. بنابراین بله، طبیعتاً مقداری خطا وجود دارد و هیچکس آن را پنهان نمیکند. دادهها در اینجا صرفاً بر اساس خودروهایی است که با بیش از 80 درصد اطمینان قابل شناسایی هستند.
فهرست منابع برای آموزش مدل
در اینجا فهرست نمونهای از منابعی که میتوانند با اطمینان بالا برای تعیین مشخصات اجتماعی یک فرد و اینکه او کیست، استفاده شوند، آورده شده است.

ما پروفایلها را از رسانههای اجتماعی، هزینه تقریبی یک آپارتمان را از CIAN و میانگین حقوق یک فرد مشخص را از HeadHunter و SuperJob دریافت میکنیم. امیدوارم هیچ نماینده HeadHunter اینجا نباشد، زیرا فکر نمیکنند گرفتن این دادهها از آنها مناسب باشد. با این حال، این میانگین حقوق برای مناطق خاص برای انواع خاصی از کار، بر اساس فرصتهای شغلی است.
آویتو، Avto.ru: اغلب اوقات، وقتی افراد شماره تلفن خود را فاش میکنند، مطمئناً (در بسیاری از موارد) آن را در جایی در آویتو، Avto.ru یا چند وبسایت دیگر که میتوانند به شناسایی آنها کمک کنند، فهرست کردهاند. اگر از آن شماره تلفن برای فروش کالسکه یا ماشین استفاده کرده باشند... Rosstat و سازمان ثبت احوال متحد دولتی اشخاص حقوقی، در نهایت، بیشتر شبیه دفاتر ثبتی هستند که میتوانند برای رتبهبندی شرکت کارفرما استفاده شوند - بر اساس فرمولی، مدلی که هر کسی میتواند تعریف کند (میتوانید تقریباً دارایی خالص آن شخص را تخمین بزنید و غیره).
تیندر به جمعآوری دادهها در مورد موقعیتهای افراد کمک میکند
بعلاوه، این نکته جالب وجود دارد (که در واقع در این مطالعه کاملاً خندهدار است) - آنها دوباره با استفاده از رباتهای تیندر، دادههایی را از تیندر مسکو جمعآوری کردند. آنها فاصله تا افراد و سپس موقعیت تقریبی آنها را تعیین کردند.
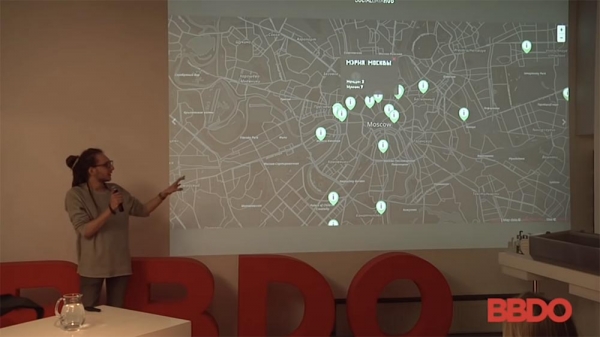
هدف این مطالعه تعیین تعداد حسابهای کاربری تیندر در سازمانهای دولتی - دوما، دفتر دادستانی و غیره - بود. اما به عنوان یک تبلیغکننده، میتوانید آن را به هر شکلی که دوست دارید تصور کنید: مثلاً میتواند استارباکس یا شخص دیگری باشد... یعنی تعداد افرادی که در تیندر با شما قهوه مینوشند، چیزی سفارش میدهند یا در فروشگاهها هستند. در مورد این موقعیت جغرافیایی: این کار را میتوان با هر سرویسی انجام داد.
پاسخ به سوال یکی از حضار:
- تیندر؟ نمیدانید؟ تیندر یک اپلیکیشن دوستیابی است که در آن روی عکسها به چپ و راست سوایپ میکنید و اپلیکیشن فاصله شما را تا آن شخص نشان میدهد. اگر فاصله تا آن شخص را از سه زاویه مختلف داشته باشید، میتوانید تقریباً موقعیت مکانی او را (+۵-۷ متر) مشخص کنید. در این مورد، پیدا کردن کسی در محل دفتر دادستانی یا دومای دولتی چندان دشوار نیست. اما از طرف دیگر، میتواند فروشگاه شما یا هر جای دیگری باشد.
برای مثال، مدتها پیش مورد مشابهی داشتیم (نه یک مطالعه) که در آن دادههای تراکم ترافیک را از یک اپراتور تلفن همراه، به همراه دادههای مربوط به تراکم حرکات سایتهای تلفن همراه دریافت کردیم و این اطلاعات بر روی مختصات بیلبوردهای واقع در بزرگراهها قرار داده شد. وظیفه اپراتور تلفن همراه تعیین تعداد تقریبی افرادی بود که از آنجا عبور میکردند و احتمالاً این بیلبوردها را میدیدند.
اگر اینجا متخصص تبلیغات بیلبوردی هستید، ممکن است بگویید: تشخیص با اطمینان بالا غیرممکن است - کسی رانندگی میکند، کسی نگاه نکرده، کسی نگاه کرده... با این وجود، این نمونهای از چگونگی ۲۰ میلیارد چندضلعی در مسکو است که تراکم این افراد را در هر ساعت در امتداد مسیرهای خاص نشان میدهد... میتوانید ببینید که این افراد در هر لحظه از چه چیزی عبور میکنند و تقریباً جریان مسافر را تخمین بزنید.
پاسخ به سوال یکی از حضار:
- هیچکس چنین دادههایی ارائه نمیدهد. ما چنین مطالعهای را برای یکی از اپراتورها انجام دادیم؛ این صرفاً یک داستان داخلی است، بنابراین متأسفانه به صورت تصویر ارائه نشده است. اما اغلب، آژانسهای تبلیغاتی بزرگ مشکلی با مراجعه به اپراتور ندارند. حداقل در مسکو، موارد زیادی وجود دارد که در آنها، برای مثال، شرکتهای بیمه به شرکتهایی مانند GetTaxi مراجعه میکنند که دادههای ناشناس در مورد سن راننده، عادات رانندگی او (خوب یا بد، بیاحتیاط یا غیر آن) را برای پیشبینی حق بیمه و غیره ارائه میدهند. همه با این موضوع مشکل دارند، اما در سطح داخلی، فکر نمیکنم کسی مشکلی با ارائه دادههای ناشناس داشته باشد.
تشخیص تصویر و الگو
بریم سراغ ادامه. مورد علاقه من تشخیص تصویر است. بخش کوتاهی در مورد تشخیص چهره وجود خواهد داشت، اما ما روی آن تمرکز نمیکنیم. ما به طور خاص روی تشخیص تصویر و شناسایی آنچه در تصویر است تمرکز میکنیم - ساخت ماشین، رنگ آن و غیره.

یه مثال بامزه دارم:

مطالعهای در مورد خالکوبیها در پلتفرمهای مختلف رسانههای اجتماعی انجام شد. بر این اساس، همین امر را میتوان در مورد هر برند، هر تصویر بصری، عملاً هر تصویر بصری اعمال کرد. برخی از آنها وجود دارند که نمیتوان با قطعیت کافی آنها را شناسایی کرد (ما به آنها نمیپردازیم).
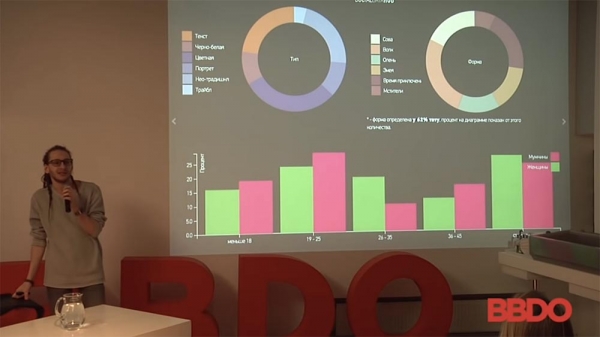
این مورد مورد علاقه من است. برندهای خودرو اغلب این نوع وظیفه را درخواست میکنند، زیرا هدف آنها، به عنوان مثال، پیدا کردن همه صاحبان یک BMW X6، فهمیدن اینکه آنها چه کسانی هستند، چه نسبتی با هم دارند، علایق آنها چیست و غیره. این مربوط به این سوال است که مردم در شبکههای اجتماعی با چه ماشینهایی عکس میگیرند.

