


سلام به همه! من دیمیتری سامسونوف هستم و به عنوان مدیر ارشد سیستم در Odnoklassniki کار میکنم. ما بیش از ۷۰۰۰ سرور فیزیکی، ۱۱۰۰۰ کانتینر در فضای ابری خود و ۲۰۰ برنامه کاربردی داریم که در پیکربندیهای مختلف، ۷۰۰ کلاستر مختلف را تشکیل میدهند. اکثریت قریب به اتفاق سرورها در حال اجرا هستند. CentOS 7.
در 14 آگوست 2018، اطلاعاتی درباره آسیبپذیری FragmentSmack منتشر شد
() و SegmentSmack (). اینها آسیبپذیریهایی با بردار حمله شبکه و امتیاز نسبتاً بالا (7.5) هستند که انکار سرویس (DoS) به دلیل فرسودگی منابع (CPU) را تهدید میکند. در آن زمان یک اصلاح هسته برای FragmentSmack پیشنهاد نشده بود، علاوه بر این، بسیار دیرتر از انتشار اطلاعات مربوط به آسیب پذیری ظاهر شد. برای حذف SegmentSmack، به روز رسانی هسته پیشنهاد شد. خود بسته به روز رسانی در همان روز منتشر شد، فقط نصب آن باقی مانده بود.
نه ما اصلا مخالف آپدیت کرنل نیستیم! با این حال، تفاوت های ظریف وجود دارد ...
چگونه هسته را در زمان تولید به روز می کنیم
به طور کلی، هیچ چیز پیچیده ای نیست:
- دانلود بسته ها؛
- آنها را روی تعدادی از سرورها (از جمله سرورهایی که میزبان ابر ما هستند) نصب کنید.
- مطمئن شوید که هیچ چیز خراب نیست.
- اطمینان حاصل کنید که تمام تنظیمات هسته استاندارد بدون خطا اعمال می شوند.
- چند روز صبر کنید؛
- بررسی عملکرد سرور؛
- استقرار سرورهای جدید را به هسته جدید تغییر دهید.
- به روز رسانی تمام سرورها توسط مرکز داده (یک مرکز داده در یک زمان برای به حداقل رساندن تأثیر بر روی کاربران در صورت بروز مشکل).
- همه سرورها را راه اندازی مجدد کنید.
این کار را برای تمام شاخه های هسته هایی که داریم تکرار کنید. در حال حاضر این است:
- سهام CentOS ۷ ۳.۱۰ - برای اکثر سرورهای معمولی؛
- وانیل 4.19 - برای ما ، زیرا ما به BFQ، BBR و غیره نیاز داریم.
- Elrepo kernel-ml 5.2 - برای ، زیرا قبلاً 4.19 ناپایدار بود، اما همان ویژگی ها مورد نیاز است.
همانطور که ممکن است حدس بزنید، راه اندازی مجدد هزاران سرور طولانی ترین زمان را می گیرد. از آنجایی که همه آسیبپذیریها برای همه سرورها حیاتی نیستند، ما فقط آنهایی را راهاندازی میکنیم که مستقیماً از طریق اینترنت در دسترس هستند. در فضای ابری، برای اینکه انعطافپذیری را محدود نکنیم، کانتینرهای قابل دسترسی خارجی را با یک هسته جدید به سرورهای جداگانه گره نمیزنیم، بلکه همه میزبانها را بدون استثنا راهاندازی مجدد میکنیم. خوشبختانه، روش در آنجا ساده تر از سرورهای معمولی است. به عنوان مثال، کانتینرهای بدون حالت می توانند به سادگی در حین راه اندازی مجدد به سرور دیگری منتقل شوند.
با این حال، هنوز کار زیادی وجود دارد و ممکن است چندین هفته طول بکشد و در صورت بروز هر گونه مشکل در نسخه جدید، تا چندین ماه طول می کشد. مهاجمان این را به خوبی درک می کنند، بنابراین به یک طرح B نیاز دارند.
