

این یک امر بدیهی است که صلاحیت یک مدیر ارشد فناوری (CTO) تنها در دومین باری که این نقش را بر عهده میگیرد، مورد آزمایش قرار میگیرد. اینکه چندین سال برای یک شرکت کار کنید، در کنار آن تکامل پیدا کنید و در عین حال که همچنان در همان زمینه فرهنگی هستید، به تدریج مسئولیتهای بیشتری به دست آورید، یک چیز است و اینکه مستقیماً در شرکتی با میراثی از مشکلات و انبوهی از مسائل که به طور مرتب پنهان شدهاند، مستقیماً وارد نقش مدیر ارشد فناوری شوید، چیز دیگری است.
از این نظر، تجربه لئون فایر، که او در ... به اشتراک گذاشت این دقیقاً منحصر به فرد نیست، اما در ترکیب با تجربه او و تعداد نقشهای مختلفی که در طول 20 سال بر عهده گرفته، بسیار مفید است. در زیر، گاهشماری از وقایع در طول 90 روز و حکایات زیادی آمده است که وقتی برای شخص دیگری اتفاق میافتند، خندیدن به آنها سرگرم کننده است، اما مواجهه حضوری با آنها چندان جالب نیست.
لئون خیلی واضح به زبان روسی صحبت میکند، بنابراین اگر ۳۵ تا ۴۰ دقیقه وقت دارید، تماشای ویدیو را توصیه میکنم. نسخه متنی در زیر آمده است تا در زمان صرفهجویی شود.

نسخه اول گزارش، شرحی ساختارمند از کار با افراد و فرآیندها بود که شامل توصیههای مفیدی میشد. اما تمام شگفتیهای پیشآمده در طول مسیر را در بر نمیگرفت. بنابراین، قالب آن را تغییر دادم و مشکلاتی را که در شرکت جدید پیش میآمد، مانند یک گزارش سرراست، و روشهای رسیدگی به آنها را به ترتیب زمانی ارائه دادم.
یک ماه قبل از
مثل خیلی از داستانهای خوب، این یکی هم با الکل شروع شد. ما با چند تا از دوستانمان در یک بار نشسته بودیم و طبق معمول در محافل فناوری اطلاعات، همه از مشکلاتشان ناله میکردند. یکی از آنها تازه شغلش را عوض کرده بود و داشت از مشکلاتش با فناوری، افراد و تیم برایم میگفت. هر چه بیشتر گوش میدادم، بیشتر متوجه میشدم که باید من را استخدام کند، چون اینها دقیقاً همان نوع مشکلاتی هستند که من در ۱۵ سال گذشته مشغول حل آنها بودهام. این را به او گفتم و روز بعد در یک محیط کاری همدیگر را ملاقات کردیم. اسم شرکت «تدریس استراتژی» بود.
شرکت Teaching Strategies یکی از پیشگامان بازار در زمینه نرمافزارهای آموزشی برای کودکان بسیار خردسال - از بدو تولد تا سه سالگی - است. این شرکت سنتی مبتنی بر کاغذ، ۴۰ سال قدمت دارد، در حالی که نسخه دیجیتال SaaS این پلتفرم ۱۰ سال قدمت دارد. فرآیند تطبیق فناوری دیجیتال با استانداردهای این شرکت نسبتاً اخیراً آغاز شده است. نسخه «جدید» در سال ۲۰۱۷ راهاندازی شد و تقریباً مشابه نسخه قدیمی بود، فقط عملکرد کمتری داشت.
جالبترین نکته این است که ترافیک این شرکت بسیار قابل پیشبینی است - روز به روز، سال به سال، میتوانید به طور دقیق پیشبینی کنید که چند نفر و چه زمانی میآیند. به عنوان مثال، بین ساعت ۱ تا ۳ بعد از ظهر، همه بچههای مهدکودک به رختخواب میروند و معلمان شروع به وارد کردن اطلاعات میکنند. و این اتفاق هر روز به جز آخر هفتهها میافتد، زیرا تقریباً هیچ کس آخر هفتهها کار نمیکند.
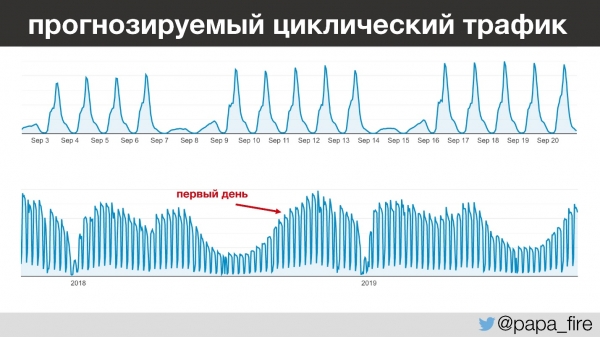
با کمی نگاه به آینده، متوجه میشوم که کارم را در دورهای که بیشترین ترافیک سالانه را داشت، شروع کردم که به دلایل مختلف جالب است.
این پلتفرم که به نظر میرسید فقط دو سال از عمرش میگذرد، یک مجموعهی منحصر به فرد داشت: ColdFusion و SQL Server از سال ۲۰۰۸. ColdFusion، اگر نمیدانید (و احتمالاً نمیدانید)، یک زبان PHP سازمانی است که در اواسط دههی ۹۰ میلادی منتشر شد و من از آن زمان حتی اسم آن را هم نشنیدهام. همچنین Ruby، MySQL، PostgreSQL، Java، Go و Python را داشت. اما هستهی یکپارچهی آن بر روی ColdFusion و SQL Server اجرا میشد.