اینجا اصلاً فیلتری وجود نداشت: موضوع مال خودشان بود، ماشین مال خودشان نبود؛ صرفاً جزئیات ماشینها بود - سن و غیره. اما تشخیص تصویر بصری اغلب استفاده میشود: این شامل جستجوی زنان باردار و جستجوی لوگوی برندها در رسانههای مختلف (چه کسی چه چیزی را پست میکند) میشود.

مثال مورد علاقه من (که رستورانهای مختلف از آن استفاده میکنند): اینکه کدام رولها را در رسانههای اجتماعی پست میکنند. خندهدار است، اما در واقع به شما این امکان را میدهد که اولاً چیزهای زیادی در مورد مشتریان خود بفهمید: چه کسی به شما مراجعه کرده و چرا این کار را انجام داده است. زیرا این یک راز نیست که در بارهای سوشی، اکثر مردم (نمیگویم "دخترها") برای ورود به سیستم، عکس گرفتن از چیزها و غیره عکس میگیرند.
یک برند میتواند از این موضوع بهره ببرد. آنها به این موضوع علاقهمند هستند که از چه محصولات خاصی باید به زیبایی عکس بگیرند و آنها را به نمایش بگذارند و چه نوع افرادی از آنها بازدید کردهاند. این کار را میتوان تقریباً با هر چیزی انجام داد، از غذا شروع میشود.
تشخیص تصویر در ویدیو
پاسخ به سوال یکی از حضار:
- نه روی ویدیو. ما آن را در حالت آزمایشی داریم. ما این فناوری را امتحان کردیم، اما معلوم شد که... همه چیز را از ویدیو به خوبی تشخیص میدهد، اما هیچ کاربردی برای آن پیدا نکردهایم. تاکنون. به غیر از تجزیه و تحلیل اینکه وبلاگنویسهای ویدیویی چقدر و کدام یک در جایی صحبت میکنند... چنین مطالعهای وجود داشت. چند نفر از چهرههای آنها ظاهر میشود، چند وقت یکبار. اما ما هنوز نفهمیدهایم که آن را کجا برای برندها پیادهسازی کنیم. شاید روزی این اتفاق بیفتد.
باز هم، این غذا است، میتواند زنان باردار، مردان (غیرباردار)، ماشینها - هر چیزی باشد.
از طرف دیگر، یک مطالعه سال نو برای یک رسانه انجام شد. این مطالعه نیز به دور از تبلیغات است، اما با این حال در مورد غذاهایی است که مردم در مورد سال نو پست میکنند:

همچنین بر اساس سن نیز تفکیک شده است. میتوانید یک همبستگی را ببینید: جوانان بیشتر غذا سفارش میدهند، در حالی که بزرگسالان بیشتر غذاهای سنتی تهیه میکنند. این یک شوخی است، اما اگر به عنوان صاحب یک برند به آن فکر کنید، میتوانید چیزهای زیادی را ارزیابی کنید: چه کسی و چگونه از محصولات شما استفاده میکند، مردم درباره آنها چه مینویسند. مردم اغلب در متن به خود برند اشاره نمیکنند و سیستمهای نظارتی تحلیلی سنتی همیشه نمیتوانند این اشاره به برند را صرفاً به این دلیل که در متن ذکر نشده است، تشخیص دهند. یا متن غلط املایی دارد، هشتگها وجود ندارند یا هر چیز دیگری.
میتوانید عکسها را ببینید. با یک عکس، میتوانید تشخیص دهید که آیا سوژه اصلی قاب است یا خیر. سپس میتوانید ببینید که شخص چه چیزی نوشته است. اما اغلب، از این برای یافتن مخاطبان بالقوهای که ماشینهای خاصی را راندهاند و غیره استفاده میشود. و سپس ما کارهای جالب زیادی با این ماشینها انجام خواهیم داد.
رباتها برای تقلید از انسانها آموزش میبینند
همچنین این گزینه برای استفاده از شمارش افراد وجود داشت:

روشی برای تطبیق افراد وجود دارد، که در آن باید افراد را بر اساس عکس پیدا کنید، پروفایل اجتماعی آنها را بفهمید و هویت آنها را شناسایی کنید. دوباره، به این نکته برمیگردیم که اگر در یک فروشگاه فیزیکی دوربین داشته باشیم، این روش بسیار خوبی برای فهمیدن این است که چه کسی به شما مراجعه میکند، آنها چه کسانی هستند، علایق آنها چیست و چه چیزی باعث شده است که به شما مراجعه کنند.
حالا به جالبترین بخش میرسیم: اگر حسابهای کاربری رسانههای اجتماعی آنها را جمعآوری کنیم، بفهمیم آنها چه کسانی هستند و علایقشان چیست، میتوانیم (به صورت اختیاری) رباتی بسازیم که شبیه این افراد باشد. این ربات شروع به زندگی مانند این افراد میکند و تبلیغاتی را که در شبکههای اجتماعی مختلف میبیند، تجزیه و تحلیل میکند. این به ما امکان میدهد تا با دقت نسبتاً خوبی بفهمیم کدام برندها این شخص را هدف قرار میدهند. این همچنین یک موقعیت نسبتاً رایج است، زمانی که لازم است نه تنها تجزیه و تحلیل کنیم که این شخص کیست و علایق او چیست، بلکه رقبای بالقوه شما یا سایر افراد علاقهمند چه تبلیغاتی را برای او هدف قرار میدهند.

تحلیل لینک شبکههای اجتماعی

نکتهی بعدی جالب است: تحلیل ارتباطات بین افراد. تحلیل واقعی ارتباطات در یک شبکه، این نمودارهای شبکه - اصلاً چیز جدیدی در مورد آن وجود ندارد، همه آن را میدانند.

اما بهکارگیری این موضوع در تبلیغات جالبترین بخش است. این کار یافتن افرادی است که روندها را تعیین میکنند، یافتن افرادی که اطلاعات را بر اساس معیارهای خاص در یک شبکه مشخص منتشر میکنند. فرض کنید ما به صاحبان یک مدل خاص BMW علاقهمند هستیم. با جمعآوری همه آنها، میتوانیم کسانی را که افکار عمومی را در دست دارند، پیدا کنیم. اینها لزوماً وبلاگنویسهای خودرو یا چیزی شبیه به آن نیستند. معمولاً اینها افراد عادی هستند که در گروههای عمومی مختلف رفت و آمد دارند، به محتوای خاصی علاقهمند هستند و میتوانند در مدت زمان بسیار کوتاهی، برند شما یا شخص مورد علاقه دیگری را به این حوزه مسئولیت، به منطقه مورد علاقه شما، بکشانند.
یک مثال. ما چند فرد بالقوه داریم، ارتباطات بین افراد. نارنجیها افراد هستند، نقطههای کوچک گروههای مشترک، دوستان مشترک هستند.