FragmentSmack/SegmentSmack. راه حل
خوشبختانه، برای برخی از آسیبپذیریها، چنین طرح B وجود دارد و به آن راه حل میگویند. بیشتر اوقات، این تغییر در تنظیمات هسته/برنامه است که می تواند تأثیر احتمالی را به حداقل برساند یا به طور کامل سوء استفاده از آسیب پذیری ها را حذف کند.
در مورد FragmentSmack/SegmentSmack این راه حل:
«میتوانید مقادیر پیشفرض 4 مگابایت و 3 مگابایت را در net.ipv4.ipfrag_high_thresh و net.ipv4.ipfrag_low_thresh (و مشابههای آنها برای ipv6 net.ipv6.ipfrag_high_thresh و net.ipv6.ipfrag_low_256 kB192) و به ترتیب به 262144 یا B64 تغییر دهید. پایین تر آزمایشها بسته به سختافزار، تنظیمات و شرایط، کاهشهای کوچک تا قابل توجهی در استفاده از CPU در طول حمله نشان میدهند. با این حال، ممکن است به دلیل ipfrag_high_thresh=XNUMX بایت، تأثیری بر عملکرد داشته باشد، زیرا تنها دو قطعه XNUMXK میتوانند در یک زمان در صف مونتاژ مجدد قرار گیرند. به عنوان مثال، این خطر وجود دارد که برنامه هایی که با بسته های بزرگ UDP کار می کنند شکسته شوند'.
خود پارامترها به شرح زیر است:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
ما UDP های بزرگی در خدمات تولید نداریم. هیچ ترافیک تکه تکه ای در شبکه LAN وجود ندارد، ترافیک تکه تکه شده در شبکه WAN وجود دارد، اما قابل توجه نیست. هیچ نشانه ای وجود ندارد - می توانید راه حل را اجرا کنید!
FragmentSmack/SegmentSmack. خون اول
اولین مشکلی که با آن مواجه شدیم این بود که کانتینرهای ابری گاهی اوقات تنظیمات جدید را فقط تا حدی اعمال میکردند (فقط ipfrag_low_thresh) و گاهی اوقات اصلاً آنها را اعمال نمیکردند - آنها به سادگی در ابتدا خراب میشدند. امکان بازتولید مشکل به صورت پایدار وجود نداشت (همه تنظیمات به صورت دستی بدون هیچ مشکلی اعمال شدند). درک اینکه چرا کانتینر در ابتدا سقوط می کند نیز چندان آسان نیست: هیچ خطایی پیدا نشد. یک چیز مسلم بود: بازگرداندن تنظیمات مشکل خرابی کانتینر را حل می کند.
چرا اعمال Sysctl روی هاست کافی نیست؟ کانتینر در فضای نام شبکه اختصاصی خود زندگی می کند، حداقل بنابراین در ظرف ممکن است با میزبان متفاوت باشد.
تنظیمات Sysctl دقیقاً چگونه در کانتینر اعمال می شود؟ از آنجایی که کانتینرهای ما فاقد امتیاز هستند، نمیتوانید تنظیمات Sysctl را با رفتن به خود کانتینر تغییر دهید - به سادگی حقوق کافی ندارید. برای اجرای کانتینرها، ابر ما در آن زمان از Docker (اکنون ). پارامترهای کانتینر جدید از طریق API، از جمله تنظیمات لازم Sysctl، به Docker منتقل شدند.
هنگام جستجوی نسخه ها، مشخص شد که Docker API همه خطاها را (حداقل در نسخه 1.10) برنگردانده است. وقتی سعی کردیم کانتینر را از طریق "Docker run" راه اندازی کنیم، در نهایت حداقل چیزی دیدیم:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
مقدار پارامتر معتبر نیست. اما چرا؟ و چرا فقط گاهی اوقات معتبر نیست؟ مشخص شد که Docker ترتیب اعمال پارامترهای Sysctl را تضمین نمی کند (آخرین نسخه آزمایش شده 1.13.1 است) ، بنابراین گاهی اوقات ipfrag_high_thresh سعی می کرد تا زمانی که ipfrag_low_thresh هنوز 256M بود روی 3K تنظیم شود، یعنی حد بالایی کمتر بود. از حد پایین تر، که منجر به خطا شد.
