

تعطیلات تمام شد و ما با دومین پست از سری مقالات Istio Service Mesh برگشتیم.

موضوع امروز Circuit Breaker است که در زبان روسی به معنای "کلید اتوماتیک" یا به زبان عامیانهتر "قطعکننده مدار" است. با این حال، در Istio، این قطعکننده مدار به جای مدارهای اتصال کوتاه یا اضافه بار، محفظههای معیوب را از مدار خارج میکند.
چگونه باید به طور ایدهآل کار کند
وقتی میکروسرویسها توسط Kubernetes مدیریت میشوند، مثلاً در پلتفرم OpenShift، بسته به بار، به طور خودکار مقیاسپذیریشان افزایش یا کاهش مییابد. از آنجایی که میکروسرویسها در podها اجرا میشوند، چندین نمونه از یک میکروسرویس کانتینر شده میتوانند روی یک نقطه پایانی واحد اجرا شوند و Kubernetes درخواستها را مسیریابی کرده و بار را بین آنها متعادل میکند. و در حالت ایدهآل، همه اینها باید کاملاً کار کنند.
ما به یاد داریم که میکروسرویسها کوچک و زودگذر هستند. زودگذری، که در اینجا به سهولت ظهور و ناپدید شدن اشاره دارد، اغلب دست کم گرفته میشود. تولد و مرگ یک نمونه میکروسرویس دیگر در یک پاد کاملاً قابل انتظار است؛ OpenShift و Kubernetes این را به خوبی مدیریت میکنند و همه چیز به طرز شگفتانگیزی کار میکند - اما باز هم، این فقط در تئوری است.
چگونه واقعاً کار میکند
حالا تصور کنید که یک نمونه خاص از میکروسرویس یا کانتینر، غیرقابل استفاده شده است: یا پاسخ نمیدهد (خطای ۵۰۳) یا بدتر از آن، پاسخ میدهد اما خیلی کند. به عبارت دیگر، دچار مشکل یا عدم پاسخگویی است، اما به طور خودکار از مخزن حذف نمیشود. در این صورت چه کاری باید انجام دهید؟ دوباره امتحان کنید؟ آن را از مسیریابی حذف کنید؟ و «خیلی کند» به چه معناست؟ این مقدار چقدر است و چه کسی آن را تعیین میکند؟ شاید بهتر باشد به آن استراحت دهید و بعداً دوباره امتحان کنید؟ اگر چنین است، چه مدت؟
تخلیه استخر در Istio چیست؟
اینجاست که Istio با مکانیسمهای محافظتی Circuit Breaker خود وارد عمل میشود، که با پیادهسازی رویه Pool Ejection، کانتینرهای معیوب را به طور موقت از Pool منابع مسیریابی و متعادلسازی بار حذف میکند.
با استفاده از یک استراتژی تشخیص دادههای پرت، Istio پادهایی را که همگامسازی نشدهاند شناسایی کرده و آنها را برای مدت زمان مشخصی که به آن پنجره خواب میگویند، از مخزن منابع حذف میکند.
برای نشان دادن نحوهی عملکرد این قابلیت در Kubernetes روی پلتفرم OpenShift، بیایید با یک اسکرینشات از میکروسرویسهای در حال اجرا از مخزن نمونه شروع کنیم. در اینجا ما دو پاد داریم، v1 و v2، که هر کدام یک کانتینر را اجرا میکنند. وقتی از قوانین مسیریابی Istio استفاده نمیشود، Kubernetes به طور پیشفرض از مسیریابی round-robin متعادل استفاده میکند:
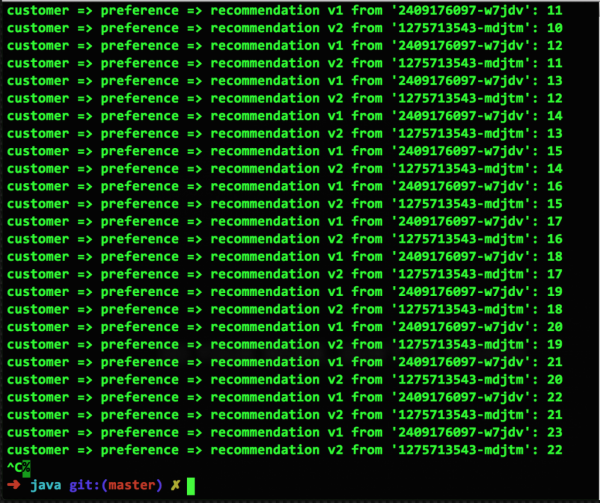
آماده شدن برای شکست
قبل از انجام Pool Ejection، باید یک قانون مسیریابی Istio ایجاد کنیم. فرض کنید میخواهیم درخواستها را بین podها به صورت ۵۰/۵۰ توزیع کنیم. همچنین تعداد کانتینرهای v2 را از یک به دو افزایش میدهیم، مانند این:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
حالا یک قانون مسیریابی تنظیم میکنیم تا ترافیک بین پادها با نسبت ۵۰/۵۰ توزیع شود.