اگر همه این ارتباطات را کنار هم بگذارید، میتوانید به وضوح ببینید که افرادی هستند که تعداد زیادی گروه مشترک، دوستان مشترک دارند و بین خودشان هستند... و اگر همین تصویرسازی را بر اساس علایق، محتوایی که منتشر میکنند و میزان تعاملشان با یکدیگر به گروههایی تقسیم کنید... در اینجا میتوانید ببینید که تصویر قبلی به این شکل درآمده است:

در اینجا، گروهها به وضوح از نظر رنگ متمایز شدهاند. در این مورد، اینها دانشجویان برنامه کارشناسی ارشد ما در مدرسه عالی اقتصاد هستند. میتوانید ببینید که بنفش/آبیها کسانی هستند که از شفافیت بینالملل، روسیه باز و صفحات عمومی خودورکوفسکی حمایت میکنند. در پایین سمت چپ، سبزها، کسانی هستند که از روسیه متحد حمایت میکنند.
میبینید که تصویر قبلی به این شکل بود (به سادگی ارتباط بین افراد)، اما حالا به وضوح مشخص شده است. یعنی همه افراد همیشه با هم در ارتباط هستند، علایق مشابهی دارند، با یکدیگر دوست هستند. برخی در بالا، برخی دیگر در پایین و برخی دیگر رفقا هستند. و اگر هر یک از این زیرگرافهای کوچک را جداگانه با پارامترهای مختلف تجسم کنید و به سرعت توزیع محتوا (به طور تقریبی، چه کسی چه چیزی را بازنشر میکند) نگاه کنید، میتوانید در هر بخش یک یا دو نفر را پیدا کنید که همیشه افکار عمومی را در دست دارند. با تعامل با آنها، درخواست از آنها برای به اشتراک گذاشتن یک پست یا چیز دیگری، میتوانید از این مخاطبان جالب، پاسخی دریافت کنید.
من یک مثال دیگر مثل این دارم. همچنین یک نمودار: اینها کارمندان گروه BBDO هستند که به عنوان نمونه در رسانههای اجتماعی یافت شدهاند. به نظر جالب نمیرسد، بزرگ، سبز و ارتباطات بین آنها...

اما من نسخهای دارم که در آن گروهها از قبل بین خودشان ساخته شدهاند. اگر کسی علاقهمند باشد، یک نسخه تعاملی هم وجود دارد - میتوانید روی آن کلیک کنید و نگاهی بیندازید.
بالا سمت راست کسانی هستند که عاشق پوتین هستند. بنفشها اینجا طراحان هستند؛ کسانی که به طراحی، هر چیز جالب و غیره علاقهمندند. سفیدها اینجا تیم مدیریت هستند (فکر میکنم اینطور فهمیدم)؛ اینها افرادی هستند که به هیچ وجه با هم ارتباط ندارند، اما تقریباً در موقعیتهای یکسانی کار میکنند. بقیه گروهها، ارتباطات و غیره مشترک آنها هستند.
برندها به وبلاگنویس نیاز ندارند، آنها به رهبران فکری نیاز دارند
ما این افراد را پیدا میکنیم و سپس آژانس تبلیغاتی خودش تصمیم میگیرد: میتواند به این شخص پول بدهد تا با این محتوا یا چیز دیگری تعامل داشته باشد، یا آنها را با کمپین تبلیغاتی خاص خود هدف قرار دهد. این روش نیز اغلب استفاده میشود، به خصوص اکنون، زیرا همه برندها میخواهند با وبلاگنویسان کار کنند، میخواهند آنها محتوای آنها را تبلیغ کنند، اما آژانسهای تبلیغاتی تمایلی به تعامل ندارند (خب، این اتفاق میافتد).
راه حل واقعی این مشکل، پیدا کردن افرادی است که وبلاگ نویس یا وبلاگ نویس زیبایی نیستند، بلکه مثلاً افراد واقعی هستند که با برند تعامل دارند، کسانی که میتوانند در یک صفحه عمومی بیکیفیت به نام "Mail.ru Answers" مطلب بنویسند و تعداد مشخصی بازدید دریافت کنند. این افراد که دائماً به محتوای این شخص علاقه دارند، آن را پخش میکنند و برند تعامل بیشتری پیدا میکند.
راه دوم برای استفاده از این فناوری، که اکنون کاملاً مرتبط است، جستجوی رباتها است، که مورد علاقه من است. این میتواند برای رقبای شما ریسک اعتباری ایجاد کند، افراد نامربوط را از کمپین تبلیغاتی شما فیلتر کند و انواع کارهای دیگر (مانند حذف نظرات و یافتن ارتباط بین افراد) را انجام دهد. من یک مثال از این دارم، همچنین بزرگ و تعاملی است - میتوانید آن را جابجا کنید. این مثال ارتباط بین افرادی را که در انجمن "Lentach" نظر دادهاند، نشان میدهد.
در اینجا مثالی میزنیم تا به شما کمک کنیم درک کنید که تشخیص رباتها چقدر آسان است؛ برای انجام این کار حتی به هیچ دانش فنی نیاز ندارید. بنابراین، لنتاچ پستی در مورد تحقیقات FBK در مورد دیمیتری مدودف منتشر کرد و افراد خاصی شروع به اظهار نظر کردند. ما لیستی از تمام افرادی که اظهار نظر کردند، گردآوری کردهایم - اینها افراد تازهکار هستند. بگذارید به شما نشان دهم:

مردم همان سبزها هستند (کسانی که نظر نوشتند). آنها اینجا هستند، اینجا هستند. نقطههای آبی بین آنها گروههای مشترکشان است، نقطههای زرد مشترکین، دوستان و غیره هستند. اینها بخش عمدهای از افرادی هستند که به هم متصل هستند. زیرا، صرف نظر از نظریه سه، چهار یا پنج درجه جدایی، همه مردم در رسانههای اجتماعی به هم متصل هستند. هیچ کس از یکدیگر جدا نیست. حتی دوستان اجتماعی هراس من، که منحصراً برای تماشای ویدیو از VKontakte استفاده میکنند، هنوز در برخی از همان صفحات عمومی ما مشترک هستند.
ناوالنی همچنین از رباتها استفاده میکند. همه ربات دارند.
بخش عمدهای از مردم (اینجا هستند) با هم در ارتباط هستند. اما گروه کوچکی از رفقا وجود دارند که منحصراً با یکدیگر دوست هستند. اینها سبزها هستند و این هم دوستان و گروههای مشترکشان. آنها حتی اینجا از هم جدا شدهاند:

و از قضا، همین افراد زیر همین پست نوشتند: «ناوالنی هیچ مدرکی ندارد» و غیره، و نظرات مشابهی گذاشتند. مطمئناً من زود قضاوت نمیکنم. با این حال، من در جریان مناظره لبدف-ناوالنی پست دیگری در فیسبوک داشتم و نظرات را به همین روش تجزیه و تحلیل کردم: معلوم شد که تمام افرادی که نوشته بودند «لبدف آشغال است» در چهار ماه گذشته وارد رسانههای اجتماعی نشده بودند، در هیچ صفحه عمومی مشترک نشده بودند، ناگهان به این پست خاص برخوردند، این نظر خاص را نوشتند و سپس آنجا را ترک کردند. باز هم، نمیتوانید از این نتیجه بگیرید، اما یکی از اعضای تیم ناوالنی نظر داد که آنها از ربات استفاده نمیکنند. خب!
نزدیکتر به تبلیغات، نزدیکتر به برند. این روزها همه ربات دارند! ما آنها را داریم، رقبای ما آنها را دارند، و برخی دیگر هم همینطور. آنها باید دور انداخته شوند یا نگه داشته شوند تا بتوانند رشد کنند؛ بر اساس این دادهها (اشاره به اسلاید قبلی)، باید آنها را تا حد کمال اصلاح کنیم، تا مانند افراد واقعی به نظر برسند، و تنها در این صورت باید از آنها استفاده کنیم. اگرچه استفاده از رباتها بد است! با این وجود، این یک داستان نسبتاً رایج است...
در حالت خودکار، این ویژگی به شما امکان میدهد افراد نامربوط را از تحلیل خود فیلتر کنید، افرادی که نباید در نمونه گنجانده شوند، افرادی که نباید در این مطالعه گنجانده شوند. این ویژگی اغلب استفاده میشود. باز هم، همه صاحبان خودرو در واقع صاحب خودرو نیستند. گاهی اوقات، شما فقط به افرادی علاقهمند هستید که بالقوه صاحب خودرو هستند، اعضای گروههای خاصی هستند، با دیگران ارتباط برقرار میکنند و مخاطبان خاصی در آنجا دارند.
تحلیل واقعیتها و نظرات
مورد بعدی که مورد علاقهام هم هست، تحلیلی از حقایق و نظرات است.

