

ماقبل تاریخ
ما دستگاههای فروش خودکار با طراحی خودمان داریم. در داخل، یک Raspberry Pi و برخی سختافزارها روی یک برد جداگانه قرار دارند. یک گیرنده سکه، یک گیرنده اسکناس و یک دستگاه خودپرداز همگی به هم متصل هستند. یک برنامه سفارشی همه چیز را کنترل میکند. تمام تاریخچه عملکرد در یک گزارش روی یک فلش مموری (MicroSD) ثبت میشود که سپس از طریق اینترنت (از طریق مودم USB) به سرور منتقل میشود و در آنجا در یک پایگاه داده ذخیره میشود. اطلاعات فروش در 1C بارگذاری میشود و همچنین یک رابط وب ساده برای نظارت و غیره وجود دارد.
یعنی، دفتر وقایع روزانه برای حسابداری (درآمد، فروش و غیره)، نظارت (انواع خرابیها و سایر شرایط اضطراری) از اهمیت حیاتی برخوردار است؛ میتوان گفت که این تمام اطلاعاتی است که ما در مورد این دستگاه داریم.
مشکل
فلش مموریها دستگاههای بسیار غیرقابل اعتمادی هستند. آنها به طور نگرانکنندهای خراب میشوند. این امر منجر به از کار افتادن دستگاه و (اگر به هر دلیلی امکان انتقال آنلاین لاگ وجود نداشته باشد) از دست رفتن دادهها میشود.
این اولین تجربه ما در استفاده از فلش مموریها نیست. ما قبلاً روی پروژه دیگری با بیش از صد دستگاه کار میکردیم که در آن گزارش روی فلش مموریهای USB ذخیره میشد. در آنجا نیز مشکلات قابلیت اطمینان وجود داشت، و گاهی اوقات دهها درایو در یک ماه از کار میافتادند. ما فلش مموریهای مختلفی از جمله فلش مموریهای برند با حافظه SLC را امتحان کردیم و برخی از مدلها از بقیه قابل اعتمادتر بودند، اما تعویض درایوها مشکل را به طور کامل حل نکرد.
اخطار! اگر به «چرایی» این کار علاقه ندارید و فقط به «چگونگی» آن علاقهمند هستید، میتوانید از ادامهی مطلب صرفنظر کنید. مقالات
تصمیم
اولین چیزی که به ذهن میرسد این است که کارت MicroSD را کنار بگذارید و مثلاً یک SSD نصب کنید و از طریق آن بوت کنید. از لحاظ تئوری، احتمالاً این کار امکانپذیر است، اما نسبتاً گران است و به خصوص قابل اعتماد نیست (یک آداپتور USB به SATA مورد نیاز است؛ میزان خرابی SSD های ارزان قیمت نیز ناامیدکننده است).
به نظر نمیرسد که USB HDD هم راهحل چندان جذابی باشد.
بنابراین ما این گزینه را مطرح کردیم: بوت شدن از طریق کارت حافظه MicroSD را رها کنید، اما از آنها در حالت فقط خواندنی استفاده کنید و گزارش عملکرد (و سایر اطلاعات منحصر به فرد برای یک قطعه سختافزاری خاص - شماره سریال، کالیبراسیون سنسور و غیره) را در جای دیگری ذخیره کنید.
موضوع FS فقط خواندنی برای رزبری پای قبلاً به طور کامل مورد مطالعه قرار گرفته است، من در این مقاله به جزئیات پیادهسازی نمیپردازم. (اما اگر علاقهای وجود داشته باشد، شاید یک مقاله کوتاه در این مورد بنویسم)تنها نکتهای که میخواهم بگویم این است که بر اساس تجربه شخصی و بازخورد کسانی که قبلاً آن را پیادهسازی کردهاند، افزایش قابلیت اطمینان وجود دارد. اگرچه حذف کامل خرابیها غیرممکن است، اما کاهش قابل توجه فراوانی آنها کاملاً امکانپذیر است. علاوه بر این، کارتها در حال استاندارد شدن هستند و جایگزینی را برای پرسنل تعمیر و نگهداری به طور قابل توجهی آسانتر میکنند.
سخت افزار
در انتخاب نوع حافظه - NOR Flash - هیچ شکی وجود نداشت.
استدلال:
- اتصال ساده (اغلب از طریق گذرگاه SPI که قبلاً استفاده شده است، بنابراین هیچ مشکل سختافزاری پیشبینی نمیشود)؛
- قیمت مسخره؛
- پروتکل عملیاتی استاندارد (پیادهسازی آن از قبل در هسته وجود دارد) Linuxاگر میخواهید، میتوانید یک شخص ثالث را که آن هم موجود است، انتخاب کنید یا حتی خودتان بنویسید، خوشبختانه همه چیز ساده است)؛
- قابلیت اطمینان و طول عمر مفید:
از یک برگه داده معمولی: دادهها به مدت 20 سال ذخیره میشوند، 100000 چرخه پاک کردن برای هر بلوک؛
از منابع شخص ثالث: نرخ خطای بسیار پایین (BER)، نیازی به کدهای تصحیح خطا فرض نشده است (بعضی مقالات ECC را برای NOR بحث میکنند، اما معمولاً منظورشان MLC NOR است و این اتفاق هم میافتد).
بیایید الزامات مربوط به حجم و منابع را تخمین بزنیم.
ما میخواهیم تضمین کنیم که دادههای چند روز را ذخیره میکنیم. این کار برای اطمینان از اینکه در صورت بروز هرگونه مشکل در اتصال، سابقه فروش از بین نمیرود، ضروری است. هدف ما ۵ روز است. (حتی با در نظر گرفتن آخر هفتهها و تعطیلات) مشکل قابل حل است.
ما در حال حاضر حدود ۱۰۰ کیلوبایت داده لاگ در روز (۳ تا ۴ هزار ورودی) جمعآوری میکنیم، اما این رقم با افزایش سطح جزئیات و اضافه شدن رویدادهای جدید، به تدریج در حال افزایش است. به علاوه، گاهی اوقات افزایش ناگهانی وجود دارد (به عنوان مثال، وقتی یک حسگر شروع به ارسال اسپم با نتایج مثبت کاذب به ما میکند). ما ۱۰،۰۰۰ ورودی ۱۰۰ بایتی را محاسبه خواهیم کرد - یک مگابایت در روز.
در مجموع ۵ مگابایت دادهی تمیز (به خوبی فشردهشده) است. و بعد ... (تخمین تقریبی) ۱ مگابایت داده سرویس.
این یعنی ما به یک تراشه ۸ مگابایتی بدون فشردهسازی یا ۴ مگابایت با فشردهسازی نیاز داریم. این ارقام برای این نوع حافظه کاملاً واقعبینانه هستند.
در مورد منبع: اگر برنامه ریزی کنیم که حافظه بیش از هر 5 روز یک بار به طور کامل بازنویسی نشود، در طول 10 سال خدمت، کمتر از هزار چرخه بازنویسی دریافت میکنیم.
بگذارید یادآوری کنم که سازنده قول صد هزار را داده است.
کمی درباره NOR در مقابل NAND
حافظه NAND مطمئناً این روزها محبوبتر است، اما من از آن برای این پروژه استفاده نمیکنم: NAND، برخلاف NOR، به کدهای تصحیح خطا، جداول بلوک خراب و غیره نیاز دارد و تراشههای NAND معمولاً پینهای بیشتری دارند.
معایب NOR عبارتند از:
- حجم کم (و بر این اساس، قیمت بالا برای هر مگابایت)؛
- سرعت تبادل پایین (عمدتاً به دلیل استفاده از رابط سریال، معمولاً SPI یا I2C)؛
- پاک کردن آهسته (بسته به اندازه بلوک، از کسری از ثانیه تا چند ثانیه طول میکشد).
به نظر میرسد که هیچ چیز مهمی برای ما وجود ندارد، بنابراین ادامه میدهیم.
اگر به جزئیات علاقه دارید، یک ریزگرد انتخاب شد (با این حال، این مهم نیست؛ کلی تراشه مشابه در بازار وجود دارد که از نظر پینآوت و سیستم فرمان با هم سازگار هستند؛ حتی اگر بخواهیم تراشهای از سازندهی متفاوت و/یا با ظرفیت متفاوت نصب کنیم، همه چیز بدون تغییر کد کار خواهد کرد).