مشکلات
هر چه بیشتر با کارمندان شرکت در مورد کارشان و چالشهایی که با آن مواجه بودند صحبت میکردم، بیشتر متوجه میشدم که مشکلات فقط فنی نیستند. خب، فناوری قدیمی بود - آنها با فناوریهای بدتری کار کرده بودند، اما مشکلاتی در تیم و فرآیندها وجود داشت و شرکت کمکم داشت این را درک میکرد.
بهطور سنتی، تکنسینهای آنها در گوشهای مینشستند و کار خودشان را انجام میدادند. اما کسبوکارها رفتهرفته به سمت دیجیتالی شدن حرکت کردند. بنابراین، در آخرین سال قبل از شروع کار من در آنجا، شرکت اعضای جدیدی را اضافه کرد: هیئت مدیره، یک مدیر ارشد فناوری، یک مدیر ارشد تولید و یک مدیر تضمین کیفیت. به عبارت دیگر، شرکت شروع به سرمایهگذاری در فناوری کرد.
ردپای یک میراث دشوار فقط در سیستمها نبود. شرکت فرآیندهای قدیمی، افراد قدیمی و فرهنگ قدیمی داشت. همه اینها باید تغییر میکرد. فکر کردم که خستهکننده نخواهد بود، بنابراین تصمیم گرفتم امتحانش کنم.
دو روز قبل از
دو روز قبل از شروع کار جدیدم، به دفتر رسیدم، آخرین مدارک را پر کردم، با تیم ملاقات کردم و متوجه شدم که آنها با مشکلی دست و پنجه نرم میکنند. مشکل این بود که میانگین زمان بارگذاری صفحه به ۴ ثانیه افزایش یافته بود، یعنی دو برابر شده بود.
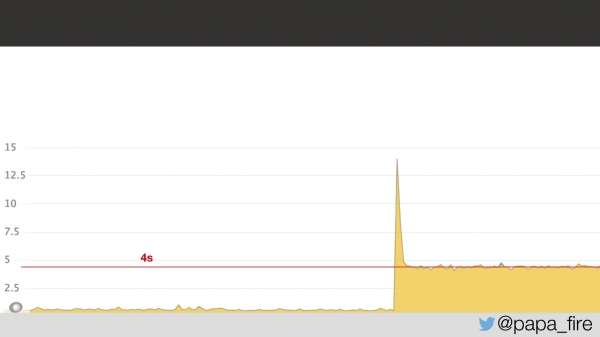
با توجه به نمودار، مشخص بود که مشکلی پیش آمده و مشخص نبود چیست. مشخص شد که مشکل از تأخیر شبکه در مرکز داده است: ۵ میلیثانیه تأخیر در مرکز داده برای کاربران به ۲ ثانیه تبدیل میشد. نمیدانستم چرا این اتفاق افتاده، اما حداقل مشخص شد که مشکل از مرکز داده است.
روز اول
دو روز گذشت و در اولین روز کاریام متوجه شدم که مشکل هنوز حل نشده است.
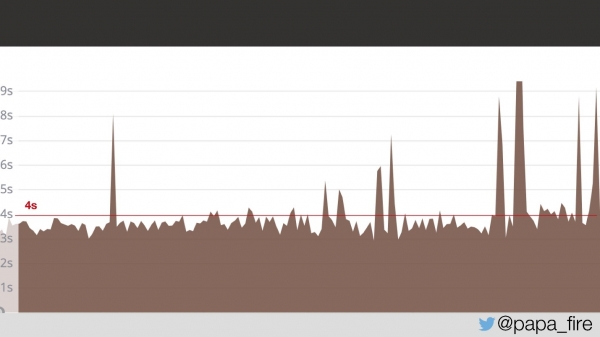
به مدت دو روز، صفحات کاربران به طور متوسط در ۴ ثانیه بارگذاری میشد. از آنها پرسیدم که آیا مشکل را پیدا کردهاند یا خیر.
- بله، ما یک بلیط باز کردیم.
- و؟
- خب، هنوز که به ما جوابی ندادهاند.
اینجا متوجه شدم هر آنچه که قبلاً به من گفته شده بود، تنها نوک کوه یخی بود که باید با آن مبارزه می شد.
یک نقل قول خوب وجود دارد که برای این مورد بسیار مناسب است:
«گاهی اوقات برای تغییر فناوری، باید سازمان را تغییر دهید.»
اما از آنجایی که کارم را در شلوغترین زمان سال شروع کردم، مجبور بودم هم راهحلهای فوری و هم راهحلهای بلندمدت را در نظر بگیرم. و مجبور بودم با چیزی شروع کنم که در حال حاضر حیاتی بود.
سه روز
بنابراین، زمان بارگذاری ۴ ثانیه است و بزرگترین اوج آن از ۱۳ تا ۱۵ ثانیه است.
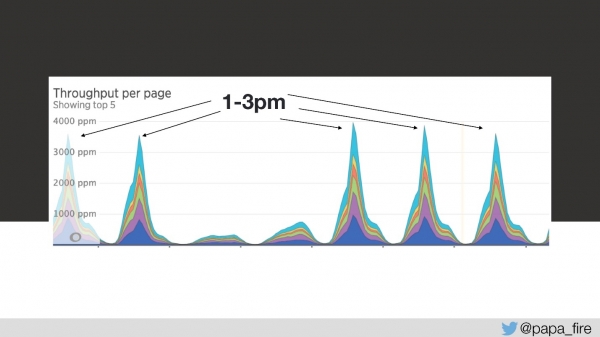
در روز سوم در این بازه زمانی، سرعت دانلود به این شکل بود:
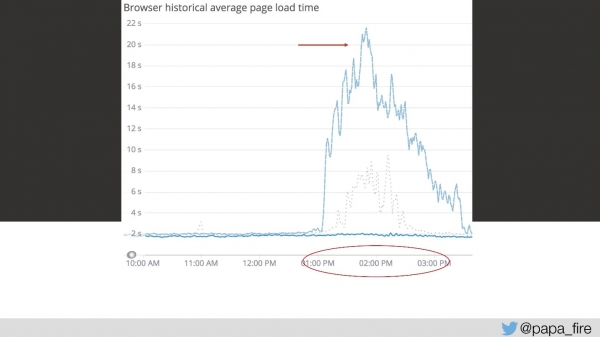
از نظر من، هیچ چیز اصلاً کار نمیکرد. از نظر بقیه، کمی کندتر از حد معمول کار میکرد. اما این اتفاق نمیافتد - این یک مشکل جدی است.