در آن زمان، ما قبلاً از مکانیسم خود برای پیکربندی مجدد ظرف پس از شروع استفاده کردیم (انجماد ظرف پس از و اجرای دستورات در فضای نام کانتینر از طریق ) و همچنین پارامترهای نوشتن Sysctl را به این قسمت اضافه کردیم. مشکل حل شد.
FragmentSmack/SegmentSmack. خون اول 2
قبل از اینکه زمان برای درک استفاده از Workaround در ابر داشته باشیم، اولین شکایات نادر از سوی کاربران شروع شد. در آن زمان چندین هفته از شروع استفاده از Workaround در اولین سرورها گذشته بود. بررسی اولیه نشان داد که شکایاتی علیه خدمات فردی دریافت شده است و نه همه سرورهای این خدمات. مشکل دوباره به شدت نامشخص شده است.
اول از همه، ما سعی کردیم تنظیمات Sysctl را به حالت قبل برگردانیم، اما هیچ تاثیری نداشت. دستکاریهای مختلف در تنظیمات سرور و برنامه نیز کمکی نکرد. راهاندازی مجدد سیستم مفید بود. راهاندازی مجدد برای Linux به همان اندازه که غیرطبیعی بود، یک شرایط عادی برای کار با ... Windows در قدیم. هرچند کار میکرد، و ما آن را به یک «اشکال هسته» هنگام اعمال تنظیمات جدید Sysctl نسبت دادیم. چقدر از ما احمق بودیم...
سه هفته بعد مشکل عود کرد. پیکربندی این سرورها بسیار ساده بود: Nginx در حالت پروکسی/بالانسر. ترافیک زیاد نیست یادداشت مقدماتی جدید: تعداد 504 خطا در مشتریان هر روز در حال افزایش است (). نمودار تعداد 504 خطا در روز را برای این سرویس نشان می دهد:
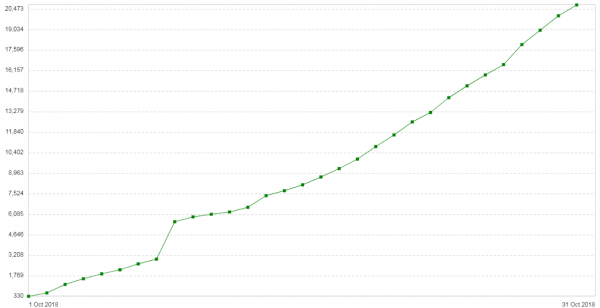
همه خطاها در مورد یک باطن هستند - در مورد خطاهایی که در ابر است. نمودار مصرف حافظه برای قطعات بسته در این باطن به شکل زیر است:
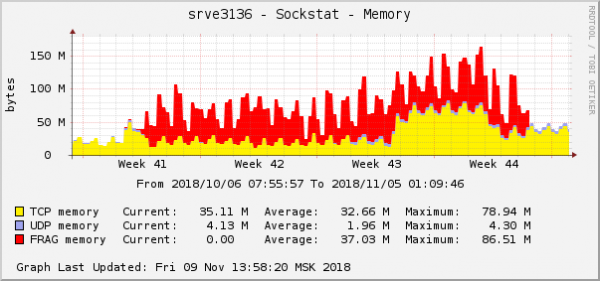
این یکی از بارزترین جلوه های مشکل در نمودارهای سیستم عامل است. در فضای ابری، درست در همان زمان، یک مشکل دیگر شبکه با تنظیمات QoS (کنترل ترافیک) برطرف شد. در نمودار مصرف حافظه برای قطعات بسته، دقیقاً یکسان به نظر می رسد:
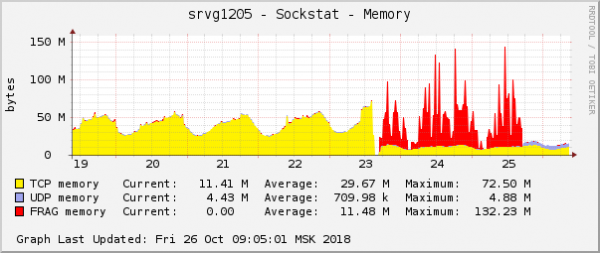
فرض ساده بود: اگر در نمودارها یکسان به نظر برسند، پس دلیل یکسانی دارند. علاوه بر این، هر گونه مشکل در این نوع حافظه بسیار نادر است.