من از روشی که توی هسته تعبیه شده استفاده میکنم Linux درایور، در رزبری پای، به لطف پشتیبانی از پوشش درخت دستگاه، همه چیز بسیار ساده است - شما باید پوشش کامپایل شده را در /boot/overlays قرار دهید و /boot/config.txt را کمی تغییر دهید.
نمونهای از یک فایل dts
راستش را بخواهید، مطمئن نیستم که بدون خطا نوشته شده باشد، اما کار میکند.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};و یک خط دیگر در config.txt
dtoverlay=at25:spimaxfrequency=50000000از اتصال واقعی بین تراشه و رزبری پای صرف نظر میکنم. از یک طرف، من متخصص الکترونیک نیستم، اما از طرف دیگر، همه چیز حتی برای من هم نسبتاً سرراست است: تراشه فقط ۸ پین دارد که از بین آنها به زمین، تغذیه و SPI (CS، SI، SO، SCK) نیاز داریم. سطوح ولتاژ مشابه رزبری پای هستند و هیچ سیمکشی اضافی لازم نیست - فقط شش پین مشخص شده را وصل کنید.
بیانیه مشکل
طبق معمول، صورت مسئله چندین بار تکرار میشود و فکر میکنم وقت آن رسیده که دوباره آن را تکرار کنیم. پس بیایید مکث کنیم، آنچه را که قبلاً نوشته شده است جمعبندی کنیم و جزئیات مبهم باقیمانده را روشن کنیم.
بنابراین، ما تصمیم گرفتیم که گزارش در SPI و نه در فلش ذخیره شود.
برای کسانی که نمیدانند NOR Flash چیست؟
این یک حافظه غیرفرار است که میتواند برای سه عملیات مورد استفاده قرار گیرد:
- خواندن:
رایجترین روش خواندن: ما آدرس را ارسال میکنیم و هر تعداد بایت مورد نیاز را میخوانیم؛ - رکورد:
نوشتن در فلش NOR یک عملیات معمولی به نظر میرسد، اما یک ویژگی خاص دارد: شما فقط میتوانید ۱ را به ۰ تبدیل کنید، اما عکس این قضیه ممکن نیست. برای مثال، اگر در یک سلول حافظه ۰x۵۵ داشته باشیم، پس از نوشتن ۰x۰f در آن، اکنون شامل ۰x۰۵ خواهد بود. (به جدول زیر مراجعه کنید); - پاک کردن:
البته، ما باید بتوانیم عملیات معکوس را نیز انجام دهیم - تبدیل 0 به 1. این دقیقاً همان کاری است که عملیات پاک کردن انجام میدهد. برخلاف دو مورد اول، این عملیات به جای بایتها، روی بلوکها عمل میکند (حداقل بلوک پاک کردن در تراشه انتخاب شده 4 کیلوبایت است). پاک کردن کل بلوک را از بین میبرد و این تنها راه برای تغییر 0 به 1 است. بنابراین، هنگام کار با حافظه فلش، اغلب لازم است ساختارهای داده را با مرز بلوک پاک کردن همتراز کنیم.
نوشتن در فلش NOR:
دادههای دودویی
بود
01010101
ضبط شده
00001111
تبدیل شده است
00000101
خودِ لاگ، دنبالهای از رکوردهای با طول متغیر است. طول معمول یک رکورد حدود ۳۰ بایت است (اگرچه گاهی اوقات رکوردهایی با طول چندین کیلوبایت نیز یافت میشوند). در این حالت، ما فقط با آنها به عنوان مجموعهای از بایتها کار میکنیم، اما اگر علاقهمند باشید، CBOR درون رکوردها استفاده میشود.
علاوه بر گزارش، ما باید برخی اطلاعات «پیکربندی» را نیز ذخیره کنیم، چه بهروزرسانیشده و چه نشده: یک شناسه دستگاه خاص، کالیبراسیون حسگرها، پرچم «دستگاه موقتاً غیرفعال است» و غیره.
این اطلاعات مجموعهای از رکوردهای کلید-مقدار است که در CBOR ذخیره میشوند. ما مقدار زیادی از این اطلاعات را نداریم (حداکثر چند کیلوبایت) و به ندرت بهروزرسانی میشوند.
در آینده آن را زمینه (context) خواهیم نامید.
اگر به یاد داشته باشیم که این مقاله چگونه آغاز شد، بسیار مهم است که از ذخیرهسازی مطمئن دادهها و در صورت امکان، عملکرد بدون وقفه حتی در صورت خرابی سختافزار/خرابی دادهها اطمینان حاصل شود.
چه منابعی را میتوان برای مشکلات در نظر گرفت؟
- قطع برق در حین عملیات نوشتن/پاک کردن. این نمونهای از «عدم دفاع در برابر دیلم» است.
اطلاعات از در stackexchange: وقتی هنگام کار با فلش، برق خاموش میشود، هم پاک کردن (تنظیم روی ۱) و هم نوشتن (تنظیم روی ۰) منجر به رفتار نامشخصی میشوند: دادهها میتوانند نوشته شوند، یا تا حدی نوشته شوند (مثلاً ما ۱۰ بایت/۸۰ بیت منتقل کردیم، اما فقط ۴۵ بیت نوشته شد)، همچنین ممکن است برخی از بیتها در حالت "میانی" قرار گیرند (خواندن میتواند ۰ یا ۱ تولید کند)؛ - خطاها در خود حافظه فلش.
BER، اگرچه بسیار پایین است، اما نمیتواند برابر با صفر باشد؛ - خطاهای گذرگاه
دادههای منتقلشده از طریق SPI به هیچ وجه محافظت نمیشوند؛ خطاهای تک بیتی و خطاهای همگامسازی - از دست دادن یا درج بیتها (که منجر به تخریب گسترده دادهها میشود) - ممکن است رخ دهند. - سایر خطاها/اشکالات
خطاهای کد، اشکالات تمشک، مداخله موجودات فضایی...
من الزاماتی را تدوین کردهام که به نظر من برای اطمینان از قابلیت اطمینان باید رعایت شوند:
- رکوردها باید بلافاصله روی حافظه فلش نوشته شوند، تأخیر در نوشتن در نظر گرفته نمیشود؛ - اگر خطایی رخ دهد، باید در اسرع وقت شناسایی و پردازش شود؛ - سیستم باید در صورت امکان، خطاها را بازیابی کند.
(مثالی از زندگی واقعی که «نباید اینطور باشد»، که فکر میکنم همه با آن مواجه شدهاند: پس از راهاندازی مجدد اضطراری، سیستم فایل «خراب» میشود و سیستم عامل بوت نمیشود)
ایدهها، رویکردها، تأملات
وقتی شروع به فکر کردن در مورد این مشکل کردم، کلی ایده از ذهنم گذشت، مثلاً:
- از فشردهسازی دادهها استفاده کنید؛
- از ساختارهای داده هوشمندانه استفاده کنید، مانند ذخیره جداگانه سرآیندهای رکوردها از خود رکوردها، به طوری که اگر در یک رکورد خطایی رخ دهد، بقیه رکوردها بدون هیچ مشکلی قابل خواندن باشند.
- استفاده از فیلدهای بیتی برای کنترل تکمیل نوشتن هنگام خاموش شدن دستگاه؛
- جمعهای کنترلی را برای همه چیز و همه کس ذخیره کنید؛
- از نوعی کدگذاری تصحیح خطا استفاده کنید.
برخی از این ایدهها مورد استفاده قرار گرفتند و برخی دیگر کنار گذاشته شدند. بیایید آنها را به ترتیب بررسی کنیم.
متراکم سازی داده ها
رویدادهایی که ما در گزارش ثبت میکنیم نسبتاً یکنواخت و تکرارپذیر هستند (مثلاً «پرتاب یک سکه ۵ روبلی»، «فشار دادن دکمه تغییر» و غیره). بنابراین، فشردهسازی باید کاملاً مؤثر باشد.