من سعی کردم تیم را متقاعد کنم، اما آنها به من گفتند که به سرورهای بیشتری نیاز دارند. این قطعاً یک راه حل است، اما به هیچ وجه تنها یا مؤثرترین راه حل نیست. پرسیدم که چرا سرورهای کافی وجود ندارد و حجم ترافیک چقدر است. دادهها را برونیابی کردم و متوجه شدم که حدود ۱۵۰ درخواست در ثانیه داریم که عموماً در محدوده معقولی است.
اما نباید فراموش کنیم که قبل از رسیدن به پاسخ درست، باید سوال درست را بپرسیم. سوال بعدی من این بود: چند سرور frontend داریم؟ جواب کمی من را "حیرتزده" کرد - ما 17 سرور frontend داشتیم!
— خجالت میکشم بپرسم، اما ۱۵۰ تقسیم بر ۱۷ میشود حدود ۸؟ منظورتان این است که هر سرور در هر ثانیه ۸ درخواست را پردازش میکند و اگر فردا ۱۶۰ درخواست در ثانیه داشته باشیم، به دو سرور دیگر نیاز خواهیم داشت؟
البته، ما به سرورهای اضافی نیاز نداشتیم. راه حل در خود کد، درست همانجا روی سطح، بود:
var currentClass = classes.getCurrentClass();
return currentClass; یک تابع وجود داشت getCurrentClass()، زیرا همه چیز در سایت در چارچوب کلاس - به درستی - کار میکند. و برای این یک تابع در هر صفحه، بیش از ۲۰۰ درخواست.
بنابراین راه حل بسیار ساده بود، حتی نیازی به بازنویسی چیزی نبود: فقط دوباره همان اطلاعات را درخواست نکنید.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;خیلی خوشحال شدم چون فکر کردم مشکل اصلی را درست روز سوم پیدا کردهام. چقدر سادهلوح بودم، این فقط یکی از مشکلات فراوان بود.
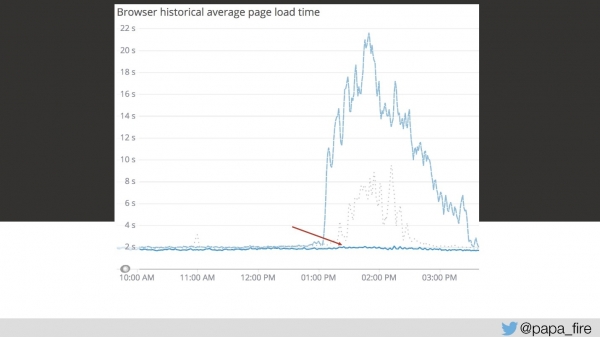
اما حل این مسئله اول، نمودار را بسیار پایینتر آورد.
همزمان، ما روی بهینهسازیهای دیگر کار میکردیم. چیزهای زیادی وجود داشت که میتوانستند فوراً اصلاح شوند. برای مثال، در آن روز سوم، متوجه شدم که سیستم یک حافظه پنهان (cache) دارد (در ابتدا فکر میکردم همه درخواستها مستقیماً از پایگاه داده میآیند). وقتی به حافظه پنهان فکر میکنم، Redis استاندارد یا Memcached را تصور میکنم. اما این فقط نظر من بود، زیرا حافظه پنهان در آن سیستم از MongoDB و SQL Server استفاده میکرد - همان سیستمی که ما دادهها را از آن میخواندیم.
روز دهم
هفته اول را صرف رسیدگی به مسائلی کردم که باید فوراً به آنها رسیدگی میشد. حدود هفته دوم، برای اولین بار به یک جلسه استندآپ رفتم تا با تیم گپ بزنم، ببینم چه خبر است و کل فرآیند چگونه پیش میرود.
دوباره چیز جالبی پیش آمد. تیم شامل ۱۸ توسعهدهنده؛ ۸ آزمایشکننده؛ ۳ مدیر؛ ۲ معمار بود. و همه آنها در مراسم مشترکی شرکت میکردند، به این معنی که بیش از ۳۰ نفر هر روز صبح به جلسه استندآپ میآمدند و در مورد کارهایی که انجام میدادند گزارش میدادند. واضح است که جلسه ۵ یا ۱۵ دقیقه طول نمیکشید. هیچکس به حرف دیگری گوش نمیداد زیرا همه روی سیستمهای مختلفی کار میکردند. در این قالب، ۲-۳ تیکت در ساعت در طول یک جلسه آمادهسازی، خود نتیجه خوبی بود.
اولین کاری که انجام دادیم این بود که تیم را به چندین خط تولید تقسیم کردیم. برای بخشها و سیستمهای مختلف، تیمهای جداگانهای شامل توسعهدهندگان، آزمایشکنندگان، مدیران محصول و تحلیلگران کسبوکار ایجاد کردیم.
نتیجه این شد:
- کاهش تجمعات و راهپیماییهای اعتراضی.
- دانش موضوعی در مورد محصول.
- حس مالکیت. وقتی افراد دائماً بین سیستمها جابجا میشدند، میدانستند که احتمالاً اشکالاتشان توسط شخص دیگری برطرف خواهد شد، نه خودشان.