این روزها همه میدانند که چگونه از برند خود در منابع مختلف نام ببرند. هیچ رازی در این کار نیست. و به نظر میرسد که همه میدانند چگونه احساسات را اندازهگیری کنند... اگرچه، شخصاً، فکر میکنم خود معیار احساسات خیلی جالب نیست، زیرا وقتی به یک مشتری میگویید: "رفیق، شما ۳۷٪ بیطرفی دارید،" و او میگوید: "وای! عالیه!" بنابراین جالبتر خواهد بود که کمی فراتر برویم: از ارزیابی احساسات به ارزیابی نظراتی که مردم در مورد محصول شما میگویند.
و این هم نکته بسیار جالبی است، چون... من شخصاً معتقدم که پیامهای خنثی در اصل غیرممکن هستند، چون اگر کسی در یک فضای عمومی چیزی بنویسد، آن پیام ناگزیر به نوعی آلوده میشود. من شخصاً هرگز پیام خنثیای ندیدهام که از یک برند خاص نام ببرد. معمولاً، نوعی تهمت است.
اگر تعداد زیادی از این پیامها را (میتواند میلیونها، حتی ۱۰ میلیون باشد) برداریم، ایده اصلی را از هر پیام استخراج کنیم و آنها را با هم ترکیب کنیم، میتوانیم به طور کاملاً قابل اعتمادی بفهمیم که مردم در مورد این برند چه میگویند، چه فکر میکنند. "من بستهبندی را دوست ندارم"، "من از قوام آن خوشم نمیآید" و غیره.
مردم در مورد ترانسآرو، آبنبات چوبی و رئیس جمهور آمریکا چه فکر میکنند؟
من یک مثال خندهدار دارم: این اینفوگرافیک درباره اینکه کاربران رسانههای اجتماعی پس از ورشکستگی شرکت ترانسآرو با آن چه خواهند کرد.

مثالهای جالب زیادی وجود دارد: سوزاندن، کشتن، تبعید به اروپا؛ حتی ۲٪ هم نوشتند: «آنها را برای جنگ به سوریه بفرستید.» از مسخرهبازی که بگذریم، این میتواند عملاً هر برندی باشد - از غذای سگ مورد علاقهام گرفته تا ماشین. کسانی که بستهبندی را دوست ندارند، کسانی که اصل آن را دوست ندارند - همیشه میتوانند با آن کنار بیایند، همیشه میتوان آنها را در نظر گرفت. نمونههای بیشماری از افرادی وجود دارد که عملاً تولید محصولات خود را تغییر دادهاند، زیرا در رسانههای اجتماعی نوشتهاند که آبنبات چوبی به اندازه کافی گرد یا شیرین نبوده است.
یه مثال خندهدار دیگه. حدس بزنید کامنتها چی هستن و در مورد کی هستن؟

به دلایلی، تحلیل نظرات، یعنی تحلیل حقایق استخراجشده از پیامها، در حال حاضر بهطور گسترده استفاده یا رایج نیست. اگرچه این فناوری فوق سری نیست، اما عملاً هیچ دانش فنی پشت آن وجود ندارد، زیرا استخراج نهاد، گزاره و گروهبندی آنها از نظرات مردم - برای انجام این کار نیازی به نبوغ در زبانشناسی محاسباتی ندارید. چندان دشوار نیست. اما امیدوارم که در چند سال آینده، مردم شروع به استفاده از آن کنند، زیرا... این نوع بازخورد خودکار فوقالعاده خواهد بود! شما همیشه میدانید که مردم در مورد شما چه میگویند. خب، میدانید، این کار در مورد رئیسجمهور ایالات متحده انجام شد.
پاسخ به سوال یکی از حضار:
- بله، این فیسبوک به زبان انگلیسی است. اینجا به روسی ترجمه شدهاند. این را جایی نوشته بودند.
کلانداده و فناوریهای سیاسی
در واقع، من مثالهای سیاسی جالب زیادی در مورد ترامپ و هر کس دیگری دارم، اما تصمیم گرفتیم آنها را اینجا نیاوریم. اما یک مثال سیاسی وجود دارد.
اینها انتخابات دومای دولتی هستند. چه زمانی برگزار شدند؟ سال گذشته؟ تقریباً یک سال و نیم پیش.
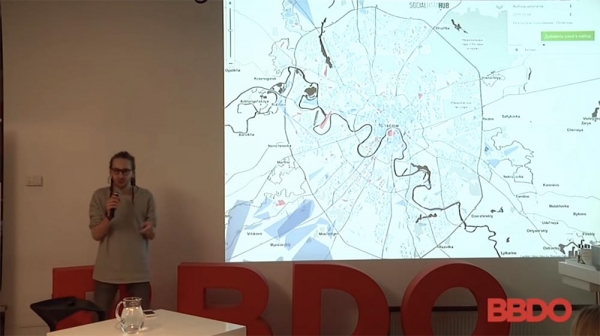
در اینجا افرادی هستند که موقعیت مکانی دقیق آنها، تا یک نقطه جغرافیایی خاص، برای تعیین محل رأیگیریشان مشخص شده است. از آنجا، فقط کسانی که نظر خاصی در مورد اینکه به چه کسی رأی میدهند ابراز کردهاند، در این فهرست گنجانده شدهاند.
از دیدگاه استراتژی سیاسی، این کاملاً درست نیست، زیرا کل ماجرا باید با توجه به تراکم جمعیت و غیره تنظیم شود. با این وجود، رأیدهندگان آبی اینجا قصد دارند به کسی که میدانید چه کسی است رأی دهند و رأیدهندگان قرمز به رفقای اپوزیسیون، که اتفاقاً تعدادشان هم زیاد نبود.
شخصاً فکر میکنم کلانداده (Big Data) تا بهکارگیری در فناوری سیاسی راه درازی در پیش دارد، اما یک نامزد انتخاباتی نیز یک برند است. و این، تا حدودی، تحلیلی از حقایق و نظرات در مورد برند آنهاست و بسیار جالب است زیرا میتوانید در لحظه بفهمید چه کسی چه کاری انجام میدهد. من چندین مورد را در بیبیسی میشناسم که در آن رسانههای اجتماعی را در حین پخش زنده رصد کردهاند: این نوع پاسخ، افرادی که در مورد آن مینویسند، این نوع سؤال را میپرسند - و این فوقالعاده است! فکر میکنم این خیلی زود مورد استفاده قرار خواهد گرفت، زیرا برای همه جالب است.
مدلسازی جایگاه برند

در ادامه، قصد دارم جایگاه برندها را مدلسازی کنم. مطلبی کوتاه و سریع در مورد چگونگی رتبهبندی برندها با استفاده از معیارهای مختلف (نه فقط لایکهای رسانههای اجتماعی، بلکه معیارهای پیچیده، علاقه به محتوا و زمان صرف شده برای جمعآوری معیارها).