ماهیت مشکل حل شده این بود که ما از زمانبندی بسته fq با تنظیمات پیش فرض در QoS استفاده کردیم. به طور پیش فرض، برای یک اتصال، به شما امکان می دهد 100 بسته را به صف اضافه کنید، و برخی از اتصالات، در شرایط کمبود کانال، شروع به مسدود کردن صف به ظرفیت خود کردند. در این حالت بسته ها حذف می شوند. در آمار tc (tc -s qdisc) به صورت زیر قابل مشاهده است:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" بسته هایی است که به دلیل فراتر رفتن از حد صف یک اتصال حذف شده اند و "Drop 464545" مجموع تمام بسته های حذف شده این زمانبندی است. پس از افزایش طول صف به 1 هزار و راه اندازی مجدد کانتینرها، مشکل متوقف شد. می توانید بنشینید و یک اسموتی بنوشید.
FragmentSmack/SegmentSmack. آخرین خون
اولاً، چند ماه پس از اعلام آسیبپذیریهای هسته، سرانجام یک اصلاحیه برای FragmentSmack منتشر شد (به یاد داشته باشید، اعلامیه ماه اوت فقط اصلاحیه SegmentSmack را منتشر کرد)، که به ما این فرصت را داد تا Workaround را که دردسر زیادی برای ما ایجاد کرده بود، کنار بگذاریم. ما در این مدت برخی از سرورها را به هسته جدید منتقل کرده بودیم و حالا باید از ابتدا شروع میکردیم. چرا هسته را بدون انتظار برای اصلاح FragmentSmack بهروزرسانی کردیم؟ واقعیت این است که فرآیند محافظت در برابر این آسیبپذیریها با فرآیند بهروزرسانی خود Workaround همزمان (و ادغام) شد. CentOS (که حتی بیشتر از بهروزرسانی فقط هسته طول میکشد). علاوه بر این، SegmentSmack یک آسیبپذیری خطرناکتر است و بلافاصله راهحلی برای آن در دسترس بود، بنابراین به هر حال منطقی بود. با این حال، بهروزرسانی ساده هسته CentOS ما به دلیل آسیبپذیری FragmentSmack که در طول [...] ظاهر شد، نمیتوانستیم CentOS نسخه ۷.۵ فقط در نسخه ۷.۶ اصلاح شد، بنابراین مجبور شدیم بهروزرسانی به ۷.۵ را متوقف کنیم و دوباره با بهروزرسانی به ۷.۶ شروع کنیم. این اتفاق هم میافتد.
ثانیاً، شکایات نادر کاربران در مورد مشکلات به ما بازگشته است. اکنون با اطمینان می دانیم که همه آنها مربوط به آپلود فایل ها از مشتریان به برخی از سرورهای ما هستند. علاوه بر این، تعداد بسیار کمی از آپلودها از کل حجم از طریق این سرورها انجام شد.
همانطور که از داستان بالا به یاد داریم، بازگرداندن Sysctl کمکی نکرد. راه اندازی مجدد کمک کرد، اما به طور موقت.
سوء ظن در مورد Sysctl برطرف نشد، اما این بار لازم بود تا حد امکان اطلاعات جمع آوری شود. همچنین کمبود زیادی برای بازتولید مشکل آپلود در مشتری به منظور مطالعه دقیق تر آنچه اتفاق می افتد وجود داشت.
تجزیه و تحلیل همه آمارها و گزارش های موجود ما را به درک آنچه در حال رخ دادن است نزدیکتر نکرد. فقدان حاد توانایی برای بازتولید مشکل به منظور "احساس" یک ارتباط خاص وجود داشت. در نهایت، توسعه دهندگان با استفاده از یک نسخه ویژه از برنامه، موفق به بازتولید پایدار مشکلات در یک دستگاه آزمایشی هنگام اتصال از طریق Wi-Fi شدند. این یک پیشرفت در تحقیقات بود. کلاینت به Nginx متصل شد، که به backend که برنامه جاوا ما بود، پروکسی کرد.
