


سلام، هابر! من آرتم کارامیشف، رئیس تیم مدیریت سیستم هستم . ما در سال گذشته محصولات جدید زیادی را عرضه کردیم. ما میخواستیم اطمینان حاصل کنیم که سرویسهای API به راحتی مقیاسپذیر، قابل تحمل خطا و آماده رشد سریع در بار کاربر هستند. پلتفرم ما بر روی OpenStack پیاده سازی شده است، و من می خواهم به شما بگویم که چه مشکلاتی در مورد تحمل خطای مؤلفه ها باید حل می کردیم تا یک سیستم مقاوم به خطا را به دست آوریم. من فکر می کنم این برای کسانی که محصولات خود را در OpenStack نیز توسعه می دهند جالب خواهد بود.
تحمل خطای کلی یک پلت فرم شامل انعطاف پذیری اجزای آن است. بنابراین ما به تدریج از تمام سطوحی که خطرات را شناسایی کرده و آنها را بسته ایم عبور خواهیم کرد.
نسخه ویدیویی این داستان که منبع اصلی آن گزارشی در کنفرانس Uptime day 4 بود که توسط ، میتوانی ببینی .
تاب آوری معماری فیزیکی
بخش عمومی ابر MCS اکنون در دو مرکز داده Tier III مستقر است، بین آنها فیبر تاریک خود وجود دارد که در سطح فیزیکی توسط مسیرهای مختلف ذخیره شده است، با توان عملیاتی 200 گیگابیت بر ثانیه. سطح III سطح لازم از تحمل خطا را برای زیرساخت فیزیکی فراهم می کند.
فیبر تیره در هر دو سطح فیزیکی و منطقی محفوظ است. فرآیند رزرو کانال تکراری بود، مشکلاتی به وجود آمد و ما دائماً در حال بهبود ارتباطات بین مراکز داده هستیم.
به عنوان مثال، چندی پیش در حین کار در چاهی نزدیک یکی از مراکز داده، یک بیل مکانیکی لوله ای را شکست و در داخل این لوله هم کابل نوری اصلی و هم یک کابل پشتیبان وجود داشت. کانال ارتباطی متحمل عیب ما با مرکز داده در یک نقطه، در چاه، آسیب پذیر بود. بر این اساس بخشی از زیرساخت ها را از دست داده ایم. ما نتیجه گیری کردیم و تعدادی اقدامات از جمله نصب اپتیک اضافی در چاه مجاور انجام دادیم.
در مراکز داده نقاط حضور ارائه دهندگان ارتباطی وجود دارد که ما پیشوندهای خود را از طریق BGP برای آنها پخش می کنیم. برای هر جهت شبکه، بهترین متریک انتخاب می شود که به مشتریان مختلف اجازه می دهد بهترین کیفیت اتصال را ارائه دهند. اگر ارتباط از طریق یک ارائه دهنده قطع شود، مسیریابی خود را از طریق ارائه دهندگان موجود بازسازی می کنیم.
اگر ارائه دهنده ای شکست بخورد، ما به طور خودکار به ارائه دهنده بعدی تغییر می کنیم. در صورت خرابی یکی از مراکز داده، ما یک نسخه آینه ای از خدمات خود در مرکز داده دوم داریم که کل بار را بر عهده می گیرند.
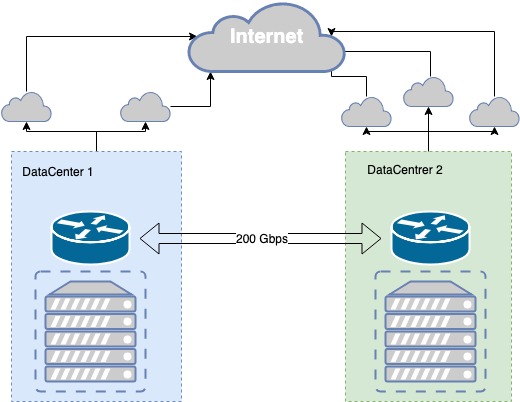
تاب آوری زیرساخت های فیزیکی
آنچه ما برای تحمل خطا در سطح برنامه استفاده می کنیم
خدمات ما بر روی تعدادی از اجزای منبع باز ساخته شده است.