من یک مثال برای یک برند خاص دارم، «داروسازی». دایرههای کوچک و با رنگهای روشن داخل، نشاندهندهی میزان محتوای متنی هستند که خود برند ایجاد میکند و دایرهی بزرگ نشاندهندهی میزان محتوای عکس و ویدیویی است که خود برند ایجاد میکند.
نزدیکی به مرکز نشان میدهد که این محتوا چقدر برای مخاطب جالب است. این یک مدل بزرگ است، با مجموعهای از معیارهای مختلف: لایکها، بازنشر، زمان پاسخ، میانگین اشتراکگذاری... در اینجا نگاهی میاندازیم: کاگوسل فوقالعادهای وجود دارد که مبلغ هنگفتی را برای تولید محتوای خود سرمایهگذاری میکند و به همین دلیل، آنها نسبتاً به مرکز نزدیک هستند. سپس دیگرانی هستند که محتوای خود را تولید میکنند، اما مخاطب علاقهای به آنها ندارد. این مثال خیلی دقیقی نیست، زیرا همه این حسابها عملاً از بین رفتهاند.
یگور کرید بیشتر از باستا دوست دارد

متاسفانه، بقیه... از آنچه که میتوان نشان داد... در اینجا، به عنوان یک گزینه، رپرهای روسی از شرکتهای واقعی نیز وجود دارند.
مزیتش چیست؟ مزیتش این است که یک شرکت میتواند عملاً هر چیزی را در این مدل لحاظ کند، از میانگین حقوق مشترکین برند شما شروع میشود؛ هر مدلی که دوست داشته باشد. چون هر آژانس تبلیغاتی معیارهای خودش را به طور متفاوتی محاسبه میکند و برندها هم معیارهای خودشان را به طور متفاوتی محاسبه میکنند.
همچنین کسی مثل باستا وجود دارد که محتوای زیادی تولید میکند، اما در حاشیه است زیرا ظاهراً برای مخاطب خیلی جالب نیست. باز هم، من کسی نیستم که قضاوت کنم. اما یگور کرید هم هست که طبق گفته رسانههای اجتماعی، عملاً یکی از بهترین مجریان زمان ماست، اما با این حال فقط عکسهای شخصی خودش را منتشر میکند. با این حال، او دنبالکنندگان زیادی دارد: چیزی حدود یک میلیون نفر. عدد دقیق را به خاطر نمیآورم؛ به یاد دارم که نرخ تعامل او بسیار بالاتر از ۸۵٪ است، به این معنی که به ازای هر یک میلیون دنبالکنندهای که دارد، ۸۵۰،۰۰۰ پاسخ از افراد واقعی دریافت میکند - واقعاً دیوانهکننده است. این درست است.