- همکاری بین تیمها. نیازی به گفتن نیست که تیمهای تضمین کیفیت و برنامهنویسان قبلاً زیاد با هم تعامل نداشتند؛ مدیر محصول کار خودش را میکرد و غیره. حالا آنها یک نقطه مشترک پاسخگویی دارند.
تمرکز اصلی ما روی کارایی، بهرهوری و کیفیت بود - اینها مشکلاتی بودند که ما سعی داشتیم با تغییر تیم حل کنیم.
روز یازدهم
در فرآیند تغییر ساختار تیم، کشف کردم که چگونه محاسبه کنم داستانامتیاز۱ SP معادل یک روز بود، و هر تیکت شامل SP برای توسعه و تضمین کیفیت بود، یعنی حداقل ۲ SP.
چطور این را کشف کردم؟
ما یک اشکال پیدا کردیم: در یکی از گزارشها، جایی که تاریخ شروع و پایان دورهای را که به گزارش نیاز دارید وارد میکنید، آخرین روز در نظر گرفته نمیشود. یعنی، در جایی از پرس و جو <= وجود نداشت، بلکه به سادگی < بود. به من گفته شد که این سه امتیاز داستان است، به این معنی 3 روز.
بعد از آن ما:
- ما سیستم امتیازدهی داستان (Story Points) را اصلاح کردهایم. اکنون، رفع اشکالات جزئی که میتوانند به سرعت از طریق سیستم پردازش شوند، سریعتر به دست کاربران میرسند.
- ما شروع به تجمیع تیکتهای توسعه و آزمایش مرتبط کردیم. پیش از این، هر تیکت، هر باگ، یک اکوسیستم بسته بود که به هیچ چیز دیگری متصل نبود. تغییر سه دکمه در یک صفحه میتوانست به جای یک تست خودکار واحد در هر صفحه، منجر به سه تیکت مختلف با سه فرآیند تضمین کیفیت متفاوت شود.
- ما شروع به همکاری با توسعهدهندگان برای رویکردی جهت تخمین هزینههای نیروی کار کردیم. سه روز برای تغییر یک دکمه چیز عجیبی نیست.
روز بیستم
تقریباً اواسط ماه اول، اوضاع کمی تثبیت شد، فهمیدم اساساً چه اتفاقی دارد میافتد، و شروع کردم به آینده نگاه کنم و به راهحلهای بلندمدت فکر کنم.
اهداف بلند مدت:
- پلتفرم مدیریتشده. صدها پرس و جو در هر صفحه جدی نیست.
- روندهای قابل پیشبینی. اوجهای ترافیکی دورهای وجود داشت که در نگاه اول، به نظر نمیرسید با سایر معیارها همبستگی داشته باشند - ما باید میفهمیدیم که چرا این اتفاق افتاده و یاد میگرفتیم که آن را پیشبینی کنیم.
- گسترش پلتفرم. این کسب و کار دائماً در حال رشد است، کاربران بیشتر و بیشتری میآیند و ترافیک در حال افزایش است.
در گذشته اغلب گفته میشد: «بیایید همه چیز را در [زبان/چارچوب] از نو بنویسیم، همه چیز بهتر کار خواهد کرد!»
در بیشتر موارد، این کار جواب نمیدهد؛ اگر بازنویسی اصلاً جواب بدهد، چیز خوبی است. بنابراین ما نیاز به ایجاد یک نقشه راه داشتیم - یک استراتژی مشخص که گام به گام نحوه دستیابی به اهداف تجاری ما (چه کاری انجام خواهیم داد و چرا) را نشان دهد، که:
- منعکس کننده ماموریت و اهداف پروژه است؛
- اهداف کلیدی را اولویتبندی میکند؛
- شامل یک برنامه زمانی برای دستیابی به آنها است.
پیش از این، هیچکس با تیم در مورد هدف از هرگونه تغییری صحبت نکرده بود. این امر مستلزم معیارهای موفقیت مناسبی است. برای اولین بار در تاریخ شرکت، ما شاخصهای کلیدی عملکرد (KPI) را برای تیم فنی تعیین کردیم و این معیارها را به معیارهای سازمانی پیوند دادیم.
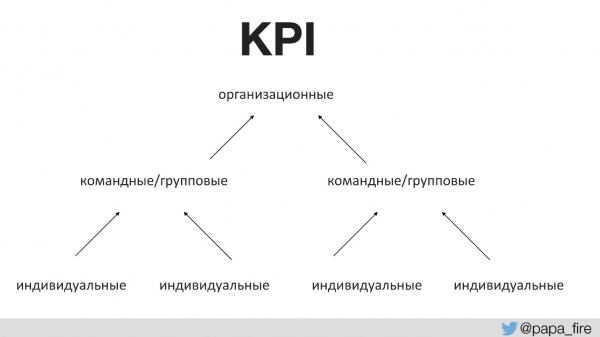
به عبارت دیگر، شاخصهای کلیدی عملکرد سازمانی توسط تیمها پشتیبانی میشوند و شاخصهای کلیدی عملکرد تیمی توسط شاخصهای کلیدی عملکرد فردی پشتیبانی میشوند. در غیر این صورت، اگر شاخصهای کلیدی عملکرد فرآیند با شاخصهای کلیدی عملکرد سازمانی همسو نباشند، همه مسئولیت را به دوش خواهند کشید.
برای مثال، یکی از شاخصهای کلیدی عملکرد سازمانی، افزایش سهم بازار از طریق محصولات جدید است.
چگونه میتوانیم از هدف داشتن محصولات جدید بیشتر حمایت کنیم؟
- اول اینکه، ما میخواهیم به جای رفع نقصها، زمان بیشتری را صرف توسعه محصولات جدید کنیم. این یک تصمیم منطقی است که به راحتی قابل اندازهگیری است.