سربار فشردهسازی ناچیز است (پردازنده ما بسیار قدرتمند است؛ حتی رزبری پای اصلی یک هسته ۷۰۰ مگاهرتزی داشت، در حالی که مدلهای فعلی دارای چندین هسته با سرعت بیش از یک گیگاهرتز هستند)، نرخ انتقال ذخیرهسازی پایین است (چند مگابایت در ثانیه) و اندازه رکورد کوچک است. در کل، اگر فشردهسازی تأثیری بر عملکرد داشته باشد، فقط مثبت خواهد بود. (کاملاً بیطرف، فقط دارم میگم)بعلاوه، ما یک دستگاه جاسازیشدهی واقعی نداریم، بلکه یک دستگاه معمولی داریم. Linux — بنابراین پیادهسازی نباید به تلاش زیادی نیاز داشته باشد (کافی است فقط کتابخانه را لینک کنید و از چند تابع آن استفاده کنید).
یک قطعه داده لاگ از یک دستگاه در حال کار (۱.۷ مگابایت، ۷۰ هزار ورودی) گرفته شد و ابتدا قابلیت فشردهسازی آن با استفاده از gzip، lz4، lzop، bzip2، xz، zstd موجود در رایانه بررسی شد.
- gzip، xz، zstd نتایج مشابهی را نشان دادند (40 کیلوبایت).
من تعجب کردم که xz مد روز اینجا در سطح gzip یا zstd خودش را نشان داد؛ - lzip با تنظیمات پیشفرض نتایج کمی بدتری داد؛
- lz4 و lzop نتایج خیلی خوبی نشان ندادند (۱۵۰ کیلوبایت)؛
- bzip2 نتیجهی شگفتانگیز خوبی (۱۸ کیلوبایت) نشان داد.
بنابراین دادهها خیلی خوب فشرده میشوند.
بنابراین (مگر اینکه نقصهای اساسی پیدا کنیم)، فشردهسازی یک امر ضروری خواهد بود! صرفاً به این دلیل که همان فلش درایو، دادههای بیشتری را در خود جای خواهد داد.
بیایید به معایبش فکر کنیم.
مشکل اول: ما قبلاً توافق کردهایم که هر نوشتن باید بلافاصله در فلش نوشته شود. معمولاً، یک بایگانیکننده دادهها را از جریان ورودی جمعآوری میکند تا زمانی که تصمیم بگیرد زمان نوشتن در جریان خروجی فرا رسیده است. ما باید فوراً یک بلوک فشرده از دادهها را دریافت کرده و آن را در حافظه غیرفرار ذخیره کنیم.
من سه راه میبینم:
- به جای الگوریتمهای مورد بحث در بالا، هر رکورد را با استفاده از فشردهسازی دیکشنری فشرده کنید.
این یک گزینه کاملاً مناسب است، اما من آن را دوست ندارم. برای دستیابی به سطح فشردهسازی مناسب، فرهنگ لغت باید متناسب با دادههای خاص تنظیم شود؛ هرگونه تغییر منجر به افت فاجعهبار فشردهسازی خواهد شد. بله، ایجاد یک نسخه جدید از فرهنگ لغت مشکل را حل میکند، اما این یک سردرد واقعی است - ما باید تمام نسخههای فرهنگ لغت را ذخیره کنیم؛ هر ورودی باید نشان دهد که با کدام نسخه فرهنگ لغت فشرده شده است... - فشردهسازی هر رکورد با استفاده از الگوریتمهای «کلاسیک»، اما مستقل از الگوریتمهای دیگر.
الگوریتمهای فشردهسازی مورد بررسی برای کار با رکوردهایی با این اندازه (دهها بایت) طراحی نشدهاند؛ نسبت فشردهسازی به وضوح کمتر از ۱ خواهد بود (یعنی افزایش حجم دادهها به جای فشردهسازی)؛ - بعد از هر بار ورود، یک بار فلاش (FLUSH) انجام دهید.
بسیاری از کتابخانههای فشردهسازی از FLUSH پشتیبانی میکنند. این یک دستور (یا پارامتر برای رویه فشردهسازی) است که پس از دریافت، بایگانیکننده یک جریان فشرده ایجاد میکند تا بتوان از آن برای بازیابی استفاده کرد. همه دادههای فشرده نشدهای که قبلاً دریافت شدهاند. این آنالوگsyncدر سیستم های فایل یاcommitدر SQL.
مهم این است که عملیات فشردهسازی بعدی بتوانند از دیکشنری انباشتهشده استفاده کنند و نسبت فشردهسازی به اندازه نسخه قبلی آسیب نبیند.
فکر میکنم واضح است که من گزینه سوم را انتخاب کردم، بیایید با جزئیات بیشتری به آن نگاه کنیم.
پیدا شد درباره FLUSH در zlib.
من بر اساس مقاله، یک آزمایش بدون فکر انجام دادم و ۷۰،۰۰۰ ورودی لاگ را از یک دستگاه واقعی با اندازه صفحه ۶۰ کیلوبایت گرفتم. (بعداً به اندازه صفحه برمیگردیم) دریافت شده:
داده های خام
فشردهسازی Gzip -9 (بدون FLUSH)
zlib با Z_PARTIAL_FLUSH
zlib با Z_SYNC_FLUSH
حجم، کیلوبایت
1692
40
352
604
در نگاه اول، هزینه FLUSH گزاف به نظر میرسد، اما در واقعیت، ما انتخابهای محدودی داریم: یا اصلاً فشردهسازی انجام نمیشود، یا فشردهسازی (و کاملاً مؤثر) با FLUSH انجام میشود. به خاطر داشته باشید که ما ۷۰،۰۰۰ رکورد داریم و افزونگی معرفی شده توسط Z_PARTIAL_FLUSH فقط ۴-۵ بایت در هر رکورد است. و نسبت فشردهسازی تقریباً ۵:۱ شد که بیش از عالی است.
شاید تعجبآور به نظر برسد، اما Z_SYNC_FLUSH در واقع روشی کارآمدتر برای انجام FLUSH است.
هنگام استفاده از Z_SYNC_FLUSH، چهار بایت آخر هر رکورد همیشه 0x00، 0x00، 0xff، 0xff خواهد بود. اگر این مقادیر را بدانیم، نیازی به ذخیره آنها نداریم، بنابراین اندازه نهایی فقط 324 کیلوبایت است.
مقالهای که لینکش را گذاشتم، این موضوع را توضیح میدهد:
یک بلوک جدید از نوع ۰ با محتوای خالی اضافه میشود.
یک بلوک نوع ۰ با محتوای خالی شامل موارد زیر است:
- هدر بلوک سه بیتی؛
- ۰ تا ۷ بیت برابر با صفر، برای دستیابی به ترازبندی بایتها؛
- دنباله چهار بایتی ۰۰ ۰۰ FF FF.
همانطور که میبینید، در آخرین بلوک، بین ۳ تا ۱۰ بیت صفر قبل از این ۴ بایت وجود دارد. با این حال، تجربه نشان داده است که در واقع حداقل ۱۰ بیت صفر وجود دارد.
معلوم میشود که چنین بلوکهای کوتاهی از دادهها معمولاً (همیشه؟) با استفاده از یک بلوک از نوع ۱ (بلوک ثابت) کدگذاری میشوند، که همیشه با ۷ بیت صفر به پایان میرسد و در نتیجه ۱۰ تا ۱۷ بیت صفر تضمینشده وجود دارد (و بقیه با احتمال حدود ۵۰٪ صفر خواهند بود).
بنابراین، در دادههای آزمایشی، در ۱۰۰٪ موارد، قبل از 0x00، 0x00، 0xff، 0xff یک بایت صفر وجود دارد و در بیش از یک سوم موارد، دو بایت صفر وجود دارد. (شاید مشکل این است که من از CBOR دودویی استفاده میکنم، و اگر از JSON متنی استفاده میکردم، بیشتر با بلوکهای نوع ۲ - بلوک پویا - مواجه میشدم، و بنابراین با بلوکهایی بدون بایت صفر اضافی قبل از 0x00، 0x00، 0xff، 0xff مواجه میشدم).
در مجموع، با استفاده از دادههای آزمایشی موجود، میتوان دادهها را در کمتر از ۲۵۰ کیلوبایت داده فشردهشده جای داد.
میتوانیم با کمی دستکاری در بیتها، کمی بیشتر صرفهجویی کنیم: حالا از وجود چند بیت صفر در انتهای یک بلوک صرف نظر میکنیم و چند بیت در ابتدای یک بلوک نیز بدون تغییر باقی میمانند...
اما اینجا تصمیم قاطعانهای گرفتم که دیگر این کار را نکنم، وگرنه با این سرعت ممکن بود در نهایت آرشیو خودم را بسازم.