ExaBGP سرویسی است که تعدادی توابع را با استفاده از پروتکل مسیریابی پویا مبتنی بر BGP پیاده سازی می کند. ما فعالانه از آن برای تبلیغ آدرسهای IP در لیست سفید خود استفاده میکنیم که از طریق آن کاربران به API دسترسی دارند.
HAProxy یک متعادل کننده با بار بالا است که به شما امکان می دهد قوانین تعادل ترافیک بسیار انعطاف پذیر را در سطوح مختلف مدل OSI پیکربندی کنید. ما از آن برای ایجاد تعادل در مقابل همه سرویسها استفاده میکنیم: پایگاههای داده، کارگزاران پیام، خدمات API، خدمات وب، پروژههای داخلی ما - همه چیز پشت HAProxy است.
برنامه API - یک برنامه وب که به زبان پایتون نوشته شده است که کاربر زیرساخت و سرویس خود را با آن مدیریت می کند.
درخواست کارگر (از این پس به سادگی کارگر) - در خدمات OpenStack، این یک شبح زیرساخت است که به شما امکان می دهد دستورات API را به زیرساخت پخش کنید. به عنوان مثال، ایجاد دیسک در worker و درخواست ایجاد در API برنامه رخ می دهد.
معماری نرم افزار OpenStack استاندارد
اکثر سرویس هایی که برای OpenStack توسعه یافته اند سعی می کنند از یک الگوی واحد پیروی کنند. یک سرویس معمولاً از 2 قسمت تشکیل شده است: API و کارگران (مجری های پشتیبان). به عنوان یک قاعده، یک API یک برنامه WSGI در پایتون است که یا به عنوان یک فرآیند مستقل (دمون) یا با استفاده از یک وب سرور آماده Nginx یا Apache راه اندازی می شود. API درخواست کاربر را پردازش می کند و دستورالعمل های بیشتری را برای اجرا به برنامه کارگر ارسال می کند. انتقال با استفاده از یک کارگزار پیام، معمولا RabbitMQ انجام می شود، بقیه ضعیف پشتیبانی می شوند. هنگامی که پیام ها به کارگزار می رسد، توسط کارگران پردازش می شود و در صورت لزوم، پاسخی را برمی گرداند.
این پارادایم شامل نقاط شکست مشترک جدا شده است: RabbitMQ و پایگاه داده. اما RabbitMQ در یک سرویس ایزوله است و در تئوری، می تواند برای هر سرویس فردی باشد. بنابراین در MCS ما این خدمات را تا حد امکان جدا میکنیم؛ برای هر پروژه جداگانه، یک پایگاه داده جداگانه، یک RabbitMQ جداگانه ایجاد میکنیم. این رویکرد خوب است زیرا در صورت بروز حادثه در برخی نقاط آسیب پذیر، کل سرویس خراب نمی شود، بلکه تنها بخشی از آن خراب می شود.
تعداد برنامه های کارگر نامحدود است، بنابراین API می تواند به راحتی در پشت متعادل کننده ها به صورت افقی مقیاس شود تا عملکرد و تحمل خطا را افزایش دهد.
برخی از سرویس ها به هماهنگی در داخل سرویس نیاز دارند زمانی که عملیات متوالی پیچیده بین API ها و کارگران رخ می دهد. در این مورد، از یک مرکز هماهنگی واحد استفاده میشود، یک سیستم خوشهای مانند Redis، Memcache، etcd، که به یک کارگر اجازه میدهد به دیگری بگوید که این وظیفه به او محول شده است («لطفاً آن را نگیرید»). ما از etcd استفاده می کنیم. به عنوان یک قاعده، کارگران به طور فعال با پایگاه داده ارتباط برقرار می کنند، اطلاعات را از آنجا می نویسند و می خوانند. ما از mariadb به عنوان یک پایگاه داده استفاده می کنیم که در یک خوشه multimaster قرار دارد.
این سرویس تک کلاسیک به روشی سازماندهی شده است که عموماً برای OpenStack پذیرفته شده است. می توان آن را یک سیستم بسته در نظر گرفت که روش های مقیاس بندی و تحمل خطا برای آن کاملاً مشهود است. برای مثال برای تحمل خطای API کافی است جلوی آنها یک متعادل کننده قرار دهید. جرم گیری کارگران با افزایش تعداد آنها به دست می آید.
نقطه ضعف در کل طرح RabbitMQ و MariaDB است. معماری آنها مستحق یک مقاله جداگانه است.در این مقاله می خواهم بر روی تحمل خطای API تمرکز کنم.