پاسخ به سوالات مخاطبان:
چه مدت طول کشید تا مدل تحلیل رپر توسعه داده شود؟
- هر کدام مخاطب هدف خاص خود، علایق خاص خود و محاسبات مربوط به هر کدام را دارند... همه اینها بر اساس فاصله تقریبی تا مرکز استاندارد شده است؛ موقعیت شعاعی آنها مهم نیست (فقط برای اهداف زیبایی شناسی در اینجا پخش شده است، بنابراین همپوشانی ندارند). فقط نزدیکی تقریبی آنها به مرکز مهم است. این مدلی است که ما استفاده می کنیم. به عنوان مثال، من یک دایره را ترجیح می دهم؛ برخی افراد از نیم دایره استفاده می کنند.
- این مدل به سرعت، در عرض دو یا سه ساعت (بله، توسط یک نفر) تهیه شد. همه چیز در مورد معیارها بود: چه چیزی را در چه چیزی ضرب میکنیم، آن را جمع میکنیم و سپس به نوعی آن را استاندارد میکنیم. بستگی به مدل دارد. برخی افراد به میانگین حقوق (بدون شوخی) فالوورهای خود علاقهمند هستند. و برای انجام این کار، باید مخاطبین آنها، آویتو، را پیدا کنید، همه را محاسبه کنید، در هم ضرب کنید. گاهی اوقات محاسبه آن زمان زیادی میبرد، اما این مورد خاص (به اسلاید قبلی اشاره میکند) پارامترهای بسیار سادهای دارد: فالوورها، بازنشر پستها و غیره. تهیه آن حدود دو یا سه ساعت طول کشید. بنابراین، این چیز به صورت بلادرنگ بهروزرسانی میشود و آماده استفاده است.
حالا به جالبترین بخش میرسیم. مثالهایم تمام شده، چون صحبت کردن طولانی مدت به تنهایی جالب نیست. و امیدوارم حالا سوالاتتان را بپرسید و از موضوعی به موضوع دیگر برویم، چون مثالهایی از نحوهی استفاده از فناوریها و غیره دارم...
پاسخ به سوالات مخاطبان:
- من یک مورد شخصی با مکانی به اصطلاح "کازینو مانند" داشتم که در آن دوربین نصب کرده بودند، تشخیص چهره انجام میدادند و غیره. درصد افرادی که شناسایی میشدند قطعاً بسیار بالا بود - هم مال ما و هم مال رقبای ما. اما در واقع بسیار جالب است. من آن را به عنوان یک چیز جالب میبینم: میتوانید بفهمید که این افراد چه کسانی هستند و به خوبی پیشبینی کنید که چرا به آنجا آمدهاند، چه چیزی در زندگی آنها تغییر کرده که باعث شده تصمیم بگیرند به کازینو بیایند. اما در مورد انواع خاص مشاغل... اگر قرار بود چنین چیزی را در یک داروخانه نصب کنید، فایدهای نداشت - نمیتوانید پیشبینی کنید که چرا کسی در وهله اول به داروخانه میآید.
چالش بزرگ اینجا ساخت مدلی بود تا بفهمیم چه زمانی ممکن است کسی به برند شما علاقهمند شود، تا بتوانید آنها را نه پس از خرید چیزی (همانطور که در حال حاضر رایج است) با تبلیغات هدف قرار دهید، بلکه "پیشبینی" کنید که چه زمانی ممکن است واقعاً این اتفاق بیفتد. با این چیدمان "شبیه کازینو" جالب بود؛ درصد نسبتاً جالبی از این افراد وجود داشت - چرا: برخی ناگهان تبلیغ دریافت کردند، برخی دیگر چیز دیگری - اینها بینشهای جالبی هستند. اما با فروشگاههای خاص، با خردهفروشی، با یک فروشگاه قرص، فکر میکنم کاملاً درست نباشد.
آیا کلان داده به صورت آفلاین هم استفاده میشود؟
- آفلاین بود. فقط باید دقیقاً، تقریباً، بفهمید که آیا این مدل کار خواهد کرد یا نه. باز هم، با آب گازدار... من واقعاً به همه چیز علاقهمند هستم، اما شخصاً نمیفهمم که تا چه حد، چگونه پروفایل و رفتار این افراد ممکن است به زمانی که میخواهند آب معدنی بخرند بستگی داشته باشد. اگرچه این ممکن است درست باشد، من نمیدانم.
چند حساب کاربری فعال در شبکههای اجتماعی دارید؟
- ما ۱۱ شبکه اجتماعی خاص داریم: VKontakte، فیسبوک، توییتر، Odnoklassniki، اینستاگرام و چند شبکه اجتماعی کوچک دیگر (میتوانم به فهرستی مثل Mail.ru و غیره نگاه کنم). ما قطعاً یک کپی از همه این افراد در VKontakte داریم. ما در VKontakte افرادی داریم - ۴۳۰ میلیون نفر از هر کسی که تا به حال وجود داشته است (که حدود ۲۰۰ میلیون نفر از آنها دائماً فعال هستند)؛ گروهها وجود دارند، بین این افراد ارتباط وجود دارد، و محتوایی وجود دارد که ما به آن علاقه داریم (متن)، و برخی رسانهها، اما بخش بسیار کوچکی... به طور کلی، ما به این تصویر نگاه میکنیم: اگر چهرهای وجود داشته باشد، آن را ذخیره میکنیم؛ اگر میمهایی وجود داشته باشد، آن را ذخیره نمیکنیم، زیرا حتی ما منابع کافی برای ذخیره محتوای رسانهای نداریم.
یک فیسبوک به زبان روسی وجود دارد. در حال حاضر، چیزی بین ۶۰ تا ۸۰ درصد کاربران Odnoklassniki هستند؛ احتمالاً تا چند ماه دیگر به همه آنها خواهیم رسید. یک اینستاگرام روسی هم وجود دارد. همه این شبکههای اجتماعی گروهها، افراد، ارتباطات بین آنها و متن دارند.
- حدود ۴۰۰ میلیون نفر. یک نکته ظریف وجود دارد: افرادی هستند که شهرشان در فهرست نیست (آنها بالقوه روسی/غیرروسی هستند)؛ از این تعداد، به طور متوسط در شبکههای اجتماعی - مثلاً در VKontakte، ۱۴٪ حسابهای خصوصی هستند؛ من رقم دقیق فیسبوک را نمیدانم.
- ما در اینستاگرام هم رسانه ذخیره نمیکنیم—فقط اگر حاوی چهره باشد. ما آن محتوای رسانهای (دیگر) را ذخیره نمیکنیم. معمولاً، ما فقط به متن، ارتباطات بین افراد علاقهمندیم—همین. رایجترین تحقیق اینستاگرام، تحقیق استاندارد مخاطبان است: این افراد چه کسانی هستند و از همه مهمتر، ارتباطات آنها با سایر شبکههای اجتماعی. پیدا کردن پروفایل این شخص در VKontakte و فیسبوک در محاسبه سن او و غیره مفید است.
- هنوز نیازی به استخدام افراد دیگر نیست—فقط به این دلیل که هیچ مشتری وجود ندارد. در مورد زبان: ما روسی، انگلیسی و اسپانیایی داریم، اما آنها هنوز منحصراً برای برندهای روسی یا حداقل برای شرکتهایی که آنها را از روسیه اداره میکنند، استفاده میشوند.
- ما روزانه در موضوعات بیشماری از مردم نظرسنجی میکنیم: ما با جستجو در وب، دادهها را جمعآوری میکنیم و این معیارها را با استفاده از APIها بهروزرسانی میکنیم. در عرض دو یا سه روز، میتوانید کل شبکه VKontakte را بررسی کنید؛ در حدود یک هفته، میتوانید کل شبکه فیسبوک را بررسی کنید و بفهمید چه کسی چه چیزی را بهروزرسانی کرده و چه کسی بهروزرسانی نکرده است. و سپس ما این افراد را بهصورت جداگانه جمعآوری میکنیم: دقیقاً چه چیزی تغییر کرده است و کل تاریخچه را ثبت میکنیم. تا جایی که من به خاطر دارم، بسیار نادر است که از پروفایل قدیمی یک فرد در رسانههای اجتماعی برای هر هدف تجاری واقعی استفاده شده باشد. این اتفاق یک بار افتاد، زمانی که یک شخصیت سیاسی به ما مراجعه کرد و وظیفه او این بود که بفهمد چه نوع افرادی به ستاد انتخاباتی میآیند و ۶-۸ ماه پیش چه کسانی بودهاند (آیا پروفایلهای خود را حذف کردهاند و واقعاً به نامزد دیگری رأی دادهاند یا اینکه برای خراب کردن رأیگیری آمدهاند).
و چند بار - داستانهای شخصی، وقتی عکسهای کسی به صورت عمومی منتشر میشد. لازم بود ارتباطاتی پیدا شود و غیره. متأسفانه، شرمآور است، اما ما نمیتوانیم در دادگاه شهادت دهیم زیرا پایگاه داده ما از نظر قانونی غیرقانونی است.
- فضای ذخیرهسازی MongoDB مورد علاقهی من است.
شبکههای اجتماعی در تلاشند تا با جمعآوری دادهها مبارزه کنند.
- ما معمولاً فقط لیستی از این حسابها را در اختیار تبلیغکنندگان قرار میدهیم و سپس آنها از استاندارد... استفاده میکنند، یعنی در شبکههای اجتماعی، مانند VKontakte، میتوانید لیستی از این افراد را مشخص کنید.