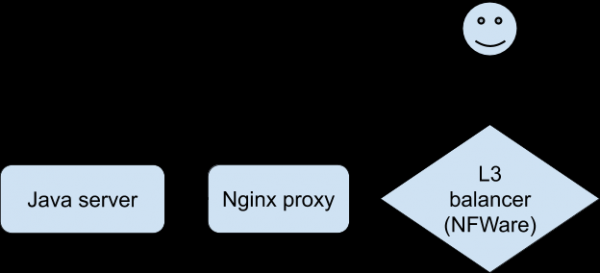
گفتگوی مشکلات به این صورت بود (در سمت پراکسی Nginx ثابت شد):
- مشتری: درخواست دریافت اطلاعات در مورد دانلود فایل.
- سرور جاوا: پاسخ.
- مشتری: POST با فایل.
- سرور جاوا: خطا.
در همان زمان، سرور جاوا در گزارش می نویسد که 0 بایت داده از مشتری دریافت شده است و پراکسی Nginx می نویسد که درخواست بیش از 30 ثانیه طول کشیده است (30 ثانیه زمان پایان برنامه مشتری است). چرا تایم اوت و چرا 0 بایت؟ از منظر HTTP، همه چیز همانطور که باید کار می کند، اما به نظر می رسد POST با فایل از شبکه ناپدید می شود. علاوه بر این، بین مشتری و Nginx ناپدید می شود. وقت آن است که خود را با Tcpdump مسلح کنید! اما ابتدا باید پیکربندی شبکه را درک کنید. پروکسی Nginx پشت بالانس L3 قرار دارد . تونل سازی برای تحویل بسته ها از متعادل کننده L3 به سرور استفاده می شود که هدرهای خود را به بسته ها اضافه می کند:
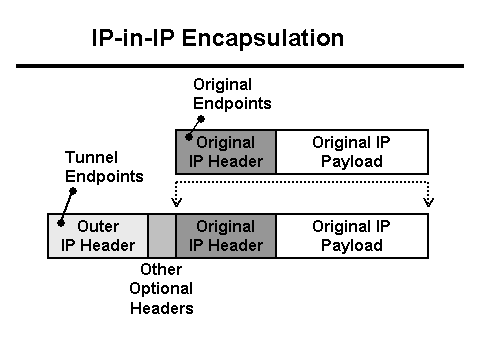
در این حالت، شبکه به صورت ترافیک با برچسب Vlan به این سرور می آید که فیلدهای خود را نیز به بسته ها اضافه می کند:
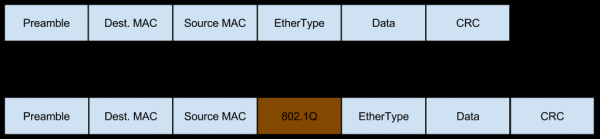
و این ترافیک همچنین می تواند تکه تکه شود (همان درصد کمی از ترافیک پراکنده ورودی که هنگام ارزیابی خطرات ناشی از Workaround در مورد آن صحبت کردیم)، که محتوای هدرها را نیز تغییر می دهد:
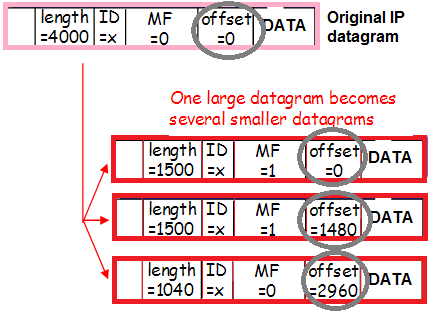
یک بار دیگر: بسته ها با یک برچسب Vlan کپسوله می شوند، با یک تونل محصور می شوند، تکه تکه می شوند. برای درک بهتر چگونگی این اتفاق، بیایید مسیر بسته را از مشتری به پراکسی Nginx ردیابی کنیم.
- بسته به متعادل کننده L3 می رسد. برای مسیریابی صحیح در مرکز داده، بسته در یک تونل محصور شده و به کارت شبکه ارسال می شود.
- از آنجایی که هدرهای بسته + تونل در MTU قرار نمی گیرند، بسته به قطعات بریده شده و به شبکه ارسال می شود.