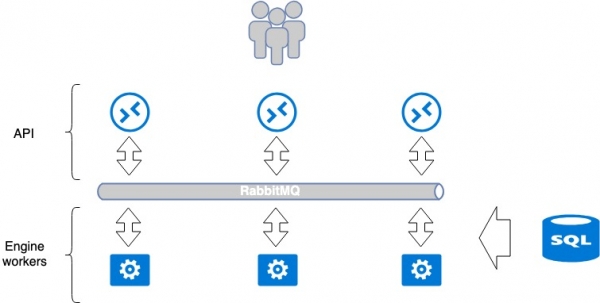
معماری برنامه Openstack. تعادل و تحمل خطای پلت فرم ابری
با استفاده از ExaBGP متعادل کننده HAProxy را مقاوم به خطا کنید
برای اینکه API های خود را مقیاس پذیر، سریع و مقاوم در برابر خطا کنیم، یک بار متعادل کننده در مقابل آنها قرار می دهیم. ما HAProxy را انتخاب کردیم. به نظر من، تمام ویژگیهای لازم برای کار ما را دارد: تعادل در چندین سطح OSI، رابط مدیریت، انعطافپذیری و مقیاسپذیری، تعداد زیادی روش متعادلسازی، پشتیبانی از جداول جلسه.
اولین مشکلی که باید حل می شد، تحمل خطای خود بالانس بود. صرفاً نصب متعادل کننده یک نقطه خرابی ایجاد می کند: بالانس خراب می شود و سرویس از کار می افتد. برای جلوگیری از این اتفاق، از HAProxy به همراه ExaBGP استفاده کردیم.
ExaBGP به شما امکان می دهد مکانیزمی را برای بررسی وضعیت یک سرویس پیاده سازی کنید. ما از این مکانیسم برای بررسی عملکرد HAProxy استفاده کردیم و در صورت بروز مشکل، سرویس HAProxy را از BGP غیرفعال کنیم.
طرح ExaBGP+HAProxy
- نرم افزارهای لازم ExaBGP و HAProxy را روی سه سرور نصب می کنیم.
- ما در هر سرور یک رابط Loopback ایجاد می کنیم.
- در هر سه سرور ما یک آدرس IP سفید یکسان را به این رابط اختصاص می دهیم.
- یک آدرس IP سفید از طریق ExaBGP در اینترنت تبلیغ می شود.
تحمل خطا با تبلیغ آدرس IP یکسان از هر سه سرور به دست می آید. از نقطه نظر شبکه، یک آدرس از سه پرش بعدی متفاوت قابل دسترسی است. روتر سه مسیر یکسان را می بیند، بالاترین اولویت را بر اساس متریک خود انتخاب می کند (این معمولاً همان گزینه است) و ترافیک فقط به یکی از سرورها می رود.
در صورت بروز مشکل در عملکرد HAProxy یا خرابی سرور، ExaBGP اعلام مسیر را متوقف می کند و ترافیک به آرامی به سرور دیگری تغییر می کند.
بنابراین، ما به تحمل خطای متعادل کننده رسیدیم.
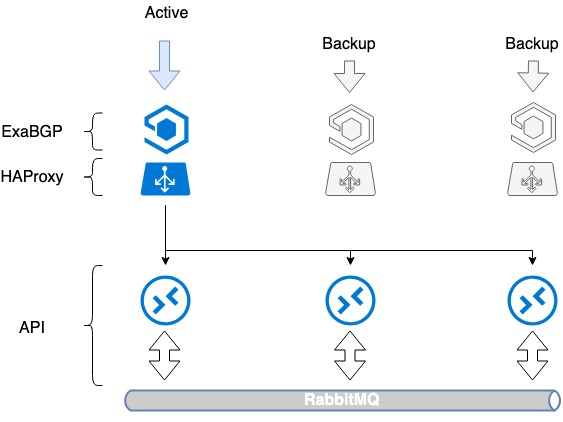
تحمل خطا بالانس های HAProxy
این طرح ناقص بود: ما یاد گرفتیم که چگونه HAProxy را رزرو کنیم، اما یاد نگرفتیم که چگونه بار را در خدمات توزیع کنیم. بنابراین، ما این طرح را کمی گسترش دادیم: ما به سمت تعادل بین چندین آدرس IP سفید حرکت کردیم.