- دوم اینکه، ما میخواهیم از رشد حجم تراکنشها حمایت کنیم، زیرا هرچه سهم بازار بیشتر باشد، کاربران بیشتر و در نتیجه، ترافیک بیشتری خواهیم داشت.
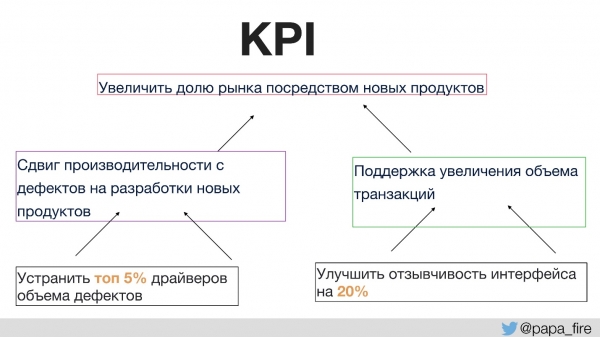
سپس، شاخصهای کلیدی عملکرد (KPI) منفردی که میتوانند در داخل گروه پیادهسازی شوند، به عنوان مثال، در جایی قرار میگیرند که نقصهای اصلی از آنجا سرچشمه میگیرند. با تمرکز ویژه بر این بخش، میتوانید نقصها را به میزان قابل توجهی کاهش دهید، زمان صرف شده برای توسعه محصولات جدید را افزایش دهید و دوباره، از شاخصهای کلیدی عملکرد سازمانی پشتیبانی کنید.
بنابراین، هر تصمیمی، از جمله بازنویسی کد، باید از اهداف خاصی که شرکت برای ما تعیین کرده است (رشد سازمانی، ویژگیهای جدید، استخدام) پشتیبانی کند.
در طول این فرآیند، نکتهی جالبی پدیدار شد که نه تنها برای تیم فنی، بلکه برای کل شرکت نیز تازگی داشت: تمام تیکتها باید حداقل روی یک شاخص کلیدی عملکرد (KPI) متمرکز باشند. بنابراین، اگر یک مدیر محصول میگوید که میخواهد یک ویژگی جدید بسازد، اولین سوال باید این باشد: «این ویژگی از چه شاخص کلیدی عملکردی (KPI) پشتیبانی میکند؟» اگر هیچ کدام را پشتیبانی نمیکند، پس متاسفم - به نظر میرسد یک ویژگی غیرضروری است.
روز سیام
در پایان ماه، نکته ظریف دیگری را کشف کردم: هیچکس در تیم عملیاتی من تا به حال قراردادهایی را که با مشتریان امضا میکنیم ندیده بود. شاید بپرسید، چرا کسی باید بخواهد اطلاعات تماسها را ببیند؟
- اولاً، زیرا SLA ها در قراردادها مشخص میشوند.
- ثانیاً، همه SLA ها متفاوت هستند. هر مشتری با الزامات خاص خود آمده است و تیم فروش بدون نگاه کردن به آنها، آنها را امضا کرده است.
نکته جالب دیگر: در قرارداد با یکی از بزرگترین مشتریان ما آمده است که تمام نسخههای نرمافزاری پشتیبانیشده توسط پلتفرم باید n-1 باشند، یعنی نه آخرین نسخه، بلکه یکی مانده به آخر.
اگر این پلتفرم مبتنی بر ColdFusion و SQL Server 2008 بود، که در ماه جولای دیگر پشتیبانی نمیشد، مشخص است که چقدر از n-1 فاصله داشتیم.
روز چهل و پنجم
جایی حدود اواسط ماه دوم، وقت کافی داشتم که بنشینم و انجام دهم ارزشجریاننقشه برداری کل فرآیند. اینها مراحل ضروری هستند که باید از ایجاد محصول تا تحویل به مصرف کننده انجام شوند و باید تا حد امکان با جزئیات شرح داده شوند.
شما فرآیند را به بخشهای کوچک تقسیم میکنید و بررسی میکنید که چه چیزی بیش از حد طول میکشد، چه چیزی میتواند بهینه شود، بهبود یابد و غیره. به عنوان مثال، چقدر طول میکشد تا درخواست محصول از مرحلهی آمادهسازی عبور کند، چه زمانی به تیکتی میرسد که یک توسعهدهنده میتواند آن را مدیریت کند، تضمین کیفیت و غیره. شما هر مرحله را با جزئیات بررسی میکنید و به این فکر میکنید که چه چیزی میتواند بهینه شود.
وقتی داشتم این کار را میکردم، دو نکته توجهم را جلب کرد:
- درصد بالایی از تیکتها از بخش تضمین کیفیت به توسعهدهندگان بازگردانده شدهاند؛
- بررسی درخواستهای Pull خیلی طول کشید.
مشکل این بود که اینها نتیجهگیریهایی از این قبیل بودند: به نظر میرسد زمان زیادی طول میکشد، اما ما دقیقاً مطمئن نیستیم چقدر.
«شما نمیتوانید چیزی را که نمیتوانید اندازهگیری کنید، بهبود بخشید.»
چطور میتوانید جدی بودن یک مشکل را توجیه کنید؟ آیا روزها یا ساعتها وقت شما را تلف میکند؟
برای اندازهگیری این موضوع، ما چند مرحله به فرآیند جیرا اضافه کردیم: «آماده برای توسعه» و «آماده برای تضمین کیفیت» تا مدت زمان انتظار هر تیکت و تعداد دفعاتی که به یک مرحله خاص برمیگردد را اندازهگیری کنیم.