اما فیسبوک از کوکیهای خریداریشده استفاده میکند. ما خودمان با کوکیها کار نمیکنیم، اما چند مورد وجود داشته که تبلیغکنندگان افراد خاصی را در اختیار ما قرار دادهاند و ما با آنها تعامل داشتهایم - آنها این شبکهها را دارند، با تبلیغات تیزر و غیر تیزر، این کوکیها. لینک دادن امکانپذیر است - مشکلی نیست! اما من طرفدار زیادی از این چیزها نیستم زیرا فکر میکنم خیلی قابل اعتماد نیستند. به نظر من، مثل ردیابی تلویزیونها توسط TNS است - مشخص نیست که آیا شما در حال تماشای تلویزیون هستید، آن را تماشا نمیکنید، یا اینکه در حالی که تلویزیون روشن است، ظرفها را میشویید... و اینجا هم همین است: من اغلب چیزی را در گوگل جستجو میکنم، اما این بدان معنا نیست که میخواهم آن را بخرم.
- اگر از یک شبکه تبلیغات متنی استاندارد استفاده میکنید، من چندین داستان داشتهام که در آنها این افراد را از سیستم خارج کردهایم و سعی کردهایم با استفاده از رابطهای کاربریشان، آنها را به کوکیهای سایتهایشان متصل کنیم. اما من طرفدار پر و پا قرص این نوع کارها نیستم.
فرمول محاسبه حقوق کاربران اینترنت
- فرمول کلی برای میانگین حقوق عبارت است از: منطقهای که فرد در آن زندگی میکند، دسته بندی کسب و کاری که در آن کار میکند (یعنی شرکتی که کارفرمای اوست)، سپس سمت او در این شرکت در نظر گرفته میشود، میانگین حقوق برای این سمت تخمین زده میشود... میانگین حقوق از Head Hunter و Superjob (و چندین منبع دیگر) برای یک موقعیت شغلی خالی مشخص در یک منطقه مشخص و برای یک زمینه کاری مشخص گرفته میشود.
Avito و Avto.ru معمولاً در صورتی که شخصی شماره تلفن خود را فاش کرده باشد، اطلاعات بیشتری ارائه میدهند. Avito به شما امکان میدهد ببینید که یک شخص چه نوع کالاهایی را میفروشد - گران، ارزان، دست دوم یا غیر گران. Avto.ru به شما امکان میدهد ببینید که آیا شخصی صاحب ماشین است یا خیر - چه صاحب ماشین باشد یا نباشد. این تعداد کمتر از 20٪ از افرادی را نشان میدهد که به طور تصادفی تلفن خود را در جایی رها کردهاند و حساب آنها را میتوان به این اطلاعات مرتبط کرد.
شرکت جمعآوری دادهها چه حجمهایی را مدیریت میکند؟
- حجم عکسهای ذخیره شده بر حسب پتابایت ۶.۴ است. نمیتوانم دقیقاً بگویم که در حال حاضر با چه سرعتی در حال رشد است، زیرا در سال ۲۰۱۶ ما ضبط «پریسکوپ» را شروع کردیم و تازه شروع به ضبط ویدیو کردهایم.
نمیتوانم دقیقاً بگویم چه زمانی صفر بود. ما از شرکتی به شرکت دیگر نقل مکان کردیم - داستانش مفصل است. اما میتوانم بگویم که VK، فیسبوک، اینستاگرام و توییتر - همه آن چیزها (افراد، گروهها و ارتباطات بین آنها) با متن و محتوا - واقعاً به آن اندازه داده نمیرسند، حتی به زحمت یک پتابایت. فکر میکنم حدود ۷۰۰، شاید ۸۰۰ گیگابایت باشد.
آیا به مشتریان کمک میکنید تا یک حوزه مرتبط را شناسایی کنند و در کجا به دنبال آن بگردند؟
- وقتی مشتری میآید، ما چنین چیزهایی را به او پیشنهاد میدهیم، اما خودمان، مثل گوگل ترندز، چنین کارهایی انجام نمیدهیم.
- ما چندین داستان مرتبط با جامعهشناسی، از جمله داستانهای انتخاباتی و پیش از انتخابات، داشتهایم - همه آنها را تحلیل کردهایم. در مورد برندها و ارزیابیهای نظرات مربوط به برند، تقریباً همیشه همه چیز با هم مطابقت دارد. اما داستانهای انتخاباتی و پیش از انتخابات - آنها (با ارزیابیهایشان از اینکه کدام نامزد باید برنده شود) اینطور نیستند. من نمیدانم چه کسی اینجا اشتباه میکند - ما یا افرادی که در VTsIOM تحقیق میکنند.
- ما معمولاً این نتایج معیار را از خود برند دریافت میکنیم و آنها نیز آنها را از افرادی که سفارش تحقیق میدهند دریافت میکنند - نظرسنجیهای تلفنی، تحقیقات بازاریابی و غیره. به علاوه، همه اینها را میتوان با موارد اساسی تأیید کرد: اینکه آیا کسی به یک خبرنامه پاسخ داده است یا اینکه آیا کسی یک نظرسنجی را تکمیل کرده است... اگر یک برند بزرگ باشد (مثلاً کوکاکولا)، مطمئناً یک یا دو میلیون نظر مشتری داخلی خود را دارند - نه فقط نظرات در رسانههای اجتماعی و نظرات؛ آنها سیستمهای داخلی، بازخورد و غیره دارند.
قانون «نمیداند» دادههای شخصی چیست!
- ما منحصراً منابع داده باز را تجزیه و تحلیل میکنیم و هرگز به اطلاعات کثیف و آلوده نمیپردازیم. مدل ما بر این اساس است که تمام دادههای باز را در مراکز داده عمومی ذخیره میکنیم، یا آنها را در جای دیگری اجاره میکنیم و آنها را در داخل، روی سرورهای خودمان، در دفاترمان تجزیه و تحلیل میکنیم و هرگز محل کار خود را ترک نمیکنیم.
اما قانون ما در حوزه دادههای باز بسیار مبهم است.
ما درک روشنی از اینکه دادههای باز چیست، دادههای شخصی چیست نداریم - قانون فدرال ۱۵۲ وجود دارد، اما هنوز... آنها چگونه آن را محاسبه میکنند؟ بنابراین، اگر نام و شماره تلفن شما را در یک پایگاه داده، شماره تلفن و ایمیل شما را در پایگاه داده دیگری و آدرس ایمیل و ماشین شما را در پایگاه داده سوم داشته باشم - همه اینها به عنوان دادههای غیرشخصی به نظر میرسند. اگر همه اینها را با هم ترکیب کنید، به نظر میرسد که طبق قانون، به دادههای شخصی تبدیل میشوند.
ما به دو روش این مشکل را حل میکنیم. اول، سرورها را با نرمافزار مشتری نصب میکنیم، بنابراین این دادهها از قلمرو آنها خارج نمیشوند و سپس مشتری مسئول انتشار این دادههای شخصی، دادههای غیرشخصی و غیره است. یا دوم، اگر در موقعیتی قرار بگیریم که مجبور شویم از شبکه اجتماعی شکایت کنیم یا چیزی شبیه به آن...
ما (در طول انتخابات مقدماتی حزب روسیه متحد) مطالعهای شبیه به این انجام دادیم که در آن حسابهای کاربری این افراد را برای LifeNews جمعآوری کردیم و به فیلمهای مستهجنی که دوست داشتند نگاهی انداختیم. چیز خندهداری بود، اما با این حال. ما آن را به عنوان نظر شخصی خودمان میفروشیم، بدون اینکه به طور قانونی در اسناد، آنچه را که تجزیه و تحلیل کردهایم - ثبت یکپارچه نهادهای قانونی، حقوق و دستمزد، رسانههای اجتماعی - را فاش کنیم. ما نظر کارشناسی خود را میفروشیم و سپس، در پشت صحنه، برای فرد توضیح میدهیم که چه چیزی را تجزیه و تحلیل کردهایم و چگونه.
چند داستان وجود داشت، اما مربوط به پروژههای تجاری عمومی بودند. به عنوان مثال، ما یک پروژه رایگان و غیرانتفاعی برای لانگبوردرها (لانگبوردهایی مانند این) داریم: هدف جمعآوری پستهای مردم بود - وقتی کسی پست میگذاشت، "من برای اسکیت به پارک گورکی رفتم." بنابراین، روی نقشه ظاهر میشد و اطرافیانشان میتوانستند ببینند که کسی در همان نزدیکی است. VK مدت زیادی در این مورد با ما مبارزه کرد زیرا دوست نداشت ما این اطلاعات را بدون اجازه مردم منتشر کنیم. اما پرونده به دادگاه نرفت زیرا ما بندی را به قوانین چندین جامعه بزرگ اضافه کردیم که اجازه میداد دادهها توسط اشخاص ثالث، آژانسها، شرکتها، برای تجزیه و تحلیل و غیره استفاده شود. البته، این کار به طور خاص اخلاقی نبود، اما با این وجود. - ما درست به موقع از خواب بیدار شدیم و شروع کردیم به فروختن نظر کارشناسیمان به همه.