تعادل بر اساس DNS به علاوه BGP
مسئله تعادل بار برای HAProxy ما حل نشده باقی مانده است. با این حال، می توان آن را به سادگی حل کرد، همانطور که در اینجا انجام دادیم.
برای متعادل کردن سه سرور به 3 آدرس IP سفید و DNS خوب قدیمی نیاز دارید. هر یک از این آدرس ها بر روی رابط حلقه بک هر HAProxy تعیین می شود و در اینترنت تبلیغ می شود.
در OpenStack، برای مدیریت منابع، از دایرکتوری سرویس استفاده می شود که API نقطه پایانی یک سرویس خاص را مشخص می کند. در این فهرست ما یک نام دامنه - public.infra.mail.ru را ثبت می کنیم که از طریق DNS توسط سه آدرس IP مختلف حل می شود. در نتیجه، توزیع بار بین سه آدرس را از طریق DNS دریافت می کنیم.
اما از آنجایی که هنگام اعلام آدرسهای IP سفید، اولویتهای انتخاب سرور را کنترل نمیکنیم، این هنوز متعادل نشده است. به طور معمول، تنها یک سرور بر اساس قدمت آدرس IP انتخاب می شود و دو سرور دیگر غیرفعال خواهند بود زیرا هیچ معیاری در BGP مشخص نشده است.
ما شروع به ارسال مسیرها از طریق ExaBGP با معیارهای مختلف کردیم. هر متعادل کننده هر سه آدرس IP سفید را تبلیغ می کند، اما یکی از آنها که اصلی ترین برای این متعادل کننده است، با حداقل متریک تبلیغ می شود. بنابراین در حالی که هر سه متعادل کننده در حال کار هستند، تماس ها به آدرس IP اول به متعادل کننده اول، به دومی به دومی و تماس با آدرس سوم به سوم می روند.
چه اتفاقی می افتد که یکی از تعادل دهنده ها سقوط کند؟ اگر هر متعادل کننده ای از کار بیفتد، آدرس اصلی آن همچنان از دو مورد دیگر تبلیغ می شود و ترافیک بین آنها توزیع می شود. بنابراین، ما چندین آدرس IP را همزمان از طریق DNS به کاربر می دهیم. با متعادل کردن DNS و معیارهای مختلف، توزیع یکنواخت بار را در هر سه متعادل کننده دریافت می کنیم. و در عین حال تحمل خطا را از دست نمی دهیم.
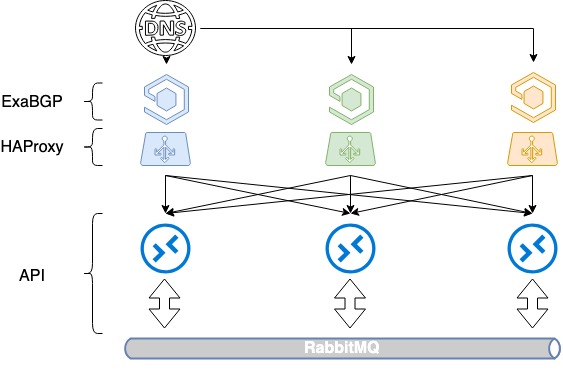
متعادل کردن HAProxy بر اساس DNS + BGP
تعامل بین ExaBGP و HAProxy
بنابراین، ما بر اساس توقف اعلام مسیرها، تحمل خطا را در صورت خروج سرور اجرا کردیم. اما HAProxy می تواند به دلایل دیگری غیر از خرابی سرور خاموش شود: خطاهای مدیریت، خرابی در سرویس. ما می خواهیم در این موارد هم بالانس شکسته را از زیر بار برداریم و به مکانیزم متفاوتی نیاز داریم.
بنابراین، با گسترش طرح قبلی، ضربان قلب را بین ExaBGP و HAProxy پیاده سازی کردیم. این یک پیاده سازی نرم افزاری از تعامل بین ExaBGP و HAProxy است، زمانی که ExaBGP از اسکریپت های سفارشی برای بررسی وضعیت برنامه ها استفاده می کند.
برای انجام این کار، باید یک بررسی کننده سلامت را در پیکربندی ExaBGP پیکربندی کنید، که می تواند وضعیت HAProxy را بررسی کند. در مورد ما، پشتیبان سلامت را در HAProxy پیکربندی کردیم و از سمت ExaBGP با یک درخواست ساده GET بررسی میکنیم. اگر اعلام متوقف شود، به احتمال زیاد HAProxy کار نمی کند و نیازی به تبلیغ آن نیست.