در مجموع، من از دادههای آزمایشیام ۳-۴ بایت به ازای هر رکورد دریافت کردم که منجر به نسبت فشردهسازی بیش از ۶:۱ شد. راستش را بخواهید، انتظار چنین نتیجهای را نداشتم؛ به نظر من، هر چیزی بهتر از ۲:۱، خود به خود نتیجهای است که استفاده از فشردهسازی را توجیه میکند.
همه چیز عالی است، اما zlib (deflate) هنوز یک الگوریتم فشردهسازی قدیمی، شایسته و تا حدودی قدیمی است. این واقعیت که از ۳۲ کیلوبایت آخر جریان داده فشرده نشده به عنوان یک دیکشنری استفاده میکند، امروزه عجیب به نظر میرسد (یعنی اگر یک بلوک داده بسیار شبیه به چیزی باشد که در جریان ورودی ۴۰ کیلوبایت قبل بوده است، به جای ارجاع به ورودی قبلی، دوباره شروع به فشردهسازی میکند). در بایگانیهای مدرن، اندازه دیکشنری اغلب بر حسب مگابایت اندازهگیری میشود نه کیلوبایت.
بنابراین، بیایید به تحقیقات کوچک خود در مورد بایگانیکنندگان ادامه دهیم.
سپس، bzip2 را امتحان کردم (به یاد داشته باشید، بدون FLUSH، نسبت فشردهسازی فوقالعادهای، تقریباً ۱۰۰:۱، نشان میداد.) متأسفانه، با FLUSH، عملکرد بسیار ضعیفی داشت؛ دادههای فشردهشده در نهایت بزرگتر از دادههای فشردهنشده شدند.
حدسهای من در مورد دلایل شکست
Libbz2 فقط یک گزینه flush ارائه میدهد که به نظر میرسد دیکشنری را پاک میکند (مشابه Z_FULL_FLUSH در zlib)، بنابراین صحبت در مورد فشردهسازی مؤثر پس از آن بیفایده است.
و در آخر، zstd را امتحان کردم. بسته به پارامترها، یا در سطح gzip فشردهسازی میکند، اما خیلی سریعتر، یا بهتر از gzip.
متأسفانه، با FLUSH هم خیلی خوب عمل نکرد: اندازه داده فشرده شده حدود ۷۰۰ کیلوبایت بود.
Я در صفحه گیتهاب پروژه، پاسخی دریافت کردم مبنی بر اینکه باید انتظار داشت برای هر بلوک داده فشردهشده، تا ۱۰ بایت داده سرویس وجود داشته باشد، که نزدیک به نتایج بهدستآمده است؛ رسیدن به deflate امکانپذیر نخواهد بود.
در این مرحله، تصمیم گرفتم آزمایش با بایگانیکنندهها را متوقف کنم (یادآوری میکنم که xz، lzip، lzo و lz4 حتی در مرحله آزمایش بدون FLUSH ارزش خود را نشان ندادند و من الگوریتمهای فشردهسازی عجیب و غریبتر را در نظر نگرفتم).
برگردیم به مشکلات بایگانی.
مشکل دوم (همانطور که به ترتیب ذکر شد، نه از نظر اهمیت) این است که دادههای فشردهشده یک جریان واحد هستند که دائماً به بخشهای قبلی ارجاع میدهند. بنابراین، اگر بخشی از دادههای فشردهشده آسیب ببیند، نه تنها بلوک دادههای فشردهنشده مرتبط، بلکه تمام بلوکهای بعدی را نیز از دست میدهیم.
برای حل این مشکل، رویکردهایی وجود دارد:
- جلوگیری از بروز مشکلات به معنای افزودن افزونگی به دادههای فشردهشده است تا امکان شناسایی و اصلاح خطاها فراهم شود؛ بعداً در مورد این موضوع بحث خواهیم کرد.
- در صورت بروز مشکل، عواقب آن را به حداقل برسانید
قبلاً اشاره کردیم که هر بلوک داده میتواند به طور مستقل فشرده شود، که این امر مشکل را برطرف میکند (خرابی دادهها در یک بلوک فقط منجر به از دست رفتن آن بلوک میشود). با این حال، این یک حالت افراطی است که فشردهسازی دادهها را بیاثر میکند. حالت افراطی مخالف: استفاده از تمام ۴ مگابایت تراشه ما به عنوان یک بایگانی واحد، که فشردهسازی عالی را فراهم میکند اما در صورت بروز خرابی دادهها، عواقب فاجعهباری خواهد داشت.
بله، از نظر قابلیت اطمینان، به یک مصالحه نیاز است. اما باید به خاطر داشته باشیم که ما در حال توسعه یک قالب ذخیرهسازی داده برای حافظه غیرفرار با نرخ خطای بسیار پایین (BER) و مدت زمان نگهداری داده اعلام شده ۲۰ ساله هستیم.
در طول آزمایشهایم، متوجه شدم که افت کم و بیش محسوس در سطح فشردهسازی، از بلوکهای دادههای فشردهشده با اندازه کمتر از ۱۰ کیلوبایت شروع میشود.
قبلاً اشاره شد که حافظه مورد استفاده مبتنی بر صفحه است، من هیچ دلیلی نمیبینم که چرا نباید از نگاشت «یک صفحه - یک بلوک از دادههای فشرده» استفاده کنید.
این بدان معناست که حداقل اندازه معقول صفحه ۱۶ کیلوبایت است (با احتساب مقداری هزینه سربار). با این حال، چنین اندازه صفحه کوچکی محدودیتهای قابل توجهی را در حداکثر اندازه رکورد ایجاد میکند.
اگرچه انتظار ندارم رکوردهایی بزرگتر از چند کیلوبایت به صورت فشرده داشته باشم، تصمیم گرفتم از صفحات ۳۲ کیلوبایتی استفاده کنم (که به ازای هر تراشه ۱۲۸ صفحه میدهد).
خلاصه:
- ما دادهها را با استفاده از zlib (deflate) فشردهسازی میکنیم؛
- برای هر ورودی، Z_SYNC_FLUSH را تنظیم میکنیم؛
- برای هر رکورد فشردهشده، بایتهای انتهایی را حذف میکنیم. (برای مثال، 0x00، 0x00، 0xff، 0xff)در سربرگ مشخص میکنیم که چند بایت را حذف کردهایم؛
- ما دادهها را در صفحات ۳۲ کیلوبایتی ذخیره میکنیم؛ در هر صفحه، یک جریان واحد از دادههای فشردهشده وجود دارد؛ فشردهسازی در هر صفحه مجدداً آغاز میشود.
و قبل از اینکه فشردهسازی را تمام کنیم، میخواهم به این نکته اشاره کنم که ما فقط چند بایت داده فشردهشده در هر رکورد دریافت میکنیم، بنابراین بسیار مهم است که اطلاعات سرویس را بیش از حد بزرگ نکنیم؛ هر بایت در اینجا مهم است.
ذخیره هدرهای داده
از آنجایی که رکوردهایی با طول متغیر داریم، باید به نحوی محل قرارگیری/مرزهای رکوردها را تعیین کنیم.
من سه رویکرد را میشناسم:
- تمام رکوردها در یک جریان پیوسته ذخیره میشوند، ابتدا سرآیند رکورد حاوی طول آن و سپس خود رکورد قرار میگیرد.
در این نوع، هم هدرها و هم دادهها میتوانند طول متغیری داشته باشند.
اساساً، ما یک لیست پیوندی منفرد دریافت میکنیم که همیشه مورد استفاده قرار میگیرد؛ - خودِ هدرها و رکوردها در جریانهای جداگانهای ذخیره میشوند.
با استفاده از هدرهای با طول ثابت، اطمینان حاصل میکنیم که خرابی یک هدر، هدرهای دیگر را تحت تأثیر قرار نمیدهد.
برای مثال، در بسیاری از سیستمهای فایل، از رویکرد مشابهی استفاده میشود؛ - رکوردها در یک جریان پیوسته ذخیره میشوند، با مرز رکورد که توسط یک نشانگر (یک کاراکتر یا دنباله ای از کاراکترها که در بلوکهای داده ممنوع است) تعریف میشود. اگر در یک رکورد با یک نشانگر مواجه شویم، آن را با یک دنباله خاص جایگزین میکنیم (از آن صرف نظر میکنیم).