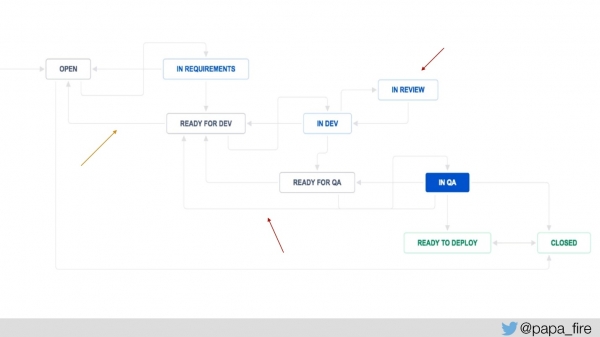
ما همچنین «در حال بررسی» را اضافه کردیم تا میانگین زمانی که تیکتها در دست بررسی هستند را پیگیری کنیم و سپس میتوانیم از آنجا شروع به اندازهگیری کنیم. ما قبلاً معیارهای سیستم را داشتیم، اما اکنون معیارهای جدیدی اضافه کردهایم و شروع به اندازهگیری کردهایم:
- کارایی فرآیند: عملکرد و برنامهریزیشده/تحویلشده.
- کیفیت فرآیند: تعداد نقصها، نقصهای ناشی از تضمین کیفیت.
این واقعاً به درک اینکه چه چیزی خوب پیش میرود و چه چیزی بد پیش میرود، کمک میکند.
روز پنجاهم
البته همه اینها خوب و جالب است، اما در اواخر ماه دوم، اتفاقی افتاد که اساساً قابل پیشبینی بود، اگرچه انتظار چنین مقیاسی را نداشتم. افراد شروع به ترک شرکت کردند زیرا مدیران ارشد تغییر کرده بودند. افراد جدیدی به مدیریت آمدند و شروع به تغییر همه چیز کردند و قدیمیها استعفا دادند. و معمولاً در شرکتی که چند سال سابقه دارد، همه با هم دوست هستند و همه یکدیگر را میشناسند.
این قابل پیشبینی بود، اما مقیاس تعدیل نیرو غیرمنتظره بود. برای مثال، در یک هفته، دو سرپرست تیم همزمان استعفای خود را ارائه دادند. بنابراین، من نه تنها مجبور شدم مسائل دیگر را فراموش کنم، بلکه باید روی ... نیز تمرکز میکردم. ایجاد یک تیمحل این مشکل طولانی و دشوار است، اما باید به آن رسیدگی میشد زیرا میخواستیم افرادی که باقی مانده بودند (یا حداقل بیشتر آنها) را حفظ کنیم. ما باید به نحوی به افرادی که رفته بودند پاسخ میدادیم تا روحیه تیم حفظ شود.
در تئوری، این چیز خوبی است: یک فرد جدید با اختیار کامل از راه میرسد، میتواند مهارتهای تیم را ارزیابی کند و جایگزین کارکنان فعلی شود. در واقعیت، به دلایل مختلف، آوردن افراد جدید به سادگی غیرممکن است. همیشه نیاز به تعادل وجود دارد.
- قدیمی و جدید. ما باید افراد قدیمی را که میتوانند تغییر دهند و از ماموریت حمایت کنند، حفظ کنیم. اما در عین حال، باید خون تازهای به رگهایمان تزریق کنیم که کمی بعد در مورد آن صحبت خواهیم کرد.
- تجربه. من با افراد سال آخر خوب که مشتاق پیوستن به ما بودند، زیاد صحبت کردم. اما نتوانستم آنها را استخدام کنم زیرا به اندازه کافی ارشد برای حمایت و راهنمایی آنها وجود نداشت. ما مجبور بودیم ابتدا افراد برتر را استخدام کنیم و فقط پس از آن جوانان را.
- چماق و هویج.
من پاسخ خوبی برای این سوال که تعادل مناسب چیست، چگونه آن را حفظ کنیم، چند نفر را نگه داریم و چقدر فشار وارد کنیم، ندارم. این یک فرآیند کاملاً فردی است.
روز پنجاه و یکم
شروع کردم به بررسی اعضای تیم تا ببینم چه کسانی را دارم، و یک بار دیگر به یاد آوردم:
«بیشتر مشکلات، مشکلات مردم هستند.»
من متوجه شدم که کل تیم، چه توسعهدهندگان و چه تیم عملیاتی، سه مشکل بزرگ داشتند:
- رضایت از وضعیت فعلی امور.
- عدم مسئولیت پذیری — زیرا هیچکس تا به حال نتایج کار اجراکنندگان را به تأثیر آنها بر کسبوکار تبدیل نکرده است.
- ترس از تغییر.

تغییر همیشه شما را از منطقه امنتان خارج میکند، و هرچه افراد جوانتر باشند، بیشتر از تغییر متنفر میشوند زیرا دلیل یا چگونگی آن را نمیفهمند. رایجترین پاسخی که شنیدم این بود: «ما هرگز این کار را به این روش انجام ندادهایم.» این به نقطه پوچی کامل رسیده بود - حتی کوچکترین تغییر بدون شکایت کسی انجام نمیشد. و مهم نبود که این تغییر چقدر بر کارشان تأثیر میگذاشت، مردم میگفتند: «نه، چرا باید زحمت بکشیم؟ این کار جواب نمیدهد.»
اما بدون تغییر هیچ چیز، نمیتوانید بهتر شوید.
من یک مکالمه کاملاً پوچ با یک کارمند داشتم، داشتم ایدههایم را برای بهینهسازی به او میگفتم که او گفت:
- آه، تو ندیدی پارسال چی داشتیم!
- پس چی؟
- الان خیلی بهتر از قبل شده.