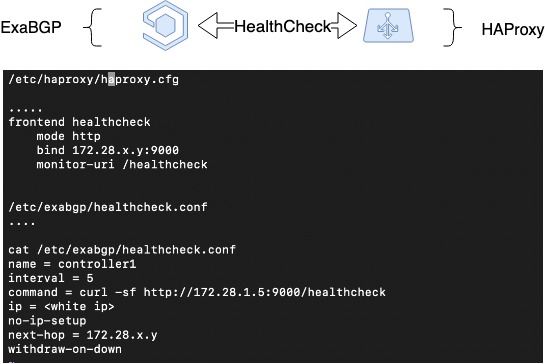
بررسی سلامت HAProxy
HAProxy Peers: همگام سازی جلسه
کار بعدی همگام سازی جلسات بود. هنگام کار از طریق متعادل کننده های توزیع شده، سازماندهی ذخیره سازی اطلاعات در مورد جلسات مشتری دشوار است. اما HAProxy یکی از معدود متعادل کننده هایی است که می تواند این کار را به دلیل عملکرد Peers انجام دهد - توانایی انتقال جداول جلسه بین فرآیندهای مختلف HAProxy.
روش های متعادل سازی مختلفی وجود دارد: روش های ساده مانند و زمانی که جلسه مشتری به خاطر سپرده می شود و هر بار که در همان سرور قبلی قرار می گیرد، تمدید می شود. می خواستیم گزینه دوم را اجرا کنیم.
HAProxy از جدولهای چسبنده برای ذخیره جلسات کلاینت این مکانیسم استفاده میکند. آنها آدرس IP اصلی مشتری، آدرس هدف انتخاب شده (باطن) و برخی از اطلاعات خدمات را ذخیره می کنند. به طور معمول، جداول چسبنده برای ذخیره یک جفت منبع-IP + مقصد-IP استفاده می شود، که به ویژه برای برنامه هایی مفید است که نمی توانند زمینه جلسه کاربر را هنگام جابجایی به متعادل کننده دیگری، به عنوان مثال، در حالت تعادل RoundRobin، انتقال دهند.
اگر به یک میز چوبی آموزش داده شود که بین فرآیندهای مختلف HAProxy حرکت کند (بین آنهایی که تعادل رخ میدهد)، متعادلکنندههای ما میتوانند با یک مجموعه از میزهای چوبی کار کنند. این امر امکان تعویض یکپارچه شبکه مشتری را در صورت عدم موفقیت یکی از متعادل کننده ها فراهم می کند؛ کار با جلسات مشتری در همان backendهایی که قبلاً انتخاب شده بودند ادامه می یابد.
برای عملکرد صحیح، مشکل آدرس IP منبع متعادل کننده ای که جلسه از آن برقرار شده است باید حل شود. در مورد ما، این یک آدرس پویا در رابط حلقه بک است.
کار صحیح همسالان فقط تحت شرایط خاصی به دست می آید. یعنی زمانبندی TCP باید به اندازه کافی بزرگ باشد یا سوئیچینگ باید به اندازه کافی سریع باشد تا جلسه TCP زمانی برای پایان نداشته باشد. با این حال، امکان سوئیچینگ بدون درز را فراهم می کند.
در IaaS ما سرویسی داریم که با استفاده از همین فناوری ساخته شده است. این که به آن اکتاویا می گویند. این مبتنی بر دو فرآیند HAProxy است و در ابتدا شامل پشتیبانی از همتایان است. آنها خود را در این خدمت عالی نشان داده اند.
تصویر به صورت شماتیک حرکت جداول همتا را بین سه نمونه HAProxy نشان میدهد، یک پیکربندی در مورد نحوه پیکربندی آن پیشنهاد شده است:
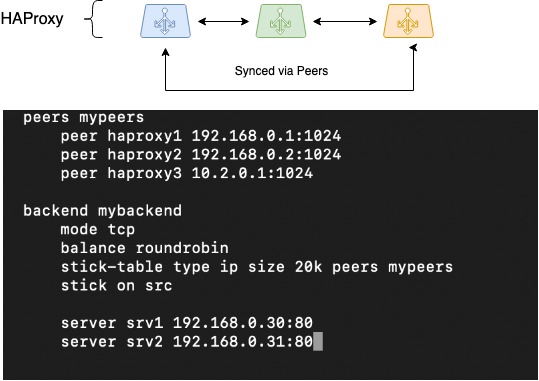
HAProxy Peers (همگام سازی جلسه)
اگر همان طرح را اجرا کنید، عملکرد آن باید به دقت آزمایش شود. این یک واقعیت نیست که 100٪ مواقع به یک شکل کار می کند. اما حداقل زمانی که باید IP منبع مشتری را به خاطر بسپارید، جداول استیک را از دست نخواهید داد.
