

میخواهم اولین تجربه موفق خودم در بازیابی کامل عملکرد یک پایگاه داده Postgres را با شما به اشتراک بگذارم. من اولین بار شش ماه پیش با Postgres آشنا شدم؛ قبل از آن، هیچ تجربهای در مدیریت پایگاههای داده نداشتم.

من به عنوان یک مهندس نیمهدوآپس در یک شرکت بزرگ فناوری اطلاعات کار میکنم. شرکت ما نرمافزارهایی را برای سرویسهای پربار توسعه میدهد و من مسئول قابلیت اطمینان عملیاتی، نگهداری و استقرار هستم. یک وظیفه استاندارد به من محول شده است: بهروزرسانی یک برنامه روی یک سرور واحد. این برنامه با Django نوشته شده است و مهاجرتها (تغییرات در ساختار پایگاه داده) در طول بهروزرسانی انجام میشوند. قبل از این فرآیند، برای احتیاط، یک نسخه پشتیبان کامل از پایگاه داده را با استفاده از برنامه استاندارد pg_dump انجام میدهیم.
هنگام تخلیه (Postgres نسخه 9.5) خطای غیرمنتظرهای رخ داد:
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly اشکال «صفحه نامعتبر در بلوک» نشان دهنده مشکلاتی در سطح سیستم فایل است که بسیار بد است. انجمنهای مختلف انجام این کار را پیشنهاد کردهاند خلاء کامل با گزینه صفحات_آسیب_دیده_صفر برای حل این مشکل. خب، پاپروبئوم...
آماده شدن برای بهبودی
WARNING! قبل از تلاش برای بازیابی پایگاه داده، حتماً از نصب Postgres خود نسخه پشتیبان تهیه کنید. اگر از ماشین مجازی استفاده میکنید، پایگاه داده را متوقف کرده و یک Snapshot بگیرید. اگر نمیتوانید Snapshot بگیرید، پایگاه داده را متوقف کرده و محتویات دایرکتوری Postgres (از جمله فایلهای .wal) را در یک مکان امن کپی کنید. مهمترین چیز این است که از بدتر شدن اوضاع جلوگیری کنید. ادامه مطلب را بخوانید. .
از آنجایی که پایگاه داده من به طور کلی کار میکرد، خودم را به یک رونوشت معمولی از پایگاه داده محدود کردم، اما جدولی را که دادههای آسیبدیده داشت، حذف کردم (گزینه -T، --exclude-table=TABLE در pg_dump).
سرور فیزیکی بود، بنابراین گرفتن snapshot غیرممکن بود. نسخه پشتیبان تهیه شده است، بیایید ادامه دهیم.
بررسی سیستم فایل
قبل از تلاش برای بازیابی پایگاه داده، باید مطمئن شویم که خود سیستم فایل سالم است. و اگر خطایی وجود دارد، باید آنها را برطرف کنیم، زیرا در غیر این صورت، فقط میتوانیم اوضاع را بدتر کنیم.
در مورد من، سیستم فایل با پایگاه داده در ... نصب شده بود "/srv" و نوع آن ext4 بود.
متوقف کردن پایگاه داده: systemctl postgresql@9.5-main.service را متوقف کن و بررسی میکنیم که سیستم فایل توسط کسی در حال استفاده نیست و میتوان آن را با استفاده از دستور unmount کرد. lsof:
lsof +D /srv
من همچنین مجبور شدم پایگاه داده redis را متوقف کنم زیرا از آن نیز استفاده می کرد "/srv"سپس آن را از سیستم جدا کردم. / srv (مقدار)
بررسی سیستم فایل با استفاده از ابزار انجام شد e2fsck با کلید -f (بررسی اجباری حتی اگر سیستم فایل پاک علامتگذاری شده باشد):
در مرحله بعد، با استفاده از ابزار dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep بررسی شد) میتوانید تأیید کنید که بررسی واقعاً انجام شده است:

e2fsck میگوید که هیچ مشکلی در سطح سیستم فایل ext4 یافت نشد، به این معنی که میتوانید به تلاش برای بازیابی پایگاه داده ادامه دهید، یا به طور دقیقتر، به ... برگردید. خلاء کامل (البته، شما باید سیستم فایل را دوباره mount کنید و پایگاه داده را اجرا کنید).