و نتیجهی این قانون به این صورت است:
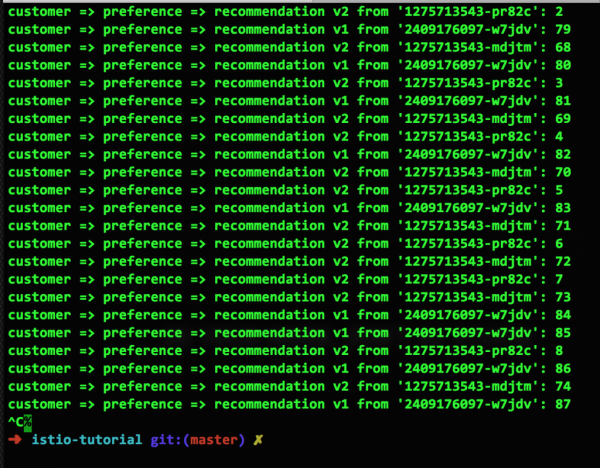
شاید کسی از این واقعیت که این صفحه نمایش 50/50 نیست، بلکه 14:9 است، ایراد بگیرد، اما اوضاع به مرور زمان بهتر خواهد شد.
ما داریم یه اختلال ایجاد میکنیم
حالا بیایید یکی از دو کانتینر v2 را غیرفعال کنیم تا یک کانتینر v1 سالم، یک کانتینر v2 سالم و یک کانتینر v2 خراب داشته باشیم:
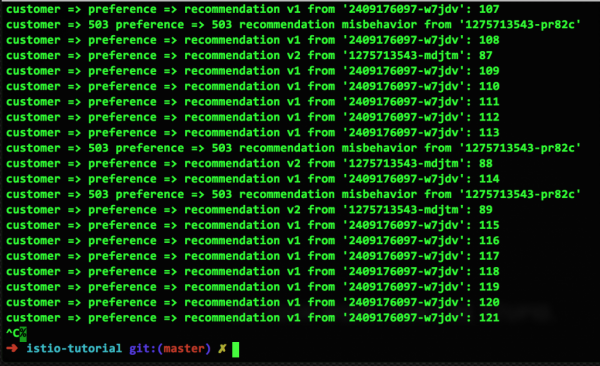
داریم مشکل رو برطرف میکنیم
خب، ما یک کانتینر خراب داریم و زمان Pool Ejection (خروج از استخر) فرا رسیده است. با استفاده از یک پیکربندی بسیار ساده، این کانتینر خراب را به مدت ۱۵ ثانیه از تمام مسیریابیها حذف میکنیم، به این امید که خودش (یا با راهاندازی مجدد یا بازیابی عملکرد) بهبود یابد. در اینجا نحوهی این پیکربندی و نتایج آن آمده است:

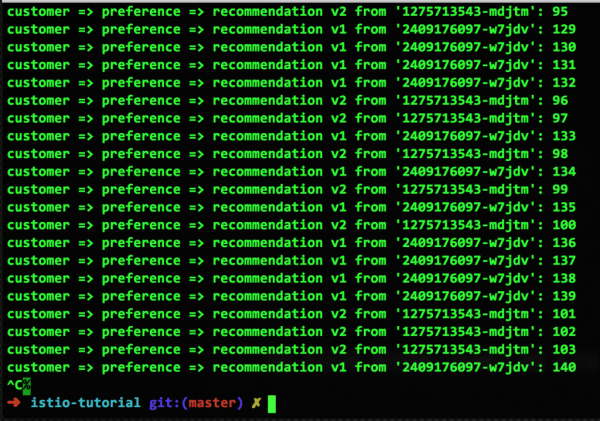
همانطور که میبینید، کانتینر v2 معیوب دیگر برای مسیریابی درخواست استفاده نمیشود زیرا از pool حذف شده است. با این حال، پس از ۱۵ ثانیه، به طور خودکار به pool باز میگردد. در واقع، ما فقط نحوهی عملکرد Pool Ejection را نشان دادهایم.