محدود کردن تعداد درخواستهای همزمان از یک مشتری
هر سرویسی که به صورت عمومی در دسترس است، از جمله API های ما، می تواند در معرض انبوهی از درخواست ها قرار گیرد. دلایل آنها می تواند کاملاً متفاوت باشد، از خطاهای کاربر گرفته تا حملات هدفمند. ما به صورت دوره ای توسط آدرس های IP DDoSed می شویم. کلاینت ها اغلب در اسکریپت های خود اشتباه می کنند و mini-DDoS به ما می دهند.
به هر طریقی، حفاظت اضافی باید ارائه شود. راه حل واضح این است که تعداد درخواست های API را محدود کنید و زمان CPU را برای پردازش درخواست های مخرب تلف نکنید.
برای اجرای چنین محدودیتهایی، از محدودیتهای نرخ استفاده میکنیم که بر اساس HAProxy سازماندهی شدهاند، با استفاده از همان جداول چوب. تنظیم محدودیت ها بسیار ساده است و به شما این امکان را می دهد که کاربر را با تعداد درخواست های API محدود کنید. الگوریتم IP منبعی را که درخواستها از آن انجام میشود به خاطر میآورد و تعداد درخواستهای همزمان یک کاربر را محدود میکند. البته، متوسط پروفایل بارگذاری API را برای هر سرویس محاسبه کردیم و حدی را ≈ 10 برابر این مقدار تعیین کردیم. ما به نظارت دقیق وضعیت ادامه می دهیم و انگشت خود را روی نبض نگه می داریم.
این در عمل چگونه به نظر می رسد؟ ما مشتریانی داریم که همیشه از APIهای مقیاس خودکار ما استفاده می کنند. آنها صبح ها تقریباً دو تا سیصد ماشین مجازی ایجاد می کنند و عصر آنها را حذف می کنند. برای OpenStack، ایجاد یک ماشین مجازی، همچنین با خدمات PaaS، به حداقل 1000 درخواست API نیاز دارد، زیرا تعامل بین سرویس ها نیز از طریق API انجام می شود.
چنین انتقال وظایف باعث ایجاد بار نسبتاً زیادی می شود. ما این بار را ارزیابی کردیم، پیکهای روزانه را جمعآوری کردیم، آنها را ده برابر کردیم و این محدودیت نرخ ما شد. انگشت خود را روی نبض نگه می داریم. ما اغلب رباتها و اسکنرهایی را میبینیم که سعی میکنند به ما نگاه کنند تا ببینند آیا اسکریپتهای CGA قابل اجرا داریم یا خیر، ما فعالانه آنها را برش میدهیم.
چگونه پایگاه کد خود را بدون توجه کاربران به روز کنیم
ما همچنین تحمل خطا را در سطح فرآیندهای استقرار کد پیاده سازی می کنیم. ممکن است در طول عرضه، اشکالاتی وجود داشته باشد، اما تأثیر آنها بر در دسترس بودن خدمات را می توان به حداقل رساند.
ما دائماً خدمات خود را به روز می کنیم و باید اطمینان حاصل کنیم که پایگاه کد بدون تأثیرگذاری بر کاربران به روز می شود. ما با استفاده از قابلیت های مدیریتی HAProxy و پیاده سازی Graceful Shutdown در سرویس های خود موفق به حل این مشکل شدیم.
برای حل این مشکل، اطمینان از کنترل متعادل کننده و خاموش شدن "صحیح" خدمات ضروری بود:
- در مورد HAProxy کنترل از طریق یک فایل stats انجام می شود که در اصل یک سوکت است و در پیکربندی HAProxy تعریف شده است. می توانید دستورات را از طریق stdio به آن ارسال کنید. اما ابزار اصلی کنترل پیکربندی ما قابل انجام است، بنابراین یک ماژول داخلی برای مدیریت HAProxy دارد. که ما فعالانه از آن استفاده می کنیم.