برای مثال، در پروتکل PPP از رویکرد مشابهی استفاده میشود.
بگذارید مثال بزنم.
1 گزینه:

همه چیز بسیار ساده است: با دانستن طول رکورد، میتوانیم آدرس سرصفحه بعدی را محاسبه کنیم. ما در سرصفحهها حرکت میکنیم تا زمانی که به ناحیهای پر از 0xff (فضای خالی) یا انتهای صفحه برسیم.
2 گزینه:

به دلیل طول متغیر رکورد، نمیتوانیم پیشبینی کنیم که در هر صفحه به چند رکورد (و بنابراین سرصفحه) نیاز داریم. میتوانیم سرصفحهها و دادهها را در صفحات مختلف تقسیم کنیم، اما من رویکرد متفاوتی را ترجیح میدهم: هم سرصفحه و هم دادهها را در یک صفحه قرار میدهیم، اما سرصفحهها (با طول ثابت) از بالای صفحه شروع میشوند و دادهها (با طول متغیر) از پایین شروع میشوند. به محض اینکه آنها "به هم میرسند" (فضای کافی برای یک رکورد جدید وجود ندارد)، صفحه را پر شده در نظر میگیریم.
3 گزینه:

نیازی به ذخیره طول یا سایر اطلاعات مکان دادهها در سرآیند نیست؛ نشانگرهایی که مرزهای رکورد را نشان میدهند کافی هستند. با این حال، دادهها باید هنگام نوشتن/خواندن پردازش شوند.
من از 0xff (که همان چیزی است که صفحه پس از پاک کردن با آن پر میشود) به عنوان نشانگر استفاده میکنم، به طوری که ناحیه خالی قطعاً به عنوان داده در نظر گرفته نشود.
جدول مقایسه:
گزینه 1
گزینه 2
گزینه 3
تحمل خطا
-
+
+
فشردگی
+
-
+
پیچیدگی پیاده سازی
*
**
**
گزینه ۱ یک نقص اساسی دارد: اگر هر هدر آسیب ببیند، کل زنجیره بعدی از بین میرود. گزینههای دیگر حتی در صورت آسیب گسترده، امکان بازیابی جزئی دادهها را فراهم میکنند.
اما در اینجا مناسب است به یاد داشته باشیم که ما تصمیم گرفتیم دادهها را به صورت فشرده ذخیره کنیم و به هر حال پس از یک رکورد «خراب»، تمام دادههای موجود در صفحه را از دست میدهیم، بنابراین حتی اگر یک منفی در جدول وجود داشته باشد، آن را در نظر نمیگیریم.
فشردگی:
- در گزینه اول، فقط باید طول را در هدر ذخیره کنیم؛ اگر از اعداد صحیح با طول متغیر استفاده کنیم، در بیشتر موارد میتوانیم با یک بایت کار کنیم؛
- در گزینه دوم، باید آدرس شروع و طول را ذخیره کنیم؛ رکورد باید اندازه ثابتی داشته باشد، من تخمین میزنم ۴ بایت برای هر رکورد (دو بایت برای آفست و دو بایت برای طول)؛
- گزینه سوم فقط به یک کاراکتر برای نشان دادن شروع یک رکورد نیاز دارد، به علاوه خود رکورد به دلیل escape کردن، ۱-۲٪ افزایش حجم خواهد داشت. در کل، تقریباً با گزینه اول برابری میکند.
در ابتدا، گزینه دوم را به عنوان گزینه اصلی در نظر گرفتم (و حتی یک پیادهسازی هم نوشتم). تنها زمانی آن را کنار گذاشتم که در نهایت تصمیم گرفتم از فشردهسازی استفاده کنم.
شاید روزی از گزینه مشابهی استفاده کنم. برای مثال، اگر مجبور باشم دادههای یک فضاپیما را که بین زمین و مریخ در حال سفر است ذخیره کنم - الزامات قابلیت اطمینان کاملاً متفاوت، تشعشعات کیهانی، ...
در مورد گزینه سوم: من به دلیل پیچیدگی پیادهسازی، دو ستاره به آن دادم، صرفاً به این دلیل که دوست ندارم با escape کردن، تغییر طول در اواسط فرآیند و غیره سر و کله بزنم. بله، ممکن است جانبدارانه عمل کنم، اما باید کد را بنویسم - چرا خودم را مجبور به انجام کاری کنم که دوست ندارم.
خلاصه: ما گزینه ذخیرهسازی به شکل زنجیرههای «سربرگ با طول - دادههای با طول متغیر» را به دلیل کارایی و سهولت پیادهسازی آن انتخاب میکنیم.
استفاده از فیلدهای بیتی برای نظارت بر موفقیت عملیات نوشتن
الان یادم نیست این ایده از کجا به ذهنم رسید، اما چیزی شبیه به این است:
برای هر ورودی، چندین بیت برای ذخیره پرچمها اختصاص میدهیم.
همانطور که قبلاً گفتیم، پس از پاک کردن، تمام بیتها با ۱ پر میشوند و میتوانیم ۱ را به ۰ تغییر دهیم، اما برعکس آن امکانپذیر نیست. بنابراین برای «پرچم تنظیم نشده» از ۱ و برای «پرچم تنظیم شده» از ۰ استفاده میکنیم.
قرار دادن یک رکورد با طول متغیر در فلش میتواند به این شکل باشد:
- پرچم «ضبط طول شروع شد» را تنظیم کنید.
- طول را یادداشت میکنیم؛
- ما پرچم «ضبط دادهها آغاز شده است» را تنظیم کردیم؛
- ما دادهها را مینویسیم؛
- ما پرچم «ضبط پایان یافت» را تنظیم کردیم.
علاوه بر این، یک پرچم «خطایی رخ داده است» خواهیم داشت که در مجموع ۴ پرچم بیتی میشود.
در این حالت، ما دو حالت پایدار داریم: "1111" (ضبط شروع نشده است) و "1000" (ضبط موفقیتآمیز بود). در صورت بروز وقفه غیرمنتظره در فرآیند ضبط، حالتهای میانی را دریافت خواهیم کرد که میتوانیم آنها را تشخیص داده و پردازش کنیم.
این رویکرد جالب است، اما فقط در برابر قطع ناگهانی برق و خرابیهای مشابه محافظت میکند، که البته مهم است، اما این به دور از تنها (و حتی نه اصلیترین) دلیل خرابیهای احتمالی است.
خلاصه: بیایید به دنبال یک راه حل خوب باشیم.
جمع های چک
چکسامها همچنین راهی برای تأیید (با اطمینان معقول) این موضوع ارائه میدهند که ما دقیقاً همان چیزی را که باید نوشته میشد، میخوانیم. و برخلاف فیلدهای بیتی که در بالا مورد بحث قرار گرفت، آنها همیشه کار میکنند.
اگر فهرست منابع بالقوه مشکلاتی که در بالا مورد بحث قرار دادیم را در نظر بگیریم، چکسام قادر به تشخیص خطا صرف نظر از منشأ آن است. (به جز، شاید، برای بیگانگان مخرب - آنها نیز میتوانند مجموع مقابلهای را جعل کنند).
بنابراین اگر هدف ما تأیید صحت دادهها باشد، استفاده از چکسامها ایده بسیار خوبی است.
انتخاب الگوریتم محاسبهی مجموع مقابلهای (CRC) سرراست بود. از یک طرف، خواص ریاضی آن امکان تشخیص ۱۰۰٪ انواع خاصی از خطاها را فراهم میکند؛ از طرف دیگر، روی دادههای تصادفی، این الگوریتم معمولاً احتمال برخوردی را نشان میدهد که خیلی بالاتر از حد نظری نیست.  شاید سریعترین الگوریتم نباشد، یا همیشه الگوریتمی با کمترین برخورد نباشد، اما یک ویژگی بسیار مهم دارد: در آزمایشهایی که با آنها مواجه شدهام، با هیچ الگویی که به وضوح باعث شکست آن شود، مواجه نشدهام. پایداری، ویژگی کلیدی در اینجا است.
شاید سریعترین الگوریتم نباشد، یا همیشه الگوریتمی با کمترین برخورد نباشد، اما یک ویژگی بسیار مهم دارد: در آزمایشهایی که با آنها مواجه شدهام، با هیچ الگویی که به وضوح باعث شکست آن شود، مواجه نشدهام. پایداری، ویژگی کلیدی در اینجا است.