- سوئیچ بعد از متعادل کننده L3، هنگام دریافت بسته، یک تگ Vlan به آن اضافه کرده و آن را روشن می کند.
- سوئیچ جلوی پراکسی Nginx می بیند (بر اساس تنظیمات پورت) که سرور منتظر بسته ای با Vlan کپسوله شده است، بنابراین بدون حذف تگ Vlan، آن را همانطور که هست ارسال می کند.
- Linux قطعات بستههای جداگانه را دریافت میکند و آنها را در یک بسته بزرگ میچسباند.
- بعد، بسته به رابط Vlan می رسد، جایی که اولین لایه از آن حذف می شود - Vlan encapsulation.
- سپس Linux آن را به رابط تونل ارسال میکند، جایی که لایه دیگری از آن حذف میشود - کپسولهسازی تونل.
مشکل این است که همه اینها را به عنوان پارامتر به tcpdump منتقل کنید.
بیایید از آخر شروع کنیم: آیا بستههای IP تمیز (بدون هدر غیر ضروری) از کلاینتها وجود دارد که حاوی vlan و تونل حذف شده است؟
tcpdump host <ip клиента>
خیر، چنین بسته هایی روی سرور وجود نداشت. پس مشکل باید زودتر وجود داشته باشد. آیا بسته هایی وجود دارد که فقط درپوش Vlan حذف شده باشد؟
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx آدرس IP مشتری در قالب هگز است.
32:4 - آدرس و طول فیلدی که IP SCR در بسته Tunnel در آن نوشته شده است.
آدرس فیلد باید با زور بی رحمانه انتخاب می شد، زیرا در اینترنت حدود 40، 44، 50، 54 می نویسند، اما هیچ آدرس IP در آنجا وجود نداشت. همچنین می توانید به یکی از بسته ها به صورت هگز (پارامتر -xx یا -XX در tcpdump) نگاه کنید و آدرس IP را که می دانید محاسبه کنید.
آیا قطعات بسته بدون Vlan و Tunnel encapsulation حذف شده است؟
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
این جادو همه قطعات، از جمله آخرین را به ما نشان می دهد. احتمالاً همین مورد را می توان با IP فیلتر کرد ، اما من سعی نکردم ، زیرا چنین بسته هایی بسیار زیاد نیست و بسته هایی که من نیاز داشتم به راحتی در جریان عمومی پیدا می شوند. آن ها اینجا هستند:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
۱۴:۰۲:۵۸.۴۷۱۱۰۳ در ۰۰:de:ff:14a:۹۴:۱۱ نوع اتر IPv02 (58.471103x00)، طول ۶۲: (tos 1x94، ttl 11، شناسه ۵۳۶۵۲، افست ۱۴۸۰، پرچمها [هیچکدام]، پروتکل IPIP اولیه (4)، طول 40)
۱۱.۱۱.۱۱.۱۱ > ۲۲.۲۲.۲۲.۲۲: ip-proto-11.11.11.11
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
این دو قطعه از یک بسته (همان شناسه 53652) با یک عکس (کلمه Exif در بسته اول قابل مشاهده است). با توجه به اینکه بسته هایی در این سطح وجود دارد، اما به صورت ادغام شده در دامپ ها وجود ندارد، مشکل به وضوح از مونتاژ است. بالاخره شواهد مستندی در این مورد وجود دارد!
رمزگشای بسته هیچ مشکلی را نشان نداد که مانع از ساخت شود. اینجا امتحانش کرد: . در ابتدا، وقتی میخواهید چیزی را در آنجا قرار دهید، رمزگشا از قالب بسته خوشش نمیآید. معلوم شد که دو اکتت اضافی بین Srcmac و Ethertype وجود دارد (به اطلاعات قطعه مربوط نمی شود). پس از حذف آنها، رسیور شروع به کار کرد. با این حال، هیچ مشکلی را نشان نداد.