آیا با موسسات آموزشی همکاری دارید؟
- بله، ما با مؤسسات آموزشی همکاری میکنیم. ما طیف وسیعی از آنها را داریم: ما یک برنامه کارشناسی ارشد در دانشکده تحصیلات تکمیلی داریم و با دانشگاههای دیگر همکاری میکنیم. ما واقعاً عاشق دانشگاهها هستیم!
- اطلاعات تماسم را دارم - میتوانید برای من بنویسید. و این هم لینک ارائه، اگر کسی علاقهمند باشد - همه این مثالها را دارد، میتوانید آنها را به اشتراک بگذارید.
- اگر شماره تلفن و آدرس ایمیل مشخص باشد، تقریباً قطعی است؛ هیچکس آنها را حذف نخواهد کرد. اگر شماره تلفن نباشد، معمولاً یک عکس است؛ اگر عکس نباشد، سال، محل سکونت و شغل است. یعنی تقریباً همه را میتوان همیشه با دقت کامل بر اساس سال، محل سکونت و شغل شناسایی کرد. اما این، باز هم، به وظیفه بستگی دارد.
فرض کنید ما یک مشتری داریم که تلویزیون اینترنتی میفروشد. شخصی اشتراک سریال «بازی تاج و تخت» را خریداری کرده است و وظیفه ما این است که با استفاده از CRM آنها، این افراد را در رسانههای اجتماعی پیدا کنیم و سپس سرنخهای بالقوه را در حوزه نفوذ آنها پیدا کنیم. من فقط میگویم که آنها مثلاً نام، نام خانوادگی و آدرس ایمیل دارند... و بنابراین انجام هر کار دیگری بسیار دشوار است. در بیشتر موارد، میتوانید افراد را از طریق آدرس ایمیل پیدا کنید.
- ما معمولاً افراد را بر اساس دوستانشان در رسانههای اجتماعی «تطبیق» میدهیم، اما این همیشه درست نیست. فقط این نیست که همیشه درست نیست - همیشه هم جواب نمیدهد. اولاً، این کار پرزحمت است، زیرا این فرآیند تطبیق باید ابتدا برای هر دوست انجام شود - تا مشخص شود که آیا آنها از رسانههای اجتماعی مهاجرت کردهاند یا خیر. و سپس این واقعیت شناخته شده وجود دارد که ما تعدادی دوست در VKontakte و دوستان دیگری در فیسبوک داریم. برای همه اینطور نیست، اما مثلاً برای من صادق است؛ و برای اکثر مردم نیز صادق است.
چگونه کاملترین دادهها را جمعآوری میکنید؟
- با نصب نرمافزار در سمت کلاینت. یک سرور در سمت آنها نصب میشود که فقط دادههای عمومی را از ما جمعآوری میکند، اما دادههای شخصی آنها را به صورت داخلی پردازش میکند. یک NDA با کلاینت امضا میشود. مطمئناً کاملاً منصفانه نیست که آنها این اطلاعات را با ما به اشتراک بگذارند، اما مسئولیت قانونی بر عهده کلاینت است - چه با نصب نرمافزار و چه با انتقال دادههای ناشناس. اما این بسیار نادر بود، زیرا - چه ناشناسسازی درست باشد و چه نادرست - در بیشتر موارد، ارتباط بین این افراد از بین میرود.
چه کسانی نرمافزار تشخیص چهره میخرند؟
- ما در واقع به اینجا میآییم چون نرمافزار اصلی ما که میفروشیم، جستجوی چهره و تحلیل روابط است و آن را به سازمانهای دولتی میفروشیم. بنابراین، یک سال و نیم پیش، تصمیم گرفتیم همه این داستانها را وارد تبلیغات، بازاریابی و بازار عمومی کنیم - اینگونه بود که Social Data Hub، یک نهاد حقوقی تجاری، تشکیل شد. و بنابراین ما تازه الان به اینجا میآییم. ما یک سال و نیم است که اینجا پرسه میزنیم و سعی میکنیم به مردم توضیح دهیم که نباید به آنها اجازه دانلود با ذکر نام داده شود، باید به سوالاتشان پاسخ داده شود، نیازی به لحن صدا نیست و غیره. بنابراین، گفتن اینکه کجا... سخت است.
- (منظورت کیست؟) به همه رفقایی که باید دنبال تروریستها، پدوفیلها بگردند.
میتوانم فوراً بگویم (این سوال بعدی خواهد بود): طبق اطلاعات ما، هیچ معلمی به دلیل بازنشر این مطلب زندانی نشده است. - در VKontakte، این عدد ۱۴٪ است؛ در فیسبوک، چیزی به نام پروفایل بسته وجود ندارد (ممکن است لیست دوستان بسته داشته باشند و غیره). و جالبترین چیز این است که من همین الان یک پیام نوشتم - آنها آن را میشمارند و به شما میگویند.
چیزی منتشر نکن که ازش خجالت بکشی!
- چیزی در رسانههای اجتماعی منتشر نکنید که از آن خجالت بکشید—این دستورالعمل شخصی من است. اگرچه من موارد شخصی زیادی داشتهام، چون قسم میخورم در فیسبوک این کار را میکنم. خب، این چیزی است که بوده، چه کاری از دستتان برمیآید؟ چیزی منتشر نکنید که از آن خجالت بکشید! اگر قصد دارید بعداً برای اتاق بازرگانی عمومی کار کنید، بله، بهتر است نظر ندهید. اگر قصد ندارید این کار را انجام دهید، پس، روی هم رفته، هیچکس اهمیتی نمیدهد. من فقط میتوانم به شما اطمینان دهم که هیچکس مکاتبات شخصی شما را نمیخواند، و تمام این تشدید اوضاع، فقط کل این ماجرا را تشدید میکند...
هر هفته، یکی ناگزیر پیش من میآید و میگوید: «ببینید، عکسهای دوستم در یک گروه عمومی ناشناس منتشر شده! کمک!» ضمناً، هرگز چیزی را در گروههای عمومی ناشناس پست نکنید.
- من در مورد سایر سیستمهای نظارتی اطلاعی ندارم - ما قطعاً این را در نظر خواهیم گرفت که ذکر نام تجاری منفی بوده است، خدا مرا ببخشد... اما میتوانم بگویم که همه این افراد وابسته به دولت فقط به افرادی با مخاطب بالای ۵۰۰۰ نفر علاقهمند هستند و افکار عمومی آنها میتواند روی کسی تأثیر بگذارد. طبق تجربه من، هرگز یک آژانس منابع انسانی که ما را برای ارزیابی پروفایلها مأمور میکند، نگفته است: "اگر کسی ناوالنی را دوست دارد، من را استخدام نکند!"
درباره انتشار نتایج. چند نفر در این تحقیق مشارکت دارند؟
- از بین ۱۰ شرکت تبلیغاتی برتر، هفت شرکت در حال حاضر در حال انتشار هستند. گفتنش سخت است: وقتی این کار را یک سال و نیم پیش شروع کردیم... ما در هر زمینه چندین نفر داریم - چند نفر در بانکها، چند نفر در منابع انسانی، چند نفر در تبلیغات. و حالا داریم فکر میکنیم که اول به سراغ چه کسی برویم که بیشترین سود را دارد، برای چه کسی باید شروع به توسعه رابط کاربری کنیم...
- (تقریباً به تعداد افراد در هر بخش بازار) بیش از ۲۵ نفر نه، چون ما به کسی تجاوز نکردیم.
- به طور کلی، فکر میکنم بیش از ۵۰٪ بازار از این فناوریها استفاده میکند. برخی در کمپینهای تبلیغاتی و برخی دیگر برای تجزیه و تحلیل داخلی استفاده میشوند. به نظر من ۴۰٪ از آنها برای تجزیه و تحلیل داخلی استفاده میکنند، در حالی که ۵۰ تا ۶۰٪ آنها را به برندهای نهایی میفروشند. اما همه چیز به خود شرکتهای تبلیغاتی بستگی دارد. میبینید، برخی به سادگی در مورد پول خرج شده و تبلیغات جعلی گزارش میدهند، در حالی که برخی دیگر در واقع گزارش میدهند که چند نفر را جذب کردهاند، به چه مخاطبی رسیدهاند... به نظر من این درست است، اما ممکن است اشتباه کنم - من واقعاً نمیفهمم که همه اینها چگونه کار میکنند. من فقط دادههای کمی را میدانم.

چند تبلیغ 🙂
از اینکه با ما ماندید متشکرم آیا مقالات ما را دوست دارید؟ آیا می خواهید مطالب جالب تری ببینید؟ با ثبت سفارش یا معرفی به دوستان از ما حمایت کنید , یک آنالوگ منحصر به فرد از سرورهای سطح ورودی که توسط ما برای شما اختراع شده است: (در دسترس با RAID1 و RAID10، حداکثر 24 هسته و حداکثر 40 گیگابایت DDR4).
Dell R730xd 2 برابر ارزان تر در مرکز داده Equinix Tier IV در آمستردام؟ فقط اینجا در هلند! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - از 99 دلار! در مورد بخوانید
منبع: www.habr.com