- خب، دیگه بهتر از این نمیشه؟
- چرا؟
سوال خوبی بود—چرا؟ انگار اگر اوضاع الان بهتر از قبل است، پس همه چیز به اندازه کافی خوب است. این منجر به عدم پاسخگویی میشود که کاملاً طبیعی است. همانطور که گفتم، گروه فنی کمی در حاشیه بود. شرکت فکر میکرد که آنها باید آنجا باشند، اما هیچ کس هرگز استاندارد تعیین نکرده استپشتیبانی فنی هرگز SLA ندیده بود، بنابراین برای گروه کاملاً "قابل قبول" بود (و این چیزی بود که بیش از همه من را تحت تأثیر قرار داد):
- بارگیری ۱۲ ثانیهای؛
- ۵ تا ۱۰ دقیقه زمان از کارافتادگی برای هر انتشار؛
- حل مسائل بحرانی روزها و هفتهها طول میکشد؛
- بدون کارمند 24 ساعته/7 روز هفته.
هیچکس هرگز سعی نکرد بپرسد که چرا نمیتوانیم آن را بهتر انجام دهیم، و هیچکس هرگز متوجه نشد که نباید اینطور باشد.
به عنوان یک امتیاز، یک مشکل دیگر هم وجود داشت: کمبود تجربهسالخوردگان رفتند و تیم جوان باقی مانده در رژیم قبلی رشد کرد و از آن مسموم شد.
علاوه بر همه اینها، مردم از شکست و بیکفایت به نظر رسیدن نیز میترسیدند. این موضوع در این واقعیت منعکس میشد که، اولاً، تحت هیچ شرایطی درخواست کمک نکرده استچند بار پیش آمده که ما به صورت گروهی و انفرادی با هم صحبت کردهایم و من گفتهام: «اگر نمیدانید چطور کاری را انجام دهید، سوال بپرسید؟» من به خودم اعتماد دارم و میدانم که میتوانم هر مشکلی را حل کنم، اما زمان میبرد. بنابراین اگر بتوانم از کسی که میداند چگونه آن را در عرض ۱۰ دقیقه حل کند، بپرسم، این کار را انجام خواهم داد. هرچه تجربه کمتری داشته باشید، بیشتر از پرسیدن میترسید، زیرا فکر میکنید بیکفایت تلقی خواهید شد.
این ترس از پرسیدن سوال به شکلهای جالبی خودش را نشان میدهد. برای مثال، شما میپرسید: «این کار چطور پیش میرود؟» و آنها میگویند: «فقط چند ساعت دیگر مانده، تقریباً کارم تمام شده است.» روز بعد، دوباره میپرسید و به شما گفته میشود که همه چیز خوب است، اما فقط یک مشکل وجود دارد و قطعاً تا پایان روز حل خواهد شد. یک روز دیگر میگذرد و تا زمانی که آنها را گیر نیندازید و مجبورشان نکنید با کسی صحبت کنند، اوضاع به همین منوال ادامه پیدا میکند. آنها میخواهند خودشان مشکل را حل کنند، چون معتقدند که حل نکردن آن توسط خودشان، یک شکست بزرگ خواهد بود.
به همین دلیل است توسعهدهندگان تخمینها را بیش از حد بزرگ کردندخیلی شوخی بود: وقتی داشتیم در مورد یک کار خاص بحث میکردیم، آنها رقمی به من دادند که واقعاً من را شگفتزده کرد. آنها به من گفتند که در تخمینهایشان، توسعهدهنده زمانی را که طول میکشد تا تیکت از QA برگردانده شود تا اشکالات پیدا شود، زمانی را که طول میکشد تا PR انجام شود، و زمانی را که افرادی که قرار است آن را بررسی کنند مشغول هستند - به عبارت دیگر، هر چیز ممکنی را در نظر میگیرد.
دوم، افرادی که از بیکفایت به نظر رسیدن میترسند، بیش از حد تحلیل کردنوقتی به آنها میگویی دقیقاً چه کاری باید انجام شود، شروع میکنند به گفتن: «نه، اگر اینجا به آن فکر کنیم چه؟» از این نظر، شرکت ما منحصر به فرد نیست؛ این یک مشکل رایج بین جوانان است.
در پاسخ، من شیوههای زیر را معرفی کردم:
- قانون ۳۰ دقیقه. اگر نمیتوانید مشکل را در نیم ساعت حل کنید، از شخص دیگری کمک بخواهید. این روش با موفقیتهای مختلفی جواب میدهد، زیرا مردم به هر حال درخواستی نمیکنند، اما حداقل این روند آغاز شده است.
- همه چیز را به جز اصل مطلب حذف کنید، در تخمین زمان لازم برای انجام یک کار، یعنی فقط در نظر بگیرید که نوشتن کد چقدر طول میکشد.
- یادگیری مداوم برای کسانی که بیش از حد تحلیل میکنند. این فقط کار مداوم با مردم است.
روز شصتم
در حالی که داشتم همه این کارها را انجام میدادم، وقت آن رسیده بود که بودجه را مرتب کنم. البته، نکات جالب زیادی در مورد نحوه خرج کردن پول پیدا کردم. برای مثال، ما یک رک کامل در یک مرکز داده جداگانه داشتیم که یک سرور FTP واحد را که توسط یک مشتری استفاده میشد، در خود جای داده بود. معلوم شد که "... ما نقل مکان کردیم، اما آنجا ماند، ما آن را جایگزین نکردیم." این مربوط به دو سال پیش است.
صورتحساب فضای ابری به طور خاص جالب بود. مطمئنم دلیل اصلی هزینه بالای فضای ابری این است که توسعهدهندگان، برای اولین بار در زندگیشان، دسترسی نامحدودی به سرورها دارند. آنها مجبور نیستند بپرسند: «لطفاً یک سرور آزمایشی به من بدهید» - خودشان میتوانند آن را بگیرند. به علاوه، توسعهدهندگان همیشه میخواهند سیستمی چنان جذاب بسازند که فیسبوک و نتفلیکس به آن حسادت کنند.
اما توسعهدهندگان فاقد تجربه در تهیه سرور و مهارتهای لازم برای تعیین اندازه مناسب سرور هستند، زیرا قبلاً نیازی به انجام این کار نداشتهاند. و اغلب تفاوت بین مقیاسپذیری و عملکرد را به طور کامل درک نمیکنند.