نمونهای از یک مطالعه حجمی: , (لینکها به narod.ru، ببخشید).
با این حال، کار انتخاب یک مجموع مقابلهای کامل نیست؛ CRC یک خانواده کامل از مجموعهای مقابلهای است. ما باید در مورد طول آن تصمیم بگیریم و سپس یک چندجملهای انتخاب کنیم.
انتخاب طول چک سام به آن سادگی که در نگاه اول به نظر میرسد، نیست.
بگذارید مثال بزنم:
بگذارید احتمال خطا را در هر بایت داشته باشیم  و برای محاسبهی میانگین تعداد خطاها در هر میلیون رکورد، به یک جمع کنترلی ایدهآل نیاز داریم:
و برای محاسبهی میانگین تعداد خطاها در هر میلیون رکورد، به یک جمع کنترلی ایدهآل نیاز داریم:
داده، بایت
جمع کنترلی، بایت
خطاهای شناسایی نشده
تشخیصهای خطای کاذب
تعداد کل پاسخهای نادرست
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
به نظر ساده میآید: بر اساس طول دادههایی که محافظت میشوند، طول مجموع مقابلهای را با حداقل تعداد مثبتهای کاذب انتخاب کنید و کار تمام است.
با این حال، چکسامهای کوتاه یک مشکل ایجاد میکنند: اگرچه در تشخیص خطاهای تک بیتی خوب هستند، اما میتوانند با احتمال نسبتاً بالایی، دادههای کاملاً تصادفی را به اشتباه معتبر تشخیص دهند. قبلاً مقالهای در مورد هابر وجود داشت که این موضوع را شرح میداد. .
بنابراین، برای اینکه تطبیق تصادفی مجموع مقابلهای عملاً غیرممکن شود، باید از مجموع مقابلهای ۳۲ بیتی یا بیشتر استفاده شود. (برای طولهای بیشتر از ۶۴ بیت، معمولاً از توابع هش رمزنگاری استفاده میشود).
با وجود این واقعیت که قبلاً نوشتم که باید به هر قیمتی در فضا صرفهجویی کنیم، همچنان از یک چکسام ۳۲ بیتی استفاده خواهیم کرد (۱۶ بیت کافی نیست، احتمال تصادم بیش از ۰.۰۱٪ است؛ و ۲۴ بیت، همانطور که میگویند، نه اینجا هستند و نه آنجا).
ممکن است اینجا یک ایراد مطرح شود: آیا ما واقعاً هنگام انتخاب فشردهسازی، تک تک بایتها را ذخیره کردیم، اما حالا مجبوریم چهار بایت را یکجا از دست بدهیم؟ آیا بهتر نبود فشردهسازی نمیکردیم یا یک چکسام اضافه نمیکردیم؟ البته که نه، فشردهسازی نه. به این معنی نیست، که ما نیازی به بررسی یکپارچگی نداریم.
در مورد انتخاب چندجملهای، ما چرخ را دوباره اختراع نمیکنیم، بلکه CRC-32C که در حال حاضر محبوب است را در نظر میگیریم.
این کد خطاهای ۶ بیتی را روی بستههای تا ۲۲ بایت (احتمالاً رایجترین حالت برای ما)، خطاهای ۴ بیتی را روی بستههای تا ۶۵۵ بایت (که آن هم یک حالت رایج برای ما است)، خطاهای ۲ بیتی یا هر تعداد فرد خطای بیتی را روی بستههای با هر طول معقولی تشخیص میدهد.
اگر کسی به جزئیات علاقه دارد
درباره سی آر سی
بر — شاید متخصص برجسته CRC در کره زمین.
В وجود دارد ، که پارامترهای کمی بهتری برای طول بستههای مرتبط با ما ارائه میدهد، اما من این تفاوت را قابل توجه نمیدانستم و خودم را به اندازه کافی شایسته برای انتخاب کد سفارشی به جای کد استاندارد و خوب تحقیق شده نمیدانستم.
همچنین، از آنجایی که دادههای ما فشرده شدهاند، این سوال مطرح میشود: آیا باید مجموع مقابلهای دادههای فشردهشده یا فشردهنشده را محاسبه کنیم؟
استدلالهایی به نفع محاسبهی مجموع مقابلهای دادههای فشردهنشده:
- در نهایت ما نیاز داریم که یکپارچگی ذخیرهسازی دادهها را بررسی کنیم - بنابراین آن را مستقیماً بررسی میکنیم (در عین حال، خطاهای احتمالی در اجرای فشردهسازی/رفع فشار، آسیبهای ناشی از حافظه بد و غیره بررسی خواهند شد)؛
- الگوریتم deflate در zlib پیادهسازی نسبتاً کاملی دارد و نباید علاوه بر این، اگر با دادههای ورودی «کج» از کار بیفتد، اغلب میتواند به طور مستقل خطاها را در جریان ورودی تشخیص دهد و احتمال کلی عدم تشخیص خطا را کاهش دهد (من آزمایشی را با وارونگی یک بیت در یک رکورد کوتاه انجام دادم، zlib در حدود یک سوم موارد خطا را تشخیص داد).
استدلالهایی علیه محاسبهی مجموع مقابلهای دادههای فشردهنشده:
- CRC به طور خاص برای خطاهای بیتی کمی که برای حافظه فلش معمول است طراحی شده است (یک خطای بیتی در یک جریان فشرده میتواند باعث تغییر عظیمی در جریان خروجی شود، که در آن، صرفاً از لحاظ تئوری، میتوانیم یک تصادم را "بگیریم")؛
- من واقعاً ایدهی وارد کردن دادههای بالقوه خراب به دستگاه رفع فشار را دوست ندارم، ، چگونه واکنش نشان خواهد داد.
در این پروژه، تصمیم گرفتم از رویه رایج ذخیره سازی مجموع مقابلهای دادههای فشرده نشده، فاصله بگیرم.
خلاصه: ما از CRC-32C استفاده میکنیم، و مجموع مقابلهای را از دادههایی که به شکلی که روی فلش نوشته شدهاند (پس از فشردهسازی) محاسبه میکنیم.
افزونگی
البته استفاده از کدگذاری افزونه، از دست رفتن دادهها را از بین نمیبرد؛ با این حال، میتواند به طور قابل توجهی (اغلب با شدت بسیار زیاد) احتمال از دست رفتن جبرانناپذیر دادهها را کاهش دهد.
ما میتوانیم از انواع مختلف افزونگی برای اصلاح خطاها استفاده کنیم.
کدهای همینگ میتوانند خطاهای تک بیتی را اصلاح کنند، کدهای رید-سولومون میتوانند نمادین باشند، چندین کپی از دادهها به همراه چکسامها یا کدگذاری مانند RAID-6 میتوانند به بازیابی دادهها حتی در صورت خرابی گسترده کمک کنند.
در ابتدا، من تمایل داشتم که به طور گسترده از کدگذاری تصحیح خطا استفاده کنم، اما بعد متوجه شدم که ابتدا باید ایدهای از اینکه میخواهیم در برابر چه خطاهایی محافظت کنیم، داشته باشیم و سپس کدگذاری را انتخاب کنیم.
قبلاً اشاره کردیم که خطاها باید در اسرع وقت شناسایی شوند. چه زمانی احتمال مواجهه با خطا وجود دارد؟
- ضبط ناتمام (به دلایلی، برق هنگام ضبط قطع شد، رزبری پای هنگ کرد و غیره)
متأسفانه، در صورت بروز چنین خطایی، تنها گزینه نادیده گرفتن رکوردهای نامعتبر و از دست رفتن دادهها است؛ - خطاهای نوشتن (به دلایلی، چیزی غیر از آنچه نوشته شده بود در حافظه فلش نوشته شده است)
اگر بلافاصله پس از ثبت، یک خوانش آزمایشی انجام دهیم، میتوانیم چنین خطاهایی را فوراً تشخیص دهیم؛ - خرابی دادهها در حافظه هنگام ذخیرهسازی؛
- خطاهای خواندن
برای اصلاح خطا، اگر مجموع بررسی مطابقت ندارد، کافی است خواندن را چندین بار تکرار کنید.