بیایید شروع به ساختن معماری کنیم
قابلیت Pool Ejection در ترکیب با قابلیتهای نظارتی Istio، به شما این امکان را میدهد که چارچوبی برای جایگزینی خودکار کانتینرهای خراب ایجاد کنید تا زمان از کارافتادگی و خرابیها را کاهش دهید، اگر نگوییم از بین ببرید.
ناسا یک شعار بلند دارد - شکست یک گزینه نیست، که نویسنده آن مدیر پرواز محسوب میشود. میتوان آن را به روسی به صورت «شکست یک گزینه نیست» ترجمه کرد، و ایده این است که هر چیزی را میتوان با اراده کافی به کار انداخت. با این حال، در زندگی واقعی، شکستها خود به خود اتفاق نمیافتند؛ آنها اجتنابناپذیرند، در همه جا و در همه چیز. بنابراین در مورد میکروسرویسها چگونه با آنها برخورد میکنید؟ به نظر ما، بهتر است نه به اراده، بلکه به قابلیتهای کانتینرها تکیه کنید. , و .
همانطور که قبلاً اشاره کردیم، Istio مفهوم جاافتاده قطعکنندههای مدار در دنیای فیزیکی را پیادهسازی میکند. همانطور که یک قطعکننده مدار الکتریکی بخش مشکلدار یک مدار را قطع میکند، قطعکننده مدار مبتنی بر نرمافزار Istio نیز در صورت بروز مشکل در نقطه پایانی، مانند خرابی یا کند شدن سرور، ارتباط بین جریان درخواست و کانتینر مشکلدار را قطع میکند.
علاوه بر این، در حالت دوم، مشکلات فقط افزایش مییابند، زیرا کند شدن یک کانتینر نه تنها باعث ایجاد آبشاری از تأخیر در سرویسهایی میشود که به آن دسترسی دارند و در نتیجه، عملکرد سیستم را به طور کلی کاهش میدهد، بلکه درخواستهای مکرری را به یک سرویس از قبل کند ایجاد میکند که فقط اوضاع را بدتر میکند.
مدارشکن در تئوری
قطعکننده مدار (Circuit Breaker) یک پروکسی است که جریان درخواستها به یک نقطه پایانی را کنترل میکند. هنگامی که این نقطه پایانی از کار میافتد یا بسته به تنظیمات پیکربندی شده، شروع به کند شدن میکند، پروکسی اتصال به کانتینر را قطع میکند. سپس ترافیک به کانتینرهای دیگر هدایت میشود، صرفاً برای اهداف متعادلسازی بار. اتصال برای یک پنجره خواب مشخص، مثلاً دو دقیقه، باز میماند و سپس نیمهباز در نظر گرفته میشود. تلاش برای ارسال درخواست بعدی، وضعیت بعدی اتصال را تعیین میکند. اگر سرویس خوب باشد، اتصال به حالت کار برمیگردد و دوباره بسته میشود. اگر سرویس همچنان از کار بیفتد، اتصال قطع میشود و پنجره خواب دوباره فعال میشود. در اینجا یک نمودار ساده از انتقال حالت قطعکننده مدار آمده است:
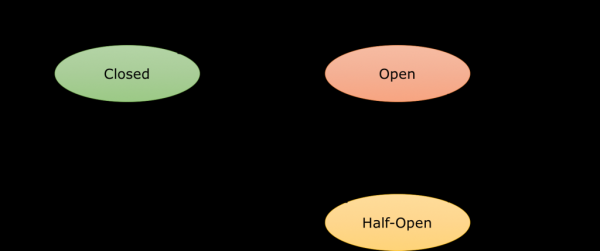
لازم به ذکر است که همه این اتفاقات در سطح معماری سیستم رخ میدهد. بنابراین، در برههای از زمان، شما باید به برنامههای خود آموزش دهید که با Circuit Breaker کار کنند، برای مثال، با ارائه یک مقدار پیشفرض در پاسخ یا در صورت امکان، نادیده گرفتن وجود سرویس. این کار با استفاده از الگوی bulkhead انجام میشود، اما فراتر از محدوده این مقاله است.