اگر سرور فیزیکی دارید، حتماً وضعیت دیسکها را بررسی کنید (از طریق smartctl -a /dev/XXX) یا کنترلر RAID را بررسی کردم تا مطمئن شوم مشکل مربوط به سختافزار نیست. در مورد من، مشخص شد که RAID مبتنی بر سختافزار است، بنابراین از مدیر محلی خواستم وضعیت RAID را بررسی کند (سرور چند صد کیلومتر دورتر بود). او گفت هیچ خطایی وجود ندارد، به این معنی که قطعاً میتوانیم بازیابی را شروع کنیم.
تلاش ۱: صفحات آسیبدیده صفر
با استفاده از یک حساب کاربری با حقوق superuser از طریق psql به پایگاه داده متصل شوید. ما به یک superuser نیاز داریم زیرا گزینه صفحات_آسیب_دیده_صفر فقط خودش میتواند آن را تغییر دهد. در مورد من، postgres است:
دستور psql -h 127.0.0.1 -U postgres -s [نام پایگاه داده]
گزینه صفحات_آسیب_دیده_صفر برای نادیده گرفتن خطاهای خواندن (از وبسایت postgrespro) لازم است:
وقتی یک هدر صفحه آسیبدیده شناسایی میشود، PostgreSQL معمولاً خطایی گزارش میدهد و تراکنش فعلی را متوقف میکند. اگر پارامتر zero_damaged_pages فعال باشد، سیستم در عوض یک هشدار صادر میکند، صفحه آسیبدیده را صفر میکند و پردازش را ادامه میدهد. این رفتار دادهها، بهویژه تمام ردیفهای صفحه آسیبدیده را خراب میکند.
ما این گزینه را فعال میکنیم و سعی میکنیم کل میز را جارو کنیم:
VACUUM FULL VERBOSE 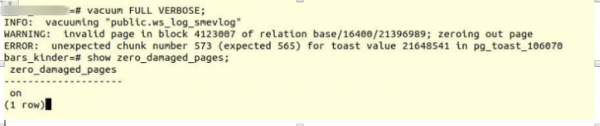
متأسفانه، شکست.
ما با خطای مشابهی مواجه شدیم:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070- مکانیزمی برای ذخیره «دادههای طولانی» در Poetgres در صورتی که در یک صفحه جا نشوند (پیشفرض ۸ کیلوبایت).
تلاش دوم: فهرستبندی مجدد
اولین نکته از گوگل کمکی نکرد. بعد از چند دقیقه جستجو، نکته دوم را پیدا کردم: مجدداً جدول خراب شده. من این توصیه را در جاهای زیادی دیدهام، اما اعتمادی ایجاد نکرده است. بیایید دوباره فهرستبندی کنیم:
reindex table ws_log_smevlog 
مجدداً بدون هیچ مشکلی تکمیل شد.
با این حال، کمکی نکرد، VACUUM FULL با خطای مشابهی از کار افتاد. از آنجایی که به شکست عادت دارم، به جستجوی مشاوره آنلاین ادامه دادم و به یک مورد نسبتاً جالب برخوردم. .
تلاش ۳: انتخاب، محدود کردن، جبران
مقاله بالا پیشنهاد داد که جدول را ردیف به ردیف بررسی کرده و دادههای مشکلساز را حذف کنیم. ابتدا لازم بود که تمام ردیفها بررسی شوند:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneدر مورد من، جدول شامل موارد زیر بود: 1 628 991 خطوط! لازم بود که از آنها مراقبت شود ، اما این موضوع بحث دیگری است. شنبه بود، این دستور را در tmux اجرا کردم و به رختخواب رفتم:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneصبح تصمیم گرفتم بررسی کنم که اوضاع چطور پیش میرود. در کمال تعجب، متوجه شدم که بعد از 20 ساعت، فقط 2٪ از دادهها اسکن شده بودند! نمیخواستم 50 روز صبر کنم. یک شکست کامل دیگر.
اما تسلیم نشدم. نمیدانستم چرا اسکن اینقدر طول میکشد. از مستندات (باز هم در postgrespro)، فهمیدم:
تابع OFFSET به آن میگوید که قبل از شروع به نمایش سطرها در خروجی، از تعداد مشخصشدهای از سطرها صرفنظر کند.
اگر هر دو پارامتر OFFSET و LIMIT مشخص شده باشند، سیستم ابتدا ردیفهای OFFSET را نادیده میگیرد و سپس شروع به شمارش ردیفهای LIMIT میکند.هنگام استفاده از LIMIT، استفاده از دستور ORDER BY نیز مهم است تا اطمینان حاصل شود که ردیفهای نتیجه به ترتیب خاصی بازگردانده میشوند. در غیر این صورت، زیرمجموعههای غیرقابل پیشبینی از ردیفها بازگردانده میشوند.