نتایج موجودی:
- از همان مرکز داده آمده است.
- ما قراردادها را با سه سرویس ثبت وقایع فسخ کردیم. چون پنج تا از آنها را داشتیم—هر توسعهدهندهای که شروع به کار با چیزی میکرد، یک توسعهدهنده جدید استخدام میکرد.
- هفت سیستم AWS تعطیل شدند. باز هم، پروژههای از کار افتاده تعطیل نشدند؛ آنها به فعالیت خود ادامه دادند.
- هزینه نرمافزار را تا ۶ برابر کاهش داد.
روز هفتاد و پنجم
زمان گذشت و قرار شد دو ماه و نیم دیگر با هیئت مدیره ملاقات کنم. هیئت مدیره ما نه بهتر و نه بدتر از بقیه است؛ مثل همه هیئت مدیرهها، میخواهد همه چیز را بداند. مردم پول سرمایهگذاری میکنند و میخواهند بفهمند که کار ما چگونه با شاخصهای کلیدی عملکرد (KPI) ما همسو است.
هیئت مدیره هر ماه اطلاعات زیادی دریافت میکند: تعداد کاربران، رشد آنها، اینکه از چه سرویسهایی و چگونه استفاده میکنند، عملکرد و بهرهوری و در نهایت، میانگین سرعت بارگذاری صفحات.
تنها مشکل این است که به نظر من میانگین، شر مطلق است. اما توضیح این موضوع به هیئت مدیره بسیار دشوار است. آنها به کار با اعداد تجمیعی عادت دارند، نه مثلاً پراکندگی زمان بارگذاری در هر ثانیه.
نکات جالبی در این زمینه مطرح شد. مثلاً گفتم که ترافیک باید بسته به نوع محتوا بین وب سرورهای جداگانه تقسیم شود.

بنابراین، ColdFusion از Jetty و nginx عبور میکند و صفحات را اجرا میکند. و تصاویر، JS و CSS از طریق یک nginx جداگانه با تنظیمات خاص خود عبور میکنند. این یک روش نسبتاً استاندارد است که من در مورد آن صحبت میکنم. همین چند سال پیش. در نتیجه، تصاویر خیلی سریعتر بارگذاری میشوند و... میانگین سرعت بارگذاری ۲۰۰ میلیثانیه افزایش یافت.
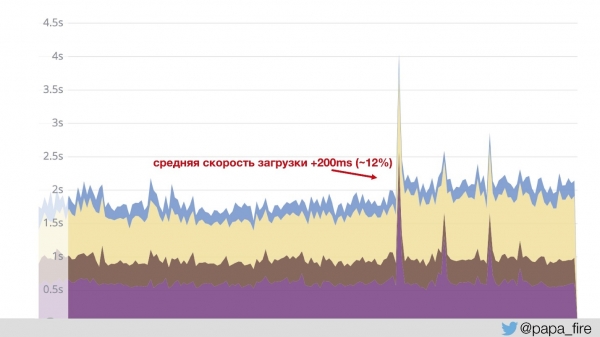
این اتفاق افتاد زیرا نمودار بر اساس دادههای Jetty است. یعنی محتوای سریع در محاسبه لحاظ نشده است - رقم میانگین افزایش یافته است. ما این را فهمیدیم و به آن خندیدیم، اما چگونه میتوانستیم برای هیئت مدیره توضیح دهیم که چرا کاری انجام دادیم که باعث کاهش ۱۲ درصدی شد؟
روز هشتاد و پنجم
تا پایان ماه سوم، متوجه شدم یک چیز هست که اصلاً روی آن حساب نکرده بودم: زمان. هر چیزی که در موردش صحبت کردهام، زمان میبرد.

این تقویم هفتگی واقعی من است - یک هفته کاری ساده، نه یک هفته خیلی شلوغ. برای همه چیز وقت کافی وجود ندارد. بنابراین، دوباره، باید افرادی را استخدام کنم تا در مقابله با مشکلات به من کمک کنند.
نتیجه
این تمام ماجرا نیست. در این داستان، من حتی به این موضوع که چگونه با محصول کار کردیم و سعی کردیم به توافق برسیم، یا چگونه پشتیبانی فنی را ادغام کردیم، یا چگونه سایر مشکلات فنی را حل کردیم، نرسیدهام. برای مثال، من کاملاً تصادفی متوجه شدم که ما از ... استفاده نمیکنیم. SEQUENCEما یک تابع خودنویس داریم nextIDو در تراکنش استفاده نمیشود.
یک میلیون مورد مشابه دیگر وجود داشت که میتوان به تفصیل در مورد آنها بحث کرد. اما مهمترین چیزی که ارزش ذکر کردن دارد فرهنگ است.

این فرهنگ یا فقدان آن است که منجر به تمام مشکلات دیگر میشود. ما در تلاشیم فرهنگی بسازیم که در آن مردم:
- از شکست نمیترسند؛
- از اشتباهات درس بگیرید؛
- همکاری با تیمهای دیگر؛
- ابتکار عمل نشان دهید؛
- مسئولیت را بر عهده بگیرید؛
- از نتیجه به عنوان یک هدف استقبال کنید؛
- موفقیت را جشن بگیرید.
با این، همه چیزهای دیگر هم به دست خواهد آمد.
لئون فایر , و .
دو استراتژی برای مقابله با میراث وجود دارد: اجتناب از آن به هر قیمتی، یا غلبه شجاعانه بر مشکلاتی که با آن همراه است. ما ما مسیر دوم را در پیش گرفتهایم، یعنی تغییر فرآیندها و رویکردها. به ما بپیوندید , и و با هم فرهنگ DevOps را پیادهسازی خواهیم کرد.
منبع: www.habr.com