هر چه که می توان گفت، هیچ چیز دیگری به جز آن Sysctl یافت نشد. تنها چیزی که باقی مانده بود یافتن راهی برای شناسایی سرورهای مشکل به منظور درک مقیاس و تصمیم گیری در مورد اقدامات بعدی بود. شمارنده مورد نیاز به سرعت پیدا شد:
netstat -s | grep "packet reassembles failed”
همچنین در snmpd تحت OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
"تعداد خرابی های شناسایی شده توسط الگوریتم مونتاژ مجدد IP (به هر دلیلی: اتمام زمان، خطاها و غیره)."
در بین گروهی از سرورهایی که مشکل بر روی آنها مطالعه شد، در دو سرور این شمارنده سریعتر، در دو سرور کندتر و در دو سرور دیگر اصلاً افزایش پیدا نکرد. مقایسه دینامیک این شمارنده با دینامیک خطاهای HTTP در سرور جاوا یک همبستگی را نشان داد. یعنی کنتور قابل نظارت بود.
داشتن یک نشانگر قابل اعتماد از مشکلات بسیار مهم است تا بتوانید دقیقاً تعیین کنید که آیا بازگشت Sysctl به شما کمک می کند یا خیر، زیرا از داستان قبلی می دانیم که این را نمی توان بلافاصله از برنامه فهمید. این شاخص به ما این امکان را میدهد تا قبل از اینکه کاربران آن را کشف کنند، تمام حوزههای مشکل تولید را شناسایی کنیم.
پس از عقب انداختن Sysctl، خطاهای مانیتورینگ متوقف شد، بنابراین علت مشکلات ثابت شد و همچنین این واقعیت که بازگشت به عقب کمک می کند.
ما تنظیمات تکه تکه شدن را در سرورهای دیگر بازگرداندیم، جایی که نظارت جدید وارد عمل شد، و در جایی حتی حافظه بیشتری را نسبت به پیشفرض قبلی برای قطعات اختصاص دادیم (این آمار UDP بود که از دست دادن جزئی آن در پسزمینه عمومی قابل توجه نبود) .
مهمترین سوالات
چرا بسته ها در متعادل کننده L3 ما تکه تکه شده اند؟ اکثر بسته هایی که از کاربران به متعادل کننده ها می رسد SYN و ACK هستند. اندازه این بسته ها کوچک است. اما از آنجایی که سهم چنین بسته هایی بسیار زیاد است، در پس زمینه آنها ما متوجه وجود بسته های بزرگی که شروع به تکه تکه شدن کردند، نشدیم.
دلیل آن خرابی اسکریپت پیکربندی بود در سرورهایی با رابط Vlan (در آن زمان سرورهای بسیار کمی با ترافیک برچسب گذاری شده در تولید وجود داشت). Advmss به ما این امکان را می دهد که این اطلاعات را به مشتری منتقل کنیم که بسته ها در جهت ما باید از نظر اندازه کوچکتر باشند تا پس از چسباندن هدرهای تونل به آنها نیازی به تکه تکه شدن آنها نباشد.
چرا Sysctl rollback کمکی نکرد، اما راه اندازی مجدد کمکی کرد؟ بازگرداندن Sysctl مقدار حافظه موجود برای ادغام بسته ها را تغییر داد. در همان زمان، ظاهراً واقعیت سرریز حافظه برای قطعات منجر به کاهش سرعت اتصالات شد، که منجر به تأخیر طولانی مدت قطعات در صف شد. یعنی این فرآیند به صورت چرخه ای پیش رفت.
راه اندازی مجدد حافظه را پاک کرد و همه چیز به حالت عادی برگشت.
آیا بدون راه حل ممکن بود؟ بله، اما در صورت حمله، خطر زیادی وجود دارد که کاربران بدون سرویس باقی بمانند. البته استفاده از Workaround مشکلات مختلفی از جمله کند شدن یکی از سرویسها را برای کاربران به همراه داشت، اما با این وجود معتقدیم که این اقدامات موجه بوده است.
با تشکر فراوان از آندری تیموفیف () برای کمک در انجام تحقیقات، و همچنین الکسی کرنف () - برای کار عظیم بهروزرسانی Centos و هستههای سرور. در این حالت، این فرآیند باید چندین بار مجدداً راهاندازی میشد که منجر به ماهها زمان میشد.
منبع: www.habr.com