واضح است که دستور فوق اشتباه بوده است: اولاً، هیچ ... وجود نداشت. سفارش توسط، نتیجه میتواند اشتباه باشد. ثانیاً، Postgres ابتدا مجبور بود ردیفهای OFFSET را اسکن و از آنها صرف نظر کند، و با افزایش انحراف بهرهوری حتی بیشتر کاهش خواهد یافت.
تلاش ۴: ضبط یک کپی از متن
سپس یک ایده به ظاهر درخشان به ذهنم رسید: گرفتن یک روگرفت به صورت متن و تجزیه و تحلیل آخرین خط ضبط شده.
اما ابتدا، بیایید با ساختار جدول آشنا شویم. ws_log_smevlog:
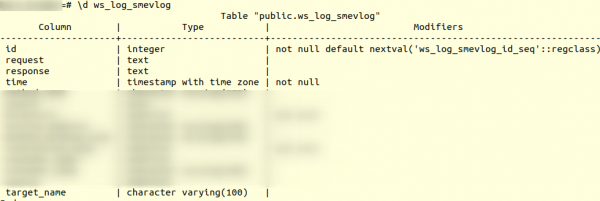
در مورد ما، یک ستون داریم "شناسه"که شامل یک شناسه منحصر به فرد (شمارنده) برای ردیف بود. طرح به شرح زیر بود:
- ما شروع به استخراج دادهها به صورت متنی (به شکل دستورات SQL) میکنیم.
- در برههای از زمان، عملیات تخلیه به دلیل بروز خطا متوقف میشد، اما فایل متنی همچنان روی دیسک ذخیره میشد.
- ما به انتهای فایل متنی نگاه میکنیم، بنابراین شناسه (id) آخرین خطی که با موفقیت حذف شده است را پیدا میکنیم.
من شروع به ارسال اطلاعات به صورت متنی کردم:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpهمانطور که انتظار میرفت، عملیات dump با همان خطا انجام نشد:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 در ادامه از طریق دم به انتهای محل دفن زباله نگاه کردم (دم -5 ./my_dump.dump) متوجه شد که عملیات تخلیه در خط با شناسه (id) قطع شده است. 186 525با خودم فکر کردم: «پس مشکل از شناسه خط ۱۸۶ ۵۲۶ است، خراب است و باید حذف شود!» اما بعد از پرسوجو از پایگاه داده:
«از ws_log_smevlog که شناسه آن ۱۸۶۵۲۹ است، * را انتخاب کنید«معلوم شد که همه چیز با این ردیف خوب است... ردیفهایی با اندیسهای ۱۸۶,۵۳۰ - ۱۸۶,۵۴۰ نیز بدون مشکل کار میکردند. یک «ایده درخشان» دیگر شکست خورد. بعداً فهمیدم که چرا این اتفاق افتاد: هنگام حذف/تغییر دادهها از یک جدول، آن جدول به صورت فیزیکی حذف نمیشود، بلکه به عنوان «تاپلهای مرده» علامتگذاری میشود، سپس میآید.» اتو وکیوم و این ردیفها را به عنوان حذف شده علامتگذاری میکند و اجازه استفاده مجدد از آنها را میدهد. برای شفافسازی، اگر دادههای یک جدول تغییر کند و اتووکیوم فعال باشد، به صورت متوالی ذخیره نمیشود.
تلاش ۵: انتخاب، از، از کجا id=
شکستها ما را قویتر میکنند. هرگز نباید تسلیم شوید، باید ادامه دهید و به خودتان و تواناییهایتان ایمان داشته باشید. بنابراین تصمیم گرفتم گزینه دیگری را امتحان کنم: به سادگی تمام رکوردهای موجود در پایگاه داده را یکی یکی بررسی کنم. با دانستن ساختار جدول من (به بالا مراجعه کنید)، ما یک فیلد id داریم که منحصر به فرد است (کلید اصلی). ما 1,628,991 ردیف در جدول داریم و id آنها به ترتیب هستند، به این معنی که میتوانیم به سادگی روی آنها یکی یکی مرور کنیم:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneبرای کسانی که نمیفهمند، این دستور به این صورت عمل میکند: جدول را خط به خط اسکن میکند و خروجی استاندارد را به / dev / null، اما اگر دستور SELECT با شکست مواجه شود، متن خطا چاپ میشود (stderr به کنسول ارسال میشود) و خطی که حاوی خطا است چاپ میشود (به لطف ||، که به این معنی است که select مشکلاتی داشته است (کد برگشتی دستور 0 نیست)).