مدارشکن در عمل
برای این مثال، ما دو نسخه از میکروسرویس پیشنهادی خود را روی OpenShift اجرا خواهیم کرد. نسخه ۱ به طور عادی اجرا میشود، اما در نسخه ۲ یک تأخیر برای شبیهسازی تأخیر سرور اضافه خواهیم کرد. برای مشاهده نتایج، از ابزار استفاده کنید :
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
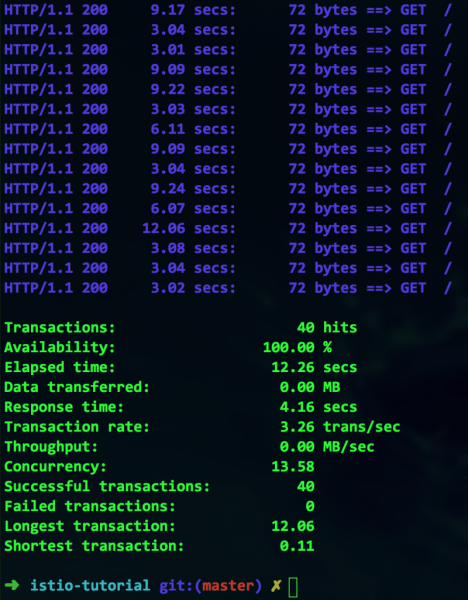
به نظر میرسد همه چیز درست کار میکند، اما به چه قیمتی؟ در نگاه اول، ما ۱۰۰٪ در دسترس هستیم، اما با نگاهی دقیقتر - حداکثر مدت زمان تراکنش ۱۲ ثانیه است. این به وضوح یک گلوگاه است و باید به آن رسیدگی شود.
برای انجام این کار، از Istio برای جلوگیری از فراخوانی کانتینرهای کند استفاده خواهیم کرد. در اینجا پیکربندی مربوطه با استفاده از Circuit Breaker به این شکل است:

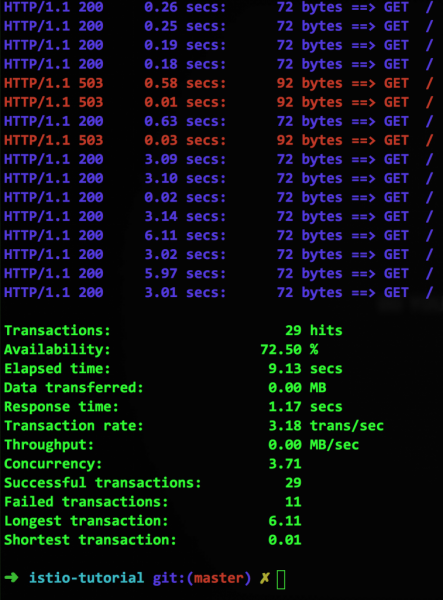
آخرین خط با پارامتر httpMaxRequestsPerConnection نشان میدهد که هنگام تلاش برای ایجاد اتصال دوم علاوه بر اتصال موجود، اتصال باید بسته شود. از آنجایی که کانتینر ما یک سرویس کند را شبیهسازی میکند، چنین موقعیتهایی به صورت دورهای رخ میدهند و سپس Istio خطای ۵۰۳ را برمیگرداند و این چیزی است که Siege نشان میدهد:
خب، ما مدارشکن رو داریم، بعدش چی؟
بنابراین، ما خاموش شدن خودکار را بدون دست زدن به کد منبع خود سرویسها پیادهسازی کردهایم. با استفاده از Circuit Breaker و رویه Pool Ejection که در بالا توضیح داده شد، میتوانیم کانتینرهای کند را از مخزن منابع حذف کنیم تا زمانی که به حالت عادی برگردند و وضعیت آنها را در یک بازه زمانی مشخص بررسی کنیم - در مثال ما، هر دو دقیقه (پارامتر sleepWindow).
لطفا توجه داشته باشید که توانایی یک برنامه برای پاسخگویی به خطای ۵۰۳ هنوز در سطح کد منبع تعریف میشود. بسته به شرایط، استراتژیهای متنوعی برای مقابله با Circuit Breaker وجود دارد.
در پست بعدی: ما ردیابی و نظارت را که در Istio تعبیه شدهاند یا به راحتی اضافه میشوند، و همچنین نحوه ایجاد خطاها به صورت عمدی در سیستم را پوشش خواهیم داد.
منبع: www.habr.com