این بدان معناست که فقط خطاهای نوع ۳ (خرابی خودبهخودی دادهها در حین ذخیرهسازی) بدون کدگذاری تصحیح خطا قابل اصلاح نیستند. به نظر میرسد که چنین خطاهایی هنوز بسیار بعید هستند.
خلاصه: تصمیم گرفته شد که از کدگذاری اضافی صرف نظر شود، اما اگر عملکرد نشان دهد که این تصمیم اشتباه است، به بررسی موضوع (با آمار از پیش جمعآوریشده در مورد خرابیها، که به ما امکان میدهد نوع بهینه کدگذاری را انتخاب کنیم) باز خواهیم گشت.
دیگر
البته، قالب مقاله اجازه نمیدهد که هر بخش از قالب توجیه شود. (و من از قبل خسته شدهام)بنابراین، به طور خلاصه به نکاتی که قبلاً به آنها اشاره نشده بود، خواهم پرداخت.
- تصمیم گرفته شد که همه صفحات "برابر" باشند
یعنی هیچ صفحه خاصی با فراداده، جریانهای جداگانه و غیره وجود نخواهد داشت، بلکه در عوض یک جریان واحد وجود دارد که همه صفحات را به نوبت بازنویسی میکند.
این امر تضمین میکند که صفحات به طور یکنواخت ساییده شوند، هیچ نقطهی خرابی وجود نداشته باشد و در عین حال زیبا باشد؛ - فراهم کردن امکان نسخهبندی قالب ضروری است.
قالبی که شماره نسخه در هدر آن نباشد، مضر است!
کافی است فیلدی با یک شماره جادویی خاص (امضا) به سرصفحه صفحه اضافه کنید که نسخه فرمت مورد استفاده را نشان میدهد. (فکر نمیکنم در عمل حتی دوازده تا از آنها وجود داشته باشد); - برای رکوردها (که تعدادشان زیاد است) از یک سرآیند با طول متغیر استفاده کنید و در بیشتر موارد سعی کنید طول آن را ۱ بایت قرار دهید؛
- برای رمزگذاری طول سرآیند و طول بخش کوتاهشدهی رکورد فشردهشده، از کدهای دودویی با طول متغیر استفاده کنید.
خیلی مفید بود. کدهای هافمن. تنها در عرض چند دقیقه، توانستیم کدهای با طول متغیر مورد نیاز را پیدا کنیم.
شرح قالب ذخیرهسازی دادهها
ترتیب بایت
فیلدهای بزرگتر از یک بایت به فرمت big-endian (ترتیب بایت شبکه) ذخیره میشوند، یعنی 0x1234 به صورت 0x12، 0x34 نوشته میشود.
تقسیم بندی به صفحات
تمام حافظههای فلش به صفحاتی با اندازه مساوی تقسیم میشوند.
اندازه پیشفرض صفحه ۳۲ کیلوبایت است، اما نه بیشتر از ۱/۴ کل اندازه تراشه حافظه (برای یک تراشه ۴ مگابایتی، این مقدار به ۱۲۸ صفحه منجر میشود).
هر صفحه دادهها را مستقل از صفحات دیگر ذخیره میکند (یعنی دادههای یک صفحه به دادههای صفحه دیگر ارجاع نمیدهد).
تمام صفحات به ترتیب طبیعی (به ترتیب صعودی آدرسها) شمارهگذاری میشوند و از شماره ۰ شروع میشوند (صفحه صفر از آدرس ۰ شروع میشود، صفحه اول از ۳۲ کیلوبایت، صفحه دوم از ۶۴ کیلوبایت و غیره).
تراشه حافظه به عنوان یک بافر حلقه ای استفاده می شود، یعنی ابتدا ضبط به صفحه شماره ۰ می رود، سپس به صفحه شماره ۱، ...، وقتی آخرین صفحه را پر می کنیم، یک چرخه جدید شروع می شود و ضبط از صفحه صفر ادامه می یابد.
درون صفحه

در ابتدای صفحه، یک هدر صفحه ۴ بایتی ذخیره میشود، سپس یک چکسام هدر (CRC-32C) و در نهایت رکوردها با فرمت «هدر، داده، چکسام» ذخیره میشوند.
سرصفحه (سبز تیره در نمودار) شامل موارد زیر است:
- فیلد دو بایتی Magic Number (همچنین به عنوان نشانگر نسخه فرمت شناخته میشود)
برای نسخه فعلی قالب، به عنوان در نظر گرفته میشود0xed00 ⊕ номер страницы; - شمارنده دو بایتی "نسخه صفحه" (شماره چرخه بازنویسی حافظه).
رکوردهای یک صفحه به صورت فشرده ذخیره میشوند (با استفاده از الگوریتم deflate). تمام رکوردهای یک صفحه در یک جریان واحد فشرده میشوند (با استفاده از یک دیکشنری مشترک)، و فشردهسازی در هر صفحه جدید از نو شروع میشود. این بدان معناست که خارج کردن هر رکورد از حالت فشرده نیاز به تمام رکوردهای قبلی آن صفحه (و فقط همان صفحه) دارد.
هر رکورد با پرچم Z_SYNC_FLUSH فشرده خواهد شد، که در نتیجه، جریان فشرده شده با ۴ بایت 0x00، 0x00، 0xff، 0xff به پایان میرسد، که احتمالاً قبل از آن یک یا دو بایت صفر دیگر نیز وجود دارد.
ما این توالی (با طول ۴، ۵ یا ۶ بایت) را هنگام نوشتن در حافظه فلش نادیده میگیریم.
هدر رکورد ۱، ۲ یا ۳ بایت است و موارد زیر را ذخیره میکند:
- یک بیت (T) که نوع رکورد را نشان میدهد: ۰ - context، ۱ - log؛
- فیلد با طول متغیر (S) از ۱ تا ۷ بیت، که طول سرآیند و «دنبالهای» را که باید برای باز کردن به رکورد اضافه شود، تعریف میکند؛
- طول رکورد (L).
جدول مقادیر S:
S
طول هدر، بایت
بایتهای دور ریخته شده هنگام نوشتن
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
سعی کردم مثال بزنم، اما نمیدانم چقدر واضح بود:
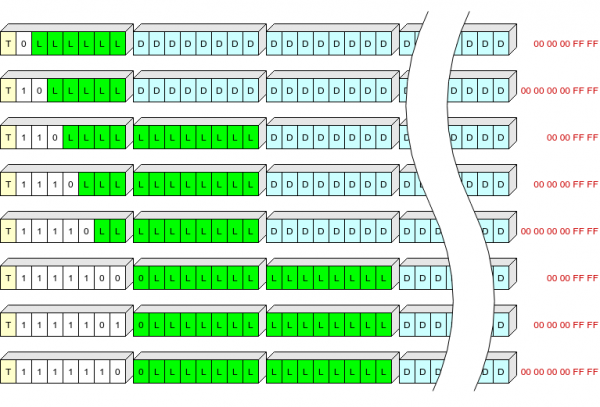
در اینجا فیلد T با رنگ زرد، فیلد S با رنگ سفید، L (طول داده فشرده شده بر حسب بایت) با رنگ سبز، داده فشرده شده با رنگ آبی و بایتهای پایانی داده فشرده شده که در حافظه فلش نوشته نمیشوند با رنگ قرمز مشخص شدهاند.
بنابراین، میتوانیم سرآیند رکوردهایی با رایجترین طول (تا ۶۳+۵ بایت به صورت فشرده) را در یک بایت بنویسیم.
پس از هر بار نوشتن، یک چکسام CRC-32C ذخیره میشود که از مقدار معکوس چکسام قبلی به عنوان مقدار اولیه (init) استفاده میکند.
CRC خاصیت "مدت زمان" را دارد، فرمول زیر کار میکند (به علاوه یا منهای وارونگی بیت در فرآیند):  .
.
یعنی در واقع CRC تمام بایتهای هدر و دادههای قبلی این صفحه را محاسبه میکنیم.
بلافاصله پس از مجموع مقابلهای، سرآیند رکورد بعدی قرار دارد.
هدر به گونهای طراحی شده است که بایت اول آن همیشه با 0x00 و 0xff متفاوت باشد (اگر به جای بایت اول هدر با 0xff مواجه شویم، به این معنی است که این یک ناحیه استفاده نشده است؛ 0x00 خطا را نشان میدهد).
الگوریتمهای تقریبی
خواندن از حافظه فلش
هر خوانشی با بررسی مجموع کنترلی همراه است.