من خوش شانس بودم، شاخصهایی روی فیلد ایجاد کرده بودم id:

این یعنی پیدا کردن ردیف با شناسهی مورد نیاز نباید زمان زیادی ببرد. در تئوری، باید کار کند. بنابراین، بیایید دستور را اجرا کنیم. tmux و بریم بخوابیم.
تا صبح، متوجه شدم که حدود ۹۰،۰۰۰ پست بازدید شده است، که کمی بیش از ۵٪ است. نتیجهای عالی در مقایسه با روش قبلی (۲٪)! اما نمیخواستم ۲۰ روز صبر کنم...
تلاش ۶: SELECT، FROM، WHERE id >= و id
مشتری یک سرور عالی برای پایگاه داده اختصاص داده بود: یک سرور دو پردازندهای. Intel Xeon E5-2697 v2ما ۴۸ رشته پردازشی (thread) در دسترس داشتیم! بار سرور متوسط بود، بنابراین به راحتی میتوانستیم حدود ۲۰ رشته پردازشی را مدیریت کنیم. همچنین رم زیادی هم داشتیم: ۳۸۴ گیگابایت!
بنابراین، تیم باید موازیسازی میشد:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneمیتوانستم اینجا یک اسکریپت زیبا و شیک بنویسم، اما سریعترین روش موازیسازی را انتخاب کردم: تقسیم دستی محدوده 0-1628991 به فواصل 100000 رکوردی و اجرای 16 دستور از نوع زیر به صورت جداگانه:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneاما این همه ماجرا نیست. اتصال به پایگاه داده همچنین به زمان و منابع سیستم نیاز دارد. اتصال ۱,۶۲۸,۹۹۱ خیلی هوشمندانه نبود، قبول دارید. پس بیایید به جای فقط یک ردیف، ۱۰۰۰ ردیف را در هر اتصال بازیابی کنیم. دستور در نهایت به این شکل شد:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done۱۶ پنجره را در یک جلسه tmux باز کنید و دستورات زیر را اجرا کنید:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
یک روز بعد، اولین نتایج را دریافت کردم! به طور خاص (مقادیر XXX و ZZZ دیگر ذخیره نشده بودند):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000این یعنی ما سه ردیف با خطا داریم. شناسههای رکوردهای مشکلدار اول و دوم بین ۸۲۹۰۰۰ تا ۸۳۰۰۰۰ و شناسه رکورد سوم بین ۱۴۶۰۰۰ تا ۱۴۷۰۰۰ بود. در مرحله بعد، ما فقط نیاز داشتیم مقادیر دقیق شناسه رکوردهای مشکلدار را پیدا کنیم. برای انجام این کار، محدوده رکوردهای مشکلدار خود را با گامهای ۱ اسکن میکنیم و شناسهها را شناسایی میکنیم:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
پایان خوش
ما ردیفهای مشکلدار را پیدا کردهایم. بیایید با استفاده از psql به پایگاه داده دسترسی پیدا کنیم و سعی کنیم آنها را حذف کنیم:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1در کمال تعجب، رکوردها بدون هیچ مشکلی حتی بدون گزینه حذف شدند. صفحات_آسیب_دیده_صفر.
سپس به پایگاه داده متصل شدم، انجام دادم VACUUM FULL (فکر میکنم انجام این کار ضروری نبود)، و در نهایت با موفقیت از آن نسخه پشتیبان تهیه کردم. pg_dumpفایل dump بدون هیچ خطایی گرفته شد! مشکل با این روش فوقالعاده احمقانه حل شد. از اینکه بالاخره بعد از این همه شکست، راه حلی پیدا کردم، خیلی خوشحال شدم!
تشکر و نتیجه گیری
این اولین تجربه من در بازیابی یک پایگاه داده واقعی Postgres بود. این تجربه را برای مدت طولانی به یاد خواهم داشت.
و در نهایت، مایلم از PostgresPro برای ترجمه مستندات به روسی و ... تشکر کنم. که در طول تحلیل مسئله بسیار مفید بودند.
منبع: www.habr.com