- اکثر سرویسهای API و Engine ما از فناوریهای خاموش کردن برازنده پشتیبانی میکنند: هنگام خاموش شدن، منتظر میمانند تا کار فعلی تکمیل شود، چه درخواست http یا یک کار خدماتی. در مورد کارگر هم همین اتفاق می افتد. تمام وظایفی که انجام می دهد را می داند و زمانی به پایان می رسد که همه چیز را با موفقیت انجام دهد.
به لطف این دو نکته، الگوریتم ایمن برای استقرار ما به این شکل است.
- توسعه دهنده بسته جدیدی از کد را جمع آوری می کند (برای ما این RPM است)، آن را در محیط توسعه آزمایش می کند، آن را در مرحله آزمایش می کند و در مخزن مرحله می گذارد.
- توسعهدهنده وظیفه استقرار را با جزئیترین شرح «مصنوعات» تعیین میکند: نسخه بسته جدید، شرح عملکرد جدید و سایر جزئیات در مورد استقرار در صورت لزوم.
- مدیر سیستم به روز رسانی را آغاز می کند. کتاب بازی Ansible را راه اندازی می کند که به نوبه خود کارهای زیر را انجام می دهد:
- یک بسته را از مخزن مرحله می گیرد و از آن برای به روز رسانی نسخه بسته در مخزن محصول استفاده می کند.
- فهرستی از باطن های سرویس به روز شده را گردآوری می کند.
- اولین سرویسی که در HAProxy بهروزرسانی میشود را خاموش میکند و منتظر میماند تا فرآیندهای آن به پایان برسد. با تشکر از خاموش کردن برازنده، ما مطمئن هستیم که تمام درخواستهای مشتری فعلی با موفقیت تکمیل میشوند.
- پس از توقف کامل API و کارگران، و خاموش شدن HAProxy، کد به روز می شود.
- Ansible خدمات اجرا می کند.
- برای هر سرویس، «دستههای» خاصی کشیده میشوند که تست واحد را روی تعدادی از تستهای کلیدی از پیش تعریفشده انجام میدهند. یک بررسی اساسی از کد جدید انجام می شود.
- اگر در مرحله قبل خطایی پیدا نشد، Backend فعال می شود.
- بیایید به باطن بعدی برویم.
- پس از به روز رسانی تمام پشتیبان ها، تست های عملکردی راه اندازی می شوند. اگر آنها از دست رفته باشند، توسعه دهنده به هر قابلیت جدیدی که ایجاد کرده است نگاه می کند.
این استقرار را کامل می کند.
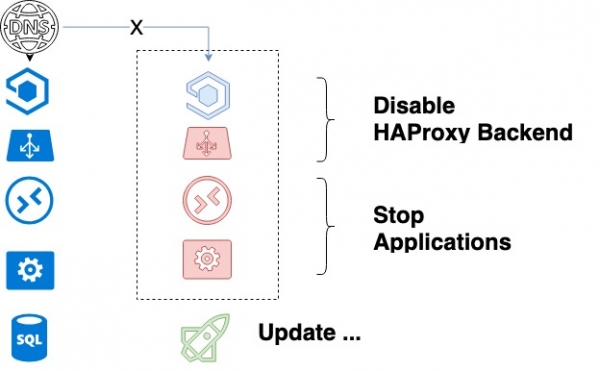
چرخه به روز رسانی سرویس
اگر یک قانون نداشتیم، این طرح کار نمی کرد. ما از هر دو نسخه قدیمی و جدید در نبرد پشتیبانی می کنیم. از قبل، در مرحله توسعه نرم افزار، مقرر شده است که حتی اگر تغییراتی در پایگاه داده خدمات ایجاد شود، کد قبلی را خراب نکنند. در نتیجه، پایه کد به تدریج به روز می شود.
نتیجه
با به اشتراک گذاشتن افکار خود در مورد یک معماری وب مقاوم در برابر خطا، می خواهم یک بار دیگر به نکات کلیدی آن اشاره کنم:
- تحمل خطای فیزیکی؛
- تحمل خطای شبکه (تعادل کننده ها، BGP)؛
- تحمل خطای نرم افزار مورد استفاده و توسعه یافته
زمان ثابت برای همه!
منبع: www.habr.com