اگر مجموع مقابلهای مطابقت نداشته باشد، خواندن چندین بار تکرار میشود به این امید که در نهایت دادههای صحیح خوانده شوند.
(این منطقی است، Linux خوانشها را از NOR Flash ذخیره نمیکند، تأیید شده است)
نوشتن روی فلش مموری
ما دادهها را یادداشت میکنیم.
بیایید آنها را بخوانیم.
اگر دادههای خوانده شده با دادههای نوشته شده مطابقت نداشته باشند، ناحیه را با صفر پر میکنیم و خطا را اعلام میکنیم.
آماده سازی یک میکرو مدار جدید برای بهره برداری
برای مقداردهی اولیه، یک هدر با نسخه ۱ در صفحه اول (به طور دقیقتر، صفر) نوشته میشود.
پس از این، زمینه اولیه (شامل UUID دستگاه و تنظیمات پیشفرض) در این صفحه نوشته میشود.
کار تمام است، فلش مموری آماده استفاده است.
بارگیری دستگاه
هنگام بارگذاری، ۸ بایت اول هر صفحه (هدر + CRC) خوانده میشود؛ صفحاتی که شماره جادویی ناشناخته یا CRC نامعتبر دارند، نادیده گرفته میشوند.
از بین صفحات «صحیح»، صفحاتی با حداکثر نسخه انتخاب میشوند و از بین آنها، صفحهای که بیشترین تعداد را دارد، انتخاب میشود.
اولین رکورد خوانده میشود، CRC برای صحت بررسی میشود و پرچم "context" بررسی میشود. اگر همه چیز خوب باشد، این صفحه فعلی در نظر گرفته میشود. در غیر این صورت، به صفحه قبلی برمیگردیم تا زمانی که یک صفحه "زنده" پیدا کنیم.
و در صفحه یافت شده، تمام رکوردها را میخوانیم، آنهایی که پرچم «زمینه» را دارند، اعمال میکنیم.
ما دیکشنری zlib را ذخیره میکنیم (برای اضافه کردن به این صفحه مورد نیاز خواهد بود).
همین است، دانلود کامل شد، متن بازیابی شد، میتوانید کار کنید.
افزودن ورودی لاگ
ما رکورد را با دیکشنری صحیح فشرده میکنیم، که Z_SYNC_FLUSH را مشخص میکند. ما بررسی میکنیم که آیا رکورد فشردهشده در صفحه فعلی جا میشود یا خیر.
اگر مناسب نیست (یا خطاهای CRC در صفحه وجود دارد)، یک صفحه جدید شروع کنید (به زیر مراجعه کنید).
ما رکورد و CRC را مینویسیم. اگر خطایی رخ دهد، یک صفحه جدید شروع میکنیم.
صفحه جدید
ما یک صفحه آزاد با کمترین عدد (صفحهای با مجموع مقابلهای نامعتبر در سربرگ یا نسخهای پایینتر از نسخه فعلی را در نظر میگیریم) را به عنوان صفحه آزاد انتخاب میکنیم. اگر چنین صفحاتی وجود نداشته باشد، صفحهای را با کمترین عدد از بین صفحاتی که نسخهای برابر با نسخه فعلی دارند، انتخاب میکنیم.
صفحه انتخاب شده را پاک میکنیم. محتویات را با 0xff بررسی میکنیم. اگر مشکلی وجود داشت، صفحه موجود بعدی را برمیداریم و به همین ترتیب ادامه میدهیم.
ما هدر را برای صفحه پاک شده مینویسیم، اولین ورودی وضعیت فعلی زمینه است و ورودی بعدی ورودی ثبت نشده (در صورت وجود) است.
کاربردپذیری قالب
به نظر من، این فرمت خوبی برای ذخیره هرگونه جریان اطلاعاتی کم و بیش فشردهپذیر (متن ساده، JSON، MessagePack، CBOR، احتمالاً protobuf) در NOR Flash است.
البته، این فرمت برای فلش SLC NOR «تیزتر» شده است.
نباید با رسانههای با BER بالا مانند NAND یا MLC NOR استفاده شود. (آیا این نوع حافظه اصلاً برای فروش موجود است؟ من فقط در مقالات مربوط به کدهای اصلاحی به آن اشاره شده است.).
علاوه بر این، نباید با دستگاههایی که FTL مخصوص به خود را دارند استفاده شود: فلش مموری USB، کارت حافظه SD، کارت حافظه MicroSD و غیره. (برای این نوع حافظه، من یک فرمت با اندازه صفحه ۵۱۲ بایت، یک امضا در ابتدای هر صفحه و شماره رکوردهای منحصر به فرد ایجاد کردم - گاهی اوقات، میتوانستم تمام دادهها را از یک فلش درایو "خراب" با یک خواندن ترتیبی ساده بازیابی کنم).
بسته به کاربرد، این فرمت را میتوان بدون تغییر روی فلش درایوها از ۱۲۸ کیلوبیت بر ثانیه (۱۶ کیلوبیت بر ثانیه) تا ۱ گیگابیت بر ثانیه (۱۲۸ مگابیت بر ثانیه) استفاده کرد. در صورت تمایل، میتوان از آن روی تراشههای با ظرفیت بزرگتر نیز استفاده کرد، اگرچه احتمالاً اندازه صفحه نیاز به تنظیم خواهد داشت. (اما در اینجا مسئله امکانسنجی اقتصادی مطرح میشود؛ قیمت فلش NOR با ظرفیت بالا دلگرمکننده نیست).
اگر کسی این قالب را جالب یافت و خواست از آن در یک پروژه متنباز استفاده کند، به من اطلاع دهد. سعی میکنم وقت پیدا کنم و کد را اصلاح کنم و آن را در گیتهاب منتشر کنم.
نتیجه
همانطور که میبینیم، قالب در نهایت ساده شد. و حتی کسل کننده.
انعکاس سیر تکامل دیدگاه من در یک مقاله دشوار است، اما باور کنید: در ابتدا، میخواستم چیزی پیچیده، فناناپذیر و قادر به تحمل حتی یک انفجار هستهای در نزدیکی خود خلق کنم. با این حال، عقل (امیدوارم) در نهایت غالب شد و به تدریج اولویتها به سمت سادگی و جمع و جور بودن تغییر کرد.
آیا ممکن است اشتباه کنم؟ بله، البته. مثلاً ممکن است ما یک سری میکروچیپ بیکیفیت خریداری کرده باشیم. یا به هر دلیل دیگری، تجهیزات انتظارات مربوط به قابلیت اطمینان را برآورده نمیکنند.
آیا برای این کار برنامهای دارم؟ فکر میکنم بعد از خواندن این مقاله، شکی نخواهید داشت که من دارم. و بیش از یک برنامه.
به طور جدی تر، این قالب هم به عنوان یک گزینه کاری و هم به عنوان یک "بالون آزمایشی" توسعه داده شد.
در حال حاضر، همه چیز روی میز به خوبی کار میکند؛ این راهکار تنها در عرض چند روز مستقر خواهد شد. (تقریباً) روی صد دستگاه، خواهیم دید که در استفاده «جنگی» چه اتفاقی میافتد (خوشبختانه، امیدوارم این قالب امکان تشخیص قابل اعتماد خرابی را فراهم کند، تا بتوانیم آمار جامعی جمعآوری کنیم). ظرف چند ماه، میتوانیم نتیجهگیری کنیم. (و اگر بدشانس باشید، حتی زودتر).
اگر بعد از استفاده، متوجه مشکلات جدی شوم و نیاز به بهبود داشته باشم، حتماً در مورد آن خواهم نوشت.
ادبیات
نمیخواستم یک فهرست طولانی و خستهکننده از منابع تهیه کنم؛ بالاخره همه گوگل دارند.
در اینجا تصمیم گرفتم فهرستی از یافتههایی که برایم جالب بودند را بگذارم، اما به تدریج آنها مستقیماً به متن مقاله منتقل شدند و فقط یک مورد در فهرست باقی ماند:
- سودمندی از نویسندهی zlib. این نرمافزار میتواند محتویات آرشیوهای deflate/zlib/gzip را به وضوح نمایش دهد. اگر نیاز به درک ساختار داخلی فرمت deflate (یا gzip) دارید، اکیداً آن را توصیه میکنم.
منبع: www.habr.com
